
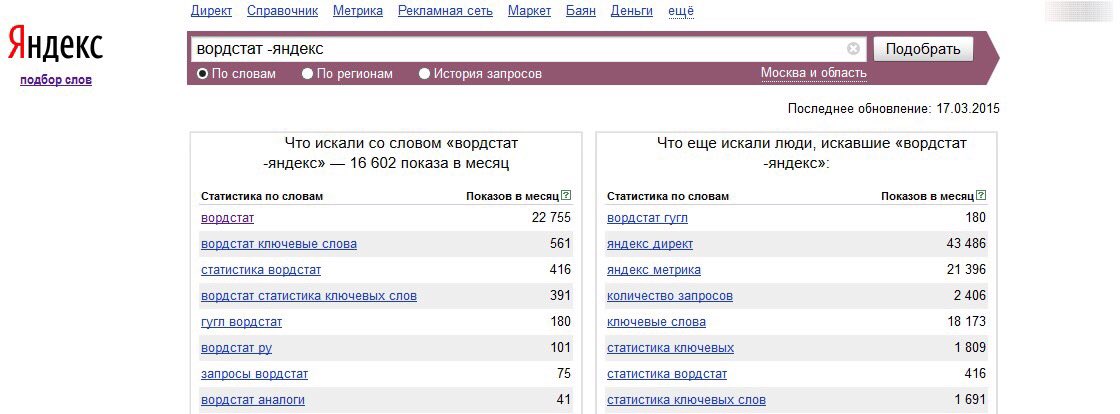
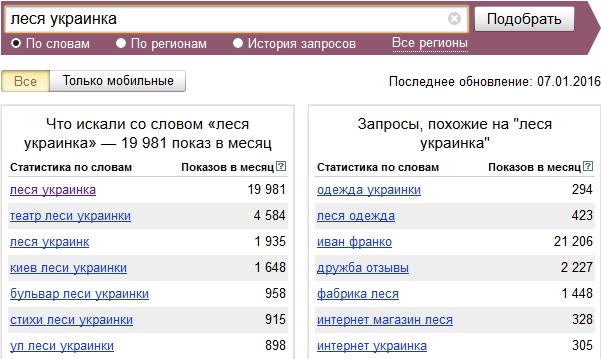
Как узнать топ популярных ключевых фраз за месяц в Яндексе
Запросы – это те фразы и словосочетания, с помощью которых идет продвижение сайта и его страниц в поисковой системе. Чем они популярнее (то бишь идеально соответствуют интересам целевой аудитории), тем быстрее ресурс будет продвигаться на первые позиции выдачи. Но это не единственная цель, для которой нужно составлять статистику запросов.
Я подробно расскажу, кому и зачем это нужно, а также опишу основные способы поиска топа запросов Яндекса за месяц.
Зачем нужно знать запросы в Яндексе
Как я уже сказала, чем частотнее запросы, по которым продвигается сайт, тем быстрее он поднимется на вершины поисковой выдачи Яндекса. Сам контент при этом должен быть не менее интересным, причем как целевой аудитории, так и поисковым роботам.
Отслеживание поисковых трендов также необходимо и для других целей – прогнозирования роста трафика на вашем сайте, оценки перспективности выбранной тематики или направления в бизнесе, а также поиска сезонных трендов.
Как узнать топ запросов Яндекса
Существует несколько сервисов, с помощью которых можно узнать о том, кто и что ищет в Яндексе. В первую очередь я рассмотрю инструменты самой компании, а уже потом буду разбирать сторонние сервисы.
Яндекс.Вордстат
Чтобы сервис Вордстат работал нормально, прежде всего надо авторизоваться в своем профиле Яндекс. Далее действовать очень просто – надо ввести в строке ключевую фразу. Сервис может потребовать ввод капчи, дабы подтвердить, что вы не робот.
Сортировку можно проводить по словам, регионам, а также истории запросов. В первом случае будут отображаться другие популярные фразы, а во втором – популярность их в конкретном регионе. Можно фильтровать запросы, выбирая показы исключительно в мобильной версии и так далее.
При подборе ключевых слов отображается два столбца – в левом запрашиваемое, а в правом похожее, смежное из этой же тематики. В данном сервисе можно также уточнять некоторые запросы с помощью специальных операторов. К примеру, если заключить ключевое слово в кавычки «», в результатах будут отображены все возможные словоформы.
В данном сервисе можно также уточнять некоторые запросы с помощью специальных операторов. К примеру, если заключить ключевое слово в кавычки «», в результатах будут отображены все возможные словоформы.
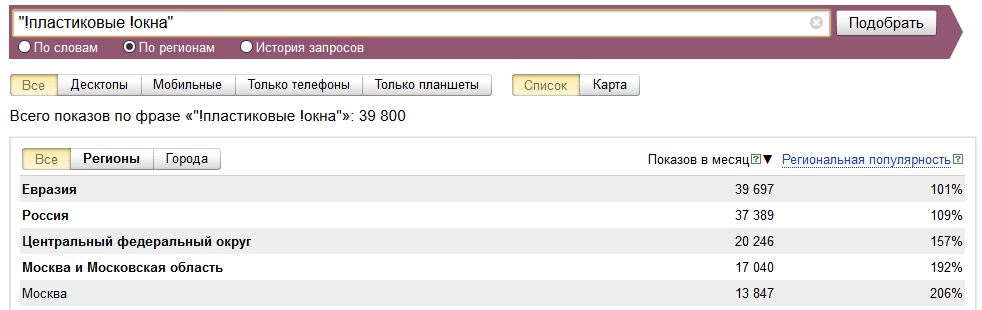
Другой вариант – заключить искомое слово в восклицательные знаки. В таком случае выделенное слово будет искаться в точном вхождении, без изменения формы. И главное, что знак этот должен ставиться перед каждым словом, которое должно быть найдено без изменений.
Еще один инструмент – квадратные скобки [ ]. В данном случае будет зафиксирован порядок слов в ключевой фразе. А вот скобки () и прямой разделитель | используются для создания комбинаций ключевых запросов.
С помощью знаков можно также добавлять или убавлять слова. Символ плюса «+» фиксирует стоп-слова, не имеющие дополнительного смысла, а минус «-», наоборот, убирает ненужные слова из фразы.
Яндекс.Вебмастер
В Яндекс.Вебмастер тоже доступна статистика поисковых запросов. Он показывает те, что используются на вашем сайте, выделяет из них наиболее популярные и показывает статистику домена с вашими конкурентами.
Яндекс.Директ
Яндекс.Директ в первую очередь предназначен для создания рекламных объявлений. Но с его помощью можно также собирать популярные ключевые слова и фразы. Единственный минус, возможно, актуальный не для всех – прежде всего необходимо создать рекламную кампанию в сервисе, а уже потом переходить к поиску.
В Яндекс.Директ предусмотрена встроенная статистика ключевых фраз. Она лишь показывает, сколько человек в предыдущем месяце искали введенные вами ключи, а также популярные схожие запросы.
Serpstat
В Serpstat есть отдельная страница с инструментом для анализа ключевых фраз. Здесь необходимо ввести определенное ключевое слово или фразу, затем нажать на кнопку «Получить данные», и сервис приведет подробную информацию по нему.
Минус – без регистрации никакой информации вы не получите.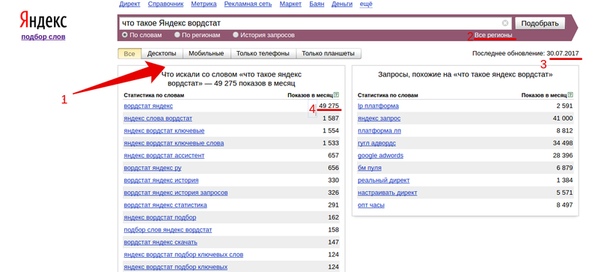 Тут можно залогиниться с помощью Google или Facebook. В результатах, кстати, будет показана частотность, ее стоимость в контекстной рекламе, конкуренты, а также платная и органическая выдача.
Тут можно залогиниться с помощью Google или Facebook. В результатах, кстати, будет показана частотность, ее стоимость в контекстной рекламе, конкуренты, а также платная и органическая выдача.
Только вот как определить, в каком регионе и к какой поисковой системе они относятся? Легко! Просто на итоговой странице открыть выпадающее меню справа и настроить регион. Выбор невелик, конечно…
Если же вы только создаете сайт и оптимизируете его, но не знаете, какие ключевые слова популярны, можно посмотреть раздел «Подбор фраз». Он находится в категории «Анализ ключевых фраз», далее «SEO-анализ». На этой странице выдаются все вариации искомой ключевой фразы, по которым сайты ранжируются в топ-50 органической выдачи поисковой сети Яндекс. Также предоставляются основные показатели по ключам в различных регионах и их стоимость.
По бесплатному тарифу можно посмотреть только 10 ключевых фраз. Чтобы увидеть больше, необходимо купить платную версию.
Магадан
Предупреждаю заранее, что Магадан – это не онлайн-сервис, а программа для установки на компьютер. С ее помощью можно проводить сбор и анализ статистики по ключевым фразам из Яндекс.Директа, группировать и объединять запросы, фильтровать их и даже хранить в различных базах.
У программы, конечно же, есть две версии – LITE и PRO. Первая ознакомительная, с ограничениями по функционалу, но скорее в плане автоматики сбора данных, нежели в ее объемах. В PRO, понятно, нет никаких ограничений.
Key Collector
Еще одна хорошая программа для оптимизации сайта – это Key Collector. С ее помощью можно быстро собрать поисковые запросы из Яндекса, узнать их стоимость и эффективность. Самое интересное, что в ней есть 70 параметров для оценки ключевых фраз и даже проведение экспертного анализа на соответствие сайта семантическому ядру. Бесплатная версия этой программы называется «Слобоеб», но она сильно ограничена по функционалу и скорости сбора ключевых слов.
Заключение
Одни из самых эффективных и востребованных инструментов для поиска топа запросов Яндекса – это Вордстат и Serpstat.
Выбор за вами!
Как узнать частотность запросов в Google и Яндекс
Эффективность SEO-продвижения напрямую зависит от выбранной стратегии подбора ключевых слов, а также оценки уровня их частотности. Поэтому так важно иметь под рукой статистику запросов. Давайте разбираться, как её можно получить.
Содержание:
Как посчитать количество запросов в Google
Лидер среди поисковых систем имеет собственный инструмент статистики запросов — Планировщик ключевых слов, или Google Keyword Planner. Он находится внутри рекламного кабинета Google Ads. Чтобы им воспользоваться, необходимо пройти обязательную регистрацию с указанием своих платёжных данных и создать рекламную кампанию. При этом запускать показ платных объявлений необязательно.
Он находится внутри рекламного кабинета Google Ads. Чтобы им воспользоваться, необходимо пройти обязательную регистрацию с указанием своих платёжных данных и создать рекламную кампанию. При этом запускать показ платных объявлений необязательно.
После этого в правом верхнем углу экрана найдите ссылку на этот инструмент и перейдите по ней.
Для проверки частотности запросов выберите окно «Новые ключевые слова».
В нём введите интересующие вас фразы в специальное поле, уточните регион и язык поиска, нажмите «Показать результаты».
Вас перебросит на страницу со статистическими данными для введённых ключевых слов, а также похожих фраз:
- Среднее число запросов в месяц, причем не точное количество, а довольно большой диапазон;
- Уровень конкуренции в контекстной рекламе;
- Стоимость показа рекламного объявления вверху поисковой выдачи.

Для составления семантического ядра нас интересует информация о частотности и вариантах ключевых слов.
При желании, в верхней части экрана вы можете изменить настройки, указав период времени, язык и регион поиска. А также с помощью фильтра исключить из списка нежелательные слова.
Как собрать частотность запросов в Яндексе
Разработчики российской поисковой системы также создали сервис по работе со статистикой ключевых слов —
Введите ключевую фразу в строку поиска и нажмите кнопку «Подобрать». Сервис отобразит запросы, в составе которых есть эти слова, а также их прогнозируемую частотность в месяц.
С помощью специальных операторов вы можете задать минус-слова или узнать статистику точного словосочетания без предлогов и изменения окончаний.
В Вордстат есть возможность выбрать сортировку по регионам, а также просмотреть историю изменений частотности запросов за последние 2 года.
Сторонние сервисы, где можно посмотреть количество поисковых запросов
Не только поисковики готовы предоставить информацию об использовании ключевиков пользователями. Некоторые сторонние сервисы также формируют статистические данные. Рассмотрим наиболее популярные и удобные программы, с помощью которых можно посмотреть количество запросов по ключевым словами.
Serpstat
Многофункциональная платформа для SEO, в которой имеется инструмент подбора ключевых слов. Serpstat — платный сервис. Вместе с тем в нём можно найти массу полезных данных для эффективного продвижения, наличие которые полностью оправдывает стоимость подписки.
Здесь есть возможность:
- посмотреть статистические данные как по Яндексу, так и по Google с привязкой к стране продвижения;
- выполнить сортировку от самых популярных поисковых запросов к низкочастотным и наоборот;
- отфильтровать данные по определённому параметру.
Полученные данные можно выгрузить, например, в Excel для дальнейшего комфортного использования.
Букварикс
В этом сервисе можно проводить бесплатный анализ ключевых слов на основе данных из Яндекс Вордстата.
Букварикс весьма прост в использовании, в нём нет ничего лишнего: ключевое слово, похожие комбинации запросов и их частотность.
Здесь же можно произвести бесплатный анализ продвигаемых ключевиков конкурентами.
Keyword Tool
Платный сервис, который собирает данные по частотности использования ключевых фраз не только в Яндекс и Google, но и на других платформах: YouTube, Instagram, Bing, Amazon и др.
Keyword Tool также прост в использовании, как и большинство подобных сервисов. С работой в нём без проблем справится даже начинающий оптимизатор.
Выводы
Поиск и анализ ключевых фраз — основа работы оптимизатора, без которой вывести сайт в ТОП довольно сложно. С помощью сервисов подбора запросов и анализа их частотности можно разработать эффективную стратегию продвижения и привлечь именно тех пользователей, которые точно нуждаются в ваших товарах или услугах.
А какой сервис используете вы для анализа частотности ключевых слов?
P.S. На курсе «Поисковик» вы узнаете все тонкости и особенности работы с ключевыми словами для продвижения вашего сайта, и самое главное — уже в процессе обучения сможете применить полученные знания на практике. Переходите по ссылке выше, и бронируйте участие. А с промокодом «SEO-25» вас будет ожидать приятный бонус.
