
Техническая оптимизация с noindex и nofollow – правила и частые заблуждения
Начнем с того, что обозначим разные способы использования noindex и nofollow:
- Тег <noindex> и атрибут rel=»nofollow»
- Метатеги <meta name=»robots» content=»noindex»/> и <meta name=»robots» content=»nofollow»/>
Тег <noindex> и атрибут rel=»nofollow»
Тег <noindex> – это HTML-тег, который запрещает Яндексу индексировать ту или иную область страницы сайта. Для поисковой системы Google этот тег не работает, более того, в Google вообще не предусмотрена возможность исключения части текста страницы из индекса.
Заблуждение №1. Основная ошибка людей, которые используют этот тег, заключается в убеждении, что если часть какого-либо текста помещена между открывающимся и закрывающимся тегом <noindex>, то робот Яндекса не станет читать и анализировать этот текст.
Единственное, что данный тег запрещает – это помещение содержимого в индексную базу, но это содержимое в любом случае будет прочитано и проанализировано роботом.
Пример: На странице вашего сайта расположен некоторый текст, использующий прямые вхождения предложений из других сторонних источников. Следовательно, эти предложения снижают уникальность вашего текста, а вам необходимо, чтобы уникальность была 100%. Вы решаете закрыть эти предложения тегом <noindex>, чтобы Яндекс считал ваш текст уникальным. Это заблуждение.
Абсолютно весь текст вашей страницы будет прочитан и обработан роботом, и ему будет известно, что текст вашей страницы не является уникальным.
Сама суть тега <noindex> – «не индексировать», значит запрета на чтение нет.
Предположим, что поисковый робот зашел на вашу страницу и начал сканировать содержимое. В какой-то момент робот находит открытие тега <noindex>, что является сигналом роботу – дальше текст не индексировать. Но чтобы найти то место кода, где тег <noindex> закрывается, роботу необходимо прочесть содержимое, идущее после открытия данного тега. Следовательно, даже теоретически нельзя запретить роботам читать содержимое с помощью тега <noindex>.
Для чего же тогда нужен тег <noindex>?
Он нужен непосредственно для того, чтобы запретить роботу выдавать в выдаче своей поисковой системы какую-либо информацию. Это могут быть, к примеру, контакты, которые по каким-либо причинам не должны отображаться в выдаче.
Заблуждение №2. Ещё одно заблуждение, которое часто встречается среди владельцев сайтов, – это мнение, что ссылка, помещенная в тег <noindex>, не будет учтена поисковым роботом. Как я говорил ранее, всё, что находится внутри тега <noindex>, будет прочитано и проанализировано роботом Яндекса. И ссылки не являются исключением. Единственное отличие размещенных обычным образом ссылок от ссылок в теге <noindex> – это то, что текст (анкор) ссылки не будет проиндексирован.
На помощь вебмастерам, которым необходимо, чтобы робот всё же не учитывал ссылки со страниц, приходит атрибут rel=»nofollow», который работает как для Яндекса, так и для Google. При использовании этого атрибута ссылка всё равно будет изучена роботом и по ней будет произведён переход, но без nofollow по ссылке будет передан вес адресату, а с nofollow вес будет сгорать.
Пример 1:
<noindex><a href=»http://1ps.ru/»>Создание и продвижение сайтов</a></noindex>
Яндекс не индексирует анкор, но учитывает ссылку на 1ps.ru и передает по ней вес
Пример 2:
<noindex><a href=»http://1ps.ru/» rel=»nofollow»>Создание и продвижение сайтов</a></noindex>
Яндекс не индексирует анкор и не передает вес по ссылке на 1ps.ru
Существует два способа написания тега <noindex> в коде:
1. <noindex>Текст, запрещённый к индексированию</noindex>
2. <!—noindex—>Текст, запрещённый к индексированию<!—/noindex—>
Второй вариант более верный. Так как тег <noindex> не входит в официальную спецификацию языка разметки HTML, то его присутствие в коде может вызвать недопонимание у других поисковых систем, которые будут считать его наличие за ошибку. Чтобы сделать код страницы валидным, для всех поисковых роботов рекомендуется использовать закомментированный вариант написания. Яндекс такое написание распознает, а другие поисковые роботы не будет обращать внимание на его присутствие.
