
Robots.txt
robots.txt (Роботс) – текстовый файл, который представляет собой один из способов регулирования индексации сайта поисковыми системами. Размещается в основном каталоге с сайтом.
Сведения и принцип работы Robots
Поисковой робот попадает на сайт и обращается к файлу Robots.txt, после анализа этого файла он получает информацию о том, какие категории (папки, разделы, страницы) веб-сайта нужно проигнорировать, а также предоставляет информацию о существующих динамичных параметрах в URL и расположении XML-карты сайта.
Данный файл позволяет убрать из поиска дубли страниц, страницы ошибок и улучшить не только позиции сайта, но и комфортность для пользователя в использовании интернет-ресурсов.
Для создания robots.txt достаточно воспользоваться любым текстовым редактором и создать файл с таким именем. Его необходимо заполнить в соответствии с определенными правилами и загрузить в корневой каталог сайта.
Директива User-agent
Управлять доступом к сайту робота Яндекса можно при помощи созданного файла.
В robots.txt проверяется наличие записей, начинающихся с ‘User-agent:’. В них осуществляется поиск подстроки ‘Yandex’, либо ‘*’.
Пример:
# будет использоваться только основным индексирующим роботом User-agent: YandexBot Disallow: /*id= # будет использована всеми роботами Яндекса, кроме основного индексирующего User-agent: Yandex Disallow: /*sid= # не будет использована роботами Яндекса User-agent: * Disallow: /cgi-bin
Директива Disallow
Для запрета доступа робота к сайту целиком или его частям используется директива ‘Disallow’.
# Пример запрета индексации сайта для поисковой системы Яндекс User-agent: Yandex Disallow: / # Пример запрета индексации страниц, начинающихся с /cgi-bin User-agent: Yandex Disallow: /cgi-bin
Директива Host
При наличии зеркала у сайта специальный робот определит их и сформирует в особую группу. В поиске будет участвовать лишь главное зеркало. В robots.txt вы можете указать имя такого зеркала. Им должно стать значение директивы ‘Host’.
В поиске будет участвовать лишь главное зеркало. В robots.txt вы можете указать имя такого зеркала. Им должно стать значение директивы ‘Host’.
Пример:
# Если www.glavnoye-zerkalo.ru - главное зеркало сайта, то robots.txt # для всех сайтов из группы зеркал выглядит так User-Agent: * Disallow: /forum Disallow: /cgi-bin Host: www.glavnoye-zerkalo.ru
Директива Host должна включать следующие части:
- указание на HTTPS в случае, если зеркало доступно по защищенному каналу;
- корректное доменное имя (одно), не являющееся IP-адресом;
- номер порта (при необходимости).
Все, все, все о Robots.txt — Реклама и продвижение
Robots.txt
Поисковые сервера всегда перед индексацией вашего ресурса ищут в корневом каталоге вашего домена файл с именем «robots.txt» (http://www.mydomain.com/robots.txt). Этот файл сообщает роботам (паукам-индексаторам), какие файлы они могут индексировать, а какие нет.
Формат файла robots.txt — особый. Он состоит из записей. Каждая запись состоит из двух полей: строки с названием клиентского приложения (user-agent), и одной или нескольких строк, начинающихся с директивы Disallow:
<Поле> ":" <значение>
Robots.txt должен создаваться в текстовом формате Unix. Большинство хороших текстовых редакторов уже умеют превращать символы перевода строки Windows в Unix. Либо ваш FTP-клиент должен уметь это делать. Для редактирования не пытайтесь пользоваться HTML-редактором, особенно таким, который не имеет текстового режима отображения кода.
Поле User-agent
Строка User-agent содержит название робота. Например:
User-agent: googlebot
Если вы обращаетесь ко всем роботам, вы можете использовать символ подстановки «*»:
User-agent: *
Названия роботов вы можете найти в логах вашего веб-сервера. Для этого выберите только запросы к файлу robots.txt. большинство поисковых серверов присваивают короткие имена своим паукам-индексаторам.
Для этого выберите только запросы к файлу robots.txt. большинство поисковых серверов присваивают короткие имена своим паукам-индексаторам.
Поле Disallow:
Disallow: email.htm
Директива может содержать и название каталога:
Disallow: /cgi-bin/
Эта директива запрещает паукам-индексаторам лезть в каталог «cgi-bin».
В директивах Disallow могут также использоваться и символы подстановки. Стандарт диктует, что директива /bob запретит паукам индексировать и /bob.html и /bob/index.html.
Если директива Disallow будет пустой, это значит, что робот может индексировать ВСЕ файлы. Как минимум одна директива Disallow должна присутствовать для каждого поля User-agent, чтобы robots.txt считался верным. Полностью пустой robots.txt означает то же самое, как если бы его не было вообще.
Пробелы и комментарии
Любая строка в robots.txt, начинающаяся с #, считается комментарием. Стандарт разрешает использовать комментарии в конце строк с директивами, но это считается плохим стилем:
Disallow: bob #comment
Некоторые пауки не смогут правильно разобрать данную строку и вместо этого поймут ее как запрет на индексацию ресурсов bob#comment. Мораль такова, что комментарии должны быть на отдельной строке.
Пробел в начале строки разрешается, но не рекомендуется.
Disallow: bob #comment
Примеры
Следующая директива разрешает всем роботам индексировать все ресурсы сайта, так как используется символ подстановки «*».
User-agent: *
Disallow:
Эта директива запрещает всем роботам это делать:
User-agent: *
Disallow: /
Данная директива запрещает всем роботам заходить в каталоги «cgi-bin» и «images»:
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Данная директива запрещает роботу Roverdog индексировать все файлы сервера:
User-agent: Roverdog
Данная директива запрещает роботу googlebot индексировать файл cheese. htm:
htm:
User-agent: googlebot
Disallow: cheese.htm
Если вас интересуют более сложные примеры, попутайтесь вытянуть файл robots.txt с какого-нибудь крупного сайта, например CNN или Looksmart.
Дополнения к стандартам
Несмотря на то, что были предложения по расширению стандарта и введению директивы Allow или учета версии робота, эти предложения формально так и не были утверждены.
Поход в поисках robots.txt
При проверке нашего валидатора robots.txt (см. конец статьи), нам понадобилось найти много-много «корма» для него. Мы создали спайдер, который скачивал с каждого найденного сайта лишь один файл robots.txt. Мы прошлись по всем ссылкам и доменам, занесенным в Open Directory Project. Так мы прошлись по 2.4 миллионам URL и накопали файлов robots.txt примерно на 75 килобайт.
Во время этого похода мы обнаружили огромное количество проблем с файлами robots.txt. Мы увидели, что 5% robots.txt плохой стиль, а 2% файлов были настолько плохо написаны, что ни один робот не смог бы их понять. Вот список некоторых проблем, обнаруженных нами:
Перевернутый синтаксис
Одна из самых распространенных ошибок — перевернутый синтаксис:
User-agent: *
Disallow: scooter
А должно быть так:
User-agent: scooter
Disallow: *
Несколько директив Disallow в одной строке:
Многие указывали несколько директив на одной строке:
Disallow: /css/ /cgi-bin/ /images/
Различные пауки поймут эту директиву по разному. Некоторые проигнорируют пробелы и поймут директиву как запрет на индексацию каталога /css//cgi-bin//images/. Либо они возьмут только один каталог (/images/ или /css/) и проигнорируют все остальное.
Правильный синтаксис таков:
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
Перевод строки в формате DOS:
Еще одна распространенная ошибка — редактирование файла robots.
Комментарии в конце строки:
Согласно стандарту, это верно:
Disallow: /cgi-bin/ #this bans robots from our cgi-bin
Но в недавнем прошлом были роботы, которые заглатывали всю строку в качестве директивы. Сейчас нам такие роботы неизвестны, но оправдан ли риск? Размещайте комментарии на отдельной строке.
Пробелы в начале строки:
Disallow: /cgi-bin/
Стандарт ничего не говорит по поводу пробелов, но это считается плохим стилем. И опять-таки, стоит ли рисковать?
