
как найти и удалить дубли страниц
Автор Алексей На чтение 7 мин. Опубликовано
Поисковые алгоритмы постоянно развиваются, часто уже сами могут определить дубли страницы и не включать такие документы в основной поиск. Тем не менее, проводя экспертизы сайтов, мы постоянно сталкиваемся с тем, что в определении дублей алгоритмы еще далеки от совершенства.
Что такое дубли страниц?
Дубли страниц на сайте – это страницы, контент которых полностью или частично совпадает с контентом другой, уже существующей в сети страницы.
Адреса таких страниц могут быть почти идентичными.
Дубли:
- с доменом, начинающимся на www и без www, например, www.site.ru и site.ru.
- со слешем в конце, например, site.ru/seo/ и site.ru/seo
- с .php или .html в конце, site.ru/seo.html и site.ru/seo.php
Одна и та же страница, имеющая несколько адресов с указанными отличиями восприниматься как несколько разных страниц – дублей по отношению друг к другу.
Какими бывают дубликаты?
Перед тем, как начать процесс поиска дублей страниц сайта, нужно определиться с тем, что они бывают 2-х типов, а значит, процесс поиска и борьбы с ними будет несколько отличным. Так, в частности, выделяют:
- Полные дубли — когда одна и та же страница размещена по 2-м и более адресам.
- Частичные дубли — когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress обычно дублей страниц нет, а вот Joomla генерирует огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Влияние дублей на продвижение сайта
- Дубли нежелательны с точки зрения SEO, поскольку поисковые системы накладывают на такие сайты санкции, отправляют их в фильтры, в результате чего понижается рейтинг страниц и всего сайта вплоть до изъятия из поисковой выдачи.
- Дубли мешают продвижению контента страницы, влияя на релевантность продвигаемых страниц. Если одинаковых страниц несколько, то поисковику непонятно, какую из них нужно продвигать, в результате ни одна из них не оказывается на высокой позиции в выдаче.
- Дубли снижают уникальность контента сайта: она распыляется между всеми дублями. Несмотря на уникальность содержания, поисковик воспринимает вторую страницу неуникальной по отношении к первой, снижает рейтинг второй, что сказывается на ранжировании (сортировка сайтов для поисковой выдачи).
- За счет дублей теряется вес основных продвигаемых страниц: он делится между всеми эквивалентными.
- Поисковые роботы тратят больше времени на индексацию всех страниц сайта, индексируя дубли.
Как найти дубли страниц
Исходя из принципа работы поисковых систем, становится понятно, что одной странице должна соответствовать только одна ссылка, а одна информация должна быть только на одной странице сайта. Тогда будут благоприятные условия для продвижения нужных страниц, а поисковики смогут адекватно оценить ваш контент. Для этого дубли нужно найти и устранить.
Программа XENU (полностью бесплатно)
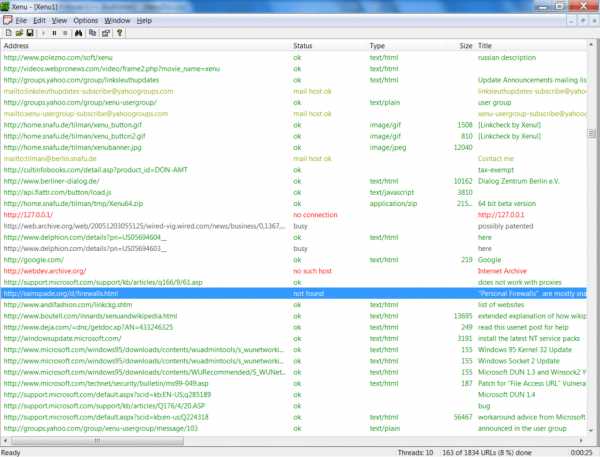
Программа Xenu Link Sleuth (http://home.snafu.de/tilman/xenulink.html), работает независимо от онлайн сервисов, на всех сайтах, в том числе, на сайтах которые не проиндексированы поисковиками. Также с её помощью можно проверять сайты, у которых нет накопленной статистики в инструментах вебмастеров.
Поиск дублей осуществляется после сканирования сайта программой XENU по повторяющимся заголовкам и метаописаниям.
Программа Screaming Frog SEO Spider (частично бесплатна)
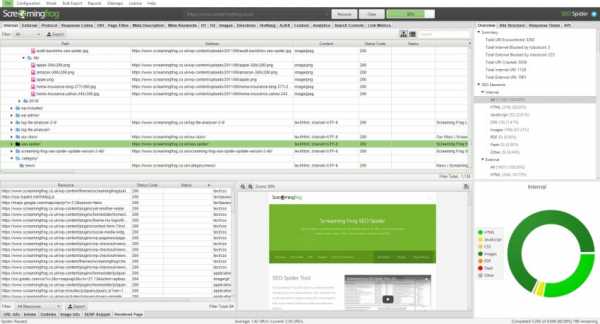
Адрес программы https://www.screamingfrog.co.uk/seo-spider/. Это программа работает также как XENU, но более красочно. Программа сканирует до 500 ссылок сайта бесплатно, более объемная проверка требует платной подписки. Сам ей пользуюсь.
Программа Netpeak Spider (платная с триалом)
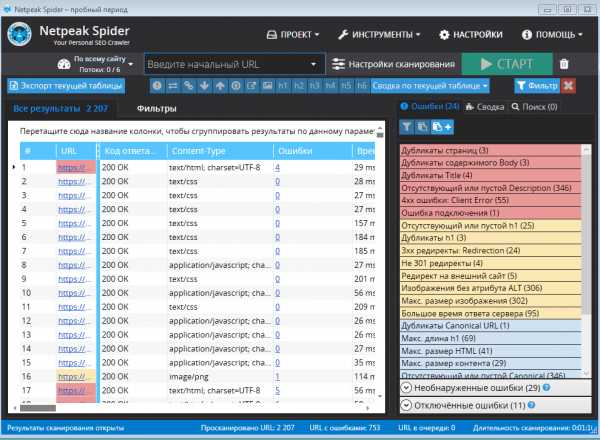
Ссылка на программу Netpeak Spider. Еще один программный сканер для анализа ссылок сайта с подробным отчетом.
Яндекс Вебмастер
Для поиска дублей можно использовать Яндекс.Вебмастер после набора статистики по сайту. В инструментах аккаунта на вкладке Индексирование > Страницы в поиске можно посмотреть «Исключенные страницы» и выяснить причину их удаления из индекса. Одна из причин удаления это дублирование контента. Вся информация доступна под каждым адресом страницы.