Метатеги <meta name=»robots» content=»noindex»/> и <meta name=»robots» content=»nofollow»/>
Использование метатега noindex в коде страницы запрещает Яндексу (Google, опять же, в данном случае не участвует) индексировать всё текстовое содержимое страницы, ссылки при этом будут проанализированы в полной мере. То есть наличие в коде страницы этого метатега не равнозначно закрытию страницы от индекса в robots.txt.
Наличие в коде страницы метатега nofollow запрещает поисковым системам индексировать ссылки на страницах. Переходить по ссылкам со страницы при наличии этого метатега роботы также не будут. Но вот что написано в помощи Яндекса:
«Робот не посетит документы, если ссылки на них стоят со страницы, содержащей метатег со значением nofollow, тем не менее, они могут быть проиндексированы, если в других источниках на них указаны ссылки без nofollow»
Подведём итоги
Тег <noindex> используем только для того, чтобы запретить роботам Яндекс выдавать информацию в выдаче.
© 1PS.RU, при полном или частичном копировании материала ссылка на первоисточник обязательна.
1ps.ru
Теги noindex и nofollow: как использовать
Тег noindex и атрибут nofollow – это различные элементы, использующиеся в коде страницы. Они предназначены для различных целей и применяются по-разному, но для лучшего понимания их стоит рассматривать вместе.
Тег noindex
Noindex применяется для того, чтобы сообщить роботу «Яндекса» о том, что нельзя индексировать определенные части веб-страницы. Тег размещается в HTML-коде и имеет закрывающий тег. Контент, оказавшийся между открывающим и закрывающим тегами, будет игнорироваться ботом.
Тег noindex был придуман «Яндексом», и в настоящее время только два поисковика учитывают его: «Яндекс» и «Рамблер». Боты других поисковых систем игнорируют тег и все равно индексируют всю веб-страницу полностью. Кроме того, тег не может запретить индексировать гиперссылки и передавать по ним вес другому веб-ресурсу.

Валидность
Тег <noindex> не стандартизирован, поэтому его применение может привести к появлению ошибок в коде. Вследствие этого его записывают немного по-другому. В коде страницы этот тег выглядит так:
<!—noindex—>
«Текст, который не должен индексироваться Яндексом»
<!—/noindex—>
Восклицательные знаки и дефисы применяются для валидации кода. Если не использовать эти символы (а писать без них, как это бывает с обычными тегами), то проверка на валидность будет показывать ошибку.
При верном использовании этого тега страница будет правильно восприниматься «Яндексом», Google и другими поисковыми роботами. При этом «Яндекс» поймет, что часть контента надо исключить из индексации, а Google сделает вывод, что в коде нет ошибок, и будет индексировать полностью. У поисковой системы «Гугл» нет аналогичного тега, несмотря на то, что у такого элемента есть много плюсов.
Когда применяется noindex
Этот тег приносит неоспоримую пользу веб-ресурсу. Его применяют, когда надо:
-
скрыть от ботов часть HTML-кода, например коды счетчиков;
-
запретить индексировать часто меняющийся текст веб-страницы, который бессмысленно добавлять в индекс;
-
скрыть неуникальные фрагменты текста, чтобы не терять позиции в поисковой выдаче из-за неуникальности.
Атрибут nofollow
Nofollow – это не тег, а атрибут, использующийся в теге гиперссылки <a>. Этот атрибут, понятный для всех поисковых роботов, используется для того, чтобы запретить переходить по ссылке и передавать вес по ней.
В коде это выглядит так:
<a href=”гиперссылка” rel=”nofollow”> Текст ссылки </a>
Этот атрибут стандартизирован в HTML, поэтому все поисковые боты правильно воспринимают его и выполняют инструкции: не переходят и не передают вес. При этом ссылка не становится невидимой.

Когда применяется nofollow
Существует много ситуаций, в которых этот атрибут незаменим. Nofollow используется, когда требуется:
-
перераспределить вес между несколькими ссылками на одной веб-странице;
-
поставить ссылку на сайт, у которого другая тематика;
-
запретить передачу веса на веб-ресурс, который поисковики считают некачественным;
-
управлять количеством ссылок, которые должны учитываться поисковыми системами;
-
не допустить передачу веса по множеству ссылок в комментариях.
