
Как закрыть сайт от индексации в robots.txt
Поисковые роботы сканируют всю информацию в интернете, но владельцы сайтов могут ограничить или запретить доступ к своему ресурсу. Для этого нужно закрыть сайт от индексации через служебный файл robots.txt.
Если закрывать сайт полностью не требуется, запрещайте индексацию отдельных страниц. Пользователям не следует видеть в поиске служебные разделы сайта, личные кабинеты, устаревшую информацию из раздела акций или календаря. Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет уменьшить время индексации и снизит нагрузку на сервер.
Как закрыть сайт полностью
Обычно ресурс закрывают полностью от индексации во время разработки или редизайна. Также закрывают сайты, на которых веб-мастера учатся или проводят эксперименты.
Запретить индексацию сайта можно для всех поисковиков, для отдельного робота или запретить для всех, кроме одного.
| Запрет для всех |
User-agent: * Disallow: / |
| Запрет для отдельного робота |
User-agent: YandexImages Disallow: / |
| Запрет для всех, кроме одного робота |
User-agent: * Disallow: / User-agent: Yandex Allow: / |
Как закрыть отдельные страницы
- административная панель;
- служебные каталоги;
- личный кабинет;
- формы регистрации;
- формы заказа;
- сравнение товаров;
- избранное;
- корзина;
- каптча;
- всплывающие окна и баннеры;
- поиск на сайте;
- идентификаторы сессий.
Желательно запрещать индексацию т.н. мусорных страниц. Это старые новости, акции и спецпредложения, события и мероприятия в календаре. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Запрет индексации
| Отдельной страницы |
User-agent: * Disallow: /contact.html |
| Раздела |
User-agent: * Disallow: /catalog/ |
| Всего сайта, кроме одного раздела |
User-agent: * Disallow: / Allow: /catalog |
| Всего раздела, кроме одного подраздела |
User-agent: * Disallow: /product Allow: /product/auto |
| Поиска на сайте |
User-agent: * Disallow: /search |
| Административной панели | Disallow: /admin |
Как закрыть другую информацию
Файл robots.txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
Запрет индексации
| Типа файлов |
User-agent: * Disallow: /*.jpg |
| Папки |
User-agent: * Disallow: /images/ |
| Папку, кроме одного файла |
User-agent: * Disallow: /images/ Allow: file.jpg |
| Скриптов |
User-agent: * Disallow: /plugins/*.js |
| utm-меток |
User-agent: * Disallow: *utm= |
| utm-меток для Яндекса | Clean-Param: utm_source&utm_medium&utm_campaign |
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
Вариант 1.Вариант 2.
<meta name=”robots” content=”none”/>
Атрибут “content” имеет следующие значения:
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические — когда правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в инструментах Яндекс.Вебмастере и Google Robots Testing Tool.
Синтаксические — когда неправильно записаны правила в файле.
К наиболее часто встречаемым относятся:
- запись без учета регистра;
- запись заглавными буквами;
- перечисление всех правил в одной строке;
- отсутствие пустой строки между правилами;
- указание краулера в директиве;
- перечисление множества вместо закрытия целого раздела или папки;
- отсутствие обязательной директивы disallow.
Шпаргалка
-
Для запрета на индексацию сайта используйте два варианта. Создайте файл robots.txt и укажите запрет через директиву disallow для всех краулеров. Другой вариант — пропишите запрет через мета-тег robots в файле index.html внутри тега .
-
Закрывайте служебные информацию, устаревающие данные, скрипты, сессии и utm-метки. Для каждого запрета создавайте отдельное правило. Запрещайте всем поисковым роботам через * или указывайте название конкретного краулера. Если вы хотите разрешить только одному роботу, прописывайте правило через disallow.
-
При создании файла robots.txt избегайте логических и синтаксических ошибок. Проверяйте файл через инструменты Яндекс.Вебмастер и Google Robots Testing Tool.
Материал подготовила Светлана Сирвида-Льорентэ.
Файл robots.txt — настройка и директивы robots.txt, запрещаем индексацию страниц
Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:

Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.

Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексацию страницы?
Как запретить индексацию зеркала?
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
Понравился пост? Сделай репост и подпишись!
Как закрыть сайт или его страницы от индексации: подробная инструкция
Что нужно закрывать от индексации?
В поисковой выдаче должны присутствовать исключительно целевые страницы, решающие задачи сайта. Что нужно закрывать от индексации в обязательном порядке:
- Страницы, являющиеся бесполезными для посетителей. В зависимости от используемой CMS таких страниц может быть большое количество. К ним относятся:
- Контент административной части сайта.
- Персональная информация пользователей, в том числе ее часть из профилей (актуально для блогов и форумов).
- Дублированный контент. Некоторые CMS могут повторять данные в разных частях сайта (например, архивы и категории).
- Формы регистрации, заказа, корзины.
- Потерявшая актуальность информация.
- Страницы печати.
- RSS лента.
- Медиа-контент шаблона.
- Страницы поиска и т.д.
- Если сайт находится на стадии разработки, страницы могут содержать нерелевантный контент, в таком случае ресурс нуждается в запрете на индексацию.
- Информация, используемая определенным кругом лиц. Например, корпоративные ресурсы, предназначенные для взаимодействия между сотрудниками.
- Аффилиаты.
Способы закрытия сайта от индексации
Закрыть сайт или страницы от посещения поисковых краулеров, можно следующими способами:
- Через файл robots.txt, с помощью специальных директив.
- Используя мета-теги в HTML-коде отдельной страницы.
- В файле .htaccess.
- При помощи плагинов, если сайт построен на готовой CMS.
Через robots.txt
Robots.txt – файл, который поисковые краулеры посещают в первую очередь перед началом индексации сайта. В нем прописываются директивы – правила для роботов.
Robots.txt должен соответствовать следующим требованиям:
- Быть правильно названным – robots.txt.
- Размер не должен превышать 500 КБ.
- Находиться строго в корне сайта.
- При проверке ссылки URL-сайта/robots.txt, должен возвращаться ответ 200.
Директивы для robots.txt:
- User-agent * – боты поисковиков, на которых распространяются директивы.
- Disallow – закрывает от индексации указанные страницы, либо весь сайт.
- Allow – индексация открыта для указанных разделов, либо всего сайта.
- Clean-param – с помощью данной директивы закрывают от индексации параметры URL адреса.
- Sitemap – абсолютный адрес расположения карты сайта (sitemap).
- Crawl-delay – диапазон времени, в который робот Яндекса заканчивает загрузку текущей страницы и приступает к загрузке следующей. Измеряется в секундах.
Полный запрет сайта на индексацию в robots.txt
Запретить индексировать сайт можно как для всех роботов поисковой системы, так и для отдельно взятых. Например, чтобы закрыть весь сайт от Яндекс бота, который сканирует изображения, достаточно прописать следующий код:
User-agent: YandexImages Disallow: /
Закрыть индексацию для всех роботов:
User-agent: * Disallow: /
Закрыть для всех, кроме указанного (в данном случае для ботов Яндекса индексация доступна):
User-agent: * Disallow: / User-agent: Yandex Allow: /
Работа с отдельными страницами и разделами сайта
Для запрета индексации одной страницы, достаточно прописать ее URL-адрес (домен не указывается) в директиве роботса:
User-agent: * Disallow: /registration.html
Закрытие раздела или категории:
User-agent: * Disallow: /category/
Также можно закрыть все, кроме указанной категории:
User-agent: * Disallow: / Allow: /category
Закрытие всей категории, кроме указанной подкатегории (в примере подкатегория – main):
User-agent: * Disallow: /uslugi Allow: /uslugi/main
Скрытие от индексирования прочих данных
По типу файлов:
User-agent: * Disallow: /*.png
По такому же принципу скрываются скриптовые файлы:
User-agent: * Disallow: /scripts/*.ajax
Директории:
User-agent: * Disallow: /portfolio/
Всю директорию, за исключением указанного файла:
User-agent: * Disallow: /portfolio/ Allow: avatar.png
UTM-метки:
User-agent: * Disallow: *utm=
Запрет на индексацию через HTML-код
Кроме файла robots.txt, запретить индексировать страницу можно с помощью мета-тегов в блоке <head> в HTML-коде.
Директивы:
- Noindex – контент страницы, кроме ссылок, закрыт от индексации.
- Nofollow – контент сканировать разрешается, но ссылки не индексируются.
- Index – индексирование содержимого разрешено.
- Follow – ссылки индексировать разрешено.
- All – все содержимое страницы подлежит индексации.
Разрешается открывать/закрывать индексацию для отдельно взятого поисковика:
- Yandex – обозначает всех роботов Яндекса.
- Googlebot – аналогично для Google.
Пример мета-тега, который запрещает индексировать страницу, на которой он размещен:
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>...</body>
</html>Директивы для определенных роботов:
Для краулера Google: <meta name="googlebot" content="noindex, nofollow"/> Для Яндекса: <meta name="yandex" content="none"/>
Запрет на уровне сервера
Бывают ситуации, когда поисковики не реагируют на прочие запреты и продолжают индексировать закрытые данные. В таком случае, рекомендуется попробовать ограничить посещение отдельных краулеров на уровне сервера. Делается это следующим кодом, который следует добавить в файл .htaccess (находится в корневой папке сайта):
SetEnvIfNoCase User-Agent "^Googlebot" search_bot # для Google SetEnvIfNoCase User-Agent "^Yandex" search_bot # для Яндекса
Закрытие сайта от индексации на WordPress
В готовых CMS для сайтов присутствуют страницы, и даже целые директории, попадание в индекс которых крайне нежелательно. Этот нюанс также относится к популярнейшей CMS WordPress.
Весь сайт через админку
Закрыть весь сайт от краулеров можно через админку: «Настройки – Чтение». Отметить пункт «Попросить поисковые системы не индексировать сайт», после чего система сама отредактирует robots.txt нужным образом.

Закрытие сайта через панель в WordPress «Настройки – Чтение»
Отдельные страницы с помощью плагина Yoast SEO
Установив и активировав плагин Yoast SEO, можно закрыть от индексации как весь ресурс, так и отдельно взятые страницы или записи. Сам плагин является мощным комбайном, помогающим в SEO-продвижении сайта.
Для того, чтобы запретить поисковым ботам индексировать определенную страницу или запись:
- Открываем ее для редактирования и пролистываем вниз до окна плагина.
- На вкладке «Дополнительно» настраиваются режимы индексации (полный ее запрет, закрытие всех ссылок – nofollow).

Закрытие от индексации с помощью плагина Yoast SEO

Настройка индексации через Yoast SEO
Запретить индексировать отдельные страницы или директории для WordPress можно также через файл robots.txt. Применяются аналогичные директивы, перечисленные выше. Хочется отметить, что готовые CMS системы требуют отдельного подхода к редактированию robots.txt, т.к. в этом случае требуется закрывать различные служебные директории: страницы рассылок, админки, шаблоны и многое другое. Если этого не сделать, то в поисковой выдаче могут появиться нежелательные материалы, а это негативно отразится на ранжировании всего сайта.
Как узнать, закрыт ли сайт от индексации?
Чтобы проверить закрыт ли сайт или отдельная страница от индексации существует множество способов, рассмотрим самые простые и удобные из них.
Через Яндекс.Вебмастер
Для проверки возможности индексации страницы, необходимо пройти верификацию в Яндексе, зайти в Вебмастер, в правом верхнем углу найти «Инструменты — Проверка ответа сервера».

Проверка индексации страницы через Яндекс.Вебмастер
На открывшейся странице вставляем URL интересующей страницы. Если страница не допущена к индексации, то появится соответствующее уведомление.

Пример уведомления о запрете индексации страницы
Таким образом можно проверить корректность работы robots.txt или плагинов для CMS.
Через Google Search Console
Зайдите в Google Search Console, выберите «Проверка URL» и вставьте адрес вашего сайта или отдельной страницы.

