
Статистика поисковых запросов — Как посмотреть статистику поисковых запросов.
Перед тем, как что-то делать в интернете: создавать сайт, настраивать рекламную компанию, писать статью или книгу, надо посмотреть, что вообще ищут люди, чем интересуются, что вводят в поисковой строке.
Зачем собирают ключевые фразы
Поисковые запросы (ключевые фразы и слова) чаще всего собирают в двух случаях:
- Перед созданием сайта. В этом случае нужно собрать максимум ключевых слов, чтобы охватить всю вашу сферу. После сбора, поисковые запросы анализируются и на основании этого принимается решение о структуре сайта.
- Для настройки контекстной рекламы. Для рекламы выбирают не все, а только слова, по которым можно определить интерес к товару или услуге, желательно активный интерес выраженный словами «купить», «цена», «заказать» и т.п.
Если вы собираетесь настраивать контекстную рекламу, то запросы и бюджеты можно подсмотреть у конкурентов.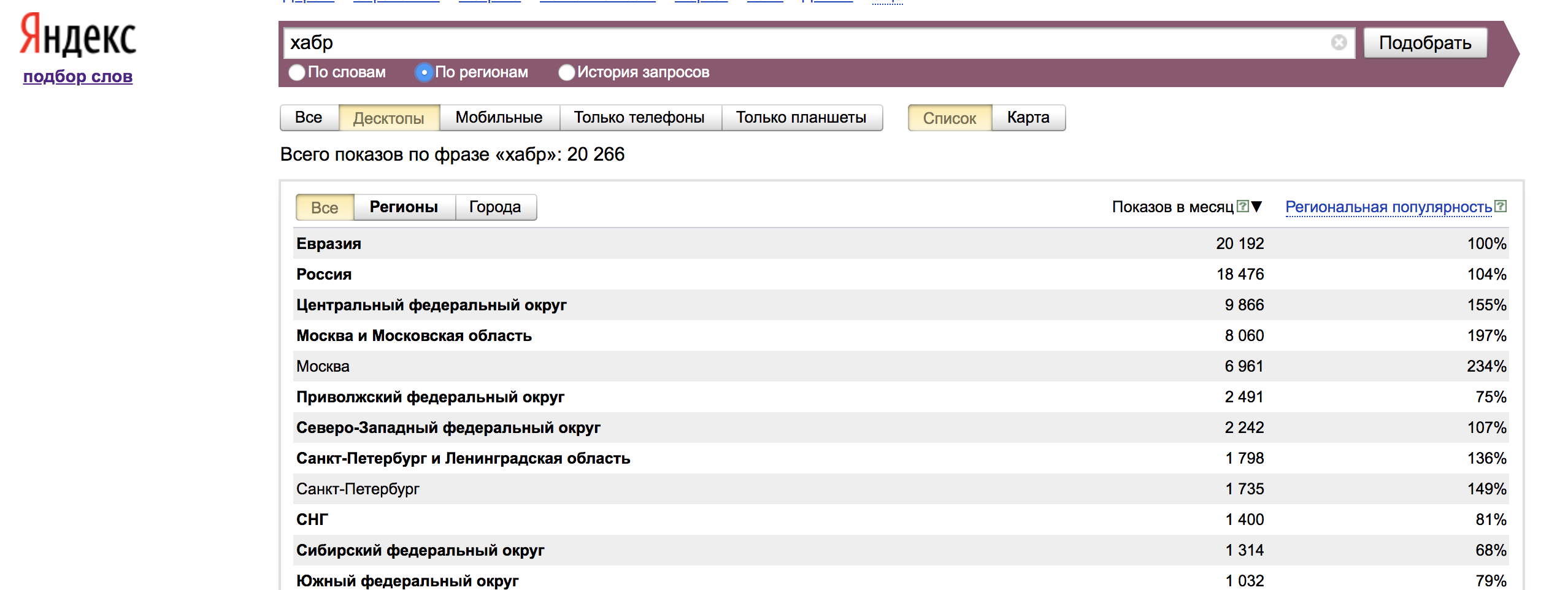
А ниже мы рассмотрим, как собрать статистику поисковых запросов в популярных поисковых системах, а так же небольшие секреты, как это сделать лучше.
Сразу добавлю, что сам я пользуюсь платными сервисами (мой любимый сейчас Keys.so), потому-что бесплатно можно очень долго собирать тот объем данных, который обычно нужен для продвижения и настройки рекламы. Если вы постоянно работаете с ключевыми словами, то платный сервис сэкономит кучу времени.
Как посмотреть статистику запросов Яндекс
У поисковой системы Яндекс есть специальный сервис «Подбор слов», находящийся по адресу http://wordstat.yandex.ru/. Пользоваться им очень просто: вводим любые слова и обычно, кроме статистики по этим словам, также видим что искали вместе с этими словами.
Очень важно понимать, что статистика по более коротким запросам, включает в себя статистику всех подробных запросов с этими словами. Например, на скриншоте запрос «статистика запросов» включает в себя запрос «статистика запросов яндекс» и все остальные запросы ниже.
В правой колонке отображаются запросы, которые искали люди, искавшие введенный вами запрос. Откуда берется эта информация? Это запросы, которые были введены до вашего запроса или сразу после него.
Чтобы посмотреть точное количество запросов по фразе, надо ввести ее в кавычках «фраза». Так, конкретно запрос «статистика запросов» искали 5047 раз.
Статистика поисковых запросов Google
Google Trends
https://trends.google.com/trends/?geo=RU
Гугл Тренды не покажет все варианты запросов, но с помощью него можно найти популярные темы в Google и посмотреть как менялась популярность в течении времени.
Кроме частоты запросов, Google покажет популярность по регионам и схожие запросы.
Google ADS
https://ads.google.com/
Второй способ посмотреть частоту поисковых запросов Гугл — это использовать сервис для рекламодателей Google ADS. Для этого нужно зарегистрироваться как рекламодатель. В меню «инструменты» нужно выбрать «Планировщик ключевых слов».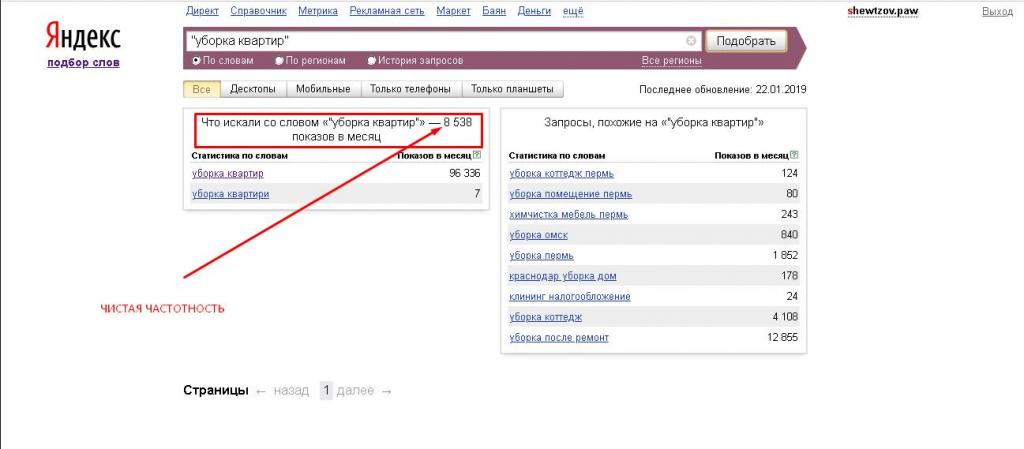
В планировщике, кроме статистики, вы узнаете уровень конкуренции рекламодателей по этому запросу и даже примерную стоимость клика, если решите тоже рекламироваться. К слову, стоимость обычно завышена.
Число запросов отображается примерное, точное число посмотреть нельзя.
Статистика поисковых запросов Mail.ru
Майл.ру обновил инструмент показывающий статистику поисковых запросов http://webmaster.mail.ru/querystat. Главная фишка сервиса — это распределение запросов по полу и возрасту.
Можно предположить, что сервис подбора слов Яндекса также учитывает запросы из Mail, т.к. в данный момент поисковая система Mail.ru показывает рекламу Яндекса, а сервис в основном рассчитан на рекламодателей.
Статистика поисковых запросов Bing
Поисковой системой Бинг пользуется еще меньше наших соотечественников. Чтобы посмотреть статистику ключевых слов, надо зарегистрироваться как вебмастер и добавить сайт (может быть сайт и не придется добавлять, но у меня этот инструмент доступен, только когда я просматриваю инфо по своему сайту).
Сделать это можно по адресу https://www.bing.com/toolbox/keywords
Поисковые запросы Youtube
Youtube раньше предлагал свой инструмент для подбора поисковых запросов, который назывался «Инструмент подсказки ключевых слов». C 1 сентября 2015 YouTube закрыл сервис подбора ключевых слов YouTube Keyword Tool.
Теперь статистику ключевых фраз на YouTube можно смотреть только в сторонних сервисах, либо использовать статистику из Яндекс Wordstat и Google ADS для анализа популярности поисковых фраз и предполагать, что в Youtube будет аналогичный спрос.
Несколько сервисов, которые можно использовать:
Ahrefs YouTube Keyword Tool
https://ahrefs.com/ru/youtube-keyword-tool
Главный минус, что он показывает только при точном совпадении слов в базе. Например, если в примере на скриншоте указать «пироги яблоки», то сервис ничего не выдаст. А например Google ADS даст много вариантов.
Google Trends Youtube
https://trends.google.com/trends/explore?gprop=youtube
В Гугл Трендах вы не найдете конкретных поисковых фраз, но можно быстро узнать какие темы и запросы по искомой теме лидируют на Youtube.
Ключевые фразы Вконтакте, Одноклассники
Не рекомендую этот способ поиска ключевых фрах, но знать о нем нужно. MyTarget, Одноклассники и Вконтакте позволяют настраивать таргетинг по ключевым фразам и показывают аудиторию, в интересы которой попадают эти фразы. Не факт, что они вводили, конкретно эти фразы, поэтому для точного сбора инструмент не подходит.
На примере Вконтакте. Надо зайти в кабинет рекламодателя и начать создавать объявление. В таргетинге выбрать таргетинг по ключевым фразам:
Сервисы для подбора и проверки поисковых фраз.
Выше я показал официальные сервисы. Далее рассмотрим сторонние инструменты, которые позволяют подобрать и оценить объем поисковых слов.
Почти все сервисы бесплатно предоставляют какой-то минимальный (а иногда и весь) объем информации, которого достаточно, если проверять конкретные поисковые фразы. А вот для подбора полноценного семантического ядра бесплатного тарифа вряд ли хватит.
Keys.so
https://www.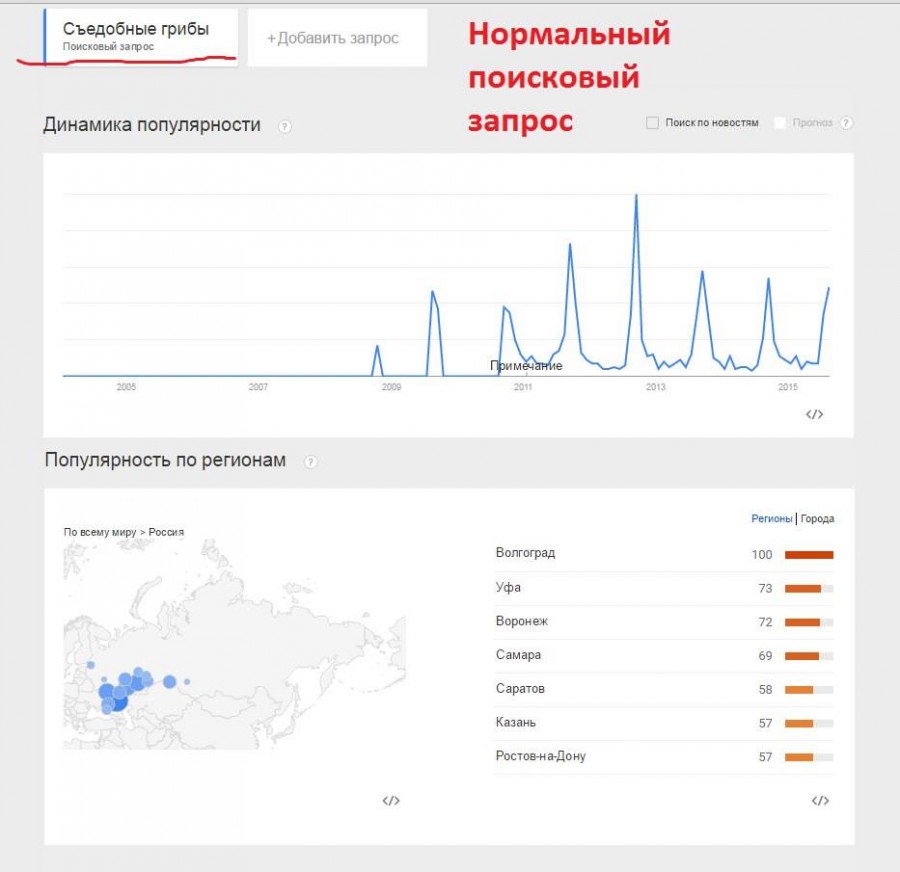 keys.so
keys.so
Отличный сервис, которым и сам пользуюсь. Кроме огромного функционала и хорошей русскоязычной базы запросов, здесь доступные тарифы. Бесплатный тариф для пробива отдельных фраз тоже будет полезней, чем тот же Wordstat от Яндекса.
На стартовом тарифе позволяет собрать семантическое ядро серией отдельных запросов, по охвату ключей даже этот тариф не имеет конкурентов на рынке — keys.so предоставит больше ключей и больше строк в отчетах, чем все известные публичные сервисы.
Букварикс
https://www.bukvarix.com/
Еще один любимый инструмент. Использую его когда нужно быстро подобрать минус слова или проверить тему. Чаще всего я вбиваю какие-то общие фразы (их еще называют «маркерами») и сразу перехожу к инструменту «Анализ», который группирует по словоформам.
Как раз в словоформах можно искать минус-слова или более узкие темы.
Serpstat
https://serpstat.com/
Serpstat — это целый комбайн для маркетинга. Если вам нужно работать с поисковыми фразами, то даже минимальный тариф покажется слишком дорогим.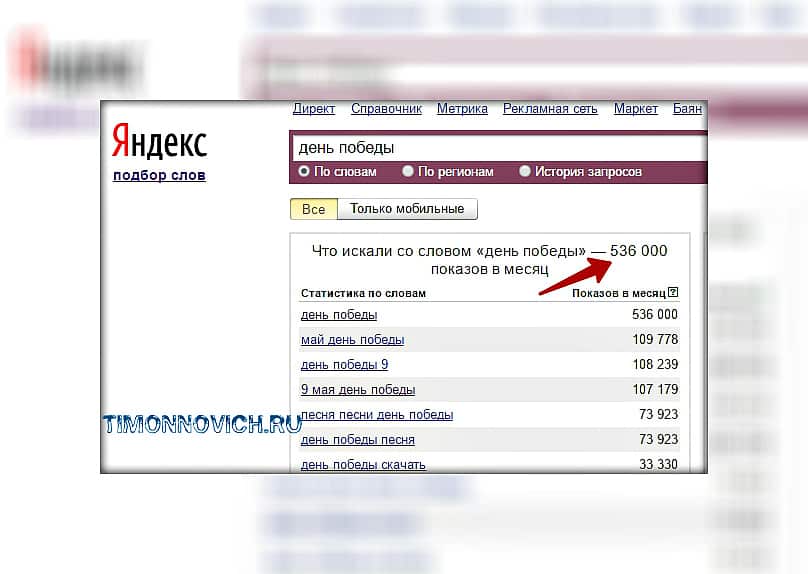 При этом, на бесплатном тарифе я иногда решаю некоторые задачи по ключевым фразам. А если нужно, то уже под проект можно оплатить подписку помесячно.