При использовании nofollow нужно знать меру, потому что сайты, на которых все ссылки закрыты с помощью этого атрибута, не вызывают доверия у поисковиков.
Теги noindex и nofollow могут применяться в качестве значения для атрибута content. Это нужно для того, чтобы в метатеге robots дать указание роботам, что на данной странице не нужно ничего индексировать или переходить по ссылкам, размещенным на ней.
Таким образом, применение nofollow или noindex зависит от целей, которых нужно достичь. В качестве таких целей может быть необходимость скрыть часть текста, ссылки или запретить индексировать всю страницу. При этом noindex работает только для «Яндекса», а nofollow – для всех поисковиков.
Noindex является тегом, а nofollow – атрибутом тега <a>. Noindex используется для того, чтобы запретить индексацию контента, а nofollow предназначен для запрета перехода по ссылке и передачи веса.
www.rookee.ru
Noindex и nofollow – надежные помощники оптимизатора
Зачем использовать тег <noindex> и атрибут rel=«nofollow»
Невзирая на то, что мы упоминаем тег <noindex> и атрибут rel=«nofollow» в пределах одной статьи, они являются совершенно разными элементами кода страниц сайта и соответственно используются для различных целей. Для каких именно, читайте далее по тексту.
Тег <noindex>. Значение и условия применения
Тег <noindex> – размещаемый в HTML-коде странички тег, который запрещает боту поисковой системы Яндекс индексировать часть текста (заключенную внутри него). Тег noindex Яндекс ввел по собственной инициативе, которую до сегодняшнего дня разделяет лишь Рамблер.
Поэтому при использовании тега noindex, Google не будет обращать на него внимания.
Если нужно, чтобы не индексировалась ссылка, noindex не сможет помочь.
В данном примере от индексации будет закрыт лишь анкор «Курсы SEO», а сама ссылка все же будет учтена и по ней передастся вес.
Кстати, довольно часто встречающаяся в сети конструкция rel=«noindex» является ошибочной, поскольку это не атрибут, а тег.
Еще один момент, к которому нужно быть готовым – закрывая от робота часть текста, <noindex> приводит к тому, что валидация сайта будет содержать множество ошибок в коде. Причина все та же: среди тех, кто понимает тег noindex – Яндекс и никто более из существенных поисковиков. Кроме того, этот тег не является стандартизированным.
Но выход все же есть. Для того, чтобы исключить ошибки, связанные с использованием этого тега, существует вариант его написания, который устраивает абсолютно всех:
В этом случае тег будет распознан Яндексом, другие поисковики не обратят на него внимания, а проверка кода не будет воспринимать его, как ошибку.
Несмотря на явную пользу от возможности использовать тег noindex, Google так и не принял его и не создал ничего аналогичного.
Кстати о пользе – вот несколько конкретных ситуаций, в которых данный тег незаменим (не забываем, это актуально только для Яндекса):
- Когда нужно спрятать неуникальный текстовый контент.
- Закрыть от глаз поисковых роботов коды различных счетчиков.
- Убрать из индексации текст, который слишком часто меняется и его добавление в индекс является бессмысленным.
rel=«nofollow». Атрибут, который «работает» со всеми поисковиками
Для того чтобы дать роботу поисковика указание о том, что не нужно переходить и передавать вес по ссылке, существует атрибут тега <a> rel=«nofollow». Он является стандартизированным элементом HTML-кода и воспринимается абсолютно всеми поисковиками.
Причем его использование не делает ссылку невидимой, а лишь указывает, что по ней не нужно переходить и заниматься индексацией страницы, на которую она указывает.
Пример использования:
Использование rel=«nofollow» позволяет:
- Исключить передачу веса на «плохой» (с точки зрения поисковых систем) или нетематичный сайт, чтобы не «испортить» свою репутацию.
- Повлиять на перераспределение веса между присутствующими на странице ссылками.
- Управлять количеством учитываемых исходящих ссылок на страничке.
- Закрыть в комментариях ссылки, по которым не предполагается передача веса.
