
что это такое и как их удалить
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Дубли страниц – это идентичные друг другу страницы, находящиеся на разных URL-адресах. Копии страниц затрудняют индексацию сайтов в поисковых системах.
Что такое дубли страниц на сайте
Дубли могут возникать, когда используются разные системы наполнения контентом. Ничего страшного для пользователя, если дубликаты находятся на одном сайте. Но поисковые системы, обнаружив дублирующиеся страницы, могут наложить фильтр\понизить позиции и т.
Какие существуют виды дублей
Дубли страниц на сайте бывают как полные, так и неполные.
- Неполные дубли – когда на ресурсе дублируются фрагменты контента. Так, например, и разместив части текста в одной статье из другой, мы получим частичное дублирование. Иногда такие дубли называют неполными.
- Полные дубли – это страницы, у которых есть полные копии. Они ухудшают ранжирование сайта.
Например, многие блоги содержат дублирующиеся страницы. Дубли влияют на ранжирование и сводят ценность контента на нет. Поэтому нужно избавляться от повторяющихся страниц.
Причины возникновения дублей страниц
- Использование Системы управления контентом (CMS) является наиболее распространённой причиной возникновения дублирования страниц. Например, когда одна запись на ресурсе относится сразу к нескольким рубрикам, чьи домены включены в адрес сайта самой записи.
 В результате получаются дубли страниц: например:
В результате получаются дубли страниц: например:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/ - Технические разделы. Здесь наиболее грешат Bitrix и Joomla. Например, одна из функций сайта (поиск, фильтрация, регистрация и т.д.) генерирует параметрические адреса с одинаковой информацией по отношению к ресурсу без параметров в URL. Например:
site.ru/rarticles.php?ajax=Y - Человеческий фактор. Здесь, прежде всего, имеется ввиду, что человек по своей невнимательности может продублировать одну и ту же статью в нескольких разделах сайта.
- Технические ошибки. При неправильной генерации ссылок и настройках в различных системах управления информацией случаются ошибки, которые приводят к дублированию страниц. Например, если в системе Opencart криво установить ссылку, то может произойти зацикливание:
Чем опасны дубли страниц
- Заметно усложняется оптимизация сайта в поисковых системах. В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
- Теряются внешние ссылки на сайт. Копии усложняют определение релевантных страниц.
- Появляются дубли в выдаче. Если дублирующий источник будет снабжаться поведенческими метриками и хорошим трафиком, то при обновлении данных она может встать в выдаче поисковой системы на место основного ресурса.
- Теряются позиции в выдаче поисковых систем. Если в основном тексте имеются нечёткие дубли, то из-за низкой уникальности статья может не попасть в SERP. Так, например часть новостей, блога, поста, и т. д. могут быть просто не замечены, так как поисковый алгоритм их принимает за дубли.
- Повышается вероятность попадания основного сайта под фильтр поисковых систем. Поисковики Google и Яндекс ведут борьбу с неуникальной информацией, на сайт могут наложить санкции.
 В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.Как найти дубли страниц
Чтобы удалить дубли страниц, их сначала надо найти. Существует три способа нахождения копий на сайте.
- Нахождение дублей на сайте с помощью расширенного поиска Google. Укажите в расширенном поиске адрес главной страницы. Система выдаст общий список проиндексированных страниц. А если указать адрес конкретной страницы, то поисковик покажет весь перечень проиндексированных дублей. В отличие от Google, в Яндексе копии страниц сразу видны.
Например, такой вид имеет расширенный поиск Google:
На сайте может быть много страниц. Разбейте их на категории — карточки товара, статьи, блога, новости и ускорьте аналитический процесс. - Программа XENU (Xenu Link Sleuth) позволяет провести аудит сайта и найти дубли. Чтобы получить аудит и произвести фильтрацию по заголовку требуется в специальную строку ввести URL сайта. Программа поможет найти полные совпадения. Однако через данную программу невозможно найти неполные дубли.
- Обнаружение дублей при помощи web – мастерской Google. Зарегистрируйтесь, и тогда в мастерской, разделе «Оптимизация Html», будет виден список страниц с повторяющимся контентом, тегами <Title>. По таблице можно легко найти чёткие дубли. Недостаток такого метода заключается в невозможности нахождения неполных дублей.
- Онлайн seo-платформа Serpstat проводит технический seo-аудит сайта по 55+ ошибок. Среди них есть блок для анализа дублируемого контента на сайте. Так сервис найдет дублирующиеся Title, Description, h2 на двух и больше страницах. Также видит случаи, когда h2 дублирует Title, на одной странице по ошибке прописаны два мета-тега Title и больше одного заголовка Н1.
Чтобы сделать технический аудит в Serpstat, нужно зарегистрироваться в сервисе и создать проект для аудита сайта.
 По таблице можно легко найти чёткие дубли. Недостаток такого метода заключается в невозможности нахождения неполных дублей.
По таблице можно легко найти чёткие дубли. Недостаток такого метода заключается в невозможности нахождения неполных дублей.Как убрать дубли страниц
От дублей нужно избавляться. Необходимо понять причины возникновения и не допускать распространение копий страниц.
- Можно воспользоваться встроенными функциями поисковой системы. В Google используйте атрибут в виде rel=»canonical». В код каждого дубля внедряется тег в виде <link=»canonical» href=»http://site.ru/cat1/page.
- Запретить индексацию страниц можно в файле robots.txt. Однако таким путём не получится полностью устранить дубли в поисковике. Ведь для каждой отдельной страницы правила индексации не провпишешь, это сработает только для групп страниц.
- Можно воспользоваться 301 редиректом. Так, роботы будут перенаправляться с дубля на оригинальный источник. При этом ответ сервера 301 будет говорить им, что такая страница более не существует.

Дубли влияют на ранжирование. Если вовремя их не убрать, то существует высокая вероятность попадания сайта под фильтры Panda и АГС.
Как избавиться от дублей страниц в Bitrix
Наличие дублирующих страниц – частая проблема, с которой приходится сталкиваться оптимизаторам. Наличие таких страниц на сайте ведёт к «замусориванию» индекса, трате краулингового бюджета на ненужные страницы, появлению на выдаче дублей вместо продвигаемых страниц. Всё это в конечном итоге ведёт к ухудшению ранжирования сайта.
Всё это в конечном итоге ведёт к ухудшению ранжирования сайта.
Среди разных CMS в моём личном рейтинге 1С-Битрикс не занимает первого места по количеству типичных проблем с дублями. Например, от Joomla можно ожидать куда большего числа проблем с разными типами дублей. Но и 1С-Битрикс не лишена своих особенностей. Наиболее часто сложности возникают с фильтром, товарами и страницами пагинации.
Но сперва расскажу про те случаи возникновения дублей, которые характерны для всех типов сайтов и CMS.
Чтобы проверить их наличие, следует проверить доступность главной страницы по следующим адресам:
https://www.oridis.ru/index.php
https://www.oridis.ru/home.php
https://www.oridis.ru/index.html
https://www.oridis.ru/home.html
https://www.oridis.ru/index.htm
https://www.oridis.ru/home.htm
(наиболее распространённые варианты)
Корректным ответом сервера при открытии подобных страниц будет 404 или 301.
