
Канонический адрес страницы — Вебмастер. Справка
Если на сайте есть страница, доступная по нескольким адресам, а также страницы с одинаковым или схожим содержимым, робот Яндекса может посчитать их дублями. Тогда он объединит страницы в группу дублей и выберет для показа в результатах поиска только одну из них — наиболее информативную и релевантную поисковым запросам. Такая страница называется канонической.
Вы можете указать роботу страницу, предпочитаемую для показа в результатах поиска, с помощью атрибута rel=»canonical». Также вы можете указать канонический адрес, если хотите изменить адрес сайта — с префиксом www или без него, протоколом HTTP или HTTPS.Внимание. Робот Яндекса воспринимает указание на канонический адрес как рекомендацию и может проигнорировать его в нескольких случаях.- Как указать канонический адрес страницы
- Как изменить адрес сайта с помощью канонического адреса
- Случаи, когда канонический адрес не учитывается
- Вопросы и ответы
Добавьте канонический адрес страницы с помощью атрибута rel=»canonical» одним из способов:
Например, страница доступна по двум адресам: www.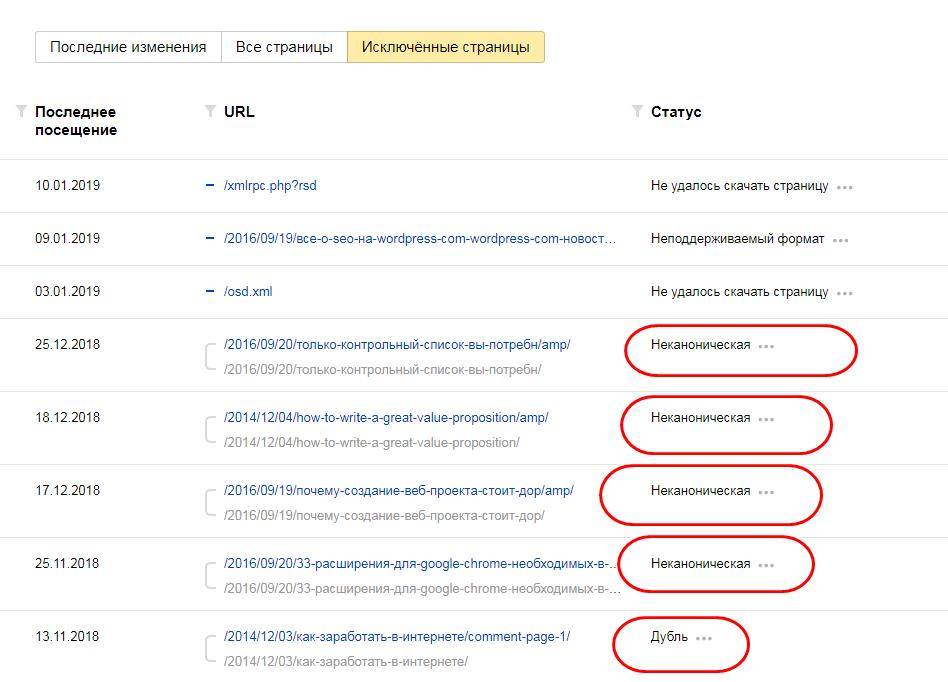 example.com/pages?id==2 и www.example.com/blog.
example.com/pages?id==2 и www.example.com/blog.
Если предпочитаемый адрес — /blog, добавьте в HTML-код страницы /pages?id=2 элемент link:
<link rel="canonical" href="http://www.example.com/blog"/>Link: <http://www.example.com/offer/file.pdf>; rel="canonical"
Примечание. Указывайте канонический адрес в пределах одного домена. В качестве канонического адреса задавайте абсолютный путь, например http://example.com/blog/.
Страница, на которой размещен атрибут rel=»canonical» с адресом другой страницы, считается неканонической.
Робот узнает об изменениях при обходе сайта. Если канонический адрес указан верно и робот не проигнорировал указание, неканоническая страница пропадет из результатов поиска. Убедиться в том, что страница удалена из поиска, можно в Вебмастере на странице (блок Исключённые страницы).
Робот игнорирует указания, если содержимое канонической страницы значительно отличается от содержимого неканонической. В этом случае в поиске может участвовать неканоническая страница. Чтобы проверить это, перейдите на страницу .
Чтобы исключить из поиска неканоническую страницу, адрес которой содержит GET-параметры или метки (UTM, from и т. д.), добавьте директиву Clean-param в файл robots.txt. В другом случае используйте директиву Disallow.
Вы можете указать канонический адрес, если хотите изменить адрес сайта:
Робот воспримет канонический адрес как редирект на новое главное зеркало и объединит две версии сайта в одну группу. Для этого в HTML-код или в HTTP-заголовок каждой страницы старого сайта добавьте ссылку на аналогичную страницу нового с атрибутом rel=»canonical».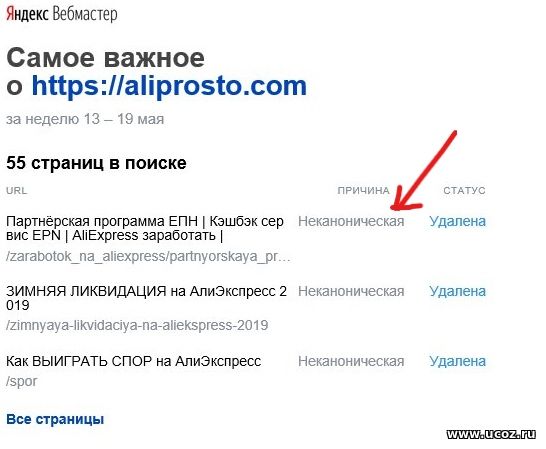 Например, вы меняете адрес http://example.com на https://example.com. На странице http://example.com/main/ нужно указать:
Например, вы меняете адрес http://example.com на https://example.com. На странице http://example.com/main/ нужно указать:
<link rel="canonical" href="https://example.com/main"/>Если атрибут будет указывать на другую страницу, робот может посчитать это различием в структуре сайтов. В таком случае переезд будет невозможен.
При смене адреса убедитесь, что контент старого и нового сайтов совпадает. Подробнее см. инструкцию по переезду.
Примечание. Если атрибут добавлен только на отдельные страницы, он не будет указывать на главное зеркало.
Робот Яндекса не учтет канонический адрес, если:
- На момент обхода неканонические страницы более полно отвечают на запрос пользователя, и их контент существенно отличается от канонических. Если вы уверены, что такие страницы не будут полезны пользователям в поиске, запретите индексирование в файле robots.txt.
- Канонический адрес недоступен для робота — перенаправляет на другую страницу или закрыт от индексирования.

В качестве канонического адреса указан URL в другом домене или поддомене.
Указано несколько канонических адресов.
Указана цепочка канонических адресов. Например, для адреса example.com/1 каноническим адресом является example.com/2, в то время как для адреса example.com/2 указан канонический адрес example.com/3.

- Атрибут rel=»canonical» указывает на страницу, на которой размещен. Это ошибка?
Если страница была исключена из поиска как неканоническая, значит, в ее HTML-коде или HTTP-заголовке робот нашел атрибут rel=»canonical» с указанием на канонический адрес. Удалите это указание и проверьте, что индексирование страницы, которую вы хотите вернуть в поиск, не запрещено.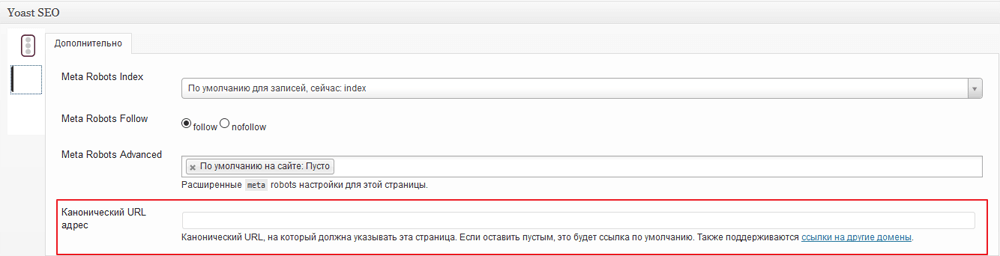
Неканонические страницы в Поиске — Блог Яндекса для вебмастеров
Часто на сайтах присутствуют страницы с разными URL, но с одинаковым или очень похожим содержанием. С помощью атрибута rel=«canonical» вебмастера могут указать, какая страница является «канонической» — предпочтительной для индексации и появления в результатах поиска. Остальные, неканонические версии как правило в поиск не попадают.
Наши исследования показывают, что страницы, размеченные как неканонические могут быть полезны, а их наличие в поиске может влиять на качество и полноту ответа на запрос пользователя. Например, если для темы форума владелец сайта указал канонической страницу с началом ветки, то многие важные и нужные ответы, которые были даны пользователями позже, в поиск не попадают. Другой пример: бывает, что какое-то литературное произведение разбито на страницы и в качестве канонической прописана первая страница. В результате сайт не находится по запросу-цитате, соответствующей тексту за пределами первой странице.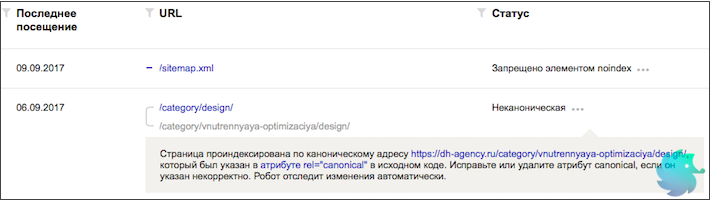 Поэтому теперь в поиске неканонические страницы будут появляться чаще.
Поэтому теперь в поиске неканонические страницы будут появляться чаще.
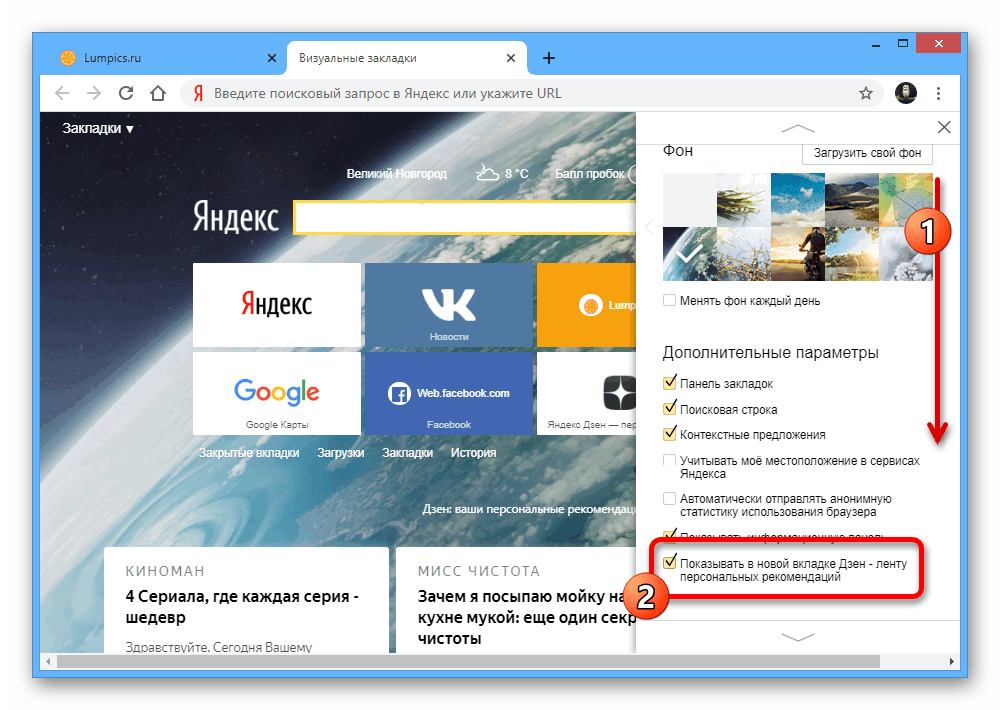
Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом. В Вебмастере такие страницы можно увидеть на странице «Страницы в поиске» с пометкой «Неканоническая». Помимо этого статуса мы начали показывать статусы «Каноническая» и «Каноническая страница не указана» для всех страниц, попавших в поиск.
Если канонические страницы настроены на сайте без ошибок, то никаких дополнительных действий от вебмастера не требуется. Для сайтов, имеющих много неканонических страниц, которые сильно отличались от канонических, возможен прирост количества страниц в Поиске. Впрочем, канонические страницы по-прежнему попадают в поиск гораздо чаще и имеют более высокий приоритет при показе в результатах поиска. Объем трафика для каждого конкретного сайта существенно не изменится.
Команда Поиска
P. S. Подписывайтесь на наши каналы
S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен
«Яндекс» начнёт чаще показывать неканонические страницы — SEO на vc.ru
{«id»:74270,»url»:»https:\/\/vc.ru\/seo\/74270-yandeks-nachnet-chashche-pokazyvat-nekanonicheskie-stranicy»,»title»:»\u00ab\u042f\u043d\u0434\u0435\u043a\u0441\u00bb \u043d\u0430\u0447\u043d\u0451\u0442 \u0447\u0430\u0449\u0435 \u043f\u043e\u043a\u0430\u0437\u044b\u0432\u0430\u0442\u044c \u043d\u0435\u043a\u0430\u043d\u043e\u043d\u0438\u0447\u0435\u0441\u043a\u0438\u0435 \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u044b»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/74270-yandeks-nachnet-chashche-pokazyvat-nekanonicheskie-stranicy»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/74270-yandeks-nachnet-chashche-pokazyvat-nekanonicheskie-stranicy&title=\u00ab\u042f\u043d\u0434\u0435\u043a\u0441\u00bb \u043d\u0430\u0447\u043d\u0451\u0442 \u0447\u0430\u0449\u0435 \u043f\u043e\u043a\u0430\u0437\u044b\u0432\u0430\u0442\u044c \u043d\u0435\u043a\u0430\u043d\u043e\u043d\u0438\u0447\u0435\u0441\u043a\u0438\u0435 \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u044b»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.
