
Валидный NOINDEX проходит валидацию
- SEO Блог
- Оптимизация сайта

Валидность документа не что иное как один из показателей качества сайта на котором он расположен, поэтому ею не следует пренебрегать. Не валидный документ может некорректно отображаться в некоторых браузерах (в большей степени это касается старых типов). Кроме этого большое количество ошибок в коде на которые указывает валидатор может послужить причиной попадания под фильтр яндекса. Гоогле к этим вещам относится терпимей и его санкции не настолько жестоки и выйти из под них намного легче.
Если ваш сайт не проходит валидацию из-за частого употребления тега NOINDEX пора задуматься о его замене валидным аналогом. Тогда и овцы будут целы — весь закрытый этим тегом контент не будет индексироваться яндексом, и волки сыты — другие поисковые боты и валидатор не найдут в вашем коде ошибок.
Как сделать тег noindex валидным
Для тех кто не в теме напомню, для того чтобы определенный участок текста или кода на странице не индексировался Яндексом его закрывают в специальный им самим выдуманный тег:
Не валидный тег noindex:
<noindex>Ваш текст или код закрытый не валидным тегом</noindex>Этот прием для закрытия от индексации определенного участка страницы с текстом использовался и до сих пор используется многими веб мастерами.
А зря поскольку уже порядочное время как появился валидный аналог тега noindex, на который валидатор не ругается и который не воспринимается им как ошибка в коде, поскольку он имитирует простой комментарий html разметки страницы. О нем так-же написано в разделе помощи Яндекса, но увы некоторые веб мастера или до сих пор не знают о нем или пренебрегают даваемыми там советами
Валидный тег noindex выглядит так:
<!--noindex-->Ваш текст или код закрыт валидным тегом<!--/noindex-->Все гениальное просто и если вы до сих пор еще используете старый вариант этого тега не поленитесь заменить его на аналог который будет валиден.
Многие оспаривают целесообразность использования тега noindex на страницах сайта, а некоторые эксперименты показали, что иногда текст и ссылки закрытые этим тегом все-равно индексируются Яндексом, но используя тег noindex валидность которого очевидна вы ни чем не рискуете.
Намного больше вас рискуют (потерей чего догадайтесь сами) те, кто продолжает смотреть дом 2 онлайн бесплатно, неужели вам это интересно, меня лично хватило только на 3 первых выпуска этой программы когда это был еще дом 1 а второй я уже даже и не начинал смотреть.
Комментарии к статье
← Предыдущая статьяСледующая статья →
seodiz.ru
что это такое за тег для Яндекса
Noindex – это тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
Вторая, не менее важная функция тега noindex, состоит в том, чтобы блокировать индексацию отдельных страниц сайта, предназначенных для публикации пользовательского контента. К таким относятся страницы с отзывами, комментариями, сообщениями и др. В данном случае noindex позволяет избежать распространения нежелательной информации и использовать менее жесткий режим модерирования пользовательских сообщений.
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности. Для сохранения валидности кода тег следует использовать в следующем формате:
<!—noindex—>Здесь находится закрытый для индексации текст<!—/noindex—>.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
wiki.rookee.ru
Тег noindex Яндекс — закрытие кода от индексации в Yandex
Тег НоуИндекс и Яндекс
Иногда, при внесении каких-то технических изменений на сайте или продолжительном ведении блога, появляются материалы и куски кода, которые могут навредить поисковому продвижению сайтов. В данной статье коснусь, прежде всего, Яндекса и опишу его «специфический» HTML-тег <noindex>.
В чём вообще здесь суть? Как известно, продвигая сайт в поисковых системах, необходимо учитывать следующее:
- материал (прежде всего, текст) отдельной страницы должен быть уникальным
- и должен соответствовать какому-либо ключевому слову (запросу), под которое эта страница SEO-оптимизируется.
Но если имеются (или появляются со временем) тексты или коды, негативно влияющие на эти 2 пункта, то продвижение может ухудшиться.
Что это конкретно и как влияет?
