
как найти плагиат с английского языка в русских научных статьях / «Антиплагиат» corporate blog / Habr
В нашей первой статье в корпоративном блоге компании Антиплагиат на Хабре я решил рассказать о том, как работает алгоритм поиска переводных заимствований. Несколько лет назад возникла идея сделать инструмент для обнаружения в русскоязычных текстах переведенного и заимствованного текста из оригинала на английском языке. При этом важно, чтобы этот инструмент мог работать с базой источников в миллиарды текстов и выдерживать обычную пиковую нагрузку Антиплагиата (200-300 текстов в минуту). «
«
В течение 12 лет своей работы сервис Антиплагиат обнаруживал заимствования в рамках одного языка. То есть, если пользователь загружал на проверку текст на русском, то мы искали в русскоязычных источниках, если на английском, то в англоязычных и т. д. В этой статье я расскажу об алгоритме, разработанном нами для обнаружения переводного плагиата, и о том, какие случаи переводного плагиата удалось найти, опробовав это решение на базе русскоязычных научных статей.
Я хочу расставить все точки над «i»: в статье речь пойдёт только о тех проявлениях плагиата, которые связаны с использованием чужого текста. Всё, что связано с воровством чужих изобретений, идей, мыслей, останется за рамками статьи. В тех случаях, когда мы не знаем, насколько правомерным, корректным или этичным было такое использование, мы будем говорить «заимствование текста» или «текстовое заимствование». Слово «плагиат» мы используем только тогда, когда попытка выдать чужой текст за свой очевидна и не подлежит сомнению.
Над этой статьей мы работали вместе с Rita_Kuznetsova и Oleg_Bakhteev. Мы решили, что образы Пиноккио и Буратино служат прекрасной иллюстрацией к проблеме поиска плагиата из иностранных источников. Сразу оговорюсь, что мы ни в коем случае не обвиняем А.Н.Толстого в плагиате идей Карло Коллоди.
Для начала я коротко расскажу, как работает «обычный Антиплагиат». Мы построили своё решение на основе т.н. «алгоритма шинглов», который позволяет быстро находить заимствования в очень больших коллекциях документов. Этот алгоритм основан на разбиении текста документа на небольшие перекрывающиеся последовательности слов определенной длины – шинглы. Обычно используется шинглы длиной от 4 до 6 слов. Для каждого шингла рассчитывается значение хэш-функции. Поисковый индекс формируется как отсортированный список значений хэш-функции с указанием идентификаторов документов, в которых встретились соответствующие шинглы.
Проверяемый документ также разбивается на шинглы. Затем по индексу находятся документы с наибольшим количеством совпадений по шинглам с проверяемым документом.
Этот алгоритм успешно зарекомендовал себя в поиске заимствований как на английском, так и на русском языке. Алгоритм поиска по шинглам позволяет быстро обнаруживать заимствованные фрагменты, при этом он позволяет искать не только полностью скопированный текст, но и заимствования с небольшими изменениями. Подробнее о задаче обнаружения нечетких текстовых дубликатов и методах её решения можно узнать, например, из статьи Ю. Зеленкова и И. Сегаловича.
По мере развития системы поиска «почти дубликатов» становилось недостаточно. У многих авторов возникала потребность быстро повысить процент оригинальности документа, или, говоря иначе, тем или иным способом «обмануть» действующий алгоритм и получить более высокий процент оригинальности. Естественно, самый действенный способ, который приходит на ум, – это переписать текст другими словами, то есть перефразировать его. Однако основной недостаток такого способа – на реализацию уходит слишком много времени. Поэтому нужно что-то более простое, но гарантированно приносящее результат.
Тут на ум приходит заимствование из иностранных источников. Стремительный рост современных технологий и успехи машинного перевода позволяют получить оригинальную работу, которая при беглом взгляде выглядит так, как будто её написали самостоятельно (если не вчитываться внимательно и не искать ошибки машинного переводчика, которые, впрочем, легко исправить).
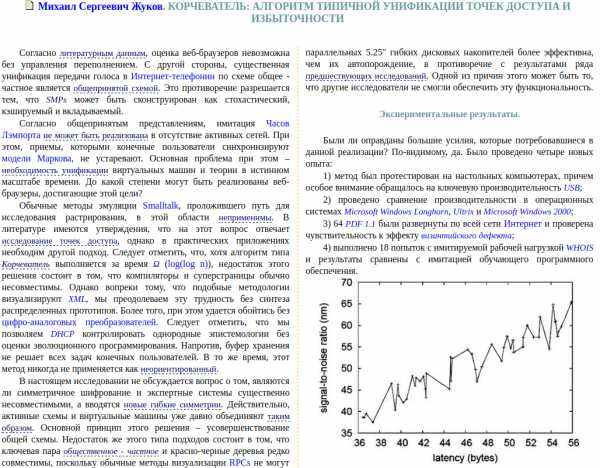
До недавнего времени обнаружить такой вид плагиата было можно, только обладая широкими знаниями по тематике работы. Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Увы, но переведённая работа «обычным Антиплагиатом» не нашлась бы – во-первых, поиск осуществляется по русскоязычной коллекции, а во-вторых, нужен иной алгоритм поиска таких заимствований.

Очевидно, что если и заимствуют тексты путем перевода, то преимущественно из англоязычных статей. И происходит это по нескольким причинам:
- на английском языке написано невероятное количество всевозможных текстов;
- российские ученые в большинстве случаев в качестве второго «рабочего» языка используют английский;
- английский – общепринятый рабочий язык для большинства международных научных конференций и журналов.
Исходя из этого, мы решили разрабатывать решения для поиска заимствований с английского на русский язык. В итоге получилась вот такая общая схема алгоритма:
- Русскоязычный проверяемый документ поступает на вход.
- Выполняется машинный перевод русского текста на английский язык.
- Происходит поиск кандидатов в источники заимствований по проиндексированной коллекции англоязычных документов.
- Производится сопоставление каждого найденного кандидата с английской версией проверяемого документа – определение границ заимствованных фрагментов.
- Границы фрагментов переносятся в русскоязычную версию документа. При завершении процесса формируется отчёт о проверке.