Редирект на другую страницу при ошибке 404:
Весьма распространено, когда веб-сервер при ошибке 404 (Файл не найден) выдает клиенту особую страницу. При этом веб-сервер не выдает клиенту код ошибки и даже не делает редиректа. В этом случае робот не понимает, что файл robots.txt отсутствует, вместо этого он получит html-страницу с каким-то сообщением. Конечно никаких проблем здесь возникнуть не должно, но стоит ли рисковать? Бог знает, как разберет робот этот html-файл, приняв его за robots.txt. чтобы этого не происходило, поместите хотя бы пустой robots.txt в корневой каталог вашего веб-сервера.
Конфликты директив:
Чтобы вы сделали на месте робота slurp, увидев данные директивы?
User-agent: *
Disallow: /
#
User-agent: slurp
Disallow:
Первая директива запрещает всем роботам индексировать сайт, но вторая директива разрешает роботу slurp это делать. Так что же все-таки должен делать slurp? Мы не можем гарантировать, что все роботы поймут эти директивы правильно. В данном примере slurp должен проиндексировать весь сайт, а все остальные не должны уйти прямо с порога.
В данном примере slurp должен проиндексировать весь сайт, а все остальные не должны уйти прямо с порога.
Верхний регистр всех букв — плохой стиль:
USER-AGENT: EXCITE
DISALLOW:
Несмотря на то, что стандарт безразлично относится к регистру букв в robots.txt, в именах каталогов и файлов регистр все-таки важен. Лучше всего следовать примерам и в верхнем регистре писать первые буквы только в словах User и Disallow.
Список всех файлов
Еще одна ошибка — перечисление всех файлов в каталоге:
Disallow: /AL/Alabama.html
Disallow: /AL/AR.html
Disallow: /Az/AZ.html
Disallow: /Az/bali.html
Disallow: /Az/bed-breakfast.html
Вышеприведенный пример можно заменить на:
Disallow: /AL
Disallow: /Az
Помните, что начальная наклонная черта обозначает, что речь идет о каталоге. Конечно, ничто не запрещает вам перечислить парочку файлов, но мы речь ведем о стиле. Данный пример взят из файла robots.txt, размер которого превышал 400 килобайт, в нем было упомянуто 4000 файлов! Интересно, сколько роботов-пауков, посмотрев на этот файл, решили больше не приходить на этот сайт.
Есть только директива Disallow!
Нет такой директивы Allow, есть только Disallow. Этот пример неверный:
User-agent: Spot
Disallow: /john/
allow: /jane/
Правильно будет так:
User-agent: Spot
Disallow: /john/
Disallow:
Нет открывающей наклонной черты:
Что должен сделать робот-паук с данной директивой:
User-agent: Spot
Disallow: john
Согласно стандартам эта директива запрещает индексировать файл «john» и каталог john». Но лучше всего, для верности, использовать наклонную черту, чтобы робот мог отличить файл от каталога.
Еще мы видели, как люди записывали в файл robots. txt ключевые слова для своего сайта (подумать только — для чего?).
txt ключевые слова для своего сайта (подумать только — для чего?).
Бывали такие файлы robots.txt, которые были сделаны в виде html-документов. Помните, во FrontPage делать robots.txt не стоит.
Неправильно настроенный сервер
Почему вдруг на запрос robots.txt веб-сервер выдает бинарный файл? Это происходит в том случае, если ваш веб-сервер настроен неправильно, либо вы неправильно закачали на сервер сам файл.
Всегда после того, как вы закачали файл robots.txt на сервер, проверяйте его. Достаточно в броузере набрать простой запрос:
http://www.mydomain.com/robots.txt
Вот и все что нужно для проверки.
Особенности Google:
Google — первый поисковый сервер, который поддерживает в директивах регулярные выражения. Что позволяет запрещать индексацию файлов по их расширениям.
User-agent: googlebot
Disallow: *.cgi
В поле user-agent вам следует использовать имя «googlebot». Не рискуйте давать подобную директиву другим роботам-паукам.
МЕТА-тег robots
МЕТА тег robots служит для того, чтобы разрешать или запрещать роботам, приходящим на сайт, индексировать данную страницу. Кроме того, этот тег предназначен для того, чтобы предлагать роботам пройтись по всем страницам сайта и проиндексировать их. Сейчас этот тег приобретает все большее значение.
Кроме того, этим тегом могут воспользоваться те, кто не может доступиться к корневому каталогу сервера и изменить файл robots.txt.
Некоторые поисковые сервера, такие как Inktomi например, полностью понимают мета-тег robots. Inktomi пройдет по всем страницам сайта если значение данного тега будет «index,follow».
Формат мета-тега Robots
Мета тег robots помещается в тег
html-документа. Формат достаточно прост (регистр букв значения не играет):<HTML>
<HEAD>
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
<META NAME="DESCRIPTION" CONTENT="Эта страница …. ">
">
<TITLE>...</TITLE>
</HEAD>
<BODY>
Значения мета-тега robots
Данному мета-тегу можно присвоить варианта четыре значений. Атрибут content может содержать следующие значения:
index, noindex, follow, nofollow
Если значений несколько, они разделяются запятыми.
В настоящее время лишь следующие значения важны:
Директива INDEX говорит роботу, что данную страницу можно индексировать.
Директива FOLLOW сообщает роботу, что ему разрешается пройтись по ссылкам, присутствующим на данной странице. Некоторые авторы утверждают, что при отсутствии данных значений, поисковые сервера по умолчанию действуют так, как если бы им даны были директивы INDEX и FOLLOW. К сожалению это не так по отношению к поисковому серверу Inktomi. Для Inktomi значения по умолчанию равны «index, nofollow«.
Итак, глобальные директивы выглядят так:
Индексировать всё = INDEX, FOLLOW
Не индексировать ничего = NOINDEX,NOFLLOW
Примеры мета-тега robots:
<META NAME=ROBOTS" CONTENT="NOINDEX, FOLLOW">
<META NAME=ROBOTS" CONTENT="INDEX, NOFOLLOW">
<META NAME=ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
Валидатор robots.txt
| Валидатор Robots.txt |
« назад к списку статей
User-agent: * # правила для всех роботов
Disallow: /cgi-bin # папка на хостинге
Disallow: /bitrix/ # папка с системными файлами битрикса
Disallow: *bitrix_*= # GET-запросы битрикса
Disallow: /local/ # папка с системными файлами битрикса
Disallow: /*index.php$ # дубли страниц index.php
Disallow: /auth/ # авторизация
Disallow: *auth= # авторизация
Disallow: /personal/ # личный кабинет
Disallow: *register= # регистрация
Disallow: *forgot_password= # забыли пароль
Disallow: *change_password= # изменить пароль
Disallow: *login= # логин
Disallow: *logout= # выход
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url= # трекбеки
Disallow: *back_url_admin= # трекбеки
Disallow: *captcha # каптча
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открываем папку с файлами uploads
Allow: /bitrix/*. js # здесь и далее открываем для индексации скрипты
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif # Укажите один или несколько файлов Sitemap
Sitemap: https://apertosib.ru/sitemap.xml # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: https://apertosib.ru
js # здесь и далее открываем для индексации скрипты
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif # Укажите один или несколько файлов Sitemap
Sitemap: https://apertosib.ru/sitemap.xml # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: https://apertosib.ru
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest. xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://medgalaxy-clinic.ru/sitemap.xml
Sitemap: http://medgalaxy-clinic.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем).
xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://medgalaxy-clinic.ru/sitemap.xml
Sitemap: http://medgalaxy-clinic.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: medgalaxy-clinic.ru
Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: medgalaxy-clinic.ru
Исправляем ошибки в robots.txt
Что такое robots.txt?
Robots.txt — это текстовый файл, расположенный в корневом каталоге сайта, в котором прописаны указания по индексации страниц для поисковых роботов. С помощью данного файла мы можем указывать поисковым системам, какие страницы на web-ресурсе нужно сканировать, а какие — нет.
