
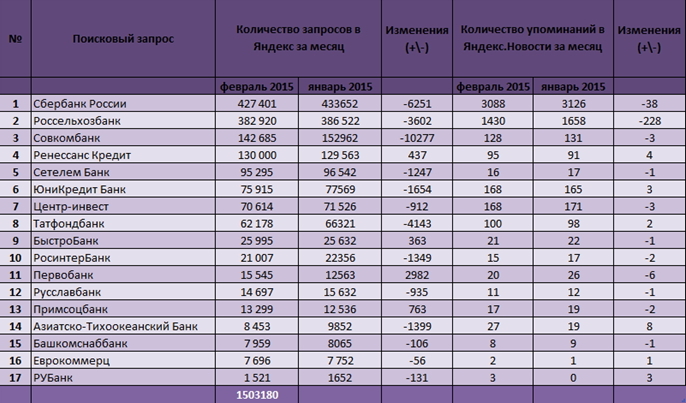
Анализ ключевых запросов в популярных поисковых системах
Поисковая система обладает даже специальным сервисом для просмотра поисковых запросов – Яндекс. Вордстат. Этот сервис очень прост в использовании: сначала нужно ввести любые слова по вашей теме, после этого покажется статистика искомых выражений и то, что искалось вместе с запросом.
Важно!
Сведения по небольшим запросам также несут в себе подробную информацию по искомым поисковым фразам.
Для того, чтобы узнать точное число ключевых фраз по конкретному выражению нужно написать это выражение в кавычках (“ключевое слово”).
1. Google Trends. Данный инструмент показывает самые популярные запросы за последний временной промежуток. Можно ввести абсолютно разные слова и узнать уровень заинтересованности ими. Плюс Гугл Тренды могут сравнить популярность по регионам и вывести похожие искомые запросы.
2. Перейти на специальный сервис adwords.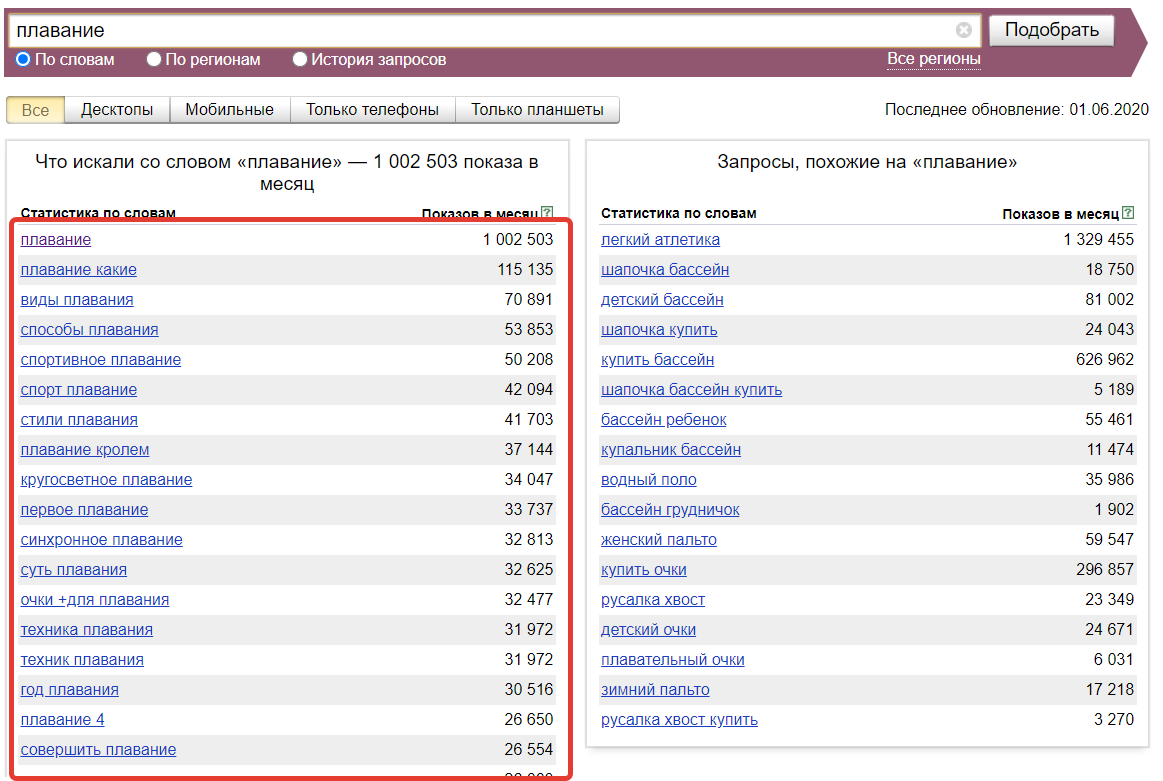
- совершить регистрацию в роли «рекламодатель»
- перейти в “Инструменты”
- нажать на “Планировщик ключевых слов”
- нажать на “Получить статистику запросов”
Этим способом можно не только изучить статистику ключевых запросов, но и оценить конкуренцию рекламодателей по этим данным и узнать приблизительную цену клика.
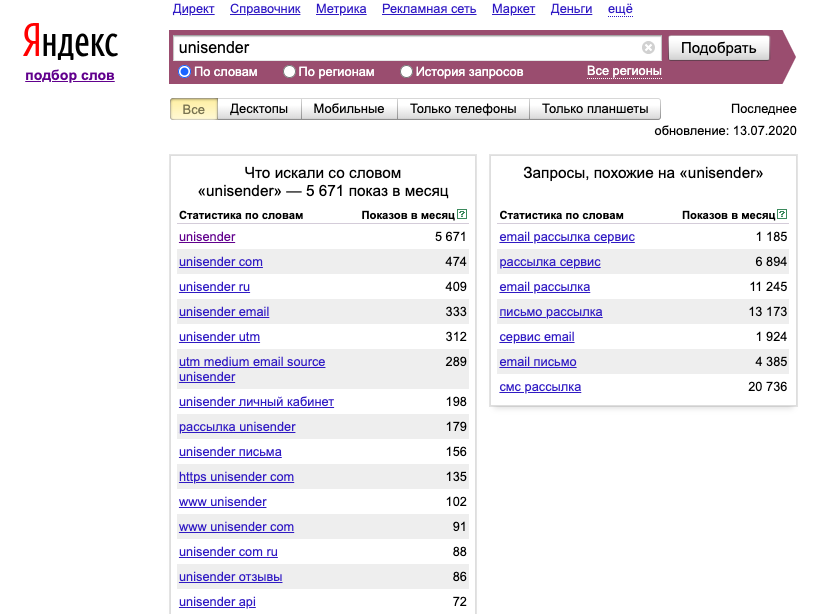
У Mail.ru средство webmaster.mail.ru/querystat для сравнения ключевых запросов есть отличительная особенность. Этот сервис распределяет искомые слова по возрасту и полу.
Можно сделать вывод, что инструмент поисковой системы “Яндекс” также может учитывать запросы из Mail.ru. Это объясняется тем, что второй браузер показывает рекламу из первого. До недавнего времени в поисковой системе Mail.ru транслировалась и реклама такого браузера как Google.
- шестьдесят процентов у Яндекс
- тридцать процентов у Google
- десять процентов у Mail.
 ru
ru
 ru
ruВажно!
Нужно помнить, что некоторые аудитории предпочитают определенный вид поисковой системы.
Поисковая система не отличается большим охватом ключевых запросов в интернете. Число захвата аудитории равняется одному проценту.
Но у Rambler действует собственный инструмент для анализа поисковых запросов – adstat.rambler.ru/wrds/ .
Принцип сервиса Rambler не отличается от выше описанных поисковых систем.
Youtube тоже не отстает, сайт также обладает инструментом для просмотра ключевых слов под названием “Инструмент для подсказки ключевых слов”. Этот сервис нужен в большей степени рекламодателям, но также можно использовать для того, чтобы описание видео соответствовало подходящим поисковым фразам.
Важно!
Youtube в две тысячи пятнадцатом году закрыли сервис для подбора ключевых запросов – YouTube Keyword Tool. На его замену пришел Display Planner.
Bing и Yahoo приходятся непопулярными поисковыми системами в России, но всё равно имеют долю процента аудитории.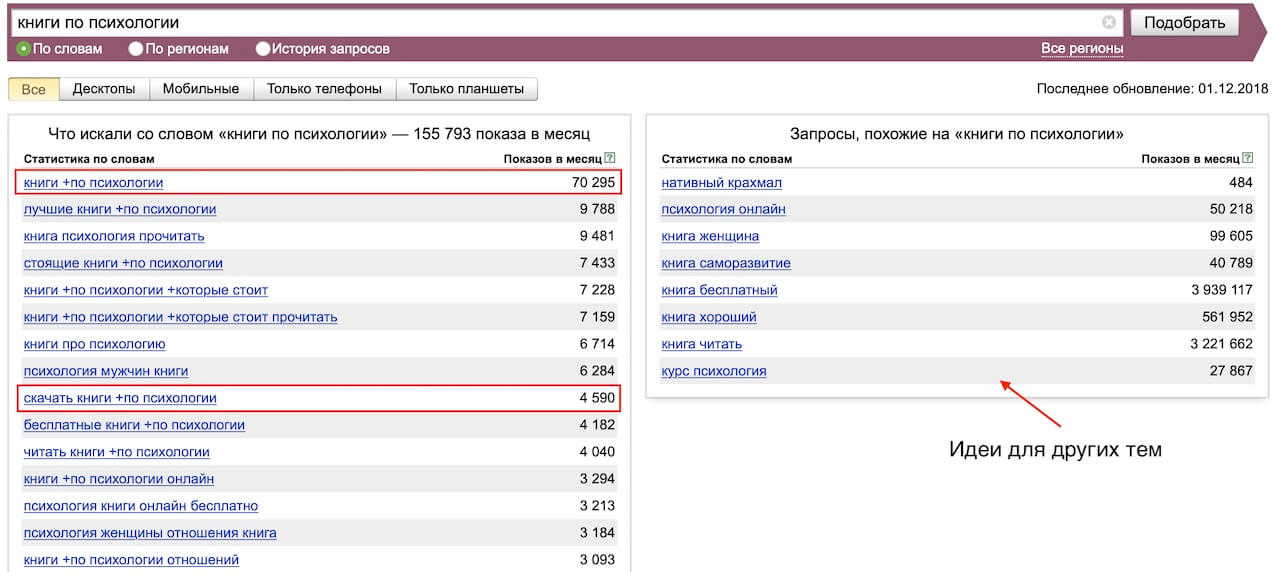
Для того, чтобы здесь приступить к анализу ключевых запросов нужно:
- совершить регистрацию как рекламодатель;
- изучить инструкцию, которая написана на иностранном языке;
- перейти на этап создания рекламной кампании (здесь уже будет видна нужная статистика).
В статье мы разобрали популярные сервисы для анализа ключевых слов известных браузеров. Надеемся, что помогли понять, как осуществить качественный подбор поисковых запросов, чтобы разработать эффективный сайт, создать рекламную кампанию или написать статью для блога.
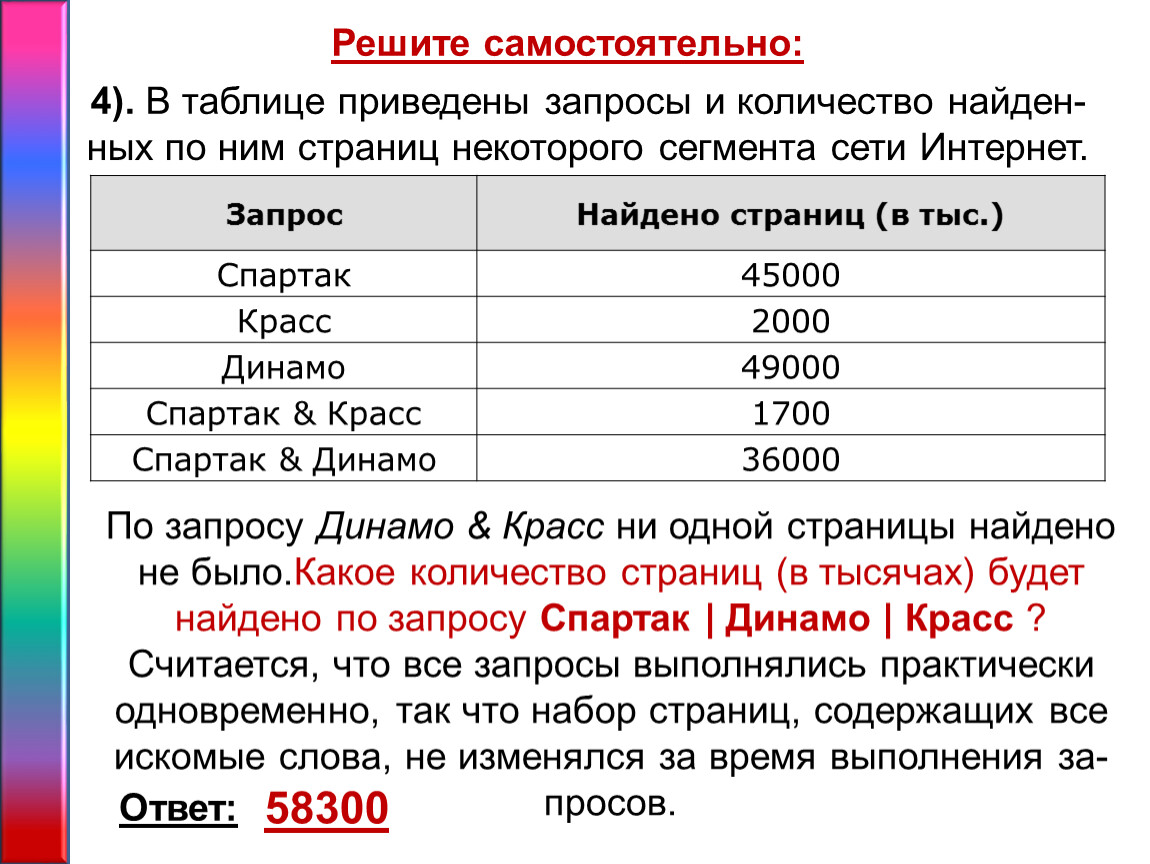
Подсчет данных при помощи запроса
В этой статье описано, как подсчитать данные, возвращаемые запросом. Например, в форме или отчете можно подсчитать количество элементов в одном или нескольких полях таблицы или элементах управления. Вы также можете вычислять средние значения, находить наибольшее и наименьшее значения, самую давнюю и самую последнюю дату.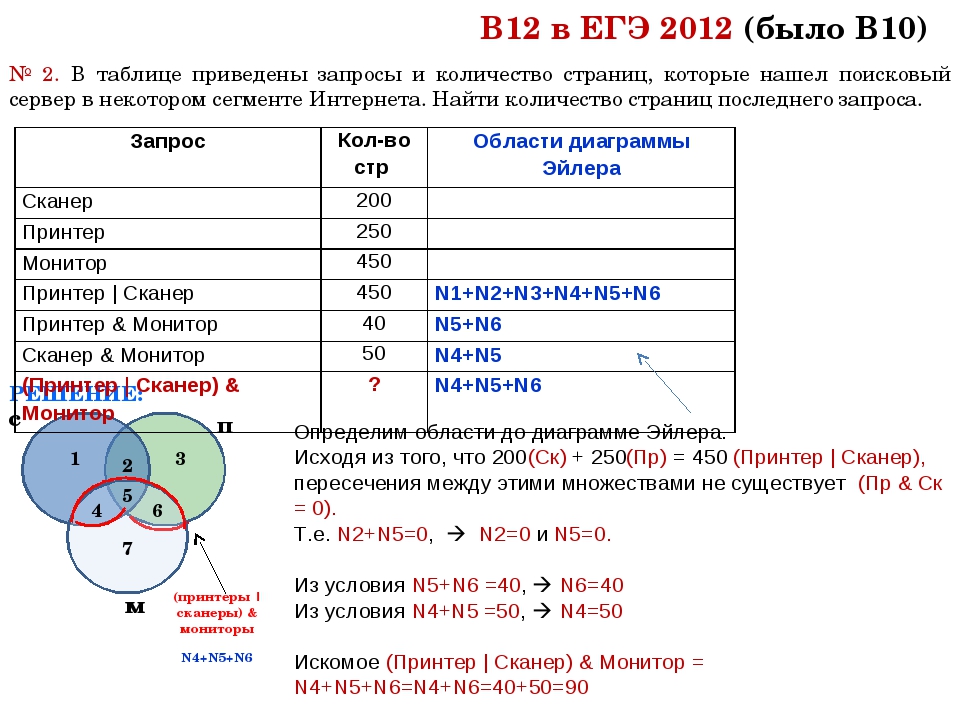 Кроме того, в Access предусмотрено средство, называемое строкой итогов, с помощью которого можно подсчитывать данные в таблице, не изменяя структуру запроса.
