
Релевантность контента — Самая полная в Рунете энциклопедия интернет-маркетинга
Материал из Самая полная в Рунете энциклопедия интернет-маркетинга
Что такое релевантность контента
Релевантность контента — фактор, который оказывает самое сильное влияние на процесс построения выдачи поисковыми системами. Ранее для определения релевантности текста ПС учитывали только количество присутствующих в нём ключевых фраз, в точности соответствующих запросу. Причём при увеличении числа повторений повышалась позиция документа. Этой особенностью пользовались оптимизаторы. Раньше в ТОПе часто встречались нерелевантные страницы или документы с переспамленным контентом, который не только плохо читался, но и не был полезным для пользователей. В 2017 году при определении релевантности контента поисковые системы применяют сложные алгоритмы и учитывают множество факторов.
Основные критерии релевантности контента
Плотность и форма ключевых слов
Плотность ключевых слов — это частота употребления запроса в тексте. Оптимальный показатель, который удовлетворит как Яндекс, так и Google — 3–7 %. Если количество ключей превысит максимально допустимое значение, позиция документа будет понижена. «Переспамленные» тексты попадут под санкции. Материалы, в которых присутствуют только прямые вхождения запроса, не получат высокую релевантность. Поисковые системы посчитают такие тексты бесполезными. Используйте словоформы и разбивайте фразы, добавляя актуальные уточнения.
Естественность и полезность
Для повышения релевантности контента важно, чтобы вписанные запросы выглядели максимально естественно. Ключевые слова нужно равномерно распределить по тексту. контент страницы должен как можно более полно отвечать на вопрос пользователя. Статья, содержащая ненужную или неактуальную информацию, не будет высоко оценена поисковыми системами.
Релевантные заголовки и структурные блоки
Заголовки по возможности должны содержать ключевые слова и нужные уточнения, связанные с содержанием структурных блоков. для каждого иЗ них необходимо подобрать соответствующие ключи. К примеру, статья про установку забора из профнастила своими руками, в которой большинство запросов содержат «купить», «стоимость», «от производителя» и т. п., будет нерелевантной. Основной ключ желательно разместить как можно ближе к началу текста/структурного блока. Поисковые системы в выдаче отображают заголовок и часть размещенного под ним абзаца, выделяя слова, которые входят в запрос. Один из эффективных приёмов — структурирование контента. Оно включает создание содержания статьи (со ссылками) и написание цепляющих заголовков по которым пользователь захочет перейти. Используйте при структурировании теги h2-h4.
Выделение ключевых слов и важной информации
Поисковые системы обращают внимание на фразы, выделенные жирным шрифтом, курсивом и подчеркиванием. Переусердствовать не стоит. Это приведёт к понижению позиции страницы. Выделяют ключевые запросы только в важных структурных блоках. Для небольшой статьи (2–3 тыс. символов) одного-двух раз вполне достаточно. Естественность и полезность стоят на первом плане. Важную информацию можно оформить в виде цитат. Их присутствие положительно оценят поисковые системы.
Наличие полезного дополнительного контента
Релевантность текста значительно повысится, если разместить в нём полезные изображения и видеоматериалы. Картинки должны быть оптимизированы. Для этого используют теги ALT (описание) и TITLE (заголовок), а также добавляют актуальные подписи.
Заполненность мета-тегов страниц
Несмотря на то, что поисковые системы всё меньше обращают внимание на мета-теги, их заполнением не следует пренебрегать. Используйте короткие и ёмкие фразы, отражающие тематику контента. При написании description ориентируйтесь на структуру текста.
Читайте также другие статьи на тему «Релевантность»
Полезные ссылки
www.optimism.ru
Релевантность что это простыми словами. Релевантность запросов
Изучая заумный SEO талмуд вы часто встречаете понятие «релевантность» текста, страницы или сайта в целом. Релевантность что это простыми словами? Именно об этом и будет эта публикация, подробно разберем термин релевантность, рассмотрим примеры релевантной выдачи поисковых систем и как ее добиться.
Релевантность что это
Релевантность это соотношение поискового запроса к полученному результату выдачи. Простыми словами релевантность информации это то насколько контент (текст, картинки, видео) удовлетворяют ищущего в поиске пользователя.
Что такое релевантность поиска
Что бы понять что такое релевантность поиска давайте рассмотрим примеры на пальцах, простыми словами попытаемся разобраться.
Пример релевантной выдачи. Некий пользователь вводит запрос в поисковике: «Как печь пироги с яблоками». В итоге мы получим первую 10-ку сайтов с рецептами.
Возьмем первых 5 позиций, проанализируем снизу вверх (начнем с 5-й):
- На пятом месте мы увидим рецепт пирога, где будет описаны нужные ингредиенты, что зачем смешивать и как готовить, общая картинка готового пирога. В роди бы все отлично, но почему этот сайт «получил» только 60% релевантности (цифра с потолка для наглядности). Пойдем дальше и поймем в чем причина.
- На 4-й позиции все тот же рецепт что и в предыдущим примере, только добавлено несколько картинок в процессе приготовления. Статья получилась уже более информативной и она получит свои 70% релевантности.
- Поднимаемся выше. Все то же самое что и в предыдущем примере, плюс добавлено видео процесса приготовления злосчастного пирога. Процент пользователей довольных полученной информацией резко увеличиться. Свои 80% релевантности информации сайт получил не зря.
- На втором пункте находится рецепт с картинками, видео, подробным текстовым описанием и расположены ссылки на похожие рецепты, к примеру с добавлением груш или более дешевый вариант. Пользователь изучил материал, остался доволен и перешел на следующую страницу. Для поисковой системы это отличный сигнал. Этот сайт получает 90%.
- И наконец наш победитель, первое место в выдаче по релевантности информации. Полный набор контента (текст, картинки, видео, ссылки на похожие материалы), довольный пользователь. Но что же отделяет этого пользователя от предыдущего? А отделяет его правильно использованные ключевые слова, которые соответствуют поисковому запросу. К примеру в тайтле страницы, в тегах h2-h6, в тексте есть слова и словосочетания встречающиеся в запросе. Это называется внутренней релевантностью. Об это я расскажу чуть ниже.
Я думаю после этого примера вам стало ясно что такое релевантность страниц сайта и как ее определить. Мы определяли уровень релевантности наглядно, но ее можно вычислить и в реальных цифрах, сразу после того как разберем внутреннюю и внешнюю релевантность.
Внутренние критерии релевантности текста
Мы рассмотрели что такое релевантность в поиске, теперь давайте выведем основные тезисы, благодаря которым можно добиться высшей степени удовлетворения посетителя:
- Первый и основной момент, текст должен рассказать или показать то, о чем спрашивает пользователь в поисковой машины. Это самое главное.
- Присутствие ключевых слов в тексте, немаловажный пункт. Если ваш контент будет идеален но в нем не будет ни одного точного вхождения продвигаемого запроса шанс попадания в топ стремиться к нулю.
- Использование синонимов и словоформ ключевых слов.
- Плотность ключей. Это понятие доживает свой век, при хорошем контенте и правильной оптимизации достаточно и одного вхождения ключа. Тем не менее старайтесь не пичкать одни и те же слова рядом, это будет расценено как спам и не только понизит релевантность теста, а может и вовсе выбросить такую страницу с поиска.
- Место расположения ключевых слов. Это интересный вопрос, над ним так же бушует много споров. Все могут согласиться в одно. Главный ключ должен находиться в точной форме в первом абзаце текста, раз в средине и в самом конце. Этого будет вполне достаточно.
- Используйте ключевые фразы в тегах h2-h6, в дескрипшине и тайтле. Это придаст значительный вес вашей странице по данному запросу.