Почему robots.txt важен для продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Например, в нем можно запретить к индексации мусорные или некачественные страницы, а также закрыть системную информацию CMS, например, страницу с доступом в административную панель.
Dissalow: /admin
Инструкция по использованию robots.txt
Какие директивы используются в robots.txt
User-agent — основная директива, которая указывает, для какого поискового робота прописаны дальнейшие указания по индексации, например:
Для всех роботов:
User-agent: *Для поискового робота Яндекс:
User-agent: YandexDisallow и Allow. Disallow — закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации.
Операторы, которые используются с этими директивами:
* — этот спецсимвол обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: * Disallow: /cgi-bin* # блокирует доступ к страницам # начинающимся с '/cgi-bin' Disallow: /cgi-bin # то же самое$ — используется, чтобы отменить * на конце правила, например:
User-agent: * Disallow: /example$ # запрещает '/example', # но не запрещает '/example. html'
html'
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
- Clean-param — используется в случае, если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое. Подробнее прочитать про эту директиву можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap — карта сайта для поисковых роботов, которая содержит всю иерархическую структуру web-ресурса. Помогает поисковым роботам быстрее индексировать страницы сайта. В robots.txt следует указать путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: site.ru/sitemap.xml
 html'
html'Пример правильно составленного файла robots.txt:
User-agent: * # сайт могут индексировать все поисковые роботы Allow: / # сайт открыт для индексации Sitemap: http://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как обнаружить ошибки в robots.txt с помощью сервиса Labrika
Отчет «Ошибки в robots.txt» находится в разделе «Технический аудит» левого бокового меню.
В случае, если при создании или редактировании файла вы допустили ошибку, Labrika вам укажет, где именно находится ошибка, и после этого вы сможете ее самостоятельно исправить.
Пример страницы с отчетом:
- При нажатии на эту кнопку вы обновите данные о наличии ошибок в файле robots.txt.
- Директива, в которой находится ошибка.
- Ошибка, которую обнаружила Labrika
С помощью этого отчета вы сможете постоянно поддерживать файл robots.txt в рабочем состоянии и вовремя исправлять все ошибки.
О том, как написать правильный robots.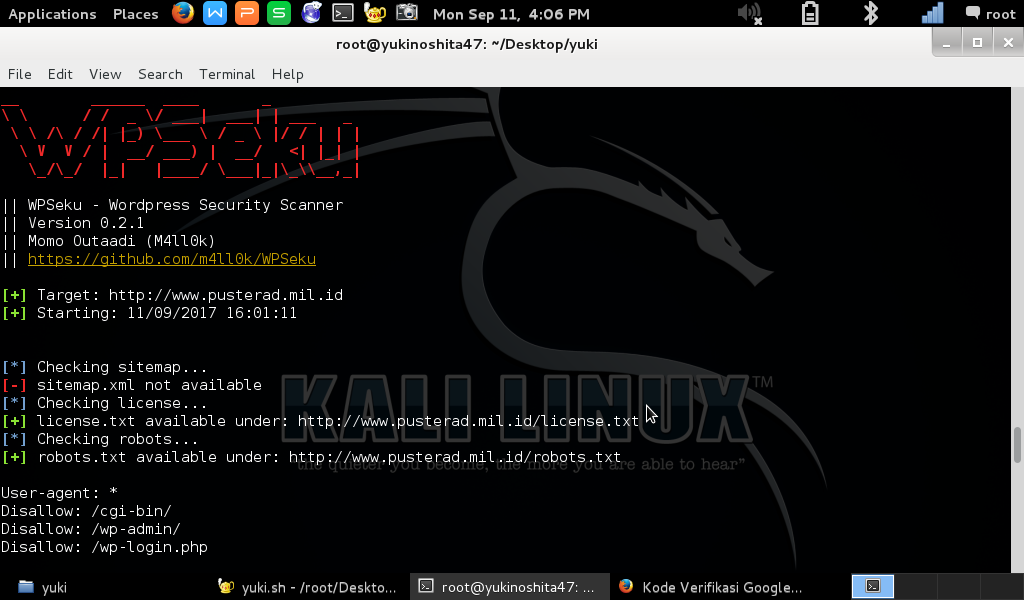 txt, вы можете прочитать в нашей статье.
txt, вы можете прочитать в нашей статье.
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /dt_headers/*
Disallow: /dt_portfolios/*
Disallow: /dt_footers/*
Disallow: /product-category/*
Disallow: /акции/page/*
Disallow: /салат-с-куриной-печенью-2/
Disallow: /product/*
Disallow: /category/uncategorized/
Disallow: /product/*
Disallow: /121-2/
Disallow: /portfolio_entries/*
Disallow: /restoran-moscow/меню-ресторана-smakunoff/*
Disallow: /канапе-из-сыра-с-фруктами-2/
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest. xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Disallow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Disallow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /dt_headers/*
Disallow: /dt_portfolios/*
Disallow: /dt_footers/*
Disallow: /product-category/*
Disallow: /акции/page/*
Disallow: /салат-с-куриной-печенью-2/
Disallow: /product/*
Disallow: /category/uncategorized/
Disallow: /product/*
Disallow: /121-2/
Disallow: /portfolio_entries/*
Disallow: /restoran-moscow/меню-ресторана-smakunoff/*
Disallow: /канапе-из-сыра-с-фруктами-2/
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Disallow: /*/*.js
Disallow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).
xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Disallow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Disallow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /dt_headers/*
Disallow: /dt_portfolios/*
Disallow: /dt_footers/*
Disallow: /product-category/*
Disallow: /акции/page/*
Disallow: /салат-с-куриной-печенью-2/
Disallow: /product/*
Disallow: /category/uncategorized/
Disallow: /product/*
Disallow: /121-2/
Disallow: /portfolio_entries/*
Disallow: /restoran-moscow/меню-ресторана-smakunoff/*
Disallow: /канапе-из-сыра-с-фруктами-2/
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Disallow: /*/*.js
Disallow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).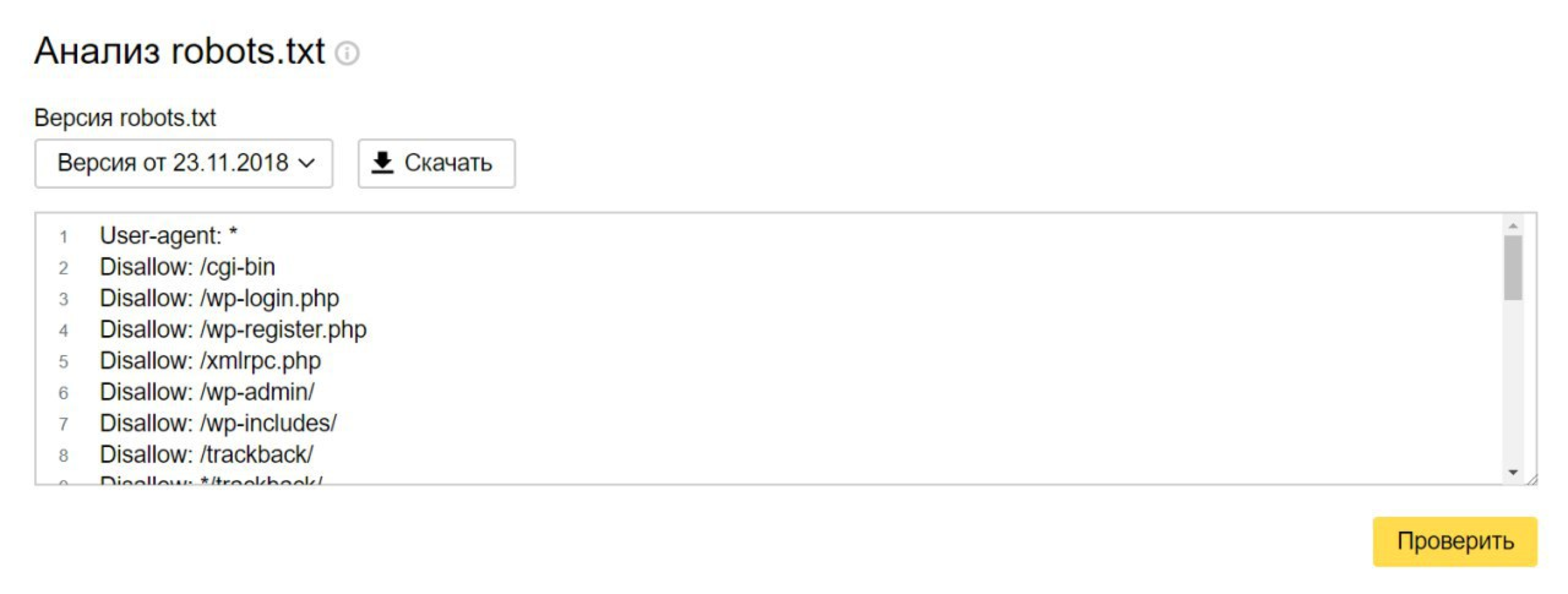 Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: https://hotelinside.ru/sitemap.xml
Sitemap: https://hotelinside.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: hotelinside.ru
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: https://hotelinside.ru/sitemap.xml
Sitemap: https://hotelinside.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: hotelinside.ru
Правильный Robots.txt для WordPress
Загрузка…Оригинал статьи в блоге Дениса Биштейнова https://seogio.ru/robots-txt-dlya-wordpress/
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruРасширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc. php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Disallow: /*attachment*
Disallow: /cart # для WooCommerce
Disallow: /checkout # для WooCommerce
Disallow: *?filter* # для WooCommerce
Disallow: *?add-to-cart* # для WooCommerce
Clean-param: add-to-cart # для WooCommerce
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Disallow: /*attachment*
Disallow: /cart # для WooCommerce
Disallow: /checkout # для WooCommerce
Disallow: *?filter* # для WooCommerce
Disallow: *?add-to-cart* # для WooCommerce
Clean-param: add-to-cart # для WooCommerce
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).