Кроме того, в Access предусмотрено средство, называемое строкой итогов, с помощью которого можно подсчитывать данные в таблице, не изменяя структуру запроса.
Выберите нужное действие
Способы подсчета данных
Подсчитать количество элементов в поле (столбце значений) можно с помощью функции Число. Функция Число принадлежит к ряду функций, называемых агрегатными. Агрегатные функции выполняют вычисления со столбцами данных и возвращают единственное значение. Кроме функции Число, в Access есть следующие агрегатные функции:
-
Сумма для суммирования столбцов чисел;
-
Среднее для вычисления среднего значения в столбце чисел;
-
Максимум для нахождения наибольшего значения в поле;
-
Минимум для нахождения наименьшего значения в поле;
-
Стандартное отклонение для оценки разброса значений относительно среднего значения;
-

В Access предусмотрено два способа добавления функции Count и других агрегатных функций в запрос. Вы можете:
-
Открыть запрос в режиме таблицы и добавить строку итогов. Строка итогов позволяет использовать агрегатные функции в одном или нескольких столбцах в результатах запроса без необходимости изменять его структуру.
-
Создать итоговый запрос. В итоговом запросе вычисляются промежуточные итоги по группам записей. Например, если вы хотите вычислить промежуточную сумму всех продаж по городам или по кварталам, следует использовать итоговый запрос для группировки записей по нужной категории, а затем просуммировать все объемы продаж.
С другой стороны, с помощью строки итогов можно вычислить общий итог для одного или нескольких столбцов (полей) данных.
 С другой стороны, с помощью строки итогов можно вычислить общий итог для одного или нескольких столбцов (полей) данных.
С другой стороны, с помощью строки итогов можно вычислить общий итог для одного или нескольких столбцов (полей) данных.Примечание: Ниже в разделах этой статьи подробно описано применение функции Сумма, однако следует помнить, что вы можете использовать другие агрегатные функции в строках итогов и запросах. Дополнительные сведения об использовании других агрегатных функций см. ниже в разделе Справочные сведения об агрегатных функциях.
Дополнительные сведения о способах использования других агрегатных функций см. в разделе Отображение итогов по столбцу в таблице.
 Следует обратить внимание на то, что функция Число работает с большим числом типов данных, чем другие агрегатные функции. Функцию Число можно использовать для любого типа полей, кроме тех, которые содержат сложные повторяющиеся скалярные данные, например поле с многозначными списками.
Следует обратить внимание на то, что функция Число работает с большим числом типов данных, чем другие агрегатные функции. Функцию Число можно использовать для любого типа полей, кроме тех, которые содержат сложные повторяющиеся скалярные данные, например поле с многозначными списками.
Общие сведения о типах данных см. в статье Изменение типа данных для поля.
К началу страницы
Подсчет данных с помощью строки итогов
Чтобы добавить в запрос строку итогов, откройте его в режиме таблицы, добавьте строку, а затем выберите функцию Число или другую агрегатную функцию, например Сумма, Минимум, Максимум или Среднее. В этом разделе объясняется, как создать простой запрос на выборку и добавить строку итогов.
Создание простого запроса на выборку
-
На вкладке Создать в группе Другое нажмите кнопку Конструктор запросов.
-
Дважды щелкните таблицу или таблицы, которые вы хотите использовать в запросе, а затем нажмите кнопку «Закрыть».
Выбранные таблицы отображаются в виде окон в верхней части конструктора запросов. На рисунке показана типичная таблица в конструкторе запросов.
-
Дважды щелкните поля таблицы, которые вы хотите использовать в запросе.
Вы можете включить поля, содержащие описательные данные, например имена и описания, но следует обязательно добавить поле, содержащее подсчитываемые значения.
Каждое поле отображается в столбце в бланке запроса.
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
Результаты запроса отображаются в режиме таблицы.
-
При необходимости переключитесь в Конструктор и скорректируйте запрос. Для этого щелкните правой кнопкой мыши вкладку документа для запроса и выберите команду Конструктор. После этого можно изменить запрос, добавив или удалив поля таблицы. Чтобы удалить поле, выберите столбец в бланке запроса и нажмите клавишу DELETE.
-
При необходимости вы можете сохранить запрос.
Добавление строки итогов
-
Откройте запрос в режиме таблицы. Если база данных имеет формат ACCDB, щелкните правой кнопкой мыши вкладку документа для запроса и выберите команду Режим таблицы.
-или-
Если используется база данных в формате MDB, созданная в более ранней версии Access, на вкладке Главная в группе Режимы щелкните стрелку под кнопкой Режим и выберите значение Режим таблицы.
-или-
Дважды щелкните запрос в области навигации. Запрос будет выполнен, а его результаты будут загружены в таблицу.
-
На вкладке Главная в группе Записи нажмите кнопку Итоги.
Под последней строкой данных в таблице появится новая строка Итог.
-
В строке Итог щелкните поле, по которому вы хотите выполнить подсчет, и выберите в списке функцию Count.

Скрытие строки итогов
Дополнительные сведения об использовании строки итогов см. в разделе Отображение итогов по столбцу в таблице.
К началу страницы
Подсчет данных с помощью итогового запроса
Когда нужно подсчитать некоторые или все записи, возвращаемые запросом, то вместо строки итогов можно воспользоваться итоговым запросом. Например, вы можете подсчитать общее число сделок или число сделок в отдельном городе.
Например, вы можете подсчитать общее число сделок или число сделок в отдельном городе.
Как правило, итоговый запрос применяется вместо строки итогов тогда, когда требуется использовать значение результата в другой части базы данных, например в отчете.
Подсчет всех записей в запросе
-
На вкладке Создать в группе Другое нажмите кнопку Конструктор запросов.
-
Дважды щелкните таблицу, которую вы хотите использовать в запросе, и нажмите кнопку «Закрыть».
Таблица появится в окне в верхней части конструктора запросов.
-
Дважды щелкните поля, которые вы хотите использовать в запросе, и убедитесь, что включено поле, количество в которое нужно подсчитать.
Можно подсчитать поля большинства типов данных, за исключением полей, содержащих сложные повторяющиеся скалярные данные, такие как поле многомерных списков. -
На вкладке Конструктор в группе Показать или скрыть нажмите кнопку Итоги.
В бланке появится строка Итог, а в строке для каждого поля запроса будет указано Группировка.
-
В строке Итог щелкните поле, по которому вы хотите выполнить подсчет, и выберите в списке функцию Count.
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
Результаты запроса отображаются в режиме таблицы.
-
При необходимости вы можете сохранить запрос.
 Можно подсчитать поля большинства типов данных, за исключением полей, содержащих сложные повторяющиеся скалярные данные, такие как поле многомерных списков.
Можно подсчитать поля большинства типов данных, за исключением полей, содержащих сложные повторяющиеся скалярные данные, такие как поле многомерных списков.Подсчет записей в группе или категории
-
На вкладке Создать в группе Другое нажмите кнопку Конструктор запросов.
-
Дважды щелкните таблицу или таблицы, которые вы хотите использовать в запросе, а затем нажмите кнопку «Закрыть».
Таблица (или таблицы) появится в окне в верхней части конструктора запросов.
-
Дважды щелкните поле, содержащее данные категории, а также поле, значения в котором вы хотите подсчитать. Запрос не может содержать других описательных полей.
-
На вкладке Конструктор в группе Показать или скрыть нажмите кнопку Итоги.
В бланке появится строка Итог, а в строке для каждого поля запроса будет указано Группировка.
-
В строке Итог щелкните поле, по которому вы хотите выполнить подсчет, и выберите в списке функцию Count.
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
Результаты запроса отображаются в режиме таблицы.
-
При необходимости вы можете сохранить запрос.
К началу страницы
Справочные сведения об агрегатных функциях
В следующей таблице перечислены и отписаны агрегатные функции Access, которые можно использовать в строке итогов и в запросах. Помните, что в Access предусмотрено больше агрегатных функций для запросов, чем для строки итогов. Кроме того, при работе с проектом Access (внешней базой данных Access, которая подключается к базе данных Microsoft SQL Server) можно использовать расширенный набор агрегатных функций, предоставляемый SQL Server. Дополнительные сведения о них см. в электронной документации Microsoft SQL Server.
Дополнительные сведения о них см. в электронной документации Microsoft SQL Server.
Функция | Описание | Поддерживаемые типы данных |
|---|---|---|
|
Сумма |
Суммирует элементы в столбце. Подходит только для числовых и денежных данных. |
«Число», «Действительное», «Денежный» |
|
Среднее |
Вычисляет среднее значение для столбца. |
«Число», «Действительное», «Денежный», «Дата/время» |
|
Число |
Подсчитывает число элементов в столбце. |
Все типы данных, за исключением сложных повторяющихся скалярных данных, таких как столбец многозначных списков. Дополнительные сведения о списках, которые могут быть многоценными, см. в руководстве по полям, которые могут быть многоценными, а также к созданию или удалите многофаентное поле. |
|
Максимум |
Возвращает элемент, имеющий наибольшее значение. |
«Число», «Действительное», «Денежный», «Дата/время» |
|
Минимум |
Возвращает элемент, имеющий наименьшее значение. Для текстовых данных наименьшим будет первое по алфавиту значение, причем Access не учитывает регистр. Функция игнорирует пустые значения. |
«Число», «Действительное», «Денежный», «Дата/время» |
|
Стандартное отклонение |
Показывает, насколько значения отклоняются от среднего. Дополнительные сведения об этой функции см. в статье Отображение итогов по столбцу в таблице. |
«Число», «Действительное», «Денежный» |
|
Дисперсия |
Вычисляет статистическую дисперсию для всех значений в столбце. Подходит только для числовых и денежных данных. Если таблица содержит менее двух строк, Access возвращает пустое значение. Дополнительные сведения о функциях для расчета дисперсии см. в разделе Отображение итогов по столбцу в таблице. |
«Число», «Действительное», «Денежный» |
 Столбец должен содержать числовые или денежные величины или значения даты или времени. Функция игнорирует пустые значения.
Столбец должен содержать числовые или денежные величины или значения даты или времени. Функция игнорирует пустые значения. Для текстовых данных наибольшим будет последнее по алфавиту значение, причем Access не учитывает регистр. Функция игнорирует пустые значения.
Для текстовых данных наибольшим будет последнее по алфавиту значение, причем Access не учитывает регистр. Функция игнорирует пустые значения.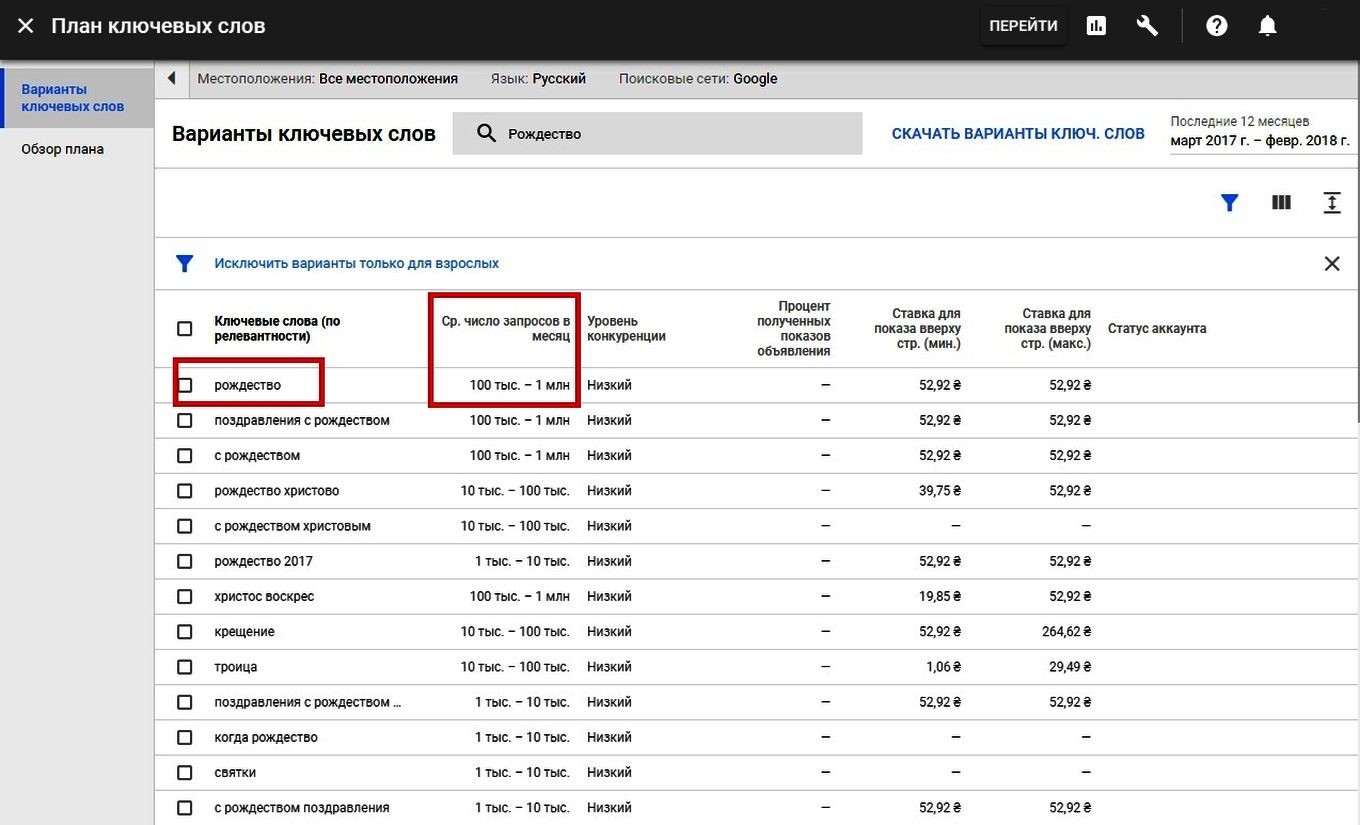
К началу страницы
что такое, методы определения частоты – Блог TRINET
Что такое частотность поисковых запросов
Частотность – это количественная величина, показывающая сколько раз пользователь обращался к поисковой системе с конкретным запросом. Как правило, рассчитывается за последний месяц. Зная спрос, SEO-специалист поймет, есть ли поисковый спрос, нужно ли создавать посадочную страницу, а также сможет спрогнозировать трафик, который получит продвигаемый сайт при ранжировании в ТОП-10.