Как пользоваться Wordstat — как работать с операторами Яндекс Вордстат и статистикой поисковых запросов
В этой статье мы расскажем:
- как работать со статистикой поисковых запросов Яндекса с самых азов;
- рассмотрим на примерах основные и дополнительные операторы;
- научимся определять сезонность спроса;
- дадим полезные советы по использованию софта, облегчающего работу.
Яндекс Вордстат – это бесплатный сервис компании Yandex, призванный помочь оптимизаторам и владельцам сайтов узнать, как люди ищут товары или услуги и собрать ключевые слова для продвижения сайтов.
Помимо этого, сервис позволит:
- узнать частотность;
- определить сезонность по каждому продвигаемому запросу;
- определить спрос по конкретным регионам;
- определить долю популярности фраз по устройствам (смартфон, десктоп, планшет).
Вы сможете собрать полное семантическое ядро и разработать структуру проекта. Сделать это проще с помощью специализированного софта, но вернемся к этому позже.
Начало работы
Для доступа к статистике сначала необходимо зарегистрироваться в Яндексе.
- заведите почтовый ящик на Яндекс и авторизуйтесь;
- откройте инструмент по ссылке https://wordstat.yandex.ru/.
Готово, можно приступать к работе.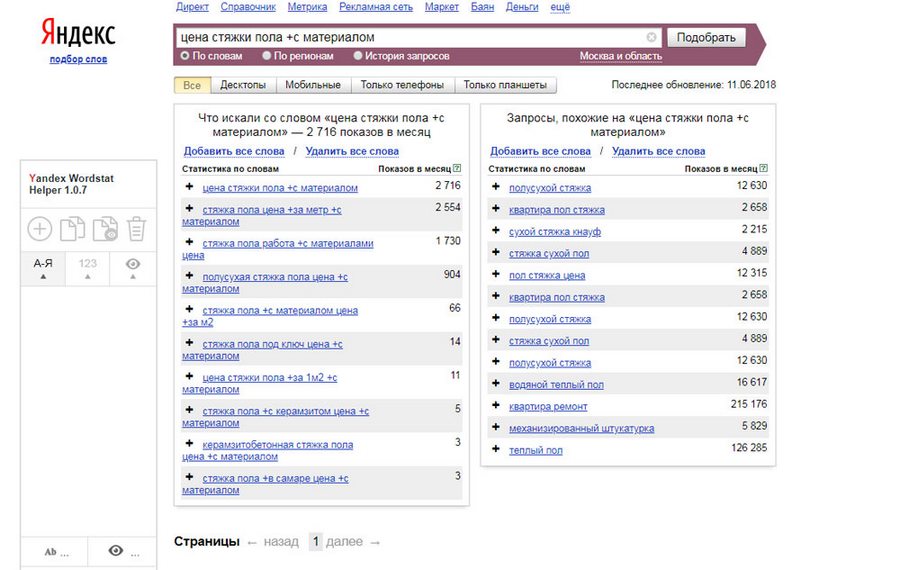
Поиск по словам
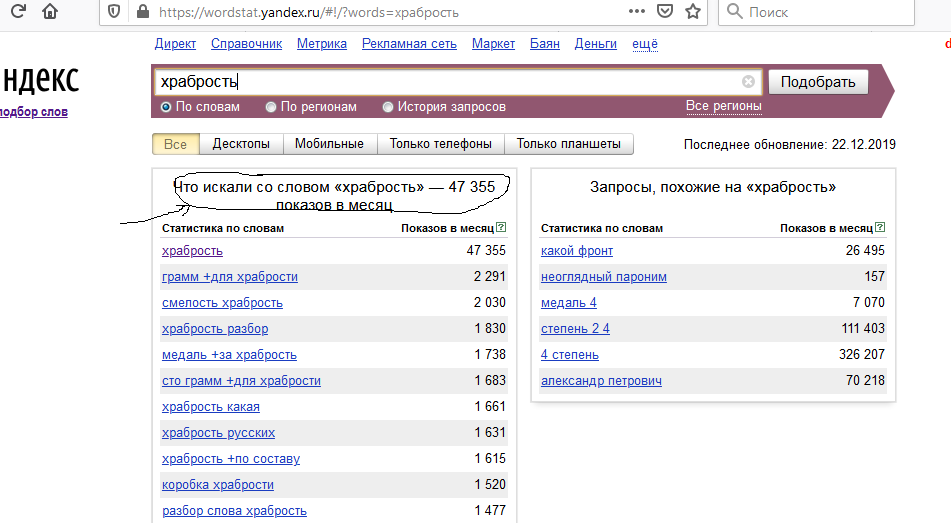
Осуществляется поиск запросов, в которых присутствует введенная фраза (в левой колонке), а также всех похожих (в правой колонке). В колонке «Показов в месяц» выводится базовая частотность за последний месяц (суммарная частотность фраз из левой колонки).
Частота по регионам
Отражает частотность запроса в отдельности по регионам, во второй и третьей колонках отражена популярность в числовом и процентном соотношении. Можно вывести списком и на карте для наглядности.
История запросов — сезонность запроса
С помощью этого инструмента можно проанализировать сезонность спроса по товару или услуге. Показывает популярность поискового запроса по месяцам или неделям. По скриншоту ниже видим, что спрос на услугу по «созданию сайтов» имеет значительный рост популярности в период с апреля по июнь.
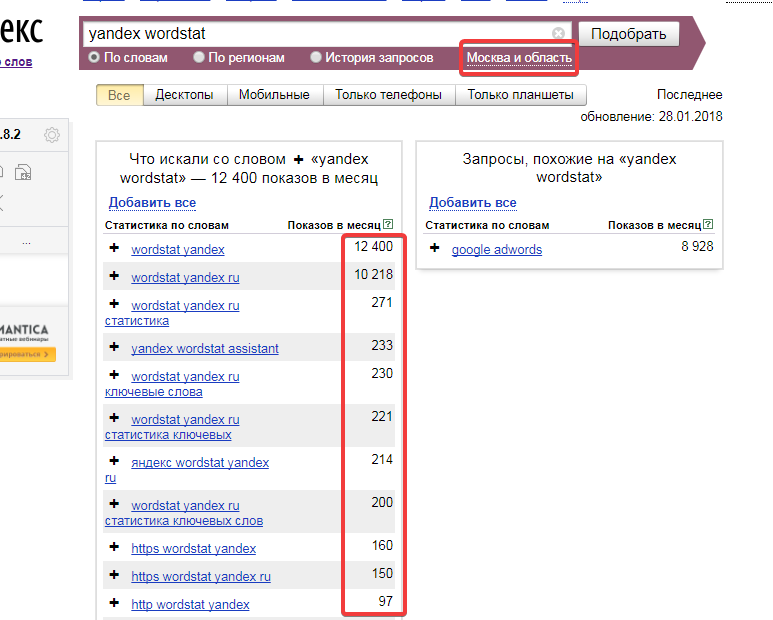
Регион отображаемой статистики
Выбираем регион, статистика по которому нас интересует. При продвижении, скажем, по Москве – выбираем «Москва и область».
При продвижении, скажем, по Москве – выбираем «Москва и область».
Инструмент позволяет сделать выгрузку по всей России, а также СНГ, Европе, Азии, Африке, Северной и Южной Америке, Австралии и Океании.
Статистика по устройствам
Вкладки «десктоп, мобильные, только телефон, только планшеты» содержат информацию с каких конкретно устройств наиболее часто вводят поисковый запрос.
Операторы Wordstat
Операторы необходимы для уточнения формулировки запроса и точного определения частотности ключевых фраз. Если ввести интересующие слова без применения специальных символов, то получим их базовую частотность, то есть – суммарную частоту поисковых запросов пользователей Яндекс с применением данной фразы.
Пример:
Частотность всех ключей со словом «велосипед» – купить велосипед, детский велосипед, трехколесный велосипед и т.д.
Ниже предлагаем рассмотреть основные операторы.
“Кавычки”
Фразы, зафиксированные оператором “кавычки”, например «создание сайтов», отобразят частотность только данного словосочетания без хвостов, во всех возможных формах и в любом порядке.
Сбор статистики запросов определенной длины
С помощью оператора “кавычки” можно вывести на экран статистику запросов, состоящих из заданного количества слов – из 2, 3, 4 и так далее.
Например, чтобы получить список ключей из 2 слов по фразе «велосипед», введите в Wordstat следующую конструкцию – “велосипед велосипед”.
В итоге получаем ключевые слова и базовую частотность по всем запросам из двух слов с заданной фразой. Данная конструкция применима для произвольного количества слов в запросе и любых тематик.
!Восклицательный !знак
Если перед введенными фразами применить оператор «восклицательный знак», то получите частотность по всем фразам с их присутствием именно в том виде и с тем окончанием, как вы ввели.
“!Кавычки !с !восклицательным !знаком”
Если совместить использование операторов Яндекс Вордстат “кавычки” и !восклицательный !знак, сервис покажет частотность четко по заданной фразе слово в слово, без учета порядка.
Дополнительные операторы
Операторы, предназначенные для более сложной сортировки данных при работе со статистикой запросов Wordstat.
[Квадратные скобки]
С помощью данной конструкции фиксируется порядок слов в запросе.
Пример – [стол для обеда]
Абсолютно точная частота запроса с учетом порядка, состава слов и окончаний.
Для получения точной частотности, используйте конструкцию вида – «[!стол !для !обеда]».
(Или|Или)
Вводится с применением вертикального разделителя “|” между словами и заключением их в круглые скобки. Чаще всего применяется, когда необходимо сравнить статистику по двум одинаковым по смыслу запросам, но с разным написанием.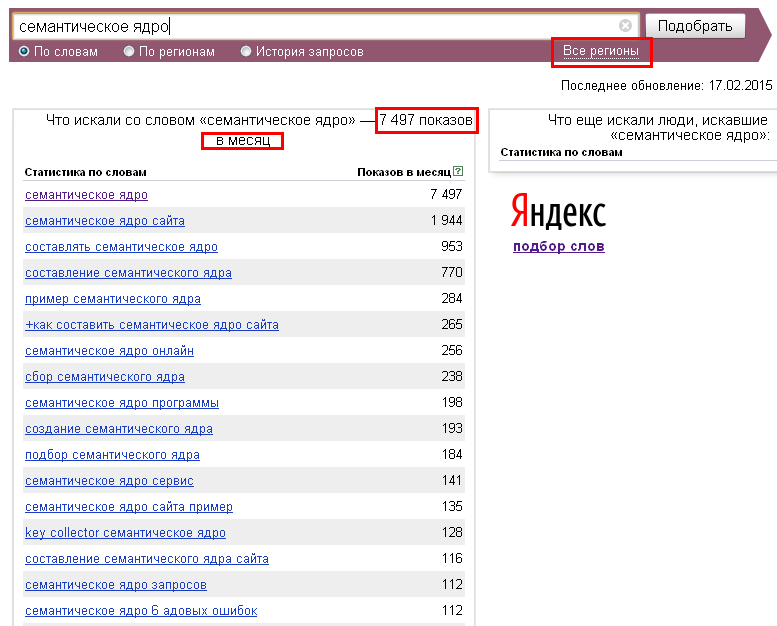
Пример –
(Iphone|айфон), (сайт|вебсайт), (раскрутка|продвижение).
Таким образом, Вордстат показывает все ключи и число их показов сразу по обеим фразам – “iphone” и “айфон”.
Оператор “+”
Если перед любым словом указать символ «плюс», то оно становится обязательным для программы. Также его использование очень полезно для выделения предлогов, так как сам Вордстат их не учитывает.
Пример #1. Вводим поисковый запрос с предлогом
Как мы видим, инструмент проигнорировал наличие предлога и мы не получили статистику в том виде, в каком хотели.
Пример #2. Указываем перед предлогом «+»
Теперь видим, что в левой колонке все запросы содержат нужное нам слово.
С помощью данной конструкции удобно готовить контент-план для публикаций в блоге. Для этого используйте вместе с основным запросом вопросительные плюс-фразы: «как, зачем, почему, своими руками» и так далее.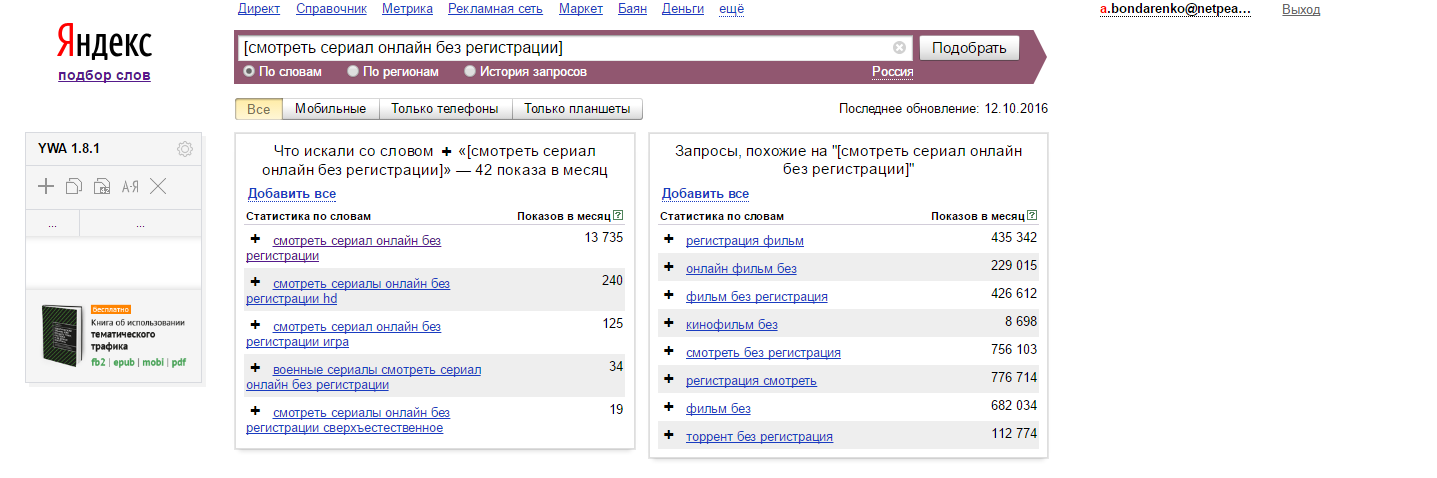
Оператор “-”
Добавление символа “минус” перед словом поможет исключить все ключи с его участием. Можно добавлять неограниченное количество минус-фраз.
Например, вы хотите создать сайт веб-студии и ваш основной запрос «Создание сайтов». Вам необходимо оценить количество коммерческих запросов и их частотность для понимания целесообразности продвижения в данной тематике.
Для этого соберите список всех минус-фраз, либо найдите в интернете (существует множество готовых списков почти под любую тематику) и введите их все по данной конструкции: создание сайтов -бесплатно -самостоятельно -обучение -курсы и так далее.