Проверка индексации через Google Search Console
С помощью операторов в поисковике
Если сайт проиндексирован Яндексом, то вбив в его поисковую строку специальный оператор + URL интересующего сайта/страницы, можно понять проиндексирован он или нет (для сайта отобразится количество проиндексированных страниц).

Проверка индексации сайта в Яндексе с помощью специального оператора

Проверка индексации отдельной страницы
С помощью такого же оператора проверяем индексацию в Google.
Плагины для браузера
Отличным плагином для проверки индексации страницы в поисковиках, является RDS-bar. Он показывает множество SEO показателей сайта, в том числе статус индексации текущей страницы в основных поисковиках.

Плагин RDS-bar
Итак, мы рассмотрели основные ситуации, когда сайт или его отдельные страницы должны быть закрыты от индексации, рассказали как это сделать и проверить, надеемся наша статья была вам полезной.
Как запретить индексацию страницы с помощью robots.txt?

От автора: У вас на сайте есть страницы, которые вы бы не хотели показывать поисковым системам? Из этой статье вы узнаете подробно о том, как запретить индексацию страницы в robots.txt, правильно ли это и как вообще правильно закрывать доступ к страницам.
Итак, вам нужно не допустить индексацию каких-то определенных страниц. Проще всего это будет сделать в самом файле robots.txt, добавив в него необходимые строчки. Хочу отметить, что адреса папок мы прописывали относительно, url-адреса конкретных страниц указывать таким же образом, а можно прописать абсолютный путь.
Допустим, на моем блоге есть пару страниц: контакты, обо мне и мои услуги. Я бы не хотел, чтобы они индексировались. Соответственно, пишем:
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/ |

Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееЕстественно, указываем настоящие url-адреса. Если же вам необходимо не индексировать страничку http://blog.ru/about-me, то в robots.txt нужно прописать так:
Другой вариант
Отлично, но это не единственный способ закрыть роботу доступ к определенным страничкам. Второй – это разместить в html-коде специальный мета-тег. Естественно, разместить только в тех записях, которые нужно закрыть. Выглядит он так:
<meta name = «robots» content = «noindex,nofollow»>
<meta name = «robots» content = «noindex,nofollow»> |
Тег должен быть помещен в контейнер head в html-документе для корректной работы. Как видите, у него два параметры. Name указывается как робот и определяет, что эти указания предназначены для поисковых роботов.
Параметр же content обязательно должен иметь два значения, которые вписываются через запятую. Первое – запрет или разрешение на индексацию текстовой информации на странице, второе – указание насчет того, индексировать ли ссылки на странице.
Таким образом, если вы хотите, чтобы странице вообще не индексировалась, укажите значения noindex, nofollow, то есть не индексировать текст и запретить переход по ссылкам, если они имеются. Есть такое правило, что если текста на странице нет, то она проиндексирована не будет. То есть если весь текст закрыт в noindex, то индексироваться нечему, поэтому ничего и не будет попадать в индекс.
Кроме этого есть такие значения:
noindex, follow – запрет на индексацию текста, но разрешение на переход по ссылкам;
index, nofollow – можно использовать, когда контент должен быть взят в индекс, но все ссылки в нем должны быть закрыты.
index, follow – значение по умолчанию. Все разрешается.
Запрещается использовать более двух значений. Например:
<meta name = «robots» content = «noindex,nofollow, follow»>
<meta name = «robots» content = «noindex,nofollow, follow»> |
И любые другие. В этом случае мы видим противоречие.
Итог
Наиболее удобным способом закрытия страницы для поискового робота я вижу использование мета-тега. В таком случае вам не нужно будет постоянно, сотни раз редактировать файл robots.txt, чтобы открыть или закрыть очередной url, а это решение принимается непосредственно при создании новых страниц.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
СмотретьКак закрыть от индексации страницу, сайт, ссылки, текст. Что нужно запрещать индексировать в robots.txt
Наш аналитик Александр Явтушенко недавно поделился со мной наблюдением, что у многих сайтов, которые приходят к нам на аудит, часто встречаются одни и те же ошибки. Причем эти ошибки не всегда можно назвать тривиальными – их допускают даже продвинутые веб-мастера. Так возникла идея написать серию статей с инструкциями по отслеживанию и исправлению подобных ошибок. Первый в очереди – гайд по настройке индексации сайта. Передаю слово автору.
Для хорошей индексации сайта и лучшего ранжирования страниц нужно, чтобы поисковик обходил ключевые продвигаемые страницы сайта, а на самих страницах мог точно выделить основной контент, не запутавшись в обилие служебной и вспомогательной информации.
У сайтов, приходящих к нам на анализ, встречаются ошибки двух типов:
1. При продвижении сайта их владельцы не задумываются о том, что видит и добавляет в индекс поисковый бот. В этом случае может возникнуть ситуация, когда в индексе больше мусорных страниц, чем продвигаемых, а сами страницы перегружены.
2. Наоборот, владельцы чересчур рьяно взялись за чистку сайта. Вместе с ненужной информацией могут прятаться и важные для продвижения и оценки страниц данные.
Сегодня мы хотим рассмотреть, что же действительно стоит прятать от поисковых роботов и как это лучше делать. Начнём с контента страниц.
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
– скрываются от индексации фильтры, форма поиска, сортировка. Наличие таких возможностей у интернет-магазина – важный коммерческий показатель, который лучше показать, а не прятать.
– прячется информация об оплате и доставке. Это делают, чтобы повысить уникальность на товарных карточках. А ведь это тоже информация, которая должна быть на качественной товарной карточке.
– со страниц «вырезается» меню, ухудшая оценку удобства навигации по сайту.
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!
У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен. Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется.
Это видно из самого описания тега в справке Яндекса.
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
«Не до конца понятна механика действия и влияние на ранжирование тега <noindex>текст</noindex>. Далее поясню, почему так озадачены. А сейчас — есть 2 гипотезы, хотелось бы найти истину.
№1 Noindex не влияет на ранжирование / релевантность страницы вообще
При этом предположении: единственное, что он делает — закрывает часть контента от появления в поисковой выдаче. При этом вся страница рассматривается целиком, включая закрытые блоки, релевантность и сопряженные параметры (уникальность; соответствие и т. п.) для нее вычисляется согласно всему имеющему в коде контенту, даже закрытому.
№2 Noindex влияет на ранжирование и релевантность, так как закрытый в тег контент не оценивается вообще. Соответственно, все наоборот. Страница будет ранжироваться в соответствии с открытым для роботов контентом.»
Ответ:

В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение.
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:

Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:

Рекомендации Google.
Рекомендации Яндекса.
Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.

Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.

Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.

Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно в блоге Siteclinic.
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Рекомендации Яндекса.
Рекомендации Google.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:

В Google Search Console «Удалить URL-адрес»:

Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Тег noindex
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.

Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:

Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег <span> на <a>. При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты.
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Заключение
Удаление со страницы объёмных сквозных блоков действительно может давать положительный эффект для ранжирования. Делать это лучше, сокращая страницу, и выводя на ней только нужный посетителям контент. Прятать контент от поисковика – костыль, который стоит использовать только в тех случаях, когда сократить другими способами сквозные блоки нельзя.
Убирая со страницы часть контента, не забывайте, что для ранжирования важны не только текстовые критерии, но и полнота информации, коммерческие факторы.
Примерно аналогичная ситуация и с внутренними ссылками. Да, иногда это может быть полезно, но искусственное перераспределение ссылочной массы на сайте – метод спорный. Гораздо безопаснее и надёжнее будет просто отказаться от ссылок, в которых вы не уверены.
Со страницами сайта всё более однозначно. Важно следить за тем, чтобы мусорные, малополезные страницы не попадали в индекс. Для этого есть много методов, которые мы собрали и описали в этой статье.
Вы всегда можете взять у нас консультацию по техническим аспектам оптимизации, или заказать продвижение под ключ, куда входит ежемесячный seo-аудит.
ОТПРАВИТЬ ЗАЯВКУ
Автор: Александр, SEO аналитик SiteClinic.ru
Настройка robots.txt – как узнать, какие страницы необходимо закрывать от индексации
Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и частоиспользуемых User-agent:
- User-agent:*
- User-agent: Yandex
- User-agent: Googlebot
- User-agent: Bingbot
- User-agent: YandexImages
- User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация индексацию всех файлов, которые находятся в папке admin и заканчиваются на .php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из user-agent, следует продублировать информацию и добавить новую.
Пример robots.txt для WordPress:

*Примечание для User agent: Yandex
-
Для того чтобы передать роботу Яндекса Url без Get параметров (например: ?id=, ?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param.

-
Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
-
Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay. Но как сообщается в блоге для вебмастеров Яндекса:
- Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
- Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс. Вебмастер добавили новый раздел «Скорость обхода».

Проверка robots.txt
Старая версия Search console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).

Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации. Более подробно о том, как устранить ошибку «Googlebot не может получить доступ к файлам CSS и JS на сайте», вы читайте в нашем блоге.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots.txt. Теперь достаточно просто вставить адрес нужной страны в строку поиска.

В следующем окне нажимаем «Изучить просканированную страницу».

Далее нажимаем ресурсы страницы

В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу google. В конкретном примере нет ресурсов, заблокированных файлом robots.txt.

Если же такие ресурсы будут, вы увидите сообщения следующего вида:

Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
- Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
- Админ панель ресурса.
- Страницы сортировок, страницы вида отображения информации на сайте.
- Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
- Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Заключение
Файл robots.txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
В статье большое количество информации посвящено роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендую после прочтения этой статьи проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить. Если вы не знаете, как это сделать, обращайтесь к нам за помощью.
Как закрыть сайт от индексации в robots.txt, через htaccess и мета-теги
Привет уважаемые читатели seoslim.ru! Некоторые пользователи интернета удивляются, какими же быстродействующими должны быть компьютеры Яндекса, чтобы в несколько секунд просмотреть все сайты в глобальной сети и найти ответ на вопрос?
Но на самом деле за пару секунд изучить все данные WWW не способна ни одна современная, даже самая мощная вычислительная машина.
Давайте сегодня пополним наши знания о всемирной сети и разберемся, как поисковые машины ищут и находят ответы на вопросы пользователей и каким образом можно им запретить это делать.
Что такое индексация сайта
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
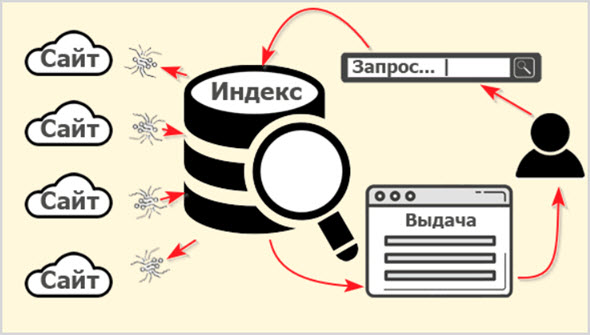
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
Это полезно знать: Какую роль в работе сайта играют DNS-сервера
В плане индексации Google работает несколько быстрее нашего Яндекса.
- Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
- В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
- Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
- Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
- В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в базы поисковиков, может существовать много.
Давайте разберемся, как задачу управления индексацией решить практически.
Как скрыть сайт от индексации поисковыми системами
Сбором информации в интернете и занесением его в базу данных поисковой системы занимаются автоматические программы, называемые роботами-индикаторами. Веб-мастера часто называют этих роботов сокращенно «ботами».
Слово «боты» вы могли уже встречать в различных мессенджерах. В этих системах быстрой коммуникации боты тоже являются компьютерными программами, выполняющими определенные функции или задачи.
Так вот, для того, чтобы роботы-индексаторы не занесли определенные веб-страницы или контент в Index поисковика, следует сформировать специальные команды, которые указывают ботам, что некоторые страницы на сайте посещать запрещено, а некоторый контент не следует заносить в поисковые базы.
Настроить команды запрета индексации можно несколькими способами, которые мы и рассмотрим ниже.
Запрет в robots.txt
В корневой папке сайта на удаленном сервере хостинг-провайдера имеется файл с именем robots.txt.
- Что такое корневая папка сайта? Корневая папка или каталог – это то место, которому в первую очередь производится запрос из браузера, когда пользователь обращается к какому-нибудь ресурсу в интернете. То есть, это исходная папка с которой начинаются все запросы к веб-ресурсу.
- Файл robots.txt – это пакетный командный файл, в котором содержатся директивы для ПС, ответственных за индексацию контента.
Говоря простыми словами, robots.txt это специальный файл, предназначенный для поисковых роботов. Что, собственно, понятно из самого имени документа – Robots, что означает «роботы».
Отредактировать файл с командами для роботов ПС можно вручную в простом текстовом редакторе, добавить или удалить команды, изменить отдельные записи.
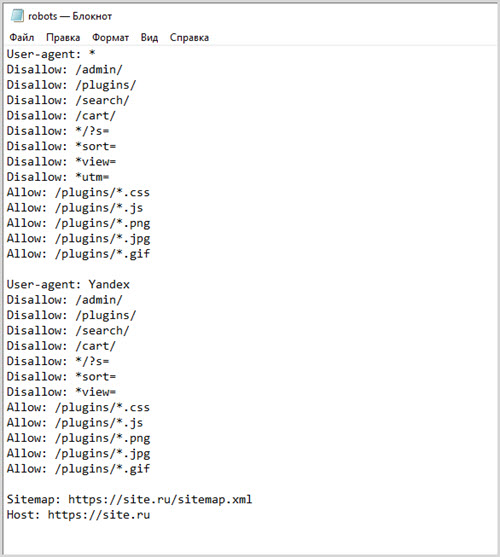
У каждой поисковой системы действует множество роботов, которые ответственны за индексацию разного рода контента. Отдельные роботы ищут и заносят в базу изображения, текст, скрипты и все остальное, что только может иметь значение для нормальной работы интернет-проекта.
Роботов индексаторов довольно много, перечислим только некоторых из них:
- Yandex – главный робот, ответственный за индексацию проекта в поисковой системе Яндекс.
- YaDirectBot – робот, ответственный за индексацию веб-страниц, на которых опубликована реклама контекстной системы Яндекс Директ.
- Yandex/1.02.000 (F) – робот, занимающийся индексации фавиконов, иконок сайта, которые пользователь видит во вкладках браузера и в сниппетах на странице выдачи.
- Yandex Images – индексация изображений.
Как вы понимаете, директивы или команды следует задавать для каждого конкретного робота в том случае, если вы желаете задать правила поведения индексация индексируемых роботов в отношении определенного типа контента.
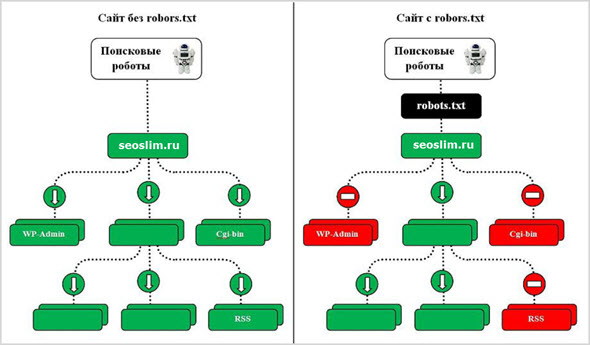
Если же необходимо задать правила индексации для всей поисковой системы, тогда в файле robots.txt прописывается директива для главного робота.
В поисковой системе Google работают свои роботы:
- Googlebot – основной бот Google.
- Googlebot Video – сбор информации о видеороликах, размещенных на площадке.
- Googlebot Images – индексация картинок.
А теперь давайте рассмотрим, как выглядят сами директивы или команды для поисковых роботов.
- Команда User-agent: определяет, какому конкретному роботу предназначена директива. Если в этой команде указана звездочка * – это означает что команда предназначена для всех, любых поисковых роботов.
- Команда Disallow означает запрет индексации, а команда Allow означает разрешение индексации.
Например, команда User-agent: Yandex задает правила поведения для всех поисковых роботов Яндекса. Если юзер-агент не задан, то команды будут действовать для всех поисковых систем.
В общем-то, для того, чтобы вручную редактировать файл robot.txt, не нужно быть опытным программистам.
В профессиональных конструкторах сайтов и системах управления контентом обычно предусмотрен отдельный интерфейс для настройки файла robots.txt. Знать конкретные названия поисковых роботов и разбираться в директивах необходимости нет. Достаточно указать то, что вам нужно в самом файле.
Рассмотрим для примера некоторые команды.
- User-agent: *
- Disallow: /
Эта директива запрещает обход проекта любым роботам всех поисковых систем. Если же будет указана директива Allow — сайт открыт для индексации.
