
30+ примеров настройки robots.txt
Как настроить корректную индексацию сайта поисковыми роботами? Как закрыть доступ сканирующих роботов к техническим файлам сайта?
Файл robots.txt ограничивает доступ поисковых роботов к файлам на сервере — в файле написаны инструкции для сканирующих роботов. Поисковый робот проверяет возможность индексации очередной страницы сайта — есть ли подходящее исключение. Чтобы поисковые роботы имели доступ к robots.txt, он должен быть доступен в корне сайта по адресу mysite.ru/robots.txt.
Пример полного доступа на индексацию сайта без ограничений:
User-agent: *
Allow: /
Применение в SEO
По умолчанию поисковые роботы сканируют все страницы сайта, к которым они имеют доступ. Попасть на страницу поисковый робот может из карты сайта, ссылки на другой странице, наличии трафика на данной странице и т.п.. Не все страницы, которые были найден поисковым роботом следует показывать в результатах поиска.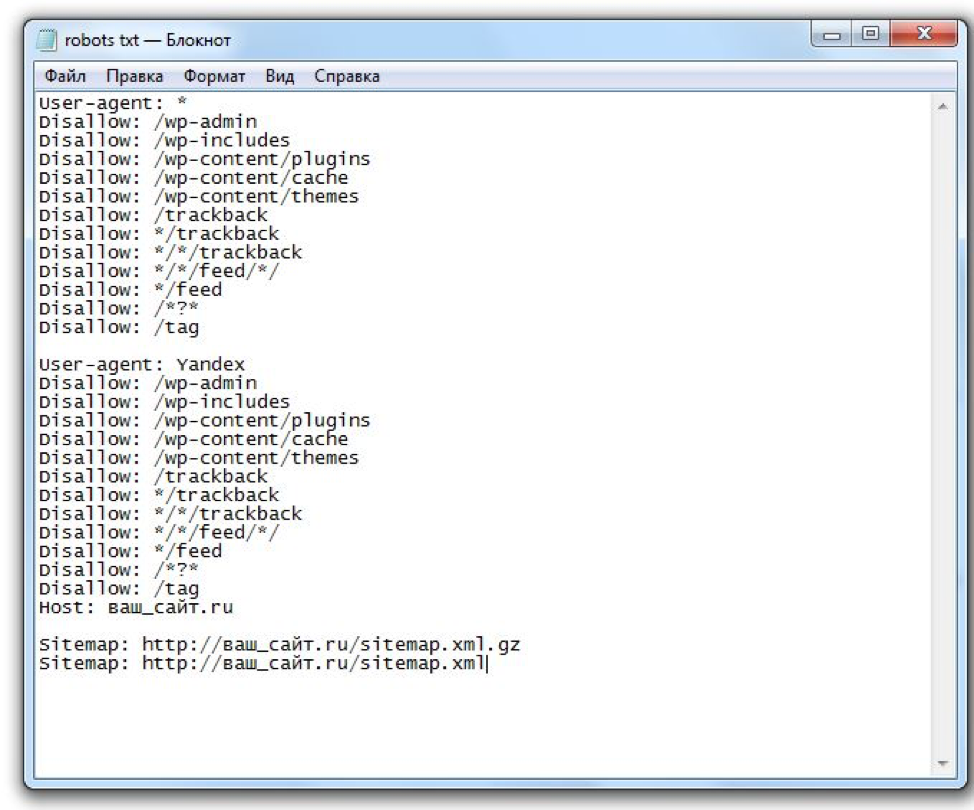
Файл robots.txt позволяет закрыть от индексации дубли страниц, технические файлы, страницы фильтрации и поиска. Любая страница на сайте может быть закрыта от индексации, если на это есть необходимость..
Правила синтаксиса robots.txt
Логика и структура файла robots.txt должны строго соблюдаться и не содержать лишних данных:
- Любая новая директива начинается с новой строки.
- В начале строки не должно быть пробелов.
- Все значения одной директивы должны быть размещены на этой же строке.
- Не использовать кавычки для параметров директив.
- Не использовать запятые и точки с запятыми для указания параметров.
- Все комментарии пишутся после символа #.
- Пустая строка обозначает конец действия текущего User-agent.
- Каждая директива закрытия индексации или открытия содержит только один параметр.
- Название файла должно быть написано прописными буквами, файлы Robots.
 txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами.
txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами. - Если директива относится к категории, то название категории оформляется слешами «/categorya/».
- Размер файла robots.txt не должен превышать 32 кб, иначе он трактуется как разрешающий индексацию всего.
- Пустой файл robots.txt считается разрешающим индексацию всего сайта.
- При указании нескольких User-agent без пустой строки между ними обрабатываться будет только первая
 txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами.
txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами.Проверка robots.txt
Поисковые системы Яндекс и Google дают возможность проверить корректность составления robots.txt:
- В Вебмастер.Яндекс — анализ robots.txt.
- В Google Search Console — ссылка, необходимо сначала добавить сайт в систему.
Примеры настройки robots.txt
Первой строкой в robots.txt является директива, указывающая для какого робота написаны исключения.
Директива User-agent
# Все сканирующие роботы
User-agent: *
# Все роботы Яндекса
User-agent: Yandex
# Основной индексирующий робот Яндекса
User-agent: YandexBot
# Все роботы Google
User-agent: Googlebot
Все директивы следующие ниже за User-agent распространяют свое действие только на указанного робота. Для указания данных другому роботу следует еще раз написать директиву User-agent. Пример с несколькими User-agent:
Для указания данных другому роботу следует еще раз написать директиву User-agent. Пример с несколькими User-agent:
Использование нескольких User-agent
# Будет использована основным роботом ЯндексаUser-agent: YandexBot
Disallow: *request_* # Будет использована всеми роботами Google
User-agent: Googlebot
Disallow: *elem_id* # Будет использована всеми роботами Mail.ru
User-agent: Mail.Ru
Allow: *SORT_*
Сразу после указания User-agent следует написать инструкции для выбранного робота. Нельзя указывать пустые сроки между командами в robots.txt, это будет не правильно понято сканирующими роботами.
Разрешающие и запрещающие директивы
Для запрета индексации используется директива «Disallow», для разрешения индексации «Allow»:
User-agent: *
Allow: /abc/
Disallow: /blog/
Указано разрешение на индексацию раздела /abc/ и запрет на индексацию /blog/. По умолчанию все страницы сайта разрешены на индексацию и не нужно указывать для всех папок директиву Allow. Директива Allow необходима при открытии на индексацию подраздела. Например открыть индексацию для подраздела с ужатыми изображениями, но не открывать доступ к другим файлам в папке:
По умолчанию все страницы сайта разрешены на индексацию и не нужно указывать для всех папок директиву Allow. Директива Allow необходима при открытии на индексацию подраздела. Например открыть индексацию для подраздела с ужатыми изображениями, но не открывать доступ к другим файлам в папке:
User-agent: *
Disallow: /upload/
Allow: /upload/resize_image/
Последовательность написания директив имеет значение. Сначала закрывается все папка от индексации, а затем открывается её подраздел.
Запрещение индексации — Disallow
Полный запрет индексации
User-agent: *
Disallow: /
Сайт закрывается от сканирования всех роботов.
Существуют специальные символы «*» и «$», которые позволяют производить более тонкое управление индексацией:
Disallow: /cat*
Disallow: /cat
Символ звездочка означает любое количество любых символов, которые могут идти следом. Вторая директива имеет тот же смысл.
Вторая директива имеет тот же смысл.
Disallow: *section_id*
Запрещает индексацию всех Url, где встречается значение внутри звездочек.
Disallow: /section/
Закрывает от индексации раздел и все вложенные файлы и подразделы.
Разрешение индексации — Allow
Задача директивы Allow открывать для индексации url, которые подходят под условие. Синтаксис Allow сходен с синтаксисом Disallow.
User-agent: *
Disallow: /
Allow: /fuf/
Весь сайт закрыт от индексации, кроме раздел /fuf/.
Директива Host
Данная директива нужна для роботов поисковой системы Яндекс. Она указывает главное зеркало сайта. Если сайт доступен по нескольким доменам, то это позволяет поисковой системе определить дубли и не включать их в поисковый индекс.
User-agent: *
Disallow: /bitrix/
Host: mysite.
 ru
ru
В файле robots.txt директиву Host следует использовать только один раз, последующие указания игнорируются.
Если сайт работает по защищенному протоколу https, то следует указывать домен с полным адресом:
User-agent: *
Disallow: /bitrix/
Host: https://domain.ru
Директива Sitemap
Для ускорения индексации страниц сайта поисковым роботам можно передать карту сайта в формате xml. Директива Sitemap указывает адрес, по которому карта сайта доступна для скачивания.
User-agent: *
Disallow: /bitrix/
Sitemap: http://domain.ru/sitemap.xml
Исключение страниц с динамическими параметрами
Директива Clean-param позволяет бороться с динамическими дублями страниц, когда содержимое страницы не меняется, но добавление Get-параметра делает Url уникальным. При составлении директивы сначала указывается название параметра, а затем область применения данной директивы:
Clean-param: get1[&get2&get3&get4&..&getN] [Путь]

Простой пример для страницы http://domain.ru/catalog/?&get1=1&get2=2&get3=3. Директива будет иметь вид:
Clean-param: get1&get2&get3 /catalog/
Данная директива будет работать для раздела /catalog/, можно сразу прописать действие директивы на весь сайт:
Clean-param: get1&get2&get3 /
Снижение нагрузки — Crawl-delay
Если сервер не выдерживает частое обращение поисковых роботов, то директива Crawl-delay поможет снизить нагрузку на сервер. Поисковая система Яндекс поддерживает данную директиву с 2008 года.
User-agent: *
Disallow: /search/
Crawl-delay: 4
Поисковый робот будет делать один запрос, затем ждать 4 секунды и снова делать запрос.
Типовой robots.txt для сайта на Bitrix
В заключении полноценный файл robots.txt для системы 1С-Битрикс, который включает все типовые разделы:
User-agent: *
Disallow: /bitrix/
Disallow: /admin/
Disallow: /auth/
Disallow: /personal/
Disallow: /cgi-bin/
Disallow: /search/
Disallow: /upload/
Allow: /upload/resize_cache/
Allow: /upload/iblock/
Disallow: *bxajaxid*
Sitemap: http://domain.
Host: domain.ru
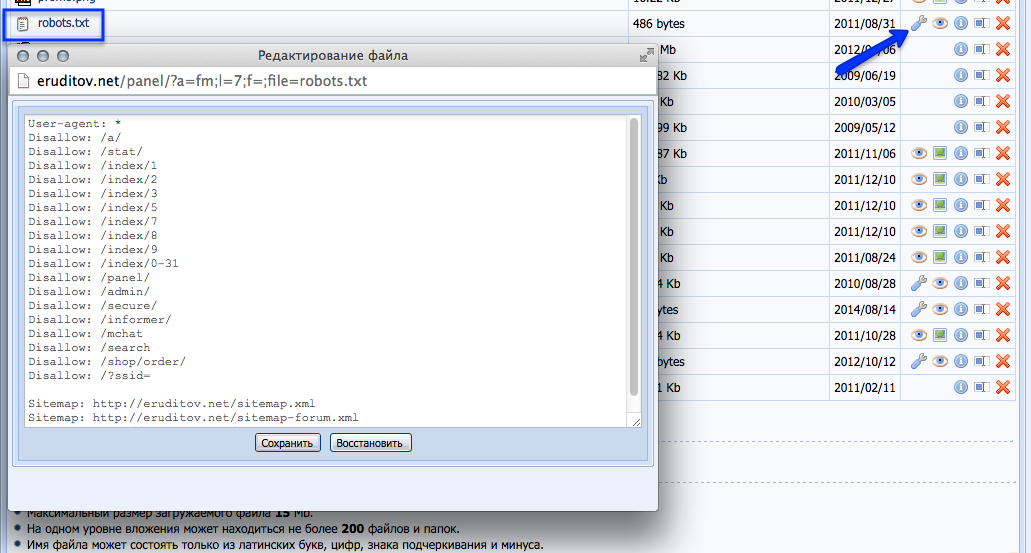 ru/sitemap.xml
ru/sitemap.xmlПравильное заполнение файла robots.txt
Эффективное продвижение сайта невозможно без совершенствования его технических параметров, в том числе файла robots. Robots.txt — это текстовый файл, находящийся в корневом каталоге сайта. Он состоит из набора инструкций для индексирования и сканирования файлов, страниц и каталогов сайта для поисковых машин.