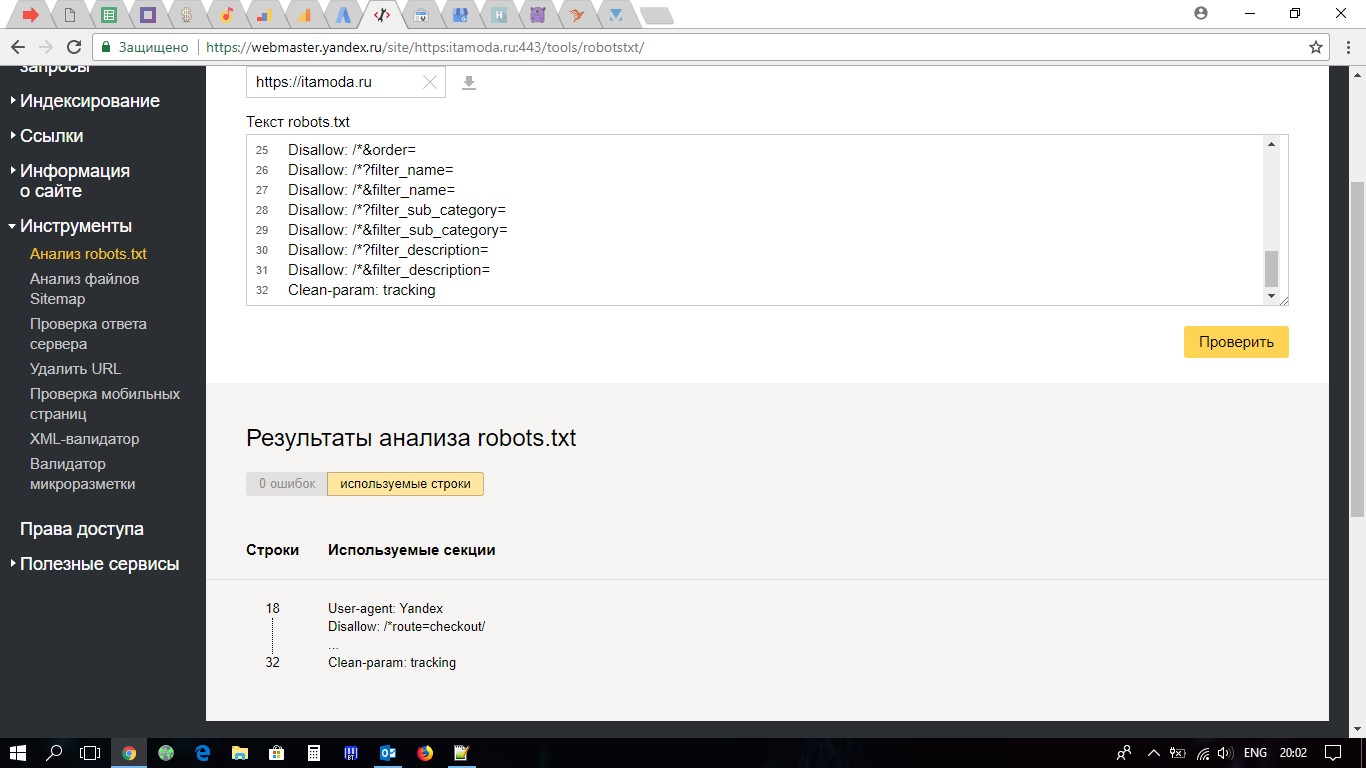
Канонические URL адреса страниц или link rel=»canonical»
Что такое канонические URL адреса?
В широком смысле слова, канонический означает «принятый за образец», «твердо установленный».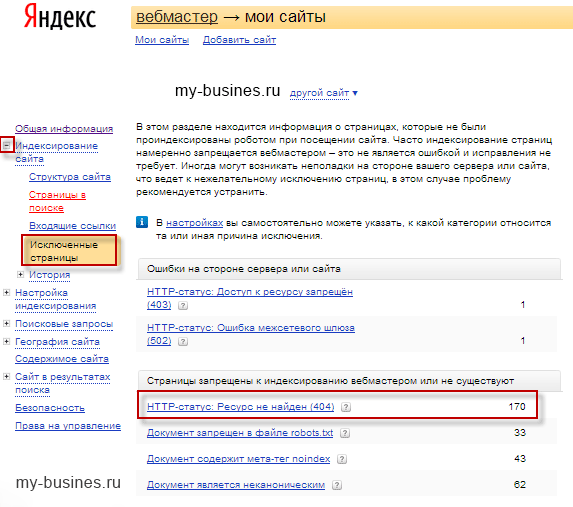
Обычно, один материал имеет один URL адрес, к примеру www.example.ru/1.html. Но иногда одна и так же страница может быть доступна по нескольким адресам. К примеру: www.example.ru/1.html и www.example.ru/1/1.html. В таком случае, необходимо определить, какой из 2-х адресов является основным или каноническим.
Предположим, что www.example.ru/1.html был выбран в качестве основного URL. Тогда на странице с данным адресом (а так же, других страницах с копией контента) необходимо разместить следующий элемент:
<link rel="canonical" href="www.example.ru/1.html" />Размещается он в шапке сайта, между тегов <head></head>.
Внимание! Что бы снизить вероятность ошибки, внутри элемента link rel=»canonical» необходимо использовать абсолютные, а не относительные адреса. То есть, добавлять к ссылке домен.
То есть, добавлять к ссылке домен.
Убедитесь, что в технической карте сайта sitemap.xml размещены именно канонические ссылки. Иначе это может привести к ошибкам индексирования.
Примеры канонических адресов
Предположим, что мы создали статью о продвижении Интернет-магазина одежды, для которой сделали красивый, понятный для человека URL.
Но статья осталась доступна по техническому адресу, который мы больше видеть не хотим.
В этом случае, на странице со статьей, нам необходимо прописать элемент <link rel=»canonical» href=»https://dh-agency.ru/prodvijenie-magazina-odejdy/» />, в котором указан основной, канонический адрес.
Вот таким образом:
Теперь адрес https://dh-agency.ru/prodvijenie-magazina-odejdy/ будет считаться основным.
Роль канонических адресов страниц в SEO
С точки зрения поисковой оптимизации, наличие одного основного URL адреса страницы просто необходимо.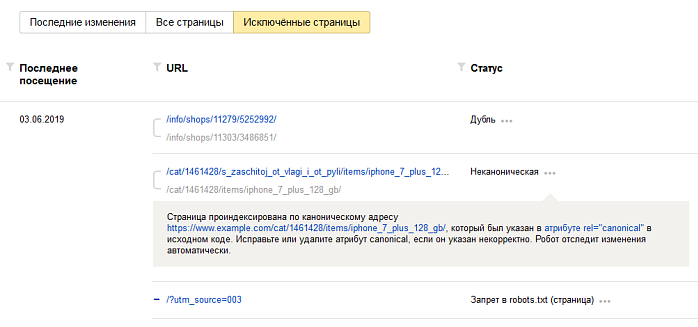 Во-первых, это позволяет сэкономить время, так как роботу не приходится загружать копии контента. Во-вторых, не остается никаких сомнений, какой адрес должен участвовать в поисковой выдаче. В-третьих, снижается нагрузка на сайт, что так-же важно для посещаемого ресурса.
Во-первых, это позволяет сэкономить время, так как роботу не приходится загружать копии контента. Во-вторых, не остается никаких сомнений, какой адрес должен участвовать в поисковой выдаче. В-третьих, снижается нагрузка на сайт, что так-же важно для посещаемого ресурса.
Нужно понимать, что краулер отводит ограниченное количество времени на индексацию сайта, поэтому многочисленные дубли страниц могут сильно ударить по эффективности его работы.
Правильно устанавливаем канонические URL адреса
Правильно установленный канонический адрес отвечает следующим требованиям:
Каноническая страница, указанная в элементе link rel=»canonical», обязательно должна существовать и быть доступна для пользователей;
Канонический адрес должен быть указан только для одного домена и поддомена. Грубо говоря, не должно быть ссылок на другие ресурсы;
Для страницы может быть указан один единственный канонический адрес;
Убедитесь, что на сайте отсутствуют рекурсии или «цепочки» канонических адресов.
То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;Элемент link rel=»canonical» должен находится между тегами <head></head>.
 То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;
То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;Уверены, что Ваши канонические адреса соответствуют всем вышеуказанным требованиям? Тогда можете считать их просто превосходными!
Понятие «каноническая ссылка»
Те, кто только начал окунаться в основы поисковой оптимизации, иногда разделяют понятия «канонический адрес» и «каноническая ссылка». На самом деле, речь идет об одном и том же — о главном URL адресе страницы.
Нет никаких канонических <a href=»»> </a> и «главных ссылок ссылок для перелинковки».
301 редирект — замена rel=»canonical»?
Когда речь заходит о выборе между 301 редиректом и элементом link rel=»canonical», мы обычно советуем использовать именно переадресацию.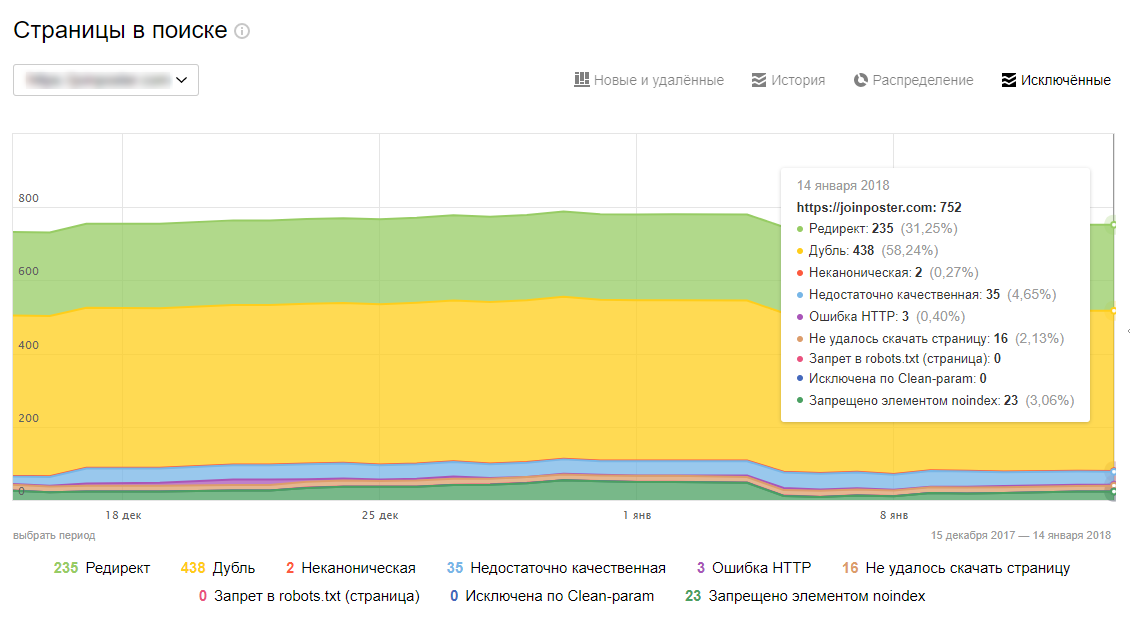 Все дело в том, что тег link rel=»canonical» не является обязательным, то есть, может быть проигнорирован поисковой системой.
Все дело в том, что тег link rel=»canonical» не является обязательным, то есть, может быть проигнорирован поисковой системой.
Использование link rel=»canonical» актуально только тогда, когда сделать 301 редирект невозможно или проблематично.
Есть и еще один плюс link rel=»canonical» перед 301 редиректом — его простановку возможно сделать автоматической при создании страницы. К примеру, в WordPress эта функция уже реализована. То есть, заранее указав канонический адрес, Вы можете избавить себя от будущих проблем с индексацией.
Яндекс Вебмастер — статус «неканоническая»
В Яндекс Вебмастере есть раздел «Исключенные страницы«, добраться туда можно из меню «Индексирование» -> «Страницы в поиске» -> «Исключенные страницы«.
Перейдя в этот раздел, Вы увидите все материалы, которые были по какой либо причине загружены в базу, но исключены из поиска.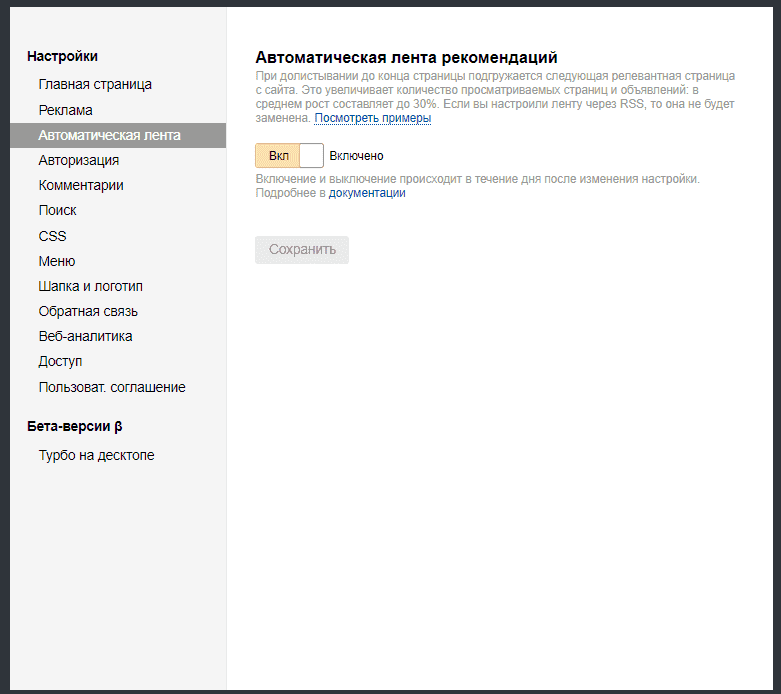
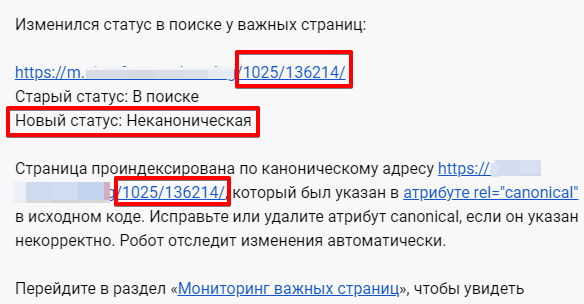
Среди прочих причин исключения Вы можете увидеть статус «Неканоническая». Нажав на троеточие, отроется сообщение следующего вида:
«Страница проиндексирована по каноническому адресу https://dh-agency.ru/category/vnutrennyaya-optimizaciya/design/, который был указан в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут canonical, если он указан некорректно. Робот отследит изменения автоматически.»
Что это значит?