Следующая команда запрещает обход всем поисковым системам, кроме Яндекса.
- User-agent: *
- Disallow: /
- User-agent: Yandex
- Allow: /
Чтобы запретить индексацию только отдельных страниц, создается вот такая команда – запрет на обход страниц «Контакты» и «О компании».
- User-agent: *
- Disallow: /contact/
- Disallow: /about/
Закрыть целый отдельный каталог сайта:
- User-agent: *
- Disallow: /catalog/
Закрыть папку с картинками:
Не индексировать файлы с указанным расширением:
- User-agent: *
- Disallow: /*.jpg
Различных команд, с помощью которых можно управлять поисковыми роботами, существует достаточно много. Веб-мастер может в широких пределах регулировать схему индексации веб-страниц и отдельных типов контента.
Запрет индексации через htaccess
На серверах Apache для управления доступом используется файл .htaccess (hypertext access).
Особенностью функционирования этого файла является то, что его команды распространяются только на папку или каталог, в которых этот файл размещен. Если этот файл помещается в корневой каталог, то его директивы будут действовать на весь ресурс.
Возникает логичный вопрос, зачем использовать более сложный .htaccess, если задать порядок индексации можно в файле robots.txt?
Дело в том, что далеко не все роботы не всех поисковых систем подчиняются команда файла robots.txt. Зачастую поисковые роботы просто игнорируют этот файл.
С другой стороны, директивы .htaccess являются всеобъемлющими по отношению к сайтам, размещенным на серверах типа Apache.
Хотя файл .htaccess тоже является текстовым и может быть отредактирован веб-мастером в простом редакторе, настройка этого файла скорее является прерогативой опытных специалистов техподдержки хостинг-провайдера. Поскольку команд у него намного больше и неопытному человеку очень легко допустить критические ошибки, которые приведут к неправильной работе проекта.
Следующая команда предназначена для запрета индексации сайта определенным поисковым роботам:
SetEnvIfNoCase User-Agent
Далее прописывается конкретный робот поисковой системы.
Для каждого робота команда прописывается отдельной строкой.
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
Как вы могли заметить, хотя .htaccess является простым текстовым файлом, он не имеет расширения txt, а должен иметь именно указанный формат, в противном случае сервер его не распознает.
С помощью админ панели WordPress
Зайдите в административную панель своего блога на WordPress и выберите раздел «Настройки». Нажмите на пункт Меню «Чтение».
После перехода в интерфейс «Чтение», вы найдете следующие возможности для настройки индексации.
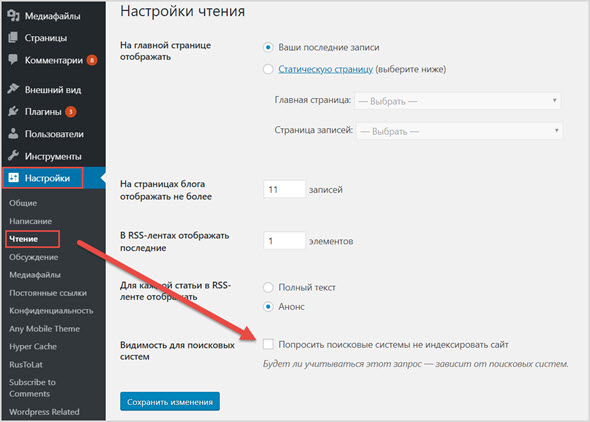
Отметьте пункт «Попросить поисковые системы не индексировать сайт», если не хотите, чтобы контент был доступен в открытом интернете. Не забудьте сохранить изменения.
Как видите, при помощи админ панели WordPress можно сделать только общие запреты или разрешения. Для более тонких настроек индексации следует использовать файл robots.txt и .htaccess.
С помощью meta-тега
Управлять индексацией можно и с помощью тегов в HTML-документе веб-страницы.
Директивы добавляются в файле header.php в контейнере <head> … </head>.
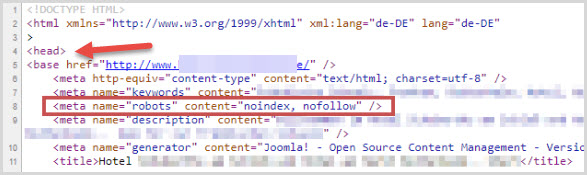
Команда выглядит следующим образом:
<meta name=”robots” content=”noindex, nofollow”/>
Это означает, что поисковым роботам запрещается индексация контента. Если вместо robots указа точное имя бота определенной поисковой машины, то запрет будет касаться только ее роботов.
На этом все, как видите существует много методов, которые позволят скрыть площадку от поисковых систем. Какой использовать вам, решайте сами.
Только помните, что проанализировать правильность директив относительно индексации сайта можно с помощью инструментов Яндекса для веб-мастеров либо через SEO-сервисы.
Страницы веб-роботов
О /robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для инструкций по их сайт для веб-роботов; это называется Исключение роботов Протокол .
Это работает так: робот хочет перейти по URL-адресу веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это произойдет, он первым проверяет http://www.example.com/robots.txt и находит:
Пользовательский агент: * Запретить: /
«User-agent: *» означает, что этот раздел применим ко всем роботам.»Disallow: /» сообщает роботу, что он не должен посещать никакие страницы на сайте.
При использовании /robots.txt следует учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, которые сканируют Web на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами. не обращаю внимания.
- файл /robots.txt является общедоступным. Все могут видеть, какие разделы вашего сервера вы не хотите, чтобы роботы использовали.
Так что не пытайтесь использовать /robots.txt для сокрытия информации.
Смотрите также:
Реквизиты
Файл /robots.txt является стандартом де-факто и не принадлежит никому орган по стандартизации. Есть два исторических описания:
Вдобавок есть внешние ресурсы:
Стандарт /robots.txt активно не развивается. См. Как насчет дальнейшего развития /robots.txt? для более подробного обсуждения.
На оставшейся части этой страницы дается обзор того, как использовать / robots.txt на ваш сервер, с несколькими простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как создать файл /robots.txt
Где поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет URL-адрес в файле «/robots.txt», он удаляет компонент пути из URL (все, начиная с первой косой черты), и помещает на его место «/robots.txt».
Например, для http: // www.example.com/shop/index.html, он будет удалите «/shop/index.html» и замените его на «/robots.txt», и в итоге будет «Http://www.example.com/robots.txt».
Итак, как владельцу веб-сайта вам необходимо разместить его в нужном месте на своем веб-сервер для работы полученного URL. Обычно это то же самое место, куда вы помещаете главный «index.html» вашего веб-сайта стр. Где именно это и как поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать строчные буквы для имени файла: «роботы.txt «, а не» Robots.TXT.
Смотрите также:
Что туда класть
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись следующего вида:Пользовательский агент: * Disallow: / cgi-bin / Запретить: / tmp / Запретить: / ~ joe /
В этом примере исключены три каталога.