php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Disallow: /*attachment*
Disallow: /cart # для WooCommerce
Disallow: /checkout # для WooCommerce
Disallow: *?filter* # для WooCommerce
Disallow: *?add-to-cart* # для WooCommerce
Clean-param: add-to-cart # для WooCommerce
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruВ примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает).
Ошибочные рекомендации
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. - Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тегrel="canonical", таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. - Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше.

Спорные рекомендации
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
UPD: Нашёл статью Prevent robots crawling “add-to-cart” links on WooCommerce (Не давайте роботам обходить ссылки WooCommerce “добавить в корзину”) в которой наглядно показывается результат закрытия ссылок с параметром ?add-to-cart=.
Но Яндекс всё равно продолжает индексировать эти ссылки. Нашёл в справке Яндекса, как можно их закрывать — через директиву Clean-param (https://yandex.ru/support/webmaster/robot-workings/clean-param.html).
Поэтому добавил в robots.txt эту директиву.
Поделиться
Поделиться
Отправить
Вотсапнуть
Твитнуть
Как использовать Robots.txt — FreeFind.com
Предпочтительный способ предотвращения индексации частей вашего сайта
заключается в использовании механизма исключения страниц Центра управления. Это описано в Как исключить страницы из поиска .
Вы должны сначала прочитать это «как».
Единственная причина, по которой вам может понадобиться
Это описано в Как исключить страницы из поиска .
Вы должны сначала прочитать это «как».
Единственная причина, по которой вам может понадобиться robots.txt файл, если вы хотите запретить кому-либо использовать эту поисковую систему
проиндексировать ваш сайт.
СОДЕРЖАНИЕ
Обзор
Примеры
Ссылка Роботы дюймов.txt " файлов
это файл текста , размещенный на вашем сервере, который содержит список роботов
и «запрещает» для этих роботов.
Каждое запрещение предотвращает любой адрес, который начинается с запрещенной строки.
от доступа.
Это руководство не является учебником по веб / HTML и предполагает, что вы уже знаете как выполняется процесс «веб-серфинга» (т.е. браузер запрашивает страницу с сервера, который затем возвращает страницу для просмотра), что такое HTML-форма и как она работает, и что такое ссылка «цель».Если вы не знакомы с этими концепциями, пожалуйста, прочтите базовое руководство по веб / HTML.
Использовать файл robots.txt просто,
но требует доступа к корневому каталогу вашего сервера.
Например, если ваш сайт находится по адресу:
http://example.com/mysite/index.htmlвам нужно будет создать файл, расположенный здесь:
http://example.com/robots.txt
Если вы не можете получить доступ к корневому каталогу вашего сервера, вы не сможете использовать robots.txt файл, чтобы исключить страницы из вашего индекса.
robots.txt — это файл TEXT (не HTML!)
в котором есть секция для каждого управляемого робота.
В каждом разделе есть строка user-agent , которая называет робота, которым нужно управлять, и имеет список «запрещает» и «разрешает».
Каждое запрещение предотвращает любой адрес, который начинается с запрещенной строки.
от доступа.
Точно так же каждое разрешение разрешит любой адрес, который начинается с разрешенной строки.
от доступа.Разрешения (dis) сканируются по порядку, при этом последнее обнаруженное совпадение определяет
разрешено ли использование адреса. Если совпадений нет, будет использован адрес.
Если совпадений нет, будет использован адрес.
Вот пример:
пользовательский агент: FreeFind запретить: / mysite / test / запретить: /mysite/cgi-bin/post.cgi?action=reply запретить: / aВ этом примере следующие адреса будут игнорируется пауком:
http: // пример.com / mysite / test / index.html http://example.com/mysite/cgi-bin/post.cgi?action=reply&id=1 http://example.com/mysite/cgi-bin/post.cgi?action=replytome http://example.com/abc.htmlи разрешены следующие:
http://example.com/mysite/test.html http://example.com/mysite/cgi-bin/post.cgi?action=edit http://example.com/mysite/cgi-bin/post.cgi http://example.com/bbc.htmlТакже можно использовать «разрешить» в дополнение к запретам.Например:
пользовательский агент: FreeFind запретить: / cgi-bin / разрешить: /cgi-bin/Ultimate.cgi разрешить: /cgi-bin/forumdisplay.cgiЭтот файл
robots.txt не позволяет пауку
доступ к каждому адресу cgi-bin от доступа кроме Ultimate.cgi и forumdisplay.cgi . Использование позволяет упростить файл robots.txt .
Вот еще один пример, который показывает robots.txt с
в нем два раздела. Один для «всех» роботов и один для паука FreeFind:
пользовательский агент: * запретить: / cgi-bin / пользовательский агент: FreeFind запретить:В этом примере всем роботам, кроме паука FreeFind, будет запрещено доступ к файлам в каталоге
cgi-bin .
FreeFind сможет получить доступ ко всем файлам (запрет, после которого ничего не указано).
означает «разрешить все»).В этом разделе есть несколько удобных примеров.
Чтобы FreeFind вообще не индексировал ваш сайт:
пользовательский агент: FreeFind запретить: /
Чтобы FreeFind не индексировал общий мусор карты изображений на главной странице:
пользовательский агент: FreeFind запретить: /_vti_bin/shtml.
 exe/
exe/
Чтобы запретить FreeFind индексировать тестовый каталог и личный файл:
пользовательский агент: FreeFind запретить: / test / запретить: частный.html
Чтобы разрешить FreeFind индексировать все, но запретить другим роботам доступ к определенным файлам:
пользовательский агент: * запретить: / cgi-bin / запретить: this.html запретить: and.html запретить: that.html пользовательский агент: FreeFind запретить:
Информация об исключении роботов
Рабочие с файлами robots.txt ФайлыRobot.txt предоставляют протокол, который поможет всем поисковым системам перемещаться по веб-сайту.Если вопросы соблюдения конфиденциальности или конфиденциальности являются проблемой, мы предлагаем вы определяете папки на своем веб-сайте, которые следует исключить из поиск. Используя файл robots.txt, эти папки можно сделать закрытыми. Следующее обсуждение роботов будет часто обновляться.