Ничего страшного не произошло. Робот Яндекса проиндексировал страницу по первому (написанному синем шрифтом) URL, при этом на самой странице стоял элемент link rel=»canonical», в котором, в качестве канонического, был указан другой адрес (написанный серым шрифтом).
Пользуясь данной инструкцией, робот исключил неканонический URL.
Переживать, что материал был полностью исключен из поиска не стоит, он находится в выдаче, но по другому URL адресу.
Что с этим делать?
Если Вас не устраивает URL, который был выбран в качестве основного, необходимо поменять адрес в элементе link rel=»canonical» на предпочтительный. После изменения, страницу желательно отправить на переобход индексирующему роботу.
(«Индексирование» -> «Переобход страниц«)
Так изменения будут загружены в базу в самое ближайшее время.
Только не забудьте изменить адрес в файле sitemap.xml.
10 основных причин, по которым страница сайта может не находиться в индексе поисковых систем Яндекс или Google
Причина номер 1. Новая страница или новый сайт
Первая причина, это то, что поисковые роботы еще просто не нашли новую страницу вашего сайта. В зависимости от того, какой ваш сайт, переобход страниц может занимать от нескольких минут до нескольких недель.
Чтобы узнать, находится ли в индексе страница Вам необходимо воспользоваться сервисами вебмастера Яндекс или Google Search Console.
В Яндекс.Вебмастере это раздел «Индексирование» — «Проверить статус URL». Если робот обошел и проиндексировал страницу, вы увидите уведомление «Страница обходится роботом и находится в поиске».
Если робот о странице еще не знает, вы увидите сообщение «Страница неизвестна роботу».
В новой версии Google Search Console вам нужен инструмент «Проверка URL». Если робот обошел и проиндексировал страницу, вы увидите уведомление «URL есть в индексе Google».
Если робот на странице еще не был, вы увидите сообщение «URL нет в индексе Google».
Причина номер 2. Страница или сайт закрыты от индексации в файле robots.txt
Существует специальный файл robots.txt, который позволяет указать роботам на то, какие страницы сайта должны быть в индексе поисковых систем, а какие страницы не должны быть включены.
Соответственно, если в файле прописаны запрещающие правила, в индексе поисковых систем данную страницу вы не найдете.
Как проверить, закрыта ли страница в robots.txt?
В Яндекс.Вебмастере: заходим в «Инструменты — Анализ файла robots.txt». В окно «Разрешены ли URL» вносим адреса страниц, которые мы хотим проверить. После того, как мы нажмем на кнопку «Проверить», внизу появится список введенных адресов и их статус: разрешены они для индексации или нет.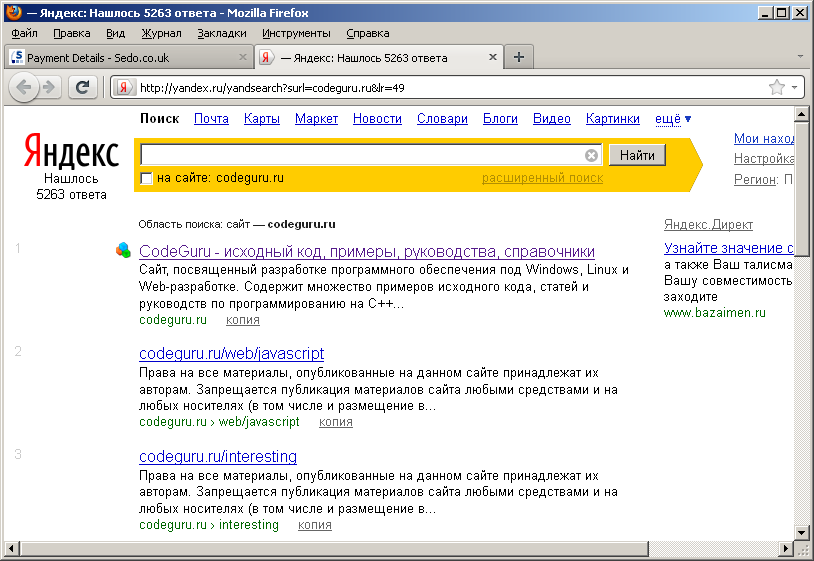 Если нет, будет указано, какое из правил запрещает обход для робота.
Если нет, будет указано, какое из правил запрещает обход для робота.
В Google похожий инструмент находится на вкладке «Сканирование — Инструмент проверки файла robots.txt».
Важно! На данный момент эта вкладка находится в старой версии вебмастера!
Причина номер 3. Указан запрет в User-Agent
У поисковых систем есть свои требования к тому, как должен строиться файл robots.txt. И начинается он с приветствия. Приветствие может быть обращено к роботу яндекс, либо гугл, либо к обеим поисковым системам.
Часто для Яндекс и Google делают отдельные секции в файле robots.txt. А потом забывают вносить правки в эти секции. Из-за этого роботы потом некорректно начинают индексировать сайт.
Проверяем наличие проблемы также, как и в предыдущем случае. Главное — это делать в вебмастере Яндекс, и в вебмастере Google.
Причина номер 4. Запрет на индексацию страниц указан в мета-теге robots.
Суть этого мета-тега такая же, как и у файла robots.txt, только если страница закрыта в robots.txt она все равно может быть проиндексирована поисковыми системами. Но если на странице используется noindex или none, страница не будет добавлена в индекс.
1. Проверить использование данного мета-тега на странице можно в коде (сочетание клавиш Ctrl+U)
2. С помощью дополнения для браузера, например seo meta
 youtube.com/embed/zoIBWWAhudc?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
youtube.com/embed/zoIBWWAhudc?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
3. С помощью вебмастеров.
Причина номер 5. Некорректно настроенный атрибут rel=canonical.
Каноникал — это еще один атрибут, помогающий управлять индексацией страниц.
Если rel каноникал настроен на другую страницу, то вы говорите поисковому роботу о том, что она схожа с другой станицей и первую страницу не нужно добавлять в индекс поисковых систем.
Проверить использование данного атрибута можно также в исходном коде, с помощью дополнения для браузера — rds бар или seo meta.
Также это можно увидеть в вебмастере Яндекс («Страницы в поиске»- «Исключенные страницы». Проверять необходимо статус «неканонические»).
Проверять необходимо статус «неканонические»).
Причина номер 6. Проблемы с ответом сервера
Для того, чтобы страница индексировалась, ее код ответа сервера должен быть 200 ОК. Если страница отдает ответ сервера 404 или 301, в индекс поисковых систем данная страница не попадет.
Проверять код ответа лучше всего с помощью вебмастеров, они показывают наиболее точные данные. А вот визуальной проверкой лучше не ограничиваться, так как бывают случаи, когда страницы выглядят корректно, но код ответа сервера не 200.
Причина номер 7. Проблемы с хостингом или сервером
Представьте, вы приходите в магазин, а он не работает. Потом снова приходите в магазин, но он все равно не работает. Какова вероятность того, что вы вернетесь туда? Вероятнее всего очень маленькая.
Какова вероятность того, что вы вернетесь туда? Вероятнее всего очень маленькая.
Тоже самое происходит и с поисковыми системами. Если он приходит на ваш сайт, а он не работает, то робот просто исключает страницы из индекса и не показывает их пользователям.
Правильно, зачем пользователей приводить на неработающий сайт.
Для того, чтобы отследить есть ли проблема, необходимо в вебмастерах проверять статус страниц. Если встречаются ошибки сервера 5хх (500, 503), а также если вам приходят уведомления из Яндекс.Метрики о том, что сайт не работает, необходимо решать данную проблему.
Причина номер 8. Проблемы со скоростью загрузки страниц
Скорость загрузки — важный показатель качества современного сайта. Если ваши страницы долго долго загружаются, роботы поисковых систем исключать такие страницы из индекса.
Если ваши страницы долго долго загружаются, роботы поисковых систем исключать такие страницы из индекса.
Кроме того, скорость загрузки страниц — является фактором ранжирования в поисковых системах. Поэтому, если у вас с этим есть проблемы, срочно это исправляйте!
Как проверить? Начните с инструмента PageSpeed Insights от Google. Дополнительно можете использовать сервисы Google Аналитика и Яндекс.Метрика.
Совет! Важно проверять скорость загрузки для нескольких типов страниц и не останавливаться выполнив только одну проверку, т.е. выполнять данные работы периодически.
Причина номер 9. Проблема с уникальностью и полезностью контента
Поисковики уделяют большое внимание качеству контента, поэтому, если на странице расположен не полезный контент, либо же дублирующийся с другими страницами, такие страницы не добавляются в индекс поисковых систем.
Как проверить, есть ли на сайте такие страницы — нужно зайти в вебмастер.
В Яндексе — это отчет «Страницы в поиске» — «Исключенные страницы». Проверять нужно статусы «Дубль» и «Недостаточно качественная».
В Google Search Console — это отчет «Покрытие» — «Страница является копией. Канонический вариант не выбран пользователем».
Причина номер 10. Проблемы с AJAX
Если ваш сайт выполнен на технологии AJAX очень важно правильно выполнить требования поисковых систем, для того чтобы поисковые роботы смогли проиндексировать страницы вашего сайта.
Таким образом для каждой отдельной страницы должна быть своя HTML-версия.
И напоследок, дадим вам несколько советов, как ускорить индексацию:
- отправляйте страницы на переобход с помощью вебмастеров
- используйте файл sitemap.xml
- используйте новейшие возможности, которые предоставляют вам поисковики. Например, Яндекс Метрике появилась возможность связать Яндекс Вебмастер и Яндекс Метрику, для того чтобы отправлять страницы на переиндексацию.
Также смотрите наш видеоролик https://youtu.be/HF-2dd4luQY с помощью которого вы сможете найти ошибки у себя на сайте и запланировать работы по их исправлению.
Если вы хотите продвинуть свой сайт в ТОП поисковой выдачи, тогда записывайтесь на курс по SEO-продвижению
Поделиться с друзьями:
Что такое canonical и зачем он нужен?
Атрибут rel=canonical тега <link> сообщает поисковой системе, что некоторые страницы сайта являются одинаковыми, несмотря на разные URL-адреса. С помощью него можно решить проблему с дублированием контента в пределах сайта.
С помощью него можно решить проблему с дублированием контента в пределах сайта.
Что такое канонические страницы
Это страницы-первоисточники. Предположим, у нас есть ряд страниц, содержащих одинаковый контент. Наиболее распространенная ситуация — наличие одного и того же товара с тем же описанием в разных категориях, и соответственно, по разным URL-адресам:
- site.ru/catalog/verhnaya-odezhda/gucci/kovta-s-printom-gucci
- site.ru/catalog/brands/gucci/kovta-s-printom-gucci
- site.ru/catalog/kovty/s-printom/kovta-s-printom-gucci
Данный товар действительно подходит для разных категорий и должен находиться в каждой из них, но для поисковой системы они являются дублями, потому что отличаются URL-адресами, но содержат одинаковый контент. В связи с этим поисковая машина может их занести в индекс и расценивать как дубликаты, что негативно сказывается на продвижении.
Чтобы избежать данной ситуации необходимо указать для них rel=»canonical». Для этого сначала необходимо определить предпочитаемый канонический URL. В нашем примере это будет
Для этого сначала необходимо определить предпочитаемый канонический URL. В нашем примере это будет
- site.ru/catalog/brands/gucci/kovta-s-printom-gucci
Теперь осталось только указать этот URL как канонический в остальных двух страницах. Тогда эта страница будет участвовать в поиске, а остальные две — считаться неканоническими.
Как указывать rel=canonical
Тег <link> с атрибутом канонической ссылки обязательно должен располагаться в теге <head> страницы. В нашем примере мы укажем его на страницах
- site.ru/catalog/verhnaya-odezhda/gucci/kovta-s-printom-gucci
- site.ru/catalog/kovty/s-printom/ kovta-s-printom-gucci
Готовый код будет выглядеть следующим образом:
<head>
<link rel=»canonical» href=»https:// site.ru/catalog/brands/gucci/kovta-s-printom-gucci/»>
</head>
Если всё будет сделано верно, эти страницы не попадут в индекс.
Правила указания канонических ссылок
При проставлении ссылок на канонические страницы необходимо помнить о следующих правилах:
- каноническая страница должна существовать и иметь код ответа сервера 200.
- ссылка не должна указывать на страницу, расположенную на другом домене.
- допускается только одна каноническая ссылка на странице.
- недопустимы цепочки из канонических ссылок. То есть ошибочно, если страница 1 указывает на неканоническую страницу 2, а та, в свою очередь, ссылается через rel=»canonical» на третью.
Летние изменения в поиске Яндекса
Несмотря на то, что лето традиционно является периодом отпусков, похоже, в поисковом департаменте Яндекса вовсю кипела и кипит работа. Ибо нововведения в поиске продолжают появляться одно за другим.
Начнем с того, что в начале июня в блоге разработчиков Яндекса устами Платона Щукина было заявлено об изменениях в учете директивы canonical, а именно, что «атрибут rel со значением canonical элемента link теперь рассматривается как указание на главное зеркало в группах зеркал сайтов с www и без www, а также с http и https». Вместе с тем Платон Щукин подчеркнул, что «межхостовый атрибут все ещё не поддерживается, поэтому, если отдельные страницы будут содержать атрибут с такими указаниями, как неканонические, они из поиска не выпадут». Да и на соответствующей странице Яндекс.Помощи указано, что «робот Яндекса не учтет канонический адрес, если: … В качестве канонического адреса указан URL в другом домене или поддомене».
Вместе с тем Платон Щукин подчеркнул, что «межхостовый атрибут все ещё не поддерживается, поэтому, если отдельные страницы будут содержать атрибут с такими указаниями, как неканонические, они из поиска не выпадут». Да и на соответствующей странице Яндекс.Помощи указано, что «робот Яндекса не учтет канонический адрес, если: … В качестве канонического адреса указан URL в другом домене или поддомене».
Однако мне удалось встретить в отчетах сервиса Яндекс.Вебмастер самое что ни на есть прямое подтверждение, что страница на одном поддомене признана канонической для страницы с другого поддомена:
Причем здесь идет речь не о склейке поддоменов, а именно о консолидации отдельных страниц. Возможно, расширение функционала директивы canonical вызвало вот такие любопытные артефакты. Что ж, нововведение скорее положительное, а если еще и заработает междоменный canonical, то это будет однозначный плюс.