При этом, на бесплатном тарифе я иногда решаю некоторые задачи по ключевым фразам. А если нужно, то уже под проект можно оплатить подписку помесячно.
Ubersuggest
https://app.neilpatel.com
Ubersuggest — один из доступных по стоимости зарубежных сервисов. Учитывая что Google все больше отвоевывает рынок у Яндекса (а сервис работает только с Гугл), данных и идей по ключевым словам достаточно.
Итог.
Мы рассмотрели популярные системы подбора поисковых запросов. Конечно, это не все сервисы для поиска ключевых фраз, есть и другие. Обычно это многоцелевые «комбайны» для SEO или рекламы, поэтому я не стал их включать в обзор. Если мне надо работать с ключевыми словами, то я использую что-то из перечисленных сервисов.
Статистика запросов в Яндекс.Директе — как посмотреть?
Создание рекламной кампании в Яндекс.Директе начинается с подбора слов для базовой семантики, на основе которой будет составлено семантическое ядро. В этой статье подробно разберем, где смотреть статистику для определения актуальных запросов для семантического ядра и откуда взять данные после запуска рекламной кампании.
Как собрать базовую семантику
Сначала изучите товар или услугу для рекламы. Для этого создайте в отдельном Excel-файле таблицу, где будет название, характеристики, слова-синонимы, транслитерация, профессиональный сленг:
Если необходимо рекламировать несколько услуг или товаров из различных категорий, то базовую семантику создавайте для каждой категории отдельно.
Подбор слов для запуска рекламы
Следующий этап — сбор семантического ядра через Яндекс.Wordstat. Это бесплатный инструмент, благодаря которому рекламодатель собирает статистику поисковых запросов в Яндекс.Директе по регионам, по устройствам за месяц.
Посмотрим как работать с Wordstat на примере запроса iphone в регионе Санкт-Петербург и Ленинградская область.
Добавим слово «купить», чтобы уточнить запрос:
Количество запросов сократилось почти в 10 раз благодаря уточнению.
Помимо слов, которые ищут пользователи, есть статистика по частоте показов за месяц по ключевому слову и вложенным запросам. Это важно знать, чтобы увидеть актуальность товара или услуги:
Это важно знать, чтобы увидеть актуальность товара или услуги:
В правой колонке статистика запросов в Яндекс.Директе, которые ищут пользователи вместе с нужными. Благодаря им можно расширить список семантического ядра.
В истории запросов посмотрите на количество трафика с разных устройств для определения примерной суммы будущего бюджета. Конечно, с каждым месяцем количество меняется, но для формирования первоначального рекламного бюджета — это отличный вариант.
Данные статистики также подходят для определения сезонности спроса. Например, известно, что Apple проводит презентацию новинок 2 раза в год (в марте и сентябре). Последние 2 года компания представляет новые модели iphone в сентябре. Соответственно, спрос увеличивается после презентации и до Нового года. Таким образом, если вы продаете смартфоны Apple, то с августа по декабрь закладывайте рекламный бюджет больше, чем в другие месяцы.
После запуска
После того, как реклама будет запущена, необходимо ежедневно отслеживать запросы пользователей в Мастере отчетов для повышения эффективности рекламы в первые несколько недель. Например, расширить семантическое ядро, добавить минус-слова на основе запросов пользователей или повысить ставки на объявления с высоким CTR.
Например, расширить семантическое ядро, добавить минус-слова на основе запросов пользователей или повысить ставки на объявления с высоким CTR.
Для этого зайдите в отчет «Поисковые запросы» и настройте столбцы необходимым образом:
Рекомендуем выбрать «Поисковый запрос», «Условие показа» и «Подобранные фразы». Подробное описание каждого критерия читайте в Яндекс.Помощи.
Более детальную статистику по частоте показов и действиям посетителей на сайте, например, об отказах, посмотрите в Метрике. Для этого настройте счётчик и цели в Яндекс.Метрике для получения данных о запросах. Подробнее об этом в инструкции Помощи.
Резюме
- Собрать базовую семантику, которая характеризует товар или услугу по нескольким критериям.
- Сформировать семантическое ядро на основе запросов пользователей за последний месяц в Яндекс.Wordstat.
- Посмотреть сезонность спроса на товар или услугу.
- Отслеживание и корректировка результатов после запуска рекламной кампании.

- Детальный анализ работы ключевых слов в Яндекс.Метрике.
Делаете всё по инструкции, но что-то не получается?
Специалисты агентства eLama готовы помочь — оставляйте заявку, мы вам перезвоним.
Оставить заявку
Как узнать количество запросов гугл или яндекс?
Статистика ключевых слов — это, по сути, база данных, которая содержит в себе информацию об обращениях пользователей к поисковой системе за определенный период времени. Каждый вебмастер или владелец ресурса в интернете стремится добавить на свой сайт только самые топовые ключевые слова, по которым запросов у пользователей больше всего. Очевидно, это делается для того, чтобы ресурс ранжировался выше, а продвижение было успешнее.
Однако не стоит забывать, что переспам ключевых запросов может привести к бану сайта. Поисковая система (например Google) ведет борьбу за рынок и клиентов так же, как и любой другой бизнес, поэтому интересы пользователя для нее на первом месте. Если человек ввел в поисковую строку определенный запрос и перешел по ссылке из выдачи, а потом резко покинул сайт и снова ввел тот же запрос — система понижает такой сайт, так как считает этот ресурс нерелевантным.
Если человек ввел в поисковую строку определенный запрос и перешел по ссылке из выдачи, а потом резко покинул сайт и снова ввел тот же запрос — система понижает такой сайт, так как считает этот ресурс нерелевантным.
Ключевые запросы пользователей
Так как же узнать количество запросов пользователей, равномерно распределить их по страницам своего ресурса и привести в свой бизнес толпы платежеспособных клиентов? Давайте разбираться вместе!
Каждый собственник, начиная свое дело, определяет ключевые слова и запросы, которые соответствуют его бизнесу. Это тот фундамент, на котором будет строится дальнейшее продвижение в интернете.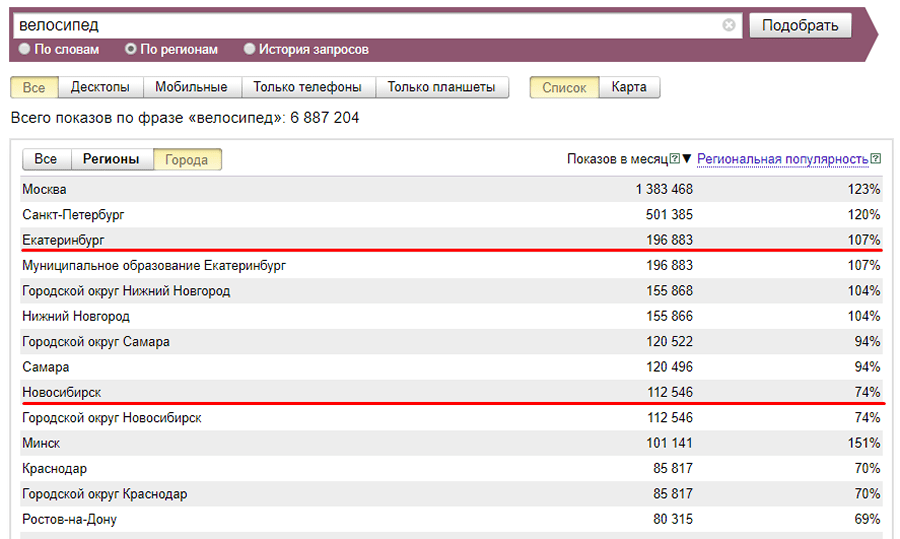
Как вы знаете, принято подразделять все поисковые запросы на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ). А также на высококонкурентные (ВК), среднеконкурентные (СК) и низкоконкурентные (НК).
Разумеется, лучшим вариантом будет размещение на вашем ресурсе высокочастотного и одновременно несколько низко- или среднечастотных запросов с одной тематики. Обычно высокочастотные — это высококонкурентные запросы, среднечастотные — среднеконкурентные и т.д. Но встречаются случаи, когда низкочастотный запрос является высококонкурентным. Мы уже писали ранее, о том как подобрать ключевые слова для сайта.
Где искать статистику запросов?
Где посмотреть количество запросов пользователей? Непосредственно, в самой поисковой системе.
Как видно из скрина выше, вы можете увидеть частоту запросов пользователей за последний месяц.
Более детально о том, где взять и как использовать статистику google запросов — читайте здесь.
Кроме планировщика Гугл, вы можете узнать количество запросов для формирования семантического ядра из другого инструмента — ЯндексВордстат. Этот инструмент позволит вам быстро и бесплатно узнать количество запросов Яндекс для русскоязычного интернета.
Безусловно, есть и другие инструменты, которые помогают осуществить подбор ключевых слов для сайта онлайн.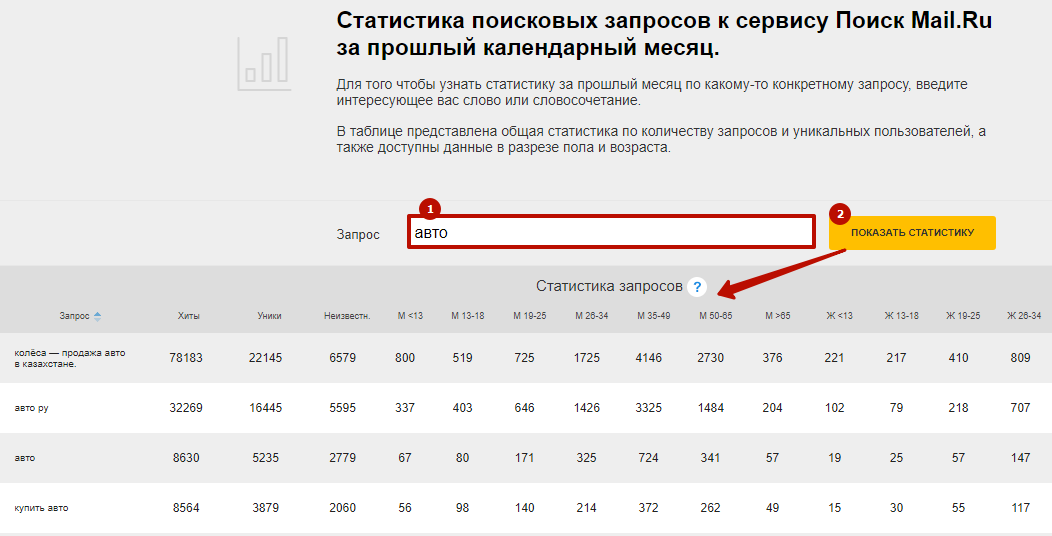
Полученная с помощью этих инструментов статистика запросов по словам поможет привлекать на ваш ресурс пользователей, которые ищут товары или услуги, которые вы предлагаете. Таким образом, вы сможете расширить семантическое ядро, и, грамотно распределив его по страницам сайта, получать клиентов из органической выдачи.
Именно статистика ключевых слов говорит о том, насколько товар или услуга популярна в сети, как часто люди взаимодействуют с ней, и по каким именно ключевым словам и словоформам пользователи ищут ту или иную информацию и, в результате, посещают те или иные сайты. Располагая этой статистикой, вы сможете выстроить поток клиентов в свой бизнес (если вы Собственник) или в бизнес клиента (если Вы вебмастер).
Очень важно понимать, что грамотное использование статистики ключевых слов в поисковых системах – одна из ключевых составляющих при оптимизации сайта. Посетители, которые зайдут по одним или другим поисковым запросам, должны получить ту информацию, на которую они рассчитывали. Только в этом случае они захотят вернуться на ваш ресурс.
Посетители, которые зайдут по одним или другим поисковым запросам, должны получить ту информацию, на которую они рассчитывали. Только в этом случае они захотят вернуться на ваш ресурс.
Как посмотреть статистику запросов в Google Ads
Статистика запросов в Гугл интересует многих владельцев бизнеса. Ведь от конкуренции на рынке зависит и стоимость контекстной рекламы, и выбор рекламной площадки, и количество клиентов. Поэтому в сегодняшнем материале мы поговорим о том, как посмотреть количество запросов по ключевым словам в Гугл Адвордс и расскажем, как полученные данные можно использовать во благо компании.
На что влияет статистика поисковых запросов в Google Adwords
Частотность ключевого запроса в Google — это то, сколько раз потенциальные клиенты ищут определённые фразы и слова. Как правило в расчёт берутся данные за месяц. При помощи частотности можно:
- Узнать популярность конкретной сферы и спрогнозировать потенциальный успех продвижения.
- Собрать с нуля или усовершенствовать имеющееся семантическое ядро.
- Выбрать регион продвижения. Например, найти город, в котором меньше конкурентов и продвигать услугу/товар в нём, что поможет снизить расходы на рекламу. Этот пункт релевантен для компаний, оказывающих услуги в онлайн-формате.
- Учесть уровень конкуренции и создать качественную контекстную рекламу, оптимизировав её стоимость.
Как и где узнать статистику ключевых запросов Google Ads
В Google есть три варианта, которые помогут с составлением семантического ядра. Далее поговорим о каждом из них и расскажем об их особенностях.
Планировщик ключевых слов
У русскоязычного конкурента Google — Яндекс, есть специальный инструмент для оценки популярности — Вордстат. Он даёт пользователю возможность оценить количество запросов по различным ключевым фразам. О том, как посмотреть статистику в этом поисковике можно прочитать в нашем материале.
У Google нет отдельного инструмента для подобных целей. Однако внутри сервиса контекстной рекламы Google Ads есть «Планировщик ключевых слов». Этот инструмент поможет увидеть все нужные данные по аналогии с Wordstat. При этом запускать контекстную кампанию не обязательно, достаточно просто иметь аккаунт в рекламном кабинете.
Однако внутри сервиса контекстной рекламы Google Ads есть «Планировщик ключевых слов». Этот инструмент поможет увидеть все нужные данные по аналогии с Wordstat. При этом запускать контекстную кампанию не обязательно, достаточно просто иметь аккаунт в рекламном кабинете.
Чтобы посмотреть статистику перейдите на главную страницу сервиса. В горизонтальном меню найдите пункт «Инструменты и настройки». Планировщик отобразится в первом вертикальном столбце.
Далее предстоит выбрать один из двух пунктов. Если у вас уже есть готовый список ключевых слов, выбирайте второй квадрат. С его помощью можно будет узнать статистику по имеющимся ключевикам. В нашем примере мы предположим, что вы только начинаете настройку кампании и ещё не подготовили базовый перечень запросов. Нажимаем на первый пункт и приступаем к анализу.
В отобразившемся поле указываем ключевые слова. Мы рассмотрим статистику по запросам «Диван-кровать» и «Круглый диван». Не забудьте указать интересующий регион показов.
В отразившейся статистике будет приведено количество запросов по указанным нами словам. Также Google предложит расширить поиск дополнительными ключевиками. Их можно увидеть в верхней части страницы.
Также система подберёт комбинации, которые помогут составить семантическое ядро рекламной кампании. В отчёте будут представлены ключевики с различным уровнем конкуренции. За счёт этого можно будет подобрать менее популярные запросы с меньшей стоимостью за 1 клик.