Сразу оговоримся, что присутствие файла robots.txt на сервере обязательно. Даже если вы полностью открываете ресурс для индексации.
Индексация robots.txt
Первое, что индексируют и сканируют поисковые системы на ресурсе, — файл robots.txt. Есть условия действительности файла:
- Название. Исключительно robots.txt. Помните, что URL-адреса чувствительны к регистру.
- Местоположение. Файл должен находиться в корневом каталоге верхнего уровня хоста и быть единственным.
- Протокол. Поддерживаются все протоколы на основе URI — HTTP и HTTPS. Поисковые боты делают обычный GET-запрос, на который должен поступить ответ со статусом 200 OK. Возможна обработка файла с FTP-серверов: доступ осуществляется с использованием анонимного входа.
- Формат. Файл должен быть в текстовом формате. Его можно создать в любом текстовом редакторе с поддержкой кодировки UTF-8. Не рекомендуем использовать текстовые процессоры, так как они могут сохранять файлы в проприетарном формате и добавлять дополнительные символы, не распознаваемые поисковыми роботами.
- Размер. Для Google значение не должно превышать 500 килобайт, а для Яндекса — 32 КБ. Гугл переходит к файлу, но сканирует первые 500 килобайт, а Яндекс сразу смотрит на размер и, если лимит превышен, считает, что доступ к содержимому сайта закрыт. При успешном сканировании и индексировании файла Яндекс исполняет инструкции в течение 2 недель, а для Google они являются рекомендуемыми и не обязательны к исполнению.


Настройка robots.txt
Чтобы правильно заполнить robots.txt, в первую очередь нужно придерживаться правил, заданных поисковиками. Особенно это касается директив.
Директивы
Поисковые роботы Google, Яндекс. Bing, Yahoo и Ask поддерживают следующие директивы:
| Директива | Описание |
|---|---|
|
User-agent |
Обязательная директива. Указывает на поискового робота, которому адресованы правила. Учитывается название бота или *, которая адресует правила ко всем ботам. Наиболее популярные в России:
Рекомендуем периодически просматривать логи сайта и закрыть доступ для агрессивных ботов, которых развелось очень много. |
|
Allow и Disallow |
Разрешает и запрещает индексирование и сканирование отдельных файлов, страниц и каталогов ресурса. Используйте запрет для:
Их можно использовать совместно в одном блоке. Приоритет отдается более длинному правилу. Если префиксы одинаковой длины, то при конфликте приоритет отдается Allow. |
|
Sitemap |
Указывает путь к одноименному файлу. |
|
Clean-param |
Указывает параметры страницы, которые не нужно учитывать. Существует два типа параметров URL:
Не стоит очищать параметры, влияющие на контент, поскольку их можно использовать как точку входа при SEO-продвижении. |
|
Crawl-delay |
Указывает время в секундах, через которое необходимо приступить к загрузке следующей страницы. |
|
Host |
Указывает на домен с протоколом и портами. Указывайте нужный протокол – HTTP или HTTPS. Если порт не отличается от стандартного, то его не нужно указывать. Отметим, что Яндекс отказался от этой директивы и заменил ее 301 редиректом. Однако веб-мастера не торопятся удалять Host из файла, поскольку работе поисковых роботов это не мешает. |


Синтаксис и примеры
Помимо директив, чтобы правильно настроить robots. txt, нужно соблюдать правила синтаксиса.
txt, нужно соблюдать правила синтаксиса.
Разберем на примерах.
-
Указания чувствительны к регистру. Пример: http://site-example.ru/file.html и http://site-example.ru/File.html — это разные пути.
-
Для кириллических адресов используйте Punycode.
#НЕВЕРНО
Disallow: /корзина#ВЕРНО:
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 -
Для комментирования используйте #. Как в предыдущем пункте.
-
Хотя бы одна Allow или Disallow должна быть в группе. Пример:
#Блокировка доступа ко всему ресурсу определенному боту
User-agent: Googlebot #сюда указывается токен бота
Disallow: /#Блокировка доступа ко всему ресурсу всем ботам
User-agent: * #звездочка означает «любой бот»
Disallow: / -
Обязательно указывайте Sitemap.
Хоть эта директива необязательна, мы советуем ее указывать, поскольку адрес может отличаться от стандартного и боты могут ее не найти. Пример:
User-agent: *
Allow: /
Sitemap: https://site-example.ru/sitemap.xml -
Для переноса строки используйте знак $.Пример:
User-agent: *
Disallow: https://site-example.ru/здесь-будет-очень-длинный-$
адрес-сайта
Sitemap: https://site-example.ru/sitemap.xml
Host: https://site-example.ru -
Можно запретить доступ к отдельному файлу, странице или категории. Пример:
User-agent: *
Disallow: /page-example.html #не нужно указывать весь путь ресурса
Disallow: /images/image-example.png #любой файл: картинка, документ, все что угодно
Disallow: /*. js$ #запретить определенный тип файла
Disallow: /category-example/
Allow: /category-example/subcategory-example/ #прошлой строкой запретили раздел и его последующие подкатегории и файлы, но далее можно разрешить сканировать другой раздел
 Хоть эта директива необязательна, мы советуем ее указывать, поскольку адрес может отличаться от стандартного и боты могут ее не найти. Пример:
Хоть эта директива необязательна, мы советуем ее указывать, поскольку адрес может отличаться от стандартного и боты могут ее не найти. Пример:
 js$ #запретить определенный тип файла
js$ #запретить определенный тип файлаНе бойтесь совершить ошибку — файлы robots.txt можно проверить на валидность с помощью специальных сервисов.
Проверка robots.txt на валидность
Чтобы убедиться в правильности составления файла robots.txt воспользуйтесь инструментами проверки от поисковых систем:
- Проверка в Google Search Console. Нужно авторизоваться в аккаунте с подтвержденными правами на сайт. Далее перейти в «Сканирование», а затем в «Инструмент проверки файла robots.txt». Проверить можно только сайт, в котором вы авторизовались.
- Проверка в инструменте Яндекса. Авторизация не нужна, просто укажите адрес сайта или загрузите исходный код файла. Проверить можно любой сайт.
 Проверить можно любой сайт.
Проверить можно любой сайт.
В сервисах проверки можно загрузить несколько страниц одновременно, увидеть все ошибки, исправить их прямо в инструменте и перенести готовый файл на сайт.
Файл robots.txt — примеры использования для сайта, закрытие от индексации сайта
Что такое файл robots.txt? С помощью этого файла, вы сообщаете поисковым роботам, о том, какие страницы нужно индексировать, а какие нет. Из этой статьи вы узнаете, как его правильно использовать. Начнем с краткого
Что такое файл robots.txt? С помощью этого файла, вы сообщаете поисковым роботам, о том, какие страницы нужно индексировать, а какие нет. Из этой статьи вы узнаете, как его правильно использовать. Начнем с краткого описания:
Robots.txt – текстовой файл, размещенный на сервере (в корне сайта), который сообщает поисковым ботам, что нужно индексировать, а что нет.
Типичная конфигурация файла robots.txt, ниже я объясню, что это значит.
User-agent: *<br /> Disallow:<br /> User-agent: *<br /> Disallow: /<br /> User-agent: *<br /> Disallow: /folder/<br /> User-agent: *<br /> Disallow: /page.html
Зачем нам знать о файле robots.txt?
- Незнание и непонимание того, как работает файл robots.txt, может иметь негативное влияние на рейтинг вашего сайта.
- Файл robots.txt контролирует то, как поисковые алгоритмы индексируют ваш сайт.
Алгоритм работы
Первое, что сделает поисковый бот, когда посетит ваш сайт – это обращение к файлу robots.txt. С какой целью? Робот хочет знать, имеет ли полномочия, проиндексировать сайт или ту или иную страницу сайта. Если нет явного запрета на обход страниц, то робот продолжает свою работу. Если существуют запреты, то робот покинет сайт. Поэтому, если вы хотите использовать какие-либо инструкции для поисковых роботов, то файл robots.txt – это тот самый инструмент.
Внимание! Существуют два важных нюанса, которые вебмастер должен проверить, если речь идет о файле robots.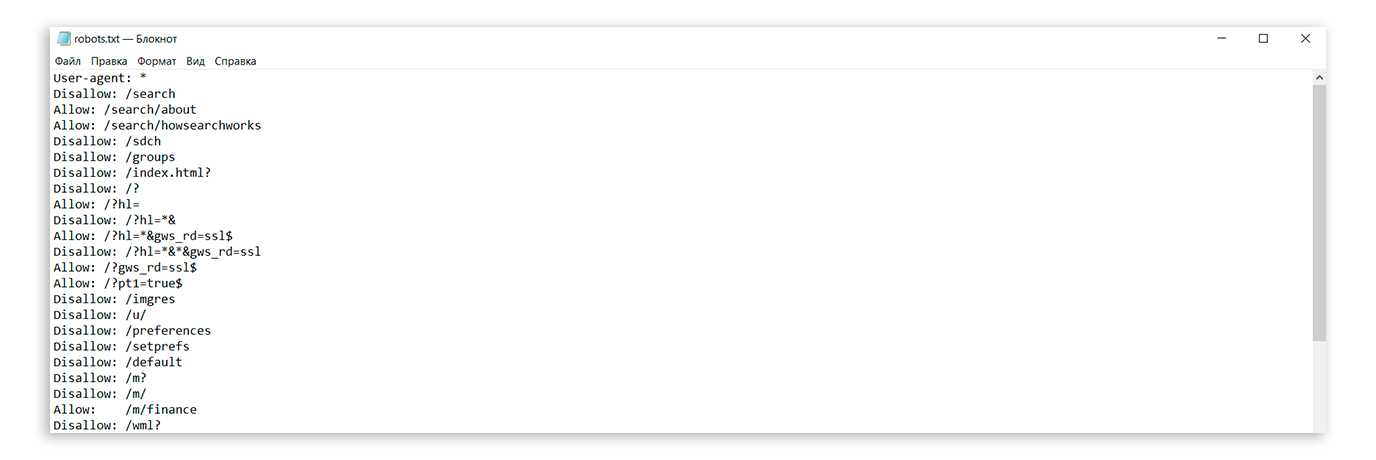 txt:
txt:
- Определить существует ли этот файл;
- Убедиться, что он не вредит индексации сайта.
Как проверить, что robots.txt существует и не мешает индексации?
Проверить существует ли такой файл можно с помощью любого веб-браузера. Файл должен быть размещен в корневой папке сайта. Достаточно просто в адресную строку ввести site.ru/robots.txt (site.ru заменив вашим доменным именем) и отобразиться содержимое этого файла. Если такого файла не существует или он пуст, то вы увидите просто белый фон или 404 ошибку.