Если же страница возвращает 200 ОК, это говорит нам о наличии дубля.
Быстро и удобно проверить главную страницу на наличие дублей можно при помощи данного сервиса:
https://apollon.guru/duplicates/
Перед началом продвижения обязательно следует определиться с тем, какой адрес сайта считать главным зеркалом – с www или без него.
Оба варианта имеют свои плюсы и минусы. Вариант без www короче. При длинном доменном имени добавление ещё четырёх символов не всегда выглядит красиво. А к плюсам варианта с www можно отнести, что при написании адреса сайта с www в некоторых редакторах адрес автоматически становится гиперссылкой.
Форма отправки письма Outlook
На нашем сайте основным зеркалом выбрана версия www.oridis.ru
Теперь для проверки корректности настройки следует проверить, что страницы без префикса www перенаправляют на страницы с www в адресе.
Пример:
https://oridis.ru/seo/
В данном случае страница перенаправляет на www-версию. Проблем нет.
Код ответа страницы можно проверить при помощи инспектора браузера либо при помощи онлайн-сервиса, например:
https://bertal. ru/index.php?a7054246/https://oridis.ru/seo/#h
ru/index.php?a7054246/https://oridis.ru/seo/#h
О том, как правильно настроить редирект, можно узнать в материале https://www.oridis.ru/articles/301-redirect.html
Прекрасный способ отыскать дубли и другие «мусорные» страницы – это посмотреть проиндексированные страницы в поисковых системах:
https://yandex.ru/search/?text=host%3Awww.oridis.ru&lr=213&clid=2186620
Часто там можно обнаружить совершенно удивительные страницы, о которых даже сложно было предположить.
В индекс попадают и страницы с метками (например, UTM). Чтобы исключить такие страницы можно использовать директиву Clean-param:
https://yandex.ru/support/webmaster/robot-workings/clean-param.html
Именно таким способом пользуется OZON.RU:
https://www.ozon.ru/robots.txt
Другой альтернативный метод борьбы с дублями GET-параметров – это закрывать их в robots.txt через директиву Disallow. Google не воспринимает директиву Clean-param, зато директиву Disallow прекрасно понимает как Google, так и Яндекс.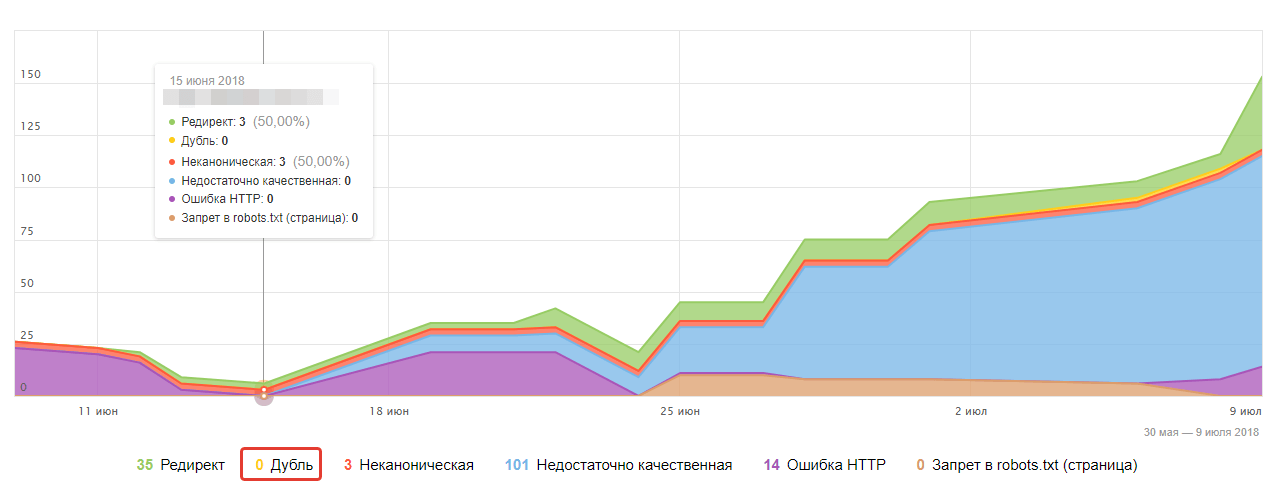
Крупный интернет-магазин Эльдорадо (работающий, кстати, на Битрикс), использует Disallow для закрытия ненужных GET-параметров:
https://www.eldorado.ru/robots.txt
Если вы хотите закрыть от индексации все страницы с GET-параметрами, то достаточно прописать строчку:
Disallow: /*?
Далее перейдём к более специфичным особенностям 1С-Битрикс.
В Битрикс подобные страницы, как правильно имеют вид:
https://site.ru/catalog/inventar/?PAGEN_1=7
Что же с ними делать? Как избавиться от подобных страниц в индексе? И нужно ли это делать в принципе?
Читаем рекомендации поисковых систем.
Яндекс:
Если в какой-либо категории на вашем сайте находится большое количество товаров, могут появиться страницы пагинации (порядковой нумерации страниц), на которых собраны все товары данной категории. Если на такие страницы нет трафика из поисковых систем и их контент во многом идентичен, то советую настраивать атрибут rel=»canonical» тега <link> на подобных страницах и делать страницы второй, третьей и дальнейшей нумерации неканоническими, а в качестве канонического (главного) адреса указывать первую страницу каталога, только она будет участвовать в результатах поиска.
https://yandex.ru/blog/platon/2878
Т.е. Яндекс рекомендует ставить нам canonical на пагинаторные страницы, ведущие на основную категорию.
Сами рекомендации датированы 2015-м годом. Обращался в техподдержку Яндекса, чтобы узнать не потеряли ли актуальность данные рекомендации. Техподдержка актуальность рекомендаций подтвердила.
Google ранее советовал настраивать link rel next/prev для пагинаторных страниц. Но на данный момент от данной рекомендации он отказался:
Spring cleaning!
— Google Search Central (@googlesearchc) March 21, 2019
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what's best for *your* users! #springiscoming pic.twitter.com/hCODPoKgKp
Google также сообщает, что использование canonical на пагинаторных страницах со ссылкой на основную категорию (первую страницу) является ошибкой:
https://webmasters.googleblog.com/2013/04/5-common-mistakes-with-relcanonical.html
Таким образом получается, что рекомендации Яндекс и Google противоречат друг другу.
Что делать в этой ситуации – каждый должен решить для себя.
Например, я обычно проставляю canonical на основную категорию, следуя рекомендациям Яндекса. Причина такого решения заключается в том, что продвижение мы в основном ведём под Рунет, где доля Яндекса пока ещё больше Google. Если же вы продвигаетесь в иностранном сегменте интернета, где царствует Google, старайтесь ориентироваться на актуальные рекомендации этой поисковой системы.