«Планировщик ключевых слов» поможет расширить имеющийся список. Например, если вы сделали черновой вариант списка ключевых слов и добавили его в пустое поле планировщика, система подскажет дополнительные варианты словосочетаний. Дополнит фразы часто употребляемыми словами в контексте вашей сферы. Это может принести дополнительные комбинации с другой частотностью, которые окажутся дешевле для показов.
Отображенная информация будет содержать минимальную и максимальную стоимость показа объявления по указанным ключевым запросам.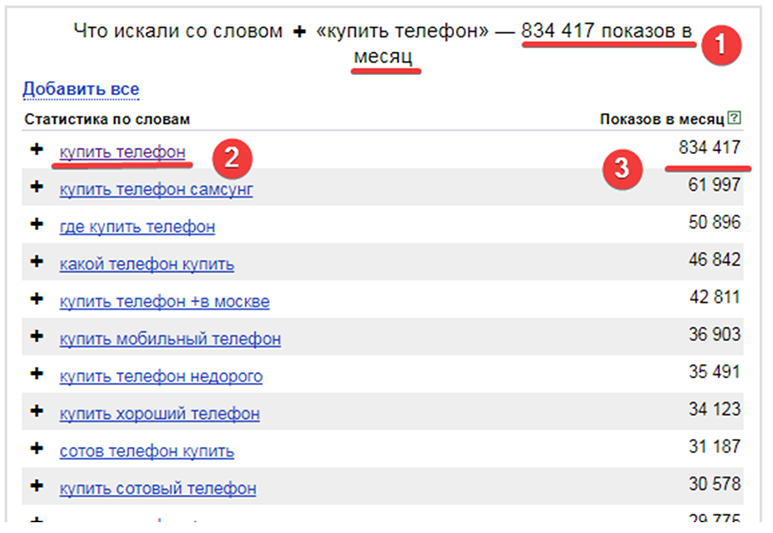 Также можно будет настроить временной интервал, за который вы хотите посмотреть статистику. Полученные данные являются примерными. По ним получится узнать только основную информацию о конкуренции в вашей сфере.
Также можно будет настроить временной интервал, за который вы хотите посмотреть статистику. Полученные данные являются примерными. По ним получится узнать только основную информацию о конкуренции в вашей сфере.
Google Trends
Данный инструмент рассказывает о трендах в определенной категории товаров и услуг. Гугл Трендc не даст точных цифр, но расскажет о динамике популярности. Например, введя запрос «Школьная форма», можно увидеть, как меняется спрос на эту одежду к началу учебного года.
В статистике можно изменить временной интервал предоставляемых данных. Это поможет отследить популярность определённых запросов не только в разрезе одного месяца или года, а даже за несколько лет. Полученная статистика даст понимание, когда лучше запускать рекламную кампанию для получения наибольшей прибыли.
Google Analytics
Инструмент статистики Google не поможет собрать новые ключевые запросы. Но поможет проанализировать целесообразность использования уже имеющихся ключевых фраз.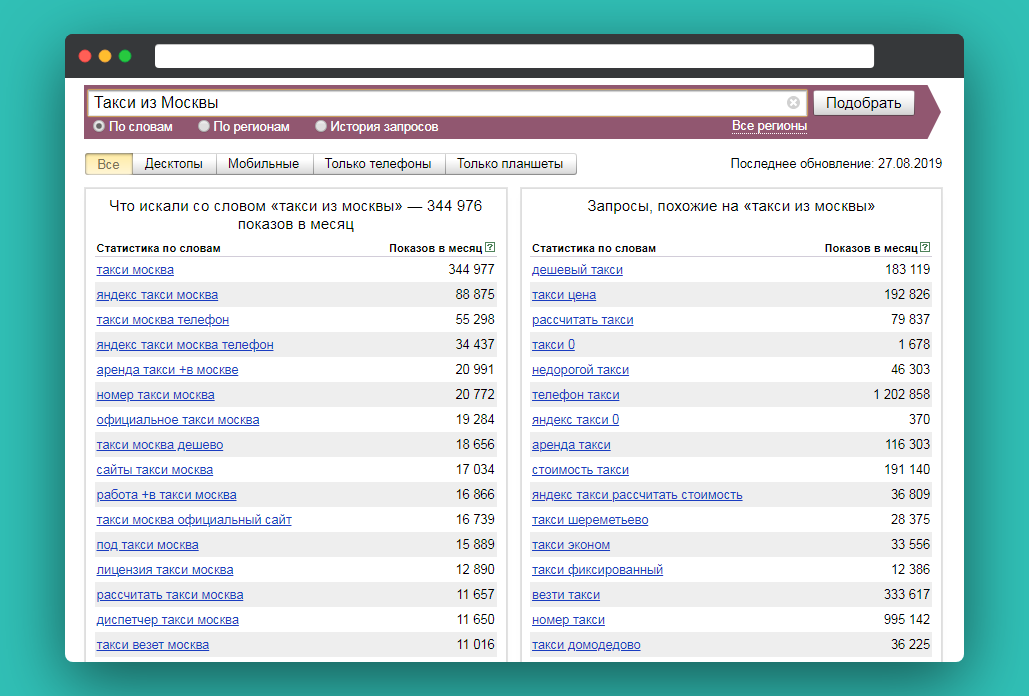 О том, как настроить Google Analytics мы пишем в этой статье. Если вы планируете использование Google Ads, обязательно прочитайте материал — наличие системы аналитики является неотъемлемым атрибутом успешной рекламной кампании.
О том, как настроить Google Analytics мы пишем в этой статье. Если вы планируете использование Google Ads, обязательно прочитайте материал — наличие системы аналитики является неотъемлемым атрибутом успешной рекламной кампании.
А пока мы предположим, что у вас уже всё настроено и покажем, где посмотреть запросы. В вертикальном меню слева выберите пункт «Источники трафика». Отчёт «Запросы» что вводили пользователи в поисковик перед тем, как попали на ваш сайт.
А произведя интеграцию с Google Ads вы сможете отслеживать популярность запросов в запущенных рекламных кампаниях. Чтобы это сделать, перейдите в пункт «Google реклама».
Дополнительные методы сбора статистики по ключевым запросам
Статистику по запросам Google можно узнать и при помощи других методов, которые могут упростить работу с рекламными кампаниями. О некоторых из мы и поговорим далее.
Сервисы для подбора ключевых слов
Упростить процесс подбора ключевых слов может специальный сервис. Вам не придётся составлять списки слов самостоятельно и сравнивать полученные данные. Тут фразы можно группировать, автоматически сортировать и смотреть удобные отчеты. Например, Key Collector покажет не только статистику по запросам в Google, но и поможет организовать структуру рекламной кампании для любой площадки контекстной рекламы.
Тут фразы можно группировать, автоматически сортировать и смотреть удобные отчеты. Например, Key Collector покажет не только статистику по запросам в Google, но и поможет организовать структуру рекламной кампании для любой площадки контекстной рекламы.
Сервисы сквозной аналитики
Сквозная аналитика может передавать данные не только по статистике показов в Google и не только по контекстной рекламе. Тут вы можете собрать абсолютно все данные по любым каналам. Это удобно тем, что вы получаете наглядный дашборд со всеми данными одновременно. Нет необходимости вручную сводить множество разрозненных данных.
Успешный старт рекламной кампании: что для этого нужно
Первое, что стоит сделать перед запуском рекламной кампании в Google Ads — это посмотреть статистику. Если запрос будет слишком популярным, то стоимость продвижения может оказаться нецелесообразно высокой. Поэтому важно собрать ключевые слова таким образом, чтобы они пошли на пользу вашему бизнесу.
Как именно вы будете смотреть статистику запросов: при помощи планировщика ключевых слов, инструмента Trends или при помощи сторонних сервисов, не имеет значения. При выборе способа стоит руководствоваться его удобством именно для вас.
При выборе способа стоит руководствоваться его удобством именно для вас.
Основная задача процедуры по сбору статистики — получение данных, которые расскажут вам о трендах на вашем рынке. И уже на основании этих трендов необходимо составлять семантику рекламной кампании.
На данном этапе не стоит забывать о специфике словообразования Google. Обязательно используйте операторы, чтобы поисковик понял вас именно так, как вы хотите.
Для повышения эффективности маркетингового продвижения через Ads стоит позаботиться не только о списке ключевых запросов, но и о качестве объявлений и сайта. А именно:
- Обратите внимание на релевантность объявлений. Важно показывать потенциальным клиентам только то, что они хотят увидеть. Если пользователь спрашивает у Google где ему купить бесшумный электрический чайник, то он с наибольшей вероятностью нажмёт на рекламу с аналогичным заголовком. Поэтому разбейте ключевые слова на группы и составьте для каждой из них отдельное объявление.
- Помимо качественного объявления также необходим привлекательный, понятный и информативный сайт. Система Google также учитывает это при показах рекламных объявлений. Если ресурс будет неинформативен для пользователя, то поисковик может поднять вам цену за клик. А ваш конкурент с более удобным ресурсом будет показан выше в рекламной выдаче.
- Ваш сайт должен соответствовать рекламному объявлению. Клиент, который искал электрические чайники и кликнул по соответствующему объявлению, ждёт от вашего сайта предложения подобных чайников. Если он увидит страницу со всеми товарами каталога, а не только с чайниками, он может разочарованно закрыть страницу. А AdRank, то есть показатель качества рекламы — снизится.
- Сайт должен быть удобен и быстро загружаться. Также он должен содержать всю необходимую информацию о товарах и о вашей компании.

Так что сбор ключевых слов — это важный этап рекламной кампании. Однако помимо этого необходимо обратить внимание на то, как формируется стоимость рекламы в Google.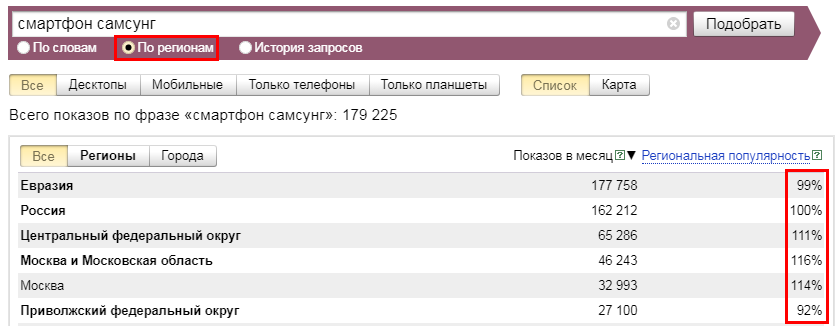
Не забудьте и о важных деталях в настройке Google Ads. Их никак нельзя упускать!
Статистика Google и Яндекс Wordstat
Почему важно знать статистику запросов
Помимо анализа аудитории, просмотр популярных запросов помогает понять, какая информация интересует пользователей больше всего. Опираясь на эти данные, вы сможете уточнить УТП, выделить преимущества и подготовить убедительный оффер.
Сбор статистики необходим для:
- Разработки стратегии продвижения сайта в поиске.
- Создания семантического ядра.
- Подбора фраз для запуска контекстной рекламы.
- Написания продающих текстов.
- Проработки новых страниц.
- Оценки сезонности спроса.
Продажи во многом зависят от популярности бренда. С повышением видимости страниц в поиске, вы привлекаете больше трафика на сайт. Чтобы получить целевых посетителей, необходимо определить часто задаваемые запросы, продумать, какие потребности вы закрываете вашим продуктом, и подготовить соответствующий контент. Со статистикой запросов по ключевым словам вы сможете сделать каждый этап работы над продвижением эффективнее.
Со статистикой запросов по ключевым словам вы сможете сделать каждый этап работы над продвижением эффективнее.
Как посмотреть статистику
Проводить мониторинг и регулярно узнавать статистику запросов Яндекс и Гугл можно с помощью их систем аналитики. У каждого сервиса – свой функционал и набор инструментов.
Yandex
Есть несколько полезных инструментов, которые помогают работать со статистикой.
Wordstat
Найти наиболее частые запросы в Яндексе можно с помощью инструмента Wordstat (Вордстат). Зарегистрируйтесь и зайдите в систему. После этого вы сможете ввести в строку поиска ключевые слова. В результате выдается список фраз и количество показов рекламы по каждой из них в месяц.
Обратите внимание, что объем трафика по самому широкому запросу включает в себя уточнения. Это значит, что статистика «лучшие кофейни» включает в себя и показы с пометками «Москвы», «Петербурга», «Спб» и т.д. Справа показываются похожие ключевики. В этом списке Wordstat выдает вариации формулировок, которые пользователи вводят в поиске.
Статистика запросов Yandex фильтруется по устройствам и локализации. Например, если вы ориентируетесь на мобильный трафик, вы можете смотреть данные только для телефонов. Нажав на кнопку «Все регионы» под строкой поиска, вы увидите окно с выбором нужных федеральных округов, областей или городов:
Отметив опцию «по регионам», вы получите информацию о популярности фразы в разных точках страны и мира. Этот показатель измеряется в процентах. За основу берется средний показатель и отмечается как 100%: колебания демонстрирует повышенную или пониженную заинтересованность. Наглядно это можно увидеть на карте:
История запросов сервиса Wordstat – это третья доступная опция, которая помогает отследить динамику изменения интересов пользователей по фразам. Например, «кофейни с верандами» популярны с мая по сентябрь, что отчетливо видно на графике.
Это поможет оценить сезонность и лучше спланировать маркетинговые кампании. Инструмент может показывать статистику Wordstat по месяцам или неделям, что позволяет точнее прогнозировать всплески спроса на продукцию.
Вебмастер
Статистика Яндекс Wordstat – не единственный инструмент для анализа ключевиков. Вебмастер – второй полезный сервис, который помогает:
- анализировать, по каким фразам показывается ваш сайт;
- выявить наиболее популярные страницы;
- проводить мониторинг трендов.
Здесь же вы можете оставить заявку на подбор «рекомендованных запросов», чтобы поднять эффективность продвижения.
Директ
Популярные поисковые запросы в Яндексе можно найти и через инструмент для создания контекстной рекламы. Чтобы упростить работу, скачайте Директ.Коммандер. Он позволяет составлять списки нужных ключевиков, выбирать нужные регионы и отслеживать статистику. С его помощью можно собрать семантическое ядро, чтобы не копировать фразы вручную.
Посмотреть количество запросов в Гугле сложнее, чем в Яндексе. Здесь нет аналога Wordstat, поэтому необходимо сразу заходить в аналог Директа для запуска контекстной рекламы – Google Adwords.
Adwords
Хотя специалисты отмечают сложность интерфейса для новичков, если вы знаете, что ваша аудитория предпочитает эту поисковую систему, лучше работать с ключевиками именно здесь. На практике вы быстро разберетесь с алгоритмом работы с этим инструментом. Более того, система поможет подобрать фразы конкретно под ваш сайт. Чтобы получить статистику, необходимо завести аккаунт и создать рекламный кабинет.
После входа в рекламный кабинет необходимо найти «Планировщик ключевых слов», который находится в разделе инструментов и настроек.
В открывшемся окне появится выбор: найти новые ключевые слова или посмотреть количество запросов и прогнозов. Если у вас уже собрано семантическое ядро или есть готовый список фраз, вам нужен второй вариант, а для работы с чистого листа воспользуйтесь первым.
Запросы по ключевым словам в Гугле можно подбирать самостоятельно, как в Wordstat, вводя разные формулировки в строку поиска. А можно просто указать свой сайт, система проанализирует содержимое и выдаст готовый список под ваш бизнес, который вы сможете подкорректировать позже.