Робот Ultraseek уважает использование файла robots.txt. Запуск по корневому URL-адресу, паук проходит по сайту на основе ссылок из этого корня. Файл robots.txt также поможет другим поисковым системам. просматривать ваш веб-сайт, исключая вход в нежелательные области.
Чтобы облегчить это, многие веб-роботы предлагают средства для администраторов веб-сайтов. и контент-провайдеры, ограничивающие деятельность роботов. Это исключение может быть достигается с помощью двух механизмов:
Протокол исключения роботов
Администратор веб-сайта может указать, какие части сайта следует не должны посещаться роботом, предоставив специально отформатированный файл на своем сайт в http: //…/robots.txt.
Файл robots.txt должен находиться в корневом каталоге. веб-сайта!
| URL сайта | Роботы-корреспонденты.txt URL |
|---|---|
| http://www.state.mn.us/ | http://www. state.mn.us/robots.txt |
| http://www.state.mn.us:80/ | http://www.state.mn.us:80/robots.txt |
Пользовательский агент: *
Disallow: / cgi-bin /
Disallow: / test /
Disallow: / ~ dept /
В этом примере исключены три каталога.
Строка User-agent указывает, каким роботам разрешено входить в
сайт.В этом случае * означает, что все роботы могут пройти. Ты
нужна отдельная строка «Disallow» для каждого префикса URL, который вы хотите
исключать; нельзя сказать «Disallow: / cgi-bin / / tmp /».
Кроме того, у вас может не быть пустых строк в записи, потому что они используются
чтобы ограничить несколько записей. Пример файла robots.txt
файл можно найти на сайте Bridges.
Мета-тег роботов
Веб-автор может указать, может ли страница быть проиндексирована или проанализирована на предмет ссылок с помощью специального тега HTML META.Тег выглядит как тот ниже и будет расположен с другими метатегами в области
веб-страницаВ теге META робота есть директивы, разделенные запятыми. В Директива INDEX предписывает роботу индексирования проиндексировать страницу. Директива FOLLOW указывает робота, который будет переходить по ссылкам на странице. И INDEX, и FOLLOW являются по умолчанию. Значения ALL и NONE включают или выключают все директивы: ALL = INDEX, FOLLOW и NONE = NOINDEX, NOFOLLOW.
Вот несколько примеров:
К сожалению, у этого метатега есть несколько недостатков: мало роботов придерживаются соответствует стандарту, и не многие люди знают и используют метатег Robots.Кроме того, нет отдельного исключения для роботов.
 Это может скоро измениться.
Это может скоро измениться.Для получения дополнительной информации о роботах посетите Страницы веб-роботов
Robot.txt — Helpjuice
Владельцы веб-сайтов используют файл /robots.txt для передачи инструкций веб-роботам о своем сайте; это называется Протокол исключения роботов .
Это работает примерно так: робот хочет посетить URL-адрес веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это сделать, он сначала проверяет наличие http: // www.example.com/robots.txt и находит:
User-agent: * Disallow: /
«User-agent: *» означает, что этот раздел применяется ко всем роботам. «Disallow: /» сообщает роботу, что он не должен посещать какие-либо страницы сайта.
При использовании /robots.txt следует учитывать два важных момента:
- Роботы могут игнорировать ваш /robots.txt. В частности, вредоносные роботы, которые сканируют веб-сайты на предмет уязвимостей безопасности, и сборщики адресов электронной почты, используемые спамерами, не будут обращать на них внимания.
- файл /robots.txt является общедоступным. Кто угодно может увидеть, какие разделы вашего сервера вы не хотите, чтобы роботы использовали.
Как использовать
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись, которая выглядит следующим образом:
User-agent: * Disallow: / cgi-bin / Запрещение: / tmp / Disallow: / ~ joe /
В этом примере исключены три каталога.
Обратите внимание, что вам нужна отдельная строка «Disallow» для каждого префикса URL, который вы хотите исключить — вы не можете сказать «Disallow: / cgi-bin / / tmp /» в отдельной строке.Кроме того, в записи может не быть пустых строк, поскольку они используются для разделения нескольких записей.
Обратите внимание, что подстановка и регулярное выражение не поддерживаются ни в User-agent, ни в Disallowlines.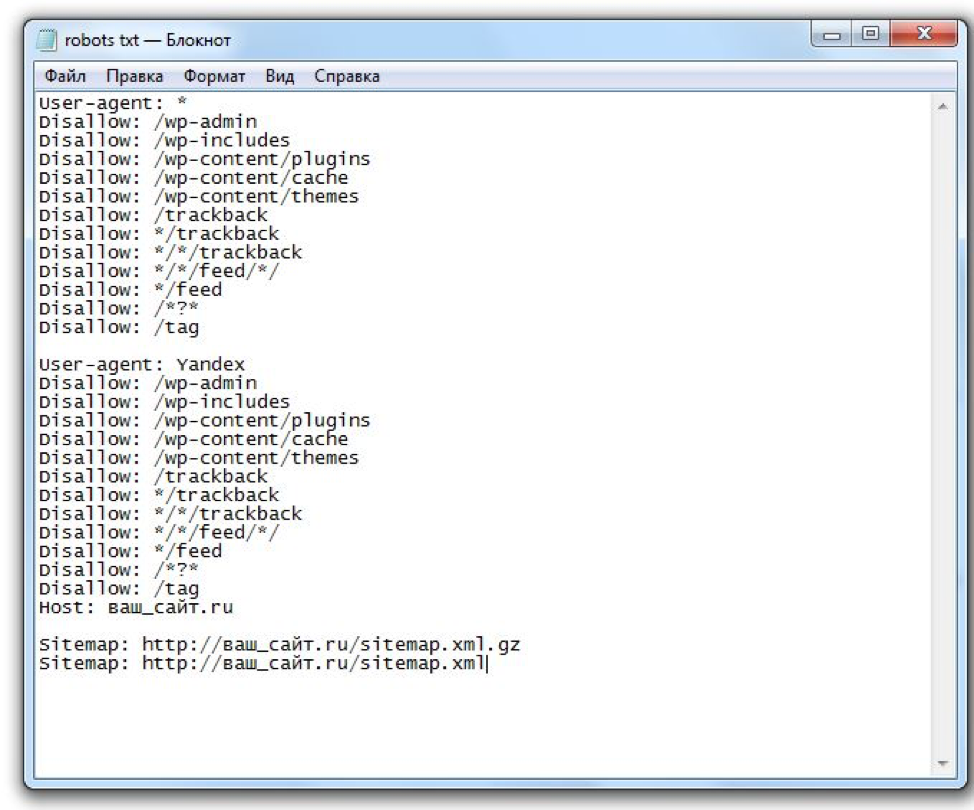 ‘*’ В поле User-agent — это специальное значение, означающее «anyrobot». В частности, у вас не может быть таких строк, как «User-agent: * bot *», «Disallow: / tmp / *» или «Disallow: * .gif».
‘*’ В поле User-agent — это специальное значение, означающее «anyrobot». В частности, у вас не может быть таких строк, как «User-agent: * bot *», «Disallow: / tmp / *» или «Disallow: * .gif».
То, что вы хотите исключить, зависит от вашего сервера. Все, что явно не запрещено, считается получением справедливой игры.Вот несколько примеров:
Чтобы исключить всех роботов со всего сервера
User-agent: * Запретить: /
Разрешить всем роботам полный доступ
User-agent: * Disallow:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
User-agent: * Disallow: / cgi-bin / Запрещение: / tmp / Disallow: / junk /
Чтобы исключить одного робота
User-agent: BadBot Disallow: /
Разрешить одного робота
User-agent: Google Запретить: Пользовательский агент: * Disallow: /
Чтобы исключить все файлы, кроме одного
В настоящее время это немного неудобно, поскольку нет поля «Разрешить».Самый простой способ — поместить все файлы, которые должны быть запрещены, в отдельный каталог, скажем «stuff», и оставить один файл на уровне выше этого каталога:
User-agent: * Disallow: / ~ joe / stuff /
В качестве альтернативы вы можете явно запретить все запрещенные страницы:
User-agent: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Disallow: /~joe/bar.html
шрифт: http://www.robotstxt.org/robotstxt.html
Была ли эта статья полезной?