Как правило, рассчитывается за последний месяц. Зная спрос, SEO-специалист поймет, есть ли поисковый спрос, нужно ли создавать посадочную страницу, а также сможет спрогнозировать трафик, который получит продвигаемый сайт при ранжировании в ТОП-10.
В данной статье пойдет речь о том, какой может быть частотность запроса и как ее определить.
Виды частотностей в поисковой системе Яндекс
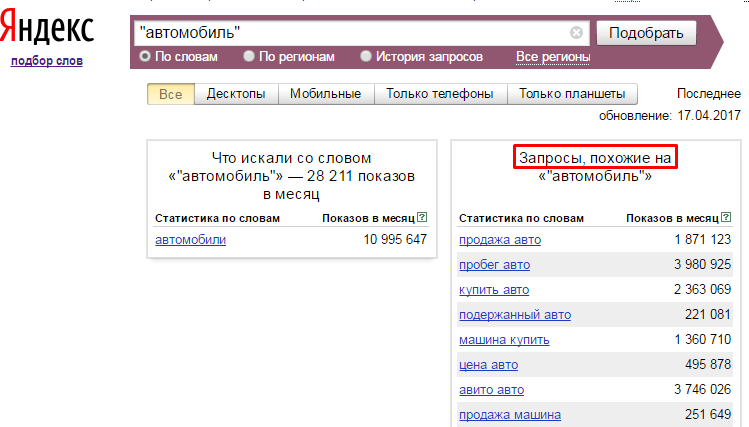
Один из инструментов определения частотностей является сервис от поисковой системы (далее ПС) Яндекс – WordStat. Он показывает популярность фразы в одноименной поисковой системе. Причем, посмотреть можно несколько видов частотностей, в зависимости от операторов, которые применяются. На примере запроса «поисковое продвижение» разберемся подробнее.
- Поисковое продвижение – такой запрос без каких-либо операторов покажет общую частотность по фразе, ее аналогам и словоформам.
Число 23 504 на рисунке выше означает, какое количество показов было со словом «поисковое продвижение» в ПС Яндекс за последний месяц.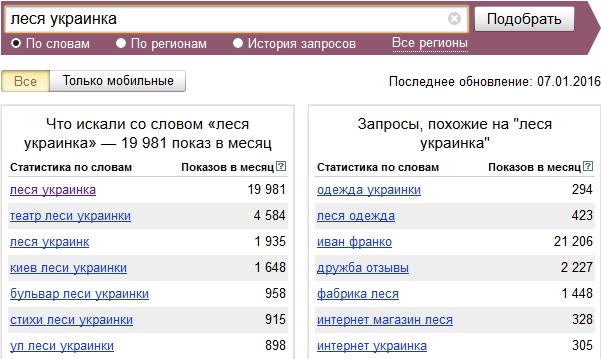 Нужно учитывать, что в эту цифру входят и более длинные фразы, например, «поисковое продвижение сайтов» и фразы с измененными словоформами, например, «услуги поискового продвижения».
Нужно учитывать, что в эту цифру входят и более длинные фразы, например, «поисковое продвижение сайтов» и фразы с измененными словоформами, например, «услуги поискового продвижения».
- Оператор «кавычки» («поисковое продвижение») фиксирует количество слов в запросе, а значит фразы формата «поисковое продвижение Москва» учитываться не будут. Как видно ниже, частота спроса стала значительно меньше.
- Оператор «кавычки и восклицательный знак» («!поисковое !продвижение») фиксирует количество слов, а также форму первого и второго слова, перед которыми стоит знак восклицания. В такой расчет не войдут запросы «поисковым продвижением» и т.д.
- Оператор «квадратные скобки» ([поисковое продвижение]) фиксирует порядок слов. Сюда не войдет фраза «продвижение поисковое помогает». Но необходимо иметь в виду, что будут посчитаны все словоформы, а также не будет зафиксировано количество слов.
- Оператор «кавычки и квадратные скобки» («[поисковое продвижение]») как раз может фиксировать и порядок слов, и их количество в запросе.

При этом словоформы все еще учитываются. Это означает, что сюда могут попасть запросы «поисковому продвижению». Для того, чтобы зафиксировать форму слова используем «!» перед ним, как в примере ниже.
- Оператор «кавычки, квадратные скобки и знак восклицания» («[!поисковое продвижение]») — фиксирует количество и порядок слов в запросе, а также словоформу первого слова, перед которым стоит знак восклицания.
- Спецоператор «плюс» (+в поисковое продвижение) в обязательном порядке фиксирует служебные части речи, местоимения, цифры и другие слова, не несущие дополнительного смысла. В нашем случае обязательным стал предлог «в» и ниже на рисунке видно, как поменялись статистика и список запросов.
В результате можно максимально точно определить, как часто пользователи интересуются той или иной тематикой в поисковой системе Яндекс.
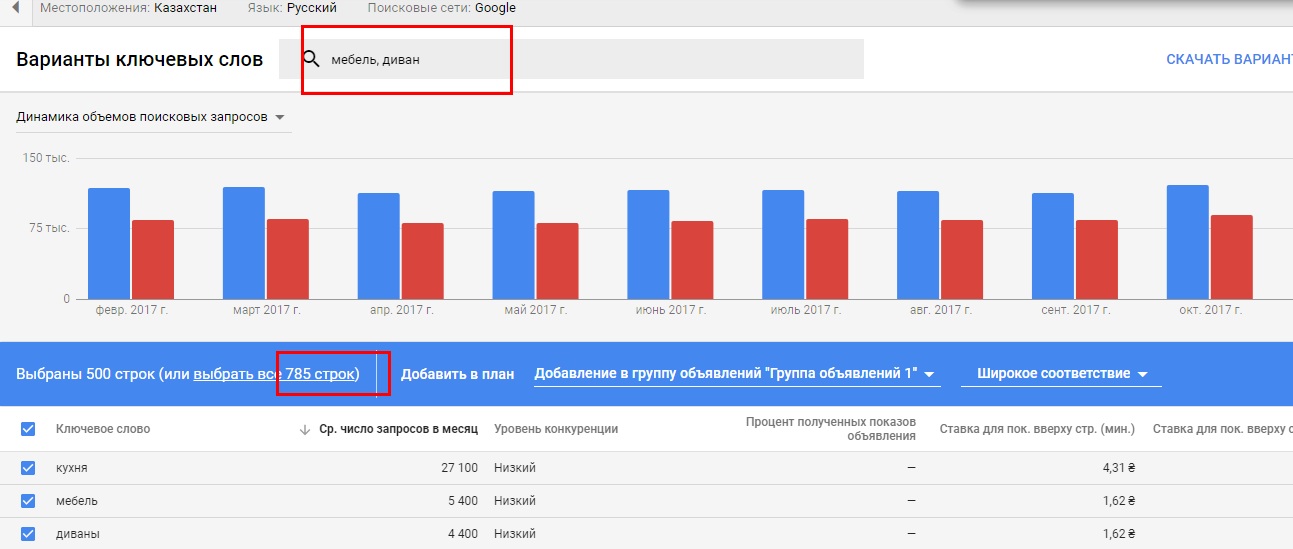
Частотность запросов в поисковой системе Google
ПС Google не дает специального сервиса для определения частотности поисковых фраз в отличие от Яндекс. Для сбора статистики можно использовать «Планировщик ключевых слов» в сервисе для запуска рекламы – Google Ads.
Для сбора статистики можно использовать «Планировщик ключевых слов» в сервисе для запуска рекламы – Google Ads.
Там есть два варианта: «Посмотреть количество запросов и прогнозы» или «Найти новые ключевые слова». Первый покажет лишь приблизительные значения, а вот с помощью второго их можно уточнить. Как именно это можно сделать описано ниже в пункте «Инструменты для определения частотностей».
Высоко- средне- и низкочастотные запросы
Существует еще одна важная классификация, на которую точно стоит обратить внимание при составлении семантического ядра. Согласно ей запросы подразделяются на следующие виды:
- высокочастотные или ВЧ (частотность от 5 000)
- среднечастотные или СЧ (частотность от 1 000 до 5 000)
- низкочастотные запросы или НЧ (частотность от 1 до 1 000)
Цифры очень условные и мы – рекомендуем ориентироваться на нишу и географию продвигаемого сайта. Ниже приводим несколько характеристик, которые способны помочь в классификации запросов.
Высокочастотные запросы
Данный вид запросов включает в себя максимально общие фразы. Они состоят, как правило, из 1-2 слов. По такому ключевику не всегда очевидно, что хочет пользователь, из-за этого они часто имеют более низкую конверсионность. Но всегда есть исключения, поэтому рекомендуем анализировать именно конкретную ситуацию. Если сайт молодой лучше начинать с НЧ и СЧ запросов, а ВЧ подключать со временем.
Пример ВЧ запроса показан ниже:
Среднечастотные запросы
Эти запросы содержат более точные фразы, обычно состоят из 3-4 слов. Хотя они все еще и охватывают большое количество пользователей, но имеют уже более понятный интент. Пример указан ниже на рисунке.
Низкочастотные запросы
Это наиболее точные запросы, показывающие намерения пользователя. Как правило, содержат 5 и более слов. Мы советуем всегда добавлять в СЯ часть НЧ фраз, которые привлекут целевой трафик на сайт. При этом они помогают более эффективно продвигать страницы за счет текстовой оптимизации.
Пример НЗ запроса показан ниже:
Отличие частотности от конкуренции
Еще один параметр – это конкуренция поискового запроса. Здесь они делятся на:
- высококонкурентные (ВК)
- среднеконкурентные (СК)
- низкоконкурентные (НК)
Низкочастотный запрос еще не значит, что по нему низкая конкуренция. На показатель конкурентности влияет множество факторов. Например, количество главных страниц в ТОП-10, прямые вхождения ключевой фразы в заголовок страницы, рекламные блоки в выдаче и т.д.
Данная тема будет затронута в другой публикации.
Зачастую, конкуренция высокая, когда запросу подходит большое количество сайтов выдачи, и низкая, если оптимизированных под запрос сайтов немного.
Одна из методик определения конкуренции, посмотреть количество результатов по запросу. Например, “продвижение сайтов спб” — 10 млн. подходящих результатов.
Показано ниже на рисунке:
Другая методика – анализировать показатель, рассчитываемый по количеству внешних входящих ссылок/доменов. В разных сервисах он может называться по-разному. Например, в сервисе Ahrefs от компании Google он называется Keyword Difficult.
Пороги значений обозначены ниже:
Что такое сезонность запроса и где её посмотреть
Частотность поисковой фразы часто сильно зависит от сезонности. Например, запрос «купить елку» ежегодно начинает набирать популярность в ноябре, пик в декабре, а в феврале уже не интересен пользователям.
Другой пример – запрос «купить септик». Актуален в течение всего года, но популярность повышается весной и летом, когда люди перебираются в частные дома и на дачи.
Сезонность – это изменения (подъемы или падения) трафика, повторяющиеся ежегодно под влиянием каких-то внешних событий. Например, смена времени года, праздники и т.д.Проверить ее можно в Яндекс WordStat. Необходимо:
- зайти в сервис
- ввести запрос
- выбрать регион
- нажать «История запросов»
Под графиком находятся данные по месяцам за последние два года:
Еще один инструмент для определения сезонности – сервис Google Trends.
Необхидимо:
- ввести запрос
- выбрать регион, источник и временной промежуток
Данные можно посмотреть, начиная с 2004 года. Можно сравнить до пяти запросов. Google показывает значения в баллах. Например, курсор на скриншоте ниже наведен на пик популярности поискового запроса – это 100 баллов.
Что такое геозависимость запроса и как ее проверить
Геозависимость запроса показывает нам, зависит ли показ по этому ключевому слову от местонахождения пользователя. Например, по запросу «услуги нотариуса» человек из Санкт-Петербурга увидит одни сайты в выдаче, а человек из Тулы – совершенно другие. Яндекс считает, что до 30 % обращений к ПС являются геозависимыми. Как правило, к ним относятся коммерческие запросы.
Вручную проверить геозависимость запроса можно методом сравнения ТОП-10 по двум разным регионам или подсветке топонима в поисковой выдаче.
Заходим в ПС Яндекс, смотрим выдачу по двум разным регионам и анализируем. Регион можно поменять внизу страницы поиска:
На примере запроса «услуги нотариуса» видим, что выдача для Санкт-Петербурга и Тулы разная и поисковая система в обеих выдачах подсвечивает актуальный для пользователя город.
Ниже представлен пример для г. Санкт-Петербург:
Мы видим преимущественно региональные сайты Петербурга.
На следующем скриншоте показаны результаты для пользователя из г. Тула:
В данном случае преимущественно региональные сайты Тулы.
Инструменты для определения частотностей
А теперь к самому интересному – как же определить частотность?
Для этого можно использовать различные сервисы.
В Яндекс WordStat необходимо ввести запрос, выбрать регион, интересующее устройство, нажать «Подобрать», далее сервис покажет результат:
Можно посмотреть статистику по регионам и городам:
Яндекс.Директ – сервис для запуска рекламы в поисковой системе Яндекс. Посмотреть частотность запроса можно при создании рекламной кампании. Доходим до второго шага «Выбор аудитории», задаем регион и нажимаем «Подобрать фразы». При вводе фразы получаем статистику по ним.
Частота запросов в Яндекс.Директ может несколько отличаться от показателей Яндекс.Вордстат. Это происходит, потому что последний не учитывает вложенные запросы с прогнозом меньше пяти. Кроме того, данные берутся за последние 30 дней, но в Директе они обновляются чаще из-за чего могут быть расхождения в пару дней. И наконец, необходимо отслеживать нет ли минус-слов в Яндекс.Директе, которые могут повлиять на статистику.
В случае снятия данных за год, они могут отличаться от данных в сервисе WordStat и быть некорректными.
Google Keyword Planner – инструмент для подбора ключевых слов при создании рекламы в ПС Google. Поможет при сборе статистики по запросам в Google.
Необходимо зайти в инструмент, авторизоваться и выбрать «Найдите новые ключевые слова»:
Далее нужно ввести слова через запятую и нажать «Показать результаты»:
Далее необходимо отметить добавленные слова галочкой (расширить список можно будет дальше), выбрать соответствие (точное, широкое, фразовое) и нажать «Добавить ключевые слова»:
Рядом с каждым запросом появляется зеленый значок «В плане»:
Переходим в пункт меню «Ключевые слова», выбираем корректный регион вверху страницы, раскрываем график по стрелочке, выставляем максимальную цену за клик:
Для анализа нужно использовать столбец «Показы»:
Этот способ покажет точную статистику по Google, насколько это возможно в рамках данной поисковой системы.
SemRush – сервис, который может показать подробную информацию по ключевому слову, в том числе уровень конкурентности, вариации ключевого слова, поисковую выдачу и другие параметры. Часть инструментов в нем платная.
Ahrefs – еще один сервис для просмотра статистики по ключевому слову и подбора аналогов. Также является платным.
Серверы SemRush, Ahrefs и другие подобные инструменты получают данные о количестве запросов методом покупки сlickstream у крупных провайдеров, поэтому их данные будут отличаться от данных в Google Keyword Planner.
Софт для ручного и автоматического съема частотностей
В продолжение предыдущего пункта, приведем несколько примеров софта для ручного и автоматического сбора частотностей.
Плагин WordStarter – бесплатное расширение для Яндекс.Вордстат, которое позволяет собирать ключевые слова и их частоту, задавать минус-слова и экспортировать все это для последующей обработки.
KeyCollector – платный софт (есть бесплатный аналог Словоеб), с помощью которого можно быстро собрать ключевые фразы и их параметры, в том числе частотность, конкурентность, стоимость, посмотреть сезонность запроса и т.д.