Интерфейс системы выглядит сложнее, но работать с ним удобно, потому что все функции под рукой. Так, например, вы одним кликом сможете скачать варианты ключевиков. На основе ваших слов, система предлагает расширить поиск или, наоборот, уточнить фразы.
В отличие от Яндекс, Google не выводит точные данные по показам. В таблице указывается только средний разброс в месяц. С другой стороны, выводятся данные по уровню конкуренции, что позволяет лучше спланировать стратегию в SEO и для контекстной рекламы.
Чтобы лучше ориентироваться при большом количестве вариантов, платформа предлагает фильтры. Так вы можете отключить «контент для взрослых», указать размер ставки, исключить отдельные слова и т.д.
Статистика по запросам за неделю здесь недоступна, зато можно гибко указывать диапазоны по месяцам. Чтобы собрать СЯ, отмечайте галочками нужные фразы и добавляйте их в план. В результате вы сможете собрать удобный список, группировать ключевики по темам и скачать это удобном для вас формате.
Учитывайте, что показатели будут меняться, исходя из статистики рекламной кампании. Данные выдаются усреднено, чтобы показать, чего ожидать при запуске объявлений.
Trends
Узнать историю запросов в динамике можно с помощью сервиса Google Trends. Эта платформа позволяет отслеживать наиболее сильные тенденции, выявлять сезонность, сравнивать показатели в разных местах и многое другое.
Помимо распределения популярности темы по странам и регионам, система предлагает наглядные графики и сразу выводит топ наиболее трендовых тематик.
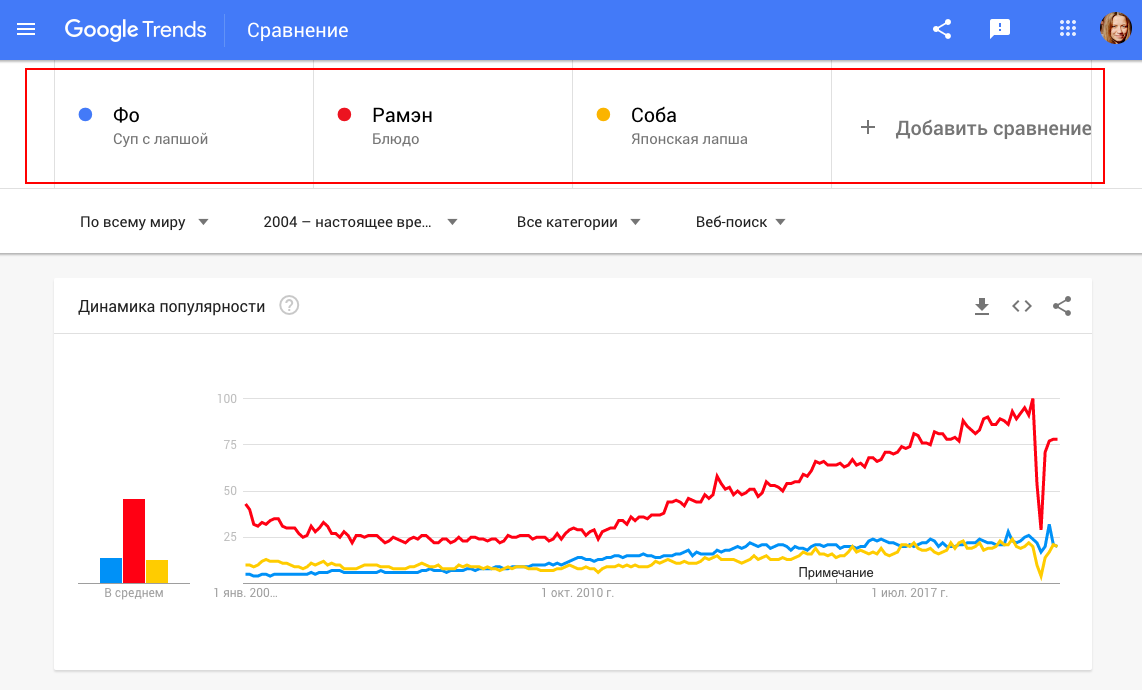
Введите ключевое слово или словосочетание в строку поиска, чтобы получить динамику за год.
На этом примере типичный сезонный бизнес: обычно купальники интересуют людей больше в летнее время. Но на графике отчетливо виден еще один небольшой подъем во время зимних каникул – это может оказаться полезной информацией.
Если продажи не так привязаны к сезону, то можно воспользоваться другими функциями. Например, можно сравнить популярность двух разных слов:
Помимо этого, вы можете посмотреть заинтересованность пользователей по регионам, как в Wordstat:
Далее идут похожие запросы и тренды по теме. Здесь можно найти много инсайтов для бизнеса. Например, наиболее популярный запрос в сфере – «кофе дальгона». Для продвижения кофейни, можно воспользоваться этой фразой, чтобы привлечь посетителей попробовать этот напиток. А еще можно узнать, что это за «кофе из тик тока» и предложить его своей аудитории.
Чтобы точнее определять статистику поисковых запросов в Google Trends, пользуйтесь операторами и фильтрами. Вы можете выбрать точную локализацию запроса, категорию и диапазон дат. Если в Яндексе статистика доступна только за последние 2 года, то здесь графики с 2004 года. Отдельно можно фильтровать результаты по типу поиска: картинки, товары, новости и YouTube. Инструмент полезен не только для маркетологов, но и для СМИ, блогеров и других специалистов, работающих в онлайн-сфере.
Полезные инструменты
Точно определить количество поисковых запросов вручную бывает сложно. В некоторых сферах списки ключевиков включают в себя тысячи фраз, поэтому процесс лучше автоматизировать. Упростить работу помогут следующие сервисы:
KeyCollector
Инструмент помогает оценивать фразы, определять релевантные страницы, анализировать сайт на соответствие поиску и выдает соответствующие рекомендации по улучшению показателей. Работает на данных Wordstat, упрощая аналитику.
Serpstat
Узнать определенное число запросов в Google и Яндекс с их частотностью можно с помощью сервиса Serpstat. Одна из наиболее полезных функций – возможность посмотреть, какие ключевики используют конкуренты. Платформа помогает собирать семантическое ядро, давая подсказки и предлагая похожие по смыслу фразы.
Магадан
Сбор слов, возможность объединять их в группы и создавать свои фильтры – все эти функции доступны в парсере Магадан. В отличие от большинства сервисов, многие инструменты можно использовать бесплатно.
Ahrefs
Помимо базовой работы с семантикой, эта платформа помогает анализировать статистику по кликам, отслеживать прогресс продвижения в поиске и собирать данные о конкурентах. Также сервис показывает лучший контент в вашей сфере, что помогает создавать привлекательные для потенциальных покупателей материалы.
Be1
Простой по функционалу, бесплатный сервис, который помогает провести SEO-анализ страниц. Сам подбирает ключевые слова и выводит в таблице данные по позиции сайта в поиске, количество запросов в месяц и эффективность показов.
Опираясь на инструкции из этой статьи, вы сможете легко научиться работать с ключевыми словами на любом этапе развития вашего бизнеса. Подпишитесь на обновления, чтобы получать уведомления о новых публикациях по теме.
Закажи юзабилити-тестирование прямо сейчас
Заказать
Отчеты и аналитика производительности CDN | Amazon CloudFront
Разрешите ведение журналов доступа CloudFront, чтобы больше узнать о трафике
CloudFront генерирует журналы, в которых содержится подробная информация о каждом полученном и отвеченном запросе. По сути эти журналы равноценны журналам веб-сервера и предоставляются в таком же формате W3C, но они также содержат дополнительные специальные данные о сервисе CloudFront. Журналы CloudFront могут быть очень полезными для изучения тенденций производительности и использования, а также для изолирования потенциальных ошибок или оптимизации конфигурации.
В CloudFront доступно два способа ведения журналов запросов от дистрибутивов: стандартные журналы и журналы в режиме реального времени.
Стандартные журналы CloudFront доставляются в выбранную корзину Amazon S3 (записи журналов доставляются за считаные минуты после запроса пользователя). После активации CloudFront публикует подробные данные журнала в расширенном формате W3C в указанную корзину Amazon S3. Журналы доступа содержат подробные сведения о каждом запросе контента, включая название объекта, дату и время запроса, периферийное местоположение, обслужившее запрос, IP‑адрес клиента, источник ссылки, пользовательский агент, заголовок cookie и тип результата (например, для кэша: hit, miss или error). За стандартные журналы CloudFront не взимается плата, но хранение файлов журналов и доступ к ним оплачиваются по тарифам Amazon S3.
Журналы CloudFront в режиме реального времени доставляются в выбранный поток данных Amazon Kinesis Data Streams (записи журналов доставляются за считаные секунды после запроса пользователя). Вы можете выбрать частоту дискретизации журналов в режиме реального времени, то есть процент запросов, для которых в журнал добавляются записи. Вы также можете выбрать конкретные поля, которые будут включаться в записи журнала. Журналы CloudFront в режиме реального времени содержат те же точки данных, что и стандартные журналы, а также дополнительную информацию о каждом запросе, например заголовки запросов пользователей и код страны в расширенном формате W3C. За использование журналов CloudFront в режиме реального времени взимается плата вдобавок к стоимости использования Kinesis Data Streams.
Подробнее о файлах журналов CloudFront »
статистика поисковых запросов Яндекса и Google, Wordstat Yandex
Статистика запросов — это база данных, которая содержит в себе информацию об обращениях пользователей к поисковой системе по «ключевым фразам». При работе с подобными системами статистики можно группировать результаты по географическому положению или даже по отдельно взятому языку, а иногда и по месяцам. В большинстве случаев сервисы показывают информацию не только об искомой фразе, но и о словосочетаниях и синонимах.
Системы статистики поисковых запросов есть у многих крупных поисковых систем, так, к примеру, у Яндекса — Wordstat, у Google – Trends. Основная цель подобных баз данных – это предоставление информации для заинтересованной в контекстной рекламе целевой аудитории. Если вы используете перечисленные инструменты для составления семантического ядра, то надо учитывать, что подобные системы показывают число показов результатов поисковой выдачи, но никак не количество переходов по запросам.
Статистика поисковых запросов Яндекса
Wordstat (Вордстат) – это база данных с информацией о количестве показов результатов выдачи в поиске Яндекса. Особенностью системы является то, что она склеивает всевозможные словоформы, при этом чаще всего не учитывая предлоги и иные формы слова.
Статистику поисковых запросов Яндекса стоит использовать ещё и потому, что она приводит не только производные от введенных ключевых слов, но и ассоциативные запросы, которые пользователи искали вместе с интересующими вас запросами. Такой функционал способствует существенному расширению семантического ядра (колонка справа — «Запросы, похожие на…»).
Вкладка «По словам» содержит общую информацию о числе показов конкретных поисковых фраз. Используя же вкладку «по регионам», вы всегда сможете определить частность этой ключевой фразы в том или ином регионе поиска.
Для того чтобы отследить частоту спроса по интересующему запросу за определенный период, можно использовать вкладки с группировкой данных «по месяцам» и «по неделям». Особенно эта информация будет актуальна для сезонных запросов.
При учете всех возможностей, которые предоставляет статистика ключевых слов, и грамотном использовании предоставляемых ею инструментов, сервис становится важнейшей составляющей, которую используют большинство вебмастеров и SEO-специалистов при составлении семантического ядра для сайта.
Статистика запросовв реальном времени — SQL Server
- 2 минуты на чтение
В этой статье
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure
SQL Server Management Studio предоставляет возможность просматривать план выполнения активного запроса в реальном времени. Этот план запроса в реальном времени дает представление о процессе выполнения запроса в режиме реального времени, поскольку элементы управления переходят от одного оператора плана запроса к другому.План запроса в реальном времени отображает общий ход выполнения запроса и статистику выполнения на уровне оператора, такую как количество созданных строк, затраченное время, ход выполнения оператора и т. Д. Поскольку эти данные доступны в режиме реального времени без необходимости ждать, пока запрос будет В целом, эта статистика выполнения чрезвычайно полезна для устранения проблем с производительностью запросов. Эта функция доступна, начиная с SQL Server 2016 (13.x) Management Studio, однако может работать с SQL Server 2014 (12.x).
Применимо к : SQL Server (начиная с SQL Server 2014 (12.x)) и База данных SQL Azure.
Предупреждение
Эта функция в первую очередь предназначена для устранения неполадок. Использование этой функции может умеренно снизить общую производительность запросов, особенно в SQL Server 2014 (12.x). Дополнительные сведения см. В разделе Инфраструктура профилирования запросов.
Эту функцию можно использовать с отладчиком Transact-SQL.
Для просмотра статистики запросов в реальном времени для одного запроса
Чтобы просмотреть план выполнения оперативного запроса, в меню инструментов щелкните значок Включить статистику оперативного запроса .
Вы также можете просмотреть доступ к плану выполнения оперативного запроса, щелкнув правой кнопкой мыши выбранный запрос в Management Studio и выбрав Включить статистику оперативного запроса .
Теперь выполните запрос. План оперативного запроса отображает общий ход выполнения запроса и статистику выполнения во время выполнения (например, прошедшее время, ход выполнения и т. Д.) Для операторов плана запроса. Информация о ходе выполнения запроса и статистика выполнения периодически обновляются во время выполнения запроса.Используйте эту информацию, чтобы понять общий процесс выполнения запроса и отладить долго выполняющиеся запросы, запросы, которые выполняются бесконечно, запросы, вызывающие переполнение базы данных tempdb, и проблемы с тайм-аутом.
Для просмотра статистики запросов в реальном времени для любого запроса
К живому плану выполнения также можно получить доступ из монитора активности , щелкнув правой кнопкой мыши любой запрос в таблице Процессы или Активные дорогие запросы .
Замечания
Инфраструктура профиля статистики должна быть включена, прежде чем статистика запросов в реальном времени сможет собирать информацию о ходе выполнения запросов.В зависимости от версии накладные расходы могут быть значительными. Дополнительные сведения об этих накладных расходах см. В разделе Инфраструктура профилирования запросов.
Разрешения
Требуется разрешение уровня базы данных SHOWPLAN для заполнения страницы результатов Live Query Statistics , а также любые разрешения, необходимые для выполнения запроса.
В SQL Server требуется разрешение уровня сервера ПРОСМОТР СОСТОЯНИЯ СЕРВЕРА для просмотра статистики в реальном времени.
На уровнях базы данных SQL Premium требуется разрешение VIEW DATABASE STATE в базе данных для просмотра статистики в реальном времени.На уровнях базы данных SQL Standard и Basic требуется учетная запись администратора Server или администратора Azure Active Directory для просмотра статистики в реальном времени.
См. Также
Планы выполнения
Руководство по архитектуре обработки запросов
Мониторинг и настройка производительности
Инструменты мониторинга и настройки производительности
Открыть монитор активности (SQL Server Management Studio)
Монитор активности
Мониторинг производительности с помощью хранилища запросов
sys.dm_exec_query_statistics_xml
sys.dm_exec_query_profiles
Флаги трассировки
Справочник по логическим и физическим операторам Showplan
Инфраструктура профилирования запросов
Устранение неполадок производительности SQL-запросов с помощью SQL Server 2016 Live Execution Statistics
SQL Server Management Studio — графический интерактив, который позволяет вам взаимодействовать с базами данных, размещенными на ваших серверах. SSMS предоставляет вам возможность писать, редактировать, выполнять, анализировать и отслеживать ваши SQL-запросы.Это также помогает администраторам баз данных ответить на важные вопросы о производительности SQL-запросов, например, почему запрос выполняется медленно или почему не используется индекс. Ответ на эти вопросы можно найти, просто отслеживая план выполнения запроса.