Группировка запросов с использованием различных операторов
Пример конструкции:
В данному случае, мы сгруппировали фразы «seo, сео, поисковое, поисковая система, поисковик, яндекс, google» с фразами «продвижение, раскрутка, оптимизация» и убрали ключевые слова с вхождениями «бесплатно, самостоятельно, самому, инструкция».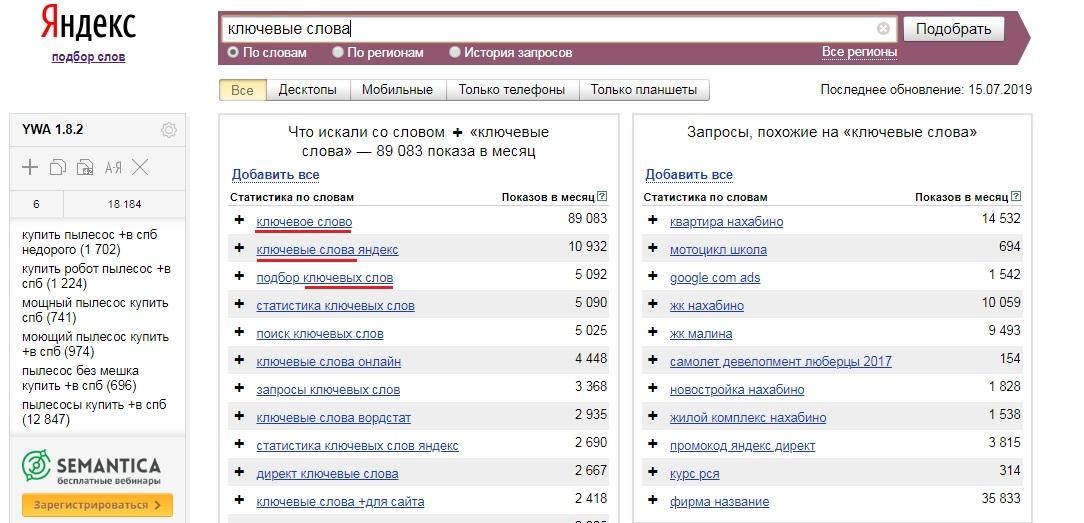
Как автоматизировать работу со статистикой Вордстат?
Сбор семантического ядра через Вордстат для крупного ресурса или интернет-магазина – очень трудоемкий процесс. Его можно автоматизировать с помощью дополнительного программного обеспечения, сильно сэкономив свое время. Существует большое количество различного ПО для подбора, расширения семантики, анализа видимости конкурентов. Ниже перечислим самые основные и популярные.
1. Yandex Wordstat Helper – бесплатное расширение для браузера Chrome, с помощью которого вы сможете добавлять выбранные запросы в отдельное поле (нажатием на «+»), а потом копировать вместе с частотами одним нажатием кнопки.
Скачать его можно здесь
2. KeyCollector — инструмент для автоматического парсинга статистики с Wordstat. Использование КейКоллектор исключает необходимость ручного сбора и копирования. Для формирования полного семантического ядра вам понадобится только список базовых запросов:
- вносите их в инструмент;
- выбираете регион сбора статистики;
-
запускаете процесс.
Программе понадобится от нескольких часов до нескольких дней, в зависимости от количества ключевых слов в вашей тематике. После окончания сбора ядра необходимо произвести чистку от ненужных фраз и кластеризацию. Но это уже тема для отдельной статьи.
2. Just Magic – содержит модуль парсинга статистики из левой колонки Wordstat с функцией поддержки всех операторов.
3. Букварикс – готовая онлайн база ключевых слов. Для моментальной выгрузки достаточно ввести базовые запросы и инструмент предоставит полный список необходимых вам фраз.
4. SpyWords – позволяет выгрузить видимость сайта конкурента в Яндекс и Google, определив по каким запросам его находят в поиске.
Итог
Надеемся, наша инструкция по Яндекс Вордстат помогла вам разобраться с сервисом. В этой статье мы рассказали о функциях и возможностях программы, а также упомянули инструменты, помогающие упростить и автоматизировать работу.
Еще мы помогаем с продвижением сайтов. Делаем полный анализ тематики вашей деятельности, составляем стратегию, оптимизируем ресурс для выхода в ТОП поисковых систем. Заполните форму ниже, мы вам перезвоним и проконсультируем.
статистика поисковых запросов Яндекса и Google, Wordstat Yandex
Статистика запросов — это база данных, которая содержит в себе информацию об обращениях пользователей к поисковой системе по «ключевым фразам». При работе с подобными системами статистики можно группировать результаты по географическрму положению или даже по отдельно взятому языку, а иногда и по месяцам. В большинстве случаев сервисы показывают информацию не только об искомой фразе, но и о словосочетаниях и синонимах.
Системы статистики поисковых запросов есть у многих крупных поисковых систем, так, к примеру, у Яндекса — Wordstat, у Google – Trends. Основная цель подобных баз данных – это предоставление информации для заинтересованной в контекстной рекламе целевой аудитории. Если вы используете перечисленные инструменты для составления семантического ядра, то надо учитывать, что подобные системы показывают число показов результатов поисковой выдачи, но никак не количество переходов по запросам.
Если вы используете перечисленные инструменты для составления семантического ядра, то надо учитывать, что подобные системы показывают число показов результатов поисковой выдачи, но никак не количество переходов по запросам.
Статистика поисковых запросов Яндекса
Wordstat (Вордстат) – это база данных с информацией о количестве показов результатов выдачи в поиске Яндекса. Особенностью системы является то, что она склеивает всевозможные словоформы, при этом чаще всего не учитывая предлоги и иные формы слова.
Статистику поисковых запросов Яндекса стоит использовать ещё и потому, что она приводит не только производные от введенных ключевых слов, но и ассоциативные запросы, которые пользователи искали вместе с интересующими вас запросами. Такой функционал способствует существенному расширению семантического ядра (колонка справа — «Запросы, похожие на…»).
Вкладка «По словам» содержит общую информацию о числе показов конкретных поисковых фраз. Используя же вкладку «по регионам», вы всегда сможете определить частность этой ключевой фразы в том или ином регионе поиска.
Используя же вкладку «по регионам», вы всегда сможете определить частность этой ключевой фразы в том или ином регионе поиска.
Для того чтобы отследить частоту спроса по интересующему запросу за определенный период, можно использовать вкладки с группировкой данных «по месяцам» и «по неделям». Особенно эта информация будет актуальна для сезонных запросов.
При учете всех возможностей, которые предоставляет статистика ключевых слов, и грамотном использовании предоставляемых ею инструментов, сервис становится важнейшей составляющей, которую используют большинство вебмастеров и SEO-специалистов при составлении семантического ядра для сайта.
«Яндекс» описал 2020 год в запросах пользователей :: Общество :: РБК
В марте люди искали также информацию о падении курса рубля и цен на нефть.
В апреле пользователи «Яндекса» интересовались новостями про дело против Олега Тинькова, слухами о смерти Ким Чен Ына и скандалом, разгоревшимся из-за высказывания телеведущей Регины Тодоренко о домашнем насилии.
Читайте на РБК Pro
К началу мая актуальными стали данные о готовящихся выборах в Белоруссии и по-прежнему чаще всего искали информацию о пандемии коронавирусной инфекции. На некоторое время заинтересовал аудиторию поисковика и скандал из-за недвижимости Елены Малышевой. К концу месяца чаще стали искать информацию о движении Black Lives Matters в США, данные о готовящихся изменениях Конституции России, а также информацию о введении электронных медицинских карт в столице.
В июне на второе место по популярности после COVID-19 ненадолго вышло резонансное ДТП с участием Михаила Ефремова, затем этот инфоповод уступил место приближающемуся голосованию о поправках в Конституцию. Среди светских новостей россиян больше всего интересовал развод Кристины Асмус и Гарика Харламова, этот запрос на некоторое время вышел в топ-3 тем по популярности. Искали обитатели Рунета также сообщения о вспышке бубонной чумы в Монголии и параде планет, который прошел 4 июля.
Июль прошел под знаком дела против бывшего губернатора Хабаровского края Сергея Фургала, слухов о деноминации рубля, обострения конфликта в Нагорном Карабахе и смерти рэпера Энди Картрайта.
Начало августа в информационной картине «Яндекса» определили запросы о взрыве в Бейруте, который унес жизни почти 200 человек, затем почти сразу на первое место по числу запросов вышли выборы и последовавшие за эти масштабные протесты в Белоруссии. Интерес к эпидемии коронавирусной инфекции в этот же месяц несколько снизился. Новой темой, интересовавшей россиян, стали экологические протесты в Башкирии, где прошли демонстрации против уничтожения горы Куштау. Конец августа отмечен всплеском интереса к отравлению оппозиционного политика Алексея Навального, которому стало плохо в самолете по пути из Томска в Москву.
Новой темой, интересовавшей россиян, стали экологические протесты в Башкирии, где прошли демонстрации против уничтожения горы Куштау. Конец августа отмечен всплеском интереса к отравлению оппозиционного политика Алексея Навального, которому стало плохо в самолете по пути из Томска в Москву.
К концу месяца пандемия вновь вышла на первое место в списке интересовавших россиян тем.
В сентябре в «Яндексе» также искали информацию о едином дне голосования и вновь — о ДТП с участием Ефремова, которому вынесли приговор. Из светских новостей россияне заинтересовались отношениями Тарзана и Анастасии Шульженко. В конце сентября вновь разгорелся конфликт в Нагорном Карабахе и число запросов о нем резко возросло. Искали люди также данные о самосожжении журналистки Ирины Славиной и новости о пропавшем во Владимирской области семилетнем мальчике. Мальчика нашли в ноябре, и это также отразилось в «Яндексе».
В октябре больше всего аудиторию интересовали коронавирус и конфликт в Нагорном Карабахе, возрос интерес к приближающимся выборам в США. Кроме того, суд в Москве вынес приговор по делу 72-летней актрисы Натальи Дрожжиной и ее супруга Михаила Цивина, обвиняемых по делу о мошенничестве с недвижимостью и банковскими счетами покойного народного артиста Алексея Баталова, и это отразилось на поисковых запросах.
Кроме того, суд в Москве вынес приговор по делу 72-летней актрисы Натальи Дрожжиной и ее супруга Михаила Цивина, обвиняемых по делу о мошенничестве с недвижимостью и банковскими счетами покойного народного артиста Алексея Баталова, и это отразилось на поисковых запросах.
Темами ноября стали выборы президента США, скандал с футболистом Артемом Дзюбой, чье приватное видео утекло в интернет, а также конфликт между бойцами Сергем Харитоновым и Адамом Яндиевым.
В декабре информационная картина изменилась мало: пандемия по-прежнему интересует россиян больше всего, люди все еще ищут информацию о конфликте в Нагорном Карабахе и выборах президента США, а также о деле Михаила Ефремова и протестах в Белоруссии и Хабаровске.
Поисковая система — глоссарий КСК ГРУПП
Сегодня каждый профессиональный оптимизатор при работе использует анализ поисковых запросов, чтобы свой продукт сделать наиболее привлекательным и успешным.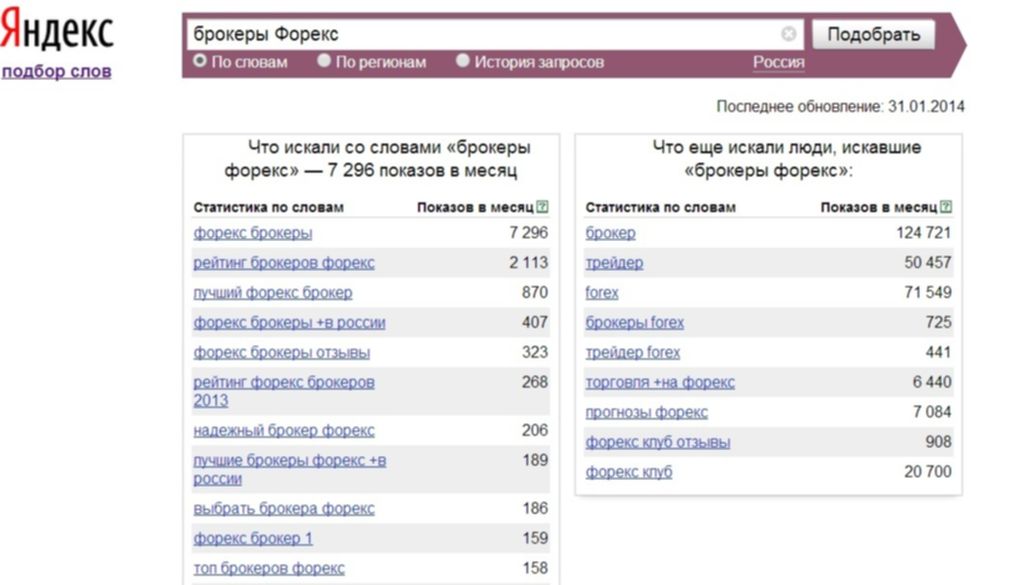 Именно благодаря изучению статистических данных можно понять, что современные пользователи ищут в Интернете. Благодаря этим знаниям составляется семантическое ядро ресурса. Если такого ядра нет, а это чаще бывает при работе с форумами, то статистику все же не стоит игнорировать. Ее также используют для оптимизации сайта под определенный ключевик. Чаще всего для таких целей используется анализ поисковиков Яндекс.Вордстат (wordstat.yandex.ru).
Именно благодаря изучению статистических данных можно понять, что современные пользователи ищут в Интернете. Благодаря этим знаниям составляется семантическое ядро ресурса. Если такого ядра нет, а это чаще бывает при работе с форумами, то статистику все же не стоит игнорировать. Ее также используют для оптимизации сайта под определенный ключевик. Чаще всего для таких целей используется анализ поисковиков Яндекс.Вордстат (wordstat.yandex.ru).
Особенности анализа Яндекс
Яндекс.Вордстат — прекрасный инструмент, который позволяет получить доскональную информацию о предполагаемом ключевике. Здесь будут объединены не только точные данные, но и словоформы. Стоит отметить, что при поиске вариантов не учитываются предлоги. Если ввести в Яндекс.Вордстат простой ключ, то инструмент выдаст все возможные варианты, где встречается это слово в единичном варианте, словоформы и варианты словосочетаний.
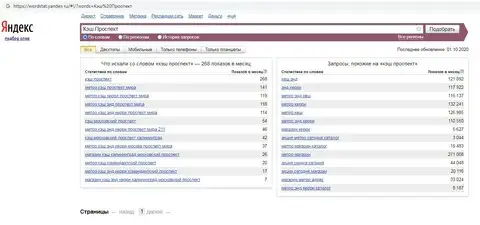
Например, если рассмотреть фразу «статистика запросов», то результатом станет значение 31 535, здесь будут включены не только формы слова, но и словосочетания, например: «статистика запросов поисковика», «статистика запросов Яндекс» и многие другие.