С использованием атрибута rel=«nofollow» важно не переусердствовать: если постоянно скрывать с его помощью ссылки, это может значительно повлиять на уровень доверия поисковиков к Вашему сайту.
Где еще используются noindex и nofollow
Также noindex и его постоянный спутник nofollow могут использоваться совершенно в ином виде – как значения атрибута content в составе мета-тега robots. Последний, в свою очередь, используется в HTML-коде страницы для указания поисковым ботам рекомендаций насчет индексации страничек и переходу по размещенным на них ссылкам.
Приведенный на скриншоте пример трактуется, как пожелание не выполнять индексацию содержимого странички и не анализировать ссылки, размещенные на ней. Наличие подобной конструкции в теле кода страниц может быть возможной причиной, по которой не индексируется сайт.
Основные выводы
Использование одного из вышеупомянутых элементов (или обоих сразу) зависит от условий, которые преследуются (сокрытие части текста, ссылки или всей страницы при использовании с мета-тегом robots).
Если нужно скрыть от робота Яндекса отдельный текст, noindex это сделает, но когда закрывается ссылка, noindex не поможет. В этом случае следует выбрать атрибут rel=«nofollow», не скрывающий анкор ссылки.
Теперь, когда Вы разобрались с особенностями применения <noindex> и rel=«nofollow», не забудьте поделиться этой важной информацией с теми, кто может в ней нуждаться!
seo-akademiya.com
Noindex и nofollow в метатеге Robots и другие способы запрета индексации
Содержание статьи
Когда нужно запретить индексацию целой категории или ряда страниц, это легче сделать с помощью правильного robots.txt. Но как быть, если требуется закрыть от индексации одну страницу либо вообще часть текста на странице? Поговорим сейчас об элементах, которые призваны решать именно эту проблему.
Что такое мета тег Robots
Сначала уясним, что есть мета тег Robots, а есть файл Robots.txt, и путать их не будем. Метатег имеет отношение только к одной html странице (на которой он указан), в то время, как файл txt может содержать директивы не только к странице, но к целым каталогам.
Важный момент — для поисковика директивы метатега Роботс имеют преимущество перед директивами из robots.txt. То есть если в .txt у вас указано, что страницу можно индексировать, а в её метатеге указано, что нельзя, поисковик будет слушаться именно директиве из метатега.
При помощи мета тега Robots можно запрещать индексировать содержимое всей страницы. На страницах моего блога он выглядит так:
<meta name=»robots» content=»noodp»/>
<meta name=»robots» content=»noodp»/> |
Это означает, что метатег роботс не запрещает индексировать страницу. Noodp тут означает, что он запрещает Google брать в сниппеты описание для страниц из каталога DMOZ — это одна из стандартных настроек плагина Yoast SEO, которым я пользуюсь.
А вот как выглядит метатег Robots, который запрещает индексацию страницы:
<meta name =“robots” content=”noindex,nofollow”/>
<meta name =“robots” content=”noindex,nofollow”/> |
Как прописать
Дедовский способ — вручную прописать для страницы. Способ подходит для сайтов на чистом HTML.
Для сайтов на CMS рекомендую использовать SEO-плагины. Я, например, для WordPress использую плагин Yoast SEO, и там под каждой записью в режиме редактирования есть такая опция:
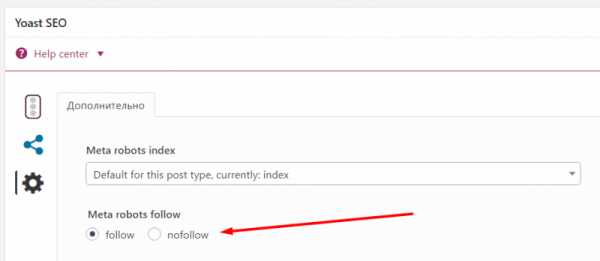
То есть проставить нужное значение можно парой щелчков.