План выполнения запроса — это графическое отображение дорожной карты выполнения запроса, за которым следует оптимизатор запросов SQL Server, определяющий стоимость выполнения каждого фрагмента кода в запросе. Планы выполнения могут быть представлены также в формате XML, заданном командами SET SHOWPLAN_ALL, SET SHOWPLAN_TEXT или SET SHOWPLAN_XML.
Прежде чем углубляться в типы планов выполнения и новую функцию Live Execution Plan, которая является основным предметом нашей статьи, давайте кратко опишем, как выполняются запросы SQL Server.
При отправке запроса SQL будет проверяться синтаксис запроса, чтобы убедиться, что он написан в правильном формате, в процессе, называемом Анализ запроса . Логические шаги, необходимые для выполнения запроса, являются результатом этого процесса синтаксического анализа.Выходные данные процесса синтаксического анализа будут переданы в Algebrizer , который отвечает за разрешение различных имен объектов в базах данных, используемых в запросе. После того, как все имена объектов разрешены, оптимизатор запросов SQL Server Query Optimizer вступает во владение. Оптимизатор запросов отвечает за определение наилучшего способа выполнения отправленного запроса путем создания множества планов выполнения кандидатов и выбора запроса с наименьшей стоимостью с точки зрения потребления ресурсов ЦП, памяти и ввода-вывода, а также времени, необходимого для выполнения запроса.Находя наиболее оптимальный компромисс между этими факторами, можно сгенерировать наиболее эффективный план выполнения. Оптимизатор запросов SQL Server зависит от SQL Server Statistics , который описывает распределение данных и индексы и метаданные в базе данных, чтобы принять это решение. Как только оптимизатор запросов сгенерирует лучший план, он сохранит его в хранилище Plan Cache . Теперь этот план будет использоваться механизмом SQL Storage Engine для выполнения запроса и извлечения запрошенных данных или управления ими.
SQL Server Management Studio может отображать два основных типа планов выполнения; План Предполагаемого выполнения , который показывает приблизительные шаги выполнения, сгенерированные анализом запроса без его выполнения, и План Фактического выполнения , который показывает реальные шаги, выполняемые при выполнении запроса, который требует выполнения запроса перед созданием этого плана. В некоторых случаях вы можете заметить разницу между фактическим и предполагаемым планами выполнения из-за разницы между статистикой SQL Server и фактическими данными, которую можно устранить, обновив статистику базы данных.
В SQL Server 2016 представлена новая функция, которая позволяет просматривать статистику выполнения Live Execution Statistics для вашего активного запроса, показывая статистику выполнения во время выполнения для каждого оператора плана выполнения, такую как количество строк, время, необходимое для каждого оператора, и оператор и общий ход выполнения, не дожидаясь завершения выполнения запроса. Это позволяет отслеживать поток данных между операторами в режиме реального времени один за другим до завершения выполнения запроса.
Эта функция очень полезна при устранении проблем с производительностью плохих запросов с огромными планами выполнения, где будет сложно и отнимать много времени, чтобы определить часть, которая работает некорректно. Убедитесь, что у вас есть разрешение на уровне базы данных SHOWPLAN для создания плана статистики оперативного запроса, разрешение VIEW SERVER STAT , чтобы иметь возможность видеть оперативную статистику и, наконец, надлежащий доступ для выполнения вашего запроса.
SQL Server Management Studio позволяет активировать статистику запросов в реальном времени для вашего запроса разными способами:
На панели инструментов редактора SQL Server Management Studio SQL щелкните значок
, который будет включать в ваш запрос текущую статистику запроса следующим образом:Щелкните правой кнопкой мыши текст запроса и выберите параметр Включить динамическую статистику запросов из просматриваемого списка, как показано ниже:
Выберите меню Query в строке меню SQL Server Management Studio и выберите опцию Include Live Query Statistics следующим образом:
В мониторе активности SQL Server Management Studio щелкните правой кнопкой мыши активный запрос из списка Активный дорогостоящий запрос и выберите Показать план оперативного выполнения , как показано ниже:
После того, как функция Live Execution Statistics включена в вашем запросе с использованием одного из ранее упомянутых методов, запрос может быть запущен, и поток данных между операторами может быть отслежен в виде пунктирных линий во время выполнения и одной строчной стрелки, когда оператор обрабатывает завершено, время, затраченное каждым оператором, процент выполнения этих операторов, фактическое и расчетное количество строк, обработанных каждым оператором, и общий ход выполнения запроса, как показано на подробном рисунке ниже:
На приведенном ниже рисунке также показано, как статистика выполнения в реальном времени менялась со временем до завершения выполнения запроса:
Давайте рассмотрим простую демонстрацию, чтобы показать, как мы можем использовать преимущества Live Execution Statistics для отслеживания запроса, определения проблемы и повышения производительности SQL-запросов.Предположим, что у нас есть приведенный ниже запрос из нашей базы данных SQLShackDemo, который выполняется очень часто и замедляет работу системы управления персоналом, и нам, как группе администрирования базы данных, предлагается выделить проблему и повысить производительность SQL-запроса. Чтобы начать устранение неполадок с этим запросом, мы запустим запрос после включения в нем функции Live Execution Statistics:
ИСПОЛЬЗОВАТЬ SQLShackDemo
GO
SELECT DEP.[DepartmentID]
, DEP. [Имя]
, DEP. [GroupName]
, DEP. [ModifiedDate]
FROM [SQLShackDemo]. [HumanResources]. [Department] DEP
JOIN [SQLShackDemo]. [SQLShackDemo]. HumanResources]. [EmployeeDepartmentHistory] EDH
ON DEP. [DepartmentID] = EDH. [DepartmentID]
где DEP. [GroupName] как «% качества» и DEP. [ModifiedDate] не как «1999-10-30»
Статистика Live Execution, полученная в результате выполнения запроса, будет следующей:
Как видно из предыдущего результата, оператор сканирования таблицы в таблице отдела является основной частью, которая замедляет запрос, поскольку он занимает больше времени, чем сканирование таблицы EmployeeDepartmentHistory, и читает больше записей, что ясно из предыдущего поток данных в реальном времени и результат ниже:
Чтобы улучшить проблему сканирования таблицы отдела, сам план выполнения предлагает отсутствующий индекс, который повысит производительность SQL-запроса на 99%, как показано зеленым на следующем снимке плана:
Щелкните план правой кнопкой мыши и выберите Сведения об отсутствующем индексе , чтобы отобразить сценарий для создания этого отсутствующего индекса.Отредактируйте имя индекса, чтобы оно соответствовало соглашению об именах вашей компании, затем запустите его, чтобы создать этот индекс. Сценарий создания индекса аналогичен приведенному ниже:
ИСПОЛЬЗОВАТЬ [SQLShackDemo]
GO
СОЗДАТЬ НЕКЛЮЧЕНЫЙ ИНДЕКС [IX_Department_DepartmentID]
НА [HumanResources]. [Department] ([DepartmentID])
INCLUDE ([Name], [GroupName]) [ModifiedDate]
ГО
Давайте снова запустим предыдущий запрос и снова проверим статистику выполнения в реальном времени, новый план будет выглядеть так:
Как видно из предыдущего плана, оператором сканирования таблицы отделов становится поиск индекса, а время оператора уменьшилось с 0.339 секунд до 0,07 секунд только. Вы также можете увидеть улучшение ввода-вывода после создания индекса, где фактическое количество строк, считываемых из отдела, уменьшилось с 6877 записей до всего лишь 32 записей, поскольку он будет читать из индекса напрямую без необходимости сканирования общая таблица. На приведенном ниже рисунке показано, что мы получаем от создания нового индекса для таблицы Department:
Заключение
Статистика выполнения SQL Server Live Execution Statistics — полезная функция, которая помогает устранять неполадки с производительностью SQL-запросов в режиме реального времени, а также выделять и исправлять части запросов с низкой производительностью, не дожидаясь завершения выполнения запроса.Вы можете рассчитать время и усилия, которые вы можете сэкономить при использовании этой функции для отладки ваших запросов, особенно тех с огромными планами выполнения, которые нелегко выделить самую дорогую часть, и тех, которые занимают много времени, чего вы не делаете нужно дождаться завершения выполнения, чтобы определить, где застрял запрос. Хотя функция Live Execution Statistics представлена в SQL Server 2016, ее можно запустить на SQL Server 2014 SP1 с помощью SQL Server 2016 Management Studio.
В функции Live Execution Statistics есть несколько ограничений, при которых вы можете использовать ее только для обычных таблиц, так как ее нельзя использовать для отслеживания таблиц, оптимизированных для памяти, таблиц с индексом ColumnStore или хранимых процедур, скомпилированных в собственном коде.
Ахмад Ясин (Ahmad Yaseen) — инженер Microsoft по большим данным с глубокими знаниями и опытом в областях SQL BI, администрирования баз данных SQL Server и разработки.Он является сертифицированным специалистом по решениям Microsoft в области управления данными и аналитикой, сертифицированным партнером по решениям Microsoft в области администрирования и разработки баз данных SQL, партнером разработчика Azure и сертифицированным инструктором Microsoft.
Кроме того, он публикует свои советы по SQL во многих блогах.
Посмотреть все сообщения от Ahmad Yaseen
Последние сообщения от Ahmad Yaseen (посмотреть все)
Статистика SQL Server и как выполнить обновление статистики в SQL
В этой статье дается пошаговое руководство по статистике SQL Server и различным методам выполнения статистики обновления SQL Server.
Введение
Статистика SQL Server необходима оптимизатору запросов для подготовки оптимизированного и экономичного плана выполнения.Эта статистика предоставляет оптимизатору запросов распределение значений столбцов и помогает SQL Server оценить количество строк (также известное как количество элементов). Оптимизатор запросов следует регулярно обновлять. Неправильная статистика может привести к тому, что оптимизатор запросов выберет дорогостоящие операции, такие как сканирование индекса вместо поиска по индексу, и может вызвать проблемы с высокой загрузкой процессора, памяти и ввода-вывода в SQL Server. Мы также можем столкнуться с блокировками, взаимоблокировками, которые в конечном итоге вызывают проблемы с базовыми запросами и ресурсами.
Параметры для просмотра статистики SQL Server
Мы можем просматривать статистику SQL Server для существующего объекта, используя как SSMS, так и метод T-SQL.
SSMS для просмотра статистики SQL Server
Подключитесь к экземпляру SQL Server в SSMS и разверните конкретную базу данных. Разверните объект (например, HumanResources.Employee), и мы сможем просмотреть всю доступную статистику на вкладке СТАТИСТИКА .
Мы также можем получить подробную информацию о любой конкретной статистике. Щелкните статистику правой кнопкой мыши и перейдите в свойства.
Он открывает свойства статистики и показывает столбцы статистики и дату последнего обновления для конкретной статистики.
Щелкните Подробности, и он покажет распределение значений и частоту появления каждого отдельного значения (гистограмма) для указанного объекта.
T-SQL для просмотра статистики SQL Server
Мы можем использовать DMV sys.dm_db_stats_properties для просмотра свойств статистики для указанного объекта в текущей базе данных.
Выполните следующий запрос, чтобы проверить статистику HumanResources.Таблица сотрудников.
SELECT sp.stats_id, name, filter_definition, last_updated, строк, rows_sampled, шагов, uniltered_rows, счетчик модификаций FROM sys.stats AS statOSS FROM sys.stats AS statOSS sys.dm_db_stats_properties (stat.object_id, stat.stats_id) AS sp ГДЕ stat.object_id = OBJECT_ID (‘HumanResources.Employee’); |
- Stats_ID: Это уникальный идентификатор объекта статистики.
- Имя : это имя статистики
- Last_updated: Это дата и время последнего обновления статистики.
- Строк: Показывает общее количество строк на момент последнего обновления статистики.
- Rows_sampled: Дает общее количество строк выборки для статистики.
- Unfiltered_rows: На скриншоте видно, что значения rows_sampled и unfiltered_rows одинаковы, потому что мы не использовали какой-либо фильтр в статистике.
- Modification_counter: Очень важно посмотреть столбец.Получаем общее количество модификаций с момента последнего обновления статистики
Различные методы для выполнения обновления статистики SQL Server
SQL Server предоставляет различные методы на уровне базы данных для обновления статистики SQL Server.
Щелкните правой кнопкой мыши базу данных и перейдите в свойства. В свойствах базы данных мы можем просмотреть параметры статистики на вкладке Автоматически.
Автоматическое создание статистики
SQL Server автоматически создает статистику по отдельным столбцам для предиката запроса, чтобы улучшить оценку количества элементов и подготовить экономичный план выполнения.
Имя автоматического создания статистики начинается с _WA
Используйте следующий запрос для определения статистики, автоматически созданной SQL Server.
SELECT sp.stats_id,
name,
filter_definition,
last_updated,
rows,
rows_sampled,
шагов,
uniltered_rows,
счетчик модификаций
FROM sys.stats AS stat
CROSS APPLY sys.dm_db_stats_properties (stat.object_id, stat.stats_id) AS sp
WHERE stat.object_id = OBJECT_ID (‘HumanResources.Employee’)
и имя типа «_WA%»;
Автоматически созданная статистика SQL Server представляет собой статистику в один столбец
- SQL Server создает автоматическую статистику для столбцов, не имеющих гистограммы для существующего объекта статистики.
Автоматическое создание инкрементной статистики
Начиная с SQL Server 2014, у нас есть новая опция Автоматическое создание добавочной статистики. SQL Server требует сканирования всей таблицы на предмет статистики обновления SQL Server, что вызывает проблемы для больших таблиц. Это также справедливо и для таблицы с секционированием. Мы можем использовать эту функцию для обновления только раздела, который нам требуется обновить. По умолчанию автосоздание инкрементального отключено для отдельных баз данных. Вы можете ознакомиться с разделом Введение в добавочную статистику SQL Server для секционированных таблиц, чтобы получить дополнительные сведения о добавочной статистике.
Автоматическое обновление статистики
Мы регулярно выполняем операции DML, такие как вставка, обновление, удаление, и такие операции изменяют распределение данных или значение гистограммы.Из-за этих операций статистика может быть устаревшей, что может вызвать проблемы с эффективностью оптимизатора запросов. По умолчанию в базе данных SQL Server есть параметр Автообновление статистики true.
С помощью этой опции автоматического обновления статистики оптимизатор запросов обновляет статистику обновления SQL Server, когда статистика устарела. SQL Server использует следующий метод для автоматического обновления статистики.
SQL Server 2014 или более ранней версии | |
Количество строк на момент создания статистики | Автоматическое обновление статистики |
<= 500 | Обновлять статистику за каждые 500 модификаций |
> 500 | Обновлять статистику каждые 500 + 20 процентов модификаций |
Для больших таблиц нам необходимо обновить 20% строки для автоматического обновления статистики.Например, таблица с 1 миллионом строк требует обновления 20 000 строк. Оптимизатор запросов может не подходить для создания эффективного плана выполнения. Начиная с SQL Server 2016, он использует порог обновления динамической статистики и автоматически настраивается в соответствии с количеством строк в таблице.
Порог = √ ((1000) * Количество элементов текущей таблицы)
Например, для таблицы с одним миллионом строк мы можем использовать формулу для вычисления количества обновлений, после которого SQL Server автоматически обновит статистику.
Порог = √ (1000 * 1000000) = 31622
SQL Server обновляет статистику после прибл. 31622 доработок в объекте.
- Примечание: уровень совместимости базы данных должен быть 130 или выше, чтобы использовать эти вычисления динамической пороговой статистики.