Проверить не мешают ли директивы файла robots.txt можно через Яндекс.Вебмастер во вкладке «Инструменты -> Анализ robots.txt.
В поле «Разрешены ли URL?» достаточно вставить адреса ваших страниц и нажать «проверить». Результат будет ниже
Аналогичную процедуру можно проделать и в Google Search Console.
Зачем нам нужен файл robots.txt?
Итак, мы знаем, где искать файл robots. txt и то, что он нужен, но зачем он нужен, какие конкретные причины?
txt и то, что он нужен, но зачем он нужен, какие конкретные причины?
- На сайте есть страницы, которые вы не хотите показывать поисковым системам;
- Необходимо, чтобы доступ к сайту имели только определенные роботы, например, сканеры Google и Яндекс;
- Вы создаете новый раздел и планируете новую структуру. Для того, чтобы ваши «тесты» не попадали в поисковую выдачу, лучше закрыть эти разделы от индексации;
- У вас многожество дублей страниц и вы хотите исключить эти дубли из поиска.
Как создать файл robots.txt?
Очень просто. Robots.txt – простой текстовой файл. Достаточно создать такой файл у себя на компьютере и закачать его на сайт через FTP-клиент, либо, если платформа позволяет это сделать, то создать такой файл прямо на хостинге.
Инструкции robots.txt – тут уже сложнее
Теперь необходимо разобраться, как этот файл правильно использовать.
User-agent
Синтаксис User-agent определяет в отношении каких ботов действуют правила.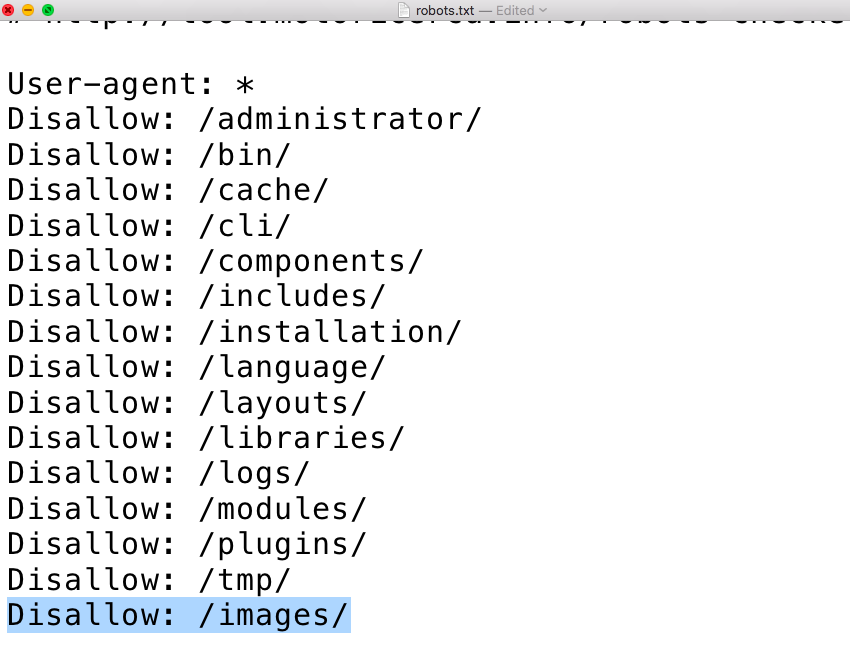 Есть два способа это сделать:
Есть два способа это сделать:
- User-agent: * — такой способ говорит, что, любой робот должен придерживаться следующих «правил».
- User-agent: GoogleBot – этот способ говорит, что данный «правила» касаются только и исключительно для робота GoogleBot.
Disallow
Инструкция «Disallow» — запрещает роботам индексировать те или иные элементы (файлы, страницы, папки, изображения). Таким образом, если вы не хотите, чтобы содержимое папки «temp» не было проиндексировано, нужно указать это в файле robots.txt следующим образом:
User-agent: *<br /> Disallow: /temp
Allow
Все что не закрыто по-умолчанию — открыто. Поэтому «allow» часто используется в сочетании с «disallow». Например.
В предыдущем примере мы закрыли от индексации папку temp, однако через некоторое время мы решили, что мы хотим открыть доступ роботам к файлу my.docx, который находиться в папке temp, но только к нему, а не к другим файлам в это папке. Запись allow позволяет нам предоставить доступ к этому файлу (или группе файлов\папок), таким образом:
Запись allow позволяет нам предоставить доступ к этому файлу (или группе файлов\папок), таким образом:
User-agent: *<br /> Disallow: /temp<br /> Allow: /temp/my.docx
Что еще должно быть в файле robots.txt?
Кроме деректив поисковым роботам о том, что нужно или не нужно индексировать, в файл robots.txt желательно прописать путь до карты сайты, делается это следующим образом:
Sitemap: https://ex-pl.com/sitemap.xml
Как проверить, что файл robots.txt работает правильно?
Правильность вашего файла вы можете проверить в Яндекс.Вебмастере или Google Search Console.
Важные замечания
Закрытие страниц, папок, файлов от поисковых роботов через файл robots.txt не гарантирует не попадания этих элементов в поисковую выдачу. Все же директивы в этом файле имеют рекомендательный характер для ботов и они могут воспользоваться этими рекомендациями, а могут не воспользоваться. Для того, чтобы на 100% исключить из индекса ту или иную страницу, можно воспользоваться тегами noindex\nofollow.
Примеры robots.txt
Пример 1
User-agent: *<br /> Disallow:
Все роботы могут посещать и индексировать все файлы и страницы сайта.
Пример 2
User-agent: *<br /> Disallow: /
Закрыть сайт от индексации через robots.txt полностью. Это значит, что ваш сайт не будет отображаться в результатах поиска.
Пример 3
User-agent: *<br /> Disallow: /cgi/<br /> Disallow: /private/<br /> Disallow: /tmp/
Ни один из роботов не будет индексировать папки: cgi, private, tmp.
Пример 4
User-agent: Googlebot-Image<br /> Disallow: /photos/
Картиночному боту Google запрещен доступ к папке photos.
Пример 5
User-agent: *<br /> Disallow: /directory/file.html
Все роботам запрещено индексировать файл file.html в папке directory.
Пример 6
User-agent: WebStripper<br /> Disallow: /
User-agent: WebCopier<br /> Disallow: /
User-agent: TeleportPro<br /> Disallow: /
User-agent: HTTrack<br /> Disallow: /
User-agent: wget<br /> Disallow: /
Данные директивы запрещают некоторым программам доступ к сайту.
Что должно быть в файле Robots.txt на WordPress?
Виктор Саркисов
Middle SEO IM
Добрый день, спасибо за ваш вопрос!
В сети достаточно много статей написано про то какой должен быть Robots.txt для WordPress либо другой CMS. Проблема стандартных файлов Robots.txt для WP заключается в том что они содержат абсолютно всё что только может быть на этом движке. Даже мусорные страницы, которые создают популярные плагины, хоть они и не установлены сайте. В общем — указано всё подряд.
Содержимое файла Robots.txt для WordPress нужно создавать исходя из конкретного сайта. В вашем примере указана директива:
Disallow: */page/
Может статься так, что пагинация (а значит, и пагинация категорий) реализована через этот фрагмент. В таком случае вы закроете от сканирования странички пагинации, содержащие карточки товаров, которые роботу полезно видеть. Мы не рекомендуем закрывать страницы пагинации от сканирования.
В обязательном порядке стоит закрыть от сканирования страницы административной панели, при помощи директивы:
Disallow: /wp-admin/
Всё остальные ошибки следует исправлять либо при помощи редиректов, либо же закрывать от индексации через мета тег robots. Проблема заключается в том что файл Robots.txt для Google содержит рекомендации по сканированию, а не индексированию. Даже если документ будет закрыт от сканирования в файле Robots.txt, то он может быть проиндексирован. Более подробно проблема описана и даны варианты решения тут.
Проблема заключается в том что файл Robots.txt для Google содержит рекомендации по сканированию, а не индексированию. Даже если документ будет закрыт от сканирования в файле Robots.txt, то он может быть проиндексирован. Более подробно проблема описана и даны варианты решения тут.
Мы рекомендуем действовать следующим образом
- Установить плагин для WordPress Clearfy Pro. Он исправляет 90% всех ошибок на сайте WP, автоматически ставит редиректы со страниц архивов, feed, авторов и прочее.
- Просканировать сайт через Netpeak Spider. Закрыть от индексации при помощи мета тега robots все мусорные страницы.
- Прописать в файле Robots.txt следующее:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://site.ua/sitemap.xml
Таким образом файл Robots.txt не будет содержать множество бесполезных директив, а все мусорные страницы, которые создает WordPress либо его плагины не будут индексироваться поисковыми системами.
Дата сообщения: 21. 05.2019, 13:25
05.2019, 13:25
Robots.txt – важные этапы при создании и проверке
Почему это важноRobots.txt – это текстовый файл с набором инструкций для поисковых роботов, который управляет правилами индексации сайтов. С его помощью можно обозначить для поисковых систем, какие страницы стоит проиндексировать в первую очередь (например, раздел «Новости компании», так как он часто обновляется) и какие страницы закрыты для индексирования (например, результаты внутреннего поиска, так как это может привести к дублированию данных в поисковой системе и ухудшению показателей ранжирования сайта). Подробней о дубликатах данных читайте в Рыбе «Дублируемый контент – как вовремя найти и обезвредить дубли».
Файл Robots.txt должен находиться в корне сайта и быть доступен по адресу:
http://site.ru/robots.txt
Если у вашего сайта несколько поддоменов (это сайты 3-го уровня, например: http://ru.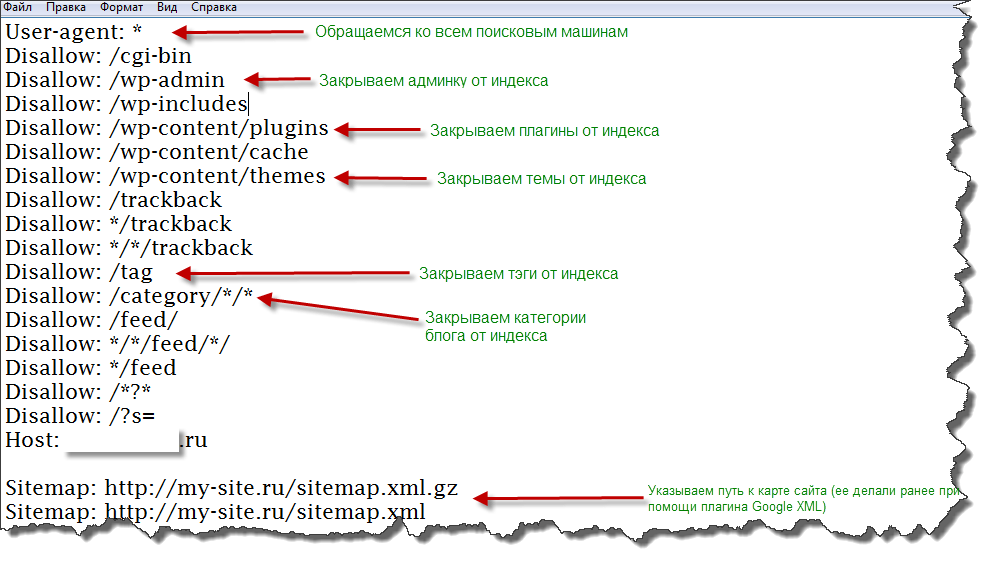 site.com), то для каждого поддомена следует писать свой robots.txt.
site.com), то для каждого поддомена следует писать свой robots.txt.