TopVisor – платный сервис для сбора статистики из Яндекс и Google.
Для проверки частоты необходимо:
- создать проект
- перейти на страницу «Поисковые запросы»
- добавить запросы
- выбрать источник, регион
RushAnalytics – еще один платный сервис, в котором есть инструмент для парсинга ключевых слов и частотностей из Яндекс и Google на высокой скорости.
Serpstat – этот сервис позволяет автоматизировать процесс, оперативно собирать большие объемы данных по запросам и выгружать их в удобном формате. Сервис также платный.
Для того, чтобы выбрать максимально удобный и полезный сервер в конкретном для вас случае, лучше попробовать каждый из представленных выше.
Заключение
Есть много нюансов в определении частотности запросов, о каждом из которых важно помнить при составлении и корректировке семантического ядра. Необходимо обязательно
проверять сезонность, конкурентность ключевых слов, регулировать соотношение высоко-, средне- и низкочастотных запросов и выбирать для сбора статистики те источники и инструменты, которые лучшего всего решат задачи конкретного проекта.
Если у вас остались вопросы, мы с удовольствием разберем их в комментариях. Возможно, вам требуется помощь с составлением семантики и разработкой структуры для вашего проекта? Пишите, наши профессионалы смогут помочь вам.
Сетевой монитор — Инструменты разработчика Firefox
Сетевой монитор (Network Monitor) показывает все сетевые запросы, которые выполняет Firefox (например, когда загружается страница или выполняются запросы типа XMLHttpRequests), а также как долго выполняется запрос и детали запроса.
Есть несколько различных способов:
Пожалуйста, обратите внимание, что сочетание клавиш было изменено в Firefox 55
- Нажмите Ctrl + Shift + E ( Command + Option + E на Mac).
- Выберите «Сеть» из меню «Web Developer» (это подменю меню «Tools» на OS X или Linux).
- Кликните значок (), который находится на панели инструментов в меню (), а после выберите «Сеть».
Сетевой монитор появится внизу окна браузера. Для просмотра запросов перезагрузите страницу:
Сетевой монитор записывает сетевые запросы постоянно, пока открыты Инструменты разработчика, даже когда вкладка Сеть не выбрана. Поэтому можно начать отладку страницы, например, в Веб-консоли, а потом переключиться и посмотреть сетевую активность в Сетевом мониторе без перезагрузки страницы.
Интерфейс разбит на четыре основные части:
Начиная с Firefox 47 и далее, панель инструментов находится сверху окна. В ранних версиях Firefox она располагалась снизу.
Она содержит:
Примечание: Начиная с Firefox 58, кнопка фильтра «Flash»более недоступна, поэтому запросы Flash включены в фильтр «Прочее» (баг 1413540).
По умолчанию Сетевой монитор показывает список всех сетевых запросов, сделанных по ходу загрузки страницы. Каждый запрос отображается в отдельной строке:
По умолчанию Сетевой монитор очищается каждый раз, когда вы переходите на новую страницу или перезагружаете текущую. Вы можете это изменить посредством включения галочки «Включить непрерывные логи» в настройках.
Поля таблицы запросов
Начиная с Firefox 55, вы можете выбирать разные колонки, кликая правой кнопкой мыши на заголовок таблицы, а затем выбирая нужные колонки в выпадающем меню. Опция «Восстановить колонки» доступна для сброса списка колонок к исходному варианту. Список колонок:
- Статус (Status): возвращённый HTTP-код статуса. Здесь есть цветной значок: Точный код отображён сразу после значка.
- Метод (Method): HTTP-метод запроса.
- Файл (File): базовое имя запрошенного файла.
- Протокол (Protocol): Используемый сетевой протокол. (По умолчанию скрытая колонка. Новая в Firefox 55)
- Схема (Scheme): Схема (https/http/ftp/…), взятая из пути запроса. (По умолчанию скрытая колонка. Новая в Firefox 55)
- Домен (Domain): домен, к которому происходит запрос.
- Если запрос использовал SSL/TLS, и подключение имело низкий уровень безопасности, например, некриптостойкий шифр, то вы увидите предупреждающий треугольник у имени домена. Вы сможете увидеть более подробную информацию о проблеме на вкладке Защита в области деталей запроса.
- Наведите мышь на имя домена, чтобы увидеть IP-адрес.
- Значок рядом с доменом предоставит расширенную информацию о статусе безопасности этого запроса. Смотрите Значки безопасности.
- Удалённый IP (Remote IP): IP-адрес сервера, отвечающего на запрос. (По умолчанию скрытая колонка. Новая в Firefox 55)
- Причина (Cause): Причина, по который был вызван запрос, например, XHR-запрос,
<img>, скрипт, скрипт, запрашивающий изображение и др. (Новая в Firefox 49) - Тип (Type):
Content-typeответа. - Куки (Cookies): Количество куки, связанных с запросом. (По умолчанию скрытая колонка. Новая в Firefox 55)
- Set-Cookies: Количество куки, связанных с ответом. (По умолчанию скрытая колонка. Новая в Firefox 55)
- Передано (Transferred): число байт, которые фактически были переданы для загрузки ресурса. Это число будет меньше, чем Размер, если ресурс был упакован. Начиная с Firefox 47, если ресурс был получен из кеша service worker, то в этой ячейке будет отображено «service worker». Если значение получено из кеша браузера — то «кешировано».
- Размер (Size): размер переданного ресурса.
По клику на заголовок колонки произойдёт сортировка всех запросов по этой колонке. По умолчанию сортировка происходит по колонке «Временная шкала».
Миниатюры изображений
Если файл является изображением, то в строку будет включена его миниатюра, при наведении на которую появится просмотр изображения во всплывающей подсказке:
Значки безопасности
Сетевой монитор показывает значок в колонке Домен:
Это предоставляет дополнительную информацию о безопасности запроса:
По слабым и ошибочным HTTPS-запросам, вы можете посмотреть более детальную информацию о проблеме на вкладке «Защита».
Колонка «Причина» (Cause)
Колонка «Причина» указывает, что было причиной запроса. Обычно это очевидно, и можно увидеть корреляцию между этой колонкой и колонкой «Тип». Наиболее распространённые значения:
- document: Исходный HTML-документ.
- img: Элемент
<img>. - imageset: Элемент
<img>. - script: Файл JavaScript.
- stylesheet: Файл CSS.
Когда запрос срабатывает из JavaScript, то слева от надписи в колонке «Причина» появится маленький значок JS. При наведении на него курсором мыши появится всплывающее окно, содержащее трассировку стека для запроса; это даёт подсказку, откуда был вызван запрос.
Во всплывающей подсказке вы можете кликнуть в любой из появившихся элементов, чтобы открыть связанный скрипт в панели «Отладчик».
Временной график
Список запросов отображает время выполнения разных частей каждого запроса.
Каждый график дан в горизонтальном виде в своей строке запроса, сдвинутый относительно позиций других запросов, поэтому вы можете увидеть полное время использованное для загрузки страницы. Для понимания деталей цветового кодирования, используемого здесь, загляните в раздел «Тайминги».
Начиная с Firefox 45 график содержит две вертикальные линии:
- синяя линия маркирует точку, в которой произошло событие
DOMContentLoadedстраницы - красная линия маркирует точку, в которой произошло событие
loadстраницы
Фильтр запросов
Вы можете отфильтровать запросы по типу контента, по URL, по XMLHttpRequests или WebSocket, или по свойствам запроса.
Фильтрация по типу контента
Для фильтрации по типу контента используйте кнопки на панели инструментов.
Фильтрация XHR
Для просмотра только XHR-запросов используйте кнопку «XHR» панели инструментов.
Фильтрация WebSockets
Для просмотра только подключений WebSocket, используйте кнопку «WS» панели инструментов.
Для контроля данных, передаваемых через WebSocket-соединения, попробуйте использовать дополнение WebSocket Sniffer.
Фильтрация по URL
Для фильтрации по URL используйте поле поиска, расположенное правее на Панели инструментов. Кликните на это поле или нажмите клавиши Ctrl + F или Cmd + F, и начните набирать текст. При этом список запросов будет отфильтрован по строкам, содержащим введённую подстроку; кроме того, фильтрация также будет происходить по колонкам «Домен» и «Файл».
Начиная с Firefox 45, вы можете фильтровать запросы, которые не содержат введённую вами строку, предварив вводимую строку символом «-«. Например, запрос «-google.com» покажет все запросы, которые не имеют подстроки «google.com» в своих URL.
Фильтрация по свойствам
Для фильтрации по конкретным свойствам запроса используйте поле поиска на Панели инструментов. Но это поле признаёт только определённые ключевые слова, которые используются для фильтрации по конкретным свойствам запроса. За ключевым словом следует двоеточие, а затем значение фильтра. Значение фильтра регистровнезависимое. Если написать знак «минус» (-), то это применит к фильтру отрицание. Также можно комбинировать несколько фильтров через пробел.
| Ключевое слово | Значение | Примеры |
|---|---|---|
status-code | Показать ресурсы, имеющие указанный код HTTP-статуса. | status-code:304 |
method | Показать ресурсы, запрошенные через указанный HTTP-метод запроса. | method:post |
domain | Показать ресурсы, пришедшие с указанного домена. | domain:mozilla.org |
remote-ip | Показать ресурсы, пришедшие с сервера с указанным IP-адресом. | remote-ip:63.245.215.53remote-ip:[2400:cb00:2048:1::6810:2802] |
cause | Показать ресурсы, соответствующие типу причины. Типы можно найти в описании колонки «причина». | cause:jscause:stylesheet |
transferred | Показать ресурсы, имеющие указанный размер переданных данных или размер близкий к нему. Буква k может быть использована как суффикс для килобайт, m — мегабайт. Например, значение 1k эквивалентно 1024. | transferred:1k |
size | Показать ресурсы, имеющие указанный размер (после декомпрессии) или размер близкий к указанному. Буква k может быть использована как суффикс для килобайт, m — мегабайт. Например, значение 1k эквивалентно 1024. | size:2m |
larger-than | Показать ресурсы, которые больше чем указанный размер в байтах. Буква k может быть использована как суффикс для килобайт, m — мегабайт. Например, значение 1k эквивалентно 1024. | larger-than:2000-larger-than:4k |
mime-type | Показать ресурсы, которые соответствуют указанному MIME-типу. | mime-type:text/htmlmime-type:image/pngmime-type:application/javascript |
is | is:cached и is:from-cache показывают только ресурсы, пришедшие из кеша.is:running показывает только ресурсы, передаваемые в настоящее время. | is:cached-is:running |
scheme | Показать ресурсы, переданные через указанную схему. | scheme:http |
has-response-header | Показать ресурсы, содержащие указанный HTTP-заголовок в ответе. | has-response-header:cache-controlhas-response-header:X-Firefox-Spdy |
set-cookie-domain | Показать ресурсы, имеющие заголовок Set-Cookie с атрибутом Domain, который имеет указанное значение. | set-cookie-domain:.mozilla.org |
set-cookie-name | Показать ресурсы, имеющие заголовок Set-Cookie и в нём атрибут с указанным именем. | set-cookie-name:_ga |
set-cookie-value | Показать ресурсы, имеющие заголовок Set-Cookie и в нём атрибут с указанным значением. | set-cookie-value:true |
regexp | Показать ресурсы, имеющие URL, который соответствует данному регулярному выражению. | regexp:\d{5} |
Контекстное меню
При клике правой клавишей мыши по строке отобразится контекстное меню:
- Копировать URL
- Копировать параметры URL (новое в Firefox 40)
- Копировать POST-данные (новое в Firefox 40, только для запросов POST)
- Копировать как cURL
- Копировать заголовки запроса (новое в Firefox 40)
- Копировать заголовки ответа (новое в Firefox 40)
- Копировать ответ (новое в Firefox 40)
- Копировать изображение как URL данных (только для изображений)
- Копировать всё как HAR (новое в Firefox 41)
- Сохранить всё как HAR (новое в Firefox 41)
- Сохранить изображение как (новое в Firefox 55, только для изображений)
- Изменить и снова отправить
- Открыть в новой вкладке
- Запустить анализ производительности
Изменить и снова отправить
Эта опция открывает редактор, позволяющий вам отредактировать метод запроса, URL, параметры и заголовки и ещё раз отправить запрос.
Копировать как cURL
Эта опция копирует сетевой запрос в буфер как команду cURL, и вы сможете запустить его из командной строки. Команда может включать следующие опции:
-X [METHOD] | Если метод запроса не GET или POST |
--data | Для параметров запроса, закодированных в URL |
--data-binary | Для параметров запроса типа Multipart. Например, файлы. |
--http/VERSION | Если HTTP версия не 1.1 |
-I | Если метод запроса HEAD |
-H | Один для каждого заголовка запроса. Начиная с Firefox 34, если присутствует заголовок «Accept-Encoding», то команда cURL будет включать |
Копировать/Сохранить всё как HAR
Новое в Firefox 41.
Эти операции создают HTTP-архив (HAR) для всех запросов из списка. Формат HAR позволяет вам экспортировать детальную информацию о сетевых запросах. «Копировать всё как HAR» копирует данные в буфер, «Сохранить всё как HAR» открывает диалог сохранения архива на диск.
После щелчка по строке в правой части Сетевого монитора появится новая панель, которая предоставит более детальную информацию о запросе.
Вкладки сверху этой панели позволяют переключаться между следующими страницами:
- Заголовки (Headers)
- Куки (Cookies)
- Параметры (Params)
- Ответ (Response)
- Тайминги (Timings)
- Защита (Security) (только для защищённых запросов)
- Предпросмотр (Preview) (только для типа HTML) (Удалено в Firefox 55)
Щелчок по значку, расположенном справа на панели инструментов (справа от поиска), закроет эту панель и вернёт вас к просмотру списка.
Эта вкладка содержит основную информацию о запросе:
Она включает:
- URL-запроса
- Метод запроса
- Удалённый IP-адрес и порт (новое в Firefox 39)
- Код состояния со ссылкой на документацию на сайте MDN (если она есть)
- HTTP-заголовки запроса и ответа, которые были отправлены
- кнопка «Изменить и снова отправить»
Вы можете отфильтровать отображаемые заголовки:
Кроме того, каждый заголовок это ссылка для углублённого изучения документации заголовков HTTP.
Куки
(Cookies)Эта вкладка показывает все детали кук, которые были отправлены с запросом или ответом:
Как и в случае с заголовками их список можно фильтровать.
Параметры
(Params)Эта вкладка отображает параметры GET и данные POST запроса:
Ответ
(Response)Полное содержание ответа. Если в ответе HTML, JS или CSS, то он отобразится как текст:
Если ответ — JSON, то он отобразится как просматриваемый объект.
Если ответ — изображение, то вкладка будет содержать предпросмотр:
Тайминги
(Timings)Вкладка «Тайминги» разбивает сетевой запрос на следующие этапы, определённые в спецификации HTTP-архива (HAR):
| Имя | Описание |
|---|---|
| Блокировка (Blocked) | Время, потраченное в очереди ожидания для создания сетевого соединения. Браузер накладывает ограничение на число одновременных соединений с одним сервером. В по умолчанию это 6, но это можно изменить, используя свойство |
| Разрешение DNS (DNS resolution) | Время на разрешение имени хоста. |
| Соединение (Connecting) | Время на создание TCP-соединения. |
| Отправка (Sending) | Время на отправку HTTP-запроса на сервер. |
| Ожидание (Waiting) | Ожидание ответа от сервера. |
| Получение (Receiving) | Время на чтение полного ответа с сервера (или из кеша). |
Здесь представлена детальная информация, есть аннотации, а также «графики-полосы» времени запроса, которые показывают разбивку общего времени на этапы:
Защита
(Security)Если работа с сайтом ведётся через HTTPS, то у вас появится дополнительная вкладка «Защита». Она содержит детали об используемой безопасной связи, включая: протокол, набор шифров, детали сертификата:
На вкладке «Защита» отображается предупреждение о слабой безопасности:
- Использование SSLv3 вместо TLS
- Использование шифра RC4
Предпросмотр
(Preview)Удалено в Firefox 55.