Как использовать noindex и nofollow в meta robots
Посмотрим на возможные значения атрибута content:
- noindex, nofollow – запрещена к индексации вся страница и переходы по ссылкам на ней; кстати, идентичной будет значение при записи: <meta name =”robots” content=”none”/>
- noindex, follow – страница не индексируется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- index, follow – разрешены к индексированию как страница, так и ссылки на ней;
- noarchive – работает как в yandex, так и в google – не показывает страницу на сохраненную копию;
- noyaca – работает только в Яндексе, если сайт зарегистрирован в каталоге YACA – запрещает использовать описание в результатах поиска, которое берется из Яндекс.Каталога; выглядит так: <meta name =”robots” content=”noyaca”/>
- noodp – работает и в Яндексе, и в Google – запрещает использовать в результатах описания, которые взяты из Каталога ДМОЗ (разумеется, если сайт там зарегистрирован).
Поговорим чуть больше о noodp
Иногда Гугл может добавлять в сниппет описание из DMOZ. Именно для этого и используется атрибут noodp. Кстати, его можно использовать вместе с тегом nofollow. Выглядит это так:
<meta name=“robots” content=”noodp, nofollow”/>
<meta name=“robots” content=”noodp, nofollow”/> |
Чего нужно опасаться при использовании
Из-за невнимательности (особенно у новичков) могут случаться конфликты между тегами: в таком случае главным будет положительное значение (разрешающее индексацию). Например тут:
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/>
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/> |
Тут выбрано будет первое значение, так как там оно положительно.
Что такое тег Noindex
Noindex — это тег, в который вы заключаете часть кода, и этот код по идее не должен индексироваться Яндексом. Тег ноиндекс был предложен именно Яндексом, и по сей день учитывается только системами Yandex и Rambler. Вот как он выглядит:
<noindex>скрываемый текст</noindex>
<noindex>скрываемый текст</noindex> |
Noindex – парный тег, и его необходимо закрывать.
Noindex не чувствителен к вложенности.
Целесообразность использования тега
Лично я смысла в его использовании не вижу. Потому что Google этот тег игнорирует. Да и зачем скрывать что-то? Надо делать сайты для людей!
Раньше сеошники скрывали в него часть текста, чтобы не было переспама. Но лично я предпочитаю в целях борьбы с переспамом просто снижать количество ключей в наиболее важных зонах документа.
Если же вы все-таки решили пользоваться этим тегом, то гляньте видео от ТопЭксперт:
Как пользоваться тегом Noindex
Нужно просто обернуть им тег:
<noindex>текст, который нам не нужен</noindex>
<noindex>текст, который нам не нужен</noindex> |
Валидный Noindex
Чтобы сделать его валидным, нужно закомментировать тег. Выглядит это так:
<!- -noindex- ->вот так все норм<!- -/noindex- ->
<!- -noindex- ->вот так все норм<!- -/noindex- -> |
Для чего нужны теги, запрещающие индексацию
Как я писал выше, тег Noindex вообще ни для чего не нужен. Он себя давно изжил. А вот метатег роботс — довольно нужная вещь. Вот примеры ситуаций, когда он бывает полезен:
- На сайте есть какая-то страница, которую бы вы не хотели видеть в индексе. Например, страница с информацией для рекламодателей. А прописывать в роботсе по каким-то причинам не хотите (например, хотите скрыть её от оптимизаторов, которые лазят по чужим роботсам). Тогда вы просто парой щелчков через плагин ставите ноиндекс для этой страницы;
- Поскольку мета тег роботс имеет приоритет перед robots.txt, можно запретить индексирование какой-либо страницы, которая находится в директории, разрешенной для индексации.
Для чего нужен атрибут rel nofollow
Если метатег robots должен закрывать от индексации страницу, а тег noindex — её часть, то атрибут rel nofollow должен запрещать поисковику переходить по ссылке. Он является атрибутом тега А и выглядит так:
<a href =”http://website.ru” <strong>rel=”nofollow”</strong>>скрытая ссылка</a>
<a href =”http://website.ru” <strong>rel=”nofollow”</strong>>скрытая ссылка</a> |
Зеленые вебмастера, которые впервые узнали о рел нофоллоу, сразу думают: «Отлично! Теперь я всем ссылкам его пропишу и вес не будет утекать никуда».