Что это
Здесь может быть много всего:
- куски неуникального текста, взятые вами с чужого сайта и вставленные в вашу уникальную (изначально) статью,
- обилие кодов рекламы — тизеры, баннеры, контекстная реклама и другая,
- множество JavaScript-скриптов и кодов flash-приложений,
- разные блоки ссылок в сайдбаре вроде «наши друзья»,
- куча установленных счётчиков,
- и др.
Как влияет
Исходя из двух пунктов списка, указанных в начале статьи, влияет это так:
- происходит «разбавление» плотности ключевых слов страниц сайта.
Поэтому неплохо бы закрыть все лишние части материалов от индексации поисковыми роботами.
Тег Noindex Яндекса и скрытие кода от его роботов
К сожалению (а может, и нет), закрыть от индексации отдельные участки HTML-кода позволяет лишь Yandex. Возможно, со временем Google и Bing также предложат что-нибудь аналогичное. А может, их разработчики просто не считают это необходимостью.
В общем, тега noindex в Google нет! — особо указываю на это из-за того, что в Сети полно разговоров по данному поводу. Зато поисковик Гугл позволяет скрывать всю страницу от роботов через X Robots tag, а также стандартными средствами — как и остальные ПС:
Использование Noindex в Яндексе
Пользоваться им не сложнее, чем любым другим HTML-тегом. Обычно выглядит всё так:
<noindex>
Что-то из того, что не надо отдавать Яндексу
</noindex>
Возможен и альтернативный вариант — тег ноиндекс в виде стандартного HTML-комментария. Вот, к примеру, как можно скрыть контекст от AdSense:
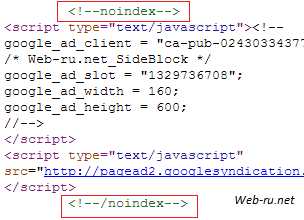
AdSense «завёрнут» в noindex tag
— т.е. всё то же самое, но добавляем указание на то, что это комментарий. На мой взгляд, такой вариант предпочтительней.
Кстати, чтобы узнать, где на веб-странице расставлены блоки тегов ноуиндекс, можно поставить:
Они будут буквально «подсвечивать» участки кода, «завёрнутые» в этот тег. Правда, RDS bar иногда не подсвечивает вариант в формате комментария —
Когда использовать?
Как и писал выше, noindex в Яндекс нужен для скрытия ненужных кусков кода, чтобы не уменьшалась уникальность текстов и релевантность статей запросам. Будет вполне логично, если возникнет мысль закрыть всё-всё, кроме текста оптимизированной статьи в тег ноиндекс — включая анкоры ссылок в верхнем меню, шапку сайта, комментарии и прочее.
На самом деле, так разгоняться не стоит. На это есть две причины:
- Подобные манипуляции (если переборщить) могут быть расценены Яндексом как поисковый спам.
- Роботы современных ПС способны различать, где, например, находится блок со статьёй, а где — комментарии к ней. Yandex тоже может — где-то 10 месяцев назад я у них это лично выяснил, т.к. планировал позакрывать все блоки с комментариями в Noindex.
С комментариями получается довольно интересно — поисковикам нравится обилие комментариев, т.к. это свидетельствует о хорошем поведенческом факторе. Поэтому не надо переживать, что тексты комментаторов уменьшат релевантность статьи запросу — лучше подумать об их защите от спама.
Также, на мой взгляд, лучше закрыть блоки AdSense от «глаз» Яндекса (как и любые другие рекламные коды) — чтобы этот поисковик не посчитал ваш сайт «слишком» рекламным и не применил некоторые поисковые санкции. НО оставить открытыми блоки РСЯ.
Смысл в том, что в РСЯ принимаются только качественные ресурсы с точки зрения Яндекса, поэтому наличие данной рекламы может намекнуть этой ПС о «качественности» вашего проекта и повысить такую абстрактную характеристику, как траст сайта.
Noindex и закрытие внешних ссылок
Одно время (когда Yandex не поддерживал nofollow), нежелательные внешние ссылки с веб-сайта приходилось «заворачивать» в <noindex> и дополнительно приписывать к тегу ссылки rel=’nofollow’, т.е. весь код закрываемой ссылки мог выглядеть так:
Закрытие ссылок в Яндекс через ноуиндекс
— при закрытии ссылки от индексации, нужно было учитывать и предпочтения Yandex, и предпочтения других поисковиков.