Но на этом Яндекс в изменении своего взгляда на директиву canonical не успокоился. В начале июля последовал анонс нового отношения Яндекса к директиве canonical, который я анализировал в своей предыдущей статье «Неканонический canonical». Вкратце – Яндекс заявил, что будет игнорировать директиву canonical в том случае, если сочтет, что контент страниц, указанных как каноническая и неканоническая, существенно различается.
В начале июля последовал анонс нового отношения Яндекса к директиве canonical, который я анализировал в своей предыдущей статье «Неканонический canonical». Вкратце – Яндекс заявил, что будет игнорировать директиву canonical в том случае, если сочтет, что контент страниц, указанных как каноническая и неканоническая, существенно различается.
По горячим следам анонса я высказал надежду, что директива canonical будет игнорироваться только в случае, если неканоническая страница будет сочтена действительно полезной и качественной. Однако, увы, практика показала, что неканонические страницы запросто удаляются Яндексом из индекса как некачественные:
То есть по сути директива canonical перестала быть удобным инструментом для консолидации страниц, контент которых может различаться (например, страниц пагинации, сортировки, результатов фильтрации и т.п.). И если для конкретного сайта игнорирование директивы canonical с последующим признанием неканонических страниц некачественными будет носить массовый характер, то, на мой взгляд, будет целесообразным отказываться от использования этой директивы в пользу 301-го редиректа для индексирующих ботов. Так что данное нововведение представляется мне однозначно со знаком «минус», так как сильно ограничивает возможность управления консолидацией страниц сайта.
Так что данное нововведение представляется мне однозначно со знаком «минус», так как сильно ограничивает возможность управления консолидацией страниц сайта.
В середине августа произошло изменение в интерфейсе поиска Яндекса, не удостоившееся официального анонса. Тихо и незаметно из меню дополнительной информации сниппетов поисковой выдачи исчез пункт «Показать еще с сайта». Причем, на момент написания статьи упоминание об этом пункте еще сохраняется в соответствующем разделе Яндекс.Помощи. И пока еще можно увидеть, как это меню выглядело еще совсем недавно:
А вот как это меню выглядит в поисковой выдаче сейчас:
Вместо пункта «Показать еще с сайта» появились пункты «Информация о сайте» и «В избранное», не имеющие отношения к поисковому функционалу.
О том, что это отнюдь не случайность, свидетельствует и исчезновение поиска по сайту из фильтров расширенного поиска:
Причем, в данном случае соответствующая страница Яндекс. Помощи это изменение зафиксировала оперативно.
Помощи это изменение зафиксировала оперативно.
В общем, в Яндексе отчетливо прослеживается тенденция к упрощению поискового функционала. Так сказать, возврат от сложных форм к простым. Можно это называть архаизацией, можно дебилизацией, но суть от этого не меняется. Времена Кубка Яндекса по поиску давно канули в лету, поисковые инженеры теперь думают над тем, как избавить пользователя от необходимости думать. Такое впечатление, что эволюция поискового интерфейса Яндекса медленно, но верно идет к аналогу легендарной гугловской кнопки «I’m Feeling Lucky» («Мне повезет»), но с той разницей, что она будет единственной и выдавать ответ будет с наиболее подходящего яндексовского сервиса.
Хотя, следует признать, что физически возможность поиска по сайту не исчезла, пока еще функционируют get-параметр site
и поисковый оператор site:
Исчезла только возможность воспользоваться этой функцией, используя интерфейс.
Что же касается Google, то у него также нет возможности поиска по сайту ни из сниппетов, ни из инструментов поиска на странице выдачи. Однако у него есть такая возможность на странице расширенного поиска, аналог которой в Яндексе на данный момент отсутствует. Конечно, пока функционал поиска по сайту в Яндексе физически существует, это нововведение нельзя считать сколько-либо значимым в плане ограничения возможностей для анализа поисковой выдачи, но сам по себе звоночек, на мой взгляд, тревожный.
И наконец, 20 августа 2019 года Яндекс объявил об изменении правил работы с контентными зеркалами. Суть изменений заключается в том, что Яндекс теперь не будет склеивать полные дубли сайтов. Склейка зеркал сайтов будет осуществляться только через 301-й редирект.
Таким образом Яндекс наконец-то прикрыл одну очень неприятную дыру в алгоритме склейки зеркал. Дело в том, что разместив на подконтрольном домене копию чужого сайта, можно было рассчитывать на то, что при склейке зеркал Яндекс может назначить главным зеркалом именно ваш дубликат, а не чужой оригинал. Соответственно, весь поисковый трафик и все внешние поисковые сигналы оригинала перетекали при склейке к главному зеркалу, то есть подконтрольному злоумышленнику сайту. Ну, а как дальше распоряжаться полученным добром, это уже зависело целиком от его фантазии.
Соответственно, весь поисковый трафик и все внешние поисковые сигналы оригинала перетекали при склейке к главному зеркалу, то есть подконтрольному злоумышленнику сайту. Ну, а как дальше распоряжаться полученным добром, это уже зависело целиком от его фантазии.
Самое интересное, что когда владелец оригинала, обнаружив, что его сайт стал второстепенным зеркалом неподконтрольного ему дубликата, обращался в Яндекс, то он получал от Платона Щукина стандартный отлуп, о том, что «вручную расклеить сайты возможности нет, так как процесс автоматизирован», с предложением решать проблему с хостером сайта-дубликата или радикально изменить контент своего сайта, чтоб могла сработать автоматическая расклейка:
В общем, данное нововведение Яндекса можно только всячески приветствовать как несомненно оздоравливающее поисковую экосреду. Здесь поисковым инженерам Яндекса можно поставить однозначный зачёт.
канонических URL — веб-мастеру. Справка
Если на сайте есть страница, доступная по нескольким URL-адресам, или страницы с идентичным или похожим содержанием, робот Яндекса может засчитать их как дубликаты. В этом случае он объединит страницы в группу дубликатов и выберет одну из них, наиболее информативную и соответствующую поисковому запросу, для отображения в результатах поиска. Это называется канонической страницей .
В этом случае он объединит страницы в группу дубликатов и выберет одну из них, наиболее информативную и соответствующую поисковому запросу, для отображения в результатах поиска. Это называется канонической страницей .
- Как указать канонический URL-адрес страницы?
- Как изменить URL-адрес, используя канонический адрес?
- Канонические ошибки
- FAQ
Добавьте канонический URL-адрес в атрибут rel = «canonical» одним из следующих способов:
Допустим, к странице можно получить доступ по двум URL-адресам: www.example.com/pages?id==2 и www. example.com/blog.
Если предпочтительный адрес — / blog, добавьте в HTML-код / pages? Id = 2 элемент ссылки:
Допустим, на сайте есть файл PDF, доступный по нескольким URL-адресам: www.example.com/offer/file.pdf и www.example.com/files/file.pdf. Если предпочтительным URL-адресом является /offer/file.pdf, настройте сервер так, чтобы он передавал в HTTP-заголовке страницы /files/file.pdf следующее: Ссылка: ; rel = "canonical" Примечание. Укажите канонический URL в одном домене. Для канонического адреса укажите абсолютный путь, например http://example.com/blog/.
Страница с атрибутом rel = «canonical», которая указывает на другой URL, считается неканонической .
Робот узнает об изменениях при сканировании сайта. Если канонический URL введен правильно и робот не игнорирует инструкции, неканоническая страница исчезает из результатов поиска.Чтобы убедиться, что страница удалена из результатов поиска, отметьте в Яндекс.Вебмастере (блок Исключенные страницы).
Робот игнорирует инструкции, если содержимое канонической и неканонической страницы существенно отличается. В этом случае в поиск может быть включена неканоническая страница. Чтобы проверить это, перейдите по ссылке.
Чтобы исключить неканоническую страницу, которая содержит параметры или теги GET (UTM, from и т. Д.) В URL-адресе, добавьте директиву Clean-param в файл robots.txt.В противном случае используйте директиву Disallow.
Вы можете ввести канонический адрес, чтобы изменить URL-адрес сайта:
Робот интерпретирует канонический адрес как перенаправление на новое главное зеркало и группирует две версии сайта. Для этого добавьте ссылку на страницы на новом сайте с атрибутом rel = «canonical» в HTML или в заголовке HTTP каждой страницы на старом сайте. Например, вы измените http://example.com на https://example.com. На странице http://example.com/main/ укажите:
Например, вы измените http://example.com на https://example.com. На странице http://example.com/main/ укажите:
Если атрибут указывает на другую страницу, робот может счесть это различием в структуре сайта. В этом случае сайт не может быть перемещен.
Если вы измените URL, убедитесь, что содержимое на старом и новом сайте совпадает. Подробнее см. инструкции по перемещению.
Примечание. Если атрибут добавлен только на некоторые страницы, он не будет указывать на главное зеркало.
Робот Яндекс не считает URL-адрес каноническим, если:
- Канонический URL-адрес недоступен для робота — он перенаправляет на другую страницу или закрыт для индексирования.Это означает, что его нельзя включить в поиск. В этом случае неканонический URL-адрес может быть включен в поиск вместо канонического URL-адреса при условии, что робот может получить к нему доступ.
Канонический URL указывает на другой домен или субдомен.
Указано несколько канонических URL.
Задана цепочка канонических URL. Например, для example.ru/1 каноническим URL будет example.ru/2. В то же время на example.ru/2 есть пример канонического URL.ru / 3.
- Атрибут rel = «canonical» указывает на страницу, на которой он расположен. Это ошибка?
Нет. Если атрибут rel = «canonical» относится к странице, на которой он находится, робот считает ее канонической.
Как повторно включить неканоническую страницу в поиск?Если страница была исключена из результатов поиска как неканоническая, это означает, что робот обнаружил атрибут rel = «canonical» с каноническим URL-адресом в своем HTML-коде или HTTP-заголовке. Удалите эту ссылку и убедитесь, что страница, которую вы хотите снова включить в поиск, не закрыта для индексации.
| Низкое качество | BAD_QUALITY | Страница считается некачественной. | См. Рекомендации. |
| Исключено Clean-param | CLEAN_PARAMS | Страница была исключена из поиска после того, как робот обработал директиву Clean-param. | Чтобы страница проиндексировалась, отредактируйте файл robots.txt. |
| Дубликат | ДУПЛИКАТ | Страница дублирует страницу сайта, которая уже находится в поиске. | Укажите предпочтительный URL-адрес для робота, используя перенаправление 301 или атрибут rel = «canonical». Если содержимое страниц отличается, отправьте их на переиндексацию, чтобы ускорить обновление поисковой базы. |
| Ошибка подключения к серверу | HOST_ERROR | При попытке доступа к сайту робот не смог подключиться к серверу. | Проверьте ответ сервера, убедитесь, что робот Яндекса не заблокирован хостинг-провайдером. Сайт автоматически индексируется, когда становится доступным для робота. |
| Ошибка HTTP | HTTP_ERROR | Произошла ошибка при доступе к странице. | Проверить ответ сервера. Если проблема не исчезнет, обратитесь к администратору сайта или администратору сервера. Если страница доступна в данный момент, отправьте ее на переиндексацию. |
| Запрещено элементом noindex. | META_NO_INDEX | Страница была исключена из поиска, поскольку ей запрещено индексировать (с помощью метатега robots, содержащего директиву content = «noindex» или content = «none»). | Чтобы страница отображалась в поиске, снимите бан и отправьте на переиндексацию. |
| Неканонический | NOT_CANONICAL | Страница индексируется каноническим URL, указанным в атрибуте rel = «canonical» в ее исходном коде. | Исправьте или удалите атрибут rel = «canonical», если он указан неправильно.Робот автоматически отслеживает изменения. Для ускорения обновления информации о странице отправьте страницу на переиндексацию. |
| Дополнительное зеркало | NOT_MAIN_MIRROR | Страница принадлежит зеркалу дополнительного сайта, поэтому была исключена из поиска. | |
| Неизвестный статус | ДРУГОЕ | У робота нет актуальных данных на странице. | Проверить ответ сервера или запрещающие элементы HTML. Если страница недоступна для робота, обратитесь к администратору сайта или администратору сервера. Если страница доступна в данный момент, отправьте ее на переиндексацию. |
| Не удалось загрузить страницу | PARSER_ERROR | При попытке доступа к странице робот не смог получить ее содержимое.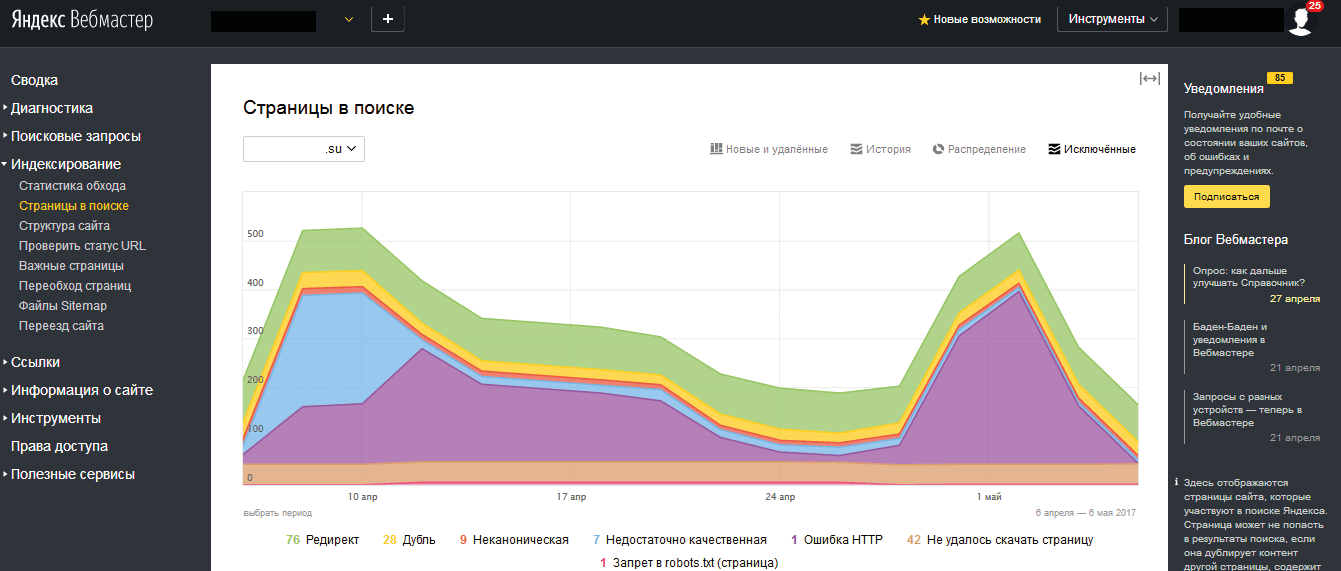 | Проверить ответ сервера или запрещающие элементы HTML. Если проблема не исчезнет, обратитесь к администратору сайта или администратору сервера.Если страница доступна в данный момент, отправьте ее на переиндексацию. |
| В поиске | REDIRECT_SEARCHABLE | Страница перенаправляется на другую страницу, но включается в поиск. | |
| Перенаправление | REDIRECT_NOTSEARCHABLE | Страница перенаправляет на другую страницу. Целевая страница проиндексирована. | Проверить индексацию целевой страницы. |
Запрещено в robots. txt (весь сайт) txt (весь сайт) | ROBOTS_HOST_ERROR | В robots запрещено индексирование сайта.txt файл. Робот автоматически начнет сканирование страницы, когда сайт станет доступен для индексации. | При необходимости внесите изменения в файл robots.txt. |
| Запрещено robots.txt (страница) | ROBOTS_TXT_ERROR | Индексирование сайта запрещено в файле robots.txt. Робот автоматически начнет сканирование страницы, когда сайт станет доступен для индексации. | При необходимости внесите изменения в файл robots.txt. |
| В поиске | В ПОИСКАХ | Страница включена в поиск. |

Поддерживает ли Яндекс канонический тег?