Причина такого решения заключается в том, что продвижение мы в основном ведём под Рунет, где доля Яндекса пока ещё больше Google. Если же вы продвигаетесь в иностранном сегменте интернета, где царствует Google, старайтесь ориентироваться на актуальные рекомендации этой поисковой системы.
При работе с интернет-магазином на 1С-Битрикс можно часто столкнуться со страницами с /filter/clear/apply/ в адресе.
Один из вариантов решения – прописать каноникал на основную категорию.
Т.е. страница:
https://site.ru/catalog/aksessuary/podsumki-i-patrontashi/filter/clear/apply/
должна содержать canonical, ведущий на:
https://site.ru/catalog/aksessuary/podsumki-i-patrontashi/
Решение можно считать правильным (по крайней мере, с точки зрения Яндекса). Однако такой подход требует определённых трудозатрат программиста на написание нужного функционала.
К тому же каноникал не является панацеей и строгой рекомендацией для поисковых систем (в отличии, например, от файла robots. txt). Канонические страницы вполне могут попадать в индекс, если поисковая система сочтёт это нужным:
txt). Канонические страницы вполне могут попадать в индекс, если поисковая система сочтёт это нужным:
https://webmaster.yandex.ru/blog/nekanonicheskie-stranitsy-v-poiske
Наименее трудозатратный и наиболее простой способ быстро решить данную проблему – это прописать соответствующие директивы в файле robots.txt.
Например, можно полностью закрыть все страницы с «filter»:
Disallow: /*filter
Часто встречаю подобный вариант написания директив:
Disallow: /*filter*
Однако, нет никакой необходимости ставить звёздочку на конце строчки. Дело в том, что по умолчанию в конце записи, если не указан спецсимвол «$», всегда подразумевается звёздочка.
Из коробки 1C-Битрикс не содержит файла robots.txt. Чтобы его создать необходимо перейти в административную панель и выбрать:
Маркетинг > Поисковая оптимизация > Настройка robots.txt
Далее можно выбрать «Стартовый набор» и нажать кнопку «Сохранить».
В результате создастся файл robots. txt. Его содержимое может иметь следующий вид:
txt. Его содержимое может иметь следующий вид:
User-Agent: *
Disallow: */index.php
Disallow: /bitrix/
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*bitrix_include_areas=
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*PAGEN
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*print_course=
Disallow: /*?action=
Disallow: /*&action=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: /*?bxajaxid=
Disallow: /*&bxajaxid=
Disallow: /*?view_result=
Disallow: /*&view_result=
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/panel/
Host: www. 1097lab.bitrixlabs.ru
1097lab.bitrixlabs.ru
Закрыты от индексации основные технические разделы и страницы. Отрыты – пути к CSS и JS-файлам. Если этого не сделать, поисковые системы могут воспринимать сайт некорректно. Например, сервис Google Mobile-Friendly Tools не сможет увидеть корректный дизайн и сайт может не пройти проверку на мобильность.
Также стоит отметить, что строчка Host лишняя и её можно смело удалять (особенно, если у вас настроены редиректы). Яндекс отменил данную директиву, но Битрикс продолжает по-прежнему генерировать файл robots.txt вместе с ней.
Распространённая трудность не только с сайтами на Битрикс, но и с любыми другими интернет-магазинами.
Поэтому расскажу, как решить этот вопрос в общем случае. Существует как минимум два подхода для устранения таких дублей.
Сперва приведу примеры. Итак, у нас есть один и тот же товар, который относится к нескольким категориям:
http://site.ru/catalog/phones/honor-10/
http://site.ru/catalog/electronics/honor-10/
Решение №1
Отказаться от вложенных адресов и формировать адреса товаров независимо от категории:
http://site.![]() ru/detail/honor-10/
ru/detail/honor-10/
http://site.ru/detail/xiaomi-mi-9/
Решение №2
Пользоваться canonical. Для этого один из адресов товара выбираем каноническим и проставляем link rel=»canonical» на страницах с повторяющимися предложениями.
Здесь на помощь приходят различные программы-краулеры. Мой личный фаворит — Netpeak Spider. Другой способ, о котором я уже писал выше – изучение индекса поисковых системах.
И конечно же вы всегда можете обратиться к нам. Поможем устранить дубли, исправить технические ошибки и сделаем ваш сайт удобным и привлекательным для пользователей.
Ямщиков Сергей, интернет-маркетолог
Здравствуйте уважаемые читатели блога sivway.com. Анализируя сайты клиентов, все время наблюдаю одну и ту же ошибку — дубль главной страницы в joomla. Ошибка достаточно распространенная и легко исправима, но из-за нее мне приходится тратить больше времени и сил. Поэтому в этой статье я опишу, какого вида бывают дубли страниц и как с ними бороться. Поэтому в этой статье я опишу, какого вида бывают дубли страниц и как с ними бороться. | |
| Виды дублей главной страницы и методы борьбы с ними. | |
Самый распространенный дубль – название сайта с www и без. До сих пор многие люди вводят название сайта с www, но некоторые «умные» вебмастера настраивают свой домен так, что попасть на сайт без www невозможно. Поэтому целесообразно давать доступ к такому домену. Но возникает следующая проблема, поисковики считают сайт с www и без как два разных сайта. Правда, через какое-то время они делают склейку домена (зеркало), но на это необходимо время, которое в наши дни очень ценно. Поэтому при создании сайта на любой CMS и не только необходимо сразу избавится от этого дубля. (.*)$ http://domain.com/$1 [R=301,L] (.*)$ http://domain.com/$1 [R=301,L] | |
| После этого ваш сайт будет доступен при вводе с www и автоматически перенаправится на без. Конечный вид адреса сайта http://site.ua. После этого роботы поисковиков так же будут перенаправляться. И в итоге уберется дубль главной страницы. | |
| Дубль страницы /index.php | |
| Второй по распространению дубль главной страницы в joomla – после названия сайта стоит /index.php или index.html. Это так же дубль главной страницы. Так же исправляется при помощи редактирования .htaccess. | |
| Код для избавления от /index.php | |
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index\. index\.html$ http://ваш сайт.ua/ [R=301,L] index\.html$ http://ваш сайт.ua/ [R=301,L] | |
| Дубль страницы / в конце адреса. | |
| Слеш в конце адреса раньше считался дублем страницы, а сейчас поисковики научились определять сайт с / и склеивают его с главным доменом. Поэтому исправление этой ошибки считается как «хороший тон» при создании сайта. Но в любом случае лучше от него избавиться или наоборот поставить. | |
| Для этого воспользуемся склейкой / в файле .htaccess | |
| Код для склейки / (убирает /) | |
| RewriteBase / | |
RewriteCond %{HTTP_HOST} (. /])$ $1/ [L,R=301] /])$ $1/ [L,R=301] | |
| И последний дубль, который я встречал в joomla – это алиас главной страницы. Объясню подробнее. К примеру, вы заходите на сайт site.ua, перед вами открывается главная страница, почитали, перешли на другую страницу. Вроде все в порядке, но после вам захотелось перейти опять на главную. Нажимаете на «Главную» и смотрите в адресную строку, а там вместо site.ua стоит site.ua/glavnaya или /content или еще что нибудь. Это явный дубль главной страницы. Простым удалением алиаса в меню главной страницы не обойтись. Здесь придется покопаться в базе joomla. Для этого открываем базу joomla через phpMyAdmin ищем таблицу jos_menu нажимаем обзор, ищем меню, которое отвечает за главную и очищаем поле alias. После сохранения базы смотрим на результат. | |
Так же дубли главной страницы могут возникать из-за различных компонентов, плагинов. Эти дубли убираются очень легко – удаляем компонент, а если он действительно так важен, то здесь уже должен быть индивидуальный подход. В любом случае есть тех. поддержка компонента, где можно найти решение. Эти дубли убираются очень легко – удаляем компонент, а если он действительно так важен, то здесь уже должен быть индивидуальный подход. В любом случае есть тех. поддержка компонента, где можно найти решение. | |
| Помимо дублей главной страницы, joomla болеет еще и внутренними дублями, избавляется закрытием дубля в файле robots.txt. | |
| Спасибо: http://sivway.com/joomla/ubiraem-dubli-glavnoj-stranicy-v-joomla.html |
Убираем дубли главной страницы в joomla
Здравствуйте уважаемые читатели блога sivway.com. Анализируя сайты клиентов, все время наблюдаю одну и ту же ошибку — дубль главной страницы в joomla. Ошибка достаточно распространенная и легко исправима, но из-за нее мне приходится тратить больше времени и сил. Поэтому в этой статье я опишу, какого вида бывают дубли страниц и как с ними бороться.