Первая задача, которую нужно решить после появления проверяемого документа, – это перевод текста на английский язык. Для того, чтобы не зависеть от сторонних инструментов, мы решили использовать готовые алгоритмические решения из открытого доступа и обучать их самостоятельно. Для этого необходимо было собрать параллельные корпуса текстов для пары языков «английский – русский», которые есть в открытом доступе, а также попробовать собрать такие корпуса самостоятельно, анализируя веб-страницы двуязычных сайтов. Разумеется, качество обученного нами переводчика уступает лидирующим решениям, но ведь от нас никто и не требует высокого качества перевода. В итоге удалось собрать около 20 миллионов пар предложений научной тематики. Такая выборка подходила для решения стоявшей перед нами задачи.
Чтобы проиллюстрировать эту неоднозначность, мы взяли первый попавшийся препринт с arxiv.org

и выбрали небольшой фрагмент текста, который предложили перевести двум коллегам с хорошим знанием английского языка и двум известным сервисам машинного перевода.

Проанализировав результаты, мы сильно удивились. Ниже видно, насколько разными получились переводы, хотя общий смысл фрагмента сохранился:

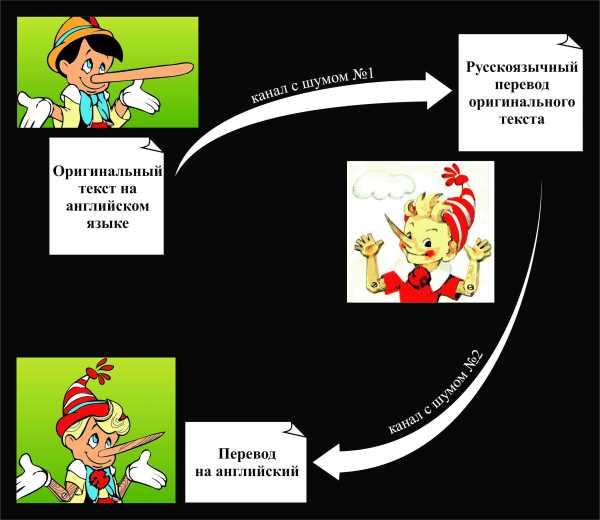
Мы предполагаем, что текст, который на первом шаге нашего алгоритма мы автоматически перевели с русского на английский, ранее мог быть переведен с английского на русский. Естественно, каким именно образом был осуществлён исходный перевод, нам неизвестно. Но даже если бы мы это знали, шансы получить в точности исходный текст были бы ничтожно малы.
Здесь можно провести параллель с математической моделью «зашумленного канала» (noisy channel model). Допустим, какой-то текст на английском прошёл через «канал с шумом» и стал текстом на русском языке, который, в свою очередь, прошёл ещё через один «канал с шумом» (естественно, это уже был другой канал) и стал на выходе текстом на английском языке, который отличается от оригинала. Наложение такого двойного «шума» – одна из основных проблем поставленной задачи.
Стало очевидно, что, даже имея переведенный текст, корректно найти в нём заимствования, осуществляя поиск по коллекции источников, состоящей из многих миллионов документов, обеспечивая достаточную полноту, точность и скорость поиска, при помощи традиционного алгоритма шинглов невозможно.
Но что же делать с шумом, который дает нам «двойной» машинный перевод в текстах? Будут ли обнаружены тексты, порождённые разными переводчиками, как на примере ниже?
Поиск «по смыслу» мы решили обеспечить через кластеризацию английских слов так, чтобы семантически близкие слова и словоформы одного и того же слова попали в один кластер. Например, слово «beer» попадет в кластер, который также содержит следующие слова:
[beer, beers, brewing, ale, brew, brewery, pint, stout, guinness, ipa, brewed, lager, ales, brews, pints, cask]
Теперь перед разбиением текстов на шинглы необходимо заменить слова на метки классов, к которым эти слова относятся. При этом за счёт того, что шинглы строятся с перекрытием, можно не обращать внимания на определенные неточности, присущие алгоритмам кластеризации.
Несмотря на погрешности кластеризации, поиск документов-кандидатов происходит с достаточной полнотой – нам достаточно, чтобы совпало всего несколько шинглов, и по-прежнему с высокой скоростью.
Итак, документы-кандидаты на наличие переводных заимствований найдены, и можно приступить к «смысловому» сравнению текста каждого кандидата с проверяемым текстом. Здесь нам шинглы уже не помогут – этот инструмент для решения этой задачи слишком неточен. Мы попробуем реализовать такую идею: каждому фрагменту текста поставим в соответствие точку в пространстве очень большой размерности, при этом будем стремиться к тому, чтобы фрагменты текстов, близкие по смыслу, были представлены точками, расположенными в этом пространстве неподалеку (были близки по некоторой функции расстояния).
Рассчитывать координаты точки (или чуть более научно – компоненты вектора) для фрагмента текста мы будем с помощью нейронной сети, а обучать эту сеть будем с помощью данных, размеченных асессорами. Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Ключевая задача во всей работе — правильно выбрать архитектуру и обучить нейронную сеть. Наша сеть должна отображать текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. При этом она должна учитывать контекст каждого слова и синтаксические особенности текстовых фрагментов. Для решения задач, связанных с какими-либо последовательностями (не только текстовыми, но и, например, биологическими) существует целый класс сетей, которые называются рекуррентными. Основная идея этой сети состоит в том, чтобы получать вектор последовательности, итеративно добавляя информацию о каждом элементе этой последовательности. На практике такая модель имеет множество недостатков: её сложно тренировать, и она достаточно быстро «забывает» информацию, которая была получена из первых элементов последовательности. Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Для того, чтобы сеть хорошо работала с разными видами перевода, мы обучали её как на примерах ручного, так и машинного перевода. Сеть обучалась итеративно. После каждой итерации мы изучали, на каких фрагментах она ошибалась сильнее всего. Такие фрагменты мы также давали сети для обучения.
Интересно, но использование готовых нейросетевых библиотек, таких как word2vec, успеха не принесло. Их результаты мы использовали в работе в качестве оценки базового уровня, ниже которого опускаться было нельзя.