Краткий ответ: Да, с некоторыми отличиями.
Как и Google, Яндекс поддерживает канонический тег и использует его примерно так же.
Вы можете использовать канонический код для устранения потенциального дублирования в индексе Яндекса, но вместо обычной практики добавления саморегулирующихся канонических тегов на все страницы Яндекс может рассматривать это как сбивающие с толку и выделять сообщения об ошибках, которые примерно переведены на английский язык:
Код документа страницы содержит тег с rel = ”canonical”, который ссылается на URL-адрес страницы, который был проиндексирован роботом.Rel = «canonical» обычно используется на повторяющихся страницах на веб-сайте, и в этом случае исправлять нечего, поскольку нет дублирования.
Если страницы не дублируются и должны индексироваться роботом, вам необходимо удалить атрибут rel = ”canonical” из их исходного кода.
Если ваш веб-сайт является международным и вы внедрили общесайтовые канонические теги со ссылками на себя в соответствии с передовой практикой Google, в вашей альтернативной русскоязычной версии может быть полезно запустить другую базу кода и обработать возможное дублирование в Google Россия в альтернативном варианте. путь — таким образом вы сможете познакомиться с лучшими практиками как крупнейшей поисковой системы России, так и Google.
Реализация тега не отличается от стандартной реализации, к которой мы привыкли с Google:
Яндекс не принимает во внимание канонический тег и выделяет ошибки, если:
- Канонический URL недоступен для робота — он перенаправляет на другую страницу или закрыт для индексации. Это означает, что его нельзя включить в поиск. В этом случае неканонический URL-адрес может быть включен в поиск вместо канонического URL-адреса при условии, что робот может получить к нему доступ.
- Канонический URL указывает на другой домен или субдомен.
- Указано несколько канонических URL-адресов.
- Указана цепочка канонических URL-адресов. Например, для example.ru/1 каноническим URL будет example.ru/2. При этом example.ru/2 имеет канонический URL example.ru/3.
Однако Яндекс не поддерживает междоменный канонический.
Sitecore SEO: Google, Яндекс и Bing
Хотя Bing и Яндекс могут показаться незначительными в цифрах, они входят в пятерку самых популярных поисковых систем на планете, а Яндекс — на первом месте.1 в России. Они не только доминируют в мире поисковых систем, они также создали новый канал в современном маркетинге — поисковую оптимизацию (SEO).
Google, Яндекс и Bing — крупнейшие поисковые системы в настоящее время. Google имеет колоссальную долю рынка 91,89%, за ней следуют Bing с 2,79% и Яндекс с 0,54% .
С их постоянно развивающимися алгоритмическими изменениями и обновлениями поисковая оптимизация становится более сложной, чем когда-либо. Упрощение SEO имеет решающее значение для успеха на этом канале.В этой статье рассказывается, что вам нужно сделать, чтобы добиться максимальной производительности Sitecore SEO от вашего сайта Sitecore.
Упрощение SEO имеет решающее значение для успеха на этом канале.В этой статье рассказывается, что вам нужно сделать, чтобы добиться максимальной производительности Sitecore SEO от вашего сайта Sitecore.
Как попасть в индекс в Google, Яндекс и Bing
Первое и самое важное, что необходимо сделать перед оптимизацией, — это проиндексировать ваш сайт Sitecore поисковыми системами. Есть множество способов подойти к этому, но лучший из них — самый простой.
Подключение вашего сайта Sitecore к консоли поиска Google
Google Search Console — это набор инструментов и ресурсов, которые помогают владельцам веб-сайтов и специалистам по поисковой оптимизации отслеживать и обслуживать веб-сайты.
Некоторые из основных функций включают предоставление информации о внешнем виде поиска, производительности трафика, технических обновлениях, статусе сканирования и данных, обратных ссылках и ссылочных URL-адресах и многое другое.
- Зарегистрируйтесь в Google Search Console аккаунт
- Нажмите Добавьте свойство и в поле URL-адреса добавления сайта
- Выберите HTML-тег в качестве метода проверки
- Скопируйте метатег и вставьте его в раздел вашего сайта
- Когда это будет сделано, нажмите Проверить в окне консоли поиска Google
Источник: Google
Подключение вашего сайта Sitecore к Bing
После подключения вашего сайта к Google Search Console подключиться к Bing Webmaster довольно просто. Это можно сделать двумя способами. Первый — вручную, а второй — для проверки вашего сайта путем импорта аутентификации из Google Search Console.
Это можно сделать двумя способами. Первый — вручную, а второй — для проверки вашего сайта путем импорта аутентификации из Google Search Console.
- Открыть учетную запись Bing для веб-мастеров
- На главной панели инструментов нажмите кнопку в правом верхнем углу с надписью Пропустить проверку, импортировав свой сайт из консоли поиска Google
Источник: Bing
Подключение вашего сайта Sitecore к Яндекс.
Для бизнеса, у которого есть русскоязычный сайт, обязательно присутствие на Яндексе.Это потому, что Яндекс — поисковая система №1, которую выбирают люди в России.
- Создать аккаунт на Яндексе
- Перейдите на домашнюю страницу, найдите карточку веб-мастера и нажмите Добавить домен
- Введите имя вашего домена и нажмите Добавить
Подтвердите, что вы являетесь владельцем сайта:
- HTML-файл : создайте HTML-файл с указанным уникальным именем и содержимым и поместите его в корневой каталог своего сайта
- Мета-тег: Добавить специальный метатег в HTML-код на главной странице сайта (в элементе head)
- Если у вас уже есть основной домен, нажмите Сделать основным . После этого ваш новый домен станет основным доменом, а старый домен будет переведен в псевдоним домена .
 После этого ваш новый домен станет основным доменом, а старый домен будет переведен в псевдоним домена
После этого ваш новый домен станет основным доменом, а старый домен будет переведен в псевдоним доменаУзнайте о других способах подключения домена к Яндекс.
Источник: Яндекс
Подключение ваших XML-карт сайта к Google, Яндекс и Bing
После подключения и проверки вашего веб-сайта следующим шагом будет загрузка вашей XML-карты сайта во все инструменты для веб-мастеров (Яндекс, Bing и Google Search Console).
XML-карта сайта содержит список всех (включенных) страниц вашего веб-сайта.Хорошо структурированная иерархия / карта сайта в формате xml ведет поисковые системы ко всем вашим важным страницам.
Карту сайта обычно можно найти, добавив /sitemap.xml к URL-адресу вашего веб-сайта. Например: www.nameofyourwebsite.com/sitemap.xml. Если у вас нет карты сайта, попросите своего партнера по технологиям создать ее для вас.
Подключение XML-карты сайта Sitecore к Google Search Console
- На панели инструментов Google Search Console перейдите к левой панели. Под индексом нажмите Sitemaps
- Введите URL-адрес карты сайта в поле Добавить новую карту сайта .URL-адрес обычно /sitemap.xml, но обязательно перед отправкой
- После отправки, в зависимости от размера вашего сайта, статус в отчете ниже будет зеленым.
 Под индексом нажмите Sitemaps
Под индексом нажмите Sitemaps Подключение XML-карты сайта Sitecore к Bing
- На панели инструментов Bing Webmasters перейдите на левую панель. В разделе Настроить личный сайт щелкните Sitemaps
- Нажмите новый Перейти к карте сайта ссылку
- Нажмите Отправить карту сайта и отправьте URL-адрес, по которому находится ваша карта сайта
Подключение XML-карты сайта Sitecore к Яндексу
- В панели управления Яндекс Вебмастера перейдите на левую панель.В разделе Индексирование щелкните Файлы Sitemap
- Нажмите новый Перейти к карте сайта ссылку
- Введите URL-адрес карты сайта в поле Добавить новую карту сайта
- Нажмите Отправить
Если веб-сайт проверен и карта сайта успешно отправлена, как вы оптимизируете свой сайт Sitecore для Google, Яндекс и Bing для улучшения SEO? Это может быть очень детализировано, но три наиболее важные и часто используемые категории оптимизации:
- Техническое SEO
- Внутреннее SEO (контент)
- Внешнее SEO (профили с обратными ссылками)
Техническое SEO
Более 95% оптимизаций, сделанных для одной поисковой системы, обычно одинаковы для других поисковых систем.
Если вы правильно понимаете технические требования Google к SEO, вы в значительной степени правильно поняли и Bing, и Яндекс, хотя есть некоторые очень отличительные особенности, которые требуют большего внимания, чем другие.
Убедитесь, что ваш веб-сайт оптимизирован для мобильных устройств
Как следует из названия, содержание, оптимизированное для мобильных устройств, предназначено для оптимизации ваших технических, дизайнерских и информационных основ для мобильных пользователей, а также для удобства использования мобильных устройств.
Ниже приведены 26 рекомендаций, которые помогут улучшить индексацию вашего сайта Sitecore на мобильных устройствах.
- Используйте одни и те же метатеги для роботов на мобильных и настольных сайтах
- Не ленитесь загружать основной контент при взаимодействии с пользователем
- Разрешить Google сканировать все ресурсы
- Убедитесь, что содержимое одинаково на настольных компьютерах и мобильных устройствах
- Используйте те же четкие и содержательные заголовки
- Убедитесь, что на вашем мобильном устройстве и на компьютере используются одинаковые структурированные данные
- Используйте правильные URL-адреса в структурированных данных
- Если вы используете Data Highlighter, обучите его на своем мобильном сайте
- Поместите одинаковые метаданные в обе версии вашего сайта (метатеги, метаописания и т. Д.)
- Обеспечивает высокое качество изображений
- Используйте поддерживаемый формат для изображений
- Не используйте URL-адреса, которые меняются каждый раз при загрузке страницы
- Убедитесь, что на мобильном сайте есть тот же замещающий текст для изображений, что и на сайте для ПК.
- Убедитесь, что качество содержимого мобильной страницы такое же хорошее, как страница для ПК.
- Не используйте URL-адреса, которые меняются каждый раз при загрузке страницы для ваших видео
- Использовать поддерживаемый формат для видео
- Использовать те же структурированные видеоданные
- Поместите видео в удобное для поиска место на странице при просмотре на мобильном устройстве
- Убедитесь, что статус страницы ошибки одинаков как на настольных, так и на мобильных сайтах.
- Убедитесь, что в вашей мобильной версии нет URL-адресов фрагментов.Например, страницы, начинающиеся с #, эти страницы не будут проиндексированы
- Убедитесь, что настольные версии, обслуживающие разный контент, имеют эквивалентные мобильные версии.
- Проверьте обе версии вашего сайта в консоли поиска (только если у вашего сайта есть собственный URL)
- Проверить hreflang ссылок на отдельные URL
- Убедитесь, что ваш мобильный сайт имеет достаточную емкость для обработки повышенной скорости сканирования
- Убедитесь, что ваши директивы robots.txt работают так, как вы предполагаете, для обеих версий (если у вас есть сайт для мобильных устройств)
- Используйте правильные атрибуты rel = canonical и rel = alternate для отдельных URL-адресов

Вы также можете использовать тест Google Mobile Friendly, чтобы узнать, насколько эффективен ваш сайт на мобильных устройствах.
Узнайте больше о передовых методах работы с мобильными устройствами.
Понимание основ JavaScript для SEO
Все специалисты по SEO и маркетологи должны привыкнуть к некоторым техническим особенностям SEO с использованием JavaScript. JavaScript — важная часть набора инструментов веб-разработки, поскольку он предоставляет множество функций, которые превращают веб-разработку в мощную платформу приложений.
Создание веб-приложений на базе JavaScript, которые можно обнаружить с помощью поисковых систем, может помочь новым пользователям и повторно привлечь существующих пользователей в процессе поиска контента, предоставляемого вашим веб-сайтом.
Понимание того, как AMP выглядит в результатах поиска и работает
В отличие от JavaScript SEO, Accelerated Mobile Pages намного проще, но в равной степени является неотъемлемой частью технического контента и планов SEO.
AMP — это более простые страницы вашего текущего веб-сайта, которые могут быть обслужены пользователями намного быстрее. Это улучшает работу в Интернете для мобильных посетителей, особенно при медленном подключении к Интернету. Google Search и все другие поисковые системы индексируют AMP.
Повышение скорости страницы
Иногда поисковые системы могут быть довольно снисходительными, когда дело доходит до того, что некоторые мелкие технические элементы не совсем правильны, но скорость страницы не входит в их число. Самое важное ожидание от поисковой системы, будь то Google, Bing или Яндекс, заключается в том, что все они требуют, чтобы ваш веб-сайт и отдельные страницы имели хорошую скорость загрузки.
Самое важное ожидание от поисковой системы, будь то Google, Bing или Яндекс, заключается в том, что все они требуют, чтобы ваш веб-сайт и отдельные страницы имели хорошую скорость загрузки.
Все поисковые системы недавно сделали скорость страницы обязательным фактором ранжирования. Инструмент Google Page Speed Tool — отличный способ узнать, насколько эффективно загружается страница вашего сайта Sitecore.
Содержимое HTTPS и смешанное содержимое
HTTPS стал фактором ранжирования в 2014 году для Google и в 2015/2016 для других поисковых систем.