Если нужно достичь конкретных результатов именно по конкретной фразе, то следует поступить немного по-другому. Для этого есть специальные операторы. Наиболее распространенным являются кавычки «». Если в них заключить словосочетание, то результат инструмента будет приблизительно 4764. В таком случае учитывается исключительно только ключ и его формы, например: статистика запросов, статистикой запросов и так далее.
Если использовать еще и восклицательные знаки, то результат будет выдан по ключу в указанной форме. Если набрать «!статистика !запросов», то результат будет, например, 4707. Таким образом, известно конкретное количество запросов с ключевым словом. Стоит быть внимательным, восклицательный знак ставится перед каждым словом.
Если использовать знак минуса, то можно исключить из введенного запроса конкретное слово, а если поставить знак +, то статистика будет обязана при поиске ключевых слов учитывать даже предлоги.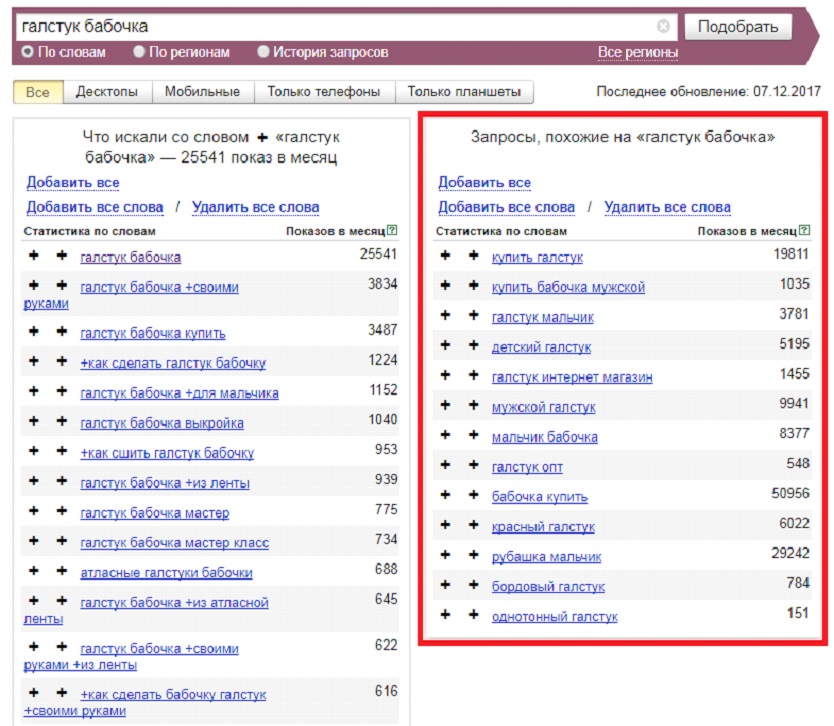 Такие операторы используют, если необходимо под одним запросом объединить несколько ключевиков.
Такие операторы используют, если необходимо под одним запросом объединить несколько ключевиков.
Получается, что при использовании операторов в различных комбинациях можно существенно сократить время получения статистики.
А также при анализе статистики инструментов Яндекс проводится анализ не только словоформ и словосочетаний, но также и ассоциативных запросов, которые используются вместе с основными ключевыми запросами. Такие расширенные возможности помогают более успешно заниматься разработкой и созданием семантического ядра.
Инструмент содержит несколько вкладок:
- «что искали люди, искавшие…» — показывает запросы, которые искали пользователи, которые вводили интересующий ключевой запрос;
- «по словам» — помогает определить количество конкретных ключей;
- «на карте» — это вкладка отобразит количество введенных запросов на карте мира, что очень удобно для анализа статистики ключевиков для конкретного региона;
- вкладки «по неделям», «за месяц» — удобная возможность для рассмотрения ключевых фраз в определенный сезон, так как они показывают их число за точный период.
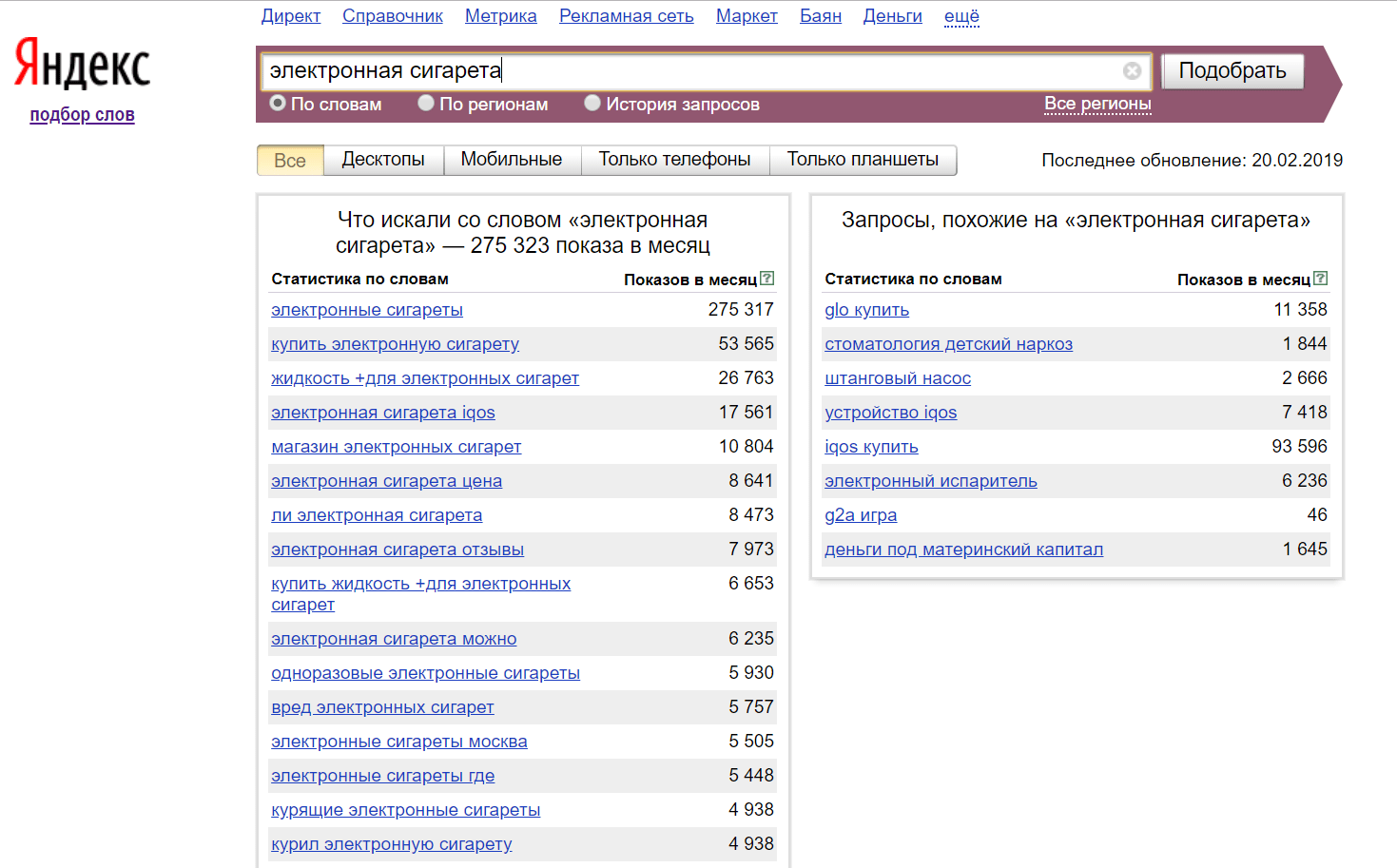
В заключение о разговоре про статистику Яндекса следует отметить основные особенности инструмента Яндекс.Вордстат.
- При работе стоит помнить, что статистика Яндекса показывает не количество людей, которые ищут подобную информацию, а именно число запросов.
- При работе с Яндекс.Вордстат проводится анализ вводимых данных на протяжении последних 30 дней. При проведении анализа это следует учитывать, так как многие запросы могут быть сезонными и в другое время не иметь такой большой актуальности.
- Цифра, отображенная в верхней части, отображает общее количество запросов. Здесь и сами ключи, их словоформы и словосочетания. Если нужно получить более подробную информацию, необходимо использовать различные операторы.
Таким образом, при правильном и грамотном использовании Яндекс.Вордстат станет прекрасным помощником при необходимости проведения анализа популярности ключевых слов.
Анализ статистики запросов с использованием Google
Для проведения анализа ключей в Google можно использовать два способа.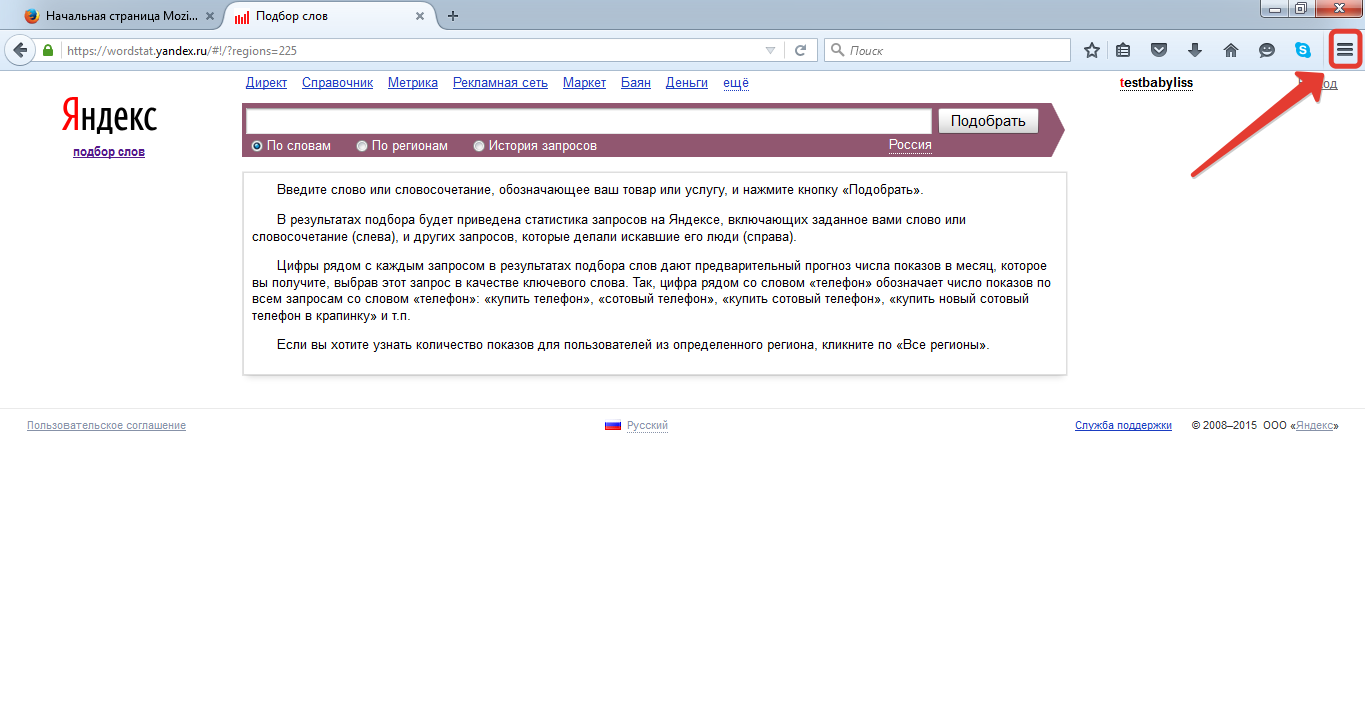 Статистику Google для выбора ключевых слов чаще всего используют как дополнительный инструмент при составлении семантического ядра. Причем механизм сам определяет местоположение и язык, которые будут использоваться при анализе. С помощью этого сервиса оптимизатор с легкостью составит набор стартовых ключевых слов.
Статистику Google для выбора ключевых слов чаще всего используют как дополнительный инструмент при составлении семантического ядра. Причем механизм сам определяет местоположение и язык, которые будут использоваться при анализе. С помощью этого сервиса оптимизатор с легкостью составит набор стартовых ключевых слов.
Статистику поиска Google лучше использовать для определения популярности и распространенности конкретных ключей. А также благодаря этому инструменту можно получить подробные графики, где отображены изменения популярности введенных слов.
Анализ статистики в Рамблере
Поисковая система Рамблер не пользуется такой популярностью, как другие поисковые системы, соответственно, и анализ ключевых слов также не слишком востребован. Провести точный анализ здесь получится только при точном вводе, чем Рамблер и отличается от других поисковых систем. Здесь не будет объединения всех словоформ и словосочетаний, как в Яндексе. При использовании статистики Рамблера получается получить анализ точных значений в конкретных формах и падежах.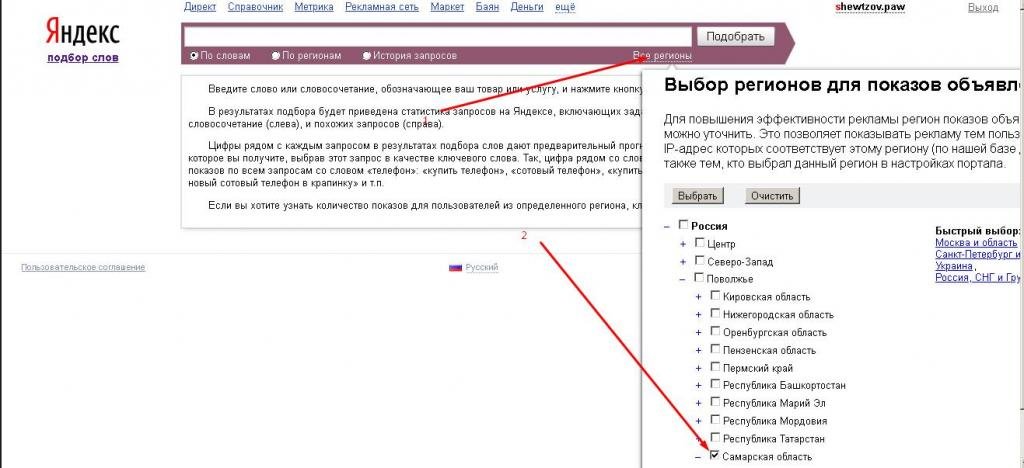
Конкурентоспособность и частность поисковых запросов
Начинающий оптимизатор, который хочет с самого начала свою работу сделать успешной, должен понимать, что все свои запросы необходимо разделять на несколько групп и анализировать каждую в отдельности.