Это основные внутренние принципы, по которым определяется релевантность информации на страницах сайта.
Внешние критерии релевантности
К внешней релевантности относятся ссылки ведущие на сайт. Чем чаще на вашу страницу ссылаются тем лучше. Если страница, с которой поставлена ссылка, схожей ил
yrokiwp.ru
Релевантность 100% — секреты поисковой оптимизации

Одной из самых сложных тематик в seo принято считать «релевантность». Ведь все мы знаем, что значимость контента для поисковика всегда находилась, да и будет находиться на первом месте. Простыми словами, слово «релевантность» означает степень совпадения поискового запроса контенту, содержащемуся на странице.
Но что такое релевантность с точки зрения поисковых алгоритмов и как правильно выстроить свой собственный текст, чтобы создать максимально возможные перспективы для ТОПовых позиций, ответить сможет не каждый.
Я сразу отмечу, что в интернете опубликовано множество статей на данную тематику, ну и каждый мало-мальский блоггер (часто даже не имеющий отношения к seo) считает обязательным вставить свои «пять копеек» по поводу релевантности запросов.
Я постараюсь вам показать всю внутреннюю и внешнюю структуру релевантности и логику основного робота при обходе и определении степени совпадения.
Хорошим примером для seo-новичков и всех тех, кто по каким-то причинам желает создать релевантный контент для собственного сайта, будет являться Wikipedia. Так уж сложилось, что Яндекс и Google считают данный сайт чуть ли не эталоном релевантности запросов. Для этого есть обоснованная причина, но разбирать её мы не будем. Поверим на слово и будем придерживаться некоторых принципов этой большой энциклопедии.
Совет для новичков: забудьте слово «релевантность», пишите хорошие статьи с качественным полезным контентом. Публикуйте то, чего ещё нет на просторах интернета. Дополняйте и пополняйте базу знаний сети! И тогда о релевантности вам и думать не придётся: Вас будут ценить за вашу уникальность, неповторимость и исключительность!
Но если вы уж решили окунуться в «кашу» современного seo, то данная статья поможет вам понять логику обработки данных поисковиками.
Любой робот, каковым является алгоритм поиска, всегда и без исключения действует по определённому алгоритму: обрабатывает данные согласно условиям и заданным характеристикам. Любой математик скажет вам, что, имея формулы, получить ответ не составит труда. Наша с вами задача — приблизиться к той формуле, которая сокрыта в тайне «релевантности». А поможет нам в этом обычная и самая простая логика!
Как составить релевантный текст
В основе любого контента заложен текст. Именно текст является основополагающим фактором для определения релевантности. Любой текст состоит из символов (букв, знаков цифр и т.д.), поисковики же собирают данные символы в слова, чаще всего понимая, что то или иное отдельное слово значит. С помощью слов-синонимов, морфологических форм и речевых оборотов определяют более точное значение многозначных слов. На основе частоты использования слов в тексте формируют общее представление о смысловой нагрузке контента в целом и каждого отдельного абзаца в частности. Так формируется релевантность на первом этапе обработки алгоритма.
Принято считать, что контент обрабатывается поисковиками по трём принципам:
- Закон Ципфа. Принцип данного закона гласит, что слова в тексте используются пропорционально рангу ключевого слова. То есть n-количество раз используемых ключевых слов делится для каждого последующего на два, три, четыре и т.д.
- Принцип формирования шинглов. Релевантность в данном случае складывается из последовательности вхождения ключевиков в абзацы. За расчёт берётся условная единица в 250 знаков (количество знаков в сниппете).
- Принцип прогрессивно уменьшающейся значимости. Заключается в том, что каждое последующее слово имеет меньшую значимость для релевантности, чем предыдущее.
Целевым указанием роботу на принадлежность того или иного контента ключевому слову являются специальные указатели, которые помогают алгоритмам сформировать более целостное представление о степени совпадении слов и смысла.
Самым главным и самым важным из них является <title> — это прямой и самый короткий ответ на вопрос, освещенный в вашем материале. Заголовок должен содержать в себе точное и короткое предложение, максимально характеризующее ваш текст, и никак по-другому!
Очень часто составить качественно и правильно текст длиной в 70 символов не представляется возможным, поэтому горе-seoшники включают в title весь набор ключевых фраз. Для этого существует второй по значимости указатель, дополняющий <title> — это <description>. Значение данного поля измеряется 220 символами — достаточным количеством, чтобы дополнить ваш title поясняющим описанием!
Особые отношения у поисковиков сложились с внутренними заголовками страниц (<h2>, <h3> и <h4>). Они также являются указателями для определения смысла контента и качества релевантности. Считается, что:
<h2> — основной заголовок статьи, должен содержать ключевую фразу;
<h3> — дополнительный заголовок, должен содержать словоформы и склонения ключевых фраз, а также расширенные ключевые фразы;
<h4> — слова синонимы и дополнения к ключевым фразам.
Важное значение поисковики отдают плотности слов и фраз в тексте, ведь именно они являются ключевым фактором определения значимости слово по отношению к общему объему текста. Достаточно знать простое правило: текст — это не игрушка. Не нужно прикручивать и вставлять фразы в контент: лаконичность и простота фраз, разнообразие лексики и сложные красивые обороты не дадут вам использовать ключевые фразы больше дозволенного количества раз. Ну, а уж если ориентируетесь на конкретные цифры, то релевантность — это 2-3% ключевиков к общему объему текста!
К значимому дополнительному указателю можно отнести медиа-контент. По большей части это иллюстрации, изображения и картинки. Именно они дают дополнительные сигналы алгоритмам о составляющей релевантности. Причём данный фактор может играть как положительную роль, так и отрицательную!
Большинство из вас знает, что поисковики рекомендуют размещать на своих страницах уникальные картинки и иллюстрации к тексту, и это может понизить вашу релевантность! Алгоритмы поисковых роботов, анализирующих изображения, далеки от совершенства, а обработка изображений основывается на тексте, размещенным возле картинок. Как следствие, уникальная картинка, даже с указанием alt и title в описании, даёт маленькое представление о изображении, а следовательно, и на релевантность влияют слабо.
Существует целая схема того, как быстро дать поисковику понять, что изображено на картинке. В данном случае в работу включаются ссылки. Самый простой способ — распространить иллюстрацию с нужным релевантным описанием в социальных сетях (в первую очередь pinterest), фото-хостингах и на самих сервисах поисковиков (Яндекс.Фото и Google+). Но данный процесс займёт некоторое время, порой несколько месяцев!
Для усиления релевантности я рекомендую использовать заимствованные изображения с других сайтов, которые уже имеют значение в базе поисковиков. Найти их можно в поиске Яндекса или Google по ключевому слову. Такие изображения уже имеют смысловые значения и, как следствие, дополняют ваш контент значимостью. Поисковики в таких случаях требуют снабжать картинки ссылками на первоисточники, что позволяет дополнительно усилить релевантность. Ссылка с релевантной страницы на релевантную помогают в понимании смысла как первоисточника, так ссылающейся страницы.
Большой редкостью для сайтов является микроразметка, а ведь именно она указывает поисковым роботам на те или иные элементы контенты на сайте. Чего уж проще: вы сами можете управлять действиями алгоритма с помощью специальных тегов. Несомненно, страницы с микроразметкой обрабатываются с сотни раз быстрее, и, как следствие релевантность определяется гораздо эффективнее!
Многие блоггеры очень часто замечали, что после написания большего количества комментариев на странице позиции начинают двигаться в противоположную сторону от ТОПа. Причиной тому является большой объём неоптимизированного контента. Микроразметка исключит данные случаи и укажет на значимость тех или иных частей контента для seo. Так, для обычного блога становится понятно, что является основным контентом (текст статьи), что картинкой — с описанием, что — ссылкой с дополняющими материалами, что — комментариями, а что сайдбаром. Таким образом вы показываете поисковому роботу, какой контент важен для релевантности, а какой учитывать ни в коем случае нельзя.