Автоматическое обновление статистики асинхронно
SQL Server использует синхронный режим для обновления статистики. Если оптимизатор запросов обнаруживает устаревшую статистику, он сначала обновляет статистику SQL Server, а затем готовит план выполнения в соответствии с недавно обновленной статистикой.
Если мы включим автоматическое обновление статистики в асинхронном режиме, SQL Server не будет ждать обновления статистики. Вместо этого он выполняет запрос с существующей статистикой и параллельно инициирует запросы на обновление статистики. Следующий выполненный запрос использует обновленную статистику. Поскольку SQL Server не ожидает обновленной статистики, мы также называем это статистикой асинхронного режима.
Обновление статистики вручную
В предыдущем разделе мы узнали, что SQL Server автоматически обновляет устаревшую статистику.Мы также можем вручную обновить статистику для улучшения плана выполнения запросов и производительности при необходимости. Мы можем использовать хранимую процедуру UPDATE STATISTICS или Sp_Update для обновления статистики SQL Server.
Давайте воспользуемся командой UPDATE STATISTICS и ее различными параметрами для обновления статистики SQL Server.
Пример 1: СТАТИСТИКА ОБНОВЛЕНИЯ SQL Server для всей статистики в объекте
Выполните следующий запрос, чтобы обновить статистику SQL Server по HumanResources.Таблица сотрудников.
Обновить СТАТИСТИКУ HumanResources.Employee |
На следующем снимке экрана мы можем убедиться, что вся статистика обновляется одновременно.
Пример 2: СТАТИСТИКА ОБНОВЛЕНИЯ SQL Server для конкретной статистики
Допустим, мы хотим обновить статистику SQL Server для статистики IX_Employee_OrganizationNode. Выполните следующий код.
Обновить СТАТИСТИКУ HumanResources.Employee IX_Employee_OrganizationNode |
Он обновляет только конкретную статистику. На следующем снимке экрана мы можем это проверить.
Пример 3: СТАТИСТИКА ОБНОВЛЕНИЯ SQL Server с ПОЛНЫМ сканированием
Мы используем ПОЛНОЕ СКАНИРОВАНИЕ в СТАТИСТИКЕ ОБНОВЛЕНИЯ для сканирования всех строк таблицы. В предыдущих примерах мы не указывали параметр FULL SCAN.Таким образом, SQL Server автоматически решает, требуется ли ПОЛНАЯ ПРОВЕРКА.
Следующий запрос выполняет полное сканирование и обновляет статистику для конкретной статистики в указанном объекте.
Обновить СТАТИСТИКУ HumanResources.Employee IX_Employee_OrganizationNode С FULLSCAN |
Мы также можем использовать предложение WITH SAMPLE 100 PERCENT вместо WITH FULLSCAN, и оба возвращают одинаковый результат.
Обновить СТАТИСТИКУ HumanResources.Employee IX_Employee_OrganizationNode С ВЫБОРКОЙ 100 ПРОЦЕНТОВ |
Пример 4: ОБНОВЛЕНИЕ СТАТИСТИКИ с ОБРАЗОМ
Мы можем использовать WITH SAMPLE CLAUSE, чтобы указать процент или количество строк для оптимизатора запросов для обновления статистики.
Следующий запрос указывает 10-процентную выборку для обновления статистики.
Обновить СТАТИСТИКУ HumanResources.Employee IX_Employee_OrganizationNode С ОБРАЗОМ 10 ПРОЦЕНТОВ |
В следующем запросе указывается образец 1000 строк для обновления статистики.
Обновить СТАТИСТИКУ HumanResources.Employee IX_Employee_OrganizationNode С ОБРАЗОМ 1000 СТРОК |
Примечание:
- Мы не должны указывать 0 PERCENT или 0 Rows для обновления статистики, потому что он просто обновляет объект статистики, но не содержит данных статистики.
- Мы не можем использовать ПОЛНОЕ СКАНИРОВАНИЕ и ОБРАЗЕЦ вместе
- Мы должны использовать SAMPLE только при определенных требованиях.Мы можем взять меньший размер выборки, и оптимизатор запросов может не подобрать подходящий план.
- Мы не должны отключать автоматическое обновление статистики, даже если мы регулярно обновляем статистику SQL Server. Автоматическое обновление статистики позволяет SQL Server автоматически обновлять статистику в соответствии с предварительно определенным пороговым значением.
- Обновление статистики с помощью ПОЛНОЙ ПРОВЕРКИ может занять больше времени для объекта с обширным набором данных. Мы должны планировать это и делать это в нерабочее время
Обычно мы выполняем обслуживание базы данных, такое как перестроение индекса или реорганизация индекса.SQL Server автоматически обновляет статистику после перестроения индекса. Однако это эквивалентно обновлению статистики с ПОЛНОЙ ПРОВЕРКОЙ; он не обновляет статистику столбца. Мы также должны обновить статистику столбца после перестроения индекса. Мы можем использовать следующие запросы, чтобы выполнить задачу для всей статистики по указанному объекту.
Обновить СТАТИСТИКУ HumanResources.Employee С FULLSCAN, COLUMNS |
SQL Server не обновляет статистику при реорганизации индекса.Мы должны обновлять статистику вручную, если это необходимо или нужно полагаться на автоматически обновляемую статистику.
Обновление всей статистики с помощью процедуры sp_updatestats
Мы можем обновить использование sp_updatestats для обновления всей статистики в базе данных. Он просматривает статистику каждого объекта и выполняет необходимое обновление. Для больших баз данных это может занять ненужное больше времени и системных ресурсов, так как он выполняет проверку каждой статистики объекта.
Если обновление не требуется, мы получаем следующее сообщение.
Обновлены 0 индексов / статистик, 1 не требует обновления.
Если он обновит статистику, мы получим следующее сообщение.
1 индекс / статистика обновлены.
Обновите СТАТИСТИКУ с помощью плана обслуживания SQL Server
Мы можем настроить план обслуживания SQL Server для регулярного обновления статистики. Подключитесь к экземпляру SQL Server в SSMS.Щелкните правой кнопкой мыши планы обслуживания и перейдите к мастеру планов обслуживания.
Выберите задачу обслуживания Обновить статистику из списка задач.
Нажмите «Далее», и вы сможете определить задачу «Обновить статистику».
На этой странице мы можем выбрать базу данных (конкретную базу данных или все базы данных), объекты (определенные или все объекты). Мы также можем указать, что нужно обновлять только статистику всех, столбцов или индексов.
Далее мы можем выбрать тип сканирования: полное сканирование или выборка по. В Sample by нам также нужно указать процент выборки или строки выборки.
Заключение
В этой статье мы изучили концепцию статистики SQL Server и различные варианты обновления этой статистики как автоматическими, так и ручными методами. Мы должны регулярно отслеживать статистику и обновлять ее в соответствии с требованиями. Вы также можете просмотреть статистику SQL Server в группах доступности AlwaysOn, чтобы узнать поведение статистики SQL Server в базах данных группы AG.
Будучи сертифицированным MCSA и сертифицированным инструктором Microsoft в Гургаоне, Индия, с 13-летним опытом работы, Раджендра работает в различных крупных компаниях, специализируясь на оптимизации производительности, мониторинге, высокой доступности и стратегиях и внедрении аварийного восстановления. Он является автором сотен авторитетных статей о SQL Server, Azure, MySQL, Linux, Power BI, настройке производительности, AWS / Amazon RDS, Git и связанных технологиях, которые на сегодняшний день просмотрели более 10 миллионов читателей.Он является создателем одного из крупнейших бесплатных онлайн-сборников статей по одной теме с его серией из 50 статей о группах доступности SQL Server Always On. Основываясь на своем вкладе в сообщество SQL Server, он был отмечен различными наградами, включая престижную награду «Лучший автор года» в 2020 и 2021 годах на SQLShack.
Радж всегда интересуется новыми проблемами, поэтому, если вам нужна консультация по любому вопросу, затронутому в его трудах, с ним можно связаться в Раджендре[email protected]
Посмотреть все сообщения от Rajendra Gupta
Последние сообщения от Rajendra Gupta (посмотреть все)SQL 2016 — Устранение неполадок с помощью Live Query Statistics
Среди множества новых функций SQL Server 2016, удобных для разработчиков и администраторов баз данных является Live Query Statistics. Если вы администратор или разработчик базы данных, вы сталкивались с ситуациями, когда выполнение запроса занимает много времени. «Фактический» план запроса можно увидеть только после завершения выполнения.Благодаря Live Query Statistics вам не нужно ждать, чтобы получить план запроса. Есть несколько способов включить эту функцию.
SQL Server Management Studio
Как показано на снимке экрана ниже, выделена небольшая кнопка, которая позволяет активировать статистику запросов в реальном времени. В реальной жизни при устранении неполадок, связанных с низкой производительностью запросов, это будет очень мощная функция. Мы можем получить план запроса, когда запрос действительно выполняется. Мы можем получить представление о плане выполнения и о том, какая часть плана выполняется в любой момент времени.
Live Query Statistics также можно включить, щелкнув правой кнопкой мыши в окне запроса и выбрав опцию «Включить Live Query Statistics».
Кроме того, это можно сделать в строке меню, нажав «Запрос».
После включения статистики оперативных запросов и выполнения запроса при выполнении запроса мы увидим новую вкладку под названием «Статистика оперативных запросов», показанная на изображении ниже.
Вот образец запроса, который мы выполнили:
ВЫБРАТЬ *
ОТ ПРОДАЖ.SalesOrderDetail d, Sales.SalesOrderHeader h
ГДЕ h.SalesOrderID = d.SalesOrderID Для этого потребуется образец базы данных AdventureWorks, который можно загрузить с http://msftdbprodsamples.codeplex.com/.
Как мы видим, он предоставляет «живой» план выполнения и отображает различные вещи:
- Общий прогресс / статус запроса.
- Статистика выполнения во время выполнения, например, прошедшее время.
- Прогресс оператора (% выполнения и затраченное время.)
- Количество обработанных строк.
Монитор активности
Если мы щелкнем правой кнопкой мыши по серверу в SSMS, у нас будет монитор активности. Обратите внимание, что на приведенном ниже экране отображается новая сетка по сравнению со старыми версиями SSMS — «Активные дорогие запросы». Мы можем увидеть текущий план, если щелкнем правой кнопкой мыши запрос и выберем опцию «Показать оперативный план выполнения».
Этот вариант немного сложен. Чтобы получить текущий план из монитора активности, запрос должен быть запущен с «УСТАНОВИТЬ СТАТИСТИКУ XML ВКЛ» или «УСТАНОВИТЬ ПРОФИЛЬ СТАТИСТИКИ ВКЛ.».«Теперь вы можете задаться вопросом, как мы можем увидеть текущий план запроса, когда он поступает из приложения? Для этого необходимо включить расширенное событие query_post_execution_showplan. После включения мы можем видеть план для всех запросов, выполняемых на сервере. Следует отметить, что это инструмент разработчика, и его следует использовать с осторожностью на рабочем сервере.
Как это работает? Если вам интересно, что происходит за кулисами, на самом деле это визуальное представление данных, доступных в DMV sys.dm_exec_query_profiles. Это задокументировано в онлайн-книгах.
Это только для SQL Server 2016? Что ж, хорошая новость заключается в том, что эта функция будет работать, если мы подключимся к экземпляру SQL Server 2014, имеющему хотя бы Service Pack 1, потому что DMV, который используется этой функцией, также доступен в SQL Server 2014. Но если мы подключимся к любой более ранней версии, она будет отключена.
Таким образом, функция Live Query Statistics позволяет нам взглянуть на то, как выполняется запрос, и выяснить, где появляются узкие места.Это дает нам анимированный способ обнаружения дорогостоящих операций.
Live Query Stats of Running Queries — SQLServerCentral
Начиная с SQL Server 2014 SP1 у нас были DMV, которые могут поддерживать Live Query Statistics (в основном план запроса, который дает вам обратную связь по мере его выполнения). Если вы не видели этого раньше, вы можете попробовать…
- Подключитесь к любому экземпляру SQL Server из 2014 SP1.
- Найдите запрос, выполнение которого занимает более нескольких секунд.
Щелкните Live Query Statistics
Выполните запрос
Это может быть действительно полезно для выяснения, сколько времени запрос тратит на каждую операцию и отслеживания узких мест.К сожалению, это становится немного сложнее, если вам нужны эти данные для запросов, выполняемых другими людьми на сервере.
Флаг трассировки 7412
Если вы используете SQL Server 2016 SP1 и до последней версии 2017 года, этот флаг трассировки включает упрощенное профилирование всех запросов, этот профиль будет получать ту же информацию, которую вы получаете из статистики запросов в реальном времени. Если вы используете SQL Server 2019, этот флаг установлен по умолчанию. У этого флага есть накладные расходы (ничто не бесплатно, несмотря на песню), я видел оценки около 2%, поэтому, если вы включаете его в производственных системах, убедитесь, что вы провели некоторое тестирование с базовой нагрузкой.Чтобы узнать, как включить это, см. Мой пост на Trace Flags.
После включения вы можете сделать пару новых вещей. В мониторе активности SSMS, если вы развернете «Активные дорогие запросы», вы можете щелкнуть их правой кнопкой мыши и просмотреть текущую статистику.
Мы также теперь получаем эту новую информацию профиля для текущих запросов в DMV sys.dm_exec_query_profiles. Есть ряд интересных вещей, которые вы можете сделать с этой информацией. Я написал следующий скрипт, чтобы увидеть статусы выполняемых запросов и их продолжительность (помните, что они будут превышать 100%, когда оценки отсутствуют, например.g Если он оценивает 1 строку, но возвращает 10, это даст результат на 1000%)
SELECT
p.node_id NodeId,
p.session_id SessionId,
p.request_id RequestId,
[sql]. [текст] [SQL],
p.physical_operator_name [PlanOperator],
obj.name AS [Объект],
ix.name AS [индекс],
SUM (p.estimate_row_count) [EstimatedRows],
СУММ (p.row_count) [ActualRows],
CAST (CAST (SUM (p.row_count) * 100 / SUM (p.estimate_row_count) AS DECIMAL (5,2)) AS VARCHAR (6)) + '%' Прогресс,
'SELECT query_plan FROM sys.dm_exec_query_plan ('+ CONVERT (VARCHAR (MAX), plan_handle, 1) +') 'GetPlan
ИЗ
sys.dm_exec_query_profiles p
ЛЕВОЕ СОЕДИНЕНИЕ sys.objects obj ON p.object_id = obj.object_id
LEFT JOIN sys.indexes ix ON p.index_id = ix.index_id И p.object_id = ix.object_id
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ (
ВЫБЕРИТЕ node_id
ОТ sys.dm_exec_query_profiles thisDb
КУДА
thisDb.session_id = p.session_id И
thisDb.request_id = p.request_id И
thisDb.database_id = DB_ID ()) а
ВНЕШНИЙ ПРИМЕНИТЬ (ВЫБРАТЬ * ИЗ sys.dm_exec_sql_text (sql_handle)) [sql]
GROUP BY p.request_id, p.node_id, p.session_id, p.physical_operator_name, obj.name, ix.name, database_id, [sql]. [Text], plan_handle
ЗАКАЗАТЬ p.session_id, p.request_id Эта информация также может быть действительно полезной для поиска запросов с очень плохими оценками в качестве возможной отправной точки для оптимизации.
В последний столбец я также включил TSQL, чтобы получить план запроса, просто скопируйте этот столбец и запустите его, чтобы увидеть план.
Как оптимизировать производительность запросов SQL Server — статистика, объединения и настройка индекса
Вы когда-нибудь покупали новый компьютер, подключали его и говорили: «Этот компьютер работает быстро, мне он нравится»? У меня есть. Через год я подумал: «Этот компьютер такой медленный, мне нужен новый».