Виды дублей главной страницы и методы борьбы с ними.
Самый распространенный дубль – название сайта с www и без. До сих пор многие люди вводят название сайта с www, но некоторые «умные» вебмастера настраивают свой домен так, что попасть на сайт без www невозможно. Поэтому целесообразно давать доступ к такому домену. Но возникает следующая проблема, поисковики считают сайт с www и без как два разных сайта. Правда, через какое-то время они делают склейку домена (зеркало), но на это необходимо время, которое в наши дни очень ценно. Поэтому при создании сайта на любой CMS и не только необходимо сразу избавится от этого дубля. Для этого воспользуемся 301 редиректом. Подробнее в статье 301 редирект. Заходим по ftp на сайт где установлена joomla ищем файл .htaccess. Внимание файл .htaccess не имеет расширения и в названии должна идти точка. Если у вас htaccess.txt переименуйте его.
В этом файле прописываем код редиректа с www на без. /])$ $1/ [L,R=301]
/])$ $1/ [L,R=301]
И последний дубль, который я встречал в joomla – это алиас главной страницы. Объясню подробнее. К примеру, вы заходите на сайт site.ua, перед вами открывается главная страница, почитали, перешли на другую страницу. Вроде все в порядке, но после вам захотелось перейти опять на главную. Нажимаете на «Главную» и смотрите в адресную строку, а там вместо site.ua стоит site.ua/glavnaya или /content или еще что нибудь. Это явный дубль главной страницы. Простым удалением алиаса в меню главной страницы не обойтись. Здесь придется покопаться в базе joomla. Для этого открываем базу joomla через phpMyAdmin ищем таблицу jos_menu нажимаем обзор, ищем меню, которое отвечает за главную и очищаем поле alias. После сохранения базы смотрим на результат.
Так же дубли главной страницы могут возникать из-за различных компонентов, плагинов. Эти дубли убираются очень легко – удаляем компонент, а если он действительно так важен, то здесь уже должен быть индивидуальный подход. В любом случае есть тех. поддержка компонента, где можно найти решение.
В любом случае есть тех. поддержка компонента, где можно найти решение.
Помимо дублей главной страницы, joomla болеет еще и внутренними дублями, избавляется закрытием дубля в файле robots.txt.
Спасибо: http://sivway.com/joomla/ubiraem-dubli-glavnoj-stranicy-v-joomla.html
Статьи по теме
Всем привет! Всех с наступившим [20]{2,}0 годом. Сегодня я хочу затронуть тему, которая иногда является темой для шуток от «Да зачем тебе все …
2021-01-22
Сколько бы ни было товаров в вашем интернет-магазине, вам нужно описывать каждый из них: заполнять характеристики и распределять товары …
2020-03-23
Все, кто пользуется Denwer (ДНВР), проще говоря джентльменским набором веб-разработчика, знают, что обновления пакета происходят не так уж и …
2018-10-07
Один из моих клиентов обратился ко мне с такой просьбой.
У них есть сайт и на нем в некоторых местах, причем не со всех устройств появляет…2018-05-02
Достаточно распространённым является мнение, что редизайн интернет-ресурса может крайне негативно сказаться на его производительност…
2018-04-03
В последнее время попадаются сайты с одной и той же уязвимостью в AdsManager, в этой статье я расскажу, как найти и закрыть уязвимость на сайт…
2018-03-21
Как писать? Стройте текст по определенной логической схеме. Интуитивно составленный текст, в котором Вы выкладываете посетителю все и с…
2017-05-24
Ребята из проекта Canva знают о сайтах с бесплатными иконками буквально все — составили список из 50 наиболее популярных и интересных. Те…
2017-05-07
Доброго времени суток уважаемые мои читатели! Сегодня мы расследуем причину появления ошибки [an error occurred while processing the directive] на одном из мо.
..2017-03-13
Чтобы поисковые роботы при попытки индексации не получали «403» ошибку и не убирались восвояси, предлагаем ознакомиться со списком диап…
2017-03-01
14 декабря стало известно об уязвимости, которая доступна во всех версиях CMS Joomla, начиная от Joomla 1.5 (до 3.4.5 включительно). Уязвимость позвол…
2017-01-16
Одна из основных − практически наиболее важных − задач сайта является обеспечение возможности для клиентов связаться с представител…
2016-11-30
Владельцы сайтов часто сталкиваются с необходимостью обеспечить сохранность веб-страниц. Не секрет, что они склонны к изменениям и с…
2016-10-12
Публикация текстового контента на интернет-сайтах несколько отличается от аналогичных действий с печатью статей в бумажных журнала.
..2016-09-21
Если вы являетесь владельцем интернет-ресурса, который был создан для работы с отечественными пользователями, то наверняка сталкива…
2016-09-13
 У них есть сайт и на нем в некоторых местах, причем не со всех устройств появляет…
У них есть сайт и на нем в некоторых местах, причем не со всех устройств появляет… ..
.. ..
..Дубли страниц в Joomla — Юрий Ключевский
У CMS Joomla есть один недостаток, это дубли адресов страниц. Дубли — это когда одна статья доступна по двум адресам.