Последний важным фактором, влияющим на релевантность, являются ссылки. И не важно, какого формата: закрытые или открытые, ссылки с анкором или безанкорные. Даже ссылки на картинки несут значимость!
В формирование релевантности участвуют как исходящие ссылки, так и входящие.
К исходящим ссылкам можно отнести прямые релевантные запросы (чаще всего исходящие внешние), либо околорелевантные запросы (входящие внутренние) — похожие статьи, тематические материалы. Так, с помощью одной единственной ссылки с wikipedia можно получить 100% релевантность вашего запроса, либо же с помощью определенного количества входящих внешних и внутренних улучшить её.
Одним из самых эффективных способов улучшения релевантности является статейное продвижение, когда внешние ссылки проставляются с релевантных страниц. В данном случае даже общая тематика сайта-донора не играет роли. Ведь каждая страница на сайте рассматривается отдельно. Ярким примером могут послужить новостной портал, где тематика страниц может быть разнообразной, но тем не менее поисковики прекрасно понимают их значения!
Всё остальные средства, такие как: выделения контента, ключевые слова в url, meta keywords т.д. играют малозначимую роль и не стоят внимания.
Стоит отдельно заметить: meta keywords всё же является неким указателем, точнее, подсказкой, которая указывает на поисковые запросы, однако данный мета-тэг не влияет на релевантность.
Применяя данные методы на практике, вы сможете указывать поисковым алгоритмам правильное направление: направление на 100%-ную релевантность ваших страниц! Но не забывайте тот совет, которой я дал новичкам в начале статьи: полезный контент всегда важнее алгоритмов. Не засоряйте поисковую выдачу, если не уверены в качестве собственного контента. Возможно его стоит просто проработать и переписать?
marseo.ru
это эффективный! Всё, что вы хотели знать про релевантный контент
Говоря о поисковых системах, специалисты очень часто обращаются к термину «релевантность». На уровне интуиции его значение понятно каждому.
По сути своей, релевантность – это то, насколько определённый документ или текст соответствует запросу пользователя. Грубо говоря, чем точнее контент отвечает на вопрос пользователя, тем выше уровень его релевантности по этому запросу.
Как это работает?
Чем отличается от нерелевантного результата релевантный? Это проще всего понять, рассмотрев простой жизненный пример.
Итак, вы — школьник или студент, которому задали написать реферат по определённой теме. Мало кто в наши дни тратит часы в библиотеке для поиска и анализа всей информации. Ведь намного проще подыскать подходящую работу в сети, возможно – немного переиначить её и выдать за результат своего труда. Оставим вопросы морали в стороне и посмотрим на это с другой точки зрения.
Что вам нужно найти прежде всего? Абсолютно верно: сайт, на котором публикуются готовые рефераты. Вы открываете страницу поисковой системы (будь то Google, Яндекс или любая другая) и вводите в строке поиска слово «рефераты». Поисковая система моментально просматривает базу проиндексированных страниц и обнаруживает в ней ссылки примерно на 8 млн. различных страниц, на которых нужное нам слово в общей суммарности встречается 30 млн раз.
Следует отметить, что поисковик находит это слово как на странице сайта «Банк рефератов», так и в Твиттере неизвестной нам Кати, которая «всю ночь писала реферат и хочет спать».
Вот тут и включается понятие «релевантный». Это значит, что поисковая система определяет, какая ссылка с большей вероятностью может заинтересовать пользователя. Именно поэтому ссылку на «Банк рефератов» мы видим уже на первой странице (она лучше соответствует запросу), а одинокий пост в Твиттере, посвященный жизненным перипетиям Кати остаётся где-то на …-дцатых страницах, хотя слово «реферат» в нём также присутствует.
Теперь, когда вы получили общее представление о том, что такое релевантность и релевантный поиск, можно перейти к более интересным моментам.
Зачем вашему сайту нужен релевантный материал?

Конечно, современные поисковые системы несовершенны и, прибегнув к определённым хитростям, можно продвинуть по определённому запросу даже нерелевантные страницы. На практике вы, скорее всего, не раз с этим сталкивались: например, вы искали результаты по запросу «купить стиральную машину», а поисковик направил вас на страницу, где расписана история создания данного агрегата.
Что вы делаете в такой ситуации? Закрываете сайт и продолжаете искать дальше.
Если ваши статьи будут нерелевантными относительно тех или иных ключевых запросов, посетители вашего ресурса тоже не задержатся на нём.
Вдобавок к этому, присутствие релевантного контента на странице значительно ускоряет её продвижение и способствует повышению позиций в общем рейтинге.
Фактически, благодаря ему вы увеличиваете трафик сайта, создаете позитивную репутацию для своего ресурса и, как следствие, повышаете уровень своего дохода.
Самые эффективные советы по созданию релевантных страниц для вашего сайта!
Прежде всего нужно определить ключевые запросы, которые подходят для выбранной странички сайта. Чем точнее они будут – тем лучше. То есть, если речь идёт о страничке интернет-магазина, на которой можно заказать чайник, логичнее продвигать её по соответствующим запросам. Например: «купить чайник», «интернет-магазин чайников» и т. д. Конечно, вы не соврёте своим посетителям, если используете фразы типа «кухонные принадлежности» или «купить кухонную утварь». Но тогда, помимо ваших потенциальных клиентов, которые действительно желают обзавестись новым чайником, на сайт перейдут и люди, которым он, мягко говоря, вообще не нужен.
Так как же создать по-настоящему эффективный, максимально релевантный контент?
1. Составьте грамотный title. В данный тег заключается название страницы. Оно должно быть как можно более ярким, оригинальным и точно описывать информацию, представленную на самой страничке. Для этого в title должно присутствовать ваше главное ключевое слово.
Пример: если вы продвигаете страницу по запросу «индийский чай», то title может выглядеть примерно следующим образом: «История индийского чая», «Купить самый вкусный индийский чай со скидками» и т. д., в зависимости от основного материала.
Помните, что важно сохранить естественную формулировку и не гнаться за точным вхождением КС.
2. Пропишите keywords. Это – отдельный пункт в коде страницы, указывающий на то, по каким запросам её нужно продвигать, этакий «маячок» для поисковиков. Не нужно увлекаться и выписывать десятки слов, фраз и их сочетаний: оптимальное количество ключевых слов – от 3 до 5.

3. Придумайте description. Description – это краткое описание страницы, которое выполняет сразу 2 функции: способствует более эффективному поисковому продвижению и показывает пользователям, о чём говорится в статье. Существует несколько «золотых правил» составления таких описаний:
- желательно, чтобы весь description состоял из 2-х предложений;
- в начале первого предложения, а также в середине или конце второго можно вставить ключевое слово;
- если употребить в точном виде не получается, можно морфологически изменить их.
Главное здесь, как и во всём процессе создания релевантного контента – естественность.
4. Заголовки и подзаголовки. Не стоит пренебрегать ими. Во-первых, структурированная статья смотрится намного лучше и легче читается. Во-вторых, включая в теги h2, h3, h4 основные и дополнительные релевантные фразы, можно сделать правильные акценты и улучшить позиции страницы в поисковиках.
5. Используйте картинки! Иллюстрированный материал всегда более релевантный. Это значит, что из двух сходных по тематике и объему статей, к одной из которых будут прикреплены тематические изображения, последняя имеет больше шансов оказаться в ТОПе поисковика. Для того чтобы добиться этого, нужно прописывать описание каждой картинки (атрибут alt). В нём также желательно использовать выбранные ключевые запросы.