На самом деле поисковик вполне себе переходит по ссылкам с этим атрибутом и они вполне себе забирают ссылочный вес у ваших страниц. То есть смысла в этом атрибуте, как и в noindex, нет. Ссылки закрывать эффективно только через Ajax, да и это я думаю не навсегда. Но, если же вы все-таки решили сконцентрировать внимание на этой точке, которая в лучшем случае даст вам микроскопический рост, то вот еще один видос от ТопЭксперт:
znet.ru
| HTML | WebReference
Поисковый робот Яндекса «ходит» по сайтам, просматривает и анализирует их содержимое, после чего сохраняет указатель на текст и изображения в поисковую базу данных Яндекса. Такой процесс называется индексированием. Часть веб-страницы можно закрыть от индексирования, поместив её внутрь элемента <noindex>. Тогда при следующем посещении веб-страницы поисковый робот проигнорирует такое содержимое и не станет добавлять его в свою базу данных. Это делается по разным причинам, к примеру, закрытые от индексации ссылки не передают ТИЦ (тематический индекс цитирования).
Важно понимать, что это нестандартный элемент и придуман Яндексом для своих целей. Браузеры никак не поддерживают <noindex> и просто выводят его содержимое как обычно.
Если вам нужно закрыть ссылку для поисковиков, добавьте к ней атрибут rel со значением nofollow:
<a href="//webref.ru" rel="nofollow">Ссылка не индексируется</a>Если требуется закрыть для поисковиков всю страницу используйте элемент <meta>, добавив его в код HTML:
<meta name="robots" content="noindex">Или добавьте в файл robots.txt следующую строку:
Disallow: /private.htmlГде private.html адрес страницы.
Закрывающий тег
Пример
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>noindex</title> </head> <body> <noindex> <p>Данный текст Яндекс не будет индексировать.</p> </noindex> </body> </html>
Браузеры
В таблице браузеров применяются следующие обозначения.
- — элемент полностью поддерживается браузером;
- — элемент браузером не воспринимается и игнорируется;
- — при работе возможно появление различных ошибок, либо элемент поддерживается с оговорками.
Число указывает версию браузреа, начиная с которой элемент поддерживается.
×Автор и редакторы
Автор: Клим Щербаков
Последнее изменение: 30.08.2018
Редакторы: Влад Мержевич
webref.ru
NOINDEX и NOFOLLOW – что такое и как использовать
Доброго времени суток, уважаемые читатели. Часто сталкиваюсь с тем, что у многих начинающих вебмастеров и блоггеров полная каша в голове по поводу использования noindex и nofollow. Давайте разберемся что это такое, с чем едят и расставим все точки над i.

Стоит начать с того, чтобы в дальнейшем у вас никогда не было путаницы в голове, что и noindex и nofollow используют в двух относительно разных значениях в web-документе.
Первое – это внутри мета-тега ROBOTS (не путайте с файлом robots.txt) в значении атрибута content. Данный мета-тег имеет отношение ко всему документу в целом. Второе, используется только nofollow – внутри тега <a> и имеет отношение к конкретной ссылке. Про тег noindex немного другая история, и о ней мы также сегодня поговорим. Стоит также отметить, что я буду рассматривать использование nofollow и noindex только в двух поисковых системах – Яндекс и Google.
NOINDEX и NOFOLLOW в мета-теге ROBOTS
Мета-тег robots отвечает за всю страницу целиком. Через данный мета-тег можно запрещать или разрешать индексировать контент страницы.
Noindex отвечает за запрет индексации текста на странице.Nofollow отвечает за запрет индексации ссылок на странице.
Используются данные значения следующим образом:
<meta name="robots" content="noindex, nofollow" />
что означает – данную страницу нельзя индексировать вообще.Могут быть и такие значения:
<meta name="robots" content="index, nofollow" />
можно индексировать контент, но игнорировать ссылки на странице, т.е. не индексировать их.Или так:
<meta name="robots" content="noindex, follow" />
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href="url" rel="nofollow">ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте - нет.
Остановимся подробнее на распределении и передаче веса в Google.Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel="nofollow", а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда.