Если тип файла это HTML, то появится вкладка «Предпросмотр». Она отображает вид, как выглядит HTML-страница в браузере:
В Firefox 58 и далее, Сетевой монитор имеет кнопку, которая приостанавливает и возобновляет запись трафика текущей страницы. Это полезно, когда, например, вы хотите получить установившийся вид страницы для отладки, но вид страницы пока ещё меняется, потому что она ещё грузится или выполняются запросы. Кнопка «Пауза» позволяет увидеть текущий снимок состояния (snapshot).
Эта кнопка находится с краю слева на главной панели Сетевого монитора, и выглядит как обычная кнопка «Пауза» — .
Вот её вид:
Когда она нажата, то меняет значок на иконку «Пуск» (треугольник), и вы можете возобновить запись трафика, нажав на эту кнопку ещё раз.
Сетевой монитор включает инструмент для анализа производительности, который покажет вам, как долго браузер загружает различные части сайта.
Для запуска инструмента анализа производительности кликните значок «Часы» на панели.
(Кроме того, если у вас только что открытый Сетевой монитор, и список запросов ещё пуст, то у вас будут «Часы» в главном окне.)
Сетевой монитор загрузит сайт дважды: первый раз с пустым кешем браузера, а второй — с заполненным. Это имитирует вход пользователя на сайт впервые и последующие посещения. Он показывает результаты обоих запусков бок о бок горизонтально, либо вертикально, если окно браузера сжатое:
Результаты каждого запуска представлены в таблице и круговой диаграмме. Таблицы группируют ресурсы по типам и показывают их общий размер и общее время, занятое их загрузкой. Сопровождающие круговые диаграммы показывают относительный объём ресурсов каждого типа.
Для возврата в Сетевой монитор нажмите кнопку «Назад», расположенную слева от результатов.
Нажав на конкретную часть в круговой диаграмме вы перейдёте в Сетевой монитор, в котором будут автоматически установлены фильтры для просмотра запросов этого типа ресурса.
Определение количества запросов к приложению за месяц
В большинстве случаев, стоимость использования продукта Валарм WAF зависит от количества запросов, обработанных установлеными WAF‑нодами. Эта инструкция описывает способы для определения среднего количества запросов, которые обрабатывает ваше приложение.
Доступ к количеству запросов
Обычно, следующие команды имеют доступ к данным о количестве запросов:
DevOps
Технический отдел
Отдел по управлению облачными сервисами
Отдел по управлению платформами
DevSecOps
Системные администраторы
Администраторы приложений
Отдел по управлению сетями
Методы определения количества запросов
Для получения среднего количества запросов, обработанных приложением за месяц, могут применяться следующие способы:
Клиенты AWS с настроенным балансировщиком нагрузки ELB или ALB могут использовать AWS‑метрики балансировщика нагрузки.
Например: если среднее количество запросов в минуту равно 350 и в месяце 730 часов, количество запросов за месяц можно определить по формуле
350 * 60 * 730 = 15330000.Клиенты GCP с настроенным HTTP‑балансировщиком нагрузки могут использовать метрику https/request_count. Метрика недоступна для балансировщика NLB.
Пользователи Microsoft IIS могут получить среднее количество запросов в секунду из метрики Requests Per Sec для одного или нескольких IIS‑серверов. Для расчета количества запросов за месяц, умножьте полученное значение на среднее количество секунд в месяце:
730 * 3600.Пользователи сервисов по мониторингу приложений (New Relic, Datadog, AppDynamics, SignalFX и других) могут найти данные о количестве запросов в консоли сервиса. При просмотре и анализе данных убедитесь, что вы получили агрегированное значение по всем необходимым серверам.
Пользователи облачных сервисов по мониторингу приложений (Datadog, AWS CloudWatch и других) и внутренних систем мониторинга (Prometheus, Nagios и других) могут определить количество обработанных запросов по текущим метрикам.
Пользователи могут проанализировать количество записей в логах балансировщика нагрузки или веб‑сервера. Например, логи NGINX ротируются на веб‑сервере 1 раз в день и в лог‑файле 653525 записей:
cd /var/log/nginx/ zcat access.log.2.gz |wc -l # 653525- Количество запросов, обработанных за месяц:
653525 * 30 = 19605750. - Если известно общее количество веб‑серверов, можно определить среднее количество запросов, обработанных всем приложением.
- Количество запросов, обработанных за месяц:
В веб‑приложениях с настроенным сервисом Google Analytics или другим сервисом мониторинга, количество запросов может быть получено из метрик, собранных сервисом мониторинга.
Планировщик ключевых слов Google AdWords: настройка и использование
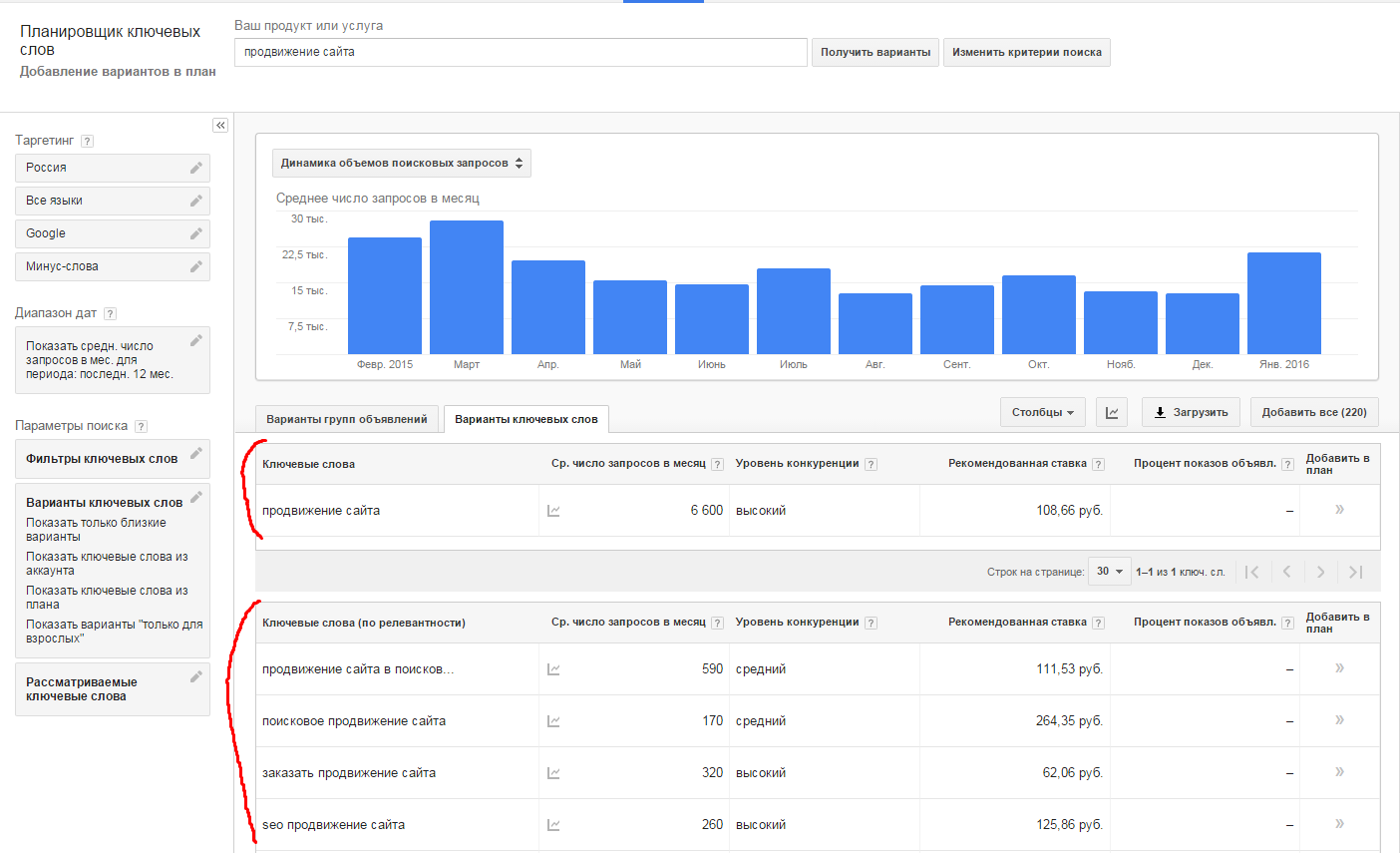
Для эффективного размещения рекламы в интернете через поисковые системы необходимо много внимания уделять корректности настроек показов. Упрощают эту работу разнообразные инструменты. Одним из главных является планировщик от Google (keyword planner). Он поможет составить семантическое ядро, которое пригодится и для SEO-оптимизации сайта.
Назначение планировщика ключевых слов
Google keyword planner ― это профессиональный инструмент подбора ключевых слов для продвижения сайта, канала на YouTube, размещения контекстной рекламы. Планировщик является альтернативой Yandex Wordstat (Яндекс Вордстат), в котором также можно подобрать ключевые слова и фразы для текущей рекламной кампании. Только Google keyword planner анализирует статистику запросов в своей поисковой сети, а также обладает более широким набором функциональных возможностей.
Продукты MANGO OFFICE для маркетолога и не только
Планировщик ключевых слов Google AdWords позволяет выполнять следующий список задач.
-
Поиск популярных запросов по категории, фразе или веб-сайту.
-
Подбор «ключевиков» на основе имеющихся.
-
Анализ статистики запросов по отдельным словам и фразам.
-
Составление прогноза результатов по текущим рекламным кампаниям в интернете.
-
Прогноз количества показов и кликов по ключевым словам.
Чтобы получить доступ ко всем этим возможностям, нужно зарегистрироваться в Google AdWords, а также тщательно изучить интерфейс планировщика.
Используемые термины
В первую очередь стоит напомнить значения и основные виды поисковых запросов.
-
Информационные. Они начинаются с наречий «как», «когда», «почему» или с существительных.
-
Навигационные. Ведут на определенные ресурсы. Например, vk.com.
-
Мультимедийные. Содержат запрос «видео» или «фото».
-
Коммерческие. В них встречаются слова «цена», «купить», «интернет-магазин» и другие.
-
Транзакционные. Они содержат поиск ресурсов для скачивания, заказа.
Кроме того, важно понимать значение следующих профессиональных терминов.
-
CTR ― соотношение числа кликов по объявлению или баннеру к количеству его показов.
-
ROI/ROMI ― ключевой показатель возврата маркетинговых инвестиций.
-
Конверсии ― соотношение числа посетителей сайта, совершивших целевое действие (покупку, заказ, скачивание), к общему их количеству.
-
Операторы соответствия ― специальные знаковые модификаторы Google AdWords, которые задают правила соответствия запроса пользователей установленным ключевым словам.
-
Охват ― количество показов объявления за определенный промежуток времени.
-
Парсинг ― сбор ключевых слов для дальнейшего анализа.
Есть и множество иных терминов в интернет-маркетинге, но для работы с планировщиком ключевых слов Google AdWords они практически не применяются.
Самостоятельная настройка и использование планировщика Google AdWords
Для некоторых новичков Google AdWords keyword tool может показаться сложным в настройке из-за широкого набора разнообразных опций. Пошаговая инструкция поможет разобраться в работе с данным инструментом.
Доступ к планировщику Google AdWords
Перейти к инструменту можно через аккаунт рекламного кабинета, выбрав раздел «Инструменты».
Можно открыть планировщик и по ссылке: https://ads.google.com/aw/keywordplanner
При входе keyword tool предлагает два варианта работы с инструментом.
-
Поиск ключевых слов.
-
Просмотр статистики и составление прогнозов по ключевым словам.
Чтобы начать подбор ключевых слов, нужно выбрать первый вариант.
При переходе в любой из представленных разделов нужно будет вначале ввести ключевые слова, задающие тематику семантического ядра. Достаточно будет 1-2 фраз для получения более 1 тыс. вариантов запросов.
После того как нужные фразы введены, нажмите кнопку «Начать» для перехода к функционалу выбранного раздела.
Поиск новых ключевых слов и статистика запросов
Если в первом разделе планировщика Google AdWords доступен подбор ключевых слов, то во втором будет видна детальная статистика. При попадании в любой из них можно задать параметры работы инструмента под свою рекламную кампанию.
Настройки планировщика Google AdWords
Первичные параметры работы инструмента отображаются на верхней панели планировщика. Здесь же они и редактируются.
Можно указать регион поиска фраз, выбрать период для анализа популярности, а также определить поисковые сети и язык.
Язык
По умолчанию статистика запросов Google AdWords показывается на русском языке. Но если вы желаете продвигать товары и услуги для англоязычной аудитории или среди пользователей иных стран, можете выбрать другой доступный язык.
В верхней части Google AdWords keyword planner нажмите на значок редактирования поля «Язык», чтобы открыть список возможных вариантов.
Просто кликните левой кнопкой мыши по нужному языку, чтобы он был применен для поиска запросов Google.
Поисковые сети
Для подбора ключевых фраз могут использоваться данные запросов только в поисковой системе Google (этот параметр установлен по умолчанию) или совместно со статистикой партнерских сайтов.
Чтобы выбрать второй вариант для более обширного сбора ключевых слов, нажмите на значок редактирования в поле «Поисковые сети» на верхней панели.
Источники ключевых фраз
Получить набор слов для анализа и составления семантического ядра можно используя следующие ресурсы.
-
Каталог сайта, если вы продвигаете товары в интернет-магазине.
-
Мета-теги конкурентных ресурсов.
-
Мозговой штурм и включение синонимов к фразам, задающим тематику.
Подобрать ключевые слова для Google AdWords возможно и с помощью простого ввода тематики вашего сайта. За раз планировщик выдает до 2 тыс. запросов схожих по значению, поэтому для первоначального поиска достаточно задать 2-3 общие фразы. Сделать это можно в верхней части страницы, наведя курсор на перечень слов.
Порядок слов в запросе
По умолчанию ключевые слова Google AdWords подбираются по правилу оператора широкого соответствия. Это значит, что учитываются синонимичные запросы, фразы схожие по значению, с измененным порядком слов и модифицированными словоформами, а также с возможными опечатками.
Если вы желаете установить определенный порядок слов в запросе, необходимо использовать оператор фразового или точного соответствия Google AdWords. Для этого перейдите в раздел «Ключевые слова» и нажмите на кнопку добавления.
Если вы введете интересующий запрос в открывшемся поле без дополнительных знаков, то к нему будет применен оператор широкого соответствия. Для включения фразового соответствия нужно указать слово или фразу в кавычках. Оператор точного соответствия применяется для запросов в квадратных скобках.
В этом же разделе можно указать минус-слова, то есть те, по которым ваше объявление не будет показываться, даже если остальная поисковая фраза запроса соответствует заданным ключевым словам.
После того как все ключевые слова с операторами соответствия Google AdWords внесены выберите группу объявлений, к которой нужно их применить и нажмите кнопку «Сохранить».
Установить правила соответствия можно и на вкладке с вариантами ключевых слов. Выберите интересующую группу запросов, отметив их галочками, и укажите нужный тип соответствия в выпадающем списке.