Учтите, что если на странице есть несколько картинок, описания alt не должны быть одинаковыми!
Соблюдая все эти рекомендации, вы сможете создавать по-настоящему релевантный контент, который будет интересен людям и «придется по душе» поисковым ботам.
Поговорим о «начинке» текста
Здесь всё просто. Текст должен соответствовать тематике ключевых запросов и самой страницы. Кроме того, имеет значение его информативность. Прочитав его, посетитель должен почерпнуть для себя какую-то полезную информацию, найти ответы на волнующие его вопросы. Только в этом случае к тексту можно применить слово «релевантный».
Это касается именно «человеческого» лица вашего материала. Но есть и другая сторона, ведь наша цель – понравиться не только пользователям, но и поисковикам.
Здесь имеет значение гармоничное вхождение ключевых фраз (как в точном, так и в склонённом виде). Для большей весомости их рекомендуется заключать в тег.
Ваша статья не должна быть ни слишком короткой (менее 400 слов), ни слишком длинной (более 2000 слов). Хотя основной упор следует делать именно на информативности. Если вы сумели осветить весь вопрос в 1500 символах, не следует «лить воду», чтобы довести объем текста до нужных размеров.

Как узнать релевантность страницы?
Большинство отечественных SEO-мастеров пользуются удобным сервисом MegaIndex. Он позволяет не только узнать релевантность страницы в процентном соотношении, но и получить множество дополнительной полезной информации. Например, с его помощью вы узнаете о том, что негативно сказывается на уровне релевантности странички и что нужно исправить, чтобы сделать её привлекательней для пользователей и ботов.
fb.ru
Как измерить релевантность контента / Rookee.ru corporate blog / Habr
Оценка контента одна из главных составляющих формулы релевантности. Знание текстовых признаков и вклад каждого из них в оценку сайта позволит приблизиться к более профессиональной работе с ресурсом. В данной статье будет рассмотрена модель, позволяющая восстановить формулу ранжирования по каждому конкретному запросу, указана значимость определение тематики сайта при продвижении по определенному запросу, а также проработан вопрос, связанного с определением неестественного текста.Восстановление формулы ранжирования
Если переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.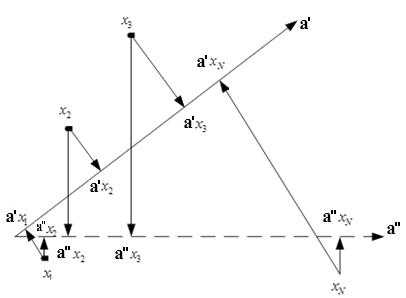
Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
, где — решение стандартной задачи квадратичного программирования при линейных ограничениях: , где
— симметричная матрица
— вектор коэффициента
— разница векторов характеристик
Данный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Таблица 1. Результаты сокращенной модели
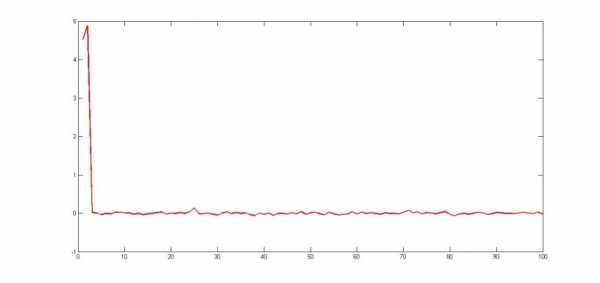
Рис. 2. Восстановленные коэффициенты регрессии при n=100 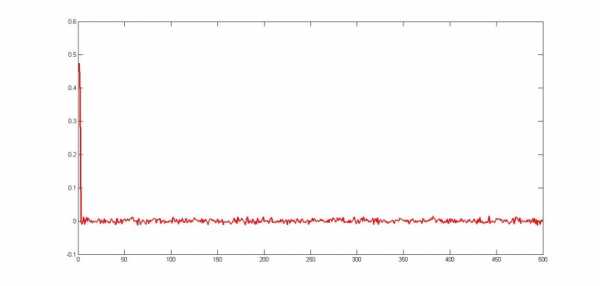
Рис. 3. Восстановленные коэффициенты регрессии при n=500
Если говорить о результатах на конкретных запросах, то проведенные эксперименты дают следующий показатель ошибка
Таблица 2. Ошибки вычислений
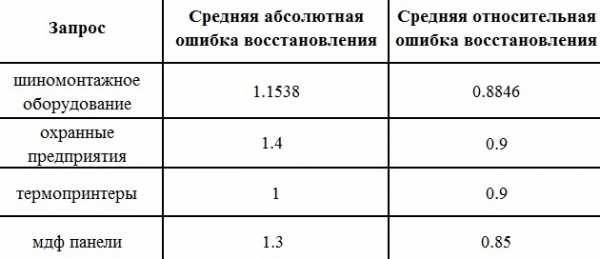
При работе над проектом данный подход использовался для прогнозирования позиций при конкретном изменении на сайте. Подобные эксперименты проводились на базе текстовых признаков. Первоначально были собраны данные по сайтам из ТОП20 по рассматриваемому запросу, затем данные подвергались стандартизации с помощью соответствующего алгоритма. После чего выполнялся алгоритм непосредственно по вычислению «релевантности» с помощью метода квадратичного программирования.
Полученные значения релевантности сайта сортируются и делается вывод о восстановленных позициях.
Таблица 3. Восстановление позиций
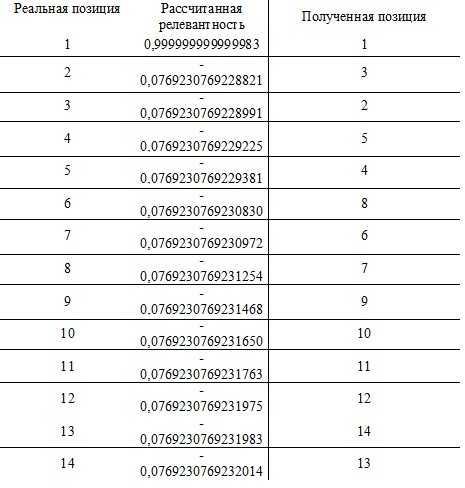
Было выявлено, что наибольшее влияние на позиции при ранжировании запроса «шиномонтажное оборудование» вносят признаки: наличие в Яндекс каталоге, вхождение первого слова из запроса «шиномонтажное», вхождение в h2 первого слова запроса «шиномонтажное», вхождение в title страницы второго слова запроса «оборудование».
Были произведены соответствующие корректировки в параметрах сайта и запущена программа. В результате был дан прогноз на соответствующую позицию.
Рис. 4. Программа, восстанавливающая формулу ранжирования
На сайте были произведены все эти изменения, после очередного апдейта сайт занял позиции, близкие к прогнозируемым. Первоначальная позиция была 50, после указанных изменений она составила ТОП20.
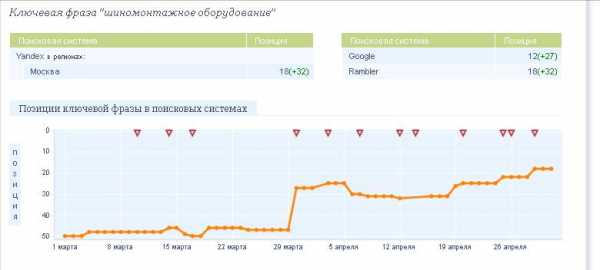
Рис.5. Результаты продвижения запроса «шиномонтажное оборудование»
Измерение тематики текста
В работе с восстановлением формулы ранжирования была подтверждена значимость измерения тематической близости тематики текста по отношению к тематике всего сайта. Подобную метрику можно построить на базе расчета косинуса между векторами соответствующих тематики страницы, релевантной запросу, и всего сайта: (2)
где и соответственно обозначение вектора тематичности сайта и рассматриваемого документа.