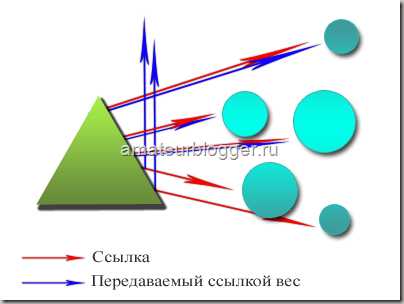
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel="nofollow". Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel="nofollow", сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
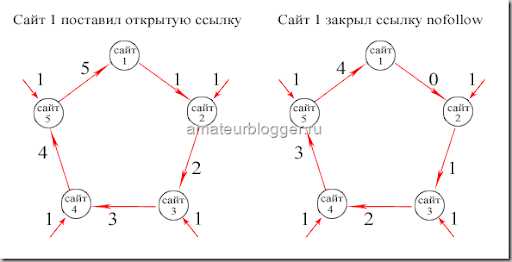
Таким образом, если первый сайт не закрыл ссылку атрибутом rel="nofollow", то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Получается, закрывать ссылки не выгодно?
Это действительно так, но только в том случае, если мы ссылаемся на качественные авторитетные ресурсы.
Закрывать ссылку невыгодно, если вы действительно, по настоящему рекомендуете своим читателям статью, на которую ссылаетесь, свою страничку в социальной сети, на свою ленту RSS. Глупо закрывать ссылки на свои же страницы в социальных сетях, когда рекомендуете своим читателям подписаться на обновления блога через них. Ведь это же ваши собственные страницы, ваша собственная RSS лента, в которой транслируется ваше же содержание. Разве вы сами не отвечаете за него?
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Дополнительно к этому Google рекомендует обозначать продажные ссылки атрибутом rel="nofollow". Также Google пишет, что с помощью nofollow мы можем указать роботу на закрытые разделы нашего сайта, но уточняет, что есть и другие способы указывать на это.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel="nofollow" не только в самих ссылках, т.е. в теге <a>, но и везде, на что только хватает фантазии. И в теге <iframe>, и <script>, и в теге <img>.
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel="nofollow" можно использовать только в теге <a>, и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel="nofollow", а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку. Теперь уделим внимание тегу noindex.
NOINDEX – рудимент от Яндекса
Когда-то Яндекс не понимал значение nofollow, и поэтому придумал свой собственные тег
<noindex>что-то внутри</noindex>
для того, чтобы можно было закрывать неугодные ссылки с его помощью. Все, что находилось внутри данного тега игнорировалось роботом Яндекса. Но с тех пор утекло немало воды, Яндекс повзрослел и начал понимать атрибут rel="nofollow". Случилось это ещё весной 2010 года. Именно тогда тег noindex потерял свое значение в качестве инструмента для закрытия ссылок. Но при этом осталось другое значение – скрывать текстовый контент. Выдержка из раздела Помощь Яндекса:Им рекомендуется скрывать служебные участки текста. О каких служебных участках идет речь – не совсем ясно, но совершенно очевидно, что к ссылкам этот тег теперь не имеет никакого отношения. Т.е. получается, если мы поместим ссылку в данный тег:
<noindex><a href="url">анкор ссылки</a></noindex>
то Яндекс учтет все, кроме анкора ссылки. Т.е. ссылка будет учтена, не будет учтен только текст. Таким образом скрывать ссылки тегом noindex не имеет никакого значения.
Можно смело отказаться от использования данного тега, тем более, учитывая ещё и его невалидность. Ведь по сути такого тега вообще не существует. Как мы знаем, стандарты HTML разрабатывает международная организация W3C, и в спецификации к языку HTML нет такого тега, это полностью выдумка Яндекса.
Остался ещё один вопрос, на который мне хотелось бы обратить ваше внимание. Часто, когда я пытаюсь объяснить то, о чем написала в данной статье, мне возражают:
"Я делаю анализ сайта таким-то инструментом, и он показывает мне, что у меня ссылки не закрыты…
или
инструмент такой-то рекомендует закрыть ссылки тегом noindex.
Вы можете верить всем этим инструментам, это ваше полное право, но не лучше ли верить официальной документации поисковиков, и не лучше ли думать собственной головой?
Удачи в оптимизации сайтов.
amateurblogger.ru
Тег Noindex: используем правильно
Здравствуйте, дорогие посетители!
Если вы попали на данную страницу, то вероятнее всего, что где-то вам посоветовали использовать тег noindex для закрытия какого-либо содержимого от индексации.
В этой статьи я вкратце расскажу, зачем он нужен и особенности его применения. Также покажу, где его применяю я на своем ресурсе.