- Высокочастотные запросы — ВЧ.
- Среднечастотные варианты — СЧ.
- Низкочастотные запросы — НЧ.
Также существует еще одна классификация, которая будет полезна при работе.
- Низкоконкурентные — НК.
- Среднеконкурентные — СК.
- Высококонкурентные — ВК.
Естественно, наилучшим вариантом станет запрос, который можно отнести одновременно к высокочастотным и низко- или среднечастотным запросам. Но в реальности такое можно встретить очень редко. Чаще всего запрос с низкой частотой бывает высококонкурентным.
И также стоит понимать, что такие понятия не несут в себе конкретного числового значения, ведь для определенной темы цифры могут существенно отличаться.
При продвижении сайта в современном мире стоит учитывать не только тематику сайта, но и конкретную ситуацию на рынке. Поэтому, предлагая свой сайт, следует учитывать интересы потребителей. Ведь важно, чтобы пользователь, посетивший сайт один раз, захотел снова вернуться и воспользоваться предложенной информацией.
Возврат к списку
Поисковые запросы яндекс. Подбор в Вебмастере
Обзор сервиса «Рекомендованные поисковые запросы» Вебмастер Яндекса. Раздела «поисковые запросы»
Вторая часть.
Первая часть: (Статистика запросов, Статистика страниц, Управление группами и Тренды)
Яндекс предоставил достаточно неплохой сервис, который можно использовать для подбора актуальных запросов при продвижении настройке контекстной рекламы интернет-магазина. Запросы собираются на основе анализа в Яндекс Директе. Расчет данных используют статистику вордстат (wordstat).
Для чего нужен раздел? — помочь маркетологу наиболее эффективно настроить и корректировать контекстную рекламу. В seo-продвижении используется в качестве подсказок, списка страниц с которыми нужно работать. В разделе можно получить список поисковых запросов, которые с большей вероятностью приведут трафик из Яндекса.
В seo-продвижении используется в качестве подсказок, списка страниц с которыми нужно работать. В разделе можно получить список поисковых запросов, которые с большей вероятностью приведут трафик из Яндекса.
В отличии от вордстата — в котором результат это совокупности значений, рекомендованные запросы имеют прямое отношение к сайту интернет-магазина.
Список учитывает статистику за 28 (30) дней, в отличии от «Управления группами» которые приводят данные за 7 дней.
Раздел больше предназначен для Директа, помогает оценить основные показатели: просмотры, прогноз цены.
Яндекс «подсказывает» наиболее интересные запросы с его точки зрения. Список можно импортировать в эксель. Работает фильтрация по регионам, содержимому запроса — важно при локальном SEO
Получить запросы для сайта
По умолчанию список отсутствует, его нужно запросить. Список будет добавлен после автоматической обработки через 3-6 дней.
Полученные рекомендательные запросы можно условно разделить на 2 группы:
Нет показов
Есть показы
Группа Нет показов
Слова и словосочетания по которым получено мало данных за 30 дней. А также не точные запросы которые не были полностью учтены. В таком случае в графе «Текущая позиция» будет стоять «0».
А также не точные запросы которые не были полностью учтены. В таком случае в графе «Текущая позиция» будет стоять «0».0 — минимальный интерес к странице (по различным причинам). При оптимизации интернет-магазина страницы с низкими показателями учитываются в последнюю очередь. Оптимизация начинается со страниц лидеров.
В текущем примереРегион «Москва»
Запрос «что такое программа лояльности«, за 28 дней при общем объеме показов 8357 — имеет 0 в текущих позициях.
Но если проверить ключ «Лояльность» на показы за 7 дней в «управлениях группой» получим список обращений по которым были показы сайта и позиции в поиске Яндекса. Расхождения обусловлены не полными данными и разным принципом обработки.
Если в группе находятся конверсионные и коммерческие запросы, по которым высокий прогноз показов, но не приносят трафик — необходимо улучшить релевантные страницы сайта. Найти причину для роста.
 Верхние строчки в отчете приставляют наибольший интерес для seo-продвижения.
Верхние строчки в отчете приставляют наибольший интерес для seo-продвижения.
Причин по которым станица имеет много показов но низкую низкую позицию «0» очень много:
— Техническая сторона сайта.
— Сложность контента, не уникальность.
— Сезонные колебания.
— Отсутствие описания страницы, заголовков, и т.д.
Какие использовать данные в seo-продвижении
Группа Есть показы
Основной список с которым нужно работать. Расчет сделан для Контекстной рекламы.Для SEO-продвижения это очень важные данные. Помогут получить наиболее приближенные запросы по сайту.
Используя систему фильтров и сортировок можно получить листинг поисковых фраз и релевантных страниц. Отбираем наиболее интересные фразы и страницы сайта из верхних позиций.
Приоритет: повышенный интерес к верхней части списка, запросы с нижних страниц — менее интересные, менее популярны и хуже оптимизированы. Необходимо сосредоточиться на самых популярных и конверсионным странницах.Приступая к оптимизации страницы необходимо понимать, что нужно улучшить, изменить. Проанализировать страницы сайтов конкурентов. Определить, что может способствовать росту показателей.
 Эти страницы ранжируются выше и быстрее приведут трафик.
Эти страницы ранжируются выше и быстрее приведут трафик.
Полученные данные можно использовать для расширения семантического ядра: описания товаров, дополнительной информации. Анализируя страницы по тематическим запросам можно подготовить более развернутый текст. Необязательно писать много — текст должен содержать подробную и актуальную информацию.
Сервис не является аналогом по планированию ключевых слов. Его работа построена на прогнозе CTR. Используя обобщенные данные вордстата, метрики, средней позиции, тренды и другие источники мы видим обобщенную картину состояния сайта.
Доступность информации, возможность ручной проверки, поможет разобраться в основах SEO даже новичку. Помогает выбрать наиболее популярные страницы для продвижения, сконцентрироваться на главном.
С его помощью можно найти проблемы в оптимизации сайта интернет-магазина, позволяет выявить проблемные и перспективные направления.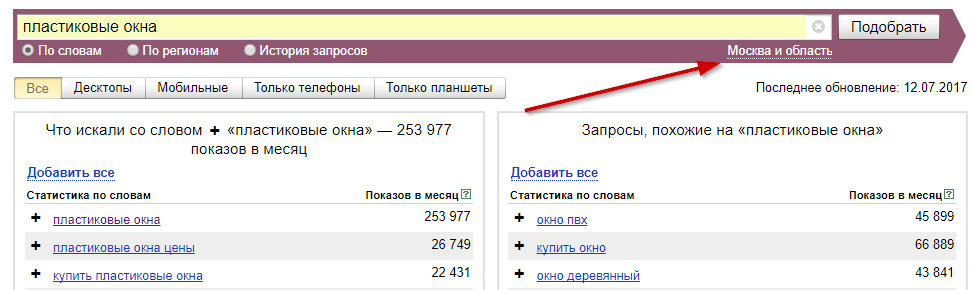
Недостатки и особенности
К недостаткам можно отнести неудобство в кластеризации запросов. Довольно рутинный процесс требующей затрат времени.Много шумовых запросов которые необходимо исключать.
Ограниченность глубины анализа — 51 позиция.
Отсутствует динамика популярности поисковой фразы.
Желательно использовать в сочетании с другими SEO программами: Серпстатом, Букварисом, Google вебмастер, Мегаиндекс и т.д. Тогда картина будет более полная.
Получите количество выпусков. Описание API
Используйте этот запрос, чтобы узнать, сколько проблем соответствует критериям в вашем запросе.
Чтобы получить количество проблем, соответствующих определенным критериям, используйте запрос HTTP POST . Критерии поиска передаются в теле запроса в формате JSON:
POST / v2 / issues / _count?
Хост: https://api. tracker.yandex.net
Авторизация: OAuth <токен OAuth>
X-Org-Id: <идентификатор организации>
{
"": {
"<имя поля>": "<значение поля>"
}
"": "фильтр запроса"
}  tracker.yandex.net
Авторизация: OAuth <токен OAuth>
X-Org-Id: <идентификатор организации>
{
"": {
"<имя поля>": "<значение поля>"
}
"": "фильтр запроса"
}
tracker.yandex.net
Авторизация: OAuth <токен OAuth>
X-Org-Id: <идентификатор организации>
{
"": {
"<имя поля>": "<значение поля>"
}
"": "фильтр запроса"
} - Параметры, переданные в теле запроса
| Параметр | Описание | Формат |
|---|---|---|
фильтр | Параметры для проблем фильтрации.Параметр может указывать любое поле и значение для фильтрации. | Объект |
запрос | Фильтр, использующий язык запросов. | Строка |
Запрос количества задач с дополнительными параметрами фильтрации:
Используется метод HTTP POST.
Ответ должен содержать только количество задач из очереди «ИЮНЬ», у которых нет правопреемника.
POST / v2 / issues / _count HTTP / 1.1
Хост: https://api.tracker.yandex.net
Авторизация: OAuth <токен OAuth>
X-Org-Id: <идентификатор организации>
Cache-Control: без кеширования
{
"filter": {
"очередь": "ИЮНЬ",
"правопреемник": "пустой ()"
}
} ' Ответ содержит количество проблем, соответствующих критериям вашего запроса.
5221186 - 200
- Запрос был успешным.
Places API
Places API — это HTTP API, который позволяет находить организации по названию, адресу, номеру телефона и другим критериям.
Тарифный план определяет лимит запросов к услуге.
Внимание. Обратите внимание, что лицензия на продукт приобретается сроком на один год. Вы не можете произвести оплату на более короткий срок. Также невозможна предоплата — вы можете начать пользоваться API только после полной оплаты.
Также невозможна предоплата — вы можете начать пользоваться API только после полной оплаты.
Доступные тарифные планы перечислены ниже:
| Лимиты запросов в день | Цена в год | Цена за каждую тысячу запросов сверх лимита |
|---|---|---|
1000 запросов | 120 000 руб. | 120 руб. |
10 000 запросов | 360 000 руб. | 36 руб. |
25 000 запросов | 600 000 руб. | |
50000 запросов | 850 000 рублей | 17 рублей |
100 000 запросов | 1000000 рублей | 11 рублей |
Более 100 000 запросов | Для расчета затрат отправьте запрос на адрес pay-api-maps @ yandex-team.ru и сообщите нам, сколько запросов в день вы ожидаете. | |
Примечание. Опубликованные условия не являются офертой.
Чтобы использовать коммерческую версию API:
- Приобретите лицензию. Подробности
Для доступа к API используйте ссылку:
https://search-maps.yandex.ru/v1/?apikey=& <дополнительные параметры>
 Подробности
ПодробностиФормат запроса . Places API
Доступ к сервису осуществляется с помощью GET-запроса по адресу https: // search-maps.yandex.ru/v1/. Обязательными параметрами запроса являются текст, язык и apikey.
В ответ сервер возвращает найденные объекты, отсортированные по релевантности запросу. За один поисковый запрос можно получить до 500 объектов.
https://search-maps.yandex.ru/v1/
? [= <ключ>]
& [= <поисковый запрос>]
& [= <типы объектов>]
& [= <язык ответа>]
& [= <центр области поиска>]
& [= <размер области поиска>]
& [= <координаты области поиска>]
& [= <не искать за пределами области поиска>]
& [= <количество результатов в ответе>]
& [= <количество результатов, которые нужно пропустить>]
& [= <название функции>] | Параметры запроса | |
apikey | Ключ для доступа к сервису. Вы можете получать ключи и управлять ими в Личном кабинете разработчика. Вы можете получать ключи и управлять ими в Личном кабинете разработчика. |
текст | Текст поискового запроса. Например, название географического объекта, адрес, координаты, название компании или номер телефона. Примеры (без кодировки URL): |
тип | Типы возвращаемых результатов. Возможные значения: Пример: |
lang | Предпочтительный язык ответа. Установите в качестве идентификатора локали формат Установите в качестве идентификатора локали формат lang = language_region , где
Поддерживаемые значения: Если параметр имеет значение локали, которого нет в этом списке, служба выбирает язык, наиболее близкий к заданному. Пример: |
ll | Центр области поиска. Определяется долготой и широтой, разделенными запятой. Долгота и широта указываются в градусах, представленных десятичными знаками. Используется вместе с параметром spn, который определяет размер области поиска. Игнорируется при обратном геокодировании. Пример: |
spn | Размер области поиска. Определяется с использованием диапазона долготы и широты, разделенных запятой. Пролеты указываются в градусах, представленных десятичными знаками. Используется вместе с параметром ll, который определяет центр области поиска. Игнорируется при обратном геокодировании. Пример: |
bbox | Альтернативный метод настройки области поиска (см. Границы области поиска определяются как географические координаты левого нижнего и правого верхнего углов области (в порядке «долгота, широта»). Примечание. Если одновременно установлены Пример: |
rspn | Указывает на «строгое» ограничение области поиска. Если ничего не найдено в области поиска (задается с помощью параметров ll + spn или bbox), служба пытается найти результаты за ее пределами. Возможные значения: |
результатов | Количество возвращаемых объектов. По умолчанию 10. Максимальное значение — 500. Пример: |
пропустить | Число объектов, которые нужно пропустить в ответе (начиная с первого). Пример: |
обратный вызов | Имя функции JavaScript, которой необходимо передать ответ (по соглашению JSONP). Пример: |
 618920,55.756994 & spn = 0.552069,0.400552
618920,55.756994 & spn = 0.552069,0.400552  Вы можете использовать параметр
Вы можете использовать параметр | 200 | OK | |
| 403 | INVALID_USER_ID | Идентификатор пользователя, выпустившего токен, отличается от указанного в запросе.В приведенных ниже примерах |
| 404 | HOST_NOT_VERIFIED | Права на управление сайтом не проверены. |
| HOST_NOT_INDEXED | Файл Sitemap отсутствует. | |
| HOST_NOT_LOADED | Данные сайта еще не загружены в Яндекс.Вебмастер. |
 Руководство разработчика
Руководство разработчика Следует использовать {user_id}.
Следует использовать {user_id}.
 "": "http: ya.ru: 80", // id хоста. идентификатор хоста.
"": "какая-то строка" // Сообщение об ошибке.}
"": "http: ya.ru: 80", // id хоста. идентификатор хоста.
"": "какая-то строка" // Сообщение об ошибке.} как отправить запрос.
Яндекс.Директ API. Версия 5В этом уроке вы узнаете:
- Как отправить запрос на доступ
- Как узнать результат рассмотрения вашего запроса
- Сроки рассмотрения запроса
- Что дальше
- Полезные ссылки
- Вопросы
В этом уроке мы обсудим второй шаг, который позволит вашему приложению получить доступ к Яндекс.Direct API: отправка запроса.