Оставьте отзыв об этой статьеЧто такое роботы.txt файл?
Что такое файл Robots.txt?
Robots.txt — это дополнительный файл веб-сервера, используемый для предотвращения доступа роботов поисковых систем и других поисковых роботов к веб-сайту или его части.
Стандарт исключения роботов не подлежит исполнению; однако наиболее авторитетные сканеры будут соблюдать директивы в файле robots.txt.
Google не будет сканировать или индексировать страницы, заблокированные файлом robots.txt, но все же может индексировать контент, если на него есть ссылки из других источников в Интернете.Лучшим методом предотвращения включения веб-страницы в индекс Google является метатег noindex для роботов.
Robots.txt с экономией трафика
Хороший аргумент в пользу использования файла robots.txt — это экономия полосы пропускания сервера. Запрет доступа роботов к веб-страницам или изображениям, которые не нужно индексировать, сэкономит пропускную способность при каждом сканировании веб-сайта.
Фактически, наличие одного только файла robots.txt может сэкономить полосу пропускания: поскольку большинство поисковых роботов пытаются получить роботов.txt перед попыткой доступа к веб-сайту, отсутствие файла robots.txt вызовет ошибку 404. Если на веб-сайте есть настраиваемых страниц ошибок , постоянные 404-е страницы будут использовать дополнительную пропускную способность впустую.
Как создать файл Robots.txt
Для создания файла robots.txt правила добавляются в простой текстовый файл, который должен называться robots.txt , а файл добавляется в корневой каталог домена или субдомена.
Основные примеры записей Robots.txt
Запретить всех веб-пауков для всего сайта:
Агент пользователя: *
Disallow: / Разрешить всем веб-паукам для всего сайта:
Агент пользователя: *
Disallow: Запретить всем веб-паукам для изображений , cgi-bin и tmp каталогов:
Агент пользователя: *
Запретить: / images /
Disallow: / cgi-bin /
Запрещение: / tmp / Запретить Googlebot для каталога около , за исключением одного конкретного файла:
Пользовательский агент: Googlebot
Disallow: / about /
Разрешить: / о / персонал. html  html
html Внешние ссылки
Вернуться к глоссарию Springboard SEO Получите предложение или позвоните нам: 1-800-514-5796Что такое robots.txt? Ответы на вопросы веб-дизайна от 3D Digital
Люди всегда спрашивают , что такое robots.txt? Это просто текстовый файл. В нем содержатся директивы или инструкции для сканеров поисковых систем о том, какие части вашего сайта могут сканироваться, а какие — нет. Разрешив поисковым системам сканировать контент на вашем сайте, вы также разрешаете им индексировать контент с вашего сайта.Индексирование позволяет отображать ваш контент в результатах поиска.
Если вас интересуют дополнительные варианты сканирования страницы без индексации содержимого — возможно, вы хотите, чтобы поисковый робот переходил по ссылкам на странице для доступа к другому содержимому, которое вы действительно хотите проиндексировать, — тогда эта статья о мета-роботах является хорошим ресурсом.
Как работает Robots.txt
Первое, что делает сканер поисковой системы, попадая на веб-сайт, — проверяет наличие файла robots.txt. Директивы в этом файле ассимилируются перед тем, как поисковый робот перейдет к просмотру страницы.
Robots.txt не является обязательным требованием для веб-сайта. Если у вас нет конкретных критериев для пользовательских агентов, то вам, скорее всего, не нужно их включать. Если его не существует, поисковый робот предполагает, что все страницы и контент на сайте могут сканироваться и индексироваться поисковыми системами.
Хотя это и есть robots.txt, и он описывает, что он делает, есть еще кое-что, что вам нужно понять, прежде чем приступить к созданию или редактированию собственного файла robots.txt.
Где роботы.txt Находится?
Файл должен быть помещен в корневой каталог сайта, чтобы сканеры могли его найти.
Самый простой способ определить, правильно ли установлен файл robots.txt на вашем веб-сайте, — это ввести http://your-domain.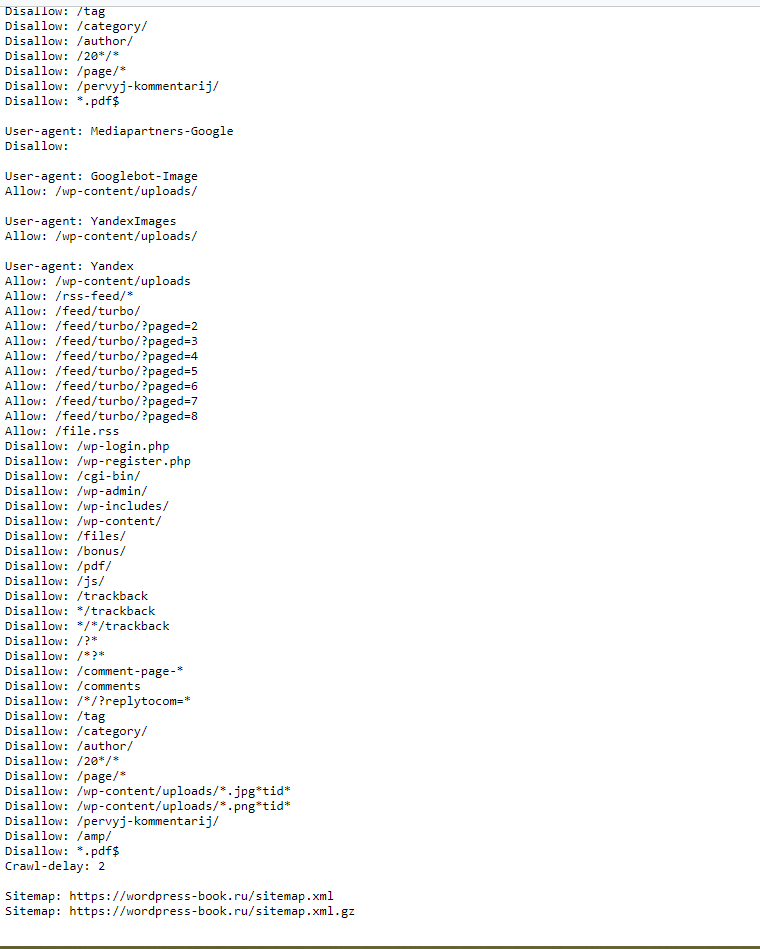 com/robots.txt в адресную строку браузера.
com/robots.txt в адресную строку браузера.
Если он существует, вы увидите контент, похожий на этот:
User-agent: *
Disallow:
В противном случае, если файл robots.txt не существует, ваш браузер выдаст ошибку «страница не найдена».
Как интерпретировать Robots.txt
Один файл robots.txt может содержать один или несколько наборов директив. Несколько наборов должны быть разделены одной пустой строкой. В последовательности набора не может быть пустых строк.
Набор начинается с агента пользователя, за которым следует одна или несколько директив.
User-agent: Googlebot
Disallow: / * private-html /
Disallow: / cgi-bin /
Карта сайта: https://my-domain.com/sitemap.xml/
Каждая директива применяется только к пользовательскому агенту, указанному в наборе.Вот четыре основных варианта директивы:
- Запретить
- Разрешить (работает только с Googlebot)
- Задержка сканирования (работает со всеми сканерами, кроме Googlebot)
- Карта сайта
Могут быть случаи, когда правила применяются более чем к одному пользовательскому агенту. В этом случае наиболее конкретный набор инструкций будет выполняться для пользовательского агента перед всеми остальными.