Robots.txt – простой текстовый файл. Внимание: имя файла должно содержать только маленькие буквы (то есть имена «Robots.txt» и «ROBOTS.TXT» — неправильные). Ещё одно ограничение robots.txt – размер файла. У Google это до 500 кб, у Яндекса до 32 кб. Если ваш robots.txt превышает эти размеры, то он может работать некорректно.
Более подробные требования к оформлению файла прописаны в справках поисковых систем: для Google и для «Яндекс».
Какие директивы существуют?Директива «User-agent»Директива, указывающая, для какого поискового робота написаны правила.
Примеры использования:
User-agent: * – для всех поисковых роботов
User-agent: Yandex – для поискового робота Yandex
User-agent: Googlebot – для поискового робота Google
User-agent: Yahoo – для поискового робота Yahoo
Рекомендуется использовать:
User-agent: *
Ниже мы рассмотрим примеры директив, как и для чего стоит их использовать.
Директива, запрещающая индексацию определённых файлов, страниц или категорий.
Эта директива применяется при необходимости закрыть дублирующие страницы (например, если это интернет-магазин, то страницы сортировки товаров, или же, если это новостной портал, то страницы печати новостей).
Также данная директива применима к «мусорным для поисковых роботов страницам». Такие страницы, как: «регистрация», «забыли пароль», «поиск» и тому подобные, – не несут полезности для поискового робота.
Примеры использования:
Disallow: /*sort – при помощи спец символа «*», мы даём понять поисковому роботу, что любой url, содержащий «SORT», будет исключён из индекса поисковой системы. Таким образом, в интернет-магазине мы сразу избавимся от всех страниц сортировки (учтите, что в некоторых CMS системах построение url сортировок может отличаться).
Disallow: /*print.php – аналогично сортировке мы исключаем все страницы «версия для печати».
Disallow: */telefon/ – в данном случае мы исключаем категорию «телефон», то есть url, содержащие «/telefon/».
Пример исключённых в данном случае url:
Пример не исключённых url в данном случае:
Disallow: /search – в данном случае мы исключим все страницы поиска, url которых начинаются с «/search». Давайте рассмотрим на примере исключенных страниц поиска:
Примеры не исключённых url в данном случае:
Disallow: / – закрыть весь сайт от индексации.
Рекомендуется использовать Disallow со специальным символом «*» для исключения большого количества страниц дублей.
Директива «Allow»Директива, разрешающая индексировать страницы (по умолчанию поисковой системе открыт весь сайт для индексации). Данная директива используется с директивой «Disallow».
Важно: директива «allow» всегда должна быть выше директивы «disallow».
Пример №1 использования директив:
Allow: /user/search
Disallow: *search
В данном случае мы запрещаем поисковому роботу индексировать страницы «поиска по сайту», за исключением страниц «поиска пользователей».
Пример №2 использование директив:
Allow: /nokia
Disallow: *telefon
В данном случае, если url-структура страниц такого типа:
Мы закрываем все телефоны от индексации, за исключением телефонов «nokia».
Такая методика, как правило, редко используется.
Директива «sitemap»Данная директива указывает поисковому роботу путь к карте сайта в формате «XML».
Директива должна содержать в себе полный путь к файлу.
Sitemap: http://site.ru/sitemap.xml
Рекомендации по использованию данной директивы: проверьте правильность указанного адреса.
Директива «Host»
Данная директива позволяет указать главное зеркало сайта. Ведь для поисковой системы это два разных сайта.
В данной директиве необходимо указывать главное зеркало сайта в виде:
Host: www.site.ru
Либо:
Host: site.ru
Пример полноценного robots. txt
txt
User-Agent: *
Disallow: /cgi-bin
Disallow: /*sort=*
Sitemap: http://www.site.ru/sitemap.xml
Host: www.site.ru
Корректность работы файла проверяется согласно правилам поисковых систем, в которых указаны правильные и актуальные директивы (ПС могут обновлять требования, поэтому важно следить за тем, чтобы ваш robots.txt оставался актуальным). Конечную проверку файла можно провести с помощью верификатора. В Google – это robots.txt Tester в панели инструментов для веб-мастеров, в ПС «Яндекс» — Анализ robots.txt.
ВыводыИнструкция robots.txt – важный момент в процессе оптимизации сайта. Файл позволяет указать поисковому роботу, какие страницы не следует индексировать. Это, в свою очередь, позволяет ускорить индексации нужных страниц, отчего повышается общая скорость индексации сайта.
Необходимо помнить, что robots.txt – это не указания, а только рекомендации поисковым системам.
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.

Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта —
Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI).
- Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
 Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI).
Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI).
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.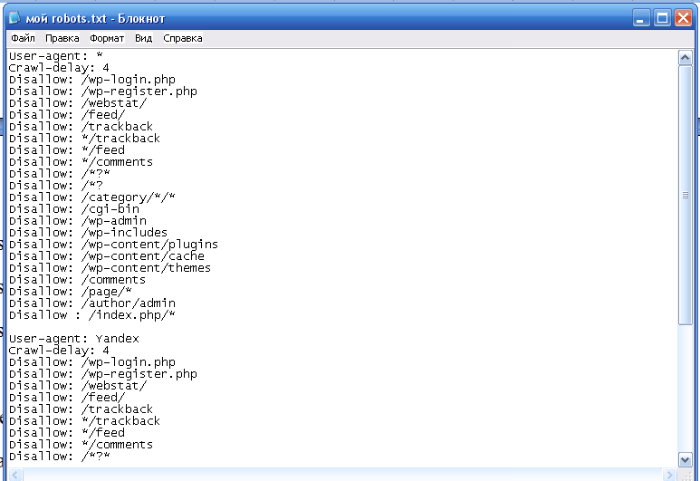 txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt«, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.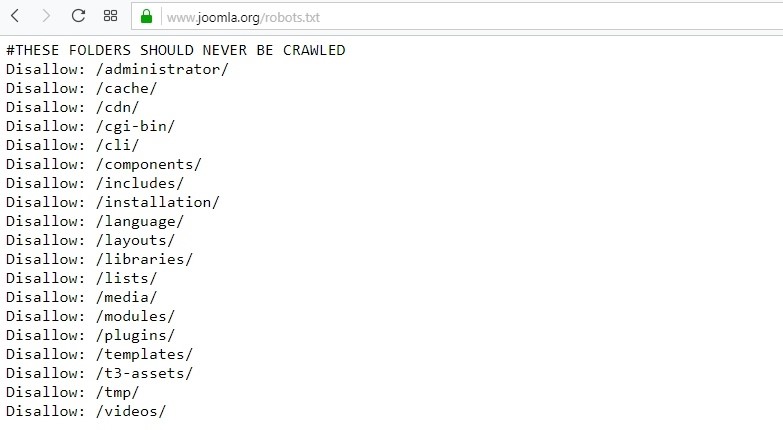 txt.
txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации.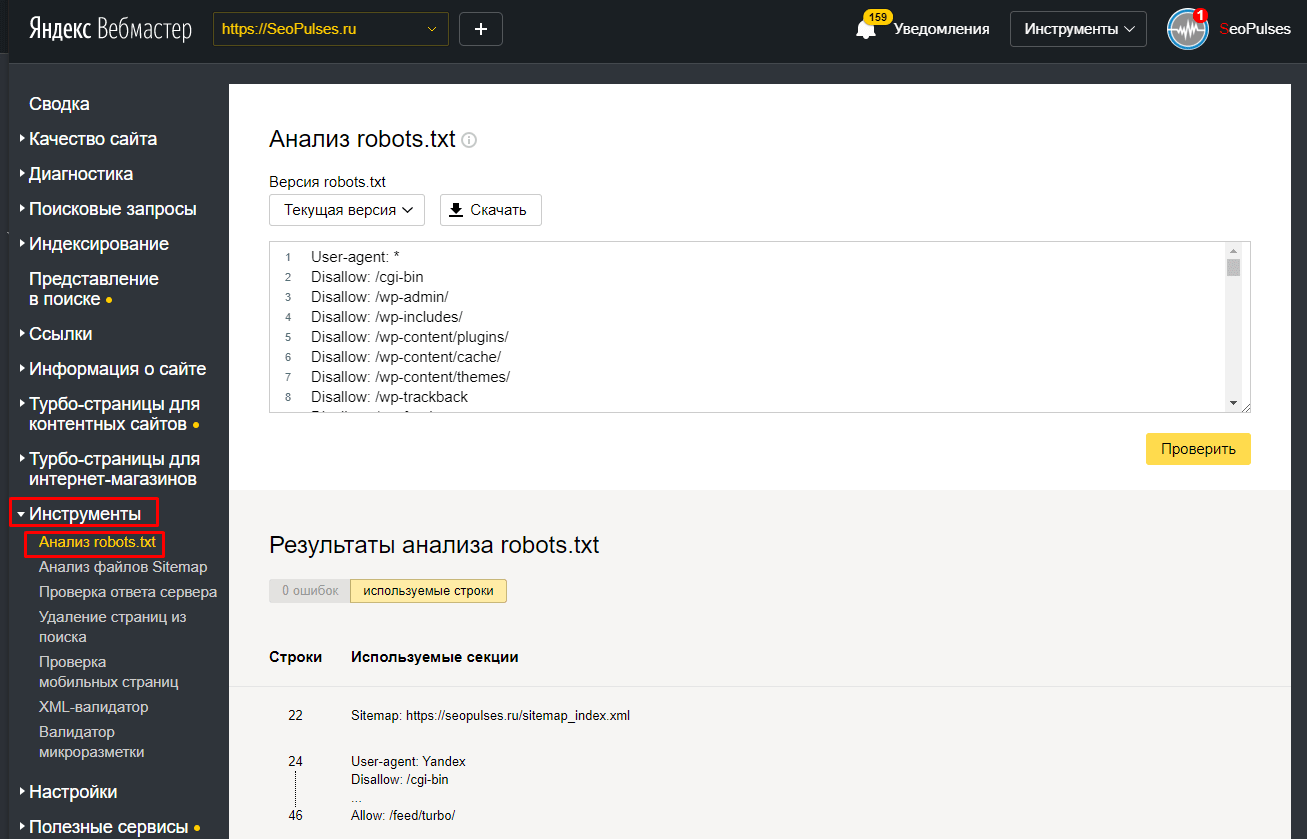 Если запрещающего правила нет, считается, что доступ к файлам открыт.
Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots. txt пустым.
txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site. com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site. com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
«www. site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123″
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243″
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311″
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже
не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.
 com/sitemap
Clean-param: ref/some_dir/get_book.pl
com/sitemap
Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
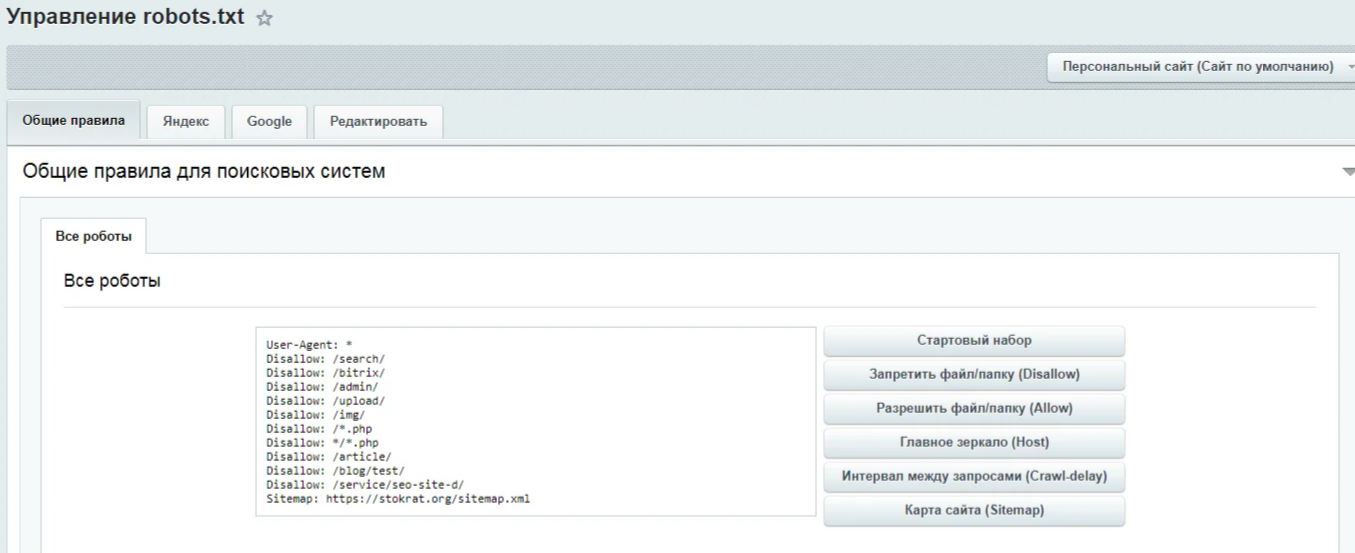
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Описание файла robots.txt с примерами
Яндекс: описание, валидатор
Google: описание, валидатор
1
User-agent
Указывает для каких ботов будут действовать последующие правила.
User-agent: Googlebot
Disallow: /category
User-agent: *
Disallow: /Недопустимы пустые строки между директивами User-agent, Disallow и Allow.
Основные роботы поисковиков
Яндекс
| YandexBot | Основной робот |
| YandexImages | Яндекс.Картинки |
| YandexMedia | Мультимедийные данные |
| YandexNews | Яндекс.Новости |
| YandexBlogs | Поиск по блогам |
| YandexCalendar | Яндекс. Календарь Календарь |
| YandexDirect | Рекламная сеть |
| YandexMarket | Яндекс.Маркет |
| YandexMetrika | Яндекс.Метрика |
| Googlebot | Основной робот |
| Googlebot-Image | Изображения |
| Googlebot-Video | Видео |
| Mediapartners-Google | AdSense |
2
Disallow
Директива запрещающая индексировать указанные адреса страниц.
Запретить GET параметр view:
Запретить все GET параметры:
Запретить http://example.com/page и все дочерние страницы:
Запретить страницу http://example.com/page, но не дочерние:
Запрет индексирования php файлов:
Запретить индексирование pdf файлы:
Не индексировать UTM-метки:
3
Allow
Разрешает индексирование страниц сайта, используется в основном в связке Disallow.
Например, следующая запись запрещает индексирование всего сайта кроме раздела http://example.com/category.
Allow: /category
Disallow: /4
Crawl-delay
Директива задает интервал в секундах между загрузками страниц Яндексом. Эту директиву следует выносить в отдельный блок т.к. файл не пройдет валидацию в Google.
Например, задержка 5 сек:
User-agent: Yandex
Crawl-delay: 5.0
User-agent: *
...5
Clean-param
Чтобы не индексировать страницы с динамическими GET параметрами (сортировки, сессии и т.д.) Яндекс ввел директиву Clean-param которая сводит такие адреса к одному. Также директиву следует выносить в отдельный блок.
В robots.txt указывается имя GET переменной которая будет игнорироваться и через пробел адрес страницы которая будет использована.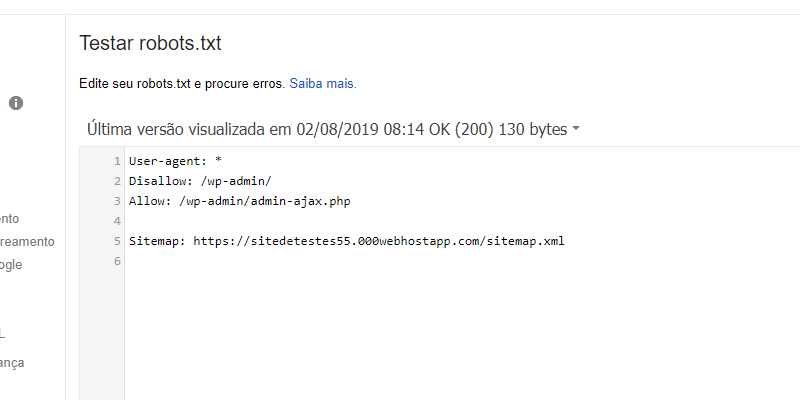
Например для следующих адресов:
http://example.com/category
http://example.com/category?sort=asc
http://example.com/category?sort=desc
Запись будет следующая:
User-agent: Yandex
Clean-param: sort /categoryМожно указать несколько GET переменных через символ &:
User-agent: Yandex
Clean-param: sort&session /category6
Host
Указывает основное зеркало сайта.
Основное зеркало с www:
Host: http://www.example.comЕсли сайт работает на https:
Host: https://example.comС апреля 2018 года Яндекс прекратил поддержку директивы Host, Google эту директиву никогда не поддерживал.
7
Sitimap
Карта сайта – файл sitimap. xml
Sitemap: http://example.com/sitemap.xml- Кодировка файла должна быть в UTF-8.
- Максимальное количество ссылок – 50 000
Можно указать несколько файлов:
Sitemap: http://example.com/sitemap.xml
Sitemap: http://example.com/sitemap-2.xml
Sitemap: http://example.com/sitemap-3.xml8
Пример файла
User-agent: *
Disallow: /search
Disallow: /themes
Disallow: /plugins
Sitemap: http://example.com/sitemap.xmlRobots.txt Введение и руководство | Центр поиска Google
Что такое файл robots.txt?
Файл robots.txt сообщает сканерам поисковых систем, какие страницы или файлы он может или
не могу запросить с вашего сайта. Это используется в основном для того, чтобы не перегружать ваш сайт
Запросы; , это не механизм для защиты веб-страницы от Google. Чтобы веб-страница не попала в Google, вы должны использовать директив noindex ,
или защитите свою страницу паролем.
Для чего используется файл robots.txt?
Файл robots.txt используется в основном для управления трафиком сканера на ваш сайт, а обычно для хранения файла вне Google, в зависимости от типа файла:
| Тип файла | Управление движением | Скрыть от Google | Описание |
|---|---|---|---|
| Интернет-страница | Для веб-страниц (HTML, PDF или другие форматы, не относящиеся к мультимедиа, которые может читать Google), файл robots.txt можно использовать для управления сканирующим трафиком, если вы считаете, что ваш сервер будет перегружен запросами от поискового робота Google, или чтобы избежать сканирования неважных или похожих страниц на вашем сайте. Вы не должны использовать файл robots.txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Это потому, что, если другие страницы указывают на вашу страницу с описательным текстом, ваша страница все равно может быть проиндексирована без посещения страницы. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или директиву Если ваша веб-страница заблокирована файлом robots.txt , она все равно может отображаться в результатах поиска, но результат поиска не будет иметь описания и будет выглядеть примерно так. Файлы изображений, видеофайлы, PDF-файлы и другие файлы, отличные от HTML, будут исключены. Если вы видите этот результат поиска для своей страницы и хотите его исправить, удалите запись robots.txt, блокирующую страницу. Если вы хотите полностью скрыть страницу от поиска, воспользуйтесь другим методом. | ||
| Медиа-файл | Используйте robots.txt для управления трафиком сканирования, а также для предотвращения появления файлов изображений, видео и аудио в результатах поиска Google. (Обратите внимание, что это не помешает другим страницам или пользователям ссылаться на ваш файл изображения / видео / аудио.) | ||
| Файл ресурсов | Вы можете использовать файл robots.txt для блокировки файлов ресурсов, таких как неважные изображения, скрипты или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не пострадают от потери .Однако, если отсутствие этих ресурсов затрудняет понимание страницы поисковым роботом Google, вы не должны блокировать их, иначе Google не сможет хорошо проанализировать страницы, зависящие от этих ресурсов. |


Пользуюсь услугами хостинга сайтов
Если вы используете службу хостинга веб-сайтов, такую как Wix, Drupal или Blogger, вам может не потребоваться (или у вас будет возможность) напрямую редактировать файл robots.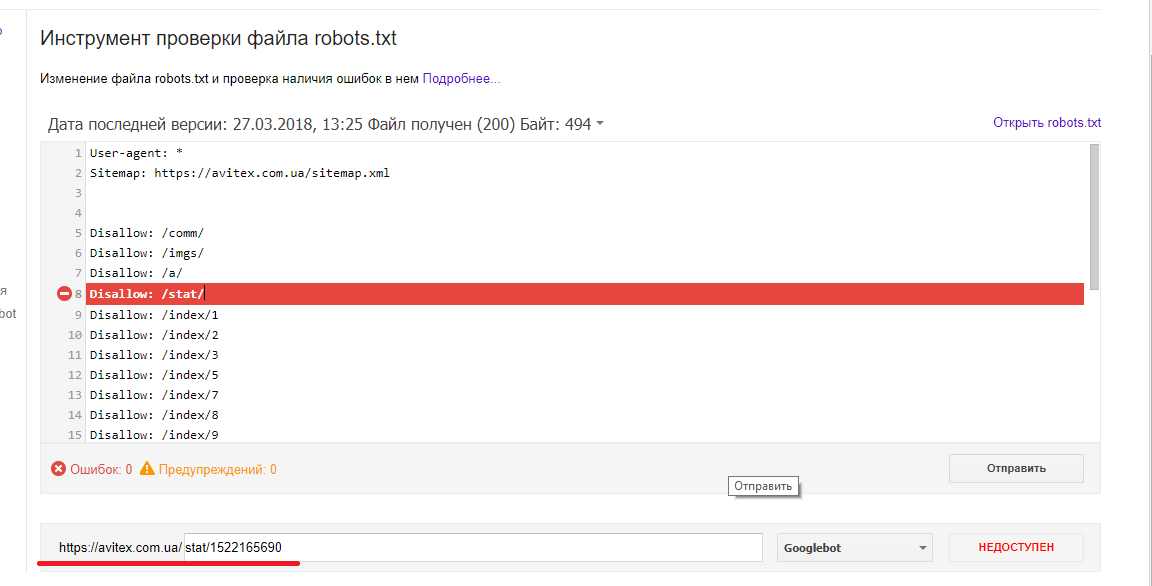 txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
Чтобы узнать, просканировала ли ваша страница Google, найдите URL-адрес страницы в Google.
Если вы хотите скрыть (или показать) свою страницу от поисковых систем, добавьте (или удалите) любую страницу входа в систему. требования, которые могут существовать, и поиск инструкций по изменению вашей страницы видимость в поисковых системах на вашем хостинге, например: wix скрыть страницу от поисковых систем
Ознакомьтесь с ограничениями файла robots.txt
Прежде чем создавать или редактировать файл robots.txt, вы должны знать ограничения этого метода блокировки URL. Иногда вам может потребоваться рассмотреть другие механизмы, чтобы гарантировать, что ваши URL-адреса не будут найдены в Интернете.