После регистрации вашего приложения в Яндекс.OAuth вам необходимо отправить запрос на доступ к API Яндекс.Директа. Для выполнения запросов API требуется одобренный запрос. Получив ваш запрос, мы добавим ваше приложение в реестр приложений, обращающихся к Яндекс.Директу, и свяжемся с вами как с его разработчиком, чтобы уведомить вас о важных новостях, попросить настроить работу вашего приложения и т. Д.
Их два виды Яндекс.Прямой доступ к API:
Пробный доступ ограничен API Яндекс.Директа; он позволяет запускать ваше приложение в тестовой среде (песочнице), изолированной от реальных пользовательских данных.
Полный доступ к API Яндекс.Директа; это позволяет вашему приложению работать как в тестовой среде, так и управлять реальными рекламными кампаниями.

Поскольку вы учитесь работать с API Яндекс.Директа, запросите пробный доступ к вашему приложению.Вы можете сделать запрос, даже если вы еще не создали свое приложение. Вы можете преобразовать этот запрос в запрос полного доступа в любое время позже.
Внимание.Только разработчик может подать заявку на доступ к приложению (а также зарегистрировать приложение в Яндекс.OAuth).
Пользователям вашего приложения это не нужно.
Создайте по одному запросу для каждого приложения, зарегистрированного на Яндекс.OAuth: один идентификатор приложения — один запрос на доступ. После утверждения запроса любое количество пользователей может запустить приложение.
Авторизуйтесь на Яндексе под своим логином разработчика, то есть с тем логином, который вы использовали для регистрации своего приложения в Яндекс.
OAuth.- В веб-интерфейсе Яндекс.Директа перейдите в раздел API, чтобы увидеть настройки доступа к API.
При первом посещении этого раздела примите пользовательское соглашение.
- Перейдите на вкладку Мои запросы.
Нажмите кнопку «Новый запрос». В открывшемся меню выберите тип запроса «Пробный доступ».
- В форме создания запроса:
- Выберите из списка идентификатор приложения, полученный при регистрации в Яндекс.OAuth на предыдущем уроке.
Введите адрес электронной почты, который вы используете в настоящее время. Мы будем использовать его, чтобы связаться с вами в случае необходимости.
Введите данные своего приложения в другие поля.
Подтвердите соблюдение вами условий пользовательского соглашения разработчика.
Нажмите кнопку «Отправить».
- Выберите из списка идентификатор приложения, полученный при регистрации в Яндекс.OAuth на предыдущем уроке.
 OAuth.
OAuth. Посмотреть свои запросы вы можете в веб-интерфейсе Яндекс.Директа: перейдите в раздел API, вкладку Мои запросы. Во вкладке вы можете:
Во вкладке вы можете:
отслеживать статус рассмотрения вашего запроса; если он отклонен, вы можете увидеть причины здесь
запросов на добавление, редактирование и удаление.
Запросы на доступ рассматриваются с 10 до 19 часов. в рабочие дни (кроме праздников в России). Рассмотрение запроса может занять от одного часа до трех рабочих дней (в периоды пиковой нагрузки это может занять до семи дней).
Итак, вы создали заявку на доступ к API Яндекс.Директа. На следующем уроке вы узнаете, как получить токен OAuth, а затем создать и настроить песочницу. Вы можете продолжить этот курс, не дожидаясь завершения рассмотрения вашего запроса: одобренный запрос вам понадобится только позже, когда вы начнете делать запросы API.
- Какие существуют типы доступа к API Яндекс.Директа?
- Кому следует подавать заявку на доступ к приложению в Яндекс.Прямой API?
- Сколько запросов лучше отправить на одно приложение?
Технологии Яндекс.
Такси-графиков: идеальный поиск без маршрутизации API-запросов | от Яндекс.Такси: Под капотомАртем Бондаренко и Сергей Воронцов, Яндекс.Такси Торговая площадка Эффективность
Когда вы заказываете поездку, ваша служба каршеринга постарается найти водителя, который сможет добраться до вас быстрее всех, чтобы вы тратят меньше времени на ожидание, и они тратят меньше времени на бесплатную поездку.Как правило, служба совместного использования автомобилей использует API маршрутизации, предоставляемый Google Maps и т. Д., Чтобы проверить ожидаемое время прибытия, сравнить их и выбрать лучший автомобиль для вас. Но этот простой поиск является очень дорогостоящим и неэффективным при масштабировании. В Яндекс.Такси нашли изящное решение этой проблемы. Наш новый алгоритм на основе графов каждый раз находит самый быстрый автомобиль, устраняя при этом дорогостоящие вызовы API.
Пятнадцать лет назад, когда мы еще жили в мире без агрегаторов такси, время посадки могло достигать получаса и более. Диспетчеры вручную выбирали ближайший автомобиль из относительно небольшого пула. С появлением агрегаторов количество доступных автомобилей резко возросло, а поиск ближайших водителей был автоматизирован. Но сегодня эффективность этого процесса оставляет желать лучшего.
Диспетчеры вручную выбирали ближайший автомобиль из относительно небольшого пула. С появлением агрегаторов количество доступных автомобилей резко возросло, а поиск ближайших водителей был автоматизирован. Но сегодня эффективность этого процесса оставляет желать лучшего.
Когда дело касается крупных игроков рынка, этот процесс необходимо оптимизировать вместе с необходимыми вычислительными ресурсами. Это как раз та задача, которую мы любим решать в Яндекс.Такси. В этом посте мы расскажем, как мы разработали алгоритм, который элегантно решает эту проблему.
Начнем со «старого» прямого подхода.
В реальном мире автомобили передвигаются по дорогам. Но в электронном мире агрегаторы знают только свои координаты на плоскости. Они не имеют ни малейшего представления о том, на какой улице движется транспортное средство и по какой дороге следует подобрать водителя. Легко понять, почему знание дорожной сети и трафика имеет решающее значение для определения того, какой автомобиль доберется до места быстрее всего.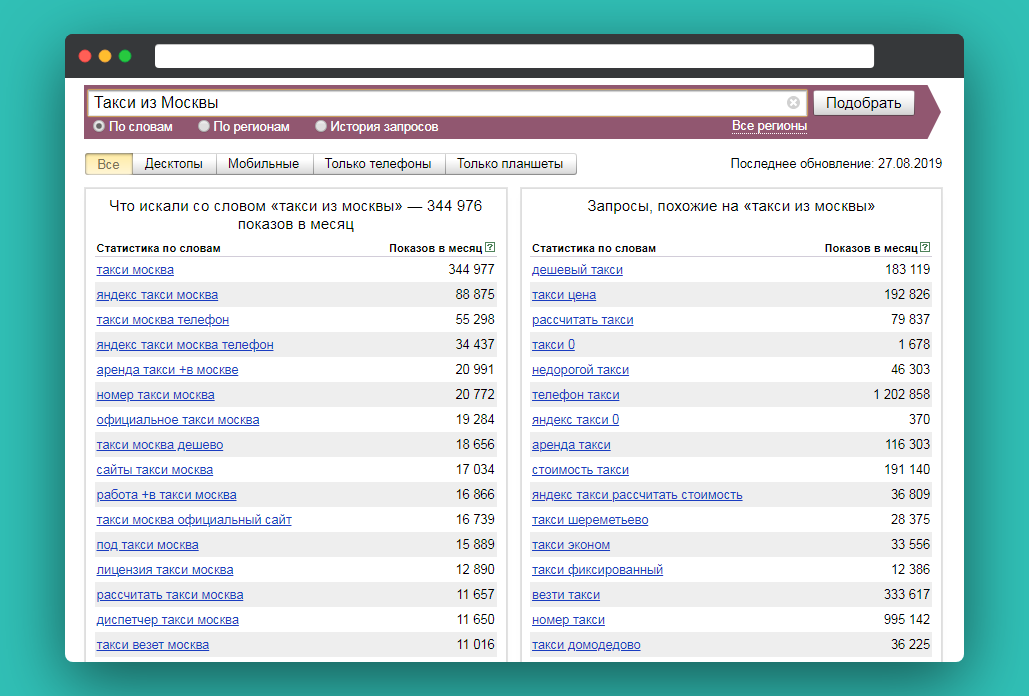 Здесь на помощь приходят сервисы маршрутизации.
Здесь на помощь приходят сервисы маршрутизации.
Приложения для совместного использования позволяют рассчитать время прибытия в пункт отправления для каждой доступной машины.Традиционно они используют службу маршрутизации для нанесения на карту маршрутов для каждого транспортного средства на основе текущего трафика.
Но вот в чем проблема: запросы на маршрутизацию стоят денег. Невозможно каждый раз спрашивать у маршрутной службы о каждой машине в городе, не обанкротившись. Предположим, есть город с 100 000 запросов в день и 1 000 доступных автомобилей в любой момент времени. Оценка времени прибытия каждой машины в город может стоить десятки или даже сотни тысяч долларов в день, что непомерно дорого.
Для нашего метода мы использовали сервисы маршрутизации нашей материнской компании, предоставляемые Яндекс-картами. Наличие собственной службы маршрутизации — огромное преимущество, но каждый дополнительный запрос маршрутизации по-прежнему не был бесплатным, поскольку увеличивал нагрузку на наш сервер.
Значит, по-прежнему нужно было как-то ограничивать количество проверяемых автомобилей. Но поскольку все, что вы знаете об автомобилях, — это их координаты, вы можете выбрать только ближайшие автомобили по геометрическому расстоянию (то есть по кругу). Действительно, проверять водителей на другом конце города бессмысленно.
К сожалению, бывают случаи, когда кружок вокруг места посадки, который обычно работает нормально, не включает ближайшую машину. Представьте себе всадника, ожидающего на одной стороне реки, а несколько водителей ждут на другой стороне без каких-либо близлежащих мостов. Этот случай может показаться редким, но по мере того, как ваше приложение масштабируется и начинает обслуживать миллионы людей, вы обнаруживаете, что теряете оптимальные совпадения в значительном количестве случаев. Это означает, что по мере того как вы ограничиваете запросы услуг маршрутизации меньшим кругом вокруг пункта посадки, вы увеличиваете риск того, что вы не найдете автомобиль, который может быстро забрать водителя.
Это приводит к следующему компромиссу:
● Сэкономьте на количестве путей, запрашиваемых службой маршрутизации, но рискуете не найти самый быстрый автомобиль
● Или всегда находите водителя с самым быстрым временем посадки, но платите через зубы в оплате услуг маршрутизации.
Новый алгоритм, который мы разработали, исключает компромисс между эффективностью и ценой: он гарантирует, что самый быстрый автомобиль будет найден каждый раз, и делает ненужными запросы к дорогостоящим службам маршрутизации.Это может показаться волшебством, но за этим стоит тяжелая работа. Нам пришлось разобрать весь процесс сопоставления и собрать новый с новыми структурами данных и новыми алгоритмами, оптимизированными для каждой задачи.
Мы начали с изучения сервисов технической маршрутизации, которые используются для обработки запросов от приложений для совместного использования. Обычно он основан на данных городской дорожной сети и трафика, включая расположение улиц, их взаимосвязи, направления движения на этих улицах и скорость движения.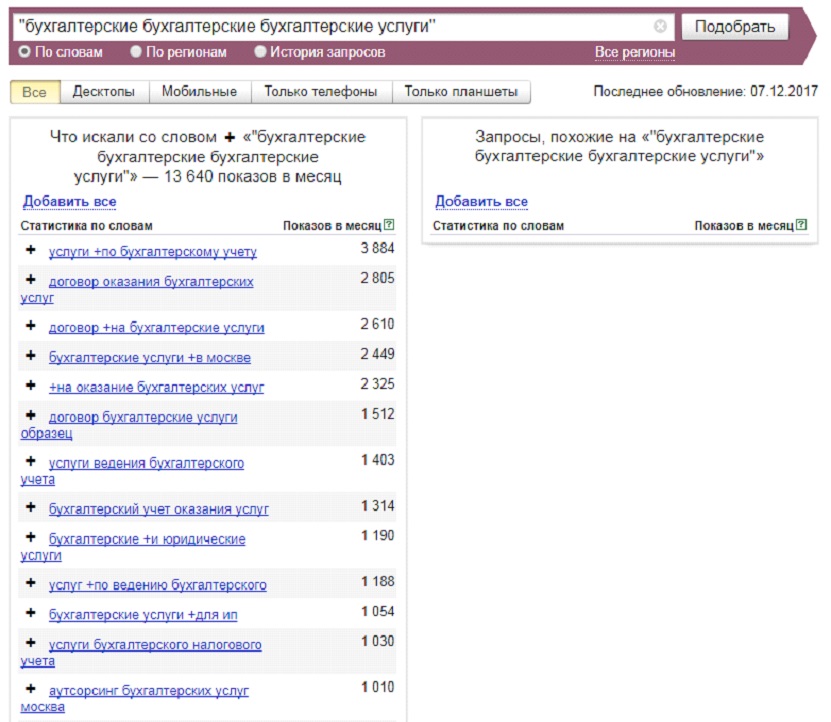 Служба маршрутизации находит самый быстрый маршрут из одной точки в другую и прогнозирует время, которое потребуется автомобилю, чтобы проехать по нему. Затем приложение для совместного использования автомобилей сравнивает ожидаемое время прибытия всех доступных водителей в определенной близости, чтобы выбрать самого быстрого. Поэтому приложения для совместного использования поездок полагаются на внешние службы маршрутизации, чтобы знать, как быстро водители могут добраться до места отправления.
Служба маршрутизации находит самый быстрый маршрут из одной точки в другую и прогнозирует время, которое потребуется автомобилю, чтобы проехать по нему. Затем приложение для совместного использования автомобилей сравнивает ожидаемое время прибытия всех доступных водителей в определенной близости, чтобы выбрать самого быстрого. Поэтому приложения для совместного использования поездок полагаются на внешние службы маршрутизации, чтобы знать, как быстро водители могут добраться до места отправления.
Легко увидеть, что если бы у нас были все эти знания на нашей стороне, мы могли бы каждый раз правильно находить самую быструю машину.Вот почему мы решили интегрировать структуру дорожных сетей в наши системы. Мы построили структуру данных графа с ребрами, представляющими улицы, узлами, представляющими перекрестки, и всеми характеристиками, необходимыми для расчета оптимального маршрута и времени прибытия, включая ограничения движения и скорость движения на каждом краю. Теперь Яндекс.Такси видит автомобили не как массу точек на поверхности, а как места на структуре данных графа.