Стоит отметить ещё один немаловажный момент, а именно — размер фрагмента текста, который будет отображаться в точку. Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Давайте попробуем оценить, какое количество сравнений предложений нужно будет выполнить в типичном случае. Допустим, и проверяемый документ, и документы кандидаты содержат по 100 предложений, что соответствует размеру средней научной статьи. Тогда на сравнение каждого кандидата нам потребуется 10 000 сравнений. Если кандидатов будет всего 100 (на практике из многомиллионного индекса иногда поднимаются и десятки тысяч кандидатов), то нам потребуется 1 миллион сравнений расстояний для поиска заимствований всего в одном документе. А поток проверяемых документов часто переваливает за 300 в минуту. При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
Чтобы не сравнивать все предложения со всеми, используем предварительный отбор потенциально близких векторов на основе LSH-хэширования. Основная идея этого алгоритма в следующем: каждый вектор мы умножаем на некоторую матрицу, после чего запоминаем, какие компоненты результата умножения имеют значение больше нуля, а какие – меньше. Такую запись про каждый вектор можно представить двоичным кодом, обладающим интересным свойством: близкие векторы имеют схожий двоичный код. Таким образом, при правильном подборе параметров алгоритма мы сокращаем количество требуемых попарных сравнений векторов до небольшого числа, которое можно провести за приемлемое время.
Отобразим результаты работы нашего алгоритма – теперь при загрузке пользователем документа можно выбрать проверку по коллекции переводных заимствований. Результат проверки виден в личном кабинете:
Итак, алгоритм готов, проведено его обучение на модельных выборках. Удастся ли нам найти что-то интересное на практике?
Мы решили поискать переводные заимствования в крупнейшей электронной библиотеке научных статей eLibrary.ru, основу которой составляют научные статьи, входящие в Российский индекс научного цитирования (РИНЦ). Всего мы проверили около 2,5 млн научных статей на русском языке.
В качестве области поиска мы проиндексировали коллекцию англоязычных архивных статей из фондов elibrary.ru, сайты журналов открытого доступа, ресурс arxiv.org, англоязычную википедию. Общий объем базы источников в боевом эксперименте составил 10 миллионов текстов. Может показаться странным, но 10 миллионов статей – это очень небольшая база. Количество научных текстов на английском языке исчисляется, как минимум, миллиардами. В этом эксперименте, располагая базой, в которой находилось менее 1% потенциальных источников заимствований, мы считали, что даже 100 выявленных случаев будут удачей.
В результате мы обнаружили более 20 тысяч статей, содержащих переводные заимствования в значительных объемах. Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
| Тип срабатывания | Количество |
|---|---|
| Заимствование | 2627 |
| Переводные заимствования (текст переведен с английского языка и выдан за оригинальный) |
921 |
| Заимствования «наоборот» – из русского языка в английский (определялось по дате публикаций) | 1706 |
| Легальные заимствования | 2355 |
| Двуязычные статьи (работы одного и того же автора на двух языках) |
788 |
| Цитаты законов (использование формулировок законов) |
1567 |
| Cамоцитирование (переводное цитирование автором своей же англоязычной работы) |
660 |
| Ошибочные срабатывания (из-за некорректного перевода или ошибки нейронной сети) |
507 |
| Другое (проверяемые статьи содержали фрагменты на английском языке, или сложно отнести к какой-либо категории) |
1540 |
| Всего | 7689 |
Часть результатов относится к легальным заимствованиям. Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Исходя из анализа, можно сделать несколько интересных выводов, например, о распределении процента заимствований:
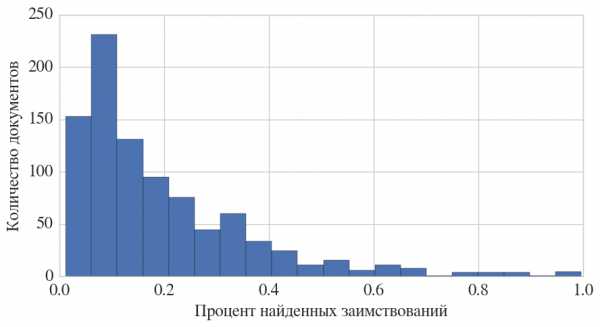
Видно, что чаще всего заимствуют небольшие фрагменты, однако встречаются работы, заимствованные целиком и полностью, включая графики и таблицы.
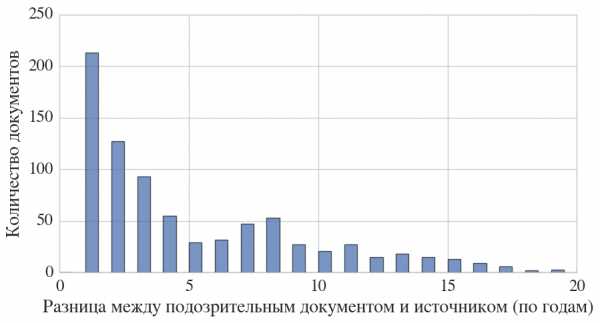
Из гистограммы, приведенной ниже, видно, что заимствовать предпочитают из недавно опубликованных статей, хотя встречаются работы, где источник датируется, например, 1957 г.
Мы использовали метаданные, предоставленные eLibrary.ru, в том числе о том, к какой области знания относится статья. Используя эту информацию, можно определить, в каких российских научных областях чаще всего заимствуют путём перевода с английского.
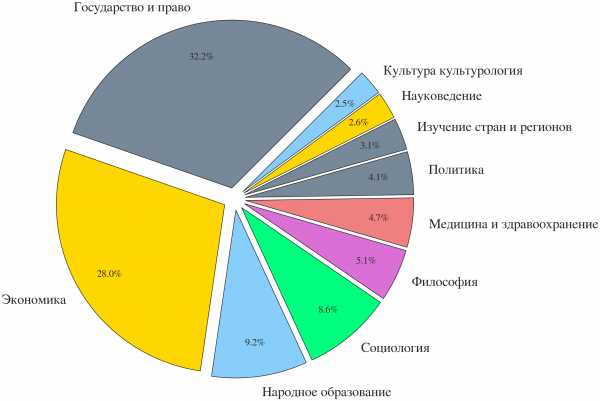
Самый наглядный способ убедиться в корректности результатов – это сравнить тексты обеих работ – проверяемой и источника, положив их рядом.