Например:
http://rightblog.ru/dizayn/ikonki-sotsial-noy-seti-vkonrtakte.html
index.php?option=com_content&view=article&id=99:vkontakteicons&catid=5:design&Itemid=5
Как появляются дубли страниц? Очень просто, на примере выше мы видим две ссылки на один материал. Первая ссылка — красивая и человекопонятная (ЧПУ ссылка), создана компонентом JoomSEF который преобразует все ссылки на сайте в такой красивый, удобочитаемый вид. Вторая ссылка — внутренная системная ссылка Джумлы, и если бы компонент Artio JoomSef не был установлен, то все ссылки на сайте были бы как вторая — непонятные и некрасивые.![]() Теперь от том насколько это страшно и как бороться с дублями.
Теперь от том насколько это страшно и как бороться с дублями.
Насколько дубли вредны для сайта. Я бы не называл его очень большим недостатком, так как по моему мнению, поисковые машины не должны сильно банить и пессимизировать сайт за такие дубли, так как дубли эти делаются не специально, а являются частью CMS системы. Причем, замечу, очень популярной системы, на которой сделаны миллионы сайтов, а значит поисковики научились понимать такую «особенность». Но все таки, если есть возможность и желание, то лучше такие дубли позакрывать от глаз большого брата.
Подробнее и как убрать из индексации дубли страниц в Joomla читаем под катом.
У CMS Joomla есть один недостаток, это дубли адресов страниц. Дубли — это когда одна статья доступна по двум адресам. Например:
http://rightblog.ru/dizayn/ikonki-sotsial-noy-seti-vkonrtakte.html
index.php?option=com_content&view=article&id=99:vkontakteicons&catid=5:design&Itemid=5
Как появляются дубли страниц? Очень просто, на примере выше мы видим две ссылки на один материал. Первая ссылка — красивая и человекопонятная (ЧПУ ссылка), создана компонентом JoomSEF который преобразует все ссылки на сайте в такой красивый, удобочитаемый вид. Вторая ссылка — внутренная системная ссылка Джумлы, и если бы компонент Artio JoomSef не был установлен, то все ссылки на сайте были бы как вторая — непонятные и некрасивые. Теперь от том насколько это страшно и как бороться с дублями.
Первая ссылка — красивая и человекопонятная (ЧПУ ссылка), создана компонентом JoomSEF который преобразует все ссылки на сайте в такой красивый, удобочитаемый вид. Вторая ссылка — внутренная системная ссылка Джумлы, и если бы компонент Artio JoomSef не был установлен, то все ссылки на сайте были бы как вторая — непонятные и некрасивые. Теперь от том насколько это страшно и как бороться с дублями.
Насколько дубли вредны для сайта. Я бы не называл его очень большим недостатком, так как по моему мнению, поисковые машины не должны сильно банить и пессимизировать сайт за такие дубли, так как дубли эти делаются не специально, а являются частью CMS системы. Причем, замечу, очень популярной системы, на которой сделаны миллионы сайтов, а значит поисковики научились понимать такую «особенность». Но все таки, если есть возможность и желание, то лучше такие дубли позакрывать от глаз большого брата.
Как бороться с дублями в Joomla и других cms1) Два дубля одной страницы, запрет в robots. txt
txt
К примеру, в индекс поисковика попадают следующие два адреса одной страницы:
http://site.ru/страница.html?replytocom=371
http://site.ru/страница.html?iframe=true&width=900&height=450
Для закрытия таких дублей в robots.txt нужно добавить:
Disallow: /*?*
Disallow: /*?
Этим действием мы закрыли от индексации все ссылки сайта со знаком «?». Такой вариант подходит для сайтов где включена работа ЧПУ, и нормальные ссылки не имеют в себе знаков вопроса — «?».
2. Использовать тег rel=”canonical”
Допустим на одну страницу идет две ссылки с разными адресами. Поисковикам Google и Yahoo моджно указать на то какой адрес на страницу является главным. Для этого в теге <a> надо прописать тег rel=”canonical”. Яндекс эту опцию не поддерживает.
Для Joomla для постановки тега rel=”canonical” я нашел два расширения, под названием 1)plg_canonical_v1.2; и 2) 098_mod_canonical_1. site.ru
site.ru
RewriteRule (.*) http://www.site.ru/$1 [R=301,L]
5. Директива Host дает определение основного домена с www или без для Яндекса.
Для тех вебмастеров, которые только что создали свой сайт, не спешите выполнять те действия, которые я описал в этом пункте, сначала нужно составить правильный robots.txt прописать директиву Host, этим вы определите основной домен в глазах яндекса.
Это будет выглядеть следующим образом:
User-Agent: Yandex
Host: site.ru
Директиву Host понимает только Яндекс. Google ее не понимает.
Дальше обязательно нужно дождаться, когда Яндекс правильно склеит домен, а уже потом делать переадресацию в файле .htaccess
6. Joomla дубли страниц склеиваем в файле .htaccess.
Очень часто главная страница сайта на joomla бывает доступна по адресу http://site.ru/index.html или http://site.ru/index.рhp, http://site.ru.html , то есть это дубли главной страницы (http://site. index.php$ http://ваш сайт.ru/ [R=301,L]
index.php$ http://ваш сайт.ru/ [R=301,L]
Используйте этот код если вам нужно избавиться от дубля с index.рhp, не забудьте в коде вместо http://ваш сайт.ru/, поставить свой домен.
Чтобы проверить получилась у вас или нет, просто введите в браузер адрес дубля (http://site.ru/index.рhp), если получилось, то вас перебросит на страницу http://site.ru, также будет происходить и с поисковыми ботами и они не будут видеть эти дубли.
И по аналогии склеиваем Joomla дубли с другими приставками к URI вашей главной страницы, просто отредактируйте код который я привел выше.
7. Указать sitemap в robots.txt
Хоть это и не относится к дублям, но раз уж пошла такая движуха, то заодно я рекомендую в файле robots.txt указать путь к карте сайта в xml формате для поисковиков:
Sitemap: http://домен.ru/sitemap.xml.gz
Sitemap: http://домен.ru/sitemap.xml
Итог
Подвоя итог вышесказанному, для Joomla я бы прописал вот такие строки в robots. index.php$ http://ваш сайт.ru/ [R=301,L]
Если вы используете другие способы устранения дублей, знаете как усовершенствовать описанное выше или просто Вам есть что сказать по этой теме — пишите, жду в комментариях.
Поиск дублей страниц сайта | Как проверить онлайн и убрать дубли
Сколько раз делаю технический аудит какого-нибудь клиентского сайта, так обязательно нахожу дубли страниц. Это особенная проблема для больших интернет магазинов. Давайте сейчас разберемся, как эту проблему диагностировать и решить.
Дубли сайта — это страницы с идентичным или почти одинаковым контентом но разными URL.
Дублями могут быть мета-теги title и description, могут быть дубли текста или полного контента, то есть всего содержимого страницы. Наиболее часто дублями бывают страницы пагинации, карточки товаров, страницы фильтра или теги.
Причем частичное совпадение контента допустимо, например, в каких-то карточках товаров могут дублироваться характеристики или какие-то блоки на странице могут дублироваться, например, отзывы. Но если взять сайт в целом, то каждая страница на сайте должна быть уникальной.