Имея такую структуру, мы используем один из наших алгоритмов «обхода графа» для поиска на графе и определения драйвера, который первым достигнет точки погрузки.Более того, алгоритм может найти любое указанное количество автомобилей в порядке ожидаемого времени прибытия.
Обратите внимание, что без данных о трафике в реальном времени было бы невозможно правильно предсказать время прибытия автомобилей. Недостаточно знать дорожную систему, потому что текущие условия движения сильно влияют на то, сколько времени потребуется, чтобы добраться из пункта A в пункт B. речь идет о картографии и навигации в реальном времени.У нас есть доступ к картам и совершенно точным, регулярно обновляемым данным о дорожной инфраструктуре, полученным с помощью геосервисов нашей материнской компании Яндекс. Кроме того, мы полагаемся на геосервисы Яндекса для получения данных о дорожной обстановке в режиме реального времени, что очень важно для точной оценки времени прибытия. Яндекс.Такси использует эти тесные отношения для создания лучших в своем классе технологий и услуг.
Яндекс.Такси использует эти тесные отношения для создания лучших в своем классе технологий и услуг.
Две части — график и данные о дорожном движении в реальном времени — взаимодействуют в гармонии, создавая совершенно новый способ подбора гонщиков и водителей.Мы избавились от необходимости запрашивать время прибытия для каждой машины поблизости от службы маршрутизации. Используя дорожную инфраструктуру и данные о дорожном движении в режиме реального времени, мы создали алгоритм, который выполняет поиск по дорожной диаграмме и находит автомобили строго по времени посадки. Другими словами, мы решили проблему «ближайшей машины» максимально точно, без необходимости многократных запросов маршрутизации. И вишенка на вершине: наш подход также определяет произвольное количество ближайших автомобилей с максимальной эффективностью.
Новая технология, которую мы создали, решает компромисс между качеством поиска и стоимостью запросов маршрутизации раз и навсегда:
1. Миллионы запросов API маршрутизации в день в алгоритмах поиска были полностью исключены.
2. Снижены средние сроки подачи, в том числе до 15% в регионах со сложной дорожной структурой: вблизи многоуровневых развязок, железных дорог и рек.
3. Мы заложили основу для создания целого ряда плоских алгоритмов, которые будут заново изобретены на графах.Скачкообразное ценообразование — один из таких алгоритмов — он может более эффективно работать в графической инфраструктуре. Например, он может распознавать различный баланс спроса и предложения на противоположных сторонах дороги. Иногда это происходит из-за асимметрии доступных автомобилей, вызванной пробками и ограничениями на разворот.
Учебники — документация Яндекс.Танк 1.15.12
Итак, вы установили Яндекс.Танк на нужную машину, он близок к цели, доступ разрешен и сервер настроен. Как сделать тест?
Примечание
Это руководство предназначено для генератора фантомной нагрузки .
Создать файл на сервере с Яндекс.Танком: load.yaml
фантом: адрес: 203.
 0.113.1:80 # [Адрес цели]: [порт цели]
uris:
- /
Загрузить профиль:
load_type: rps # запланировать загрузку, указав количество запросов в секунду
расписание: линия (1, 10, 10 м) # начиная с 1 об / с линейно увеличивая до 10 об / с в течение 10 минут
приставка:
enabled: true # включить вывод в консоль
телеграф:
enabled: false # отключим в первый раз мониторинг телеграфа
0.113.1:80 # [Адрес цели]: [порт цели]
uris:
- /
Загрузить профиль:
load_type: rps # запланировать загрузку, указав количество запросов в секунду
расписание: линия (1, 10, 10 м) # начиная с 1 об / с линейно увеличивая до 10 об / с в течение 10 минут
приставка:
enabled: true # включить вывод в консоль
телеграф:
enabled: false # отключим в первый раз мониторинг телеграфа
И запустить: $ яндекс-танк -c груз.yaml
фантом имеет 3 примитива для описания схемы нагрузки:
step (a, b, step, dur)выполняет ступенчатую нагрузку, где a, b — значения начальной / конечной нагрузки, step — значение приращения, dur — продолжительность шага.
- Примеры:
step (25, 5, 5, 60)— ступенчатая нагрузка от 25 до 5 об / с, с шагом 5 об / с, длительность шага 60 с.step (5, 25, 5, 60)— ступенчатая нагрузка от 5 до 25 об / с, с шагом 5 об / с, длительность шага 60 с
line (a, b, dur)выполняет линейную нагрузку, гдеa, b— начальная / конечная нагрузка,dur— время увеличения линейной нагрузки от a до b.
- Примеры:
линия (10, 1, 10м)— линейная нагрузка от 10 до 1 об / с, продолжительность — 10 минутлиния (1, 10, 10м)— линейная нагрузка от 1 до 10 об / с, продолжительность — 10 минут
const (load, dur)обеспечивает постоянную нагрузку.загрузка— количество оборотов в секунду,dur— продолжительность загрузки.
- Примеры:
const (10,10м)— постоянная нагрузка 10 оборотов в секунду в течение 10 минут.const (0, 10)— 0 об / с в течение 10 секунд, фактически пауза в 10 секунд в тесте.
Примечание
- Вы можете установить дробную загрузку следующим образом:
-
линия (1,1, 2,5, 10)— с 1,1 до 2,5 за 10 секунд.
Примечание
шаг и строка могут использоваться с увеличением и уменьшением интенсивности:
С помощью этих примитивов можно указать сложные схемы нагрузки.
- Пример:
график: линия (1, 10, 10м) const (10,10м)линейная нагрузка от 1 до 10 об / с в течение 10 минут, затем 10 минут при постоянной нагрузке 10 об / с.
Продолжительность времени может быть определена в секундах, минутах (м) и часах (ч).
Например: 27х203м645
Для теста с постоянной нагрузкой при 10 об / с в течение 10 минут load.yaml должен
иметь следующие строки:
фантом:
адрес: 203.0.113.1: 80 # [Адрес цели]: [порт цели]
uris:
- / uri1
- / uri2
Загрузить профиль:
load_type: rps # запланировать загрузку, указав количество запросов в секунду
schedule: const (10, 10m) # начиная с 1 об / с линейно увеличивая до 10 об / с в течение 10 минут
приставка:
enabled: true # включить вывод в консоль
телеграф:
enabled: false # отключим в первый раз мониторинг телеграфа
Подготовка запросов
- Есть несколько способов настроить запросы:
- Режим доступа
- URI-стиль
- URI + POST
- в стиле запроса.

Примечание
Стиль запроса — тип боеприпасов по умолчанию.
Примечание
Независимо от выбранного формата, результирующий файл с запросами мог быть сжат с помощью gzip — танк поддерживает архивные файлы боеприпасов.
Чтобы указать внешний файл боеприпасов, используйте параметр ammofile .
Примечание
Вы можете указать URL-адрес аммофайла, http (s). Небольшие аммофайлы (~ <100 МБ) будут загружены как есть,
в каталог / tmp / , большие файлы будут читаться из потока.
Примечание
Если тип боеприпасов — uri-style или request-style, танк попытается угадать его.
Используйте опцию ammo_type , чтобы явно указать формат боеприпасов. Не забудьте изменить параметр ammo_type .
если вы измените формат боеприпасов, иначе вы можете получить ошибки.
Пример:
фантом: адрес: 203.0.113.1:80 ammofile: https: //yourhost.
 tld/path/to/ammofile.txt
tld/path/to/ammofile.txt
в стиле URI, URI в load.yaml
Конфигурация YAML-файла: не указывайте ammo_type явно для этого типа боеприпасов.
Обновление файла конфигурации с заголовками HTTP и URI:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
header_http: "1.1"
заголовки:
- «[Хост: www.target.example.com]»
- «[Подключение: закрыть]»
uris:
- "/ uri1"
- "/купить"
- "/ sdfg? sdf = rwerf"
- «/ sdfbv / swdfvs / ssfsf»
приставка:
включен: правда
телеграф:
включен: ложь
Параметр uris содержит uri, который следует использовать для генерации запросов.
Примечание
Обратите внимание на приведенный выше пример, потому что пробелы в многострочных uris и заголовках имеют важное значение.
в стиле URI, URI в файле
Конфигурация YAML-файла: ammo_type: uri
Создать файл с заявленными запросами: ammo.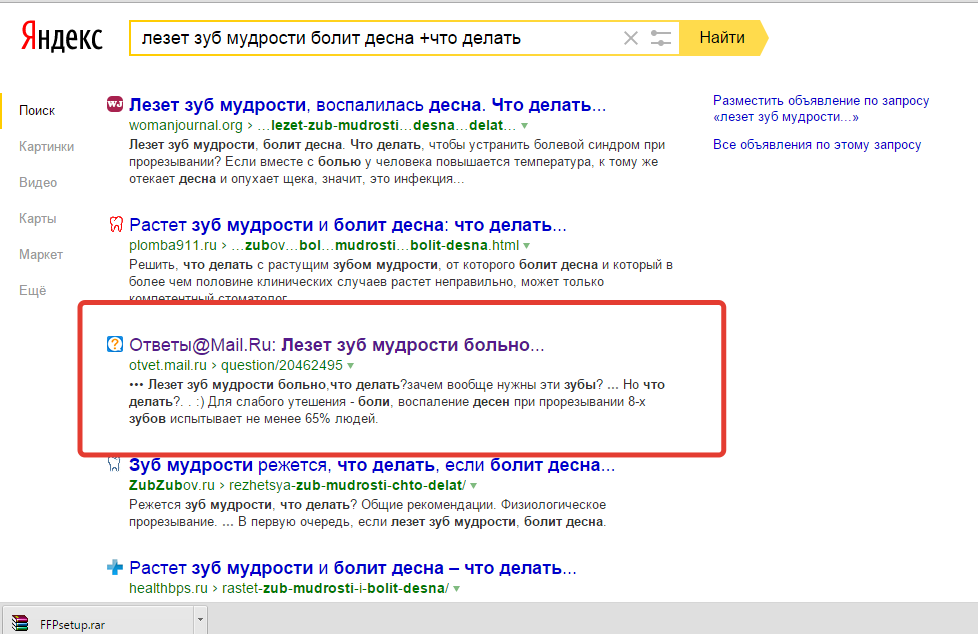 txt
txt
[Подключение: закрыть] [Хост: target.example.com] [Cookie: Нет] /? drg tag1 / / купить tag2 [Cookie: test] / buy /? rt = 0 & station_to = 7 & station_from = 9
Файл состоит из списка URI и заголовков, которые должны быть добавлены к каждому запросу, определенному ниже.Каждый URI должен начинаться с новой строки с / в начале.
Каждая строка, начинающаяся с [, считается заголовком.
Заголовки могут быть (пере) определены в середине URI, как в примере выше.
- Пример:
- Запрос
/ buy /? Rt = 0 & station_to = 7 & station_from = 9будет отправлен сCookie: test, а неCookie: нет.
Запрос может быть помечен тегом, вы можете указать его через пробел после URI.
URI + POST-стиль
Конфигурация YAML-файла: ammo_type: uripost
Создать файл с заявленными запросами: ammo.txt
[Хост: example.
 org]
[Подключение: закрыть]
[User-Agent: Tank]
5 /route/?rll=50.262025%2C53.276083~50.056015%2C53.495561&origin=1&simplify=1
класс
10 /route/?rll=50.262025%2C53.276083~50.056015%2C53.495561&origin=1&simplify=1
привет! класс
7 /route/?rll=37.565147%2C55.695758~37.412796%2C55.691454&origin=1&simplify=1
урипост
org]
[Подключение: закрыть]
[User-Agent: Tank]
5 /route/?rll=50.262025%2C53.276083~50.056015%2C53.495561&origin=1&simplify=1
класс
10 /route/?rll=50.262025%2C53.276083~50.056015%2C53.495561&origin=1&simplify=1
привет! класс
7 /route/?rll=37.565147%2C55.695758~37.412796%2C55.691454&origin=1&simplify=1
урипост
Файл начинается с необязательных строк […], содержащих заголовки, которые будут добавляться к каждому запросу.После этого раздела идет список URI и тел POST. Каждая строка URI начинается с числа, равного размеру следующего тела POST.
Стиль запроса
Конфигурация YAML-файла: ammo_type: phantom
Полные запросы перечислены в отдельном файле. Для более сложных запросы, такие как POST, вам нужно будет создать специальный файл. Формат файла это:
[размер_запроса] [тег] \ n [request_headers] [body_of_request] \ r \ n [size_of_request2] [tag2] \ n [request2_headers] [body_of_request2] \ r \ n
где size_of_request - размер запроса в байтах.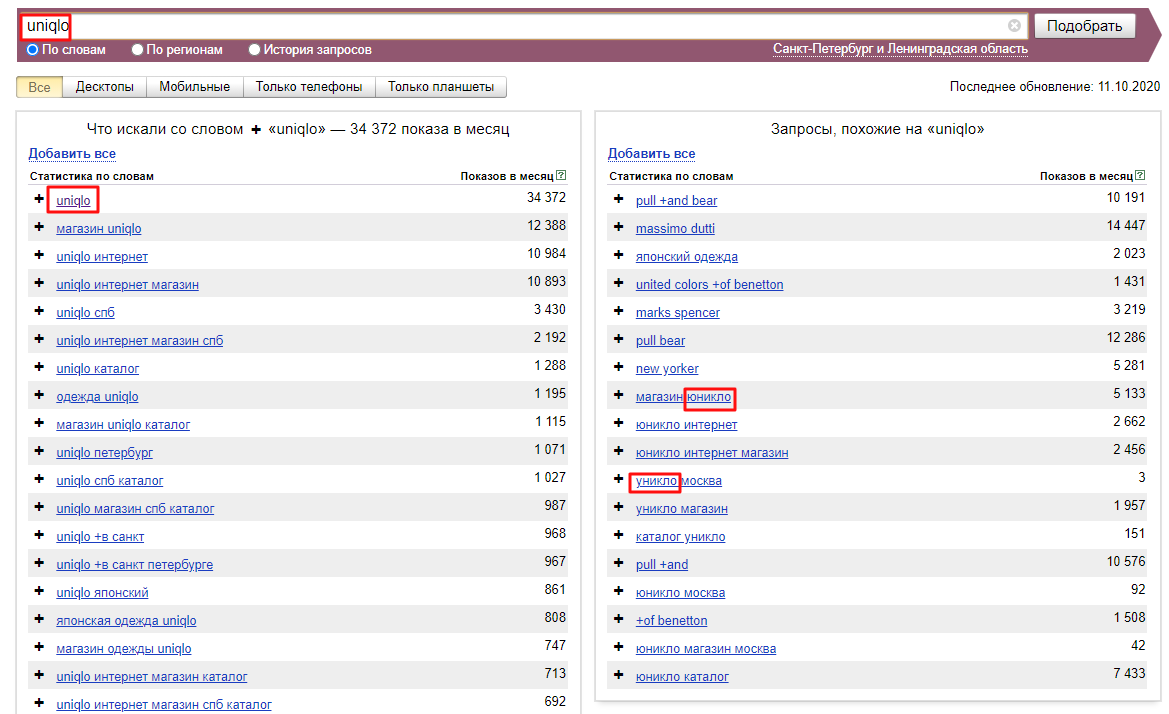 Символы "rn" после
Символы "rn" после тело игнорируются и никуда не отправляются, но требуется для
включать их в файл после каждого запроса. Обратите внимание на образец выше
потому что символы "r" обязательны.