Google Search Console
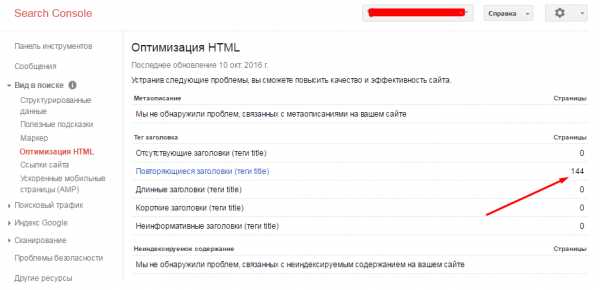
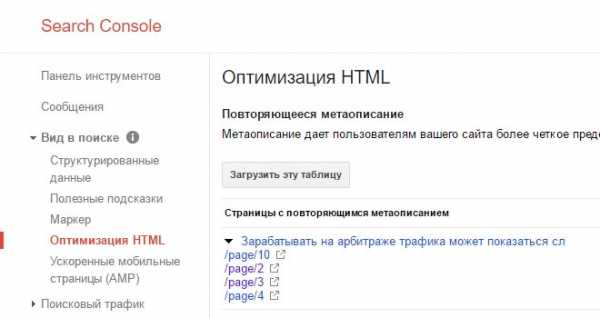
В консоли веб-мастера Google тоже есть инструмент поиска дублей. Откройте свой сайт в консоли Гугл вебмастер. На вкладке Вид в поиске > Оптимизация HTML вы увидите, если есть, повторяющиеся заголовки и метаописания. Вероятнее всего это дубли (частичные или полные).
Язык поисковых запросов
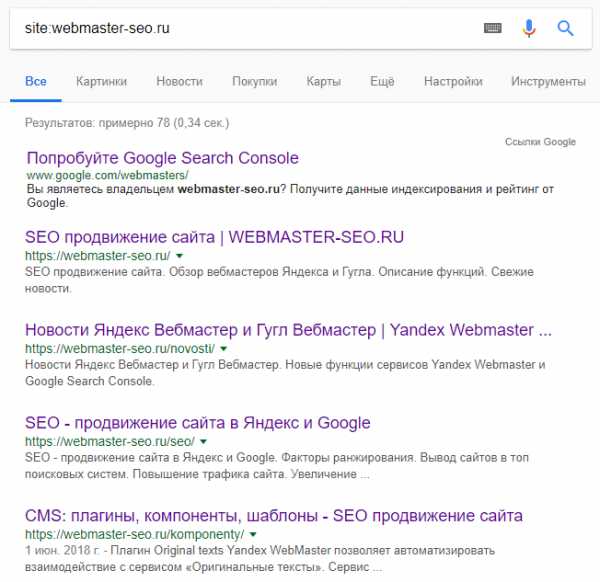
Используя язык поисковых запросов можно вывести список всех страниц сайта, которые есть в выдаче (оператор «site:» в Google и Yandex) и поискать дубли «глазами».
Сервисы онлайн
Есть сервисы, который проверяют дубли страниц на сайте онлайн. Например, сервис Siteliner.com (http://www.siteliner.com/). На нём можно найти битые ссылки и дубли. Можно проверить до 25000 страниц по подписке и 250 страниц бесплатно.
Российский сервис Saitreport.ru, может помочь в поиске дублей. Адрес сервиса: https://saitreport.ru/poisk-dublej-stranic
Удаление дублей страниц сайта
Способов борьбы с дубликатами не так уж и много, но все они потребуют от вас привлечения специалистов-разработчиков, либо наличия соответствующих знаний. По факту же арсенал для «выкорчевывания» дублей сводится к:
- Их физическому удалению — хорошее решение для статических дублей.
- Запрещению индексации дублей в файле robots.txt — подходит для борьбы со служебными страницами, частично дублирующими контент основных посадочных.
- Настройке 301 редиректов в файле-конфигураторе «.htaccess» — хорошее решение для случая с рефф-метками и ошибками в иерархии URL.
- Установке тега «rel=canonical» — лучший вариант для страниц пагинации, фильтров и сортировок, utm-страниц.
- Установке тега «meta name=»robots» content=»noindex, nofollow»» — решение для печатных версий, табов с отзывами на товарах.
Чек-лист по дублям страниц
Часто решение проблемы кроется в настройке самого движка, а потому основной задачей оптимизатора является не столько устранение, сколько выявление полного списка частичных и полных дублей и постановке грамотного ТЗ исполнителю.
Запомните следующее:
- Полные дубли — это когда одна и та же страница размещена по 2-м и более адресам. Частичные дубли — это когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
- Полные и частичные дубли могут понизить позиции сайта в выдаче не только в масштабах URL, а и всего домена.
- Полные дубликаты не трудно найти и устранить. Чаще всего причина их появления зависит от особенностей CMS сайта и навыков SEO разработчика сайта.
- Частичные дубликаты найти сложнее и они не приводят к резким потерям в ранжировании, однако делают это постепенно и незаметно для владельца сайта.
- Чтобы найти частичные и полные дубли страниц, можно использовать мониторинг выдачи с помощью поисковых операторов, специальные программы-парсеры, поисковую консоль Google и ручной поиск на сайте.
- Избавление сайта от дублей сводится к их физическому удалению, запрещению индексации дублей в файле «robots.txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name=»robots» content=»noindex, nofollow»».
webmaster-seo.ru
Как найти и удалить дубли страниц на сайте — Офтоп на vc.ru
Дубли страниц — документы, имеющие одинаковый контент, но доступные по разным адресам. Наличие таких страниц в индексе негативно сказывается на ранжировании сайта поисковыми системами.
Какой вред они могут нанести
- Снижение общей уникальности сайта.
- Затрудненное определение релевантности и веса страниц (поисковая система не может определить, какую страницу из дубликатов необходимо показывать по запросу).
- Зачастую дубли страниц имеют одинаковые мета-теги, что также негативно сказывается на ранжировании.
Как появляются дубликаты
Технические ошибки
К ним относят доступность страниц сайта:
- по www и без www;
- со слэшем на конце и без;
- с index.php и без него;
- доступность страницы при добавлении различных GET-параметров.
Особенности CMS
- страницы пагинации сайта;
- страницы сортировки, фильтрации и поиска товаров;
- передача лишних параметров в адресе страницы.
Важно! Также дубли страниц могут появляться за счет доступности первой страницы пагинации по двум адресам: http://site.ru/catalog/name/?PAGEN_1=1 и http://site.ru/catalog/name/.
Дубликаты, созданные вручную
Один из наиболее частых примеров дублирования страниц — привязка товаров к различным категориям и их доступность по двум адресам. Например: http://site.ru/catalog/velosiped/gorniy/stern-bike/ и http://site.ru/catalog/velosiped/stern-bike/.
Также страницы могут повторяться, если структура сайта изменилась, но старые страницы остались.
Поиск дублей страниц сайта
Существует большое количество методов нахождения дубликатов страниц на сайте. Ниже описаны наиболее популярные способы:
- программа Screaming Frog;
- программа Xenu;
- Google Webmaster: «Вид в поиске» -> «Оптимизация HTML»;
- Google Webmaster: «Сканирование» -> «Оптимизация HTML».
Для программы Screaming Frog и Xenu указывается адрес сайта, и после этого робот собирает информацию о нем. После того, как робот просканирует сайт, выбираем вкладку Page Title — Duplicate, и анализируем вручную список полученных страниц.
С помощью инструмента «Оптимизация HTML» можно выявить страницы с одинаковыми description и title. Для этого в панели Google Webmaster надо выбрать необходимый сайт, открыть раздел «Вид в поиске» и выбрать «Оптимизация HTML».