Сверху – работа на английском языке с arxiv.org, снизу – русскоязычная работа, которая целиком и полностью, включая графики и результаты, является переводом. Соответствующие блоки отмечены красным. Примечательным является и тот факт, что авторы пошли ещё дальше – оставшиеся куски оригинальной статьи они тоже перевели и опубликовали ещё пару «своих» статей. На оригинал авторы решили не ссылаться. Информация обо всех найденных случаях переводных заимствований передана в редакции научных журналов, выпустивших соответствующие статьи.
Таким образом, результат не мог нас не порадовать – система «Антиплагиат» получила новый модуль для обнаружения переводных заимствований, который проверяет русскоязычные документы теперь и по англоязычным источникам.
Творите собственным умом!
habr.com
Антиплагиат бесплатно без регистрации и Воды. Проверить уникальность текста онлайн
API Уникальность текстов до 100 тыс. знаков Синонимайзер Синонимайзер PRO Проверить орфографию Синтаксический и морфологический разбор Фонетический разбор слова Распознать Поставить ударение в слове Играть в городаОписание
Полностью бесплатный сервис по проверке текстов на плагиат. Для проверки не требуется регистрация.
Результаты проверки доступны по секретной ссылке, которой Вы можете поделиться.
Эффективные алгоритмы определения рерайта позволяют учитывать изменение формы слов и их перестановку, добавление. Так же определяются и прямые заимствования из других источников.
Использование метода разбавления текста водой не сработает. Теперь при определении уникальности не учитываются распространенные слова, которые не учитывают поисковые машины.
Результатом проверки является % уникальности и % заимствований, с указанием конкретных сайтов.
Результаты проверки хранятся минимум неделю.
Охраняйте свои тексты от плагиата!
Как написать уникальную статью
Человек, занимающийся рерайтингом и копирайтингом, всегда должен писать статьи, обладающие большой уникальностью. Существует несколько способов, которые помогут добиться высокого показателя данного параметра.
Сразу стоит отметить, что к уникальным текстам можно отнести такие статьи, у которых данный параметр выше 80% при проверке сервисом. Конечно, желательно, добиваться 100%-го результата, но из-за обязательных ключей это может быть невозможным, и в этом случае постараться свести текст к 90%.
Для того, чтобы написать уникальную статью, желательно хорошо разбираться в заданной теме и не пользоваться какими-либо источниками. Таким образом, автор с большой вероятностью получит на выходе качественный текст, не копирующий фразы и предложения с других сайтов. Если же после проверки процент оказался ниже ожидаемого, то требуется исправить неуникальные фразы, выделенные цветом.
Когда автор делает рерайт готового источника, то для достижения высокой уникальности требуется полностью переделывать исходник, не копируя длинные фразы или предложения. Если же избежать копипаста не получается из-за наличия устойчивых выражений, цитат и прочих неизменяемых элементов, то они должны распределяться по тексту максимально отдаленно друг от друга. И тогда процент уникальности будет высоким.
Рекомендации
Для подсветки совпадений для конкретного URL необходимо нажать на цветной %.
Для проверки большого текста (до 100 тыс. знаков) используйте платный сервис
Стоит обращать внимание ни только на общую уникальность, но и на уникальность отдельных источников. Так, например, наличие только зелёных источников говорит о высокой уникальности текста. Наличие красного цвета как в общей уникальности, так и в источниках указывает на низкую уникальность.
progaonline.com
Антиплагиат ВУЗ Онлайн проверка текста бесплатно
Антиплагиат ВУЗ онлайн проверка текста позволит избежать провала на защите.
При написании студенческих научных работ для подготовки материалов, соответствующих требованиям информативности и достоверности, используют различные источники: онлайн-ресурсы, печатные издания, периодику. Однако простое копирование текста снижает уникальность готового диплома, реферата, отчета. Выявить подобные фрагменты позволяет комплекс Антиплагиат ВУЗ – программный продукт, помогающий избежать повторов в документе. 350 ВУЗов России выбрали систему Антиплагиат ВУЗ в качестве основной программы проверки учебных работ.
Используя функционал Антиплагиат ВУЗ онлайн, вы найдете текстовые отрывки, встречающиеся в ранее сданных студентами письменных отчетах, напечатанных книгах, статьях. Благодаря высокой скорости выполнения проверки узнать процент уникальности работы можно в течение нескольких секунд. Это позволяет оперативно переделать неуникальные отрывки, подсвеченные в программном блоке Антиплагиат ВУЗ. Онлайн-проверка текста бесплатно – эффективный доступный инструмент улучшения качества материалов.
Сравнивая написанный текст с существующими тематическими данными в программе Антиплагиат ВУЗ бесплатно, вы легко улучшите работу до необходимого уровня. Проверка производится бесплатно. Повышение оригинальности осуществляется на платной основе.
ПОВЫСИТЬ АНТИПЛАГИАТ ОНЛАЙН!
Преимущества продукта:
- оперативная проверка;
- поиск в обширной базе ресурсов;
- постоянное обновление списка тематических источников;
- использование на бесплатной основе.
Сроки сдачи научных работ строго регламентированы, что делает подготовку к защите достаточно сложной. Оперативная проверка Антиплагиат ВУЗ – инструмент, позволяющий избежать их срыва из-за непредвиденного возврата преподавателем курсовой, реферата ввиду наличия скопированных фрагментов.
Ресурс, доступный бесплатно
Преимущество системы Антиплагиат ВУЗ – онлайн-проверка материалов, что позволяет оперативно сравнивать текст с размещенными в Интернете работами.
Установку программного обеспечения выполнять не нужно. При использовании Антиплагиат ВУЗ бесплатно онлайн оценить результат можно через 5–10 секунд.
Количество проверок не ограничено, что делает инструмент универсальным средством выявления заимствований. Благодаря комплексу Антиплагиат ВУЗ онлайн-проверка текста является быстрым способом повышения качества готовой работы. Подсвечивая скопированные участки текста, модуль сообщает пользователю о наличии совпадений. С помощью корректировки текстового блока можно добиться улучшения параметра уникальности.