N – число слов в словаре коллекции. Вес каждого слова j в документе Di рассчитывается по формуле:(3)
где countij – число вхождений слова в документ, IDFwj — обратная частота слова в коллекции. После расчета веса каждого слова в документе, вектор нормируется:(4)
Аналогичным образом строится вектор и для всего сайта, при этом текст сайта получается объединением текстов всех входящих в него документов.
Таким образом, алгоритм определения тематической ценности документа можно представить в следующем виде:
1) Определяется словарь, в котором отсутствуют редкие и стоп-слова, т.е. IDF слов, формирующих словарь, лежит в диапазоне значимых слов.
2) Строится N-мерный вектор тематичности для рассматриваемого документа , используя формулы 3 и 4.
3) Строится N-мерный вектор тематичности для всего сайта , используя формулы 3 и 4.
4) С помощью (2) устанавливается близость векторов и . Чем ближе вектора, тем тематическая ценность документа выше.
На основе данной модели была написана программа, позволяющая определить тематическую схожесть рассматриваемого документа и текстовой составляющей самого сайта. Эксперименты проводились на базе 3 групп сайтов: с одинаковой тематикой, с близкой тематикой, с разной тематикой. Всего было обработано 200 статей. В результате обработки были получены следующие данные по 20 группам «1 тестовый документ / 9 обучающих документов», представленные в таблице.
Таблица 4. Результаты проверки тематической полноты
Из таблицы видно, что предложенный метод определения тематической полноты информационного ресурса работает на практике: проверяемые документы, расположенные на сайтах с более полно раскрывающейся тематикой, имеют более высокие показатели. Однако были выявлены и недочеты разработанной системы. Во-первых, на сайтах часто находятся неинформативные или малоинформативные страницы (формы заказов, обратной связи, контакты и т.п.). Во-вторых, при выборе случайно заданного количества обучающих текстов можно отобрать нетематические страницы. В-третьих, в качестве тестовых текстов могут попасться неспецифический контент, но близкие по тематике, например – правописание того или иного слова. В-четвертых, существуют сайты, которые охватывают разные тематические направления, при этом пересекающихся по смыслу (интернет-магазины, новостные сайты, банки рефератов).
При перечисленных недочетах общая картина позволяет оценить тематическую полноту ресурса. В качестве примера рассмотрим сайт тематики «логистика» с запросами, касающимися оборудования (на сайте присутствует каталог, помимо информации о логистике). Сайт зарегистрирован в Яндекс.Каталоге и имеет рубрику «экспедирование и перевозка грузов»:
Рис. 6. Рубрика, присвоенная в Каталоге.Яндекса
При использовании рассмотренного выше метода был сделан вывод, что тематическая полнота продвигаемых страниц не полная по отношению к запросам тематики «перевозка и доставка из Китая», но достаточная большая по отношению к тематике «оборудование». Соотношение страниц «логистика: оборудование» составляло соответственно «30:200». Соответственно, и позиции, и трафик был лишь у запросов, связанных с оборудованием. При этом приоритетна была «логистика». Для решения проблемы было написано письмо в Яндекс с целью получения развернутой информации. Однако был получен стандартный ответ «Платона» об улучшении и развитии сайта, но в целом все в порядке.
В качестве решения стоял выбор между развитием требуемой тематике на сайте и разнесением двух тематик на разные поддомены. Выиграла необходимость получить быстрый результат. Были составлены ТЗ на перенос направления «оборудование» на поддомен, а на основном сайте сохранена информация по «логистике», а так же на развитие ресурса путем добавления новых релевантных тематике страниц. Результат изменений представлен на рис. Запросы по оборудованию успешно перешли на поддомен и заняли положительные позиции. А после добавления тематических страниц по логистике и запросы по перевозкам, стали показывать положительную динамику.
Рис. 6. Результаты продвижения, после разведения тематик
Таким образом, за счет схемы «поддомен + домен» получилось без потерь разнести тематики и за счет этого повысить релевантность каждой из тематик по-отдельности и добиться положительную динамику по запросам.
Измерение естественности текста
Требования попадания в Яндекс.Каталог ужесточаются. В последнее время приходится сталкиваться с тем, что при проверки сайта, сотрудники яндекса сообщают о некачественном контенте. Выявить данный факт вручную на большом сайте представляется проблемой. Поэтому в настоящий момент ведутся работы по анализу признаков данных текстов. Расскажу о некоторых из них. Можно выделить два основных подхода в получении спам-текста: замена русских букв латинскими и генерация контента, лишенного смысла.
Первый подход вскрывается путем выявления измененных слов с помощью инвертированной частоты и сравнением с установленной эмпирическим путем критической величиной. Слова, образованные заменой русских букв аналогичными латинскими, являются редкими словами с точки зрения статистики употребления. С помощью инвертированной частоты по общей коллекции можно выявить такие слова. Каждому элементу текстового узла , ставится в соответствие значение с помощью функции инвертированной частоты fh:(5)
В качестве функции инвертированной частоты были рассмотрены:(6), (7), (8).
Здесь D – число документов в коллекции, DF – количество документов, в которых встречается лемма, CF – число вхождений леммы в коллекцию, TotalLemms – общее число вхождений всех лемм в коллекции. Из этих вариантов лучший результат в эксперименте, также как и в исследовании Гулина А. показал ICF (7), поэтому где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве.
Чем больше значение функции fh, тем реже слово встречается. Для получения интервала ICF значимых слов была написана программа, на вход которой подавались тексты различного содержания (устранение тематического влияния). Программа обработала порядка 500 МБ текстовой информации. В результате обработки был получен словарь обратных частот слов ICF в нормальной форме. Лемматизация слов была осуществлена с помощью парсера mystem, компании Яндекс. Все элементы словаря были отсортированы в порядке увеличения обратной частоты. В результате анализа данного словаря был получен интервал значимых слов: [500; 191703].
Для установления критерия выявления спам-текстов, также вводится критическая величина Hкрит и производится подсчет Hp процента слов, чья характеристика превышает установленную эмпирическим путем критическую величину Hкрит :(9)
В качестве критической отметки используется процент незначащих слов – 50% (наибольший показатель частоты служебных слов — 37.60%, а придуманных слов автором в среднем — 5.63%). Большой процент употребления в одном тексте таких словообразований Hp будет свидетельствовать о том, что документ является сгенерированным.
Однако сайтов с такими спам-текстами достаточно мало. Второй подход более распространен. Существует класс неестественных текстов, порожденных с помощью генераторов на основе цепей Маркова. На основе исследований Павлова А.С. была предложена модель, позволяющая выявлять такие тексты.
Вся текстовая составляющая B документа D имеет ряд признаков , трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом: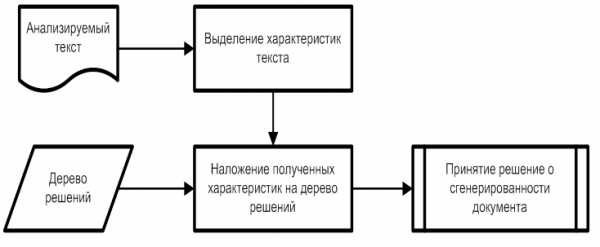
Рис. 7. Алгоритм определения сгенерированного контента
Для получения дерева решений была подготовлена база естественных текстов в размере 2000 и база неестественных текстов объемом также 2000, часть найдена в интернете, часть сгенерирована, остальные получены путем синонимизации документов-образцов или путем перевода с иностранных языков. Исходной коллекцией стала коллекция ROMIP By.Web. Инструменты генерации и синонимизации были найдены в интернете (TextoGEN, Generating The Web 2.2, SeoGenerator и другие).