Теперь данная ПС поддерживает nofollow и можно обойтись без «заворчивания» ссылки в <noindex> и пользоваться стандартным приёмом с nofollow. Подробнее про атрибут Rel=nofollow читайте тут.
Кажется, это всё, что можно рассказать про тег Noindex и Яндекс. Имейте всё это в виду и используйте грамотно
Loading…web-ru.net
Используем rel=nofollow и noindex для Yandex
В апреле, поисковик Yandex, обрадовал рунетовских веб-мастеров, включением поддержки атрибута rel=»nofollow» в ссылках. Какую пользу это нам — блоггерам принесет? Как правильно прописать атрибут rel=»nofollow» в ссылках и что теперь будет с <noindex>?
Давайте попробуем разобраться в этих новинках Яндекса .
Небольшая предыстория атрибута rel=nofollow
Что такое rel=nofollow?
Rel=» « — атрибут в ссылке <a>, указывающий отношение ссылки к целевой странице. Также, есть еще атрибут Rev=» «, указывающий отношение целевой страницы к ссылке, например (ссылка с rev=»sponsor» указывает, что это спонсорская ссылка). Но об этом в следующей статье.
Nofollow — статус, говорящий о том,что вы не одобряете данную ссылку.
Исходя из вышесказанного:
Rel=nofollow — определяет отношение вашей ссылки к целевой странице как не одобряемое. Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Rel=nofollow был введен и стандартизирован в 2005 году, в ответ на многочисленный ссылочный спам, присутствующий в блогах. Инициатором введения была поисковая система Google.
Google, встречая ссылку с данным атрибутом, не следует по данной ссылке и не передает вес PR целевым страницам. Также, данные ссылки не учитывались в расчетах распределения ссылочного веса по ссылкам страницы. Но, так было до 2010 года. На данный момент, Google, также не передает ссылочный вес и не следует по ссылкам с rel=»nofollow», но вот ссылочный вес, внутри страницы, стал распределятся и на эти ссылки но впустую. То есть, если у вашей страницы PR-10 и 10 ссылок на странице, где 5 из них закрыты, то каждая открытая ссылка передавала по 2PR на целевую страницу. Теперь каждая открытая ссылка будет передавать 1PR по открытым ссылкам и по 1PR в пустоту по закрытым. Но эта статья не о Google, вернемся к Яндексу.
Yandex, до апреля месяца 2010г., не учитывал данный статус. В рекомендациях Яндекса находим нашумевший тег <noindex>, который позволял сделать тоже самое и больше. Теперь там и nofollow.
В чем разница rel=nofollow и <noindex>
Так в чем же проблема?
Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
се дело в том, что тег <noindex> это личная инициатива Yandex. Данный тег нигде в мире, кроме самого Яндекс, не поддерживается и не стандартизирован. При проверке ресурса на ошибки в коде и поддержке web-стандартов, веб-мастера всегда получали «не валидный» код. То есть, ваш ресурс содержит ошибки. Но, спешу вас успокоить, это не критическая ошибка и практически ни на что не влияет. Для тех кому важен валидный код, вот структура, рекомендованная самим Yandex для валидности вашего кода:
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->
Еще одна проблема тега <noindex> в том, что зарубежные веб-мастера, не ведая о данном теге, не используют его в разработках своих плагинов к WordPress. Приходится данные плагины адаптировать под Яндексовскую реальность.
Если в комментариях блога ссылки были закрыты атрибутом rel=»nofollow», то для Яндекса эти ссылки были открыты. Это означало, что роботу приходилось путешествовать по всем ссылкам указанным в комментариях.
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать.
Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow». Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Зачем нужен <noindex>?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex.
Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует. Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент.