Предполагается, что более 80% веб-сайтов во всех поисковых системах поддерживают протокол HTTPS. Вот почему важно проверять распространенные проблемы HTTPS в рамках ежемесячных аудитов, поскольку новые ресурсы и вновь созданный контент не всегда могут быть безопасными. Например, проблемы смешанного содержимого обычно возникают, когда защищенный контент (ресурсы и страницы HTTPS) смешивается с незащищенными страницами (ресурсы и страницы HTTP).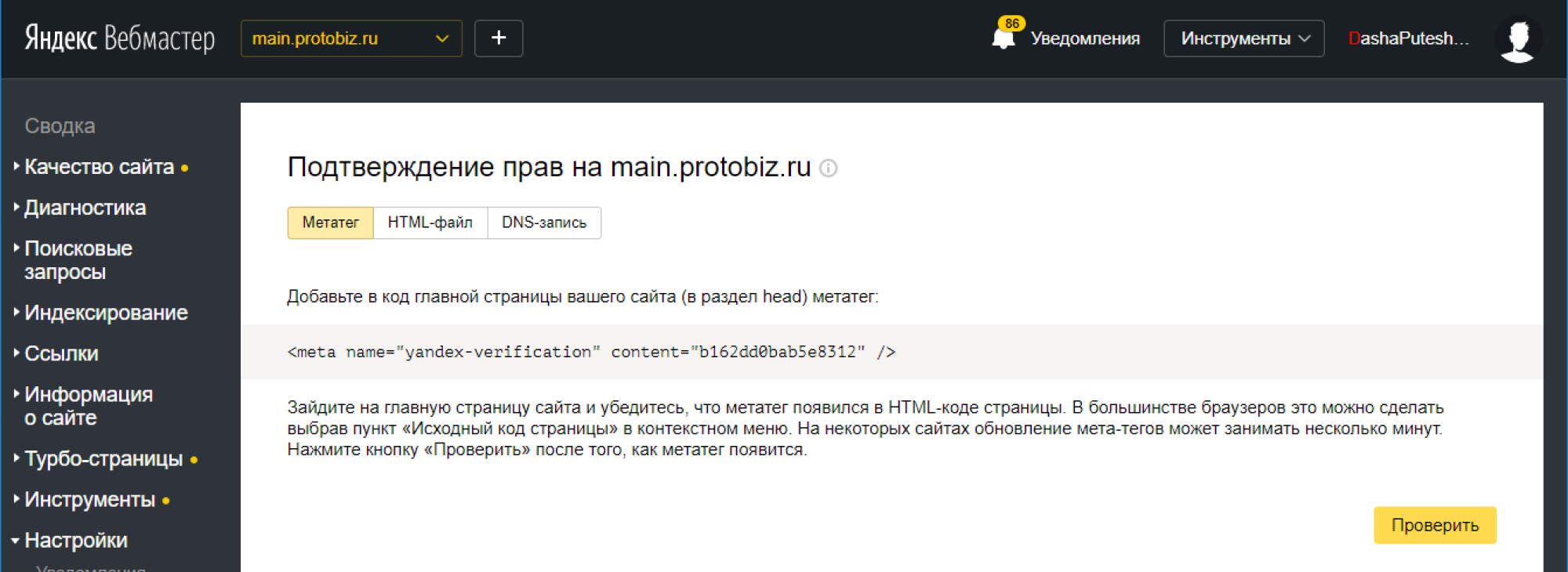 Это ослабляет воспринимаемую безопасность.
Это ослабляет воспринимаемую безопасность.
Канонические проблемы и проблемы с hreflang
Канонический тег или rel = canonical информирует поисковые системы о том, что конкретный URL-адрес является главной копией страницы.Другими словами, это предпочтительный URL для индексации.
Использование канонического тега предотвращает проблемы идентификации, с которыми сталкиваются сканеры, посещающие веб-страницу, и предотвращает индексацию дублированного контента. Он сообщает поисковым системам, какую версию URL вы хотите проиндексировать и таким образом отображать в поисковых системах.
Некоторые передовые практики:
- Канонические теги могут ссылаться на себя
- Убедитесь, что вы канонизируете свою домашнюю страницу
- Проверьте динамические канонические теги (не пытайтесь написать скрипт для заполнения ваших канонических тегов, это может пойти не так и потенциально проиндексировать 100 неправильных страниц)
- Включите поле Canonical URL в редактор содержимого всех ваших страниц Sitecore.

Если на вашем сайте Sitecore включено международное управление версиями, то применение атрибута hreflang оптимизирует ваше SEO.
Применение тега hreflang сообщает поисковым системам, какую версию контента показывать в зависимости от языка и региона посетителя. hreflang также предотвращает проблемы с дублированием содержимого. Если в URL-адресе указан идентификатор страны / языка (например, страница www / yourdomain.com / en-gb / ) в сочетании с атрибутами hreflang для региональных / языковых вариантов, эта английская версия страницы будет отображаться в поисковой выдаче для пользователь в Великобритании.
Внутренние ссылки и «ссылочный сок»
Внутренние ссылки могут быть частью более сложной технической экосистемы, но также являются частью оптимизации контента.
Внутренние ссылки помогают поисковым системам лучше сканировать сайт. Думайте об этом как о строках, которые связывают все статьи и страницы друг с другом. Сканеры используют эти строки для поиска контента и его индексации. Чем больше строк связано со всеми частями сайта, тем лучше индексация. Это также называется «ссылочным соком».
Сканеры используют эти строки для поиска контента и его индексации. Чем больше строк связано со всеми частями сайта, тем лучше индексация. Это также называется «ссылочным соком».
Очень важно, чтобы вы включали релевантные ссылки на другие части веб-сайта на каждой странице или в каждой статье. Но постарайтесь не переусердствовать, поскольку контент должен хорошо (и естественно) читаться посетителям.
Статьи в блогах — лучшее место для связи с другими частями вашего сайта.
Чтобы лучше понять, как работают внутренние ссылки, просмотрите отчеты профилей ссылок в Google Search Console, Яндексе и Bing.
Увеличьте свой краулинговый бюджет
Бюджет сканирования — это количество страниц, которые поисковые системы просматривают за определенный период времени. Это не фактор ранжирования, но он помогает чаще приглашать роботов к вашему поиску.
Чтобы понять, как это работает, просмотрите разделы в своих веб-мастерах, которые говорят, что Статистика сканирования или Статус сканирования .
Если вы видите, что графики краулингового бюджета высоки, это означает, что ваш сайт нуждается в хорошей очистке с точки зрения SEO. Так что же такое хорошая чистка?
- Удалите дублированный контент, , чтобы не тратить краулинговый бюджет
- Ограничить индексацию страниц без значения SEO . Страницы со старым контентом, которые не работают должным образом или имеют больше проблем, которые посещают, или, что еще лучше, перенаправляют их
- Добавить параметры URL в Google Search Console .По умолчанию Google сканирует все страницы, представленные на веб-сайте, но иногда важно добавить ограничения на параметры URL, чтобы ограничить индексирование страниц, таких как страницы BackToResults или динамические страницы, найденные с помощью расширенных фильтров на вашем сайте
- Исправить цепочки переадресации. Цепочка перенаправления — это цепочка перенаправлений, которая может быть собрана за период перенаправления одних и тех же страниц на другие страницы, не зная, перенаправлялись ли они ранее. Избегайте этого, потому что поисковый робот постоянно индексирует одни и те же страницы
 Избегайте этого, потому что поисковый робот постоянно индексирует одни и те же страницы
Избегайте этого, потому что поисковый робот постоянно индексирует одни и те же страницыSEO на странице
Оптимизация на странице — это практика оптимизации отдельных веб-страниц для повышения их рейтинга в поисковых системах и увеличения посещаемости.В отличие от технического SEO, оптимизация на странице в основном связана с контентом и связанным с ним HTML.
Ниже приведены некоторые методы, которые помогут вашему Sitecore на странице SEO:
Публикуйте высококачественный контент
Качество может иметь большое значение для многих маркетологов. Обычно это приводит к слишком большому количеству контента, слишком маленькому контенту, нерелевантному контенту или контенту, который поглощается ключевыми словами. Ниже приведены несколько советов по улучшению SEO на странице Sitecore:
- Исходное содержимое: Никаких копий и перезаписей существующего содержимого; постарайтесь использовать на странице как можно больше исходных ресурсов
- Добавьте канонические теги : убедитесь, что каждая статья или сообщение имеют канонический URL
- Значение : публикация содержимого, предоставляющего значение
- Исследование : Напишите хорошо изученный контент
- Деталь: Создавайте более длинные и подробные статьи
Заголовки страниц и метаописания
Это основная форма SEO и фундаментальный фактор ранжирования. Вот несколько советов:
Вот несколько советов:
- Каждая страница должна иметь уникальный заголовок и соответствовать тому, что страница пытается сказать
- Добавьте ключевые слова в начало заголовков страниц
- Пишите короткие и описательные заголовки. Пользователи обычно нажимают на короткие точные заголовки
- Не всегда обязательно указывать название вашего домена
- Убедитесь, что в заголовке указано ограничение на количество символов поисковой системы
Метаописание — это описание страницы в нескольких словах, которое часто можно увидеть прямо на странице результатов поисковой системы.Это возможность превратить холодного пользователя в читателя. Вот несколько способов оптимизации метаописаний:
- Найдите время, чтобы написать оригинальные метаописания и сохранить уникальность тегов
- Убедитесь, что вы также добавили в него целевые ключевые слова.
- Не превышайте ограничение по количеству слов мета-описания, которое есть в поисковых системах
Оптимизировать содержимое страницы
Оптимизация общего форматирования контента и самого контента является ключевым моментом, поскольку сканеры всех поисковых систем следуют текстовому формату HTML. Так что убедитесь:
Так что убедитесь:
- Все теги заголовков верны (h2, h3, h4 и т. Д.)
- Попробуйте включить ключевые слова в заголовки
- Используйте хорошо изученные ключевые слова с высокой посещаемостью в тексте
- Используйте ключевые слова LSI (слова, которые имеют прямое или косвенное отношение к вашей теме)
- Сохраняйте изображения высокого качества
- Убедитесь, что изображения имеют замещающий текст и другие атрибуты, например «Название».
- Добавить разметку схемы или структурированные данные
- Добавьте Facebook Open Graph для лучшего обмена в социальных сетях
- Избегайте длинных абзацев.Сделайте статью удобочитаемой и разбейте на кусочки информацию
Оптимизировать URL
Это может быть самый простой из всех методов оптимизации на странице, но в большинстве статей это неверно из-за динамически генерируемых URL-адресов. По возможности избегайте этого и пишите простые, точные и релевантные структуры URL-адресов с соответствующими ключевыми словами.
Внутренняя ссылка
Как уже упоминалось, внутренние ссылки помогают поисковым системам лучше сканировать сайт, поскольку они используют ссылки для перемещения по сайту.
Внешние ссылки
Наличие внешних ссылок из вашей статьи на другой надежный источник или публикацию повышает надежность статьи. Это положительный фактор SEO. Каждый раз, когда вы цитируете или используете контент с другого веб-сайта, упомяните источник и сделайте ссылку на статью.
Внестраничное SEO
Off-page SEO — это оптимизация вашего собственного сайта. Он получает рейтинг SEO по сравнению с другими внешними веб-сайтами в виде обратных ссылок. Google недавно подтвердил, что обратные ссылки являются одним из трех наиболее важных факторов ранжирования.Обратные ссылки должны быть в верхней части списка для всех маркетологов.
Как получить обратные ссылки:
- Начать гостевой блог с авторитетными блогами и издателями
- Переверните обратные ссылки ваших конкурентов и внесите свой вклад в их источники обратных ссылок
- Упомяните ключевых влиятельных лиц отрасли в своих сообщениях в блоге
- Публикуйте загружаемый контент и руководства со ссылками на ваш основной веб-сайт
- Публикация статей или контента в качестве приглашенных пользователей на сайтах пользователей и в социальных сетях
- Станьте лидером отрасли, публикуя контент других участников на своем сайте в обмен на публикацию вашего контента на их сайте
Оптимизация для Google похожа на оптимизацию для всех других поисковых систем, поскольку они являются наиболее сложной и доминирующей поисковой системой на рынке. Выполнение шагов, описанных в этой статье, улучшит SEO Sitecore для Google, Яндекс и Bing.
Выполнение шагов, описанных в этой статье, улучшит SEO Sitecore для Google, Яндекс и Bing.
Наша команда по цифровому опыту помогла многим клиентам начать работу с SEO на сайтах Sitecore, а также решить более сложные задачи SEO. Чтобы получить дополнительную информацию о том, как SEO-аудит может помочь вашему сайту, свяжитесь с нами.
Beyond Google: вселенная поиска
Блог OnCrawl> Мысли об SEO> За пределами Google: вселенная поиска
Когда мы говорим о поиске, мы часто говорим о Google: на Google и свойства Google приходится львиная доля видимости при поиске.Есть причина, по которой мы говорим, что собираемся что-то «погуглить». Но Google — не единственная поисковая система, и, в зависимости от вашей аудитории, вы можете получить большую популярность, адаптируя SEO для остальной части поисковой вселенной.
Поисковые системы, поисковые системы везде
Несмотря на мировое господство Google, есть районы, в которых другие поисковые системы имеют прочную — и растущую — точку опоры. Фактически, Википедия перечисляет около 20 или около того текущих общих поисковых систем, а также намного больше тематических поисковых систем..
Фактически, Википедия перечисляет около 20 или около того текущих общих поисковых систем, а также намного больше тематических поисковых систем..
Крупнейшими конкурентами Google являются Bing (и Yahoo!), Яндекс, Baidu и небольшая, но растущая компания DuckDuckGo:
.Bing и Yahoo!
В 2009 году Bing и Yahoo! Подписали десятилетнее соглашение о совместном использовании поисковых технологий, что означает, что их ранжирование, индексы и использование поиска одинаковы и могут быть объединены в единую поисковую систему с двумя лицами. Мы будем рассматривать их как единое целое до конца этой статьи.
Bing особенно интересен для SEO и маркетологов, но только потому, что ему принадлежит более трети доли рынка США, а также потому, что есть некоторые свидетельства того, что трафик Bing конвертируется лучше, чем трафик Google.
Оптимизация для Bing
Bing использует многие из тех же технологий и работает со многими из тех же сигналов ранжирования, что и Google. Однако есть отличия.