C помощью инструмента «Параметры URL» можно задать параметры, которые необходимо индексировать в адресах страниц.
Для этого надо выбрать параметр, кликнуть на ссылку «Изменить» и выбрать, какие URL, содержащие данный параметр, необходимо сканировать.
Также, найти все индексируемые дубли одной страницы можно с помощью запроса к поиску Яндекса. Для этого в поиске Яндекса необходимо ввести запрос вида site:domen.ru «фраза с анализируемой страницы», после чего проанализировать вручную все полученные результаты.
Как правильно удалить дубли
Чтобы сайт открывался лишь по одному адресу, например «http://www.site.ru/catalog/catalog-name/», а не по «http://site.ru/catalog/catalog-name/index.php», необходимо корректно настроить 301 редиректы в файле htaccess:
- со страниц без www, на www;
- со страниц без слэша на конце, на «/»;
- со страниц с index.php на страницы со слэшем.
Если вам необходимо удалить дубликаты, созданные из-за особенностей системы управления сайтом, надо правильно настроить файл robots.txt, скрыв от индексации страницы с различными GET-параметрами.
Для того чтобы удалить дублирующие страницы, созданные вручную, нужно проанализировать следующую информацию:
- их наличие в индексе;
- поисковый трафик;
- наличие внешних ссылок;
- наличие внутренних ссылок.
Если неприоритетный документ не находится в индексе, то его можно удалять с сайта.
Если же страницы находятся в поисковой базе, то необходимо оценить, сколько поискового трафика они дают, сколько внешних и внутренних ссылок на них проставлено. После этого остается выбрать наиболее полезную.
После этого необходимо настроить 301-редирект со старой страницы на актуальную и поправить внутренние ссылки на релевантные.
Ждите новые заметки в блоге или ищите на нашем сайте.
Материал опубликован пользователем. Нажмите кнопку «Написать», чтобы поделиться мнением или рассказать о своём проекте.
Написатьvc.ru
Похожие, дублированные страницы. Ищем дубли контента
Здравствуйте Уважаемые читатели SEO-Mayak.com. В статье — «Файл robots.txt — запрет индексации для Яндекса и Google» я уже касался темы дублированных страниц и сегодня поговорим об этом более подробно.
Что такое дубли страниц? Это страницы с похожим или одинаковым текстом доступные по разным URL адресам. Например, очень часто встречающиеся дубли главной страницы ресурса
Ниже мы рассмотрим несколько распространенных вариантов дублирования контента, а сейчас давайте поговорим о том, как влияют похожие страницы на продвижение сайта.
Поисковые системы давно научились определять уникальность текста по последовательности символов, т.е по одинаково составленным предложениям, откуда берется последовательность букв и пробелов. Если контент не уникальный (ворованный), то робот без труда это выяснит, а когда не уникальный текст встречается часто, то перспектива попадания такого ресурса под фильтр АГС довольно высока.

Давайте представим себе работу поискового робота. Зайдя на сайт он в первую очередь смотрит на файл robots.txt и от него получает инструкции: что нужно индексировать и что для индексации закрыто. Следующим его действием будет обращение к файлу sitemap.xml, который покажет роботу карту сайта со всем разрешенными маршрутами. Почитайте статью — «Файл sitemap.xml для поисковиков Google и Яндекс.» Получив всю необходимую информацию, робот отправляется выполнять свои привычные функции.
Зайдя на определенную страницу он «впитывает» ее содержимое и сравнивает с уже имеющейся в его электронных мозгах информацией, собранной со всего бескрайнего простора интернета. Уличив текст в не уникальности поисковик не станет индексировать данную страницу и сделает пометку в своей записной книжке, в которую он заносит «провинившиеся» URL адреса. Как Вы наверное уже догадались на эту страницу он больше не вернется, дабы не тратить свое драгоценное время.
Допустим, страница имеет высокую уникальность и робот ее проиндексировал, но пройдя по следующему URL того же ресурса он попадает на страницу с полностью или частично похожим текстом. Как в такой ситуации поступит поисковик? Конечно он тоже не станет индексировать похожий тест, даже если оригинал находиться на том же сайте, но по другому URL. Робот наверняка останется недоволен бесполезно потраченным временем и обязательно сделает пометочку в своем блокноте. Опять же, если такой инцидент будет неоднократно повторяться, то ресурс может пасть в немилость к поисковой системе.
Вывод №1. Похожие страницы расположенные по разными URL отнимают время, которое отводится роботу для индексации сайта. Дубли страниц он все равно индексировать не будет, но потратит часть временного лимита на ознакомление с ними и возможно не успеет добраться до действительно уникального контента.
Вывод№ 2. Дублированный контент отрицательно скажется но продвижении сайта в поисковой системе. Не любят поисковики не уникальные тексты!
Вывод №3. Надо обязательно проверять свой проект на дубли страниц, чтобы избежать проблем перечисленных выше.
Многие совершенно не заботятся об «чистоте» своего контента. Ради интереса я проверил несколько сайтов и был несколько удивлен положению дел с дублями страниц. На блоге одной женщины я вообще не обнаружил файла robots.txt.
Необходимо со всей серьезность бороться с дублями контента и начинать надо с их выявления.
Примеры часто встречающихся дублей контента и способы устранение проблемы
Дубль главной страницы. Пример:
- http://сайт.com
- http://сайт.com/index.php.
В этом случаи вопрос решается с помощью 301 редиректа — «командой» для сервера через файл .htaccess. Как сделать 301 редирект (перенаправление) через файл .htaccess
Еще один пример дубля главной страницы:
- http://сайт.com
- http://www.сайт.com
Чтобы избежать подобного дублирования можно прописать основное зеркало сайта в файле robots.txt в директиве — «Host» для Яндекс:
А также воспользоваться 301 редиректом и указать поисковикам Яндекс и Google на главное зеркало сайта посредством инструментов для веб-мастеров.
Пример дубля главной страницы, который чуть не взорвал мне мозг при поиске решения выглядит так:
- http://сайт.com
- http://сайт.com/
Я где-то прочитал, что слеш в конце ссылки на главную страницу, создает дубль и поисковики воспринимают ссылки со слешом и без, как разные URL, ведущие на страницу с одинаковым текстом. Меня забеспокоила даже не сама возможность дублирования, сколько потеря веса главной страницы в такой ситуации.
Я начал копать. По запросу к серверу по вышеупомянутым URL я получил ответ код 200. Код 200 означает — » Запрос пользователя обработан успешно и ответ сервера содержит затребованные данные». Из этого следует, что все-таки дубль на лицо.
Я даже попытался сделать 301 редирект (перенаправление), но команды не действовали, и желанного ответного кода 301 я так и получил. Решение проблемы состояло в отсутствии самой проблемы. Каламбур такой получился. Оказывается, современные браузеры сами подставляют символ «/» в конце строки, делая его невидимым, что автоматически делает дубль невозможным. Вот так!