Полученный набор текстов делился на две равные части. Первая группа использовалась в качестве обучающей выборки, а вторая часть – тестовый набор. Обе выборки имели равное количество документов-образцов и порожденных текстов.
Для процесса обучения была написана программа, которая по каждому тексту строила вектор, оценивающий параметры, влияющие на определение естественности текста. Согласно исследованию Павлова А.С. наибольший вклад в обучение вносит список параметров, определяющих текстовое разнообразие и частоту использования частей речи. В таблице представлен список наиболее ценных признаков для классификации русскоязычных текстов, для каждого признака указана F-мера и тип признака.
Таблица 5. Наиболее ценные признаки для классификации текстов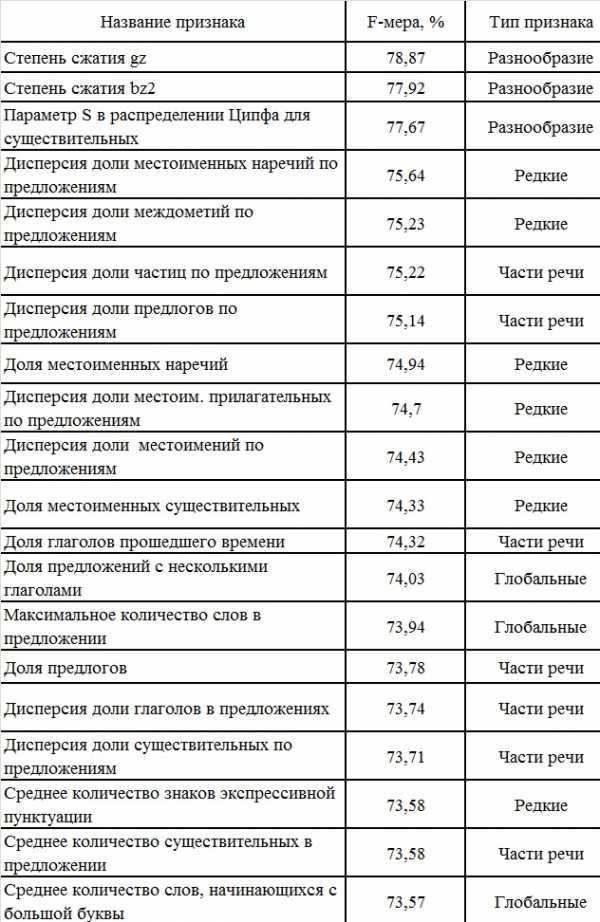
По полученным векторам P каждого из документа D строилось дерево решений. Данная процедура проводилась с помощью аналитической платформы Deductor Studio Academic версии 5.2. В Deductor в основе обработчика «Дерево решений» лежит модифицированный алгоритм C4.5, решающий задачи классификации. В результате было построено дерево со 157 узлами и 79 правилами. На рис. представлена часть полученного дерева. Полученные правила использовались в основной программе при определении спам-текстов сайта.
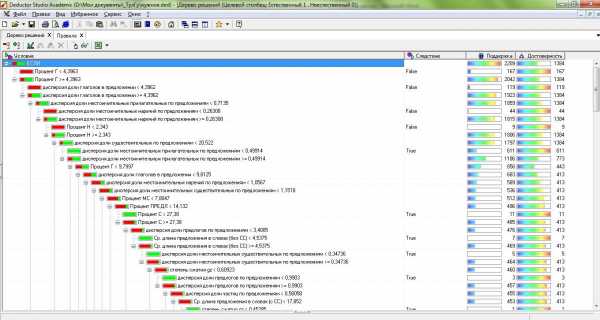
Рис. 8. Дерево решений. Аналитическая платформа Deductor 5.2.

Рис. 9. Результат работы программы по анализу текстов
На практике данный подход помог обнаружить причину отсутствия динамики по запросам. Программа обнаружила сгенерированные тексты на всех страницах категорий сайта. При расследовании было выяснено, что они представляют контент машинного перевода этого же сайта, но английской версии.
Рис. 10. Тексты на страницах категорий
После редактирования данных текстов даже только на продвигаемых страницах, была получена хорошая динамику: запросы из ТОП500 сразу попали в ТОП10 за 9 недель.
Рис. 11. Пример измененного текста.
Рис. 12. Изменение позиций по неделям после выкладки.
В заключение необходимо отметить, что разработка рассмотренных функционалов — не обязательна! Она полезна при глобальных исследованиях поисковых машин. При продвижении сайта достаточно выработать подход, позволяющий точечно работать с запросами на основе анализа ТОПа. Для этого существует много естественных инструментов:
1) Проверьте, сколько по запросу релевантных страниц на сайте и сравните с конкурентами – сможете оценить текстовую полноту сайта
2) Обратите внимание на подсвеченные слова в многословных запросам в сохраненной копии – помощь при составлении текстов, на сколько далеко могут стоять друг от друга слова
3) Используйте язык запросов. Например, анализируя выдачу по точному запросу и без кавычек, можно выявить проблемы с текстовой составляющей
4) Через расширенный поиск ищите запрос по конкретным сайтам и анализируйте, какие страницы и почему выше продвигаемой
5) Результаты Вебмастера.Яндекса и Вебмастера.Гугл, данные метрики и GA также помогут выявить проблемы и провести работу с ними.
Целенаправленная деятельность по запросам всегда дает положительный результат.
Авторы статьи: Неелова Н.В. (к.т.н., руководитель отдела ПП Ingate), Поленова Е.А. (руководитель группы ПП Ingate).
habr.com
поиск тем и оптимизация текста
Сегодня конкуренция в онлайн-бизнесе больше, чем когда-либо прежде. Любой может создавать сайт и продвигать его в поиске. Единственным реальным отличием между сайтами сегодня является их содержание — контент. По сути, именно это и будет выделять вашу площадку среди тысяч конкурентов.
Поскольку вы хотите привлекать целевой трафик, необходимо убедиться, что ваш сайт занимает высокие позиции в Google и Яндекс именно по тем ключевым запросам, которые обеспечивают продажи.
Почему релевантный контент так важен
У вашего бизнеса много задач, а создание контента требует времени, денег и ресурсов, которые не следует растрачивать впустую.
Это означает, что каждый вид контента (видео, блог, инфографика, социальный пост и т. д.) должен быть создан с определенной цель и ориентирован на потребности ваших клиентов.
Контент, который соответствует потребностям клиентов, имеет массу преимуществ:
- Он отвечает на конкретные вопросы и удовлетворяет потребности ваших клиентов.
- Он уменьшает количество отказов, так как ваши читатели, заходя на сайт, видят именно то, что искали.
- Он улучшает поведенческие факторы. Посетители будут дольше находится на сайте с релевантным контентом и чаще просматривать его.
- Он увеличивает ваше присутствие в социальных сетях. Люди часто делятся полезным контентом в соцсетях.
- Он повысит ваши позиции в поисковой выдаче.
- Он привлечет целевой трафик.
YouTube поможет создать полезный контент и продвинуть его
Хороший релевантный контент в идеале должен содержать видео. При этом не стоит забывать, что видеоролики можно продвигать не только как часть вашего сайта, но и на Ютубе.
На самом деле, YouTube — это вполне самостоятельный маркетинговый инструмент. Вы можете привлекать трафик и повышать продажи, просто размещая качественное видео и правильно продвигая его.
Если говорить вкратце, то для продвижения в Ютубе важно:
- Помнить, что ключи для YouTube и ключи для поиска Гугл будут сильно отличаться. Используйте аналитику Ютуб канала и специальные сервисы анализа каналов конкурентов для поиска нужных ключевых слов.