Как правильно прописать rel=nofollow и <noindex>
- Для закрытия ссылок от индексации, с помощью rel=»nofollow», используется простая схема:
<a rel=»nofollow» href=»http://www.site.com» title=»Подсказка»>Ссылка на сайт</a>
перехода по ссылке не будет. - Для закрытия блока текста тегом <noindex>, со всем содержимым, в том числе и с анкорами ссылок, используется схема:
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->данный текстовый блок не будет проиндексирован в Яндекс, со всеми текстами ссылок. - Для закрытия блока текста тегом и ссылок в блоке, используется схема:
<!--noindex-->Блок вашего закрываемого текста <a rel="nofollow" href="http://www.site.com" title="Подсказка">Текст анкор ссылки</a> Блок вашего закрываемого текста<!--/noindex-->данный блок не будет проиндексирован в Яндекс, со всеми ссылками содержащимся в данном блоке.
Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
corp2.info
Валидность сайта, HTML страницы – сервисы проверки, валидный noindex
На все том же пресловутом сео семинаре я услышал мнение, что для хорошего восприятия того или иного сайта google, он должен быть кроме всего прочего валидным, то есть иметь валидный HTML код. Не знаю как насчет css, поисковые системы вроде как его не сильно понимают, но вот с HTML куда проще. Я уже как-то обращался к данной теме в посте с советами по улучшению блога, но тема затронута была несколько в ином ключе.
В принципе, особых проблем по созданию валидного HTML кода нет. В зависимости от используемого формата DOCTYPE определены те или иные правила. Чаще всего в блогах на WordPress идет тип документа XHTML 1.0 Transitional. Большинство шаблонов, найденных в сети, уже валидны, поскольку их создатели беспокоятся о правильности кода — с ошибками продать темы не получится. Да и вообще стандартам «там», по-моему, больше внимания уделяется.
Сервисы проверки валидности кода HTML
Скорее всего, в сети есть очень много seo и обычных сервисов для проверки валидности, тем не менее, главный из них находится на сайте W3C здесь. В специальной форме вводите ссылку на свой сайт или любую его страницу, если требуется, выбираете дополнительные опции (кодировку, DOCTYPE), после чего запускаете проверку Check.
При наличии неточностей, в результатах вы получите список предупреждений и ошибок в коде. Иначе высветится приятная зеленая надпись «This document was successfully checked as XHTML 1.0 Transitional!»:)
Чтобы ускорить процесс можно использовать одну из функций модуля для firefox web developer, где кроме валидации есть куча других полезных мелочей.
Валидный noindex
Проблема валидности, как это не удивительно, часто подстерегает с использованием отечественных особенностей, например, счетчики различные и тег noindex. Он используется исключительно для Яндекса чтобы запретить индексацию информации, находящейся в нем. Точно также как для гугла закрываются от индексации ссылки через rel=»nofollow». Но проблема заключается в том, что в W3C вообще не знают или не воспринимают тег noindex, поэтому получить валидный HTML с его использованием нереально. Приходится применять маленькую хитрость в виде следующего кода:
<span><![CDATA[<noindex>]]></span> Текст и ссылки, которые не индексируются <span><![CDATA[</noindex>]]></span> |
<span><![CDATA[<noindex>]]></span> Текст и ссылки, которые не индексируются <span><![CDATA[</noindex>]]></span>
Это для HTML, при этом в CSS пишите класс:
Данный метод можно найти на множестве сайтов и блогов, о нем не писал только ленивый. А я вот лишь сейчас только занялся валидацией, поэтому и обратил внимание. Использовал его на своем сайте — HTML валидация проходится успешно. При этом многие авторы (оптимизаторы) заявляют, что в процессе тестирования noindex продолжает корректно выполнять свои функции для Яндекса. То есть, походу данное решение позволяет получить валидный noindex.
Кроме того в коде часто бывают проблемы со счетчиками, где используется символ «&». Так вот для типа документа XHTML его нужно просто заменить набором символов «&». Чтобы исправить другие ошибки, читайте пояснения валидатора.
Даже, если валидность HTML не влияет на восприятие сайта поисковиком google, то она может помочь выявить наличие ошибок в самом проекте. Некоторые браузеры (как firefox) часто закрывают глаза на небольшие нюансы — типа отсутствие закрывающей конструкции —> и т.п., в то время как IE будет выводить ошибочное содержимое страницы. Или div какой-то не закрыли, упустили — все это можно с большой вероятностью обнаружить при валидации документа HTML.