Ну и еще один пример дубля главной страницы:
- http://сайт.com
- https://сайт.com
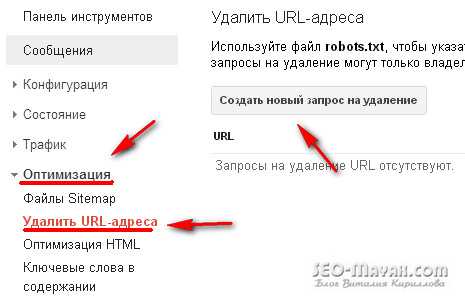
Бывают случаи, что по ошибке веб-мастера или глюка поисковика или при других обстоятельствах в индекс попадает ссылка под защищенным протоколом https://. Что же делать в таком случаи и как избежать этого в будущем? Конечно надо удалить ссылки с протоколом https://из поиска, но делать придется в ручную средствами инструментов для веб-мастеров:
В поисковой системе Яндекс, веб- мастер — мои сайты — удалить URL:

В Google инструменты для веб мастеров — Оптимизация — Удались URL адреса:
И в файле .htaccess прописать 301 редирект.
Теперь пройдемся по дублям встречающимся при не правильном составлении файла robots.txt . Пример:
- http://сайт.com/page/2
- http://сайт.com/2012/02
- http://сайт.com/category/название категории
- http://сайт.com/category/название категории/page/2
На первый взгляд не чего особенного, но это и есть классический пример частичного дублирования.
Что такое частичное дублирование? Это когда в индекс попадают страницы с анонсами постов. Причем размер таких анонсов бывают чуть ли не в половину всей статьи. Не делайте объемных анонсов! Решение проблемы простое. В файле robots.txt прописываем следующее:
- Disallow: /page/
- Disallow: /20*
- Disallow: /category/
Пример полного дублирования:
- http://сайт.com/tag/название статьи
- http://сайт.com/название статьи/comment-page-1
Решение опять же находиться в файле robots.txt
- Disallow: /tag/
- Disallow: /*page*
Я не веду речь про интернет магазины и другие сайты на коммерческой основе, там ситуация другая. Страницы с товарами, содержащие частично повторяющийся текст с множеством изображений, также создают дубли, хотя визуально выглядит все нормально. В таких случаях в основном применяется специальный тег:
rel="canonical"
Который указывает поисковику на основную страницу, подробнее читайте тут.
Важно! Директивы, прописанные в файле robots.txt, запрещают поисковым роботам сканировать текст, что уберегает сайт от дублей, но те же директивы не запрещают индексировать URL страниц.
Подробнее читайте в статьях:
Supplemental index. Дополнительный (сопливый) индекс Google
Мета-тег robots. Правильная настройка индексации сайта
Как определить похожие страницы по фрагменту текста
Есть еще один довольно действенный способ определения «клонов» с помощью самих поисковых систем. В Яндексе в поле поиска надо вбить: link.сайт.com «Фрагмент теста». Пример:
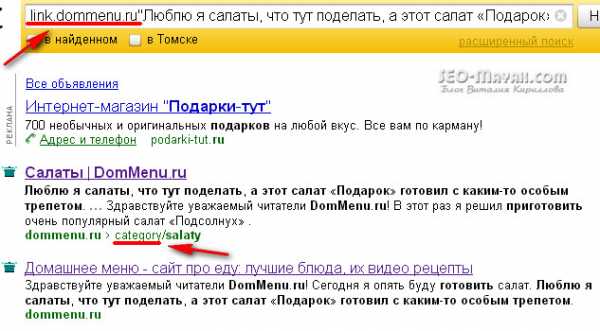
Яндекс нашел 2 совпадения потому, что я не закрыл от индексации категории и поэтому есть совпадение с анонсом на главной странице. Но если для кулинарного блога участие рубрик в поиске оправдано, то для других тематик, таких как SEO такой необходимости нет и категории лучше закрыть от индексации.
С помощью поиска Google проверить можно так: site:сайт.com «Фрагмент текста». Пример:
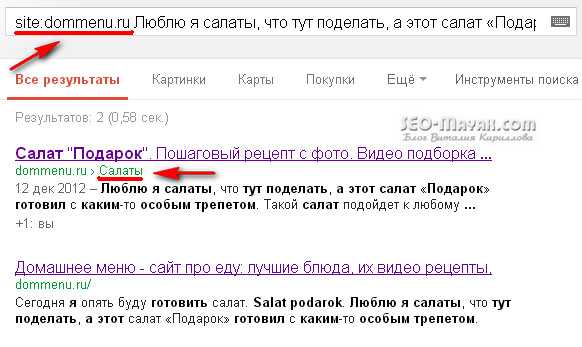
Программы и онлайн сервисы для поиска внутренних и внешних дублей контента по фрагментам текста
Я не буду в этой статье делать подробный обзор популярных программ и сервисов, остановлюсь лишь на тех, которыми сам постоянно пользуюсь.
Для поиска внутренних и внешних дублей советую использовать онлайн сервис www.miratools.ru. Помимо проверки текста сервис включает еще различные интересные возможности.
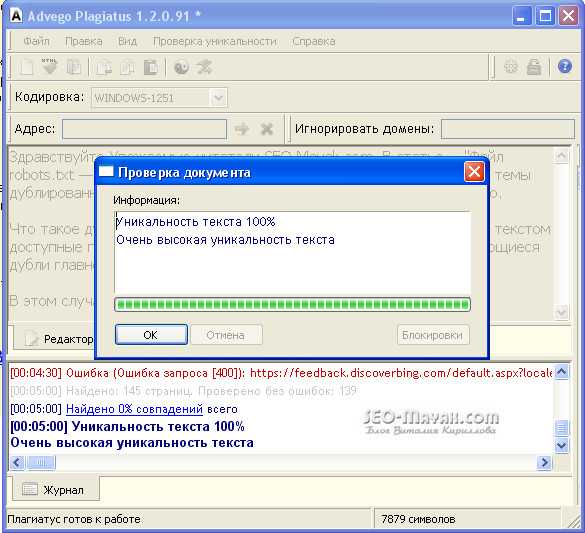
Программа для поиска дублей — Advego Plagiatus. Очень популярная программа, лично я ей пользуюсь постоянно. Функционал программы простой, чтобы проверить текст достаточно скопировать его и вставить в окно программы и нажать на старт.

После проверки будет представлен отчет об уникальности проверяемого текста в процентах с ссылками на источники совпадений:
Также, будут выделены желтым фоном конкретные фрагменты текста, по которым программы нашла совпадения:
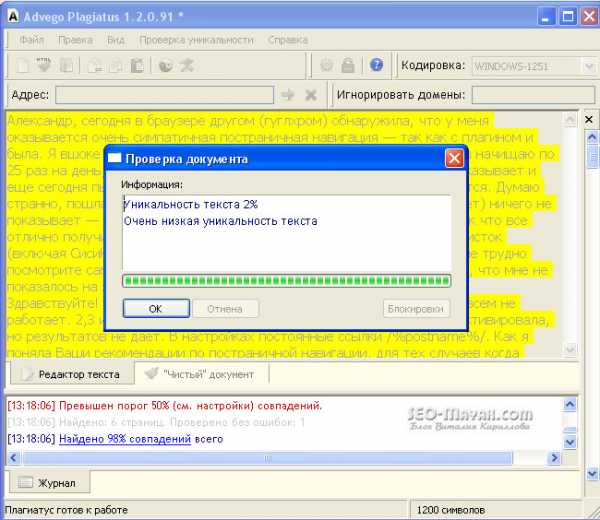
Очень хорошая программа, пользуйтесь и обязательно подпишитесь на обновления блога.