Общие сведения
Как и в случае с атрибутом nofollow, с которым я рекомендую ознакомиться, noindex имеет значения, как в случае обычного тега, так и мета-тега.
- Тег noindex закрывает от индексации только те части, которые заключены внутри него;
- Мета-тег noindex - закрывает всю страницу от индексирования.
В первом случае, тегом оборачиваются необходимые части текста на страницах, которые не нужно индексировать. Это могут быть служебные участки текста или же какая-то конфиденциальная информация.
Тег можно использовать, как в общепринятом варианте, так и валидном, чтобы сделать код страницы валидным и убрать ошибки за счет тега. Снизу даю 2 строки, первая из которых обычный вариант, а вторая - валидный.
<noindex>тут часть контента, которую нужно закрыть</noindex> <!--noindex-->тут часть контента, которую нужно закрыть<!--/noindex-->
<noindex>тут часть контента, которую нужно закрыть</noindex> <!--noindex-->тут часть контента, которую нужно закрыть<!--/noindex--> |
Какой вариант использовать, решайте сами. Я же пришел ко второму.
В случае же с мета-тегом, noindex добавляется в шапку сайта, что запрещает всю страницу от индексации. Необходим в том же случае (служебные страницы и так далее), только уже для полной страницы.
В данном случае noindex является значением мета-тега robots (см. ниже).
Теперь по поводу использования данного тега.
к содержанию ↑Применение
Как я уже я писал выше, применять его стоит в том случае, если на странице имеется какая-то служебная информация. Также это имеет место, когда имеются неуникальные куски текста, которые пагубно влияют на продвижения страницы. Их также можно закрывать тегом noindex.
Если же взять мета-тег, который применяется ко всей странице и содержится внутри мета-тега robots (скриншот выше), то данный случай стоит применять для закрытия целых страниц от индексации. Это могут быть целые служебные страницы, не несущие никакой пользы сайту и посетителям. Например, страницы контактов, карты сайта и так далее.
Также имеет место закрытие страниц пагинации, то есть тех страниц, которые разбиваются на списки. Например, в постраничной навигации на сайте можно закрыть все страницы, кроме первой, чтобы обезопасить себя от появления дублированного контента.
Хотя, в последнее время я перестал закрывать страницы мета-тегом noindex. Связано это с произведенным мной анализом других популярных сайтов. Я увидел, что никто из гигантов не использует такое закрытие. Исходя из этого, я также убрал. Хотя раньше я добавлял noindex на такие страницы и все работало на ура. Поэтому, если у вас мета-тег добавляется на страницы пагинации, то можете не переживать.
Главное, чтобы сами контентные страницы были полностью открыти и на них не было мета-тега noindex.
Посмотреть его наличие можно в исходном коде страницы, нажав комбинацию клавиш ctrl+u.
Касаемо моего сайта, то я применяю тег и довольно часто, но не в самих статьях, а в самой верстке шаблона. Я закрываю все части, которые не несут смысловой нагрузки сайту:
- социальные кнопки;
- формы подписки;
- на страницах рубрик, архивов и поиска закрываю текст краткого анонса, чтобы не дублировать контент, ведь он доступен и в полной версии статьи.
Проверить закрытые части данным тегом можно с помощью дополнения к браузеру RDS bar.
Вот, как выглядит закрытие формы подписки и социальных кнопок при активном RDS баре (закрытые области подсвечиваются коричневым).
А вот закрытый кусок текста на страницах рубрик, архивов и поиска.
Таким образом можно закрыть очень много ненужного в своем шаблоне.
На этом можно заканчивать данный материал. Больше о данном теге ничего толкового и не скажешь. В окончание хочу сказать, что если вы хотите закрывать внешние ссылки в noindex, то закроется только содержимое ссылки, то есть ее анкор.
Сама же ссылка работать будет и вес также будет передаваться акцептору. Для закрытия внешних ссылок, нужно использовать атрибут nofollow.
Если у вас остались какие-то вопросы по поводу тега noindex, то пишите их в комментариях под блоком похожих записей, которые также можете почитать. Уверяю вас, будет интересно.
Все, друзья. До связи.
С уважением, Константин Хмелев!
kostyakhmelev.ru