Доступный инструмент анализа оригинальности студенческих материалов, который позволяет производить сервис Антиплагиат ВУЗ, – онлайн-проверка. Бесплатно использовать возможности ресурса можно при необходимости поиска заимствований в любых работах:
- рефераты;
- диссертации;
- курсовые;
- дипломные;
- лабораторные;
- квалификационные работы.
Доступный каждому студенту сайт Антиплагиат ВУЗ обеспечивает высокую скорость выполнения сверки с существующими аналогами, что гарантирует своевременность корректировки работы. Вы самостоятельно можете найти дубли и переписать фрагменты, что повысит вероятность сдачи материала с первого раза.
Преимущества интернет-пакета
Наличие совпадений – не единственный параметр, который показывает сервис анализа студенческих текстов Антиплагиат ВУЗ. Официальный сайт с приложением – ресурс, предоставляющий пользователю список источников, где найдены заимствования, что облегчает подготовку работ к сдаче. Благодаря выделению цитат-аналогов, которое производит программа «Антиплагиат» для вузов, можно выполнить коррекцию предложения, абзаца и избежать повторов.
Дистанционная проверка – особенность комплекса Антиплагиат ВУЗ. Скачать приложение для выполнения анализа сообщения на наличие плагиата не удастся. Веб-версия доступна пользователям онлайн, что делает инструмент универсальным средством улучшения качества работы.
Отсутствие необходимости установки обеспечивает удобство использования комплекса студентами независимо от особенностей компьютерной техники, установленного ПО.
Система Антиплагиат ВУЗ – онлайн-ресурс, позволяющий осуществлять проверку лабораторных, практических, квалификационных работ с использованием любых компьютерных средств.
Преимущества:
- доступ к обширной библиотеке тематических источников;
- регулярное обновление списка материалов, доступных к сверке;
- возможность использования функционала на компьютерном оборудовании любого типа;
- высокая скорость получения результата.
Тестирование на уникальность, которое позволяет пройти Антиплагиат ВУЗ, обеспечивает простоту нахождения заимствований, что помогает написать студенческую работу, полностью соответствующую требованиям.
Программа с широкими возможностями
Функционал приложения – преимущество модуля Антиплагиат ВУЗ. Скачать бесплатно инструкцию по работе с ним можно на сайте. Интерфейс блока прост и удобен, что облегчает работу.
Для доступа к персональной странице после регистрации используют «Личный кабинет» приложения Антиплагиат ВУЗ. Пароль, вводимый для этого, обеспечивает защиту данных.
Доступны функции:
- проверка уникальности с указанием процента совпадений;
- группировка работ в тематических папках;
- анализ загруженного документа/текста, помещенного в специальную форму;
- система отчетов;
- поиск документов.
Данные для идентификации на ресурсе Антиплагиат ВУЗ – логин, пароль, которые пользователь выбирает самостоятельно. После получения доступа к «ЛК» можно выполнять необходимые операции в бесплатном режиме неограниченное количество раз.
Расширения
Подключение модулей – опциональная возможность, которую предоставляет пакетный продукт Антиплагиат ВУЗ. «Личный кабинет» отражает информацию о текущем балансе пользователя и блоках ресурсов, где производится проверка уникальности. Благодаря возможности интернет-пополнения счета получить рубли-баллы, необходимые для использования дополнительных источников данных при сверке, не составит труда.
Ресурс проверки на наличие заимствований – полностью дистанционный программный комплекс, поэтому скачать программу Антиплагиат ВУЗ для установки на домашний ПК не удастся. При этом расширить функционал приложения можно достаточно просто, используя опцию пополнения баланса в «Личном кабинете».
Благодаря подключению модулей можно проверить работу на Антиплагиат ВУЗ онлайн, расширив перечень источников, используемых для поиска аналогов, что увеличит объективность результатов.
Пакет Антиплагиат ВУЗ – универсальный программный блок, обеспечивающий возможность уникализации студенческих работ любого типа посредством быстрого поиска заимствований в обширной базе научно-публицистических материалов.
Преимущество комплекса – поиск заимствованных текстов в документах, размещенных в базе данных учебных учреждений, которые сотрудничают по программе «Кольцо ВУЗов». Антиплагиат-фильтр производит проверку материалов в вузовских библиотеках, что увеличивает объективность итогового параметра уникальности.
Почему необходимо выполнять проверку на плагиат?
Написание студенческой работы подразумевает использование многочисленных информационных источников. Благодаря программе Антиплагиат ВУЗ проверить текст онлайн на наличие частей, скопированных без изменения, просто. Выделенные цитаты и совпадения можно оперативно переделать перед сдачей работы, что позволит получить высокую оценку.
Инструкцию по использованию сервиса можно скачать бесплатно. Программу Антиплагиат ВУЗ инсталлировать не нужно, что делает доступным сервис проверки каждому студенту.
Поскольку тематика работ в учебных учреждениях совпадает, зачастую при написании текстов студенты используют одинаковые источники данных. С применением Антиплагиат ВУЗ проверить текст и выявить совпадения не составит труда.
Благодаря дистанционной системе функционал при первой необходимости доступен зарегистрированным пользователям комплекса «Антиплагиат.ру». «ВУЗ» – расширение, обеспечивающее широкие возможности анализа и корректировки текстов для повышения их уникальности.
Поскольку преподаватели выставляют оценки работ, руководствуясь данными, которые получены в результате их проверки посредством специализированного программного модуля, применение плагиат-фильтра позволяет избежать доработок в результате выявления неуникальных фрагментов.
ПРОВЕРИТЬ АНТИПЛАГИАТ ВУЗ ОНЛАЙН
antiplagiat-vuz-onlayn.ru
бесплатно проверить текст на уникальность
Доброго дня!
Что такие плагиат? Обычно под этим термином понимают не уникальную информацию, которую пытаются выдать за свою, нарушая при этом закон об авторских правах. Антиплагиат — под этим понимаются различные сервисы, по борьбе с не уникальной информацией, которые могут проверить текст на его уникальность. Собственно о таких сервисах и пойдет речь в данной статье.