А вы что думаете по поводу валидности кода — соблюдаете или нет?
UPD 9.07. Почитав еще немного информации на сайтах и форумах, пришел к выводу, что конструция <![CDATA[<noindex>]]> ссылки от Яши не закроет, хотя валидность будет 100%. Поэтому, думаю, правильным будет соблюдение всех правил написания html кода, но с обычным использованием тега noindex без извращений.
UPD UPD 15.05.11 Неожиданно ответ по поводу валидного noindex был найден на сайте Яндекса, где в описании совершенно четко указано решение данной проблемы, позволяющее использовать noindex и не нарушающего никакие правила W3C (плюс, кстати, Яндекс теперь понимает rel=»nofollow»):
<!--noindex-->текст, индексирование которого нужно запретить<!--/noindex--> |
<!—noindex—>текст, индексирование которого нужно запретить<!—/noindex—>
P.S. Постовой. Поисковое продвижение сайта, поисковая оптимизация сайтов.
Новые книги предлагает книжный интернет магазин Букля. Низкие цены, бесплатная доставка!
Машинки и паровозики — игрушки для детей.
Посетите наш цветочный салон и купите цветы, готовые букеты.
tods-blog.com.ua
Метатег robots | Закрыть страницу от индексации
Метатег robots | Закрыть страницу от индексации
Статья для тех, кому лень читать справку по GoogleWebmaster и ЯндексВебмастер
|
|
Закрывание ненужных страниц веб-ресурса от поисковой индексации очень важно для его SEO-оптимизации, особенно на начальном этапе становления сайта или блога «на ноги». Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п. |

- Метатег robots
- Почему метатег robots лучше файла robots.txt
Метатег robots
Для управления поведением поисковых роботов на веб-странице, в HTML существует метатег robots и его атрибут content. закрытия веб-страницы от поисковой индексации,
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
|
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») |
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут rel=»nofollow» у отдельно стоящей ссылки, поисковые роботы Google не переходят по такой ссылке и не индексируют её видимую часть (анкор). Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
достаточно добавить в её заголовок строку с метатегом:
<meta name=»robots» content=»nofollow»/> - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example.ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example.ru» rel=»nofollow»><noindex>Анкор</noindex></a>
Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
Почему метатег robots лучше файла robots.txt
Самый простой и популярный способ закрыть веб-страницу от индексации – это указать для неё соответствующую директиву в файле robots.txt. Для этого, собственно файл robots.txt и существует. Однако, закрывать через метатег robots – гораздо надёжнее.
И, вот почему.
Алгоритмы обработки роботами метатега robots и файла robots – совершенно различные. Работу этих алгоритмов можно сравнить с действием в известном анекдоте, где бьют не «по паспорту», а – «по морде». Пусть этот пример весьма груб и примитивен, но он, как нельзя лучше – отображает поведение поискового робота на странице:
- В случае использования метатега robots, поисковик просто и прямо заходит на веб-страницу и читает её заголовок («смотрит в её морду». Если робот там находит метатег robots – он разворачивается и уходит восвояси. Вуаля! Всё предельно просто. Робот увидел запись, что здесь ловить нечего, и сразу же – «свалил». Ему проблемы не нужны. Это есть работа по факту записи прямо в заголовке страницы («по морде»).
- В случае использования файла robots.txt, поисковик, перед заходом на страницу – сверяется с этим файлом (читает «паспорт»). Это есть работа по факту записи в постороннем файле («по паспорту»). Если в файле robots.txt («паспорте») прописана соответствующая директива – робот её выполняет. Если нет, то он – сканирует страницу в общем порядке, поскольку по-умолчанию – к сканированию разрешены все страницы.
Казалось-бы, какая разница.
Тем более, что сам Яндекс рассказывает следующее:
При сканировании сайта, на основании его файла robots.txt – составляется специальный список (пул), в котором ясно и чётко указываются и излагаются директории и страницы, разрешённые к поисковому индексированию сайта.