От дублей страниц очень много бед для сайта. Например, они понижают общий рейтинг сайта, его общее качество в глазах поисковых систем. В google вообще можно словить фильтр Панду за большое количество дублей.
Например, яндекс идентифицирует дубли, они отображаются в яндекс вебмастере, он просто выплевывает их из выдачи.
А google наоборот их хранит и при достижении какого-то критического значения накладывает фильтр на сайт. В общем, вреда от дублей для сайта много и поэтому от них обязательно нужно избавляться.
Но для начала их нужно идентифицировать, и есть несколько способов поиска и проверки дублей страниц сайта онлайн, я разберу способы ручные и способы автоматизированные. Эти способы являются универсальными и подойдут для любого движка, будь то wordpress, битрикс, opencart, joomla и других.
Проверка дублей через яндекс вебмастер
Самый простой способ, если у вас есть яндекс вебмастер, вы можете зайти в раздел «Индексирование — страницы в поиске».
Выбрать здесь «Исключенные страницы» и посмотреть, нет ли у вас вот такой картины.
Вебмастер показывает, что это дубли, и если такое присутствует, то нужно от этого избавляться. Дальше я покажу, какие есть варианты исправить их.
Поиск через индекс поисковых систем
Следующий способ также ручной — нужно вбить в поисковую строку google такую комбинацию site:santerma.shop (после двоеточия адрес вашего сайта), и покажутся все страницы, которые есть в индексе поисковой системы.
Аналогично работает и в яндексе.
Затем вручную пройтись по сайту и посмотреть, какие есть проблемы. Например, вот видно, есть какие-то дубликаты заголовков — интернет магазин сантехники и водоподготовки САНТЕРМА.
Можно перейти и посмотреть, что это за дубликаты, заголовки у них одинаковые, получается страницы тоже могут быть одинаковые.
Это страницы пагинации, о чем я и говорил, что очень часто дублями является такие страницы. То есть сами страницы не являются дублями, но здесь дубли мета-теги, тайтл у всех этих страниц одинаковый.
То есть сами страницы не являются дублями, но здесь дубли мета-теги, тайтл у всех этих страниц одинаковый.
Это означает, что вот таких страниц «Интернет магазин сантехники и водоподготовки» очень много, соответственно, эту проблему тоже нужно решать, для страниц пагинации делают rel canonical.
Как проверить дубли с помощью Screaming Frog
Следующий способ, как можно проверить онлайн и найти дубли страниц на сайте, уже является автоматическим, с помощью программы Screaming frog. Загружаем адрес сайта, нажимаем «Старт», и программа начинает парсить весь сайт.
Затем переходим в раздел Page title, нажимаем сортировку, и вот опять видно, что тайтлы полностью идентичные, причем разные url, а тайтлы везде одинаковые.
Это очень грубая ошибка, ее нужно исправлять, то есть тайтл для каждой страницы должен быть уникальным.
Как найти дубли сайта онлайн с помощью Saitreport
Еще один способ, как найти дубли сайта — через сервис Saitreport. Я записывал обзор по этому сервису, посмотрите видео:
Я записывал обзор по этому сервису, посмотрите видео:
Вкратце скажу, что дубли страниц можно найти во вкладке «Контент», спускаемся вниз и здесь вот есть «Полные дубликаты», «Почти дубликаты» и «Очень похожие».
Нас интересуют вот эти полные совпадения и почти дубликаты, особенно полные совпадения, переходим сюда и видим, что достаточно много дублей.
По URL видно, что эта страницы фильтров, две полностью идентичные страницы. Самое главное, чтобы фильтр был закрыт от индексации, чтобы весь этот мусор не попал в индекс. Если это просто находится на сайте, но не в индексе, то ничего страшного нет, но если этот мусор попадет в индекс, то можно легко похерить сайт.
Проверка дублей страниц index.php и index.html
И последний способ найти дубли — проверить файлы index.php и index.html, которые могут отвечать за отображение главной страницы сайта. Часто бывает, что на сайтах эти файлы настроены неправильно.
Часто бывает, что на сайтах эти файлы настроены неправильно.
Чтобы это проверить нужно к адресу главной страницы через слэш прописать index.php. Если все настроено правильно, то должен произойти 301 редирект (сайт перебросит с index.php на главную страницу) или должна открыться страница 404 ошибки.
Но если по адресу site.ru/index.php открывается опять главная страница, то это является дублем, то есть страница site.ru/index.php дублирует главную страницу.
В этом случае нужно проверить внутренние страницы — также через слэш прописать index.php. Скорее всего опять откроются дубли внутренних страниц, иногда открывается опять главная, получаются многократные дубли через неправильную настройку этого файла.
Аналогично нужно проверить файл index.html. Как я сказал, должен произойти или 301 редирект (перебросить на главную страницу) или открыться страница 404 ошибки.
Как убрать дубли
Итак, что теперь делать с этими дублями, которые найдены? Вариантов много, и каждый вариант нужно выбирать в зависимости от ситуации, сайта, потому что один и тот же вариант может подойти одному сайту, но не подойдет другому.
Самое главное, нужно определить, насколько важны эти страницы для продвижения сайта. Есть ли на них трафик или может быть планируется, и дальше действовать в соответствии с этой важностью.
Если эта страницы не важны, то есть варианты:
- закрыть их от индексации;
- настроить на них canonical;
- совсем удалить их сайта.
Если же это страницы важные, то нужно их уникализировать:
- переписать метатеги;
- переписать заголовоки;
- переписать контент;
- сделать каждую страницу уникальный, чтобы она несла пользу посетителю и продвигалась в поиске.
Для закрепления материала, посмотрите более подробное и наглядное видео по поиску дублей:
Итак, я надеюсь, что статья была полезной для вас! Пишите ваши вопросы, комментарии, может что-то не понятно, просто пишите, если статья понравилась, я рад любой обратной связи. Поделитесь ею с друзьями в социальных сетях!
Сергей Моховиков
SEO специалист
Здравствуйте! Я специалист по продвижению сайтов в поисковых системах Яндекс и Google. Веду свой блог и канал на YouTube, где рассказываю самые эффективные технологии раскрутки сайтов, которые применяю сам в своей работе.
Вы можете заказать у меня следующие услуги:
Загрузка…Как удалить дубли страниц в WordPress за несколько минут
Что такое дубли страниц?
Очень часто владельцы wordpress сайтов начинают беспокоиться, если не понимают из-за чего отдельные страницы проваливаются в выдаче. Причиной тому могут быть дубли страниц. Это страницы, содержащие материалы с идентичным или похожим контентом. Речь о страницах архивов дат, рубрик, авторов и комментариев. При этом они могут располагаться под разными адресами, что позволяет дублям конкурировать с основной статьей за место в поисковой выдаче. В этом материале мы расскажем как избавиться от дублей страниц.
В этом материале мы расскажем как избавиться от дублей страниц.