Обратите внимание, что для каждого префикса URL-адреса вам нужна отдельная строка «Disallow». хотите исключить — вы не можете сказать «Disallow: / cgi-bin / / tmp /» на одна линия.Кроме того, в записи может не быть пустых строк, так как они используются для разграничения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается ни в User-agent, ни в Disallow линий. ‘*’ В поле User-agent — это специальное значение, означающее «любой робот «. В частности, у вас не может быть таких строк, как» User-agent: * bot * «, «Запрещать: / tmp / *» или «Запрещать: * .gif».
Что вы хотите исключить, зависит от вашего сервера. Все, что явно не запрещено, считается справедливым игра для извлечения.Вот несколько примеров:
Чтобы исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Разрешить всем роботам полный доступ
Пользовательский агент: * Disallow:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользовательский агент: * Disallow: / cgi-bin / Запретить: / tmp / Disallow: / junk /
Для исключения одного робота
Пользовательский агент: BadBot Запретить: /
Чтобы позволить одному роботу
Пользовательский агент: Google Disallow: Пользовательский агент: * Запретить: /
Для исключения всех файлов, кроме одного
В настоящее время это немного неудобно, поскольку нет поля «Разрешить». простой способ — поместить все файлы, которые нельзя разрешить, в отдельный директорию, скажите «вещи» и оставьте один файл на уровне выше этот каталог:Пользовательский агент: * Запретить: / ~ joe / stuff /В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Запретить: /~joe/bar.html,
Объяснение и иллюстрация файла robots.txt
«Используйте файл robots.txt на своем веб-сервере.
— из руководства Google для веб-мастеров 1
Что такое файл robots.txt?
- Файл robots.txt — это простой текстовый файл, размещенный на вашем веб-сервере, который сообщает веб-сканерам, таким как робот Googlebot, следует ли им обращаться к файлу или нет.
Базовые примеры robots.txt
Вот несколько распространенных роботов.txt (они будут подробно описаны ниже).
Блокировать одну папку
User-agent: *
Disallow: / folder /
Блок одного файла
User-agent: *
Disallow: /file.html
Почему вам следует узнать о файле robots.txt?
- Неправильное использование файла robots.txt может повредить вашему рейтингу
- Файл robots.txt контролирует, как пауки поисковых систем видят ваши веб-страницы и взаимодействуют с ними.
- Этот файл упоминается в нескольких рекомендациях Google
- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальной частью работы поисковых систем.
Совет. Чтобы узнать, не работает ли ваш robots.txt блокирует любые важные файлы, используемые Google, используйте инструмент рекомендаций Google.
Пауки поисковых систем
Первое, на что паук поисковой системы, такой как робот Googlebot, обращает внимание при посещении страницы, — это файл robots.txt.
Он делает это, потому что хочет знать, есть ли у него разрешение на доступ к этой странице или файлу. Если в файле robots.txt указано, что он может входить, паук поисковой системы переходит к файлам страниц.
Если у вас есть инструкции для робота поисковой системы, вы должны сообщить ему эти инструкции.Вы делаете это с помощью файла robots.txt. 2
Приоритеты вашего сайта
Есть три важных вещи, которые должен сделать любой веб-мастер, когда дело касается файла robots.txt.
- Определите, есть ли у вас файл robots.txt
- Если он у вас есть, убедитесь, что он не вредит вашему рейтингу и не блокирует контент, который вы не хотите блокировать
- Определите, нужен ли вам файл robots.txt
Определение наличия файла robots.txt
Вы можете ввести веб-сайт ниже, нажать «Перейти», и он определит, есть ли на сайте файл robots.txt, и отобразит то, что написано в этом файле (результаты отображаются здесь, на этой странице) .
Если вы не хотите использовать вышеуказанный инструмент, вы можете проверить его в любом браузере. Файл robots.txt всегда находится в одном и том же месте на любом веб-сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
www.yourwebsite.com/robots.txt
Если у вас там есть файл, то это ваш файл robots.txt. Вы либо найдете файл со словами, либо найдете файл без слов, либо вообще не найдете файл.
Определите, блокирует ли ваш robots.txt важные файлы
Вы можете использовать инструмент рекомендаций Google, который предупредит вас, если вы блокируете определенные ресурсы страницы, которые необходимы Google для понимания ваших страниц.
Если у вас есть доступ и разрешение, вы можете использовать консоль поиска Google для тестирования своих роботов.txt файл. Инструкции для этого можно найти здесь (инструмент не общедоступен — требуется логин) .
Чтобы полностью понять, не блокирует ли ваш файл robots.txt что-либо, вы не хотите, чтобы он блокировал, вам необходимо понять, о чем он говорит. Мы рассмотрим это ниже.
Вам нужен файл robots.txt?
Возможно, вам даже не понадобится иметь файл robots.txt на вашем сайте. На самом деле, зачастую он вам не нужен.
Причины, по которым вы можете захотеть иметь robots.txt файл:
- У вас есть контент, который вы хотите заблокировать для поисковых систем
- Вы используете платные ссылки или рекламу, требующую специальных инструкций для роботов
- Вы хотите настроить доступ к своему сайту для надежных роботов
- Вы разрабатываете действующий сайт, но не хотите, чтобы поисковые системы еще индексировали его
- Они помогают следовать некоторым рекомендациям Google в определенных ситуациях.
- Вам нужно частично или полностью из вышеперечисленного, но у вас нет полного доступа к вашему веб-серверу и его настройке
Каждой из вышеперечисленных ситуаций можно управлять другими способами, но не с помощью robots.txt — хорошее центральное место для заботы о них, и у большинства веб-мастеров есть возможность и доступ, необходимые для создания и использования файла robots.txt.
Причины, по которым не может иметь файл robots.txt:
- Это просто и без ошибок
- У вас нет файлов, которые вы хотите или которые нужно заблокировать для поисковых систем
- Вы не попадете ни в одну из перечисленных выше причин, по которым у вас есть файл robots.txt.
Не иметь роботов — это нормально.txt файл.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как Googlebot, будут иметь полный доступ к вашему сайту. Это нормальный и простой метод, который очень распространен.
Как сделать файл robots.txt
Если вы умеете печатать или копировать и вставлять, вы также можете создать файл robots.txt.