Ну, чего ещё проще – составил списочек,
прошёлся списочком по сайту,
и всё – можно «баиньки»…
Простота развеется, как майский дым, если мы вспомним, что роботов много, что все они разные, и самое главное – что все роботы ходят по ссылкам. А сей час, представим себе стандартную ситуацию, которая случается в интернете миллионы раз на дню – поисковый робот пришёл на страницу по ссылке из другого сайта. Вот он, трудяга Сети – уже стоит у ворот (у заголовка) странички. Ну, и где теперь файл robots.txt?
У робота, пришедшего на сайт по внешней ссылке, выбор не большой. Робот может, либо лично «протопать» к файлу robots.txt и свериться с ним, либо просто скачать страницу себе в кэш и уже потом разбираться – индексировать её или нет.
Как поступит наш герой, мы не знает. Это коммерческая тайна каждой поисковой системы. Несомненно, одно. Если в заголовке страницы будет указан метатег robots – поисковик выполнит его немедля. И, если этот метатег запрещает индексирование страницы – робот уйдёт немедля и без раздумий.
Вот теперь, совершенно ясно, что прямой заход на страницу, к метатегу robots –
всегда короче и надёжнее, нежели долгий путь через закоулки файла robots.txt
Метатег robots | Закрыть страницу от индексации на tehnopost.info
- Метатег robots
- Почему метатег robots лучше файла robots.txt
tehnopost.info
или — как правильней? [Архив]
Просмотр полной версии : <noindex> или <!—noindex—> — как правильней?
kazi_mir
23.12.2011, 14:59
текстили
<noindex>текст</noindex>
Какой вариант правильней и что (как) лучше использовать.
В чем отличия.
Масол
23.12.2011, 15:01
Правильный для чего?
Первый вариант — комментарий, второй — рабочее закрывание от индексации.
maldivec
23.12.2011, 15:03
Отличия в том, что нет такого тега в стандартах html, поэтому валидаторы на него будут ругаться. Да и другие поисковики кроме яндекса его не признают.При использовании конструкции <!—noindex—>текст<!—/noindex—> код будет проходить валидацию, т.к. это будет восприниматься как закомментированный текст.
Для яндекса все равно, какой вариант вы будете использовать. Он понимает оба.
provocator
23.12.2011, 15:03
Можно и так и так, но первый вариант более валидный.
обычно ставлю <noindex><nofollow>***text***</nofollow></noindex>
maldivec
23.12.2011, 15:06
Первый вариант — комментарий, второй — рабочее закрывание от индексации.Т.е. по-вашему первый вариант не сработает? 🙂
———- Добавлено в 17:06 ———- Предыдущее сообщение было в 17:05 ———-
обычно ставлю <noindex><nofollow>***text***</nofollow></noindex>
Тега <nofollow> вообще не существует и он никаким образом не работает 😀
Масол
23.12.2011, 15:07
Можно и так и так, но первый вариант более валидный.
Более валидный для чего?
Т.е. по-вашему первый вариант не сработает? 🙂
———- Добавлено в 17:06 ———- Предыдущее сообщение было в 17:05 ———-
Тега <nofollow> вообще не существует и он никаким образом не работает 😀
Вот блин(
А как от гугла закрывать?
Более валидный для чего?
для валидаторов )
kimberlit
23.12.2011, 15:11
Для тех, кто в танке.http://help.yandex.ru/webmaster/?id=1111858
Тег <noindex>
Для запрета индексирования служебных участков текста вы можете использовать тег <noindex>. Тег работает аналогично мета-тегу noindex, но распространяется только на контент, заключенный внутри тега в формате:
<noindex>текст, индексирование которого нужно запретить</noindex>
Тег noindex не чувствителен к вложенности (может находиться в любом месте html-кода страницы). При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<!—noindex—>текст, индексирование которого нужно запретить<!—/noindex—>
<!—noindex—>текст<!—/noindex—>
лучше такой вариант использовать
provocator
23.12.2011, 15:15
Вот блин(
А как от гугла закрывать?