До встречи!
С уважением, Кириллов Виталий
seo-mayak.com
что это такое и как их удалить
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Дубли страниц – это идентичные друг другу страницы, находящиеся на разных URL-адресах. Копии страниц затрудняют индексацию сайтов в поисковых системах.
Что такое дубли страниц на сайте
Дубли могут возникать, когда используются разные системы наполнения контентом. Ничего страшного для пользователя, если дубликаты находятся на одном сайте. Но поисковые системы, обнаружив дублирующиеся страницы, могут наложить фильтр\понизить позиции и т. д. Поэтому дубли нужно быстро удалять и стараться не допускать их появления.
Какие существуют виды дублей
Дубли страниц на сайте бывают как полные, так и неполные.
- Неполные дубли – когда на ресурсе дублируются фрагменты контента. Так, например, и разместив части текста в одной статье из другой, мы получим частичное дублирование. Иногда такие дубли называют неполными.
- Полные дубли – это страницы, у которых есть полные копии. Они ухудшают ранжирование сайта.
Например, многие блоги содержат дублирующиеся страницы. Дубли влияют на ранжирование и сводят ценность контента на нет. Поэтому нужно избавляться от повторяющихся страниц.
Причины возникновения дублей страниц
- Использование Системы управления контентом (CMS) является наиболее распространённой причиной возникновения дублирования страниц. Например, когда одна запись на ресурсе относится сразу к нескольким рубрикам, чьи домены включены в адрес сайта самой записи. В результате получаются дубли страниц: например:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/ - Технические разделы. Здесь наиболее грешат Bitrix и Joomla. Например, одна из функций сайта (поиск, фильтрация, регистрация и т.д.) генерирует параметрические адреса с одинаковой информацией по отношению к ресурсу без параметров в URL. Например:
site.ru/rarticles.php
site.ru/rarticles.php?ajax=Y - Человеческий фактор. Здесь, прежде всего, имеется ввиду, что человек по своей невнимательности может продублировать одну и ту же статью в нескольких разделах сайта.
- Технические ошибки. При неправильной генерации ссылок и настройках в различных системах управления информацией случаются ошибки, которые приводят к дублированию страниц. Например, если в системе Opencart криво установить ссылку, то может произойти зацикливание:
site.ru/tools/tools/tools/…/…/…
Чем опасны дубли страниц
- Заметно усложняется оптимизация сайта в поисковых системах. В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
- Теряются внешние ссылки на сайт. Копии усложняют определение релевантных страниц.
- Появляются дубли в выдаче. Если дублирующий источник будет снабжаться поведенческими метриками и хорошим трафиком, то при обновлении данных она может встать в выдаче поисковой системы на место основного ресурса.
- Теряются позиции в выдаче поисковых систем. Если в основном тексте имеются нечёткие дубли, то из-за низкой уникальности статья может не попасть в SERP. Так, например часть новостей, блога, поста, и т. д. могут быть просто не замечены, так как поисковый алгоритм их принимает за дубли.
- Повышается вероятность попадания основного сайта под фильтр поисковых систем. Поисковики Google и Яндекс ведут борьбу с неуникальной информацией, на сайт могут наложить санкции.
Как найти дубли страниц
Чтобы удалить дубли страниц, их сначала надо найти. Существует три способа нахождения копий на сайте.
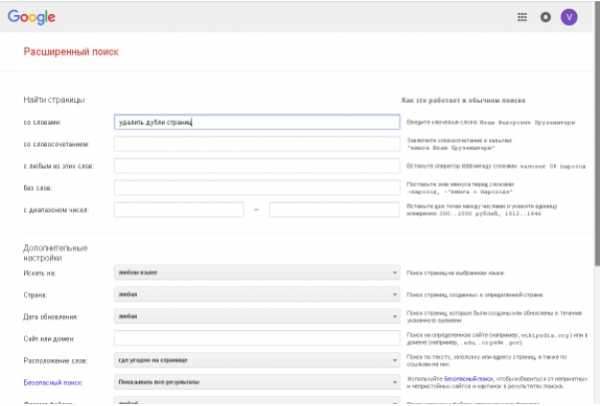
- Нахождение дублей на сайте с помощью расширенного поиска Google. Укажите в расширенном поиске адрес главной страницы. Система выдаст общий список проиндексированных страниц. А если указать адрес конкретной страницы, то поисковик покажет весь перечень проиндексированных дублей. В отличие от Google, в Яндексе копии страниц сразу видны.
Например, такой вид имеет расширенный поиск Google:
На сайте может быть много страниц. Разбейте их на категории — карточки товара, статьи, блога, новости и ускорьте аналитический процесс. - Программа XENU (Xenu Link Sleuth) позволяет провести аудит сайта и найти дубли. Чтобы получить аудит и произвести фильтрацию по заголовку требуется в специальную строку ввести URL сайта. Программа поможет найти полные совпадения. Однако через данную программу невозможно найти неполные дубли.
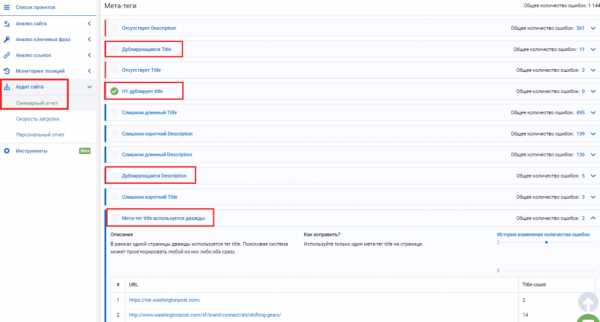
- Обнаружение дублей при помощи web – мастерской Google. Зарегистрируйтесь, и тогда в мастерской, разделе «Оптимизация Html», будет виден список страниц с повторяющимся контентом, тегами <Title>. По таблице можно легко найти чёткие дубли. Недостаток такого метода заключается в невозможности нахождения неполных дублей.
- Онлайн seo-платформа Serpstat проводит технический seo-аудит сайта по 55+ ошибок. Среди них есть блок для анализа дублируемого контента на сайте. Так сервис найдет дублирующиеся Title, Description, h2 на двух и больше страницах. Также видит случаи, когда h2 дублирует Title, на одной странице по ошибке прописаны два мета-тега Title и больше одного заголовка Н1.
Чтобы сделать технический аудит в Serpstat, нужно зарегистрироваться в сервисе и создать проект для аудита сайта.
Как убрать дубли страниц
От дублей нужно избавляться. Необходимо понять причины возникновения и не допускать распространение копий страниц.