- Подобрать оптимальную длительность видео конкретно для вашей аудитории. Вам нужно найти баланс между фактическим временем просмотра видео и глубиной просмотра (процент от общей продолжительности ролика). Для ранжирования важны оба показателя.
- Сделать ставку на первые 15 секунд. Это самый важный отрезок видео.
- Побуждать пользователей ставить лайки и писать комментарии.
- Отвечать на комментарии, хотя бы на некоторые.
- Включать ключевые запросы в Title, Description и что, не менее важно, в само видео. Да, Ютуб умеет понимать то, что вы говорите в своем ролике.
- Делать привлекательные превьюшки. Помните — люди кликают в первую очередь по картинкам, которые видят.
- Создавать яркие заголовки.
Как сделать контент для целевой аудитории
Основная цель Google — как можно быстрее предоставить пользователю результаты, которые максимально отвечают на его запрос.
Поэтому Google делает все возможное, чтобы найти необходимую информацию конкретному человеку в нужное время.
Всегда думайте о потребностях ваших клиентов. Вот несколько примеров того, что люди на самом деле ищут в Google.
Релевантность и трастовость
Хотя есть много составляющих, которые следует учитывать при SEO-оптимизации, можно выделить два основных фактора при просмотре веб-сайта:
- авторитет;
- релевантность.
Эти компоненты одинаково важны, поскольку каждый из них способствует успеху другого.
- Релевантность помогает Google оценивать конкретные поисковые запросы и то, насколько точно контент отвечает на них.
- Авторитет дает основание Google доверять вашему сайту, что повышает позиции в результатах поиска и увеличивает трафик.
Оба эти фактора совершенно разные и измеряются по-разному, но, в конце-концов, каждый из них влияет на позицию сайта в органическом поиске. И в обоих случаях ключевым моментом является создание релевантного контента, поскольку от него зависит и авторитет, и релевантность сайта.
Как подбирать ключевые запросы
Сбор ключевых запросов для SEO — отправная точка. Поисковая выдача происходит на основании запроса, который ввел пользователь. Соответственно создавать контент необходимо именно под те темы, которые волнуют ваших потенциальных клиентов.
Какие бывают ключи
Для начала немного поговорим о классификации поисковых запросов. Есть несколько признаков, по которым их группируют. Самые важные, пожалуй:
- тип запроса;
- частотность;
- конкурентность.
Выделяют следующие типы ключевых слов:
- Общие. Как правило — это 1 или два слова, которые характеризуют какую-либо широкую тему. Например: платье, недвижимость и т.д. Такие ключи не дадут высокой конверсии, они не целевые.
- Информационные. По таким запросам ищут информацию: как поклеить обои и т.д. Естественно, что продаж от них почти нет. Но можно заманивать холодных клиентов с помощью блогов, новостей и всевозможных «сделай сам». Такие посетители способны в дальнейшем сделать у вас заказ.
- Транзакционные. Самые конвертируемые запросы: купить авто, сделать страховку и т.д.
- Навигационные — это поиск конкретного бренда, сервиса, услуги. Пример: Сбербанк, Лентач, Фейсбук и т.д.
- Мультимедийные запросы — это поиск музыки, видео, изображений.
По частотности ключи делят на:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Никаких четких критериев по частоте слова для этих групп нет. Но, как правило, ВЧ считаются запросы с частотностью от 5000 показов в месяц.
Также важно понимать, насколько большая конкуренция вас ожидает в случае продвижения по конкретному запросу. Как правило, высокочастотники стоят дороже, но это не всегда действует. Многое зависит от тематики.
В некоторых нишах низкоконкурентных запросов практически нет. Там борьба идет даже за совсем маленький трафик.
Определить конкуренцию можно:
- На глазок. Посмотреть, сколько результатов в поисковой выдаче и сколько рекламных блоков контекстной рекламы.
- Если собрать данные с помощью специальных сервисов и программ, например Key Collector.
Пожалуй, лучше всего о цене ключа говорят данные о стоимости контекстной рекламы. В России чаще всего пользуются статистикой Яндекс.Директ.
Как собирать ключи
По-большому счету, есть 2 способа сбора семантического ядра:
- вручную;
- автоматически.
Вручную ключи можно собрать с помощью планировщика ключей Гугл и Вордстата от Яндекса.
Оба сервиса довольно просты. Вы вводите интересующий вас базовый запрос (самый общий), а система показывает вам, что еще по данной теме искали пользователи.
Автоматически собрать семантическое ядро вам помогут многочисленные специализированные сервисы. Как правило, они подбирают ключи:
- анализируя трафик конкурентов;
- собирая информацию из тех же Вордстат и планировщика Гугл.
Сбор и кластеризация семантического ядра — тема необъятная. В любом случае, уделите этому этапу SEO максимум внимания. Без него вы никуда не продвинитесь.
Как создать релевантный контент с помощью SEMrush
Есть много инструментов, которые помогут оптимизировать контент так, чтобы он стал релевантным запросам ваших посетителей. Но одним из лучших многие профессиональные сео-специалисты считают SEMrush.
Предположим, что у нас есть зоосалон, который занимается грумингом. Нам нужно наполнить свой сайт статьями, которые будут интересны клиентам и ответят на их вопросы.
Прежде всего необходимо зайти в SEMrush и ввести нашу идею в инструмент исследования темы. Вы можете добавить самый общий ключевой запрос, например груминг животных или же указать сайт конкурента, и система проанализирует его.

SEMrush Topic Research предоставит нам длинный список потенциальных тем, которые мы можем использовать для создания контента.
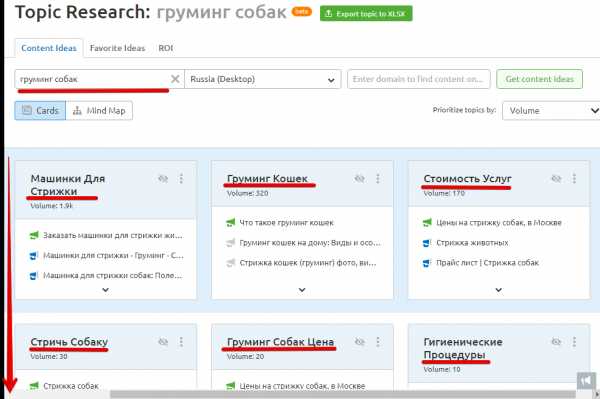
В этом примере давайте выберем тему «груминг кошек».
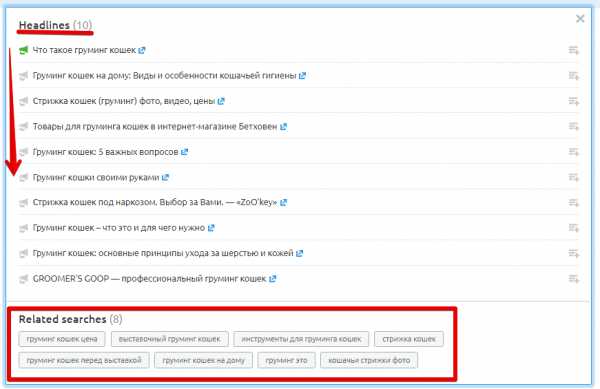
В раскрывшемся окне мы увидим список статей со схожей тематикой. Их можно использовать:
- как источник для написания контента;
- для того чтобы получить представление о темах, которые можно затронуть в своей статье.
Также внизу окна будут указаны наиболее популярные поисковые запросы.
Теперь, когда у нас есть эта информация, давайте посмотрим, как мы можем использовать ее для улучшения контента.