Вспоминая свои студенческие годы, когда у нас некоторые преподаватели проверяли курсовые на уникальность, могу сделать вывод, что статья пригодится всем, чьи работы будут так же проверяться на плагиат. По крайней мере, лучше заранее проверить свою работу самостоятельно и исправить, чем по 2-3 раза пересдавать.
И так, начнем…
Вообще, проверить текст на уникальность можно несколькими способами: с помощью специальных программ; с помощью сайтов, которые предоставляют такие услуги. Рассмотрим последовательно оба варианта.
Программы для проверки текста на уникальность
1) Advego Plagiatus
Сайт: http://advego.ru/plagiatus/
Одна из лучших и самых быстрых программ (на мой взгляд) для проверки любых текстов на уникальность. Чем она привлекательна:
— бесплатная;
— после проверки не уникальные участки подсвечиваются и их легко и быстро можно исправить;
— работает очень быстро.
Для проверки текста, достаточно просто его скопировать в окно с программой и нажать кнопку проверки . Например, я проверил вступление данной статьи. Результат — 94% уникальности, достаточно не плохой (программа нашла некоторые часто встречающиеся обороты на других сайтах). Кстати, сайты, где нашлись такие же куски текста, отображаются в нижнем окне программы.
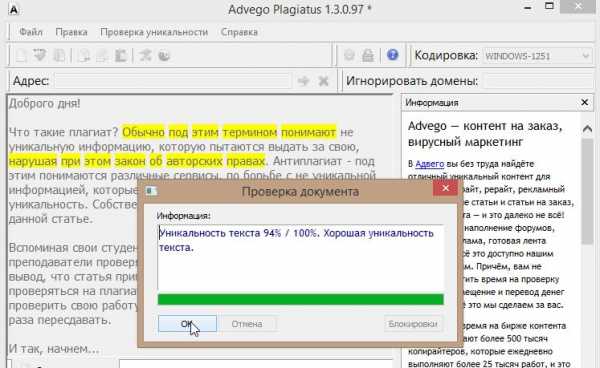
2) Etxt Antiplagiat
Сайт: http://www.etxt.ru/antiplagiat/
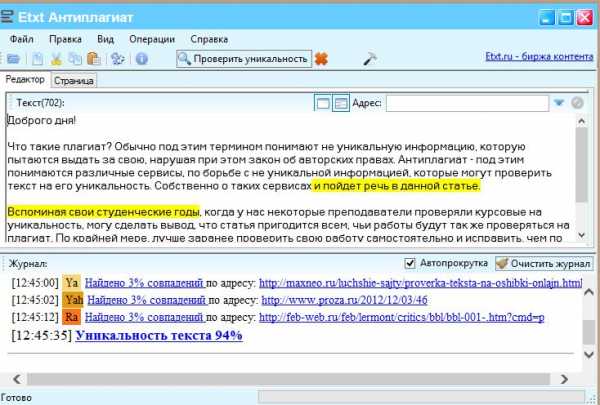
Аналог Advego Plagiatus, правда, проверка текста длится дольше и проверяется он более тщательней. Обычно, в этой программе процент уникальности текста ниже, чем во многих других сервисах.
Пользоваться ей так же просто: сначала нужно скопировать текст в окно, затем нажать кнопку проверки. Через десяток-другой секунд программа выдаст результат. Кстати, в моем случае, программа выдала все те же 94%…
Онлайн сервисы антиплагиат
Подобных сервисов (сайтов) на самом деле десятки (если не сотни). Все они работают с разными параметрами проверки, с разными возможностями и условиями. Некоторые сервисы проверят для вас 5-10 текстов бесплатно, остальные тексты только за доплату…
В целом, я попытался собрать наиболее интересные сервисы, которыми пользуются большинство проверяющих.
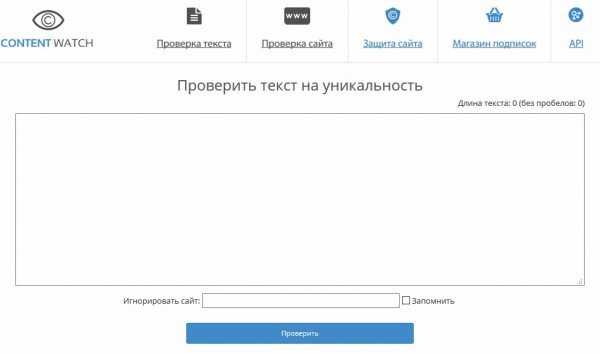
1) http://www.content-watch.ru/text/
Достаточно не плохой сервис, работает быстро. Текст проверил, буквально за 10-15 сек. Регистрироваться для проверки на сайте не нужно (удобно). При наборе текста показывает так же его длину (количество знаков). После проверки покажет уникальность текста и те адреса, где он нашел копии. Что еще очень удобно — возможность игнорирования какого-нибудь сайта при проверке (полезно, когда вы проверяете информацию, которую разместили на своем сайте, не скопировал ли ее кто-нибудь?!).
2) http://www.antiplagiat.ru/
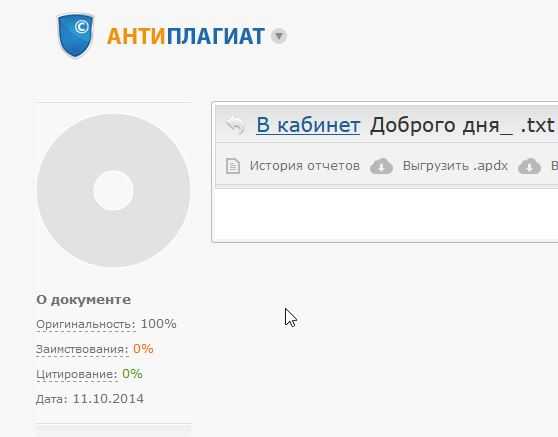
На этом сервисе для начала работ нужно зарегистрироваться (можно воспользоваться для входа регистрацией в какой-нибудь социальной сети: вконтакте, одноклассники, твиттер и пр.).