Обычные пользовательские агенты поисковых систем включают:
- Googlebot
- Googlebot-Image
- Msnbot
- Бингбот
- Slurp (агент пользователя Yahoo)
- Facebot (пользовательский агент Facebook)
Стоит отметить, что существует множество типов пользовательских агентов, но только те, которые следует учитывать в robots.txt — это сканеры поисковых систем. Помните, что мы инструктируем сканеров поисковых систем, как продолжить сканирование и индексирование нашего содержания в robots.txt.
Даже если в robots.txt можно указать конкретные директивы, их интерпретация остается на усмотрение отдельных поисковых роботов. Технически пользовательские агенты могут не придерживаться определенных директив (хотя, как правило, это не обычные пользовательские агенты, а скорее вредоносные боты и тому подобное).
Звездочка (*) в роботах.txt
Эта звездочка очень важна. Этот специальный символ указывает на нечто всеобъемлющее.
Например:
- Когда вы видите User-agent: *, это буквально означает все сканеры поисковых систем.
- Когда вы видите Disallow: / * private /, это означает блокировать каждое имя файла, которое заканчивается символами «private».
Как создать файл Robots.txt
Вам нужен текстовый редактор. Некоторые популярные текстовые редакторы — Блокнот, TextPad, Brackets и Atom.Существует множество текстовых редакторов, многие из которых можно загрузить бесплатно.
- Создайте новый файл.
- Напишите директивы сканирования для ваших страниц.
- Каждый набор должен адресовать только один пользовательский агент или использовать звездочку.
- Каждый может содержать несколько директив.
- Каждый набор должен быть разделен одной пустой строкой.
- Его необходимо сохранить как текстовый файл. Сохраните как: robots.txt .
- Загрузите файл в корневой каталог вашего веб-сайта.Когда вы вводите следующий URL-адрес в браузере (конечно, используя ваш реальный домен), появляется содержимое robots.txt.
http://www.my-domain.com/robots.txt
Помимо написания директив обхода контента, robots.txt — очень эффективный метод сообщения поисковым системам, где находятся ваши карты сайта.
Например:
User-agent: *
Карта сайта: https://www.my-domain.com/sitemap.xml
В этом примере директива сообщает всем сканерам поисковых систем, что карта сайта, которой следует следовать, находится в корневом каталоге веб-сайта в файле с именем карта сайта.xml.
Другие примеры
Чтобы сканеры поисковых систем могли сканировать все на вашем сайте:
User-agent: *
Disallow:
Чтобы запретить или запретить сканерам поисковых систем сканировать все на вашем сайте:
User-agent: *
Disallow: /
Если вы хотите, чтобы поиск картинок Google не сканировал и не индексировал фотографии на вашем сайте:
User-agent: Googlebot-Image
Disallow: /
Если вы хотите заблокировать сканирование и индексирование отдельных веб-страниц:
User-agent: *
Disallow: / private_page.html /
Запретить: /private/financial_docs.xls/
Если вы хотите запретить роботу часть сервера:
User-agent: *
Disallow: / cgi-bin /
Disallow: / temp /
Если вы хотите запретить сканирование определенных типов файлов:
User-agent: *
Disallow: /*.pdf$/
Если вы хотите запретить использование любого имени файла, содержащего определенную последовательность символов:
Содержит частное в имени файла:
User-agent: *
Disallow: / * private * /
Имя файла, которое начинается с частного:
User-agent: *
Disallow: / private * /
Имя файла, заканчивающееся на частное:
User-agent: *
Disallow: / * private /
По конкретным вопросам, касающимся директив поиска, обращайтесь к нам через раздел комментариев ниже.
Чтобы узнать больше о наших веб-службах, посетите нашу страницу веб-дизайна. Если вас интересуют другие наши цифровые услуги или вы хотите получить расценки, мы будем рады обсудить с вами ваш проект. Позвоните нам по телефону 904-330-0904.
2.16 Имеет ли значение Robots.txt?
К вашему удивлению, есть небольшие текстовые файлы, которые на самом деле отвечают за рейтинг вашего сайта. Одна небольшая ошибка может либо испортить ваш сайт, либо привести к тому, что поисковые системы не будут сканировать ваш сайт, т.е. ваши веб-страницы не будут отображаться на странице результатов поиска.
Следовательно, очень важно понимать, как работает файл Robots.txt.
Что такое Robots.txt?
Robots.txt — это текстовый файл, который вы размещаете на своем веб-сайте, чтобы указать поисковым роботам, какие страницы вы бы хотели, чтобы они не посещали. Установив некоторые правила в текстовом файле, вы можете приказать роботам не сканировать и не индексировать определенные файлы, страницы вашего сайта.
Допустим, мы не хотим, чтобы поисковая система сканировала или посещала раздел изображений на сайте, поскольку она использует пропускную способность сайта и может быть бессмысленной, Роботы.txt сообщает об этом Google. Веб-разработчики могут использовать robots.txt для поддержания связи с веб-роботами, получая доступ ко всем или частям вашего веб-сайта, которые вы хотите сохранить в тайне. Файл robots.txt не является обязательным для поисковых систем. Как правило, поисковые системы следят за тем, что их просят сделать.
Проще говоря, robots.txt используется, когда веб-мастер не хочет, чтобы поисковые системы сканировали определенные каталоги, страницы или URL-адреса.
Действительно ли Robots.txt важен. Как это влияет на сайт?
Роботы.txt важен или нет, полностью зависит от вебмастера; Если веб-мастер хочет скрыть некоторую информацию или веб-страницы от сканирования поисковыми системами, файл важен, а если нет, то нет необходимости использовать файл robots.txt.
Несколько причин для использования файла robots.txt на вашем веб-сайте:
- Сохраняет пропускную способность сервера — Сканер не сможет сканировать те веб-страницы, на которых нет важной информации.
- Обеспечивает защиту — Хотя и не является отличным источником безопасности, но каким-то образом не позволяет поисковым системам достигать того, чего вы не хотите, чтобы поисковые системы достигли.Людям на самом деле придется посетить ваш сайт, а затем перейти в каталог, вместо того, чтобы находить его в поисковых системах, таких как Google, Yahoo или Bing.
- Better Server logs — Каждый раз, когда любая поисковая система сканирует ваш сайт, она запрашивает файл robots.txt, если у вас его нет; он каждый раз генерирует ошибку «404 Not Found». Обнаружить настоящие ошибки становится действительно сложно.
- Предотвращает спам и штрафы — Чтобы предотвратить спам или дублирование контента или данных, можно защитить с помощью роботов.текст. Это помогает предотвратить индексацию контента и избежать его неправильного использования. Некоторые владельцы веб-сайтов используют файл robots.txt, чтобы скрыть области разработки или конфиденциальные области веб-сайта для всеобщего просмотра.
- Инструменты Google для веб-мастеров — Важно иметь файл robots.txt, чтобы Google мог проверить ваш сайт. Инструменты веб-мастера важны для понимания вашего веб-сайта.
Некоторые из вариантов использования robots.txt:
- По запретить поисковым роботам посещать личные папки или страницы, которые могут содержать конфиденциальные данные.
- Кому разрешить определенным веб-роботам сканировать ваш сайт. Таким образом сохраняется пропускная способность.
- На обеспечьте работу с ботами, указав директиву в файле robots.txt , где находится ваш Sitemap.
Карта сайта: http://yoursite.com/sitemap-location.xml
Директивы не зависят от строки пользовательского агента и поэтому могут быть добавлены в любом месте файла robots.txt. Вам просто нужно указать расположение вашей карты сайта в файле sitemap-location.xml часть URL-адреса. Не беспокойтесь, если у вас несколько файлов Sitemap, так как вы можете указать расположение файла индекса Sitemap.
Создание файла robots.txt головная боль? Chill, давай создадим его!
Создать файл robots.txt не так уж и сложно. Если у вас его нет, всегда лучше создать:
- Создать новый текстовый файл: Первый шаг — создать новый текстовый файл и сохранить его. Используя программу «Блокнот» на ПК с Windows или TextEdit для Mac, нажмите «Сохранить как».Создается новый текстовый файл.