Создание дублей страниц на сайте
Как мы уже рассказывали ранее, дубли одной конкретной страницы, где размещена одна конкретная статья создаются и в архивах дат, и в рубриках или категориях (могут называться по-разному), а также на страницах с комментариями. Благодаря этому пользователи могут сортировать посты и находить по определенным критериям нужные. Система делает это автоматически.
Давайте посмотрим как это выглядит на примере архива дат. Предположим нам нужно выбрать все статьи за ноябрь. На главной странице сайта кликните на ссылку в виджете с указанием месяца.
Кликнув на ссылку «ноябрь 2018» перед вами появится список из статей, которые были сделаны за указанный месяц. Вот наглядный пример того, что под архивы дат wordpress создает отдельную страницу. Вспоминаем про индексацию лишних страниц поисковиком и об ее негативных для продвижения последствиях. Подробнее мы рассказывали в статье о том, как удалить страницы вложений в wordpress.
Дубли в комментариях
При работе с комментариями вебмастерам следует учитывать, что как таковые, дубли страниц создаются при наличии древовидной системы обсуждения. В том числе если обсуждений очень много и комментариям не хватает места на одной странице, то часть их перемещается на следующие. И в этом случае вам необходимо удалить дубли страниц в wordpress, иначе проиндексированные страницы станут своеобразной ловушкой для пользователей. Они просто попадут на страницу комментариев статьи, а не на саму статью, после чего посетители, скорее всего покинут сайт. SEO-продвижение явно пострадает от большого количества отказов.
Как удалить дубли с помощью плагина WordPress
Чтобы не разбираться с провалами в поисковой выдаче, лучше заранее провести профилактическую работу. А именно удалить дубли страниц в wordpress. Мы предлагаем вам воспользоваться плагином оптимизации сайтов Clearfy. В его арсенале большой спектр полезных функций для удаления дублей страниц. Скачайте данное приложение и установите, так мы сможем рассказать о всех фичах более предметно.
Скачайте данное приложение и установите, так мы сможем рассказать о всех фичах более предметно.
После активации перейдите в меню настроек плагина: «Настройки» => «Clearfy меню» =>
=> далее раздел «SEO» (в левом боковом меню плагина) => вкладка «Дубли страниц»
Начнем по порядку, с удаления архивов дат. Здесь стоит сразу уточнить, что удалять дубли в буквальном смысле мы не будем. Их просто отключат от индексирования. И это важнее, чем избавиться фактически от копий страниц. Если дубликаты не видит поисковик, значит пользователь перейдет на основную, нужную вам для продвижения страницу и не заблудится в многообразии ссылок-клонов. Чтобы запустить функцию нажмите кнопку ВКЛ.
С архивом автора, ситуация такая же, как и с архивом дат: дубли не удаляются, а отключаются от индексации. Также ставится редирект с дубля на основную страницу. Активируйте и эту функцию.
Чтобы удалить метки архивов, нужно поставить редирект со страниц тегов на главную. Для этого активируйте функцию ниже. Аналогично предыдущим. Обратите внимание на серую метку со знаком вопроса. Она указывает на то, что негативных последствий настройка не вызовет.
Для этого активируйте функцию ниже. Аналогично предыдущим. Обратите внимание на серую метку со знаком вопроса. Она указывает на то, что негативных последствий настройка не вызовет.
Для каждой фотографии или видео wordpress создает отдельную «страницу вложений» с возможностью комментирования, что является своеобразным якорем оптимизации. Подробней об этом мы говорили в предыдущей статье. Нажимаем кнопку ВКЛ.
Если у вас на сайте пагинация настроена таким образом, что контент размещается сразу на нескольких страницах, то в конце URL, в том или ином виде, будет добавляться порядковый номер каждой страницы. Clearfy же, предложит вам удалить постраничную навигацию записей. То есть каждая страница одной статьи будет редиректиться на основную. Нажмите кнопку ВКЛ.
Если у вас настроены древовидные комментарии, то их иерархия создаст благоприятные условия для создания копий страниц. Выглядит это так: вы отвечаете на чей-то комментарий и одновременно в URL появляется переменная ?replytocom — это значит, что поисковик видит в этом не ответ на комментарий, а отдельную страницу, так как адрсе отличается. Удалить дубли страниц в wordpress и выполнить редирект вы можете активировав данную функцию.
Удалить дубли страниц в wordpress и выполнить редирект вы можете активировав данную функцию.
Заключение
Время и силы, затраченные на продвижение сайта или отдельных статей могут уйти впустую. Если не позаботиться об удалении дублей страниц заранее. Они индексируются поисковиком и могут составить конкуренцию основным статьям. После прочтения данной статьи мы надеемся, что вы оценили весь спектр представленных функций и теперь вам будет несложно удалить дубли страниц в wordpress.
Удалить повторяющиеся сообщения в разных разделах главной страницы
Таким же образом необходимо воздействовать на третий запрос. Извлеките идентификаторы из результатов второго запроса, который использует аргументы $ post_type_fp_2. Вы можете array_merge () любое количество массивов. Объедините элемент массива arg ‘post__not_in’ (если он существует) из аргументов третьего запроса с $ post_type_fp_2 [‘post__not_in’] и идентификаторами, извлеченными из второго запроса. Получите уникальные идентификаторы из слияния и назначьте их элементу массива arg post__not_in третьего запроса.
Получите уникальные идентификаторы из слияния и назначьте их элементу массива arg post__not_in третьего запроса.
Не хватает контекста, чтобы дать вам что-то более конкретное.
Автор темы Шир(@shirwp)
@bcworkz спасибо за любезный ответ!
1. Откуда мне взять идентификаторы щипков? А также аргументы $ post_type_fp_2? Это в файле header.php?
2. Какой контекст будет хорошим? Достаточно ли прикрепить здесь код header.php в виде файла?
Еще раз спасибо 🙂
Вы извлекаете идентификаторы из свойства сообщений второго объекта запроса после его создания.Я не знаю, где это будет. Возможно, где-нибудь в шаблонах страницы. Маловероятно, что это header.php, хотя это возможно удаленно. Это может быть даже обработчик шорткода или блочный код. Где код у вас живет? Как / где выводятся сообщения второго / третьего раздела? Контекст, который я ищу, — это любой код, отвечающий за запросы сообщений в каждом разделе. Это может быть в любом количестве мест. Сам запрос обычно выполняется с помощью
Это может быть в любом количестве мест. Сам запрос обычно выполняется с помощью get_posts или нового WP_Query .Возможно query_posts .
Если вы обнаружите необходимость опубликовать большой объем кода, разместите его на pastebin.com или gist.github.com и предоставьте ссылку здесь.
Автор темы Шир(@shirwp)
@bcworkz Еще раз большое спасибо за ваше время 🙂
Хорошо, поэтому я просто просмотрел (просто нажав ctrl + f) то, что вы упомянули выше (get_posts, new WP_query и query_posts) в большинстве файлов темы. Ничего не нашел.
Единственное, что мне удалось найти, это get_post (единственное число) внутри некоторого файла частей шаблона.