Однако есть отличия.
Некоторые сигналов ранжирования имеют большее значение в Bing, чем в Google:
- Возраст домена и продление
- Социальные сигналы
Социальные сети играют важную роль в сегодняшних усилиях по повышению рейтинга в результатах поиска. Наиболее очевидная роль, которую он играет, — это влияние. Если вы являетесь влиятельным лицом в социальных сетях, ваши подписчики обычно широко делятся вашей информацией, что, в свою очередь, приводит к тому, что Bing видит эти положительные сигналы.Эти положительные сигналы могут повлиять на то, как ваш сайт будет занимать в долгосрочной перспективе органический рейтинг.
Внутреннее SEO для Bing также немного отличается от Google. Бинг объясняет:
- Ожидается только один
на странице.
- Внутренние ссылки используются для определения того, как контент связан.
- Ключевое слово / фразу, на которую вы нацеливаете, следует несколько раз использовать в содержании вместе с вариантами ключевого слова или фразы.
- Свежий контент, как в Google, является преимуществом.

Как и Google, Bing оценивает удобство использования для мобильных устройств . При определении удобства использования мобильных устройств учитываются следующие особенности:
- Конфигурация окна просмотра
- Конфигурация увеличения
- Ширина содержимого
- Читаемость текста
- Расстояние между ссылками и другим контентом
- Важные ресурсы, заблокированные для Bingbot
Вы можете настроить таргетинг на локальных поисковых запросов с помощью геотаргетинга всего или части вашего сайта в Инструментах для веб-мастеров.Геотаргетинг в Bing явно указывается веб-мастером и может применяться к странице, каталогу, субдомену или ко всему домену.
Наконец, Bing также использует сущности для лучшего понимания контента и поддерживает множество сущностей с помощью разметки Schema.org :
Скорость страницы: быстрая победа для SEO
Почему вам нужно заботиться о скорости страницы? Потому что это важно для вашего SEO. OnCrawl показывает, где падает порог между «достаточно быстро» и «слишком медленно».
OnCrawl показывает, где падает порог между «достаточно быстро» и «слишком медленно».
Возможность сканирования для Bing
Как и Google, индекс Bing создается и обновляется в основном путем сканирования Интернета. Это означает, что веб-сайты должны быть доступны для сканирования для правильного ранжирования в Bing.
Согласно документации Bing, следующие элементы облегчают сканирование:
Как и Google, вы также можете отправлять URL-адреса для индексации. Bing будет сканировать URL-адреса, которые он находит в картах сайта, но вы также можете массово отправлять URL-адреса с помощью их инструмента индексации и отправлять их непосредственно в индекс через их API.
Инструменты и технологии Bing
Инструменты
Технологии
Яндекс
Яндекс — это российский эквивалент Google. В дополнение к своей поисковой системе у него есть много других веб-ресурсов, аналогичных Google: электронная почта, фотографии, продукты . .. Яндекс может претендовать на более 50% доли поискового рынка в России, и он хорошо известен и используется во многих соседних странах. .
.. Яндекс может претендовать на более 50% доли поискового рынка в России, и он хорошо известен и используется во многих соседних странах. .
[Электронная книга] Техническое SEO для нетехнических мыслителей
Техническое SEO — одно из растущих направлений SEO сегодня.Он включает поиск решений для SEO на основе того, как и почему работают поисковые системы и веб-сайты. В этой электронной книге есть все, чем вы всегда хотели поделиться со своими клиентами, друзьями и коллегами по маркетингу.
Рейтинг в Яндексе
Важно понимать, что Яндекс, как русскоязычная поисковая система (в первую очередь русскоязычная), отдает приоритет географии России в локальном поиске и использует отдельные алгоритмы ранжирования для доменов .ru по сравнению с остальной частью Интернета.
По сравнению с Google процесс индексации Яндексом сильно отличается:
- Более медленный процесс индексации
- Страницы размером более 10 МБ не индексируются
- URL длиной более 1024 символов не индексируются
- Языковая фильтрация:
- «Автоматическая» индексация сайтов, содержащих страницы на русском, украинском и белорусском языках
- Оценка содержания сайтов на английском, немецком и французском языках
- Другие языки не поддерживаются
Наконец, не все проиндексированные страницы могут отображаться в поиске. Фактически, коды статуса 3xx, 4xx и 5xx или переадресация, нацеленная только на роботов, могут исключить страницу из результатов поиска, даже если она проиндексирована.
Чтобы узнать, какие из ваших страниц доступны, вы можете обратиться к разделу «Страницы в поиске» в инструментах для веб-мастеров.
Среди сигналов ранжирования с наибольшим весом для Яндекса:
- Поведение пользователя: «Поведение пользователя является ОГРОМНЫМ фактором ранжирования и играет гораздо большую роль, чем другие сигналы, такие как создание ссылок».
- Техническая оптимизация
- Полнота и уникальность контента (обратите внимание, что фильтр дублированного контента Яндекс более строгий, чем у Google.)
- Локализация (регион)
- Факторы коммерческого ранжирования, такие как подробная информация о компании, цены, условия обслуживания или отзывы
- Возраст домена и актуальность контента
- Использование ключевого слова, включая мета-теги ключевых слов и наличие ключевого слова в URL-адресе. Однако обновление алгоритма Палеха для длиннохвостых запросов также ввело нейронную сеть в анализ запросов Яндекса.
 Однако обновление алгоритма Палеха для длиннохвостых запросов также ввело нейронную сеть в анализ запросов Яндекса.
Однако обновление алгоритма Палеха для длиннохвостых запросов также ввело нейронную сеть в анализ запросов Яндекса.Если это начинает выглядеть как крупные, хорошо зарекомендовавшие себя сайты электронной коммерции, это значит, что вы недалеко от цели.
Сканируемость для Яндекса
Хотя веб-сайт необходимо просканировать, чтобы он был проиндексирован и ранжирован в Яндексе, ключевые слова играют более важную роль, чем внутренние ссылки. Следовательно, внутренняя структура сайта менее важна, чем для Google.
Веб-мастерам рекомендуется:
- Отправить карты сайта
- Используйте статический контент, так как краулер Яндекса не поддерживает Javascript
Бот Яндекса проверяет следующие элементы HTML:
- Мета-ключевые слова: используются для определения релевантности страницы
- Мета-описание: используется как описание в сниппетах (также можно использовать текст страницы)
- Meta viewport: указывает на совместимость адаптивного дизайна
- Мета Content-Type: используется для определения типа и содержимого URL-адреса
- Meta Refresh: может использоваться для перенаправления страниц. Этот метатег перенаправит посетителя через N секунд
- Мета-роботы
- тегов
- Ссылка rel = nofollow
- Ссылка rel = canonical. Это можно игнорировать, если канонический URL недоступен, если канонический находится в другом домене или субдомене или если предоставлено несколько канонических URL-адресов.
 Этот метатег перенаправит посетителя через N секунд
Этот метатег перенаправит посетителя через N секундОптимизация под Яндекс
Есть несколько аспектов, в которых Яндекс существенно отличается от Google.
Hreflang
Hreflang следует использовать для Яндекс в следующих случаях:
- Версии страницы «различаются только языком шаблона», хотя контент, например сообщения в блогах или комментарии на форуме, остается прежним
- Версии страницы на одном языке, но ориентированы на разные страны или регионы
- Страницы — это «полные и точные» переводы
- Страницы, которые автоматически перенаправляются по местоположению или языку, должны использовать hreflang по умолчанию x
Теги Hreflang работают только в ответах
или HTTP; карты сайта не поддерживаются.
Тематический указатель цитирования (TIC)
ТИЦ Яндекса используется для прямого ранжирования сайтов; теперь он стал отражением качества, но не совсем коррелирует с рейтингом сайта. TIC — это оценка от 0 до 150 000, которая измеряет, насколько хорошо сайт ссылается на то, что повышает ценность для пользователя. Ценность определяется качественным содержанием и актуальностью тематики.
Геотаргетинг
Яндекс призывает веб-мастеров указывать в инструментах для веб-мастеров регион, на который ориентированы их веб-сайты.
Геозависимые и геонезависимые запросы обрабатываются по-разному, и результаты не смешиваются в результатах поиска. Это означает, что если ваш бизнес может получать прибыль от локального поиска, требуется геотаргетинг.
Для геотаргетинга страницы вам потребуется:
- Опубликуйте название, адрес, почтовый индекс, номер телефона и код города своей компании на своем веб-сайте.
- Публикуйте одинаковую информацию для всех региональных филиалов вашего бизнеса.
- Сделайте каждую страницу своего сайта доступной для робота Яндекса независимо от IP-адреса робота.
Антиссылка на спам
Яндекс вложил значительные усилия в борьбу со ссылочным спамом, который они определяют как использование ссылок, созданных для воздействия на поисковые алгоритмы, которые могут быть куплены или проданы в попытке искусственно повысить авторитет сайта без повышения качества сайта.
Алгоритм «Минусинск» обнаруживает ссылочный спам и может привести к серьезным штрафам.
Мобильный поиск
Мобильный поиск в России стремительно развивается.Критерии ранжирования Яндекс для мобильного поиска аналогичны критериям Google.
Однако важно разместить мобильную версию сайта на отдельном субдомене или отдельном домене:
Яндекс рассматривает основную версию и мобильную версию сайта как отдельные сайты и индексирует их отдельно друг от друга.
Чтобы помочь роботу правильно идентифицировать мобильную версию, укажите URL-адреса мобильных страниц на соответствующих страницах основного сайта.
[…] Если мобильная версия сайта находится в основном каталоге сайта, робот-индексатор Яндекса не сможет ее правильно проиндексировать. Рекомендуем создавать мобильную версию в отдельном домене или в поддомене основного сайта.— Служба поддержки Яндекса
 Например, вы можете использовать элемент.
Например, вы можете использовать элемент.Инструменты и технологии Яндекса
Инструменты
Технологии
Яндекс имеет ряд операторов, которые можно использовать для создания более конкретных поисковых запросов:
- Проверьте, что индексируется для сайта, с помощью оператора запроса url.В поисковой строке Яндекса введите url: оператор запроса, адрес сайта и *. Например: url: www.example.com *.
- Заголовок [ключевое слово] — поиск по заданному ключевому слову в теге заголовка, работает так же, как оператор Google intitle :.
- Inurl = ”keyword” — работает так же, как оператор Google inurl :.
- Mime = ”html / pdf / doc / ppt / xls / rtf / swf” — поиск файлов определенных типов, например: seo << mime = ”ppt” вернет результаты, которые являются файлами PowerPoint, имеющими отношение к SEO.

Baidu (百度)
Baidu — основная поисковая система Китая. Коммунистический режим Китая означает, что это подразумевает несколько важных моментов: во-первых, Google недоступен в Китае. Во-вторых, Baidu ограничен веб-сайтами, оба на китайском языке. Наконец, действует государственная цензура.
Рейтинг в Baidu
Как и другие поисковые системы, индекс Baidu создается путем сканирования пауком Baidu. Вместо простого перехода по ссылкам, URL-адреса, полученные с помощью инструмента отправки ссылок Baidu, имеют приоритет для сканирования.
Алгоритмы ранжирования Baidu не дискриминируют иностранные сайты. Однако они ранжируют только те сайты, которые соответствуют запросам на упрощенном китайском языке. Это означает, что содержание на китайском языке является обязательным.
Упрощенный сценарий и грамматика китайского языка могут быть препятствием для регионов, в которых используется традиционный сценарий (Тайвань, Гонконг), а также регионов, где используются другие китайские языки с упрощенным сценарием, хотя Baidu по-прежнему используется веб-сайтами и пользователями в обоих случаях .
Другие факторы ранжирования включают:
- Свежесть
- Плоская структура сайта (страницы, расположенные ближе к домашней странице, считаются более важными, а элементы, связанные с внутренними ссылками, такие как неработающие ссылки, перенаправления и текст привязки, могут иметь прямое влияние на рейтинг.Например, страницы-сироты часто не индексируются.)
- Несколько поддоменов
- Нет Javascript (не поддерживается Baidu spider)
- Скорость страницы
- Качество контента
- Мобильность
- Точное совпадение ключевого слова в заголовке
Наконец, как и в поисковой выдаче Google, продукты Baidu часто помещаются перед органическими результатами. Сюда входят объявления и страницы, принадлежащие Baidu.
Оптимизация для Baidu
Скорость страницы
Алгоритмы Baidu придают огромное значение скорости страницы до такой степени, что веб-сайты должны размещаться в Китае, чтобы быть конкурентоспособными. Хостинг в Китае чрезвычайно сложен для иностранных веб-сайтов (вам нужна лицензия поставщика интернет-контента, которая, в свою очередь, требует китайской бизнес-лицензии…), поэтому большинство зарубежных веб-сайтов должны полагаться на CDN.
Хостинг в Китае чрезвычайно сложен для иностранных веб-сайтов (вам нужна лицензия поставщика интернет-контента, которая, в свою очередь, требует китайской бизнес-лицензии…), поэтому большинство зарубежных веб-сайтов должны полагаться на CDN.
Независимо от того, как вы размещаете свой веб-сайт, скорость загрузки страниц важна, и ограничения очевидны: первый экран страниц должен загружаться в течение 1,5 секунд.
Качество содержания
До недавнего времени качество контента не имело особого значения; однако качество становится все более важным фактором.
Заголовки страниц чрезвычайно важны. Заголовки должны быть четкими, краткими (нерелевантные слова могут повлечь за собой штрафные санкции) и содержать ключевые слова страницы (но за набивку текста наказываются).
Из-за местного, коммунистического контекста чрезвычайно важно проверять и подтверждать весь контент перед его публикацией.
SEO на странице
Поисковая оптимизация на странице для Baidu рассматривает многие из тех же элементов, что и поисковая оптимизация на странице для других поисковых систем, но уделяет приоритетное внимание другим аспектам.
Инструкции Baidu для веб-мастеров включают следующие правила для страниц:
- Первый экран вашей страницы должен загрузиться в течение 1,5 секунд
- В контенте должен использоваться шрифт не менее 10 пунктов
- Основной контент (основная часть, за исключением панели навигации и любой рекламы) вашего веб-сайта должно занимать не менее 50% первого экрана.