Производительность — это большое дело, и это была первая строчка в статье, написанной на тему «Как оптимизировать производительность запросов SQL Server». В первоначальной статье показано не только, как разрабатывать запросы с учетом производительности, но также показано, как находить запросы с низкой производительностью и как устранять узкие места этих запросов.Я настоятельно рекомендую сначала прочитать вышеупомянутую статью, потому что она придаст гораздо больше смысла, а также потому, что это приложение к этой теме.
Прежде чем мы продолжим, вот краткий обзор охваченных тем и их основных целей:
- Обзор оптимизации запросов — В этой части мы узнали, что такое планы запросов. В этой части подробно объясняется, как планы запросов помогают SQL Server найти наилучший и эффективный путь к данным и что происходит, когда запрос отправляется на SQL Server, включая шаги, которые он выполняет для поиска этих маршрутов.Кроме того, мы также рассмотрели статистику и то, как она помогает оптимизатору запросов построить наиболее эффективный план, чтобы SQL Server мог найти лучший способ получения данных. Мы также упомянули несколько советов и приемов (руководящих принципов) о том, как проявлять инициативу при разработке запросов с учетом производительности, чтобы гарантировать, что наши запросы будут хорошо работать сразу после выхода.
- Работа с планами запросов — Здесь мы перешли к инструменту под названием ApexSQL Plan, чтобы ознакомиться с планами запросов и понять, как их «расшифровать», что в конечном итоге поможет нам найти узкие места в запросах с низкой производительностью.Мы снова упомянули статистику, но на этот раз мы также покажем, где они хранятся в SQL Server и как их просматривать. Кроме того, эту статистику можно поддерживать и обновлять, чтобы оптимизатор запросов создавал наилучшие предположения при извлечении данных. Мы также рассмотрели примеры различных сценариев использования того, как SQL Server обращается к данным, используя полное сканирование таблицы, полное сканирование индекса, поиск индекса и т. Д.
- Оптимизация производительности запросов — В последней части мы применяем некоторые из рекомендаций из предыдущих разделов.Мы использовали плохо разработанный запрос и применили методы проектирования на практике, написав его правильно. В конце концов, мы поделились лучшими практиками и некоторыми рекомендациями. Мы едва затронули несколько тем, которые играют большую роль, когда дело доходит до выполнения запросов, и цель этой статьи — подробно ознакомиться с этими темами и применить их на практике на некоторых примерах.
Итак, давайте сначала подведем итоги того, что происходит под капотом, когда мы нажимаем кнопку выполнения.Думайте о плане запроса / выполнения как о карте. Это карта, по которой SQL Server прокладывает наиболее эффективный путь к данным. Когда SQL Server принимает запрос, поступающий либо от приложения, либо непосредственно от пользователя, он передает его оптимизатору запросов, который затем создает план запроса / выполнения:
Этот план выполнения — это просто метод SQL Server для доступа к данным, хранящимся на страницах данных на диске. Для создания этих планов запросов требуются ресурсы, поэтому SQL Server будет их кэшировать:
В следующий раз, когда поступит запрос с аналогичным предложением Where или путем к данным, SQL Server повторно использует план запроса для игры с производительностью.Конечно, существуют алгоритмы устаревания, которые удаляют старые планы запросов из кеша, но это внутренняя составляющая, и, как всегда, SQL Server отлично справляется с ее управлением.
Статистика
Итак, мы уже говорили, что статистика важна, потому что она помогает оптимизатору запросов. Мы также кратко описали, что статистика содержит информацию о столбцах, которые оптимизатор запросов использует для создания планов запросов. Вам может быть интересно, как именно статистика помогает оптимизатору запросов делать наилучшие предположения при доступе к данным? Вот хорошая аналогия, чтобы ответить на этот вопрос.Если вы когда-либо планировали вечеринку, в большинстве случаев, когда люди отправляют приглашения, они говорят: «Пожалуйста, RSVP», что в основном означает «пожалуйста, ответьте», планируют ли они присутствовать на вечеринке или нет. Они делают это, чтобы иметь возможность планировать соответственно: сколько еды заказать, сколько напитков получить и т. Д., Потому что это позволяет им лучше оценить все те вещи, которые им нужны, чтобы они не получали слишком много или слишком мало и именно это и делает статистика. Чем актуальнее статистика, тем лучше будет решение, которое Оптимизатор запросов примет решение о том, как выполнить запрос и найти данные эффективным способом.
Статистика создается по индексам и столбцам. Итак, первое, что мы можем сделать, — это запустить хранимую процедуру sp_helpstats, которая возвращает статистическую информацию о столбцах и индексах указанной таблицы. Выполните приведенный ниже запрос, передав имя вашей таблицы и параметр «ALL», который предоставит нам как индексы, так и статистику, сгенерированные для указанной таблицы:
sp_helpstats [@objname =] 'имя_объекта'
[, [@results =] 'значение']
Выполнение этой команды вернет всю автоматически сгенерированную и управляемую статистику и индексы SQL Server:
Это настолько просто, насколько это возможно.Однако мы можем запустить команду DBCC SHOW_STATISTICS, чтобы отобразить текущую статистику оптимизации запросов для конкретной таблицы или индексированного представления. Опять же, передав имя вашей таблицы и имя статистики:
DBCC SHOW_STATISTICS (table_or_indexed_view_name, target)
В этом случае мы рассмотрим первичный ключ (PK_Customer_CustomerID) идентификатора клиента, который представляет собой кластерный индекс, который покажет нам всю статистическую информацию:
Возвращенная табличная информация в наборе результатов показывает различную полезную информацию, такую как общее количество строк в таблице или индексированном представлении при последнем обновлении статистики, среднее количество байтов на значение для всех ключевых столбцов в объекте статистики, гистограмма с распределением значений в первом ключевом столбце объекта статистики и т. д.Дело в том, что вся эта статистика поможет оптимизатору запросов принять наилучшее решение для создания наилучшего возможного плана выполнения.
Эту точную информацию также можно получить в обозревателе объектов. Если мы перейдем к таблице в базе данных, под ней должна быть папка Statistics , в которой хранятся данные, которые мы ранее видели в наборе результатов. Для этого щелкните статистику правой кнопкой мыши и выберите Свойства внизу контекстного меню:
Если мы переключимся на страницу Details в верхнем левом углу, мы увидим те же самые данные, на которые только что смотрели:
Мы упомянули, что SQL Server автоматически обновляет эту статистику, и вы можете проверить этот параметр, перейдя в свою базу данных в обозревателе объектов, щелкнув его правой кнопкой мыши и выбрав команду Properties в нижней части контекстного меню:
Если мы переключимся на страницу Options в верхнем левом углу, вы должны увидеть под правилами Automatic два элемента: Auto Create Statistics и Auto Update Statistics options set to True :
Возможно, стоит оставить их включенными, если вы не хотите полностью контролировать создание и обновление статистики.Однако, если, например, есть причина обновить их вручную, мы можем просто перейти к свойствам статистики и на странице General вы найдете опцию Обновить статистику для этих столбцов . Вот также информация о том, когда статистика обновлялась в последний раз. Выберите эту опцию и нажмите кнопку OK , чтобы автоматически выполнить обновление на месте:
Оптимизатор запросов определяет, когда статистика может быть устаревшей, а затем обновляет ее, когда это необходимо для плана запроса.Если вам интересно, как мы можем определить, застопорилась ли статистика, то, как правило, мы можем увидеть это, посмотрев на план выполнения. Как? В большинстве случаев просто глядя на оценочные и фактические строки. Если навести указатель мыши на операцию, появится всплывающая подсказка, в которой мы сможем увидеть, есть ли большой разрыв между фактическим количеством строк и расчетным количеством строк , тогда мы знаем, что статистику необходимо обновить. В приведенном ниже случае оба числа совпадают, что означает, что статистика актуальна, поэтому обновляйте их вручную только в том случае, если числа сильно отличаются:
Присоединяется к
В первой статье мы рассмотрели различные типы сканирования и индексов.Часто мы пишем сложные запросы с несколькими задействованными таблицами, объединяя данные из разных таблиц. Что ж, именно здесь у SQL Server есть три разных способа связать данные из нескольких таблиц вместе, соединяя их. В мире T-SQL мы знаем его как оператор Join, но у SQL Server есть много способов объединения данных, и он всегда выбирает лучший из них. Я просто хочу показать вам, как они выглядят в планах выполнения, и потому что хорошо знать в целом, как SQL Server объединяет данные воедино.
Начнем с написания простого оператора соединения двух таблиц. Фактически мы можем заставить оптимизатор запросов использовать определенный тип соединения, когда он объединяет таблицы вместе. Это можно сделать с помощью параметров цикла, хэша или слияния, которые обеспечивают конкретное соединение между двумя или более таблицами. В следующем примере используется база данных AdventureWorks2014:
ВЫБЕРИТЕ p.ProductID, p.Name, p.ListPrice, p.Style FROM Production.Product p ПРИСОЕДИНЯЙТЕСЬ к продажам.ProductID = sod.ProductID ВАРИАНТ (LOOP JOIN)
Если мы посмотрим на план выполнения вышеуказанного запроса в ApexSQL Plan, мы увидим, что SQL Server выполняет соединение цикла. В основном этот цикл выполняет для каждой строки внешнего ввода, он сканирует внутренний ввод и, если он находит совпадение, выводит его в результаты:
Если это лучший способ объединить данные? Что ж, давайте выполним тот же запрос, но без указания типа соединения. Для этого достаточно удалить параметр options.На этот раз оптимизатор запросов выбрал объединение слиянием:
Я уверен, что некоторые скажут: «Эй, мы только что перешли с 25,4% до 33,2%. Как это хорошо ». Ну не в этом дело. Подобно правилам сканирования индекса и поиска индекса, некоторые правила применяются в целом, но не обязательно означают, что это всегда будет наиболее эффективным способом. Кроме того, большая часть затрат будет приходиться на объединение слиянием, потому что оно должно сортировать данные. Потерпите меня, мы можем доказать это, перейдя на вкладку History в главном меню, чтобы просмотреть планы выполнения для обоих запросов.Если мы посмотрим на столбец Execution time , обратите внимание, что счетчик времени равен 1,19, когда мы форсировали соединение цикла, и меньше, когда Query Optimizer выбрал объединение слиянием:
Кроме того, мы также можем проверить оба плана и нажать кнопку Сравнить , чтобы увидеть дополнительную статистику, и из этого примера мы можем увидеть, что объединение слиянием работает намного лучше, просто посмотрев на столбцы чтения:
Давайте также посмотрим, что делает хеш-соединение, заставляя план выполнения использовать его:
Иногда числа могут сбивать с толку.Мне нравится помещать все три соединения в один текст запроса и смотреть на план выполнения:
При размещении нескольких операторов в плане выполнения мы получаем обзор общей стоимости запроса относительно пакета. В этом случае, если мы выберем оператор с объединением слиянием, которое также является типом объединения, которое SQL Server выберет по умолчанию, мы увидим ниже в плане выполнения, что общая стоимость запроса составляет 20,3%:
Если мы переключимся на два других, мы увидим, что соединение цикла заняло 46.6%, а на хеш-соединение ушло 33,3%:
Итак, хеш-соединение предназначено для больших объемов данных. Это действительно рабочий курс, который SQL Server будет использовать для таких вещей, как сканирование таблиц или сканирование индекса, всего, что не является поиском, а также в тех случаях, когда это поиск, но все же он извлекает большой объем данных.
Общее практическое правило: вложенные циклы подходят для небольших объемов данных. SQL Server, скорее всего, выберет этот тип соединения, когда данных для работы не так много.Вы увидите объединение со средним объемом данных, а хеш-соединение с большим объемом данных. Если запросы покрыты индексами, SQL Server будет работать с меньшим объемом данных, и именно здесь с наибольшей вероятностью будут видны соединения цикла. С другой стороны, если вам не хватает индексов, SQL Server будет работать с большим объемом данных (сканирование таблиц), и вы, вероятно, увидите хэш-соединения или, по крайней мере, объединения слиянием.
Мастер настройки индекса
Возвращаясь к индексам, помните, что мы должны часто возвращаться к ним.В базе данных с большим количеством объектов эта миссия кажется невыполнимой. Не совсем. Давайте взглянем на один инструмент, входящий в состав SQL Server, который называется Index Tuning Wizard, который может помочь нам в этом. Помните, что самое важное, что мы можем сделать с точки зрения производительности наших баз данных, — это иметь хорошую стратегию индексирования.
Итак, давайте познакомимся с этим мастером настройки индекса и посмотрим, что мы можем с ним сделать. Этот инструмент можно использовать при разработке приложения, базы данных или запроса.Первое, что нам нужно сделать, это настроить рабочую нагрузку. Это делается путем выполнения запроса к вашей базе данных и захвата результатов. Затем мы можем отправить эти результаты мастеру настройки индекса, который на основе самого запроса и результатов сообщит нам, что следует индексировать и охватить статистикой, и даст нам общие рекомендации.
Рабочая нагрузка — это просто набор операторов T-SQL, которые выполняются для базы данных, которую мы хотим настроить. Итак, следующим шагом будет либо ввести наш сценарий T-SQL в редактор запросов, либо использовать e.грамм. существующие хранимые процедуры (превратить их в рабочую нагрузку). Чтобы упростить этот пример, мы собираемся использовать серию наиболее часто используемых операторов Select, которые попадают в нашу базу данных. Как показано ниже, это всего пять часто используемых операторов Select в одном запросе:
Всегда рекомендуется выполнять пакет, чтобы убедиться, что запрос действителен и что в наборе результатов нет предупреждений или ошибок. Кроме того, после успешного выполнения в строке состояния SSMS будет отображаться количество возвращенных строк и общая продолжительность.Как видно из этого примера, весь процесс занял более десяти минут и вернул 242К + строк, что является довольно хорошей рабочей нагрузкой:
Все, что нам теперь нужно сделать, это сохранить файл с расширением .sql:
Затем в меню Инструменты SQL Server Management Studio щелкните Помощник по настройке ядра СУБД :
Появится диалоговое окно Connect to Server, поэтому оставьте все как есть или внесите соответствующие изменения и нажмите кнопку Connect , чтобы продолжить:
В следующем окне нам нужно настроить несколько вещей, прежде чем мы продолжим:
- Найдите ранее созданный файл рабочей нагрузки.
- Выберите подходящую базу данных для анализа рабочей нагрузки
- Выберите соответствующую базу данных и таблицы для настройки
- Нажмите кнопку Start Analysis , чтобы начать следующий шаг настройки.
Строка Progress показывает информацию о предпринятых действиях и их статусе:
Он будет проходить этапы настройки пять раз, и как только это будет сделано, он перейдет к следующему этапу (вкладка «Рекомендации»).Этот шаг может занять некоторое время, но как только он будет выполнен, будет показан список рекомендаций по индексированию. Также есть оценочное число улучшений (в данном случае 75%), что по-своему информативно. Это правда? Что ж, давайте закончим оптимизацию и проверим результаты позже:
Если мы прокрутим горизонтально вправо, появится столбец с названием Definition , в котором находится предварительный код T-SQL для создания этих недостающих индексов и статистики:
При нажатии на ссылку из списка Определения откроется окно предварительного просмотра сценария SQL, в котором показан сценарий T-SQL для создания недостающих индексов и статистики, которые можно скопировать в буфер обмена и использовать позже:
Вместо того чтобы копировать каждый сценарий по одному в буфер обмена (когда список длинный), мы можем сохранить все рекомендации, щелкнув команду Сохранить рекомендации в меню Действия :
Как только это будет сделано, этот вновь созданный скрипт можно будет запустить в целевой базе данных:
Вернитесь в SSMS, откройте скрипт и выполните его.Должно появиться сообщение об успешном выполнении команды:
Большинство из нас не смогли бы понять, как именно создавать эти наилучшие возможные индексы и статистику, но этот инструмент облегчает нашу жизнь.