А зачем от него закрывать? Гугл вроде более лоялен к контенту. Можно на всей странице контент закрыть с помощью мета-тега nofollow.
Масол
23.12.2011, 15:16
Т.е. по-вашему первый вариант не сработает?А как по вашему, комментарии влияют на индексацию сайта поисковыми системами?
UPD. Яндекс удивил )))
maldivec
23.12.2011, 15:17
А как по вашему, комментарии влияют на индексацию сайта поисковыми системами?Данный комментарий влияет, потому что он аналогичен коду <noindex></noindex>
богоносец
23.12.2011, 15:18
А как от гугла закрывать?
За рамками HTML.
JS XML AJAX
Можно на всей странице контент закрыть с помощью мета-тега nofollow.
В хелп!
Масол
23.12.2011, 15:20
Данный комментарий влияет, потому что он аналогичен коду <noindex></noindex>
Ага, уже увидел. «Чудны дела твои…» ну и далее по тексту. 🙂
Всё не как у всех. 🙂
kazi_mir
23.12.2011, 22:38
обычно ставлю ***text***А разве нофоллоу это тэг, а не атрибут ссылки (rel=»nofollow»)?
Костный мозг
24.12.2011, 08:08
А разве нофоллоу это тэг, а не атрибут ссылки (rel=»nofollow»)?
ответ:
nofollow
это
атрибут ссылки
🙂
господа, что-то вы уже такие основы основ обсуждаете… мы так и до тега <html> докатимся, куда его вставлять и валидный ли это тег?))
богоносец
24.12.2011, 13:06
мы так и до тега <html> докатимся, куда его вставлять
Зря смеётесь. Об нём в современных ПС многое… подразумевается.
kazi_mir
24.12.2011, 14:35
ответ:господа, что-то вы уже такие основы основ обсуждаете… мы так и до тега <html> докатимся, куда его вставлять и валидный ли это тег?))
г-н Костный мозг, я не ставил вопрос, а поправлял г-на softer в своей типичной манере! Вы просто этого не поняли. Возможно, если б я поставил смайлик 😉 или :confused:, или даже :dont:, то это не вызвало у вас такой реакции.
А как от гугла закрывать?
как вариант (http://support.google.com/webmasters/bin/answer.py?hl=ru&answer=93710)
<meta name=»googlebot» content=»noindex»>
Костный мозг
24.12.2011, 17:10
Зря смеётесь. Об нём в современных ПС многое… подразумевается.
а темы на серче о нем нет, непорядок)
поправлял г-на softer в своей типичной манере
значит я просто вас не так понял
Вот блин(
А как от гугла закрывать?
<noindex><a href=»#» rel=»nofollow»>блабла</a></noindex>
Стоит помнить, что атрибут rel=»nofollow» не закрывает от индексации, он просто указывает, что вес страницы по этой ссылке передаваться не должен.
богоносец
24.12.2011, 18:21
так и до тегаЗагляните в код ццц.яндекс.ру (http://www.yandex.ru/) // говорят, что он в индексе… хотя теги отсутствуют.
Если убираете <html> то всё индексится (http://yandex.ru/yandsearch?text=site:seo-xslt.narod.ru/DEMO/Root-Elemen-Already-Specified.XML)… а если вместо него пишите <root> например, то возникают проблемы — разные в разных ПС… в Гугле (http://www.google.com/search?q=site:seo-xslt.narod.ru/DEMO/Root-Not-Html-Head-Title-Meta.xml).
И ни один бот Шукин вам ни в чём не признается.
Костный мозг
24.12.2011, 20:34
богоносец, интересно было почитать для общего развития, спасибо
Всё не как у всех.
Значит у Гугла тоже не как у всех. (http://code.google.com/intl/ru-RU/apis/searchappliance/documentation/46/admin_crawl/Preparing.html) Это не по поводу как скрыть от индексации.
kimberlit
25.12.2011, 14:58
Значит у Гугла тоже не как у всех. Это не по поводу как скрыть от индексации.
А что там?…..
А что там?…..
Ну я ж для этого и дал ссылку, чтобы увидеть, что и гугл тоже некоторые директивы оформляет как комментарии.
searchengines.guru