Поиск фраз по регионам
Как известно, Google, в отличие от Яндекса, является международной поисковой системой. Потому и рекламные объявления можно размещать для пользователей разных регионов планеты. Чтобы оно соответствовало актуальным запросам, сбор ключевых фраз также можно настроить в соответствии с регионом.
В верхней панели планировщика Google AdWords выберите раздел «Местоположение».
Определите нужный регион для работы AdWords keyword на интерактивной карте в открывшемся окне. При выборе страны вы сразу же сможете увидеть охват аудитории в нем.
Аналогичные настройки можно задать и в разделе «Местоположение».
Анализ сезонности
Некоторые продукты пользуются популярностью лишь в конкретные периоды времени. Есть сезонные и событийные товары. Как и спрос на них с течением времени меняется популярность соответствующих запросов. Чтобы подобрать ключевые слова согласно сезонным колебаниям, можно воспользоваться отдельным инструментом Google Trends.
Введите поисковый запрос в поле сервиса, чтобы получить график изменения популярности.
В появившемся графике можно сразу увидеть охват, наведя курсор на определенный временной промежуток.
Здесь же можно выбрать регион и период для анализа.
Добавление ключевых слов в план
После того как все настройки подбора ключей в Гугл произведены, вы убедились в целесообразности использовании отдельных фраз в текущем сезоне, правила соответствия и операторы ключевых слов, минус-слова заданы, можно приступать к включению составленного списка в рекламную кампанию.
На вкладке «Варианты ключевых слов» отметьте подходящие запросы галочками. Выберите вариант добавления:
Определившись с параметрами Google AdWords keyword planner, нажмите кнопку «Добавить ключевые слова» для их сохранения.
Фильтры
Статистика Google AdWords по ключевым словам показывается в отдельной таблице на вкладке, посвященной списку вариантов.
В ней есть специальные фильтры, которые можно настроить в верхней части, выбрав меню «Столбцы».
Здесь же возможна установка особых фильтров. Например, исключение вариантов для взрослых.
Среднее число запросов в месяц
В этой графе планировщик Адвордс показывает усредненное значение поисковых запросов по каждой отдельной фразе и близким к ней вариантам.
Уровень конкуренции
Этот показатель говорит о соотношении количества рекламодателей по конкретному ключевому слову к общему числу поисковых запросов Google.
Процент полученных показов
С помощью данного показателя можно проверить, доступно ли увеличение охвата по ключевой фразе. Вычисляется как соотношения числа полученных показов к общему количеству запросов по данной ключевой фразе (точное соответствие) за последний месяц в текущем регионе.
Ставка для показа вверху страницы
Данный показатель позволяет спланировать бюджет продвижения по заданным ключевым словам. Он показывает уровень минимальных ставок, которые оплачивают рекламодатели за показ объявления на верхних позициях по конкретному запросу поиска.
Разбор и группировка (кластеризация) ключевых запросов в Google AdWords
Для большей оперативности и удобства работы с полученным списком ключевых слов планировщик поисковой системы разбивает добавленные фразы на отдельные сегменты. Увидеть их можно на вкладке «Сгруппированные варианты».
Каждая группа содержит определенное количество отдельных ключевых слов, которые можно посмотреть в раскрывающемся списке.
Группы или кластеры запросов можно добавлять в отдельную группу объявлений, новый план. Возможна и установка для них общего оператора Google AdWords.
Те же функции доступны при раскрытии группы и выбора отдельных слов внутри нее.
Удаление дублей
При обработке большого массива данных очень сложно осуществлять поиск идентичных ключевых слов, которые могут получиться из-за разного применения операторов соответствия AdWords. Помогут решить эту задачу быстро Google Таблицы и функция UNIQUE.
Скачайте составленный список ключевых слов.
Откройте полученный файл в приложении Google Таблицы. В командной строке задайте команду «UNIQUE (диапазон ячеек со списком ключевых фраз)». Система сама уберет все дубли, сохранив порядок уникальных значений.
Полученный список добавьте в новый план через вкладку «Ключевые слова».
Еще одним способом работы с неявными дублями является использование специализированных программ. Например, Key Collector. Загрузите в нее полученный из планировщика список ключевых слов и нажмите кнопку «Анализ неявных дублей» в разделе «Данные».
Удаление нецелевых запросов
К ним относятся так называемые минус-слова. Чтобы найти их быстро можно использовать ту же программу Key Collector. Для удаления нецелевых запросов нужно загрузить список подобранных ключевых слов из планировщика и зайти на вкладку «Данные». Здесь требуется нажать кнопку «Анализ групп».
В полученном результате вам будет удобно находить минус-слова. Выделите их и нажмите кнопку «Удалить фразы».
Для большего удобства можно не удалять минус-слова, а добавить их в тематический список. Внутри него вы всегда сможете перепроверить, не включены ли нужные ключевые фразы по ошибке в перечень стоп-запросов. Чтобы создать тематический список-минус слов в подготовленном отчете по анализу групп нужно выделить нужные слова и нажать на иконку «Стоп-слова».
Деление на группы
Для удобства работы с семантическим ядром все в той же программе Key Collector можно разделить ключевые слова из планировщика Google AdWords по следующим критериям:
Перейдите на вкладку «Данные» и нажмите кнопку «Анализ групп». В полученном результате выделите интересующие кластеры ключей. Автоматически на главном экране Key Collector будут отмечены соответствующие фразы. Чтобы перенести их в отдельную группу, нужно перейти к разделу «Сбор данных». В нем нажмите кнопку переноса фраз.
По итогу вы получите сегментированный список ключевых запросов, которым будет легко управлять в Google AdWords.
Планирование бюджета и прогнозы
Google AdWords поможет быстро и легко проверить, насколько правильно собрано семантическое ядро. После того как вы установили все настройки, подобрали ключевые слова, операторы соответствия, минус-слова, перейдите на вкладку «Обзор плана». Здесь можно увидеть общий бюджет затрат с учетом прогнозируемого охвата по списку ключевых фраз, а также:
-
число показов;
-
количество кликов;
-
среднюю стоимость за клик;
-
CTR;
-
среднюю позицию объявления.
Здесь же можно добавить и другие показатели конверсии для более подробного прогноза.
В нижней части экрана вы увидите ранжирование ключевых фраз по их стоимости, а также прогноз источников трафика (с ПК, со смартфонов или планшетов).
Перенос из планировщика в ADS (AdWords)
Просто собрать семантическое ядро недостаточно. Его нужно применить к рекламной кампании. Чтобы выполнить перенос ключевых слов для Google AdWords перейдите на вкладку вариантов или групп ключевых запросов. Выделите интересующие фразы и слова и нажмите кнопку «Добавить в группу объявлений», выберите из выпадающего списка подходящую.
Из списка «Добавить в план» можно выбрать рекламную кампанию, в которую требуется перенести подобранные слова.
Если у вас еще нет рекламной кампании в Google AdWords, вы можете на основе собранных в планировщике ключевых слов создать ее. Просто нажмите на соответствующую кнопку в верхней части экрана вкладки «Группа объявлений», чтобы перейти к настройкам таргетинга и вариантам составления объявления.
Анализ результата
После того как рекламная кампания будет запущена, важно периодически оценивать эффективность ее работы. Для этого можно использовать отчет конверсий или сервис Google Analytics, который уже встроен в рекламный аккаунт.
Из отчетов вы увидите, какие ключевые запросы приносят наибольшее количество трафика, сколько стоит одно обращение по ним. При детальном и глубоком анализе полученных результатов можно найти неэффективные или дорогостоящие ключевые фразы, минус-слова, которые необходимо удалить из рекламной кампании.
Чтобы проверить, показывается ли ваше объявление по конкретному запросу, перейдите на страницу «Предварительный просмотр и диагностика объявлений».
Введите в открывшемся поле конкретный поисковой запрос, чтобы увидеть выдачу рекламы по нему в интересующем регионе.
Здесь же можно настраивать варианты региона показов, типы используемых устройств.
Секреты работы с планировщиком Google AdWords
Этот инструмент имеет некоторые изъяны, например, скрытие некоторых низкочастотных запросов или округление по кластерам (или «корзинам») охвата. Однако, планировщик Google AdWords все же остается лучшим бесплатным сервисом для сбора семантического ядра, по признанию профессиональных маркетологов. С его помощью можно выбрать тему для блога компании, оптимизировать SEO-данные сайта или интернет-магазина, настроить эффективную рекламную кампанию.
Однако, функционала одного планировщика не всегда хватает. Чтобы работа с ним не была проведена даром, а эффективность интернет-маркетинга повышалась, возьмите на вооружение и другие бесплатные инструменты.
-
Google Trends. Поможет в анализе изменения популярности запросов.
-
Google Analytics. Расскажет обо всех особенностях поведения посетителей вашего сайта.
-
Google Search Console. Найдет ошибки в сайте и причины высокого уровня отказов, низкой конверсии.
Изучайте список релевантных ключевых фраз, ставки по ним, настраивайте рекламные кампании под особенности вашей целевой аудитории, анализируйте результаты и проводите сплит-тестирование для получения наилучших результатов.
Программы и сервисы поиска запросов для Google
Чтобы повысить эффективность интернет-маркетинга и рекламы в сети, можно взять за основу семантического ядра те ключевые фразы и слова, которые выводят на первые места ваших конкурентов в сети. Для этого есть несколько основных сервисов.
-
Semrush.
-
SpyWords.
-
Prodvigator.
Не все из этих сервисов имеют русскоязычный интерфейс и бесплатные версии. Однако возможность отслеживать работу конкурентов в сети поможет опередить их, а значит данные программы и сервисы для поиска запросов достойны внимания профессионального маркетолога.
Конверсия по запросу
Одним из наиболее важных показателей эффективности рекламы является соотношения посетителей к числу совершивших целевое действие. Отследить конверсию по каждому отдельному запросу можно несколькими способами: с помощью сторонних вспомогательных ресурсов и сервисов Google.
Google Analytics
В рекламном аккаунте ADS вы можете сразу видеть всю необходимую информацию о работе компании и поведении пользователей на сайте. Для этого достаточно выполнить интеграцию с кабинетом Google Analytics.
Откройте раздел «Связанные аккаунты» в меню «Инструменты»
В появившемся списке выберите Google Analytics для дальнейшей интеграции.
В рекламном кабинете AdWords в разделе «Ключевые слова» можно посмотреть конверсии по каждому из запросов. Для этого нужно прокрутить общую отчетную таблицу до конца вправо.
Коллтрекинг MANGO
Чтобы понять, какое из объявлений и по каким запросам приносит наибольшую эффективность, воспользуйтесь специальным продуктом от Mango Office. Вы можете внедрять неограниченное количество подменных номеров, по которым будет собрана статистика обращений. Используйте коллтрекинг для анализа результатов разных параметров рекламной кампании.
В отчете «Сквозная аналитика» можно получить следующие важные сведения.
-
Количество рекламных показов.
-
Уровень затрат по отдельным кампаниям и каналам.
-
Число совершенных пользователями звонков.
-
Количество обращений и средняя стоимость одного.
-
Число полученных с сайта заявок.
-
Стоимость привлечения клиента.
-
Число успешно открытых сделок.
-
ROMI.
Чтобы получить информативную, понятную и детальную аналитику достаточно выбрать подходящий тарифный план, оплатить счет и настроить код виджета коллтрекинга на своем сайте. Если у вас при этом возникнут вопросы по настройке и интеграции, вы всегда можете обратиться за бесплатной профессиональной помощью к специалистам службы поддержки, которая работает 24/7.
Спросите Siri, Диктовка и конфиденциальность
Когда Вы обращаетесь с просьбой к голосовому помощнику, Siri отправляет в Apple определенные данные о Вас, чтобы точнее реагировать на Ваши запросы.
При использовании Siri и Диктовки произнесенные и надиктованные Вами слова отправляются в Apple для обработки Ваших запросов. В дополнение к этим аудиозаписям Ваше устройство отправляет другие Данные Siri, среди которых могут быть данные перечисленных ниже типов.
• Имена, псевдонимы и данные о родственных и иных связях с Вашими контактами (например, «мой папа»), если эти данные указаны в карточках контактов.
• Музыка и подкасты, которые Вы слушаете.
• Имена Ваших устройств и устройств пользователей, входящих в Вашу группу Семейного доступа.
• Имена аксессуаров, домов, сценариев и пользователей, которые вместе с Вами используют дом в приложении «Дом».
• Метки объектов, такие как имена людей в приложении «Фото», названия будильников и списков Напоминаний.
• Названия приложений, установленных на Вашем устройстве, а также быстрые команды, добавленные с помощью Siri.
Ваши запросы к голосовому помощнику связаны со случайным идентификатором. Они не связаны с Вашим Apple ID.
Данные Siri также включают генерируемые компьютером расшифровки Ваших запросов к Siri и помогают Siri и Диктовке лучше понимать и распознавать Ваши слова на Вашем устройстве iOS и на любых Apple Watch и HomePod, которые настроены для использования с Вашим устройством iOS.
Данные Siri связаны со случайным идентификатором, который создается на устройстве. Этот случайный идентификатор не связан с Вашим Apple ID, адресом электронной почты или другими данными, которые могла получить компания Apple, когда Вы использовали службы Apple.
Данные Siri и запросы к голосовому помощнику не используются для создания Вашего маркетингового профиля и никогда никому не продаются.
Если службы геолокации включены, компания Apple также будет получать информацию о местонахождении Вашего устройства в момент запроса, это позволит Siri и Диктовке успешнее обрабатывать Ваши запросы. Для предоставления более точных ответов Apple может использовать IP-адрес Вашего интернет-подключения, чтобы определять приблизительную геопозицию Вашего устройства, соотнося ее с географическим регионом.
Siri сохраняет минимальное количество данных на серверах Siri
По умолчанию Apple сохраняет конспекты Ваших диалогов с Siri, а также сообщений и текстов, которые Вы надиктовываете, используя функцию «Диктовка». Apple может анализировать некоторые из этих конспектов. Вы можете разрешить хранить и анализировать аудиозаписи, которые были получены, когда Вы использовали Siri и Диктовку. Хранение и анализ осуществляются сотрудниками Apple для дальнейшей разработки и совершенствования Siri и Диктовки. Чтобы разрешить хранение и анализ аудиозаписей фрагментов речи, перейдите в «Настройки» > «Конфиденциальность» > «Аналитика и улучшения» и включите параметр «Улучшить Siri и Диктовку».
История Ваших запросов к голосовому помощнику остается связанной со случайным идентификатором в течение не более чем шести месяцев. История запросов может включать расшифровки записей и аудиозаписи, если пользователь решил помочь улучшить Siri и Диктовку. История также может содержать данные Siri и связанные данные, включая характеристики и конфигурацию устройства, статистику производительности и приблизительное местонахождение устройства в момент запроса. По истечении шести месяцев история Ваших запросов перестает быть связанной со случайным идентификатором. После этого она может храниться на протяжении двух лет. В течение этого периода Apple может продолжать использовать историю запросов для разработки и совершенствования Siri, Диктовки и других функций распознавания и обработки речи, например Управления голосом. Небольшое количество запросов может быть проанализировано. Такие запросы могут храниться дольше двух лет для дальнейшего улучшения функциональных возможностей Siri. При более длительном хранении запросы также не связаны со случайным идентификатором.