- Можно воспользоваться встроенными функциями поисковой системы. В Google используйте атрибут в виде rel=»canonical». В код каждого дубля внедряется тег в виде <link=»canonical» href=»http://site.ru/cat1/page.php»>, который указывает на главную страницу, которую нужно индексировать.
- Запретить индексацию страниц можно в файле robots.txt. Однако таким путём не получится полностью устранить дубли в поисковике. Ведь для каждой отдельной страницы правила индексации не провпишешь, это сработает только для групп страниц.
- Можно воспользоваться 301 редиректом. Так, роботы будут перенаправляться с дубля на оригинальный источник. При этом ответ сервера 301 будет говорить им, что такая страница более не существует.
Дубли влияют на ранжирование. Если вовремя их не убрать, то существует высокая вероятность попадания сайта под фильтры Panda и АГС.
semantica.in
Яндекс удалил из поиска страницы сайта как дубли главной — Яндекс
Помогите, пожалуйста! Яндекс выкинул из поиска почти все страницы, которые были топовыми по запросам. Сайту 1 год, проблем никаких не было. Поисковик расценил эти страницы как дубли на главную страницу сайта. Вот сам сайт Ссылка
Какие это дубли, если тексты, заголовки совершенно разные? Если про ошибки сервера, то на этом же хостинге есть еще один сайт, на таком же движке, настроен аналогичным образом, меню и виджеты созданы аналогичным образом, но его проблема не коснулась.
Установлен плагин All in one seo pack, поставлены галочки на Канонические url и Запретить пагинацию для канонических URL. Могло ли это повлиять на выброс страниц из поиска как дублей?
В роботс также есть настройки запрета дублей, может некоторые из них некорректны и надо что-то исправить?
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-
Disallow: /?
Disallow: /search/
Disallow: *?s=
Disallow: *&s=
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?*
Disallow: /tag
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/*
Disallow: /author
Disallow: /2015
Disallow: */embed
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ #
Disallow: /xmlrpc.php
Allow: */uploads
User-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Allow: /wp-*.jpg
Allow: /wp-admin/admin-ajax.php
Allow: */uploads
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Кстати, от рег ру приходило такое сообщение:
Технические работы
Здравствуйте! Вас приветствует Регистратор доменныx имен REG.RU!
Уважаемые клиенты!
Информируем вас о том, что 03.10.2018 года в период с 00:00 до 06:00 часов по московскому времени будут проводиться плановые работы по обновлению программного обеспечения серверов:
ххх.hosting.reg.ru
на которых располагаются следующие услуги:
- Web-хостинг (тариф ххх) для ххх
Планируемое время проведения технических работ в указанный период составит порядка 1 часов и 0 минут. В течение этого времени все сайты и сервисы на данном сервере будут недоступны.
Приносим свои извинения за возможные неудобства.
И привожу теперь скопированное из вебмастера (может, это технические работы на сервере повлияли? но другой сайт без проблем индексируется):
talk.pr-cy.ru
5 способов избавится от дубликатов страниц на вашем сайте
В данном обзоре рассмотрим как найти и навсегда удалить дубли страниц.
Как возникают дубликаты страниц
Какие бывают дубли страниц
Какую опасность несут в себе дубли страниц
Как обнаружить дубликаты на сайте
5 способов удалить дубликаты страниц
Как возникают дубликаты страниц
Основные причины появления дублей — несовершенство CMS сайта, практически все современные коммерческие и некоммерческие CMS генерируют дубли страниц. Другой причиной может быть низкий профессиональный уровень разработчика сайтов, который допустил появление дублей.
Какие бывают дубли страниц
1. Главная страница сайта, которая открывается с www и без www
пример www.site.ua и site.ua
site.ua/home.html и site.ua/
2. Динамическое содержание сайта с идентификаторами ?, index.php, &view
site.ua/index.php?option=com_k2&Itemid=141&id=10&lang=ru&task=category&view=itemlist
site.ua/index.php?option=com_k2&Itemid=141&id=10&lang=ru&layout=category&task=category&view=itemlist
3. Со слешем в конце URL и без
site.ua/cadok/
site.ua/cadok
4. Фильтры в интернет-магазине (пример VirtueMart)
site.ua//?Itemid=&product_book&
5. Странички печати
site.ua/cadok/?tmpl=component&print=1&layout=default&page=»
Какую опасность несут в себе дубли страниц
Представьте себе что вы читаете книгу где на страничках одинаковый текст, или очень похожий. Насколько полезна для вас такая информация? В таком же положении оказываются и поисковые машины, ища среди дубликатов вашего сайта то полезное содержимое которое необходимо пользователю.
Поисковые машины не любят такие сайты, следовательно ваш сайт не займет высокие позиции в поиске, и это несет для него прямую угрозу.
Как обнаружить дубликаты на сайте
1. С помощью команды site:site.ua можете проверить какие именно дубли попали в индекс поисковой машины.
2. Введите отрывки фраз с вашего сайте в поиск, таким образом обнаружите страницы на которых она присутствует
3. Инструменты для веб-мастеров Google, в разделе Вид в поиске → Оптимизация HTML, можете увидеть страницы, на которых есть повторяющееся метаописание или заголовки.
5 способов удалить дубликаты страниц
1. С помощью файла robots.txt
Пример
Disallow: /*?
Disallow: /index.php?*
Таким образом, дадим знать поисковой машине, что странички, которые содержат параметры ?, index.php?, не должны индексироваться.
Есть одно «но»: файл robots — это только рекомендация для поисковых машин, а не правило, которому они абсолютно следуют. Если, например, на такую страничку поставлена ссылка то она попадет в индекс.
2. Файл .htaccess, позволяет решить проблему с дублями на уровне сервера.
.htaccess — это файл конфигурации сервера Apache, находится в корне сайта. Позволяет настраивать конфигурацию сервера для отдельно взятого сайта.
Склеить странички сайта 301 редиректом.
Пример
Redirect 301 /home.html http://site.ua/ (для статических страниц cайта)
RewriteCond %{QUERY_STRING} ^id=45454
RewriteRule ^index.php$ http://site.ua/news.html? [L,R=301] (редирект для динамических страничек)
Использовать 410 редирект (полное удаление дубля)
Он сообщает что такой странички нет на сервере.
Пример
Redirect 410 /tag/video.html
Настроить домен с www и без www
Пример с www
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^site\.ua
RewriteRule ^(.*)$ http://www.site.ua/$1 [R=permanent,L]
Без www
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.site.ua$ [NC]
RewriteRule ^(.*)$ http://site.ua/$1 [R=301,L]
Добавляем слеш в конце URL
RewriteCond %{REQUEST_URI} (.*/[^/.]+)($|\?) RewriteRule .* %1/ [R=301,L]
Для сайтов с большим количеством страниц будет довольно трудозатратно искать и склеивать дубли.
3. Инструменты для веб-мастеров
Функция Параметры URL позволяют запретить Google сканировать странички сайта с определенными параметрами
Или вручную удалить
Удаление страничек возможно только в случае если страничка:
— запрещена для индексации в файле robots.txt
— возвращает ответ сервера 404
— запрещена тегом noindex
4. Мета тег noindex — это самый действенный способ удаления дубликатов. Удаляет навсегда и бесповоротно.