Примечание
Параметр ammo_type не нужен, стиль запроса - тип боеприпасов по умолчанию.
пример запросов GET (пустое тело)
73 хорошо GET / HTTP / 1.0 Хост: xxx.tanks.example.com Пользовательский агент: xxx (оболочка 1) 77 плохо ПОЛУЧИТЬ / abra HTTP / 1...
образец POST multipart:
533 POST / updateShopStatus? HTTP / 1.0 Пользовательский агент: xxx / 1.2.3 Хост: xxxxxxxxx.dev.example.com Живучесть: 300 Тип содержимого: multipart / form-data; border = AGHTUNG Длина содержимого: 334 Подключение: Закрыть - AGHTUNG Content-Disposition: данные формы; name = "host" load-test-shop-updatestatus.ru - AGHTUNG Content-Disposition: данные формы; name = "user_id" 1 - AGHTUNG Content-Disposition: данные формы; name = "wsw-fields"--АГХТУНГ-- отключить
образцов генераторов боеприпасов вы можете найти на странице Генераторы боеприпасов.
Запустить тест!
- Запросить спецификации в load.yaml - запустить как
yandex-tank -c load.yaml - Запросить спецификации в ammo.txt - запустить как
yandex-tank -c load.yaml ammo.txt
Яндекс.Танк определяет формат запросов и формирует конечные запросы версии.
яндекс-танк вот имя исполняемого файла Яндекс.Танка.
Если Яндекс.Танк установлен правильно и файл конфигурации правильно, нагрузка будет дана через несколько секунд.
Результаты
Во время выполнения теста вы увидите ошибки HTTP и сети, время ответа
распределение, прогрессбар и другие интересные данные. В то же время
Записывается файл phout.txt , который можно будет проанализировать позже.
Если вам нужен более понятный отчет, вы можете попробовать плагин Report, Вы можете найти его здесь
Если вам нужно выгрузить результаты во внешнее хранилище, такое как Graphite или InfluxDB, вы можете использовать один из существующих модулей загрузки артефактов Modules
SSL
Для активации SSL добавьте фантома: {ssl: true} до нагрузки..
Теперь наша базовая конфигурация выглядит так: yaml
yaml
фантом:
адрес: 203.0.113.1:443
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
ssl: правда
Примечание
Не забудьте указать порт ssl на адрес . В противном случае вы можете получить «ошибки протокола».
Автостоп
Autostop - это возможность автоматически останавливать выполнение теста. при достижении некоторых условий.
HTTP и Net коды условия
Есть возможность определить конкретные коды (404 503 100), а также код группы (3xx, 5xx, xx).Также вы можете определить относительный порог (процент от всего количества ответов в секунду) или абсолютных (количество ответы с указанным кодом в секунду).
Примеры:
autostop: http (4xx, 25%, 10)- остановить тест, если количество HTTP-кодов 4xx в каждую секунду периода последних 10 секунд превышает 25% ответов (относительный порог).
autostop: net (101,25,10)- остановить тест, если количество 101 net-кода в каждую секунду последних 10 секунд больше 25 (абсолютный порог).
autostop: net (xx, 25,10)- остановить тест, если количество ненулевых net-кодов в каждую секунду последних 10 секунд больше 25 (абсолютный порог).

Средние временные условия
- Пример:
-
автостоп: время (1500,15)- останавливает тест, если среднее время ответа превышает 1500 мс.
Итак, если мы хотим остановить тест, когда все ответы за 1 секунду равны 5xx плюс некоторые сетевые и временные факторы - добавьте строку автоостановки в загрузку.yaml:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
авто стоп:
авто стоп:
- время (1 с, 10 с)
- http (5xx, 100%, 1 с)
- нетто (xx, 1,30)
Лесозаготовки
Поиск ответов цели очень полезен при отладке. Для того, чтобы делать
которые используют параметр writelog, например добавьте
Для того, чтобы делать
которые используют параметр writelog, например добавьте phantom: {writelog: all} до load.yaml для регистрации всех сообщений.
Примечание
Запись ответов при высокой нагрузке приводит к интенсивному вводу-выводу на диск использование и может повлиять на точность теста.**
Формат журнала:
<метрики>
Где метрики:
size_in size_out response_time (interval_real) interval_event net_code (размер запроса, размер ответа, время ответа, время ожидания ответа
с сервера ответьте на код сети)
Пример:
user @ tank: ~ $ head answ _ *. Txt 553 572 8056 8043 0 ПОЛУЧИТЬ / создать-проблему HTTP / 1.1 Хост: target.yandex.net Пользовательский агент: tank Принимать: */* Подключение: закрыть HTTP / 1.1 200 ОК Тип содержимого: приложение / javascript; кодировка = UTF-8
Для load.yaml вот так:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
writelog: все
авто стоп:
авто стоп:
- время (1,10)
- http (5xx, 100%, 1 с)
- нетто (xx, 1,30)
результатов в phout
phout.txt - журнал запросов. Это может быть использовано для служебного поведения
анализ (Excel / gnuplot / etc) Он имеет следующие поля: время, тег, interval_real, connect_time, send_time, latency, receive_time, interval_event, size_out, size_in, net_code proto_code
Пример Phout:
1326453006.582 1510 934 52 384 140 1249 37 478 0 404 1326453006,582 прочие 1301 674 58 499 70 1116 37 478 0 404 1326453006,587 тяжелая 377 76 33 17837 478 0404 1326453006,587 294 47 27 146 74 147 37 478 0 404 1326453006,588 345 75 29 166 75 169 37 478 0 404 1326453006.590 276 72 28 119 57 121 53 476 0 404 1326453006,593 255 62 27131 35 134 37 478 0 404 1326453006.594 304 50 30 147 77 149 37 478 0 404 1326453006,596 317 53 33 158 73 161 37 478 0 404 1326453006,598 257 58 32 106 61110 37 478 0 404 1326453006.602 315 59 27 160 69 161 37 478 0 404 1326453006.603 256 59 33 107 57 110 53 476 0 404 1326453006.605 241 53 26 130 32 131 37 478 0 404
Примечание
содержимое phout зависит от версии фантома, установленной в вашей системе Яндекс.Танк.
сетевых кодов - это системные коды с errno.h, в большинстве систем на базе Debian это:
1 EPERM Работа не разрешена 2 ENOENT Нет такого файла или каталога 3 ESRCH Нет такого процесса 4 EINTR Прерванный системный вызов 5 Ошибка ввода / вывода EIO 6 ENXIO Нет такого устройства или адреса 7 E2BIG Список аргументов слишком длинный 8 Ошибка формата ENOEXEC Exec 9 EBADF Неверный дескриптор файла 10 ECHILD Нет дочерних процессов 11 EAGAIN Ресурс временно недоступен 12 ENOMEM Невозможно выделить память 13 EACCES Разрешение отказано 14 EFAULT Неверный адрес 15 ENOTBLK Требуется блочное устройство 16 EBUSY Устройство или ресурс занят 17 EEXIST Файл существует 18 EXDEV Неверная ссылка между устройствами 19 ENODEV Нет такого устройства 20 ENOTDIR Не каталог 21 EISDIR - это каталог 22 EINVAL Неверный аргумент 23 ENFILE Слишком много открытых файлов в системе 24 EMFILE Слишком много открытых файлов 25 ENOTTY Несоответствующий ioctl для устройства 26 ETXTBSY Текстовый файл занят 27 EFBIG Файл слишком большой 28 ENOSPC На устройстве не осталось места 29 ESPIPE Незаконный поиск 30 EROFS Файловая система только для чтения 31 EMLINK Слишком много ссылок 32 EPIPE Сломанная труба 33 EDOM Числовой аргумент вне домена 34 ERANGE Числовой результат вне допустимого диапазона 35 EDEADLOCK Избежание блокировки ресурсов 36 ENAMETOOLONG Слишком длинное имя файла 37 ENOLCK Нет доступных замков 38 ENOSYS Функция не реализована 39 ENOTEMPTY Каталог не пуст 40 ELOOP Слишком много уровней символических ссылок 42 ENOMSG Нет сообщения желаемого типа 43 Идентификатор EIDRM удален 44 ECHRNG Номер канала вне допустимого диапазона 45 EL2NSYNC Level 2 не синхронизирован 46 EL3HLT Уровень 3 остановлен 47 EL3RST Сброс уровня 3 48 ELNRNG Номер ссылки вне допустимого диапазона 49 Драйвер протокола EUNATCH не подключен 50 ENOCSI Нет доступной структуры CSI 51 EL2HLT Уровень 2 остановлен 52 EBADE Неверный обмен 53 EBADR Неверный дескриптор запроса 54 EXFULL Обмен полный 55 ENOANO Без анода 56 EBADRQC Неверный код запроса 57 EBADSLT Неверный слот 59 EBFONT Неверный формат файла шрифта 60 ENOSTR Устройство не поток 61 ENODATA Нет данных 62 Срок действия таймера ETIME истек 63 ENOSR Нет ресурсов потоков 64 ENONET Машина не в сети 65 ENOPKG Пакет не установлен 66 EREMOTE Объект удален 67 ENOLINK Ссылка разорвана 68 Ошибка объявления EADV 69 Ошибка подключения ESRMNT 70 ECOMM Ошибка связи при отправке 71 Ошибка протокола EPROTO 72 EMULTIHOP Multihop попытка 73 EDOTDOT RFS специфическая ошибка 74 EBADMSG Плохое сообщение 75 EOVERFLOW Значение слишком велико для определенного типа данных 76 ENOTUNIQ Имя не уникально в сети 77 EBADFD Дескриптор файла в плохом состоянии 78 EREMCHG Удаленный адрес изменен 79 ELIBACC Невозможно получить доступ к необходимой разделяемой библиотеке 80 ELIBBAD Доступ к поврежденной разделяемой библиотеке 81 ELIBSCN.Раздел lib в a.out поврежден 82 ELIBMAX Попытка связать слишком много общих библиотек 83 ELIBEXEC Невозможно запустить разделяемую библиотеку напрямую. 84 EILSEQ Недействительный или неполный многобайтовый или широкий символ 85 ERESTART Прерванный системный вызов следует перезапустить. 86 Ошибка канала ESTRPIPE Streams 87 EUSERS Слишком много пользователей 88 ENOTSOCK Работа с сокетом без сокета 89 EDESTADDRREQ Требуется адрес назначения 90 EMSGSIZE Слишком длинное сообщение 91 EPROTOTYPE Протокол неправильного типа для сокета 92 Протокол ENOPROTOOPT недоступен 93 EPROTONOSUPPORT Протокол не поддерживается 94 ESOCKTNOSUPPORT Тип сокета не поддерживается 95 ENOTSUP Операция не поддерживается 96 Семейство протоколов EPFNOSUPPORT не поддерживается 97 EAFNOSUPPORT Семейство адресов не поддерживается протоколом 98 EADDRINUSE Адрес уже используется 99 EADDRNOTAVAIL Невозможно назначить запрошенный адрес 100 ENETDOWN Сеть не работает 101 ENETUNREACH Сеть недоступна 102 ENETRESET Сеть разорвала соединение при сбросе 103 ECONNABORTED Программное обеспечение вызвало разрыв соединения 104 ECONNRESET Сброс соединения одноранговым узлом 105 ENOBUFS Нет доступного буферного пространства 106 EISCONN Транспортная конечная точка уже подключена 107 ENOTCONN Транспортная конечная точка не подключена 108 ESHUTDOWN Не удается отправить после завершения работы транспортной конечной точки 109 ETOOMANYREFS Слишком много ссылок: склейка невозможна. 110 ETIMEDOUT Превышено время ожидания соединения 111 ECONNREFUSED В соединении отказано 112 EHOSTDOWN Хост не работает 113 EHOSTUNREACH Нет маршрута к хосту 114 EALREADY Операция уже выполняется 115 EINPROGRESS Операция в процессе 116 ESTALE Дескриптор устаревшего файла 117 EUCLEAN Конструкция нуждается в очистке 118 ENOTNAM Не файл именованного типа XENIX 119 ENAVAIL Нет доступных семафоров XENIX 120 EISNAM Файл именованного типа. 121 EREMOTEIO Ошибка удаленного ввода-вывода 122 EDQUOT Дисковая квота превышена
График и статистика
Использовать плагин отчета ИЛИ ЖЕ используйте ваш любимый пакет статистики, например R.
Ограничение резьбы
экземпляров: N в load.yaml ограничивает количество одновременных
соединения (резьбы).
Пример с ограничением в 10 потоков:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
экземпляров: 10
Ограничение динамической резьбы
Вы можете указать load_type: instance вместо «rps», чтобы запланировать количество активных экземпляров.
которые генерируют столько оборотов в секунду, сколько им удается.Помните, что количество активных инстансов нельзя уменьшить.
и конечное их количество должно быть равно экземплярам значению параметра.
Пример:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: экземпляры
график: линейный (1,10,10м)
экземпляров: 10
loop: 10000 # не останавливаться, когда достигнут конец боеприпасов, а зацикливать его 10000 раз
Примечание
При использовании load_type: instance вы должны указать, сколько циклов
боеприпасы, которые вы хотите создать, потому что танк не может узнать из расписания
сколько патронов тебе нужно
Пользовательский протокол без сохранения состояния
При необходимости тестирования HTTP-подобного протокола без сохранения состояния Яндекс.HTTP Танка парсер можно было выключить, давая возможность генерировать нагрузку с любые данные, получая любой ответ взамен. Для этого используйте Параметр tank_type:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
экземпляров: 10
tank_type: нет
Примечание
Обязательное условие: закрытие соединения должно быть инициировано удаленной стороной
Гатлинг
Если у сервера с Яндекс.Танком несколько IP-адресов, они могут быть
используется, чтобы избежать нехватки порта исхода.Используйте параметр gatling_ip для
что. load.yaml:
фантом:
адрес: 203.0.113.1:80
Загрузить профиль:
load_type: rps
график: линия (1, 10, 10м)
экземпляров: 10
gatling_ip: IP1 IP2
.