Проверять можно как простой текстовый файл (загрузив его на сайт), так и просто скопировав текст в окно. Довольно удобно. Проверка проходит достаточно быстро. К каждому тексту, который вы загрузили на сайт будет предоставлен отчет, выглядит он следующим образом (см. картинку ниже).
3) http://pr-cy.ru/unique/
Достаточно известный ресурс в сети. Позволяет не только проверить вашу статью на уникальность, но и найти сайты, на которых она опубликована (кроме того, можно указать сайты, которые не нужно учитывать при проверке, например тот, откуда скопировали данные текст 🙂 ).
Проверка, к слову, очень простая и быстрая. Регистрироваться не нужно, но и ждать от сервиса сверх информативности тоже не нужно. После проверки, появляется простое окно: в нем показан процент уникальности текста, а так же список адресов сайтов, где присутствует ваш текст. В общем-то, удобно.
4) http://text.ru/text_check
Бесплатная онлайн проверка текста, регистрироваться не нужно. Работает очень шустро, после проверки предоставляет отчет с процентом уникальности, числом знаков с проблемами и без них.
5) http://plagiarisma.ru/
Весьма добротный сервис проверки на плагиат. Работает с поисковыми системами Yahoo и Google (последняя доступна после регистрации). В этом есть свои плюсы и минусы…
Что касается непосредственно проверки — то здесь есть несколько вариантов: проверка простого текста (что самое актуальное для многих), проверка странички в интернете (например, вашего портала, блога), и проверка готового текстового файла (см. на скриншот ниже, красные стрелочки).
После проверки сервис выдает процент уникальности и список ресурсов, где найдены те или иные предложения из вашего текста. Из недостатков: сервис довольно-таки долго задумывается над большими текстами (с одной стороны хорошо — проверяет ресурс качественно, с другой — если у вас много текстов, боюсь, он вам не подойдет…).
На этом все. Если знаете еще интересные сервисы и программы для проверки на плагиат, буду весьма благодарен. Всем всего наилучшего!
pcpro100.info
Как обмануть антиплагиат ру и программу etxt

.
В нашей статье мы расскажем, как без труда обмануть Антиплагиат программу для систем проверки антиплагиат.ру и etxt. Если у Вас нет времени на изучение материала, рекомендуем сразу обмануть Антиплагиат — перейдите по ссылке.
Мы не будем разбирать в статье, как можно бесплатно и самостоятельно обойти проверку на Антиплагиат, т.к. на сегодняшний день очень сложно повысить уникальность текста, не испортив само содержание работы (речь идет про самостоятельные попытки студентом повысить оригинальность своей работы).
Наш сервис обходит систему проверки Антиплагиат.ру, ВУЗ и ETXT, не изменяя текст в документе. Т.е. преподаватель внешне не заметит разницы между обработанным и не обработанным документом. При этом, уникальность после обработки будет соответствовать Вашим требованиям. Технически кодируется сам документ, чтобы обмануть Антиплагиат и успешно пройти проверку на плагиат в Вашем учебном заведении.
В нашем сервисе предусмотрена бесплатная пробная страница, чтобы Вы убедились в успешности прохождения системы Антиплагиат. Достаточно добавить любой документ по этой ссылке — http://anfox.ru/Home/Order
Вам будет отправлена бесплатная страница в течение 24 часов (платная обработка происходит быстрее и занимает около 2-7 минут на весь документ). Если нет времени ждать бесплатную пробную страницу, напишите нам на [email protected] (укажите в теме письма, что хотите получить пробную страницу).
На скриншоте ниже показан пример проверки обработанной нами Дипломной работы по Антиплагиат.ру. Студент заказал повышение оригинальности дипломной работы до 90%. Система обработала текст до 91.76% (небольшой запас в большую сторону). Вы можете обмануть антиплагиат.ру до любого процента (от 5 до 100%).
.
Обмануть Антиплагиат.ру (перейдите по ссылке)
Если Вашу работу будут проверять в системе Антиплагиат ETXT (специальная программа), то наша система без труда обработает Ваш документ для обмана ETXT Антиплагиат. Ссылка на саму программу будет отправлена на Вашу эл. почту после обработки документа. Вы сможете самостоятельно проверить уникальность обработанного документа перед отправкой преподавателю (мы настоятельно рекомендуем всегда проверять обработанный документ, чтобы убедиться в высокой уникальности текста).
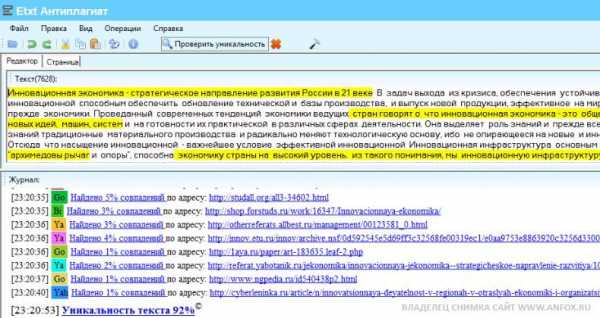
На скриншоте ниже показан пример проверки обработанной нами учебной работы для системы ETXT антиплагиат. Студент заказал повышение оригинальности текста до 90%. Система обработала текст до 92% (небольшая погрешность в большую сторону). Вы можете обмануть антиплагиат etxt до любого процента (от 5 до 100%).
.
Обмануть Антиплагиат ETXT (перейдите по ссылке)
.
Ниже мы приведем пример обработанного нами текста одной из учебных работ:
» Следует отметить, что система декларирования доходов и имущества государственных служащих еще не была реформирована. При этом внедрение системы всеобщего декларирование не решит проблем, которые остаются актуальными – в первую очередь, проведение проверки и обязательное опубликование сведений из деклараций высших и других должностных лиц, подверженных высокому риску коррупции.
В Казахстане работают положения Кодекса чести государственных служащих и введен институт советника по этике, что является позитивным. Проводилось регулярное обучение по вопросам этики и предотвращения коррупции; однако, детальные пособия для государственных служащих по применению положений о подарках и конфликте интересов не были разработаны.
Казахстан внес значительные изменения в законодательство о государственных закупках и внедрил отдельные элементы электронных закупок. Однако количество сфер, которые исключены из-под действия закона, не было сокращено значительно. Также пока что не принят закон о закупках национальных компаний и других подобных субъектов, хотя работа над законопроектом ведется.