По заявлению Google наличие тега noindex полностью исключает страничку из индекса.
Пример
<meta name=»robots» content=»noindex»>
Важно. Для того что бы робот смог удалить страничку, он должен ее проиндексировать, то есть она не должна быть закрыта от индексации в файле robots.txt.
Реализовать можно через регулярные выражения PHP, используя функцию preg_match().
5. Атрибут rel=»canonical»
Атрибут rel=»canonical» дает возможность указать рекомендуемую (каноническую) страничку для индексации поисковыми машинами, таким образом дубликаты не попадают в индекс.
rel=»canonical» указывается двома способами
1. С помощью атрибута link в в HTTP-заголовке
Пример
Link: <http://site.ua/do/white>; rel=»canonical»
2. В раздел <head> добавить rel=»canonical» для неканонических версий страниц
Пример
<link rel=»canonical» href=»http://site.ua/product.php?book»/>
В некоторые популярные CMS атрибут rel=»canonical» внедрен автоматически — например, Joomla! 3.0 (почитайте об отличии версии Joomla! 2.5 и Joomla! 3.0). У других CMS есть специальные дополнения.
Подведем итог. При разработке сайта учитывайте возможности появления дублей и заранее определяйте способы борьбы с ними. Создавайте правильную структуру сайта (подробнее здесь).
Проверяйте периодически количество страниц в индексе, и используйте возможности панели Инструментов для веб-мастеров.
При написании использовались материалы
https://support.google.com/webmasters/topic/2371375?hl=ru&ref_topic=1724125
Зберегти
Зберегти
Зберегти
blog.mcsite.ua
Все о том, как найти дубли страниц на сайте… и убрать
Все, что вы хотели найти про дубли страниц на сайте и дублирование контента. Узнайте 7 методов, чтобы проверить, найти и убрать все, что мешает развитию.
Неважно какой движок у вашего сайта: Bitrix, WordPress, Joomla, Opencart… Проверка сайта на дубли страниц может выявить эту проблему и её придется срочно решать.
Дублирование контента, равно как и дубли страниц на сайте, является большой темой в области SEO. Когда мы говорим об этом, то подразумеваем наказание от поисковых систем.
Этот потенциальный побочный эффект от дублирования контента едва ли не самый важный. Даже с учетом того, что Google по сути почти никогда не штрафует сайты за дублирование информации.
Наиболее вероятные проблемы для SEO из-за дублей:
Потраченный краулинговый бюджет.
Если дублирование контента происходит внутри веб-ресурса, гарантируется, что вы потратите часть краулингового бюджета (выделенного лимита на количество индексируемых за один заход страниц) при обходе дублей страниц поисковым роботом. Это означает, что важные страницы будут индексироваться менее часто.
Разбавление ссылочного веса.
Как для внешнего, так и для внутреннего дублирования контента разбавление ссылочного веса является самым большим недостатком для SEO. Со временем оба URL-адреса могут получить обратные ссылки. Если на них отсутствуют канонические ссылки (или 301 редирект), указывающие на исходный документ, вес от ссылок распределится между обоими URL.
Только один вариант получит место в поиске по ключевой фразе.
Когда поисковик найдет дубли страниц на сайте, то обычно он выберет только одну в ответ на конкретный поисковый запрос. И нет никакой гарантии, что это будет именно та, которую вы продвигаете.
Любые подобные сценарии можно избежать, если вы знаете, как найти дубли страниц на сайте и убрать их. В этой статье представлено 7 видов дублирования контента и решение по каждому случаю.
Стоит заметить, что дубли контента могут быть не только у вас на сайте. Ваш текст могут просто украсть. Начнем разбор с этого варианта.
1 Копирование контента
Скопированное содержание в основном является неоригинальной частью контента на сайте, который был скопирован с другого сайта без разрешения. Как я уже говорилось ранее, Google не всегда может точно определить, какая часть является оригинальной. Так что задачей владельца сайта является поиск фактов копирования контента и принятие мер, если обнаружится факт кражи контента.
Увы, это не всегда легко и просто. Но иногда может помочь маленькая хитрость.
Отслеживайте сохранение уникальности ваших документов (если у вас есть блог, желательно это контролировать) с помощью каких-либо сервисов (например, text.ru) или программ. Скопируйте текст своей статьи и запустите проверку уникальности.
Конечно, если сайт содержит сотни статей, то проверка займет много времени. Поэтому я установил на данный сайт комментарии «Hypercomments» и включил функцию фиксации цитирования. Каждый раз, как кто-то скопирует кусок текста, он появляется во вкладке цитаты. Мне сразу видно, что был скопирован весь текст такой-то статьи. Это повод проверить её уникальность через некоторое время.
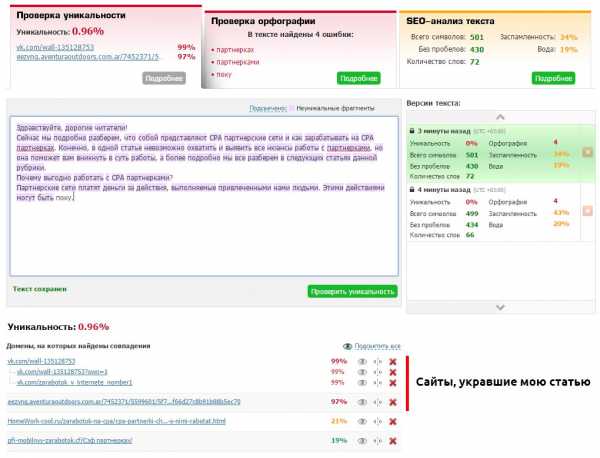
Таким образом вы найдет все сайты, которые содержат текст полностью или частично взятый с вашего сайта. В таком случае необходимо первым делом обратиться к веб-мастеру с просьбой удалить позаимствованный контент (или поставить каноническую ссылку, если это для вашего бизнеса работает и его сайт не слишком плохой в плане SEO). Если консенсус не будет достигнут, вы можете сообщить о копии в Google: отчет о нарушении авторских прав.
2 Синдикация контента
Синдикация – это переиздание содержания на другом сайте с разрешения автора оригинального произведения. И хотя она является законным способом получения вашего контента для привлечения новой аудитории, важно установить рекомендации для издателей, чтобы синдикация не превратилась в проблемы для SEO.
В идеале, издатель должен использовать канонический тег на статью, чтобы указать, что ваш сайт является первоисточником. Другой вариант заключается в применении тега noindex к синдицированному контенту.
Вариант 1: <link rel=»canonical» href=»http://site.ru/original-content» />
Вариант 2: <div rel=»noindex»>Синдицированный контент</div>
Всегда проверяйте это вручную каждый раз, когда разрешаете дублирование вашего контента на других сайтах.