- Директивы Robots.txt могут поддерживаться не всеми поисковыми системами
Инструкции в файлах robots.txt не могут принудить сканер к вашему сайту; гусеничный робот должен им подчиняться. В то время как робот Googlebot и другие уважаемые веб-сканеры подчиняются инструкциям в файле robots.txt, другие сканеры могут этого не делать.Поэтому, если вы хотите защитить информацию от веб-сканеров, лучше использовать другие методы блокировки, такие как защита паролем личных файлов на вашем сервере. - Различные поисковые роботы по-разному интерпретируют синтаксис
Хотя уважаемые веб-сканеры следуют директивам в файле robots.txt, каждый поисковый робот может интерпретировать директивы по-разному. Вы должны знать правильный синтаксис для обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции. - Роботизированная страница все еще может быть проиндексирована, если на нее есть ссылки с других сайтов
Хотя Google не будет сканировать и индексировать контент, заблокированный файлом robots. txt, мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылка с другого места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, может по-прежнему отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег noindexили заголовок ответа (или полностью удалить страницу).
 txt, мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылка с другого места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, может по-прежнему отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег
txt, мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылка с другого места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, может по-прежнему отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег Тестирование страницы на наличие блоков robots.txt
Вы можете проверить, заблокирована ли страница или ресурс правилом robots. txt.
txt.
Для проверки директив noindex используйте инструмент проверки URL.
Robots.txt и SEO: Полное руководство
Что такое роботы.текст?
Robots.txt — это файл, который сообщает паукам поисковых систем не сканировать определенные страницы или разделы веб-сайта. Большинство основных поисковых систем (включая Google, Bing и Yahoo) распознают и обрабатывают запросы Robots.txt.
Почему важен Robots.txt?
Большинству веб-сайтов не нужен файл robots.txt.
Это потому, что Google обычно может найти и проиндексировать все важные страницы вашего сайта.
И они автоматически НЕ будут индексировать несущественные страницы или дублировать версии других страниц.
Тем не менее, есть 3 основные причины, по которым вы хотите использовать файл robots.txt.
Блокировать закрытые страницы. Иногда на вашем сайте есть страницы, которые вы не хотите индексировать.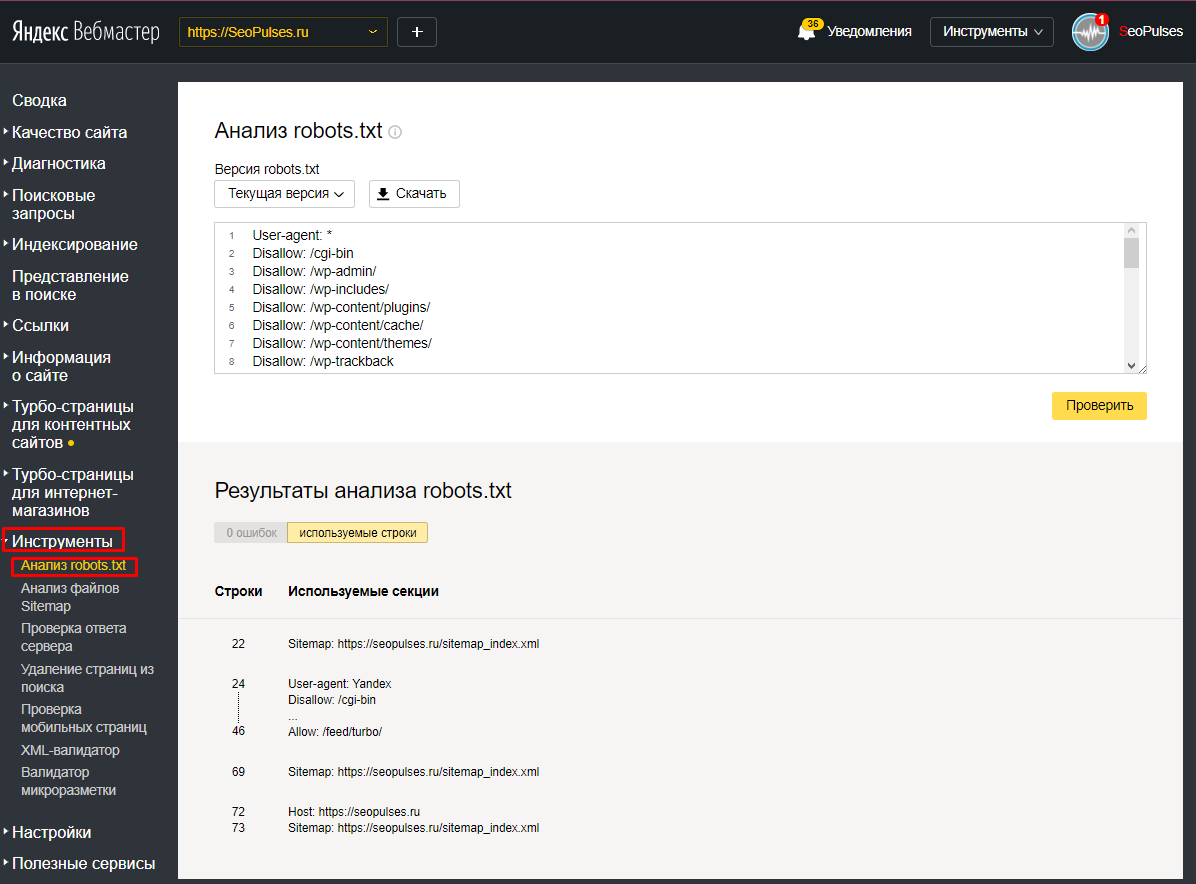 Например, у вас может быть промежуточная версия страницы. Или страницу входа в систему. Эти страницы должны существовать. Но вы же не хотите, чтобы на них садились случайные люди. Это тот случай, когда вы использовали robots.txt, чтобы заблокировать эти страницы от поисковых роботов и роботов.
Например, у вас может быть промежуточная версия страницы. Или страницу входа в систему. Эти страницы должны существовать. Но вы же не хотите, чтобы на них садились случайные люди. Это тот случай, когда вы использовали robots.txt, чтобы заблокировать эти страницы от поисковых роботов и роботов.
Максимальное увеличение бюджета сканирования. Если вам сложно проиндексировать все страницы, возможно, у вас проблемы с бюджетом сканирования.Блокируя неважные страницы с помощью robots.txt, робот Googlebot может тратить большую часть вашего краулингового бюджета на действительно важные страницы.
Предотвращение индексации ресурсов: использование метадиректив может работать так же хорошо, как и Robots.txt для предотвращения индексации страниц. Однако метадирективы плохо работают для мультимедийных ресурсов, таких как файлы PDF и изображения. Вот где в игру вступает robots.txt.
В нижней строке? Robots.txt сообщает паукам поисковых систем не сканировать определенные страницы вашего веб-сайта.
Вы можете проверить, сколько страниц вы проиндексировали, в Google Search Console.
Если число совпадает с количеством страниц, которые вы хотите проиндексировать, вам не нужно возиться с файлом Robots.txt.
Но если это число выше, чем вы ожидали (и вы заметили проиндексированные URL-адреса, которые не следует индексировать), то пора создать файл robots.txt для вашего веб-сайта.
Лучшие Лрактики
Создание файла Robots.txt
Ваш первый шаг — создать роботов.txt файл.
Являясь текстовым файлом, вы можете создать его с помощью блокнота Windows.
И независимо от того, как вы в конечном итоге создаете свой файл robots.txt, формат точно такой же:
Агент пользователя: X
Запрещено: Y
User-agent — это конкретный бот, с которым вы разговариваете.
И все, что идет после «запретить», — это страницы или разделы, которые вы хотите заблокировать.
Вот пример:
User-agent: googlebot
Disallow: / images
Это правило указывает роботу Googlebot не индексировать папку изображений на вашем веб-сайте.
Вы также можете использовать звездочку (*), чтобы общаться со всеми ботами, которые останавливаются на вашем сайте.
Вот пример:
User-agent: *
Disallow: / images
Знак «*» говорит всем паукам НЕ сканировать папку с изображениями.
Это лишь один из многих способов использования файла robots.txt. В этом полезном руководстве от Google есть дополнительная информация о различных правилах, которые вы можете использовать для блокировки или разрешения ботам сканировать разные страницы вашего сайта.
Сделайте своих роботов.txt Легко найти
Когда у вас есть файл robots.txt, самое время запустить его.
Технически вы можете разместить файл robots.txt в любом основном каталоге вашего сайта.
Но чтобы увеличить вероятность того, что ваш файл robots.txt будет найден, я рекомендую разместить его по адресу:
https://example.com/robots.txt
(Обратите внимание, что ваш файл robots.txt чувствителен к регистру.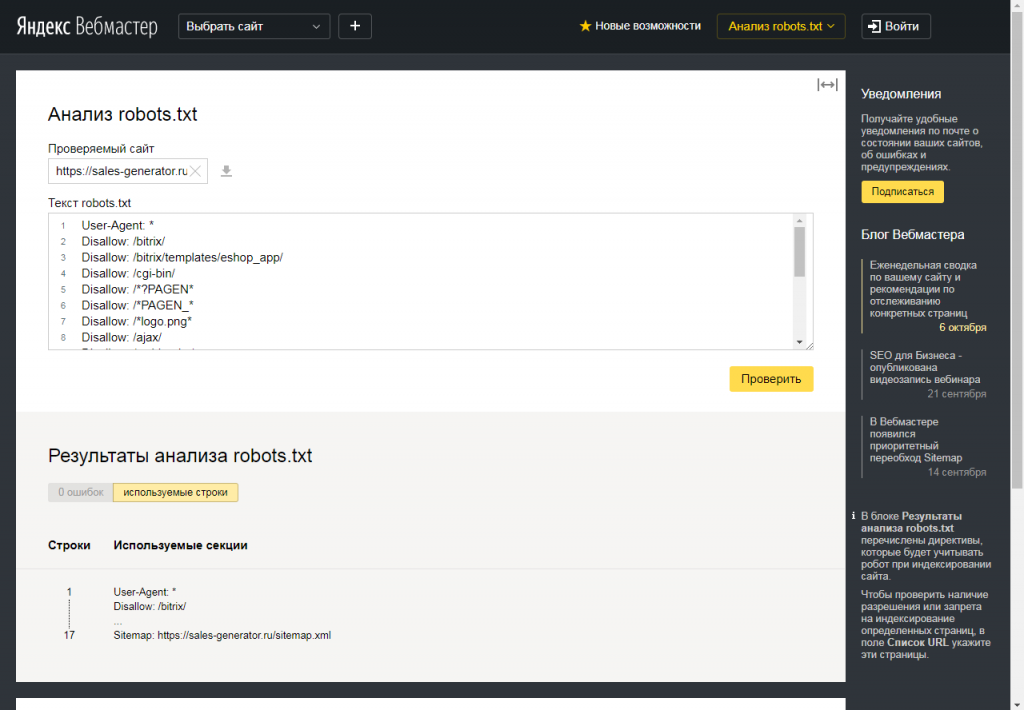 Поэтому обязательно используйте строчную букву «r» в имени файла)
Поэтому обязательно используйте строчную букву «r» в имени файла)
Проверка ошибок и ошибок
ДЕЙСТВИТЕЛЬНО важно, чтобы ваш файл robots.txt настроен правильно. Одна ошибка — и весь ваш сайт может быть деиндексирован.
К счастью, вам не нужно надеяться, что ваш код настроен правильно. У Google есть отличный инструмент для тестирования роботов, который вы можете использовать:
Показывает ваш файл robots.txt… и все обнаруженные ошибки и предупреждения:
Как видите, мы не позволяем паукам сканировать нашу страницу администратора WP.
Мы также используем robots.txt, чтобы блокировать сканирование страниц с автоматически созданными тегами WordPress (для ограничения дублирования контента).