Если локальная обработка запросов диктовки включена, основной текст Диктовки будет обрабатываться на iPhone, iPad или Apple Watch (для Диктовки в Поиске требуется серверная обработка). Используя информацию, которая хранится на Вашем устройстве, локальная обработка запросов диктовки может персонализировать Диктовку. Локальную обработку запросов диктовки можно включить на определенных устройствах, загрузив поддерживаемую языковую модель в настройках клавиатур. Некоторые метрики локальной обработки запросов диктовки будут передаваться в Apple вместе с историей запросов. По умолчанию расшифровки фрагментов речи и аудиозаписи для локальной обработки запросов диктовки не передаются на серверы Siri. Вы можете делиться этими данными с Apple, чтобы помочь улучшить Siri и Диктовку. Для этого откройте «Настройки» > «Конфиденциальность» > «Аналитика и улучшения» и включите параметр «Улучшить Siri и Диктовку».
Если Вы разрешите использовать Siri в сторонних приложениях, некоторые данные из стороннего приложения могут быть отправлены в Apple, чтобы помочь Siri обработать Ваши запросы, а отдельные части запроса будут предоставлены приложению, чтобы оно могло вернуть ответ или выполнить необходимые действия (например отправить сообщение или заказать поездку). Когда Siri взаимодействует со сторонним приложением от Вашего имени, применяются положения и условия, а также политика конфиденциальности стороннего приложения. Если Вы разрешите приложениям использовать Siri для конспектирования, голосовые данные, которые Вы хотите законспектировать, могут отправляться в Apple.
Если Вы используете iCloud, настройки Siri будут синхронизироваться на всех Ваших устройствах Apple с использованием сквозного шифрования. Если у Вас настроена функция «Привет, Siri», небольшая подборка Ваших запросов также будет синхронизироваться с применением сквозного шифрования, чтобы обеспечить персонализированное распознавание речи на каждом устройстве, когда Вы используете «Привет, Siri». Персонализированные модели распознавания речи могут использовать информацию на устройстве для совершенствования механизмов работы. Чтобы другие пользователи могли управлять находящимися поблизости таймерами и будильниками, а также работать с общими медиафайлами, сведения об их состоянии на Вашем устройстве и расстоянии до других устройств могут быть переданы на Ваш HomePod или Apple TV.
Выбор и контроль — в Ваших руках
Функцию «Спросите Siri» и Диктовку можно выключить в любой момент. Чтобы выключить функцию «Спросите Siri», откройте «Настройки» > «Siri и Поиск», а затем касанием выключите параметры «Слушать «Привет, Siri»» и «Вызов Siri кнопкой «Домой»» или «Вызов Siri боковой кнопкой». Чтобы выключить Диктовку, откройте «Настройки» > «Основные» > «Клавиатура», а затем выключите параметр «Включение диктовки». Если выключить функцию «Спросите Siri» и Диктовку, Apple удалит Данные Siri, которые связаны со случайным идентификатором.
Можно удалить аудиозаписи фрагментов речи, полученные в ходе взаимодействия с голосовыми функциями, которые связаны со случайным идентификатором и хранятся в течение шести месяцев. Для этого перейдите в «Настройки» > «Siri и Поиск» > «История Siri и Диктовки» и коснитесь «Удалить историю Siri и Диктовки».
Можно указать, какие приложения могут взаимодействовать с Siri. Для этого откройте «Настройки» > «Siri и Поиск» > [выберите приложение] > «Использовать с Siri».
Службы геолокации для Siri можно выключить. Для этого откройте «Настройки» > «Конфиденциальность» > «Службы геолокации» и выберите вариант «Никогда» для параметра «Siri и Диктовка».
Если Вы не хотите, чтобы персонализация Siri синхронизировалась между Вашими устройствами, можно выключить Siri. Для этого откройте «Настройки» > [Ваше имя] > «iCloud» и касанием выключите параметр Siri.
Вы также можете ограничить использование Siri и Диктовки. Для этого откройте «Настройки» > «Экранное время» > «Контент и конфиденциальность» > «Разрешенные приложения» и коснитесь параметра «Siri и Диктовка».
Можно указать, какие приложения могут использовать Siri для конспектирования. Для этого откройте «Настройки» > «Конфиденциальность» > «Распознавание речи».
Используя Siri или Диктовку, Вы даете компании Apple, ее дочерним организациям и агентам согласие на передачу, сбор, хранение, обработку и использование всей указанной информации для обеспечения работы и улучшения Siri и функциональных возможностей диктовки в продуктах и службах Apple. Информация, которую собирает Apple, всегда обрабатывается в соответствии с Политикой конфиденциальности Apple, доступной по адресу www.apple.com/privacy.
Алгоритм— как подсчитать количество запросов за последнюю секунду, минуту и час
Если требуется 100% точность:
Имейте связанный список всех запросов и 3 подсчета — за последний час, последнюю минуту и последнюю секунду.
У вас будет 2 указателя в связанном списке — минуту назад и секунду назад.
Час назад будет в конце списка. Если время последнего запроса больше, чем на час до текущего времени, удалите его из списка и уменьшите счетчик часов.
Указатели минут и секунд будут указывать на первый запрос, который произошел через минуту и секунду назад соответственно. Если время запроса превышает текущее время более чем на минуту / секунду, сдвиньте указатель вверх и уменьшите счетчик минут / секунд.
При поступлении нового запроса добавьте его ко всем 3 счетчикам и добавьте в начало связанного списка.
Запросы подсчетов просто включают возвращение подсчетов.
Все вышеперечисленные операции амортизируются в постоянное время.
Если допустима точность менее 100%:
Сложность пространства для вышеупомянутого может быть немного большим, в зависимости от того, сколько запросов в секунду вы обычно получаете; вы можете уменьшить это, немного пожертвовав точностью:
Создайте связанный список, как указано выше, но только на последнюю секунду. Также имейте 3 счета.
Затем создайте круговой массив из 60 элементов, указывающих счетчики каждой из последних 60 секунд. Каждый раз, когда проходит секунда, вычтите последний (самый старый) элемент массива из счетчика минут и добавьте последний счетчик секунд к массиву.
Сделайте похожий круговой массив на последние 60 минут.
Потеря точности: Отсчет минут может быть отключен для всех запросов в секунду, а счетчик часов может быть отключен для всех запросов за минуту.
Очевидно, это не имеет смысла, если у вас только один запрос в секунду или меньше. В этом случае вы можете сохранить последнюю минуту в связанном списке и просто иметь круговой массив за последние 60 минут.
Есть и другие варианты — соотношение точности и используемого пространства может быть отрегулировано по мере необходимости.
Таймер для удаления старых элементов:
Если вы удаляете старые элементы только при поступлении новых, амортизируется постоянное время (некоторые операции могут занять больше времени, но среднее время будет постоянным).
Если вам нужно истинное постоянное время, вы можете дополнительно запустить таймер, который удаляет старые элементы, и каждый его вызов (и, конечно, вставки и проверка счетчиков) будет занимать только постоянное время, поскольку вы удаляете не более одного числа. элементов, вставленных за постоянное время с момента последнего тика таймера.
javascript — есть ли максимальное количество запросов Get?
Принимающий сервер имеет определенную возможность для того, сколько одновременных запросов он может обработать. Это может быть небольшое количество или очень большое количество, в зависимости от целого ряда вещей, включая конфигурацию сервера, архитектуру серверного программного обеспечения, типы отправляемых запросов и т. Д.
Если вы получаете таймауты от сервера, то вы, вероятно, отправляете достаточно запросов, чтобы сервер не мог обработать их все до того, как будет настроен тайм-аут запроса (на клиенте или сервере), и, таким образом, вы получите ошибку тайм-аута.
Обычный способ обработки этого на клиенте — контролировать, сколько одновременных запросов вы отправляете одновременно, а затем, когда один из них завершится, вы можете отправить следующий и так далее. Вам нужно будет протестировать, чтобы узнать, каковы возможности принимающего сервера, а затем вы должны немного отступить от этого, чтобы позволить другой нагрузке из других источников некоторое пространство для выполнения во время выполнения ваших запросов.
Предполагая, что ваши запросы не являются необычно тяжелыми вещами, которые нужно выполнять на сервере, я обычно тестирую 5 или 10 запросов за раз и смотрю, как принимающий сервер обрабатывает это.
Здесь обсуждается множество вариантов управления этим:
Promise.all потребляет всю мою оперативную память
Сделайте несколько запросов к API, который может обрабатывать только 20 запросов в минуту
Управление параллелизмом также является частью Promise.map () в библиотеке обещаний Bluebird.
СерверыЕсть ли максимальное количество запросов Get?
ограничены в количестве запросов, которые они могут обрабатывать одновременно, по целому ряду причин.Настройка каждого сервера, вероятно, будет отличаться, и это также зависит от типов запросов, которые вы отправляете (и того, что они должны делать). Некоторые серверы могут обрабатывать сотни тысяч запросов (вероятно, потому, что за ними стоит кластер, и они настроены на большую нагрузку). Меньшие конфигурации могут обрабатывать только десятки одновременно.
Это связано с ограничением количества подключений?
У любого принимающего сервера будет ограничение на количество входящих соединений, которые он разрешит ставить в очередь.То, что это такое, будет зависеть от многих факторов, и вы не можете (извне) точно знать, каков этот предел. Ошибки тайм-аута обычно не означают, что вы достигли этого предела.
Как рассчитать максимальное количество запросов к серверу в секунду | Ризал Видьярта Гованди
Компьютер может производить вычисления. Этот расчет требует, чтобы ЦП работал. Обработка изображения и преобразование строки в байт — это примеры процесса, требующего вычисления. Следовательно, ограничивающим фактором является количество мощности процессора, имеющееся на машине. Здесь ограничение — это мощность процессора и количество ядер. В основном, чем больше ядер, тем больше рабочих. Больше рабочих означает, что можно выполнить больше задач, и чем выше RPS.
В системе с привязкой к ЦП мы можем рассчитать количество запросов в секунду по следующей формуле:
запросов в секунду для системы с привязкой к ЦПНапример, сервер с общим количеством ядер 4 и длительностью задачи 10 мс может обрабатывать 400 запросов в секунду, в то время как тот же сервер при длительности задачи 100 мс может обрабатывать только 40 запросов в секунду.
Для работы компьютеру требуется информация или данные.Он извлекает данные из базы данных, читает файл или получает данные из сети, вызывая другой компьютер. ЦП большую часть времени ничего не делает, ожидая данных. Поскольку на компьютере может быть несколько воркеров, другие воркеры по-прежнему могут выполнять задачу, пока воркер ожидает завершения предыдущего процесса.
Из предыдущей части мы знаем, что компьютер ограничен числом рабочих, но компьютер должен хранить данные в памяти, прежде чем выполнять какие-либо операции с самими данными. Предел здесь — ОЗУ . В основном, чем больше памяти, тем больше рабочих. Больше рабочих означает, что можно выполнить больше задач, и чем выше RPS.
В системе с привязкой к памяти мы можем рассчитать количество запросов в секунду по следующей формуле:
запросов в секунду для системы с привязкой к памятиНапример, сервер с общим объемом ОЗУ 16 ГБ, использованием памяти задачами 40 МБ и длительностью задачи 100 мс может обрабатывать 4000 запросов в секунду, в то время как тот же сервер с длительностью задачи 50 мс (половина предыдущего) может обрабатывать 8000 запросов в секунду.
Чтобы иметь больше запросов в секунду, серверу необходимо иметь больше оперативной памяти, меньшее использование памяти для задач и более высокую продолжительность выполнения задач.
Компьютер может разговаривать с другим компьютером. Чтобы поговорить с другим, компьютер должен создать запрос, а принимающий компьютер должен принять запрос. На компьютере под управлением UNIX при создании и принятии запроса создается файловый дескриптор. Компьютер имеет ограниченное количество файловых дескрипторов. Предел здесь — лимит открытых файлов .Лимит открытых файлов имеет мягкие и жесткие ограничения.
Мягкие ограничения — это те, которые фактически влияют на процессы; жестких ограничений — максимальных значений для мягких ограничений . Любой пользователь или процесс может поднять мягкие ограничения до значения жестких ограничений .
Эти ограничения сильно зависят от операционной системы. По умолчанию ограничения равны 1024 для мягких ограничений и 4096 для жестких ограничений. Предел открытых файлов — это обычное ограничение, при котором RPS не может возникнуть, даже если на сервере все еще есть ЦП и место для использования памяти.Более высокий лимит открытых файлов означает, что может быть получено и сделано больше запросов, что приведет к более высокому RPS.
Другой вид ограничения ввода-вывода — это пропускная способность сети. Помните, что когда компьютер разговаривает с другим компьютером, он в основном отправляет данные с одного компьютера на другой. Когда сервер интенсивно обрабатывает данные, принимает или отправляет данные размером в Гб, но имеет пропускную способность сети только в мегабайтах, он нормализуется только при очень низком RPS.
Количество запросов учитывает …
Привет всем,
Я думаю, мы смешиваем здесь несколько вариантов использования.Позвольте мне попытаться разобраться в этом:
Пример использования 1 : Подсчитайте общее количество веб-запросов
… чтобы ответить на такие вопросы, как: « Сколько веб-запросов у нас в день? »
Создать новый настраиваемую диаграмму в AppMon, щелкните правой кнопкой мыши и выберите «Добавить серию …», выберите « Количество запросов » переключите разбиение на « Без разделения (только отрисовка всего) », нажмите « Добавить »
исходное сообщение от @Stefan M. со сценарием 1-3 прекрасно объясняет, как рассчитываются значения.
Независимо от количества отслеживаемых уровней (многофункциональный клиент, браузер, веб-сервер, серверы приложений и т. Д.) Один веб-запрос всегда будет считаться одним веб-запросом.
Пример использования 2 : Подсчитайте количество веб-запросов на уровне
… чтобы ответить на такие вопросы, как: « Распределена ли нагрузка равномерно по моим экземплярам tomcat? »
Создайте новую настраиваемую диаграмму в AppMon, щелкните правой кнопкой мыши и выберите « Добавить серию … », снова выберите « Количество запросов », но теперь переключите разделение на « Агент », нажмите « Добавить ».
Теперь вы увидите количество веб-запросов на агента / уровень. Как эти значения вычисляются, лучше всего иллюстрирует пример, предоставленный @Dan S ..
Теперь сбивает с толку, когда вы добавляете обе метрики в одну диаграмму и сравниваете общее количество веб-запросов (из варианта использования 1) с количество веб-запросов на агента / уровень (из варианта использования 2).
Пример :
У вас есть один веб-запрос, который обрабатывается веб-сервером Apache и пересылается одному экземпляру Tomcat.
Всего у нас есть один веб-запрос (вариант использования 1), но в то же время у нас есть один веб-запрос для агента / уровня веб-сервера Apache и один веб-запрос для агента / уровня Tomcat.
Итак, хотя сумма по обоим уровням будет равна двум, общее значение равно единице. Это может выглядеть как ошибка, но вы также сравниваете значения для двух разных вариантов использования.
Вариант использования 3 : Подсчитайте количество веб-запросов по логическому уровню
Я думаю, что сообщение @Fran Garcia H .. посвящено этому варианту использования.
«Агент» представляет такой процесс, как веб-сервер Apache или сервер приложений Tomcat. Пока ваши уровни (например, внешний интерфейс, серверная часть) представлены процессами, вы можете выбрать разделение по «агенту». Но что, если ваши уровни не привязаны к конкретным процессам? Что, если ваш внешний и внутренний уровни являются логическими и все они работают в экземплярах Tomcat? Как бы вы посчитали количество запросов на уровне внешнего или внутреннего интерфейса?
В этом случае у вас есть две возможности: приложения или бизнес-операции.Правильный выбор зависит от того, хотите ли вы подсчитывать одну транзакцию один или несколько раз:
PurePath может быть назначен только одному приложению. Можно настроить способ идентификации приложения, но это всегда первое обнаруженное приложение, которое назначается PurePath. Поэтому, если у вас есть несколько типов интерфейсного уровня (например, один для B2B и один для потребителей), вы можете использовать приложения для разделения количества запросов.