Вернемся к предполагаемому количеству улучшений… как создание индексов и статистики улучшило общую производительность? Хороший. При выполнении того же тяжелого запроса время выполнения сократилось почти вдвое.
Помните, что число, представленное в помощнике по настройке ядра СУБД, является приблизительным.Результаты могут отличаться, но в целом улучшения должны быть.
И последнее: знакомство с динамическими административными представлениями (DMV) также может помочь нам найти медленно выполняющиеся запросы. Этот инструмент можно использовать для поиска плохо или долго выполняющихся запросов. На самом деле это просто набор представлений и функций, которые можно запустить для поиска информации о SQL Server. Эти представления и функции возвращают данные о том, что происходит в SQL Server. На официальном сайте Microsoft много документов, и они также хорошо распределены по категориям, поэтому настоятельно рекомендуется проверить онлайн-книги и узнать больше о DMV.
Вот два быстрых метода, которые можно использовать на любом сервере SQL:
ВЫБРАТЬ ТОП 10 qs.total_elapsed_time / qs.execution_count / 1000000.0 AS AverageSeconds,
qs.total_elapsed_time / 1000000.0 AS TotalSeconds,
qt.text КАК запрос,
DB_NAME (qt.dbid) как DatabaseName
ОТ sys.dm_exec_query_stats qs
ПЕРЕКРЕСТИТЬ ПРИМЕНИТЬ sys.dm_exec_sql_text (qs.sql_handle) AS qt
LEFT OUTER JOIN sys.objects o ON qt.objectid = o.object_id
ЗАКАЗАТЬ ПО AverageSeconds DESC;
Вышеупомянутый запрос вернет 10 самых продолжительных запросов в базе данных. Все, что делает этот запрос, в основном просто запускает представление sys.dm_exec_query_stats, которое возвращает информацию о запросе, который находится в базе данных, указанной в операторе Select, а затем перекрестно применяет его к функции значения таблицы, передающей дескриптор (который является столбцом из view), который даст нам фактический запрос, который был выполнен.
Приведенный ниже запрос вернет десять самых дорогих запросов с точки зрения ввода / вывода (операции чтения с диска):
ВЫБРАТЬ ТОП 10 (total_logical_reads + total_logical_writes) / qs.Execution_count в среднем по IO,
(total_logical_reads + total_logical_writes) AS TotalIO,
qt.text КАК запрос,
o.name AS ObjectName,
DB_NAME (qt.dbid) как DatabaseName
ОТ sys.dm_exec_query_stats qs
ПЕРЕКРЕСТИТЬ ПРИМЕНИТЬ sys.dm_exec_sql_text (qs.sql_handle) AS qt
LEFT OUTER JOIN sys.objects o ON qt.objectid = o.object_id
ЗАКАЗАТЬ ПО AverageIO DESC;
Ни один из них не вернет никаких данных в этом случае, потому что в среде (SQL Server), настроенной для этой статьи, нет реальной активности, но используйте их на большом сервере, который имеет много активности, и набор результатов будет заполнен данными.
В заключение я хотел бы сказать еще один совет, который также должен познакомить вас с SQL Server Profiler. С помощью этого инструмента мы можем настроить трассировку для сервера или базы данных и в основном перехватить все операторы, поступающие на сервер или базу данных. Кроме того, этот инструмент позволяет нам точно видеть, что происходит на нашем сервере, какие данные передаются и параметры, входы и выходы из системы и т. Д. Он также интегрируется с мастером настройки индекса, который мы видели при создании рабочей нагрузки. Как только вы освоите все эти инструменты и объедините их с планами выполнения, устранение неполадок запросов станет намного проще.
Я надеюсь, что эти две статьи были для вас информативными, и благодарю вас за чтение.
Полезные ссылки
28 февраля 2018 г. Инструмент запросов— документация pgAdmin 4 5.2
Инструмент запросов — это мощная многофункциональная среда, которая позволяет выполнить произвольные команды SQL и просмотреть набор результатов. Вы можете получить доступ к Инструмент запросов через пункт меню Инструмент запросов в меню Инструменты или через контекстное меню выбора узлов элемента управления «Дерево браузера».Инструмент запросов позволяет:
Выпустить специальные запросы SQL.
Выполнять произвольные команды SQL.
Редактировать набор результатов запроса SELECT, если он обновляемый.
Отображает текущее соединение и состояние транзакции, настроенное пользователем.
Сохраните данные, отображаемые на панели вывода, в файл CSV.
Просмотрите план выполнения оператора SQL в текстовом или графическом виде. формат или формат таблицы (аналогично https: // объяснение.depesz.com).
Просмотр аналитической информации об операторе SQL.
Вы можете открыть несколько копий инструмента запросов на отдельных вкладках. одновременно. Чтобы закрыть копию инструмента запроса, щелкните X в верхний правый угол панели вкладок.
Инструмент запросов состоит из двух панелей:
На верхней панели отображается редактор SQL . Вы можете использовать панель для входа, отредактировать или выполнить запрос.Он также показывает вкладку History , которую можно использовать для просмотра запросов, которые были выполнены в сеансе, и блокнот Scratch Pad который можно использовать для хранения фрагментов текста во время редактирования. Если блокнот закрыт, его можно открыть повторно (или открыть дополнительные), щелкнув правой кнопкой мыши в редактор SQL и другие панели и добавление новой панели.
На нижней панели отображается панель Вывод данных . На панели с вкладками отображается набор результатов, возвращаемый запросом, информация о плане выполнения запроса, сообщения сервера, связанные с выполнением запроса и любыми асинхронными уведомления, полученные с сервера.
Панель редактора SQL
Панель редактора SQL — это рабочая область, в которой вы можете вручную ввести запрос, скопировать запрос из другого источника или прочитать запрос из файла. Редактор SQL Особенности синтаксической раскраски и автозаполнения.
Чтобы использовать автозаполнение, начните вводить свой запрос; когда вы хотите, чтобы запрос редактор, чтобы предложить имена объектов или команды, которые могут быть следующими в вашем запросе, нажмите комбинацию клавиш Control + Space. Например, введите « SELECT * FROM ». (без кавычек, но с пробелом в конце), а затем нажмите Control + Space сочетание клавиш для выбора из всплывающего меню параметров автозаполнения.
После ввода запроса выберите значок Execute / Refresh на панели инструментов. В полное содержимое панели редактора SQL будет отправлено на сервер базы данных для выполнения. Чтобы выполнить только часть кода, отображаемую в В редакторе SQL выделите текст, который должен запускать сервер, и щелкните значок Execute / Refresh .
Сообщение, возвращаемое сервером при выполнении команды, отображается на Сообщения вкладка.Если команда выполнена успешно, откроется вкладка Сообщения . детали исполнения.
Параметрыв меню Редактировать предлагают функции, которые помогают с форматированием кода и комментируют:
Функция автоматического отступа автоматически делает отступ текста той же глубины, что и предыдущую строку при нажатии клавиши Return.
Заблокируйте отступ текста, выделив две или более строк и нажав клавишу Tab.
Внедрить или удалить стиль SQL или переключить нотацию комментариев в стиле C в вашем код.
Вы также можете перетащить определенные объекты из древовидной структуры, которые может сэкономить время при вводе длинных имен объектов. Текст, содержащий имя объекта, будет полностью квалифицирован со схемой. При необходимости будут добавлены двойные кавычки. Для функций и процедур имя функции вместе с именами параметров будет быть вставленным в Инструмент запросов.
Панель вывода данных
Панель вывода данных отображает данные и статистику, сгенерированные большинством недавно выполненный запрос.
На вкладке Вывод данных отображается набор результатов запроса в виде таблицы. Вы можете:
Выберите и скопируйте из отображаемого набора результатов.
Используйте параметры Execute / Refresh для получения информации о выполнении запроса и установить параметры выполнения запроса.
Используйте значок Сохранить результаты в файл , чтобы сохранить содержимое вывода данных tab как файл с разделителями-запятыми.
Отредактируйте данные в наборе результатов запроса SELECT, если он является обновляемым.
Набор результатов можно обновить, если:
Все столбцы либо выбираются непосредственно из одной таблицы, либо не являются столбцами таблицы (например, объединение двух столбцов). Только столбцы, выбранные непосредственно из таблицы, являются редактируемые, остальные столбцы доступны только для чтения.
Все столбцы первичного ключа или OID таблицы выбираются в набор результатов.
Любые столбцы, которые были переименованы или выбраны более одного раза, также доступны только для чтения.
Столбцы, доступные для редактирования и только для чтения, обозначаются значками карандаша и замка. (соответственно) в заголовках столбцов.
Версия драйвера psycopg2 должна быть не ниже 2,8 для обновляемого набор результатов запроса для работы.
Обновляемый набор результатов идентичен сетке данных в Режим просмотра / редактирования данных, который можно изменить таким же образом.
Если автоматическая фиксация отключена, изменения данных выполняются как часть текущего транзакция, если транзакция не выполняется, инициируется новая.Данные изменения не фиксируются в базе данных, если транзакция не зафиксирована.
Если при сохранении возникают какие-либо ошибки (например, попытка сохранить NULL в столбец с ограничением NOT NULL) изменения данных откатываются до автоматически создается SAVEPOINT, чтобы гарантировать, что любые ранее выполненные запросы в текущая транзакция не откатывается.
Все наборы строк из предыдущих запросов или команд, которые отображаются в данных Вывод панели будет отброшен при вызове другого запроса; открыть другой Вкладка инструмента запросов, чтобы ваши предыдущие результаты оставались доступными.
Панель объяснения
Чтобы создать план запроса Explain или Explain Analyze , щелкните Объяснение или Объяснение Кнопка анализа на панели инструментов.
Дополнительные параметры, относящиеся к Объяснить и Объяснить Анализ можно выбрать из раскрывающийся список справа от кнопки Explain Analyze на панели инструментов.
Обратите внимание, что pgAdmin генерирует план Explain [Analyze] в формате JSON.
При успешном создании плана Explain будет создано три вкладки / панели под панелью «Объяснение».
Обратите внимание, что EXPLAIN VERBOSE не может отображаться графически. Нажмите на значок узла на вкладке Graphical для просмотра информации об этом элементе; всплывающее окно справа появится окно с информацией о выбранных объект. Для получения информации о JIT-статистике, триггерах и сводке щелкните на кнопка в правом верхнем углу; при необходимости отобразится аналогичное всплывающее окно.
Используйте кнопку загрузки в верхнем левом углу холста Explain для загрузки план в виде файла SVG.
Примечание. Загрузка в формате SVG не поддерживается в Internet Explorer.
Обратите внимание, что план запроса, который сопровождает анализ Explain Analyse , доступен на вкладка Вывод данных .
Таблица Вкладка показывает детали плана в формате таблицы, она генерирует формат таблицы аналогично manage.depsez.com .Каждая строка таблицы представляет данные для Узел плана объяснения . Он может содержать информацию об узле, эксклюзивную синхронизацию, включая сроки, фактические и запланированные различия строк, фактические строки, запланированные ряды, петли.
. Цвет фона столбцов исключительных, включающих и строк X может варьироваться в зависимости от разница между фактическим и запланированным.
Если процент исключительных / включенных таймингов от общего времени запроса: > 90 — красный цвет > 50 — оранжевый (между красным и желтым) цветом > 10 — Желтый цвет
Если планировщик неверно оценил количество строк (фактическое и запланированное) на 10 раз — желтый цвет 100 раз — оранжевый (между красным и желтым) цветом 1000 раз — Красный цвет
Статистика Вкладка показывает две таблицы: 1.Статистика по типу узла плана 2. Статистика по таблице
Панель сообщений
Используйте вкладку Сообщения для просмотра информации о последних выполненных запрос:
Если сервер возвращает ошибку, сообщение об ошибке будет отображаться на Вкладка сообщений , и синтаксис, вызвавший ошибку, будет подчеркнут в Редактор SQL. Если запрос выполнен успешно, на вкладке Сообщения отображается, как долго запрос завершился и сколько строк было получено:
Панель уведомлений
Используйте вкладку Уведомления для просмотра уведомлений с помощью PostgreSQL Listen / Уведомить функцию .Подробнее см. Документацию PostgreSQL.
Пример:
Выполнить LISTEN «foo» в первом сеансе Query Tool
2. В другом сеансе Инструмента запросов выполните команду Notify или pg_notify функция для отправки уведомления о событии вместе с полезной нагрузкой.
3. Вы можете увидеть вкладку Notification в первом сеансе Query Tool . где отображается записанное время, событие, идентификатор процесса и полезная нагрузка конкретный канал.
Панель истории запросов
Используйте вкладку История запросов для просмотра активности в текущем сеансе:
На вкладке «История запросов» отображается информация о последних командах:
Дата и время вызова запроса.
Текст запроса.
Количество строк, возвращаемых запросом.
Время, затраченное сервером на обработку запроса и возврат набор результатов.
Сообщения, возвращаемые сервером (не указано на вкладке Сообщения ).
Источник запроса (обозначается значками, соответствующими панели инструментов).
Вы можете показать или скрыть запросы, сгенерированные внутри pgAdmin (во время «Просмотр / редактирование данных» или «Сохранить данные»).
Чтобы удалить содержимое вкладки История запросов , выберите Очистить историю из раскрывающееся меню Очистить .
История запросов поддерживается по сеансам для каждой базы данных для каждого пользователя.
при работе в режиме Query Tool. В режиме просмотра / редактирования данных история не
сохранено. По умолчанию для каждой базы данных сохраняются последние 20 запросов. Этот
можно настроить в config_local.py или config_system.py (см.
config.py), переопределив MAX_QUERY_HIST_STORED значение. См. Раздел «Развертывание»
для дополнительной информации.
Состояние подключения
Используйте функцию Состояние подключения для просмотра текущего подключения и статус транзакции, щелкнув значок статуса в Инструменте запросов:
Сменить соединение
Пользователь может подключиться к другому серверу или базе данных из существующего открытого сеанса инструмента запросов.
Теперь выберите сервер, базу данных, пользователя и роль для подключения и нажмите OK.
Вновь созданное соединение теперь отображается в списке опций.
Для подключения выберите вновь созданное подключение из раскрывающегося списка.
Макросы
Макросы инструментаQuery Tool позволяют выполнять предварительно определенные запросы SQL одним нажатием клавиши. Предопределенные запросы могут содержать заполнитель $ SELECTION $.После выполнения макроса заполнитель будет заменен текущим выделенным текстом на панели редактора запросов в Инструменте запросов.
Чтобы создать макрос, выберите опцию Manage Macros из меню Macros в инструменте запросов . Выберите ключ, который вы хотите использовать, введите имя макроса и запрос, необязательно включая заполнитель выбора, а затем нажмите кнопку Сохранить , чтобы сохранить макрос.
Чтобы очистить макрос, выберите макрос в диалоговом окне « Управление макросами », а затем нажмите кнопку « Очистить ».
Сервер запросит подтверждение для очистки макроса.
Чтобы очистить все макросы, нажмите кнопку Очистить слева от клавиши. Сервер предложит вам подтвердить очистку всех строк.
Чтобы выполнить макрос, просто выберите соответствующие сочетания клавиш или выберите его в меню Macros .
.