Robots.txt и мета-директивы
Зачем вам использовать robots.txt, если вы можете блокировать страницы на уровне страницы с помощью метатега «noindex»?
Как я упоминал ранее, тег noindex сложно реализовать в мультимедийных ресурсах, таких как видео и PDF-файлы.
Кроме того, если у вас есть тысячи страниц, которые вы хотите заблокировать, иногда проще заблокировать весь раздел этого сайта с помощью robots.txt вместо того, чтобы вручную добавлять тег noindex на каждую страницу.
Есть также крайние случаи, когда вы не хотите тратить бюджет сканирования на целевые страницы Google с тегом noindex.
Тем не менее:
Помимо этих трех крайних случаев, я рекомендую использовать метадирективы вместо robots.txt. Их проще реализовать. И меньше шансов на катастрофу (например, блокировку всего вашего сайта).
Узнать больше
Узнайте о файлах robots.txt: полезное руководство по использованию и интерпретации роботов.текст.
Что такое файл Robots.txt? (Обзор SEO + Key Insight): подробное видео о различных вариантах использования robots.txt.
Пример txt файла Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете скопировать их на свой сайт или объединить шаблоны, чтобы создать свои собственные.
Помните, что файл robots.txt влияет на ваше SEO, поэтому обязательно проверяйте вносимые вами изменения.
Приступим.
1) Запретить все
Первый шаблон остановит сканирование вашего сайта всеми ботами.Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду.
Какой бы ни была причина, как вы запретите всем поисковым роботам читать страницы:
Агент пользователя: *
Disallow: / Здесь мы ввели два «правила»:
- User-agent — Настройте таргетинг на конкретного бота, используя это правило, или используйте * в качестве подстановочного знака, что означает всех ботов
- Disallow — Используется, чтобы сообщить боту, что он не может перейти в эту область сайта.Установив для этого параметра значение
/, бот не будет сканировать ни одну из ваших страниц.
Что, если мы хотим, чтобы бот сканировал весь сайт?
2) Разрешить все
Если у вас нет файла robots.txt на вашем сайте, то по умолчанию бот будет сканировать весь сайт. Один из вариантов — не создавать и не удалять файл robots.txt.
Тем не менее, иногда это невозможно, и нужно что-то добавить. В этом случае мы бы добавили следующее:
На первый взгляд это кажется странным, поскольку у нас все еще действует правило Disallow.Тем не менее, он другой, поскольку он не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL-адрес не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда вам нужно заблокировать часть сайта, но разрешить доступ остальным. Хорошим примером этого является админка страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты просматривали эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: *
Запретить: / admin / Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое и с файлами. Возможно, существует конкретный файл, который вы не хотите, чтобы он попал в поиск Google. Опять же, это может быть админка или что-то подобное.
Чтобы заблокировать это для ботов, используйте файл robots.txt.
Агент пользователя: *
Disallow: /admin.html Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением.Например, вы можете заблокировать PDF-файлы на вашем сайте, чтобы они попадали в поиск Google. Или у вас есть электронные таблицы, на чтение которых робот Googlebot не должен тратить время зря.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— Это подстановочный знак и будет соответствовать всему тексту -
$— Знак доллара остановит сопоставление URL-адресов и представляет конец URL-адреса
При совместном использовании вы можете заблокировать PDF-файлы следующим образом:
Агент пользователя: *
Запретить: / *. pdf $  pdf $
pdf $ или .xls файлов вроде этого:
Агент пользователя: *
Disallow: /*.xls$ Обратите внимание, что правило запрета имеет значение /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example.com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https: // example.com / pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью правила User-agent , до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если мы хотим разрешить просмотр страниц сайта только роботу Googlebot, мы могли бы добавить этот файл robots. txt:
txt:
Агент пользователя: *
Запретить: /
Пользовательский агент: Googlebot
Disallow: 7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота.Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Пользовательский агент: Googlebot
Запретить: /
Пользовательский агент: *
Disallow: Есть много пользовательских агентов-ботов, вот список общих, с которыми вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайская поисковая система
- ЯндексБот — это русская поисковая машина
- facebot — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter
8) Ссылка на вашу карту сайта
Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы упрощаете ботам поиск всех ссылок на вашем сайте.
В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы упрощаете ботам поиск всех ссылок на вашем сайте.
Для этого вам необходимо использовать правило Sitemap :
Агент пользователя: *
Карта сайта: https://pagedart.com/sitemap.xml Это взято из файла robots.txt PageDart. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https: // в начале, чтобы он работал.
9) Снизьте скорость ползания
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер испытывает трудности при высоком трафике.
Bing, Yahoo и Яндекс поддерживают правило Crawl-delay . Это позволяет вам установить задержку между просмотром каждой страницы следующим образом:
Агент пользователя: *
Задержка сканирования: 10 В приведенном выше примере бот будет ждать 10 секунд перед запросом следующей страницы. Вы можете установить задержку от 1 до 30 секунд.
Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуйте робота
Этот последний шаблон предназначен для развлечения. Вы можете добавить искусство ASCII, чтобы добавить робота в файл robots.txt, например:
# _
# []
# ()
# |> |
# __ / === \ __
# // | о = о | \\
# <] | о = о | [>
# \ ===== /
# / / | \ \
№ <_________> Если кто-нибудь придет посмотреть на ваш robots.txt, то он может заставить их улыбнуться.
Некоторые компании уже делают это, у Airbnb есть реклама в их файле robots.txt:
https://www.airbnb.co.uk/robots.txt
NPM имеет робота в своем robots.txt:
https://www.npmjs.com/robots.txt
На Avvo.com есть рисунок Grumpy Cat в кодировке ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood. com/robots.txt
com/robots.txt
Заключение, пример файла robots txt
Мы рассмотрели 10 разных роботов.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всем ботам со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить конкретного бота
- Ссылка на вашу карту сайта
- Понизьте скорость, с которой бот сканирует ваш сайт
- Нарисуйте какие-то работы в ваших роботах.txt файл
Помните, что вы можете комбинировать части этих шаблонов любым удобным вам способом, пока действуют правила. Чтобы проверить, действителен ли файл robots.txt, вы можете использовать нашу программу проверки robots.txt.
Все, что вам нужно знать
У вас больше контроля над поисковыми системами, чем вы думаете.
Это правда; вы можете управлять тем, кто сканирует и индексирует ваш сайт, вплоть до отдельных страниц. Чтобы контролировать это, вам нужно будет использовать файл robots.txt. Роботы.txt — это простой текстовый файл, который находится в корневом каталоге вашего веб-сайта. Он сообщает роботам, которых отправляют поисковые системы, какие страницы сканировать, а какие игнорировать.
Хотя это не совсем универсальный инструмент, вы, вероятно, догадались, что это довольно мощный инструмент, который позволит вам представить свой веб-сайт в Google так, как вы хотите, чтобы они его увидели. Поисковые системы сурово разбираются в людях, поэтому произвести хорошее впечатление необходимо. Robots.txt при правильном использовании может повысить частоту сканирования, что может повлиять на ваши усилия по поисковой оптимизации.
Итак, как его создать? Как Вы этим пользуетесь? Чего следует избегать? Прочтите этот пост, чтобы найти ответы на все эти вопросы.
Что такое файл Robots.txt?
В те времена, когда Интернет был всего лишь ребенком с детским лицом, способным творить великие дела, разработчики изобрели способ сканирования и индексации новых страниц в сети. Они назвали их «роботами» или «пауками».
Иногда эти маленькие ребята забредали на веб-сайты, которые не были предназначены для сканирования и индексации, например, на сайты, находящиеся на техническом обслуживании.Создатель первой в мире поисковой системы Aliweb порекомендовал решение — своего рода дорожную карту, которой должен следовать каждый робот.
Эта дорожная карта была завершена в июне 1994 года группой технически подкованных в Интернете технических специалистов под названием «Протокол исключения роботов».
Файл robots.txt является исполнением этого протокола. В протоколе изложены правила, которым должен следовать каждый настоящий робот, включая ботов Google. Некоторые незаконные роботы, такие как вредоносное ПО, шпионское ПО и т. Д., По определению, действуют вне этих правил.
Вы можете заглянуть за кулисы любого веб-сайта, введя любой URL-адрес и добавив в конце: /robots.txt.
Например, вот версия POD Digital:
Как видите, нет необходимости иметь файл, состоящий только из песен и танцев, поскольку наш веб-сайт относительно небольшой.
Где найти файл Robots.txt
Ваш файл robots.txt будет храниться в корневом каталоге вашего сайта. Чтобы найти его, откройте свою FTP cPanel, и вы сможете найти файл в каталоге вашего веб-сайта public_html.
В этих файлах нет ничего, чтобы они не были здоровенными — возможно, всего несколько сотен байт, если это так.
Как только вы откроете файл в текстовом редакторе, вас встретит что-то вроде этого:
Если вы не можете найти файл во внутренней работе вашего сайта, вам придется создать свой собственный.
Как собрать файл Robots.txt
Robots.txt — это очень простой текстовый файл, поэтому его просто создать.Все, что вам понадобится, это простой текстовый редактор, например Блокнот. Откройте лист и сохраните пустую страницу как robots.txt.
Теперь войдите в свою cPanel и найдите папку public_html, чтобы получить доступ к корневому каталогу сайта. Как только он откроется, перетащите в него свой файл.
Наконец, вы должны убедиться, что вы установили правильные разрешения для файла. В основном, как владелец, вам нужно будет писать, читать и редактировать файл, но никакие другие стороны не должны иметь права делать это.
Файл должен отображать код разрешения «0644».
Если нет, вам нужно будет изменить это, поэтому щелкните файл и выберите «Разрешение файла».
Вуаля! У вас есть файл Robots.txt.
Robots.txt Синтаксис
Файл robots.txt состоит из нескольких разделов «директив», каждый из которых начинается с указанного пользовательского агента. Пользовательский агент — это имя конкретного робота-обходчика, с которым обращается код.
Доступны два варианта:
- Вы можете использовать подстановочный знак для одновременного обращения ко всем поисковым системам.
- Вы можете обращаться к конкретным поисковым системам индивидуально.
Когда бот развернут для сканирования веб-сайта, он будет привлечен к блокам, которые обращаются к нему.
Вот пример:
Директива пользователя-агента
Первые несколько строк в каждом блоке — это «пользовательский агент», который определяет конкретного бота. Пользовательский агент будет соответствовать определенному имени бота, например:
Итак, если вы хотите сказать роботу Google, что делать, например, начните с:
Пользовательский агент: Googlebot
Поисковые системы всегда пытаются чтобы определить конкретные директивы, которые наиболее к ним относятся.
Так, например, если у вас есть две директивы, одна для Googlebot-Video и одна для Bingbot. Бот, который поставляется вместе с пользовательским агентом Bingbot, будет следовать инструкциям. Тогда как бот «Googlebot-Video» пропустит это и отправится на поиски более конкретной директивы.
В большинстве поисковых систем есть несколько разных ботов, вот список наиболее распространенных.
Директива хоста
Директива хоста на данный момент поддерживается только Яндексом, хотя некоторые предположения говорят, что Google ее поддерживает.Эта директива позволяет пользователю решить, отображать ли www. перед URL, использующим этот блок:
Хост: poddigital.co.uk
Поскольку Яндекс является единственным подтвержденным сторонником директивы, полагаться на нее не рекомендуется. Вместо этого 301 перенаправляет имена хостов, которые вам не нужны, на те, которые вам нужны.
Disallow Directive
Мы рассмотрим это более конкретно чуть позже.