Файл представляет собой просто текстовый файл, что означает, что вы можете использовать блокнот или любой другой текстовый редактор для его создания. Вы также можете сделать их в редакторе кода. Вы даже можете «скопировать и вставить» их.
Вместо того чтобы думать: «Я создаю файл robots.txt», просто подумайте: «Я пишу заметку», это в значительной степени один и тот же процесс.
Что должен сказать robots.txt?
Это зависит от того, что вы хотите.
Все инструкции robots.txt приводят к одному из следующих трех результатов
- Полное разрешение: все содержимое может сканироваться.
- Полное запрещение: сканирование контента невозможно.
- Условное разрешение: директивы в файле robots.txt определяют возможность сканирования определенного контента.
Давайте объясним каждый.
Полное разрешение — все содержимое может сканироваться
Большинство людей хотят, чтобы роботы посещали все на их веб-сайтах. Если это так и вы хотите, чтобы робот индексировал Во всех частях вашего сайта есть три варианта, чтобы роботы знали, что им рады.
1) Нет файла robots.txt
Если на вашем сайте нет файла robots.txt, вот что происходит …
В гости приходит робот вроде Googlebot. Ищет файл robots.txt. Он не находит его, потому что его там нет. Затем робот чувствует бесплатно посещать все ваши веб-страницы и контент, потому что это то, на что он запрограммирован в данной ситуации.
2) Создайте пустой файл и назовите его robots.txt
Если на вашем веб-сайте есть файл robots.txt, в котором ничего нет, то вот что происходит …
В гости приходит робот вроде Googlebot.Ищет файл robots.txt. Он находит файл и читает его. Читать нечего, поэтому После этого робот может свободно посещать все ваши веб-страницы и контент, потому что это то, что он запрограммирован делать в данной ситуации.
3) Создайте файл с именем robots.txt и напишите в нем следующие две строки …
Если на вашем веб-сайте есть файл robots.txt с этими инструкциями, происходит следующее …
В гости приходит робот вроде Googlebot. Он ищет роботов.txt файл. Он находит файл и читает его. Читает первую строку. Затем это читает вторую строку. Затем робот может свободно посещать все ваши веб-страницы и контент, потому что это то, что вы ему сказали (я объясню это ниже).
Полное запрещение — сканирование содержимого невозможно
Предупреждение. Это означает, что Google и другие поисковые системы не будут индексировать или отображать ваши веб-страницы.
Чтобы заблокировать доступ всех известных пауков поисковых систем к вашему сайту, вы должны иметь эти инструкции в своем файле robots.txt:
Не рекомендуется делать это, так как это не приведет к индексации ни одной из ваших веб-страниц.
Инструкции robot.txt и их значение
Вот объяснение того, что означают разные слова в файле robots.txt
Агент пользователя
Часть «User-agent» предназначена для указания направления к конкретному роботу, если это необходимо. Есть два способа использовать это в ваш файл.
Если вы хотите сообщить всем роботам одно и то же, поставьте «*» после «User-agent». Это будет выглядеть так…
Вышеупомянутая строка говорит: «Эти указания применимы ко всем роботам».
Если вы хотите что-то сказать конкретному роботу (в этом примере роботу Google), это будет выглядеть так …
В строке выше говорится, что «эти инструкции относятся только к роботу Googlebot».
Запрещено:
Часть «Запретить» предназначена для указания роботам, в какие папки им не следует смотреть. Это означает, что если, например, вы не хотите, чтобы поисковые системы индексировали фотографии на вашем сайте, вы можете поместить эти фотографии в одну папку и исключить ее.
Допустим, вы поместили все эти фотографии в папку под названием «фотографии». Теперь вы хотите запретить поисковым системам индексировать эту папку.
Вот как должен выглядеть ваш файл robots.txt в этом сценарии:
User-agent: *
Disallow: / photos
Две вышеуказанные строки текста в файле robots.txt не позволят роботам посетить папку с фотографиями. «Пользовательский агент *» часть говорит: «Это относится ко всем роботам». В части «Запретить: / фотографии» указано «не посещать и не индексировать папку с моими фотографиями».
Инструкции для робота Googlebot
Робот, который Google использует для индексации своей поисковой системы, называется Googlebot. Он понимает еще несколько инструкций, чем другие роботы.
Помимо «Имя пользователя» и «Запретить» робот Googlebot также использует инструкцию Разрешить.
Разрешить
Инструкции «Разрешить:» позволяют сообщить роботу, что можно видеть файл в папке, которая была «Запрещена». по другим инструкциям. Чтобы проиллюстрировать это, давайте возьмем приведенный выше пример, когда робот не посещает и не индексирует ваши фотографии.Мы поместили все фотографии в одну папку под названием «фотографии» и создали файл robots.txt, который выглядел так …
User-agent: *
Disallow: / photos
Теперь предположим, что в этой папке есть фотография с именем mycar.jpg, которую вы хотите проиндексировать роботом Googlebot. С Разрешить: инструкции, мы можем сказать Googlebot сделать это, это будет выглядеть так …
User-agent: *
Disallow: / photos
Allow: /photos/mycar.jpg
Это сообщит роботу Googlebot, что он может посещать mycar.jpg «в папке с фотографиями, хотя папка» фото «в противном случае не входит.
Тестирование файла robots.txt
Чтобы узнать, заблокирована ли отдельная страница файлом robots.txt, вы можете использовать этот технический инструмент SEO, который сообщит вам, блокируются ли файлы, важные для Google, а также отобразит содержимое файла robots.txt.
Ключевые концепции
- Если вы используете файл robots.txt, убедитесь, что он используется правильно
- Неправильный robots.txt может заблокировать индексирование вашей страницы роботом Googlebot
- Убедитесь, что вы не блокируете страницы, необходимые Google для ранжирования ваших страниц.
 Патрик Секстон
Патрик Секстон
.
сканеров google — индексируется сам контент robots.txt?
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Общественные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним возможности технической карьеры
- Талант Нанять технических талантов
- реклама Обратитесь к разработчикам по всему миру
Загрузка…
- Авторизоваться
Как запретить использование определенной страницы в robots.txt
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Общественные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним возможности технической карьеры
- Талант Нанять технических талантов
- реклама Обратитесь к разработчикам по всему миру