Но если вы хотите подсчитывать запросы не только для первого уровня транзакции, но и для каждого уровня, транзакция проходит, бизнес-транзакции — ваш выбор.Хотя PurePath может иметь только одно приложение, он может иметь несколько значений для одной и той же бизнес-транзакции. Обнаружение приложений использует идентификаторы веб-приложений, имена хостов или шаблоны (например, для URL-адресов). Все это также можно использовать как результат разделения для бизнес-транзакции.
С уважением
Roland
лимитов и квот на запросы API | Analytics Core Reporting API
В этом документе описываются ограничения и квоты запросов к Руководству. API-интерфейсы и API-интерфейсы отчетов.
Google Analytics используют миллионы сайтов. Ставим лимиты и квоты по запросам API, чтобы защитить систему от получения большего количества данных, чем он может обрабатывать и обеспечивать справедливое распределение системных ресурсов. Лимиты и квоты могут быть изменены.
В этом видео обсуждаются передовые методы управления Google Analytics API. запросить квоты.
Общие лимиты квот
Следующие квоты применяются к API управления, Core Reporting API v3, MCF Reporting API, API метаданных, API удаления пользователей и API отчетов в реальном времени:
- 50 000 запросов на проект в день, которые могут быть увеличены.
- 10 запросов в секунду (QPS) на IP-адрес .
- В консоли API есть аналогичный квота, именуемая запросов на 100 секунд на пользователя . По умолчанию он установлен на 100 запросов в 100 секунд на пользователя и может можно отрегулировать до максимального значения 1000. Но количество запросов к API ограничено максимум 10 запросами в секунду на пользователя.
- Если ваше приложение выполняет все запросы API с одного IP-адреса
(т.е. от имени ваших пользователей) используйте параметр
userIPилиquotaUserс каждым запросом, чтобы получить полную квоту QPS для каждого пользователя.Увидеть Сводка стандартных параметров запроса для подробностей.
API отчетов
Следующие квоты применяются ко всем API отчетов, включая Core Reporting API v3, Analytics Reporting API версии 4, API реального времени v3 и API многоканальных последовательностей версии 3:
- 10000 запросов на представление (профиль) в день (не может быть увеличено)
- 10 одновременных запросов на представление (профиль) (не может быть увеличено)
Ошибки запросов API отчетов
Если ваш запрос к Reporting API завершился неудачно из-за ошибки сервера, вы получите
код ответа 500 или 503 . Вы можете повторно отправить запрос; однако не
повторно отправить этот запрос несколько раз, если он неоднократно терпит неудачу. Гугл Аналитика
позволяет:
- 10 ошибок сервера неудачных запросов на проект на представление (профиль) в час
- 50 ошибок сервера ошибок сервера запросов на проект на представление (профиль) в день
Если количество неудачных запросов превышает эти квоты, вы получите следующая ошибка:
Ошибка квоты: количество недавних запросов API отчетов, завершившихся ошибкой сервера, слишком велико.Вы временно заблокированы для доступа к API отчетов как минимум на час. Пожалуйста, отправляйте меньше ошибок сервера в будущем, чтобы избежать блокировки.
Чтобы снизить вероятность ошибок сервера запросов, упростите запрос: уменьшение диапазона дат, уменьшение количества параметров в запросе или уменьшение количества метрик в запросе.
Не повторно отправлять неудавшийся запрос. Вместо, реализовать экспоненциальную отсрочку отправить его повторно.
Превышение квоты
Если квота на запрос Google Analytics API превышена, API
возвращает код ошибки 403 или 429 и сообщение о том, что учетная запись превысила
квота.См. Условия обслуживания для получения дополнительной информации.
Запрос дополнительной квоты
Можно запросить только на увеличение:
Примечание: Невозможно увеличить 10 000 запросов на представление (профиль) в день или 10 одновременных запросов на представление (профиль) .Чтобы просмотреть или изменить лимиты использования для вашего проекта, или запросить увеличение до свою квоту, сделайте следующее:
- Если у вас еще нет платежного аккаунта для вашего проекта, а затем создайте его.
- Посетите страницу «Включенные API» на Библиотеку API в консоли API и выберите API из список.
- Чтобы просмотреть и изменить параметры, связанные с квотами, выберите Квоты . Смотреть статистика использования, выберите Использование .
Чтобы запросить увеличение максимальной суммы квоты, используйте форму запроса квоты Analytics API. Обязательно ознакомьтесь с информацией и следуйте инструкциям в квоте. форма запроса перед отправкой запроса.Для Reporting API v4: имя API в консоли Google API — Google Analytics Reporting API . Все остальные API v3 (например, Management API v3, Core Reporting API v3, API отчетов в реальном времени v3, User Deletion API v3) перечислены в Analytics API в консоли Google API.
Для получения дополнительной информации об управлении квотами и настройке приложения. информацию об использовании квот см. в разделе «Мониторинг API и ограничение использования».
Пределы запросов и регулирование — Azure Resource Manager
- 6 минут на чтение
В этой статье
В этой статье описывается, как Azure Resource Manager регулирует запросы.Он показывает вам, как отслеживать количество запросов, которые остаются до достижения лимита, и как реагировать, когда вы достигли лимита.
Регулирование происходит на двух уровнях. Azure Resource Manager регулирует запросы для подписки и клиента. Если запрос находится в пределах дросселирования для подписки и клиента, Resource Manager направляет запрос поставщику ресурсов. Поставщик ресурсов применяет ограничения регулирования, адаптированные к его операциям. На следующем изображении показано, как применяется регулирование при передаче запроса от пользователя к Azure Resource Manager и поставщику ресурсов.
Ограничения по подписке и арендаторам
На каждую операцию на уровне подписки и клиента действуют ограничения регулирования. Запросы подписки — это запросы, которые включают передачу идентификатора вашей подписки, например получение групп ресурсов в вашей подписке. Запросы клиентов не включают идентификатор вашей подписки, например получение допустимых местоположений Azure.
Пределы регулирования по умолчанию в час показаны в следующей таблице.
| Объем | Операции | Предел |
|---|---|---|
| Подписка | читает | 12000 |
| Подписка | удаляет | 15000 |
| Подписка | пишет | 1200 |
| Арендатор | читает | 12000 |
| Арендатор | пишет | 1200 |
Эти ограничения относятся к участнику безопасности (пользователю или приложению), выполняющему запросы, и идентификатору подписки или идентификатору клиента.Если ваши запросы поступают от более чем одного участника безопасности, ваш лимит для подписки или клиента превышает 12000 и 1200 в час.
Эти ограничения применяются к каждому экземпляру Azure Resource Manager. В каждом регионе Azure есть несколько экземпляров, и Azure Resource Manager развернут во всех регионах Azure. Итак, на практике лимиты выше этих лимитов. Запросы от пользователя обычно обрабатываются разными экземплярами Azure Resource Manager.
Ограничения поставщика ресурсов
Поставщики ресурсов применяют собственные ограничения регулирования.Поскольку диспетчер ресурсов регулирует по идентификатору участника и экземпляру диспетчера ресурсов, поставщик ресурсов может получать больше запросов, чем ограничения по умолчанию, указанные в предыдущем разделе.
В этом разделе обсуждаются ограничения регулирования некоторых широко используемых поставщиков ресурсов.
Дросселирование хранилища
Следующие ограничения применяются только при выполнении операций управления с помощью Azure Resource Manager с хранилищем Azure.
| Ресурс | Предел |
|---|---|
| Операции по управлению учетными записями хранения (чтение) | 800 за 5 минут |
| Операции управления учетной записью хранения (запись) | 10 в секунду / 1200 в час |
| Операции управления учетной записью хранения (список) | 100 за 5 минут |
Дросселирование сети
Microsoft.Поставщик сетевых ресурсов применяет следующие ограничения дроссельной заслонки:
| Эксплуатация | Предел |
|---|---|
| запись / удаление (PUT) | 1000 за 5 минут |
| прочитать (GET) | 10000 за 5 минут |
Примечание
Частный DNS-сервер Azure имеет ограничение в 500 операций чтения (GET) за 5 минут.
Регулирование вычислений
Сведения об ограничениях регулирования для вычислительных операций см. В разделе Устранение ошибок регулирования API — вычисления.
Для проверки экземпляров виртуальных машин в масштабируемом наборе виртуальных машин используйте операции масштабируемых наборов виртуальных машин. Например, используйте масштабируемый набор виртуальных машин — список виртуальных машин с параметрами для проверки состояния питания экземпляров виртуальных машин. Этот API уменьшает количество запросов.
Регулирование графика ресурсов Azure
Azure Resource Graph ограничивает количество запросов к своим операциям. Действия, описанные в этой статье, по определению оставшихся запросов и способам реагирования при достижении лимита, также применимы к графику ресурсов.Однако график ресурсов устанавливает собственный предел и частоту сброса. В разделе Заголовки регулирования графика ресурсов.
Другие поставщики ресурсов
Для получения информации о регулировании в других поставщиках ресурсов см .:
Код ошибки
При достижении лимита вы получаете код состояния HTTP 429 Слишком много запросов . Ответ включает значение Retry-After , которое указывает количество секунд, в течение которых ваше приложение должно ждать (или спать) перед отправкой следующего запроса.Если вы отправляете запрос до истечения значения повторной попытки, ваш запрос не обрабатывается и возвращается новое значение повторной попытки.
После ожидания в течение указанного времени вы также можете закрыть и снова открыть подключение к Azure. Сбросив соединение, вы можете подключиться к другому экземпляру Azure Resource Manager.
Если вы используете пакет SDK для Azure, в пакете SDK может быть настроена автоматическая повторная попытка. Дополнительные сведения см. В разделе «Рекомендации по повторным попыткам для служб Azure».
Некоторые поставщики ресурсов возвращают 429, чтобы сообщить о временной проблеме.Проблема может заключаться в перегрузке, которая не связана напрямую с вашим запросом. Или это может означать временную ошибку о состоянии целевого или зависимого ресурса. Например, поставщик сетевых ресурсов возвращает 429 с кодом ошибки RetryableErrorDueToAnotherOperation , когда целевой ресурс заблокирован другой операцией. Чтобы определить, связана ли ошибка с регулированием или временным состоянием, просмотрите сведения об ошибке в ответе.
Оставшиеся запросы
Вы можете определить количество оставшихся запросов, изучив заголовки ответов.Запросы на чтение возвращают в заголовке значение количества оставшихся запросов на чтение. Запросы на запись включают значение количества оставшихся запросов на запись. В следующей таблице описаны заголовки ответов, которые вы можете проверить на предмет этих значений:
| Заголовок ответа | Описание |
|---|---|
| x-ms-ratelimit-осталось-подписка-чтения | Осталось прочтений в пределах подписки. Это значение возвращается при операциях чтения. |
| x-ms-ratelimit-Остающийся-подписка-пишет | Осталось записей в рамках подписки. Это значение возвращается при операциях записи. |
| x-ms-ratelimit-остались-чтения-арендатора | Область действия арендатора — оставшиеся |
| x-ms-ratelimit-Остающийся-арендатор-пишет | Осталось записей в пределах арендатора |
| x-ms-ratelimit-left-subscription-resource-requests | Осталось запросов на тип ресурса с областью действия подписки. Это значение заголовка возвращается только в том случае, если служба переопределила ограничение по умолчанию. Диспетчер ресурсов добавляет это значение вместо чтения или записи подписки. |
| x-ms-ratelimit-Остающийся-ресурс-сущностей-подписки-чтение | Остались запросы на сбор типа ресурса с ограниченным объемом подписки. Это значение заголовка возвращается только в том случае, если служба переопределила ограничение по умолчанию. Это значение обеспечивает количество оставшихся запросов на сбор (список ресурсов). |
| x-ms-ratelimit-left-tenant-resource-requests | Осталось запросов типа ресурса в области арендатора. Этот заголовок добавляется только для запросов на уровне клиента и только в том случае, если служба переопределила ограничение по умолчанию. Диспетчер ресурсов добавляет это значение вместо чтения или записи клиентом. |
| x-ms-ratelimit-оставшийся-тенант-ресурс-сущностей-чтение | Остались запросы на сбор типа ресурса в области арендатора. Этот заголовок добавляется только для запросов на уровне клиента и только в том случае, если служба переопределила ограничение по умолчанию. |
Поставщик ресурсов также может возвращать заголовки ответов с информацией об оставшихся запросах. Сведения о заголовках ответов, возвращаемых поставщиком вычислительных ресурсов, см. В разделе Заголовки информационных ответов о скорости вызова.
Получение значений заголовка
Получение этих значений заголовков в вашем коде или скрипте ничем не отличается от получения любого значения заголовка.
Например, в C # вы получаете значение заголовка из объекта HttpWebResponse с именем response со следующим кодом:
ответ.Headers.GetValues ("x-ms-ratelimit-остались-чтения-подписки"). GetValue (0)
В PowerShell вы получаете значение заголовка из операции Invoke-WebRequest.
$ r = Invoke-WebRequest -Uri https://management.azure.com/subscriptions/{guid}/resourcegroups?api-version=2016-09-01 -Method GET -Headers $ authHeaders
$ r.Headers ["x-ms-ratelimit-остались-чтения-подписки"]
Полный пример PowerShell см. В разделе Проверка ограничений диспетчера ресурсов для подписки.
Если вы хотите увидеть оставшиеся запросы на отладку, вы можете указать параметр -Debug в своем командлете PowerShell .
Get-AzResourceGroup -Debug
, который возвращает множество значений, включая следующее значение ответа:
ОТЛАДКА: ============================ ОТВЕТ HTTP ================ ============
Код состояния:
ОК
Заголовки:
Прагма: без кеширования
x-ms-ratelimit-остальные-подписки-чтения: 11999
Чтобы получить ограничения на запись, используйте операцию записи:
New-AzResourceGroup -Name myresourcegroup -Location westus -Debug
, который возвращает множество значений, включая следующие значения:
ОТЛАДКА: ============================ ОТВЕТ HTTP ================ ============
Код состояния:
Созданный
Заголовки:
Прагма: без кеширования
x-ms-ratelimit-оставшаяся подписка-пишет: 1199
В Azure CLI значение заголовка можно получить с помощью параметра более подробной информации.
az список групп --verbose --debug
, который возвращает множество значений, включая следующие значения:
msrest.http_logger: Статус ответа: 200
msrest.http_logger: Заголовки ответа:
msrest.http_logger: 'Cache-Control': 'no-cache'
msrest.http_logger: 'Pragma': 'без кеша'
msrest.http_logger: 'Content-Type': 'application / json; charset = utf-8 '
msrest.http_logger: 'Content-Encoding': 'gzip'
msrest.http_logger: 'Истекает': '-1'
msrest.http_logger: 'Vary': 'Accept-Encoding'
msrest.http_logger: 'x-ms-ratelimit-остались-подписки-чтения': '11998'
Чтобы получить ограничения на запись, используйте операцию записи:
az group create -n myresourcegroup --location westus --verbose --debug
, который возвращает множество значений, включая следующие значения:
msrest.http_logger: Статус ответа: 201
msrest.http_logger: Заголовки ответа:
msrest.http_logger: 'Cache-Control': 'no-cache'
msrest.http_logger: 'Pragma': 'без кеширования'
msrest.http_logger: 'Длина содержимого': '163'
msrest.http_logger: 'Content-Type': 'application / json; charset = utf-8 '
msrest.http_logger: 'Истекает': '-1'
msrest.http_logger: 'x-ms-ratelimit-оставшаяся подписка-пишет': '1199'
Следующие шаги
` класс ReservationApp (TaskSequence): класс ReservatonLocust (HttpLocust): если имя == « main «: |