3 HTTP и HTTPS протоколы
Одной из наиболее распространенных внутренних причин дублирования страниц на сайте является одновременная работа сайта по протоколам HTTP и HTTPS. Эта проблема возникает, когда перевод сайта на HTTPS реализован с нарушением инструкции, которую можно прочитать по ссылке. Две распространенные причины:
Отдельные страницы сайта на протоколе HTTPS используют относительные URL
Это часто актуально, если использовать защитный протокол только для некоторых страниц (регистрация/авторизация пользователя и корзина покупок), а для всех остальных – стандартный HTTP. Важно иметь в виду, что защищенные страницы могут иметь внутренние ссылки с относительными URL-адресами, а не абсолютными:
Абсолютный: https://www.homework-cool.ru/category/product/
Относительный: /product/
Относительные URL не содержат информацию о протоколе. Вместо этого они используют тот же самый протокол, что и родительская страница, на которой они расположены. Если поисковый бот найдет такую внутреннюю ссылку и решит следовать по ней, то перейдет по ссылке с HTTPS. Затем он может продолжить сканирование, пройдя по нескольким относительным внутренним ссылкам, а может даже просканировать весь сайт с защитным протоколом. Таким образом в индекс попадут две совершенно одинаковые версии ресурса.
В этом случае необходимо использовать абсолютные URL-адреса вместо относительных для внутренних ссылок. Если боту уже удалось найти дубли страниц на сайте, и они отобразились в панели вебмастера в Яндексе или Google, то установите 301 редирект, перенаправляя защищенные страницы на правильную версию с HTTP. Это будет лучшим решением.
Вы полностью перевели сайт на HTTPS, но HTTP версия все еще доступна
Это может произойти, если есть обратные ссылки с других сайтов, указывающие на HTTP версию, или некоторые из внутренних ссылок на вашем ресурсе по-прежнему содержат старый протокол.
Чтобы избежать разбавления ссылочного веса и траты краулингового бюджета используйте 301 редирект с HTTP и убедитесь, что все внутренние ссылки указаны с помощью относительных URL-адресов.
Чтобы быстро проверить дубли страниц на сайте из-за HTTP/HTTPS протокола, нужно проконтролировать работу настроенных редиректов.
4 Страницы с WWW и без WWW
Одна из самых старых причин для появления дублей страниц на сайте, когда доступны версии с WWW и без WWW. Как и HTTPS, эта проблема обычно решается за счет включения 301 редиректа. Также необходимо указать ваш предпочтительный домен в панели вебмастера Google.
Чтобы проверить дубли страниц на сайте из-за префикса WWW, так же редирект должен корректно работать.
5 Динамически генерируемые параметры URL
Динамически генерируемые параметры часто используются для хранения определенной информации о пользователях (например, идентификаторы сеансов) или для отображения несколько иной версии той же страницы (например, сортировка или корректировка фильтра продукции, поиск информации на сайте, оставление комментариев). Это приводит к тому, что URL-адреса выглядят следующим образом:
URL 1: https:///homework-cool.ru/position.html?newuser=true
URL 2: https:///homework-cool.ru/position.html?older=desc
Несмотря на то, что эти страницы будут содержать дубли контента (или очень похожую информацию), для поисковых роботов это повод их проиндексировать. Часто динамические параметры создают не две, а десятки различных версий страниц, которые могут привести к значительному количеству напрасно проиндексированных документов.
Найти дубли страниц на сайте можно с помощью панели вебмастера Google в разделе «Вид в поиске — Оптимизация HTML»

Яндекс Вебмастер покажет их в «Индексирование – Страницы в поиске»
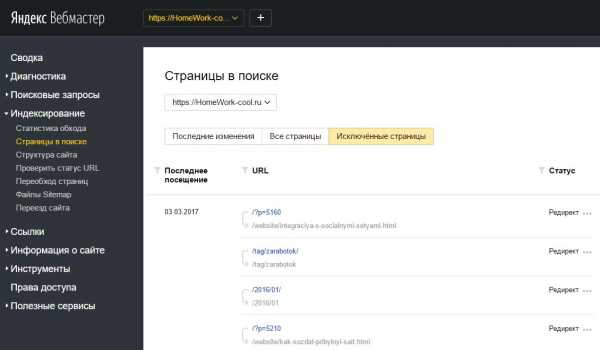
Для конкретного случая в индексе Google находятся четыре страницы пагинации с одинаковым метаописанием. А скриншот из Яндекса наглядно показывает, что на все «лишние» атрибуты в ссылках настроен редирект, включая теги.
Еще можно прямо в поисковике ввести в строку:
site:domen.ru -site:domen.ru/&
Таким образом можно найти частичные дубли страниц на сайте и малоинформативные документы, находящиеся в индексе Google.
Если вы найдете такие страницы на вашем сайте, убедитесь, что вы правильно классифицируете параметры URL в панели вебмастера Google. Таким образом вы расскажите Google, какие из параметров должны быть проигнорированы во время обхода.
6 Подобное содержание
Когда люди говорят про дублирование контента, они подразумевают совершенно идентичное содержание. Тем не менее, кусочки аналогичного содержания так же попадают под определение дублирования контента на сайте от Google:
«Если у вас есть много похожих документов, рассмотрите вопрос о расширении каждого из них или консолидации в одну страницу. Например, если у вас есть туристический сайт с отдельными страницами для двух городов, но информация на них одинакова, вы можете либо соединить страницы в одну о двух городах или добавить уникальное содержание о каждом городе»
Такие проблемы могут часто возникать с сайтами электронной коммерции. Описания для аналогичных продуктов могут отличаться только несколькими специфичными параметрами. Чтобы справиться с этим, попробуйте сделать ваши страницы продуктов разнообразными во всех областях. Помимо описания отзывы о продукте являются отличным способом для достижения этой цели.
На блогах аналогичные вопросы могут возникнуть, когда вы берете старую часть контента, добавите некоторые обновления и опубликуете это в новый пост. В этом случае использование канонической ссылки (или 301 редиректа) на оригинальный пост является лучшим решением.
7 Страницы версий для печати
Если страницы вашего сайта имеют версии для печати, доступные через отдельные URL-адреса, то Google легко найдет их и проиндексирует через внутренние ссылки. Очевидно, что содержание оригинальной статьи и её версии для печати будет идентичным – таким образом опять тратится лимит индексируемых за один заход страниц.
Если вы действительно предлагаете печатать чистые и специально отформатированные документы вашим посетителям, то лучше закрыть их от поисковых роботов с помощью тега noindex. Если все они хранятся в одном каталоге, таком как https://homework-cool.ru/news/print/, вы можете даже добавить правило Disallow для всего каталога в файле robots.txt.
Disallow: /news/print
Подведем итоги
Дублирование контента и скрытые дубли страниц на сайте могут обернуться головной болью для оптимизаторов, так как это приводит к потере ссылочного веса, трате краулингового бюджета, медленной индексации новых страниц.
Помните, что вашими лучшими инструментами для борьбы с этой проблемой являются канонические ссылки, 301 редирект и robots.txt. Не забывайте периодически проверять и обновлять контент вашего сайта с целью улучшения индексации и ранжирования в поисковых системах.
Какие случаи дублей страниц вы находили на своем сайте, какие методы используете, чтобы предотвратить их появление? Я с нетерпением жду ваших мыслей и вопросов в комментариях.
homework-cool.ru