Если это может помочь — это моя структура файлов темы (где это может быть?):
Тема:
assets
css
customize-controls.css
js
customizer-control.js
customizer.js
html5.js
scripts. js
skip-link-focus-fix.js
библиотека
много разных под- files 🙂
inc
tgm
class-tgm-plugin-activate.php
theme-info (много файлов и под этим)
custom-header.php
customizer.php
functions.php
newscard-footer-info.php
newscard-metaboxes.php
newscard-widgets.php
template-functions.php
languages
template-parts
templates
404.php
arcieve. php
comments.php
footer.php
functions.php
index.php
ЛИЦЕНЗИЯ
page.php
readme.txt
rtl.css
screenshot.png
search.php
searchform.php
sidebar.php
single. php
style.css
wpml-config.xml
- Этот ответ был изменен 8 месяцев назад пользователем Shir.
- Этот ответ был изменен 8 месяцев назад пользователем Shir.
Это может быть любой из этих многочисленных файлов во вложенных папках. Поиск отдельных файлов с помощью Ctrl-F слишком утомителен, чтобы надежно что-либо найти. Вам нужен инструмент, который ищет текст в нескольких файлах во всем дереве каталогов. Классический инструмент командной строки Unix / Linux, который делает это, — это
Вам нужен инструмент, который ищет текст в нескольких файлах во всем дереве каталогов. Классический инструмент командной строки Unix / Linux, который делает это, — это grep . В Windows вы можете использовать findstr с той же целью.Загрузите файлы вашей темы на свой локальный компьютер (как можно ближе к C: \, избегайте пробелов в именах папок пути). Войдите в командную строку Windows (найдите «команда» в поле поиска Windows). Используйте cd в приглашении, чтобы сделать папку вашей темы актуальной. Введите что-то вроде findstr / S / N / C: "новый WP_Query" * .php . Будет произведен поиск всех файлов .php в текущей папке и во всех ее подпапках.
Это может дать слишком много результатов, чтобы быть полезным.
Автор темы Шир(@shirwp)
ОК.
Итак, третий раздел (который повторяет сообщения из разделов 1 + 2) находится в WP под настройкой -> «Заголовок избранных сообщений».
Кроме того, я искал «новый запрос WP», как вы мне подсказали выше, — есть несколько результатов.
Не уверен, какой из них подходит…
Вот результаты (опять же, сохраненные в Github, когда вы меня направляли :)):
https://github.com/shirgu/remove-duplicate-hp-posts
Одних результатов поиска недостаточно, чтобы определить, какой из них применим.Это только начало дальнейших исследований. «Заголовок избранных сообщений» в настройщике — это то, что добавлено вашей темой. Я все равно не знаю, где делается связанный запрос.
Можно изменять запросы с помощью обработчика действия pre_get_posts, не зная, где создается запрос, но вам все равно нужно знать что-то особенное о запросе, чтобы изменялся только правильный. Это может оказаться бесполезным, но это вариант, если известна правильная информация.
Я рекомендую узнать, как изменить запрос, через специальный канал поддержки вашей темы. Они лучше всех знают, как это сделать.
Контент Elementor Page Builder дублируется под нижним колонтитулом ???
Я не знаю причины проблемы (я бы посмотрел на другие плагины или скрипты, которые могут делать что-то странное).
Что касается обходного пути, мой первый вопрос был бы: зачем вам нужен другой шаблон, а не страница по умолчанию.Вы говорите, что должны сохранить заголовок темы. А как насчет нижнего колонтитула? Почему нельзя просто использовать значение по умолчанию?
Привет,
Я почти уверен, что это связано с темой / конфликтует с Elementor или другим плагином.
Я лично использую и предпочитаю бесплатную тему OceanWP, потому что она имеет отличную поддержку и отлично работает с Elementor.
С этой темой вы можете легко получить тот же макет, что и сейчас, и, по моему опыту, не будет этих (вероятных проблем совместимости).
Почему бы не попробовать, просто оставьте пока другую тему и переключитесь на OceanWP?
Конечно, всегда (я уже говорил, всегда ха-ха) делайте резервные копии!
https://nl.wordpress.org/plugins/all-in-one-wp-migration/ — мой любимый бесплатный инструмент для резервного копирования!
Энни
Спасибо за ответы.
Дело в том, что я создаю сайт для клиента, у которого уже есть другой сайт, принадлежащий другой компании. Клиент хочет, чтобы это было почти идентичным по стилю, потому что две компании должны быть явно связаны.Вот почему я использую ту же тему и тому подобное.
@ Josiah
Причина, по которой я хочу создавать собственный контент, заключается в том, что параметры для шаблона домашней страницы по умолчанию очень ограничены. По сути, у вас есть около восьми различных «виджетов», чтобы их так называть, со встроенными функциями. Они выполнили работу с содержанием домашней страницы предыдущего сайта, но на этот раз нужно добавить что-то новое, чего нельзя сделать с помощью этих виджетов. Есть текстовый виджет, но он слишком ограничен.Вот почему я хочу встроить свои собственные элементы в тело, сохранив исходный верхний и нижний колонтитулы, чтобы они по-прежнему были хорошо узнаваемы для тех, кто знает другой сайт. Что отлично работает, если бы не дублированный контент под нижним колонтитулом.
Нижний колонтитул, который там сейчас находится, ЯВЛЯЕТСЯ по умолчанию. Я попытался создать собственный нижний колонтитул, чтобы посмотреть, можно ли выровнять его по нижнему краю или, по крайней мере, ниже дублированного содержимого, но это не удалось — он просто вел себя точно так же, как нижний колонтитул по умолчанию.
Кроме того, когда вы вводите текст в стандартном текстовом редакторе WordPress вместо Elementor, то же самое происходит с этим текстом — он дублируется под нижним колонтитулом. Это заставляет меня думать, что это не обязательно вина Elementor …
@ LogoLogics
Если я не найду решение, тогда нам просто не повезет, и мне все-таки придется перенести сайт на другую тему. Спасибо за советы, они пригодятся, если такое случится.
В моей теме вы можете либо использовать встроенные функции для компоновки страницы и включения виджетов, ЛИБО вы можете просто определить свою собственную страницу и настроить тему для использования этой страницы. Если вы определяете свою собственную страницу, вы можете выбрать один из трех макетов для любого данного шаблона: боковая панель слева, боковая панель справа или без боковой панели. Итак, если вы выберете шаблон по умолчанию без боковой панели и отредактируете его в Elementor, вы сможете поместить все, что захотите, в тело, сохранив при этом верхний и нижний колонтитулы темы. Не знаю, позволяет ли это ваша тема.
Если вы определяете свою собственную страницу, вы можете выбрать один из трех макетов для любого данного шаблона: боковая панель слева, боковая панель справа или без боковой панели. Итак, если вы выберете шаблон по умолчанию без боковой панели и отредактируете его в Elementor, вы сможете поместить все, что захотите, в тело, сохранив при этом верхний и нижний колонтитулы темы. Не знаю, позволяет ли это ваша тема.
Это действительно странная ошибка, учитывая, что основной текст дублируется после тега