- Для результатов мобильного поиска целевая страница должна быть адаптирована для мобильных устройств
- Необходимо соблюдать правила мобильной связи и пользовательского интерфейса
- Сайт должен использовать HTTPS
- Страница должна включать следующие HTML-теги:
,<meta name = ”description”>,<meta name = ”keywords”> и заголовки (<h2><span class="ez-toc-section" id="i-29">…) </span></h2></li><li> Страница должна ссылаться на домашнюю страницу</li></ul><p> <strong> Домашняя страница </strong></p><p> Дополнительный вес придается домашней странице веб-сайта как в алгоритмах ранжирования, так и в правилах для страниц.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/i2.wp.com/ilyapronin.ru/wp-content/uploads/2014/08/urlyandex.png' style='float: right;' /><noscript><img src='/800/600/https/i2.wp.com/ilyapronin.ru/wp-content/uploads/2014/08/urlyandex.png' style='float: right;' /></noscript> Фактически, домашние страницы чаще появляются в результатах поиска. Следовательно, многие китайские сайты, оптимизированные для Baidu, содержат мало страниц, поэтому большую часть своего контента предпочитают размещать на самой домашней странице.</p><h4><span class="ez-toc-section" id="_Baidu-3"> Инструменты Baidu </span></h4><p> <strong> Инструменты </strong></p><h3><span class="ez-toc-section" id="DuckDuckGo"> DuckDuckGo </span></h3><p> DuckDuckGo сильно отличается от других поисковых систем как своими принципами, так и технологиями. Он был основан на идее, что конфиденциальность должна иметь значение, и поэтому не адаптирует свои результаты на основе профилей пользователей.Он также не использует поискового робота для индексации и ранжирования, а основывает свои результаты поиска на «источниках».</p><p> Как следствие, локальный поиск, как правило, дает менее подходящие результаты на DuckDuckGo. Даже запросы с указанием местоположения часто не очень точны, но поисковая система привлекает все большее количество пользователей из-за проблем с конфиденциальностью и данными.</p><h4><span class="ez-toc-section" id="_DuckDuckGo"> Рейтинг в DuckDuckGo </span></h4><p> DuckDuckGo объясняет:</p><blockquote><p> DuckDuckGo получает результаты из более чем четырехсот источников.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/otvet.imgsmail.ru/download/dc1ff7f0230be890620af671655b5265_i-498.jpg' style='float: right;' /><noscript><img src='/800/600/https/otvet.imgsmail.ru/download/dc1ff7f0230be890620af671655b5265_i-498.jpg' style='float: right;' /></noscript> К ним относятся сотни вертикальных источников, доставляющих нишевые мгновенные ответы, DuckDuckBot (наш поисковый робот) и краудсорсинговые сайты (такие как Википедия, хранящиеся в наших индексах ответов).У нас также, конечно, есть более традиционные ссылки в результатах поиска, которые мы получаем из Bing, Yahoo и Яндекс. <br/> — Источники DuckDuckGo</p></blockquote><p> Это означает, что если ваш сайт проиндексирован на Bing, Yandex или Google, он также будет доступен на DuckDuckGo.</p><p> Поскольку DuckDuckGo создает не свой собственный индекс сайтов с нуля, а свои собственные алгоритмы ранжирования, «лучший способ получить хороший рейтинг (почти во всех поисковых системах) — это получить ссылки с высококачественных сайтов.”</p><p> Однако имеется очень мало дополнительной информации о его алгоритмах ранжирования.</p><h4><span class="ez-toc-section" id="_DuckDuckGo-2"> Оптимизация для DuckDuckGo </span></h4><p> Предложения по оптимизации для DuckDuckGo не сильно отличаются от оптимизации для других поисковых систем. Тем не менее, было высказано предположение, что перепрофилирование контента из нескольких источников может помочь в рейтинге на DuckDuckGo.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/pbs.twimg.com/media/D7pQfkgXoAAZ_fq.jpg' style='float: right;' /><noscript><img src='/800/600/https/pbs.twimg.com/media/D7pQfkgXoAAZ_fq.jpg' style='float: right;' /></noscript></p><p> Другие стратегии для того, чтобы стоять на DuckDuckGo, включают следующее:</p><ul><li> Посоветуйте, что DuckDuckGo добавит вам удачи на сайт.Bangs (! Websitename) обеспечивает быстрый прямой доступ к вашему сайту</li><li> Использовать структурированные данные (Schema.org)</li><li> Укрепите свою стратегию обратных ссылок</li><li> Убедитесь, что ваш веб-сайт доступен для сканирования и индексации другими поисковыми системами</li></ul><h3><span class="ez-toc-section" id="i-30"> Заключение </span></h3><p> В зависимости от вашей целевой аудитории Google может не быть единственным и конечным элементом вашей видимости. Однако если вы посмотрите за пределы Google, вы можете найти широкий спектр поисковых систем, каждая со своими особенностями.</p><p> Многие из них имеют много общего с Google, либо потому, что они конкурируют за одних и тех же пользователей, либо потому, что они оценивают одни и те же веб-сайты. В случае с Bing именно мелкие технические детали могут иметь большое значение в рейтинге. Однако там, где это не так, поисковые системы могут работать по-другому — и, в свою очередь, создатели веб-сайтов и оптимизаторы поисковых систем должны адаптироваться.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/pbs.twimg.com/media/EcpIGiSWkAQ1vbM.png' style='float: right;' /><noscript><img src='/800/600/https/pbs.twimg.com/media/EcpIGiSWkAQ1vbM.png' style='float: right;' /></noscript></p><p> Так обстоит дело с Яндексом и его региональными настройками, с Baidu и его домашними страницами, размещенными в Китае, или с DuckDuckGo и его индексом, построенным на основе индексов многих других источников.</p><h2><span class="ez-toc-section" id="SEO_8"> SEO для Яндекса: 8 вещей, которые нужно знать </span></h2><h3><span class="ez-toc-section" id="5"> 5. Как и Достоевский, Яндекс — это мета </span></h3><p> Конечно, метатеги важны и для Google. Но для сравнения, Google не воспринимает их так серьезно, как Яндекс. На самом деле, если вы неправильно получите свои метатеги, теги title и description, URL-адреса и канонические теги, вы можете оказаться в беде, как Раскольников в романе Достоевского. Короче говоря, пусть ваш веб-мастер внесет их в ваш список приоритетов:</p><p> <strong> Теги заголовка и описания </strong> <br/> <em> Хотя для Яндекса заголовки могут быть немного длиннее, чем для Google, лучше всего придерживаться диапазона в 60 символов.Для описания используйте около 160 символов. Но будьте осторожны: как мы уже упоминали выше, качество является ключевым фактором.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/lumpics.ru/wp-content/uploads/2020/05/proczess-perehoda-v-keshirovannuyu-versiyu-straniczy-cherez-yandeks-v-yandeks.brauzere.png' style='float: right;' /><noscript><img src='/800/600/https/lumpics.ru/wp-content/uploads/2020/05/proczess-perehoda-v-keshirovannuyu-versiyu-straniczy-cherez-yandeks-v-yandeks.brauzere.png' style='float: right;' /></noscript> Если вы автоматически генерируете эти тексты, не проверяя их качество, они могут исчезнуть из результатов поиска. </em></p><p> <strong> Мета-ключевые слова </strong> <br/> <em> Очень важно, чтобы на каждой странице было хотя бы несколько целевых ключевых слов. Хотя Google в значительной степени покончил с метатегами для ключевых слов, Яндекс, как и Baidu, по-прежнему ценит их. </em></p><p> <strong> Канонические теги </strong> <br/> <em> Помните, как мы упоминали, что Яндекс не любит спам? Дубликаты, конечно, можно считать спамом.Итак, убедитесь, что все ваши канонические теги в порядке. </em></p><p> <strong> URL-адресов </strong> <br/> <em> Поскольку мы выбираем русскоязычных пользователей, ваши URL-адреса должны отображаться на кириллице для русскоязычных регионов, на которые вы ранее ориентировались. </em></p><h3><span class="ez-toc-section" id="7"> 7. Никаких ссылок на мусор, пожалуйста, </span></h3><p> Вы, вероятно, не ожидали этого, но Яндекс отказался от обратных ссылок как общего требования SEO для ранжирования в результатах своих поисковых систем.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/helpadmins.ru/wp-content/uploads/2017/03/Uvelichenie-shrifta-v-brauzere.jpg' style='float: right;' /><noscript><img src='/800/600/https/helpadmins.ru/wp-content/uploads/2017/03/Uvelichenie-shrifta-v-brauzere.jpg' style='float: right;' /></noscript> Конечно, перекрестные ссылки по-прежнему важны, но, опять же, для ранжирования в Яндекс.</p><p> Итак, если вы включаете ссылки на свой сайт, убедитесь, что пользователи найдут их интересными и интересными. Это увеличит трафик. И чем больше у вас трафика и вовлеченности в России, тем выше ваш рейтинг на первой странице.</p><h2><span class="ez-toc-section" id="_Awesome_Link"> Другой источник данных Awesome Link </span></h2><p> Веб-мастера и специалисты по поисковой оптимизации часто полагаются на данные о ссылках из известных сторонних инструментов, таких как Majestic SEO или SEOMoz, но забывают копаться в собственных данных поисковых систем. Инструменты Google и Bing для веб-мастеров показывают типичную часть ваших данных о ссылках.В случае с Google это в основном те ссылки, которые Google считает релевантными и значимыми (они, как правило, не учитывают те, которые никак не влияют на сайт, но по-прежнему показывают ссылки nofollow, поскольку они могут принести ценный трафик).</p><p> Ну вот еще один — Яндекс для веб-мастеров:</p><p> Идея пришла из одной из наших ночных тусовок, когда Алистер Латтимор предложил нам попробовать.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/expange.ru/img/upload/1/3/136.png' style='float: right;' /><noscript><img src='/800/600/https/expange.ru/img/upload/1/3/136.png' style='float: right;' /></noscript> Я не удержался и сразу же зарегистрировался, проверив свой адрес электронной почты, телефон и авторизовав свой сайт с помощью загрузки файла HTML.</p><p> На скриншоте выше вы можете увидеть обзор внешних ссылок, отфильтрованных по URL-адресу страницы (/ mind-blowing-hack / также работает для каталогов и с модификатором подстановочного знака *).</p><p> Что меня порадовало, так это то, как Яндекс сортирует мои ссылки. Он намного ближе к тому, что я считаю релевантными и авторитетными сайтами, чем то, как он представлен во многих других инструментах (в частности, Google Webmaster Tols, где вы можете сортировать по дате или экспортировать чистый случайный список в виде файла CSV).</p><p> Идея состоит в том, чтобы получить как можно больше данных от каждой поисковой системы и объединить их в единую базу данных ссылок.</p><h3><span class="ez-toc-section" id="i-31"> Параметры и возможности Яндекс. Инструментов для веб-мастеров </span></h3><p> Вот список всех опций, доступных в Яндексе для веб-мастеров:</p><ol><li> Общая информация</li><li> Индексирование<ol><li> Структура сайта</li><li> Страниц в поиске</li><li> Ссылки на сайт</li><li> Исключенные страницы</li><li> История индексирования<ol><li> Количество запросов</li><li> HTTP-коды</li></ol></li></ol></li><li> Опции индексирования<ol><li> Роботы.<img class="lazy lazy-hidden" src="//gnomesmonetized.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/studfile.net/html/1438/356/html_iKXdbQyvMl.ixGw/htmlconvd-3QUY44437x1.jpg' style='float: right;' /><noscript><img src='/800/600/https/studfile.net/html/1438/356/html_iKXdbQyvMl.ixGw/htmlconvd-3QUY44437x1.jpg' style='float: right;' /></noscript><div class='yarpp-related yarpp-related-none'><p>No related posts.</p></div></div></div><div class="single-meta"><footer class="entry-footer"> #<a href="https://gnomesmonetized.ru/category/raznoe-2" rel="category tag">Разное</a></footer></div></article><nav class="navigation post-navigation" aria-label="Записи"><h2 class="screen-reader-text">Навигация по записям</h2><div class="nav-links"><div class="nav-previous"><a href="https://gnomesmonetized.ru/raznoe/tekst-pod-kartinkoj-css-tekst-poverx-izobrazheniya-html-css.html" rel="prev"><span class="screen-reader-text">Предыдущая запись:</span> <span class="post-title">Текст под картинкой css – Текст поверх изображения. HTML + CSS</span></a></div><div class="nav-next"><a href="https://gnomesmonetized.ru/raznoe-2/bukva-nyu-v-vorde-404-page-not-found-error.html" rel="next"><span class="screen-reader-text">Следующая запись:</span> <span class="post-title">Буква ню в ворде – 404 (Page Not Found) Error</span></a></div></div></nav><div id="comments" class="comments-area"><div class="comments-wrapper"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe-2/nekanonicheskaya-stranicza-sajta-v-yandekse-chto-eto-kanonicheskij-adres-straniczy-vebmaster-spravka.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://gnomesmonetized.ru/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='6893' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></div></main></div><aside id="secondary" class="widget-area" role="complementary"><div class="theiaStickySidebar"><div id="search-2" class="widget widget_search"><form role="search" method="get" class="search-form" action="https://gnomesmonetized.ru/"> <label> <span class="screen-reader-text">Найти:</span> <input type="search" class="search-field" placeholder="Поиск…" value="" name="s" /> </label> <input type="submit" class="search-submit" value="Поиск" /></form></div><div id="nav_menu-2" class="widget widget_nav_menu"><h5 class="widget-title center-widget-title">Рубрики</h5></div></div></aside></div><footer id="colophon" class="site-footer" role="contentinfo"><div class="copyright-area"><div class="wrapper"><div class="col-row"><div class="col col-full"><div class="site-info"><div class="footer_image"></div><h4 class="site-copyright"> 2019 © Все права защищены.</h4><div class="col col-full site-copyright"> <a href="/sitemap.xml" class="c_sitemap">Карта сайта</a></div></div></div></div></div></div></footer></div><div class="scroll-up alt-bgcolor"> <i class="ion-ios-arrow-up text-light"></i></div> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://gnomesmonetized.ru/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <script type="text/javascript" id="jumla-script-js-extra">var jumlaVal={"nonce":"50c1cf5c4a","ajaxurl":"https:\/\/gnomesmonetized.ru\/wp-admin\/admin-ajax.php"};</script> <!-- noptimize --> <style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script> <!-- /noptimize --> <script defer src="https://gnomesmonetized.ru/wp-content/cache/autoptimize/js/autoptimize_d860e31b86df1b8ed458d52ae42d9e57.js"></script></body></html><script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="e9aaedd0305cf725e07e5a36-|49" defer></script>