Заголовки, которые привлекают трафик
Заголовок — самая важная часть любого контента, который вы создаете. Это первое, что ваши читатели увидят в результатах поиска Google, поэтому, если хотите, чтобы клиенты открывали ваши страницы, заголовок должен заставить их перейти по ссылке.
Один из способов создать отличный заголовок — получить идеи из ТОП-выдачи по данному поисковому запросу. Мы можем сделать это в инструменте SEMrush Topic Research.
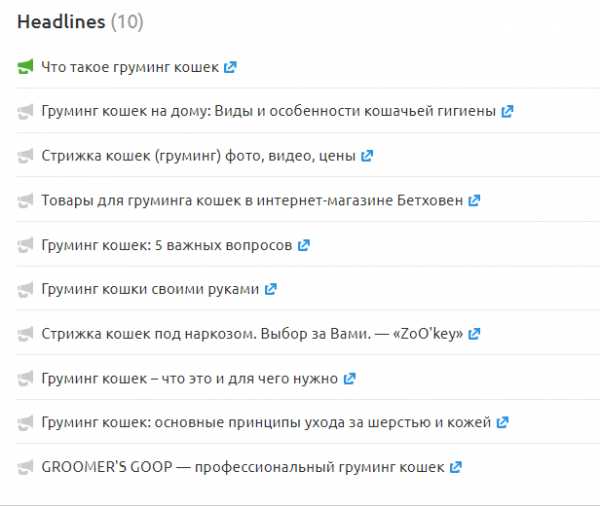
Результаты показывают большой выбор заголовков. И хотя вы не должны красть чужие заголовки, можете использовать их, чтобы сформировать свои уникальные идеи.
Включите вопросы и ответы в свой контент
Поскольку перед нами стоит 2 задачи:
- ответить на вопросы, которые задает наша целевая аудитория;
- убедить Google в том, что мы ответили на вопросы пользователей, мы должны подумать о том, как включать вопросы в наш контент.
Точное соответствие является важной частью для оптимизации контента. Этот подход также показывает вашим читателям, что вы знаете их проблемы, и что они могут доверять вам.
Важно: не нужно заспамливать текст точными вхождениями ключевых слов. Лучше подумайте, какие вопросы люди хотели задать и используйте их в материале.
Из приведенных выше результатов SEMrush Topic Research можно выделить такие вопросы:
- Что такое груминг?
- Как делают груминг кошкам?
- Чем груминг кошек отличается от груминга собак, зачем нужен отдельный специалист?
- Какими инструментами делают груминг кошек?
- Могу ли я сам дома сделать груминг своему питомцу?
- Сколько стоит профессиональный груминг для кошек?
- Не будет ли моей кошечке больно во время процедуры? Можно ли этого избежать с помощью наркоза?
Используйте связанные и LSI-запросы
Алгоритм поиска Google отлично подходит для поиска контента на основе конкретных запросов, но чтобы сделать ваш материал релевантным для большинства клиентов, нужно добавить в него LSI (латентно семантически связанные) слова и выражения.
SEMrush Topic предоставит вам список наиболее связанных поисковых запросов. Вы можете использовать их в своем контенте, но желательно в разбавленном виде, чтобы не нарваться на фильтр.
Кроме того, используйте LSI. Речь идет о словах и выражениях, которые непосредственно связаны с темой контента.
Так, например, для статьи об адвокатских услугах латентной семантикой будут слова и выражения:
- суд;
- исковое заявление;
- доверенность;
- представительство;
- апелляция.
Инструменты, которые помогут сделать качественный контент
Создание релевантного и контента — трудозатратный процесс. В статье 22 эффективных инструмента для создания качественного контента подробнее рассказывается о сервисах который помогут написать качесвтенный контент проще и быстрее. Я же просто их перечислю.
7 сервисов, которые помогут найти новые идеи для вашего сайта:
- Adwords.
- Google Trends.
- Mediametrics.
- Soovle.
- PromoRepublic.
- Pinterest.
- Urfingbird.ru.
8 сервисов, которые помогут написать и быстро отредактировать контент:
- Google Документы.
- Evernote.
- Грамота.ру.
- Орфограммка.
- Свежий взгляд.
- Главред.
- Адвего.
- Качественный сниппет.
3 сервиса для работы с графикой:
- GIMP.
- Skitch.
- Developers Charts от Google.
3 инструмента, которые помогут в SEO оптимизации контента:
- Планировщик ключей от Google.
- Яндекс.Вордстат.
- PageSpeed Insights от Google.
2 сервиса, которые помогут анализировать то как работает ваш контент:
- Яндекс.Метрика.
- Аналитика Google.
Вывод
Если вы не новичок в интернет-бизнесе, то наверняка уже поняли, насколько сложно бывает создать контент, который одновременно хорошо ранжируется поисковыми системам и в то же время привлекает на сайт хороший целевой трафик.
Однако, понимая потребности своих клиентов, вы сможете сэкономить время и деньги, чтобы сосредоточиться только на тех темах, которое соответствует требованиям ваших клиентов и целям вашего бизнеса.
Вы можете использовать инструменты, такие как SEMrush Topic Research, чтобы найти идеи для своего контента и правильно оптимизировать его.
Оставь комментарий, нажми «Мне нравится» («Like») и «Сохранить», а я напишу для тебя еще что-нибудь интересное 🙂
ritmlife.ru
что это такое. Виды релевантности — Самая полная в Рунете энциклопедия интернет-маркетинга
Материал из Самая полная в Рунете энциклопедия интернет-маркетинга
Релевантность страницы — это степень соответствия ее содержания запросам, которые пользователи вводят в поисковых системах.
Релевантность страницы: что это такое
Основной фактор, влияющий на позицию документа в выдаче. Рассмотрим пример. Пользователь ищет информацию о способах восстановления операционной системы и вводит в Яндексе или Google запрос «как восстановить операционную систему». В данном случае релевантными будут те страницы, на которых размещены тематические статьи. Причём чем информативнее и полезнее контент, тем выше показатель соответствия.
Нерелевантными же окажутся оптимизированные под запрос страницы компаний, предлагающих свои услуги за деньги.
Релевантность поисковой выдачи
Релевантность поисковой выдачи — это степень соответствия отображаемых поисковыми системами интернет-ресурсов нуждам пользователей. К примеру, запросу «эффективные методы продвижения сайтов» будут соответствовать учебники по SEO и полезные блоги, а не сайты компаний, предоставляющих услуги профессионального продвижения за деньги. Поисковые системы непрерывно совершенствуют алгоритмы и стремятся сделать выдачу более релевантной. Однако это не всегда удаётся из-за влияния человеческого фактора. Пользователи часто вводят общие или некорректные запросы. Допустим, кто-нибудь ищет «ноутбуки». Ни Яндекс, ни Google в этом случае не будут знать, что именно хотел пользователь, и отобразят в выдаче подборку как информационных, так и коммерческих ресурсов, ориентируясь на имеющиеся данные о человеке (пол, возраст, географическое положение, история предыдущих запросов и т. д.).
Релевантность ссылок
Релевантная ссылка — это URL, анкор которого соответствует содержимому целевой страницы. Рассмотрим пример. Если ссылка «купить ноутбуки Apple» ведёт на нужную страницу каталога интернет-магазина, она считается релевантной. В противном случае — нет. Безанкорные URL также могут быть релевантными, если они ведут на страницы со схожим по тематике контентом. При нарушении требований ссылки становятся бесполезными. Размещение релевантных ссылок на тематических сторонних ресурсах положительно сказывается на поисковом продвижении. Максимальный эффект дают URL, по которым есть реальные переходы. Чем больше таких ссылок, тем выше авторитет сайта «в глазах» поисковых систем.
Читайте также другие статьи на тему «Релевантность»
Полезные ссылки
www.optimism.ru