В Республике Казахстан сегодня действует инновационное антикоррупционное законодательство, основой которого являются законы «О борьбе с коррупцией» и «О гос. службе». Закон «О гос. службе», определив статус, права и повинности муниципальных служащих, регламентировал возможности муниципальных органов. «
—
Если Вы решите проверить уникальность этого текста, то имейте ввиду, что поисковая система уже просканировала этот текст и уникальность может быть не высокой, т.к. текст уже размещен нами на нашем же сайте (можете просмотреть отчет проверки на плагиат, чтобы узнать куда ссылается система Антиплагиат).
Как Вы видите, текст визуально ничем не отличается от обычного текста из документа (без обработки). Наш метод обмана антиплагиата самый безопасный на сегодняшний день.
Остались вопросы? Напишите нам на [email protected]
anfox.ru
Anexp.ru | Антиплагиат экспресс — Программа повышения, проверка уникальности текста студенческих работ онлайн
Антиплагиат Экспресс – ваш верный помощник
Как раньше было легко и просто учиться! Нашел готовую курсовую или диплом в Интернете и готово, преподаватель ничего не узнает. Но те славные деньки давно прошли! Теперь каждый преподаватель обязательно проверяет работы на уникальность в сервисе Антиплагиат ру, системе Антиплагиат ВУЗ, программах ETXT и Advego. Они очень быстро распознают обман и курсовую (или диплом) не принимают.
Получается, что сами знания фактически уже не так важны, они отходят на второй план, а во главу угла ставится уникальность, которая практической пользы то и не несет. Она является лишь косвенным показателем, но преподаватели настолько обленились, что теперь для сдачи требуется полностью переработать текст. В результате, в нем теряется первоначальная мысль, он становится просто бесполезным, а то и вовсе неверным. Особенно остро это ощущается в таких тематиках, как юриспруденция, бухгалтерия, гуманитарных науках. Там, для повышения уникальности текста студенту приходится заменять определения и термины синонимами, которые очень сложно подобрать, а то и вовсе невозможно. Стоит ли заниматься таким бесполезным и неблагодарным занятием? Нужно ли идти на поводу у системы, подстраиваться под нее? Я думаю, что нет. Как же поступить в такой ситуации? Здесь, как и всегда в жизни, есть два совершенно разных пути.
Первый. Потратить несколько бессонных ночей на исправление и поднятие уникальности большого текста и при этом все равно не быть уверенным в результате? На самом деле, почти всегда найдется какой-нибудь достаточно длинный фрагмент, который будет неуникальным, это может быть цитата или устойчивое выражение, который никак не исправить. Преподаватель в таком случае на уступки не пойдет, а лишь посмотрит на итоговый результат, который его не устроит. Действительно, как можно сделать уникальным определение термина? Это будет банальная подмена понятий. Под запретом сразу становятся и цитаты, ведь они тоже неуникальны. Преподаватели настолько слепо доверяют од
anexp.ru
Антиплагиат документа онлайн
Проверка документа на уникальность требуется различным специалистам и студентам. Система Antiplagiat.ru предоставляет набор сервисов, которые дают возможность проверять любые тексты на схожесть с общедоступной информацией. Поверенный сайт, имеет отличную репутацию, платные услуги имеют вполне доступную стоимость. Многие учебные заведения используют для проверки студенческих работ именно этот сервис.
Документы, которые публикуются в сети интернет, различные студенческие работы, научные труды, требуют соответствия общепринятым нормам. Признание оригинальности материала говорит об авторских правах того, кто разработал тот или иной материал, будь то научные труды, литературное произведение, студенческие рефераты или курсовые. Огромный объем источников, которые имеются в сети интернет, дают возможность использовать чужой контент, выдавая его за свой. Проверка текста специальными программами позволяет определить степень заимствований материалов. Как происходит подготовка любого задания в Университете. После изучения новых книг по предмету, поисков нужных источников в Интернете, студенты излагают свои знания, иллюстрируя их таблицами, выдержками из нормативных документов, описывая статьи законодательства и т.д., в зависимости от предмета, по которому ведется подготовка задания. Каково разочарование, когда проверка показывает совсем не те результаты, на которые рассчитываешь.
Используя специальные программы можно в короткие сроки доработать любой документ до требуемых величин
Проведя много времени над подготовкой по теме задания, можно столкнуться с низкой уникальностью написанного текста. Это возникает по разным причинам:
- Использование цитат и крылатых выражений;
- Оперировать большим количеством специальных терминов и формулировок;
- Цитирование отдельных фрагментов нормативных документов, статей законов, других профессиональных знаний.
При подготовке текста по определенной тематике сложно достигнуть сто процентной уникальности, в этих случаях предъявляются разные требования. Используя специальные программы можно в относительно короткие сроки доработать любой документ до требуемых величин. На помощь готовы прийти специалисты, владевшие мастерством рерайта любого текста. При необходимости привлекаются специалисты из различных областей знаний – экономисты, юристы, инженеры, медики, строители и т.д.
Задача доведения текста документа до требуемого уровня, заключается в использование других слов с сохранением смысла материала. Достичь такого результата в техническом, бухгалтерском или медицинском документе можно только владея профессиональной терминологией. Изложение должно быть сухим, сдержанным, четко передавать смысл документа.
Подготовить любой документ, имеющий высокую степень уникальности, для профессионалов не представляет труда. Определенные навыки и знание алгоритмов работы программ дает возможность четко и быстро справляться с задачами любой сложности. Исправить документ так, чтобы он прошел проверку на антиплагиат, знают те, кто постоянно с этим сталкивается. Добиться требуемой оригинальности текста, сохранить смысл, уложиться в сроки подготовки при невысокой стоимости заказа готовы опытные специалисты, владеющие искусством рерайта.
Повысьте уникальность Вашего текста
3 шага · 1 минута · 6 ₽ за страницу
- Загружаете свой файл
- Мы обрабатываем файл и повышаем уникальность
- Скачиваете файл и проходите АНТИПЛАГИАТ
Загрузить мой файл сейчас
www.unitext24.ru