- Загрузить в корневой каталог: После сохранения файла загрузите файл в корневой каталог веб-сайта. Это папка корневого уровня, называемая «htdocs» или «www», благодаря чему она появляется сразу после имени домена.
- Создайте файл robots.txt для каждого субдомена: Если вы используете субдомены, для каждого субдомена будет создан отдельный файл robots.txt.
Два важных компонента файла robots.txt!
Роботы.txt состоит из двух основных компонентов: User-agent и Disallow:
- User-agent: Пользовательский агент отображается с подстановочным знаком (*), который является знаком звездочки, который указывает, что инструкции по блокировке предназначены для всех веб-роботов. Вы можете указать имя веб-робота в директиве user-agent, если хотите, чтобы боты были разрешены или заблокированы на определенных страницах.
- Disallow: Если запрет не указывает ничего, это означает, что веб-роботы могут сканировать все страницы на сайте. Если вы хотите заблокировать определенную страницу, вы должны использовать только один префикс URL для каждого запрета.В robot.txt вы не можете включать несколько папок или префиксов URL-адресов под элементом disallow.
Некоторые основные элементы, которые необходимо знать:
Что включать в txt-файл robots?
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Он содержит одну запись, например:
User-agent: *
Disallow: / cgi-bin /
Disallow: / tmp /
Disallow: / somedirectory /
Ниже приведен пример, в котором исключены три каталога. .
Чтобы исключить любой префикс URL, вам нужно использовать отдельную строку «Disallow» — «Disallow: / cgi-bin / / tmp /» в одной строке не будет работать. Любые пустые строки в записи приведут к разделению нескольких записей.
Clotting или подобные типы регулярных выражений не поддерживаются ни строками User-agent, ни Disallow. «*» В поле User-agent — это специальное значение, означающее «любой робот». Кроме того, у вас не может быть таких строк, как «User-agent: * bot *», «Disallow: / tmp / *» или «Disallow: * .gif».
Исключение чего-либо зависит от вашего сервера.Давайте рассмотрим несколько примеров:
- Исключение всех роботов со всего сервера
User-agent: *
Disallow: / - Разрешение полного доступа всем роботам
User-agent: *
Disallow:
(создать пустой файл «/robots.txt» или не использовать его вообще) - Исключение всех роботов из части сервера
User-agent: *
Disallow: / cgi-bin /
Disallow: / tmp /
Disallow: / trunk / - Исключение одного робота
Агент пользователя: BadBot
Disallow: / - Разрешение одного робота 9
-agent: Google
Disallow:
User-agent: *
Disallow: / - Исключение всех файлов, кроме одного
Поскольку поля «Разрешить» нет, это может оказаться немного сложным.Лучший способ — вынести все файлы в отдельный каталог, который необходимо запретить, например, «shoes», оставив один файл на уровне выше этого каталога:
User-agent: *
Disallow: / somedirectory / shoes /
Запрещение всех запрещенных страниц:
User-agent: *
Disallow: /somedirectory/junk.html
Disallow: /somedirectory/foo.html
Disallow: /somedirectory/bar.html
Что нельзя включать в robots. txt файл?
Обычно в файле robots.txt веб-сайта есть команда:
User-agent: *
Disallow: /
Эта команда указывает всем ботам просто игнорировать весь домен, что означает, что ни одна страница этого веб-сайта не будет просканированные или проиндексированные поисковыми системами.
Что произойдет, если у вас нет файла robots.txt?
Если файл robots.txt отсутствует, поисковые системы могут сканировать все и все, что они найдут на веб-сайте. Это может быть проблемой для веб-мастеров, которые хотят скрыть некоторую информацию с веб-страниц и не хотят, чтобы эти страницы сканировались и индексировались поисковыми системами, что привело к тому, что информация стала общедоступной.Кроме того, всегда лучше точно указать свою карту сайта XML, так как это поможет поисковым системам легко сканировать ваш новый контент.
Robots.txt может быть недостатком для веб-сайтов:
Следует действительно понимать логику создания robots.txt и риски, связанные с методом блокировки URL. Бывают случаи, когда вы хотите увидеть через другие механизмы, доступны ли ваши URL-адреса в Интернете или нет.
- Robots.txt работает только в соответствии с директивами.
Роботы.txt — это файл, который функционирует в соответствии с заданной командой. Установив некоторые правила в текстовом файле, вы можете приказать роботам не сканировать и не индексировать определенные файлы и каталоги на вашем сайте. Веб-сканеры следуют инструкциям в файле robots.txt, а некоторые могут не выполнять их. Поэтому всегда рекомендуется защищать информацию от поисковых роботов с помощью каких-либо методов блокировки. - У каждого поискового робота может быть свой синтаксис.
Как правило, поисковые роботы следуют директивам файла robots.txt файл. Таким образом, есть вероятность, что поисковый робот может интерпретировать инструкции по-разному. Необходимо иметь полное представление о синтаксисе обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенных инструкций. - Роботс.txt не может остановить предотвращение ссылок с других сайтов на ваши URL-адреса.
Есть вероятность, что Google не просканирует или не проиндексирует контент, заблокированный файлом robots.txt, но мы все равно можем найти и проиндексировать запрещенный URL из других мест в Интернете.Следовательно, URL-адрес и другая открытая информация все еще может отображаться в результатах поиска Google.
Друг нуждается в проверке файла robots.txt. Ну вот!
Инструмент для проверки файла robot.txt.
http://tool.motoricerca.info/robots-checker.phtml
Заключение
Файл Robots.txt спасет ваш сайт, если вы не хотите, чтобы его страницы индексировались поисковыми системами. Более того, файл гарантирует, что ваши веб-страницы защищены, обеспечивая оптимальные результаты в поисковой оптимизации.
Пользовательский агент: * Задержка сканирования: 30 Disallow: /~ward/sudokant.cgi Запретить: / wiki / history Запрещение: / ~ ward / morse / ve Запретить: / Лиза Disallow: / ~ ward / wikitect Disallow: / cgi / allpages Disallow: / cgi-bin / allpages Disallow: / cgi / blockme Disallow: / cgi-bin / blockme Disallow: / cgi / bridges.застегивать Disallow: /cgi-bin/bridges.zip. Disallow: /cgi/cam.cgi Disallow: /cgi-bin/cam.cgi Disallow: / cgi / eprime Disallow: / cgi-bin / eprime Disallow: /cgi/favicon.ico Disallow: /cgi-bin/favicon.ico Disallow: / cgi / fullSearch Disallow: / cgi-bin / fullSearch Disallow: / cgi / grid Disallow: / cgi-bin / grid Disallow: / cgi / длина сетки Disallow: / cgi-bin / длина сетки Запретить: / cgi / grid-words Запретить: / cgi-bin / grid-words Disallow: / cgi / histDiff.cgi Disallow: /cgi-bin/histDiff.cgi Запретить: / cgi / imagemap Запретить: / cgi-bin / imagemap Disallow: / cgi / isbn Disallow: / cgi-bin / isbn Disallow: / cgi / kaweahits Disallow: / cgi-bin / kaweahits Disallow: / cgi / likeGameData Disallow: / cgi-bin / likeGameData Disallow: / cgi / links Disallow: / cgi-bin / links Disallow: / cgi / locale Disallow: / cgi-bin / locale. Disallow: /cgi/longs.cgi Disallow: /cgi-bin/longs.cgi Disallow: / cgi / mb Disallow: / cgi-bin / mb Disallow: / cgi / onTopic Disallow: / cgi-bin / onTopic Disallow: / cgi / orphanWikiPages Disallow: / cgi-bin / orphanWikiPages Disallow: / cgi / outline Disallow: / cgi-bin / outline Запретить: / cgi / quickChanges Запретить: / cgi-bin / quickChanges Disallow: / cgi / quickDiff Запретить: / cgi-bin / quickDiff Запретить: / cgi / quickDiff.