Вторая строка в блоке директив — Disallow. Вы можете использовать это, чтобы указать, какие разделы сайта не должны быть доступны ботам.Пустое запрещение означает, что это является бесплатным для всех, и боты могут угождать себе, где они делают, а где не ходят.
Директива карты сайта (XML-карты сайта)
Использование директивы карты сайта сообщает поисковым системам, где найти карту сайта в формате XML.
Однако, вероятно, наиболее полезным было бы отправить каждый из них в специальные инструменты для веб-мастеров поисковых систем. Это потому, что вы можете узнать много ценной информации от каждого о своем веб-сайте.
Однако, если у вас мало времени, директива карты сайта является жизнеспособной альтернативой.
Директива о задержке сканирования
Yahoo, Bing и Яндекс могут быть немного счастливы, когда дело доходит до сканирования, но они действительно реагируют на директиву задержки сканирования, которая удерживает их на некоторое время.
Применение этой строки к вашему блоку:
Crawl-delay: 10
означает, что вы можете заставить поисковые системы ждать десять секунд перед сканированием сайта или десять секунд, прежде чем они повторно получат доступ к сайту после сканирования — это, по сути, то же самое, но немного отличается в зависимости от поисковой системы.
Зачем использовать Robots.txt
Теперь, когда вы знаете об основах и о том, как использовать несколько директив, вы можете собрать свой файл. Однако следующий шаг будет зависеть от типа контента на вашем сайте.
Robots.txt не является важным элементом успешного веб-сайта; Фактически, ваш сайт может нормально функционировать и хорошо ранжироваться без него.
Однако есть несколько ключевых преимуществ, о которых вы должны знать, прежде чем отклонить его:
Point Bots Away From Private Folders : Если запретить ботам проверять ваши личные папки, их будет намного сложнее найти и проиндексировать.
Держите ресурсы под контролем : Каждый раз, когда бот просматривает ваш сайт, он поглощает пропускную способность и другие ресурсы сервера. Для сайтов с тоннами контента и большим количеством страниц, например, сайты электронной коммерции могут иметь тысячи страниц, и эти ресурсы могут быть истощены очень быстро. Вы можете использовать robots.txt, чтобы затруднить доступ ботам к отдельным скриптам и изображениям; это позволит сохранить ценные ресурсы для реальных посетителей.
Укажите местоположение вашей карты сайта : Это довольно важный момент, вы хотите, чтобы сканеры знали, где находится ваша карта сайта, чтобы они могли ее просканировать.
Держите дублированный контент подальше от результатов поиска : Добавив правило к своим роботам, вы можете запретить поисковым роботам индексировать страницы, содержащие дублированный контент.
Вы, естественно, захотите, чтобы поисковые системы находили путь к наиболее важным страницам вашего веб-сайта. Вежливо ограничивая определенные страницы, вы можете контролировать, какие страницы будут отображаться для поисковиков (однако убедитесь, что никогда не блокирует полностью поисковым системам для просмотра определенных страниц).
Например, если мы посмотрим на файл роботов POD Digital, мы увидим, что этот URL:
poddigital.co.uk/wp-admin был запрещен.
Поскольку эта страница предназначена только для того, чтобы мы могли войти в панель управления, нет смысла позволять ботам тратить свое время и энергию на ее сканирование.
Noindex
В июле 2019 года Google объявил о прекращении поддержки директивы noindex, а также многих ранее неподдерживаемых и неопубликованных правил, на которые многие из нас ранее полагались.
Многие из нас решили поискать альтернативные способы применения директивы noindex, и ниже вы можете увидеть несколько вариантов, которые вы можете выбрать вместо этого:
Noindex Tag / Noindex HTTP Response Header: Этот тег может быть реализован двумя способами: сначала будет заголовок HTTP-ответа с X-Robots-Tag или создать тег, который необходимо будет реализовать в
раздел.
Ваш тег должен выглядеть, как показано ниже:
СОВЕТ : помните, что если эта страница была заблокирована роботами.txt, сканер никогда не увидит ваш тег noindex, и все еще есть вероятность, что эта страница будет представлена в результатах поиска.
Защита паролем: Google заявляет, что в большинстве случаев, если вы скрываете страницу за логином, ее следует удалить из индекса Google. Единственное исключение представлено, если вы используете разметку схемы, которая указывает, что страница связана с подпиской или платным контентом.
Код состояния HTTP 404 и 410: Коды состояния 404 и 410 представляют страницы, которые больше не существуют.После того, как страница со статусом 404/410 просканирована и полностью обработана, она должна быть автоматически удалена из индекса Google.
Вам следует систематически сканировать свой веб-сайт, чтобы снизить риск появления страниц с ошибками 404 и 410, и при необходимости использовать переадресацию 301 для перенаправления трафика на существующую страницу.
Правило запрета в robots.txt: Добавив правило запрета для конкретной страницы в файл robots.txt, вы предотвратите сканирование страницы поисковыми системами.В большинстве случаев ваша страница и ее содержание не индексируются. Однако вы должны иметь в виду, что поисковые системы по-прежнему могут индексировать страницу на основе информации и ссылок с других страниц.
Инструмент удаления URL в Search Console: Этот альтернативный корень не решает проблему индексации в полной мере, поскольку инструмент удаления URL в Search Console удаляет страницу из результатов поиска на ограниченное время.
Однако это может дать вам достаточно времени, чтобы подготовить дальнейшие правила и теги роботов для полного удаления страниц из поисковой выдачи.
Инструмент удаления URL-адреса находится в левой части основной панели навигации в Google Search Console.
Noindex vs. Disallow
Многие из вас, вероятно, задаются вопросом, что лучше использовать тег noindex или правило запрета в вашем файле robots.txt. В предыдущей части мы уже рассмотрели, почему правило noindex больше не поддерживается в robots.txt и других альтернативах.
Если вы хотите убедиться, что одна из ваших страниц не проиндексируется поисковыми системами, вам обязательно стоит взглянуть на метатег noindex.Он позволяет ботам получить доступ к странице, но тег позволит роботам узнать, что эта страница не должна индексироваться и не должна отображаться в результатах поиска.
Правило запрета может быть не таким эффективным, как тег noindex в целом. Конечно, добавляя его в robots.txt, вы блокируете сканирование вашей страницы ботами, но если упомянутая страница связана с другими страницами внутренними и внешними ссылками, боты все равно могут индексировать эту страницу на основе информации, предоставленной другими страницами. / сайты.
Вы должны помнить, что если вы запретите страницу и добавите тег noindex, то роботы никогда не увидят ваш тег noindex, что по-прежнему может вызывать появление страницы в поисковой выдаче.
Использование регулярных выражений и подстановочных знаков
Итак, теперь мы знаем, что такое файл robots.txt и как его использовать, но вы можете подумать: «У меня большой веб-сайт электронной коммерции, и я хотел бы запретить все страницы, которые содержат вопросительные знаки (?) в своих URL «.
Здесь мы хотели бы представить ваши подстановочные знаки, которые можно реализовать в файле robots.txt. В настоящее время у вас есть два типа подстановочных знаков на выбор.
* Подстановочные знаки — где подстановочные знаки * соответствуют любой последовательности символов по вашему желанию.Этот тип подстановочного знака будет отличным решением для ваших URL-адресов, которые следуют тому же шаблону. Например, вы можете запретить сканирование всех страниц с фильтрами, в URL-адресах которых стоит вопросительный знак (?).
$ Подстановочные знаки — где $ соответствует концу вашего URL-адреса. Например, если вы хотите убедиться, что ваш файл robots запрещает ботам доступ ко всем файлам PDF, вы можете добавить правило, подобное приведенному ниже:
Давайте быстро разберем приведенный выше пример.Ваш файл robots.txt позволяет любым ботам User-agent сканировать ваш веб-сайт, но запрещает доступ ко всем страницам, которые содержат конец .pdf.
Ошибок, которых следует избегать
Мы немного поговорили о том, что вы можете сделать, и о различных способах работы со своим robots.txt. Мы собираемся немного углубиться в каждый пункт этого раздела и объяснить, как каждый из них может обернуться катастрофой для SEO, если его не использовать должным образом.
Не блокировать хороший контент
Важно не блокировать любой хороший контент, который вы хотите представить роботам для всеобщего сведения.txt или тега noindex. В прошлом мы видели много подобных ошибок, которые отрицательно сказывались на результатах SEO. Вам следует тщательно проверять свои страницы на наличие тегов noindex и запрещающих правил.
Чрезмерное использование Crawl-Delay
Мы уже объяснили, что делает директива crawl-delay, но вам не следует использовать ее слишком часто, поскольку вы ограничиваете страницы, просматриваемые ботами. Это может быть идеальным для некоторых веб-сайтов, но если у вас большой веб-сайт, вы можете выстрелить себе в ногу и помешать хорошему ранжированию и устойчивому трафику.
Чувствительность к регистру
Файл Robots.txt чувствителен к регистру, поэтому вы должны не забыть создать файл robots правильно. Вы должны называть файл роботов «robots.txt», все в нижнем регистре. Иначе ничего не получится!
Использование Robots.txt для предотвращения индексации содержимого
Мы уже немного рассмотрели это. Запрет доступа к странице — лучший способ предотвратить ее прямое сканирование ботами.
Но не сработает в следующих случаях:
Если на страницу есть ссылка из внешнего источника, боты все равно будут проходить и индексировать страницу.
Незаконные боты по-прежнему будут сканировать и индексировать контент.
Использование Robots.txt для защиты частного содержимого
Некоторое личное содержимое, такое как PDF-файлы или страницы с благодарностью, можно индексировать, даже если вы направите роботов от него. Один из лучших способов дополнить директиву disallow — разместить весь ваш личный контент за логином.
Конечно, это означает, что он добавляет дополнительный шаг для ваших посетителей, но ваш контент останется в безопасности.
Использование Robots.txt для скрытия вредоносного дублированного содержимого
Дублированное содержимое иногда является неизбежным злом — например, страницы, удобные для печати.
Однако Google и другие поисковые системы достаточно умны, чтобы знать, когда вы пытаетесь что-то скрыть. Фактически, это может привлечь к нему больше внимания, и это связано с тем, что Google распознает разницу между страницей, удобной для печати, и тем, кто пытается заткнуть себе глаза:
Есть еще шанс, что ее можно найти в любом случае.
Вот три способа работы с таким содержанием:
Перепишите контент — Создание захватывающего и полезного контента побудит поисковые системы рассматривать ваш сайт как надежный источник. Это предложение особенно актуально, если контент представляет собой задание копирования и вставки.
301 редирект — 301 редирект информирует поисковые системы о том, что страница переместилась в другое место. Добавьте 301 на страницу с дублированным контентом и перенаправьте посетителей на исходный контент на сайте.
Rel = «canonical » — это тег, который информирует Google об исходном местонахождении дублированного контента; это особенно важно для веб-сайта электронной коммерции, где CMS часто генерирует повторяющиеся версии одного и того же URL-адреса.
Момент истины: проверка вашего файла Robots.txt
Теперь пора протестировать ваш файл, чтобы убедиться, что все работает так, как вы хотите.
В Инструментах для веб-мастеров Google есть файл robots.txt, но в настоящее время он доступен только в старой версии Google Search Console. Вы больше не сможете получить доступ к тестеру robot.txt с помощью обновленной версии GSC (Google усердно работает над добавлением новых функций в GSC, поэтому, возможно, в будущем мы сможем увидеть тестер Robots.txt в основная навигация).
Итак, сначала вам нужно посетить страницу поддержки Google, на которой представлен обзор возможностей тестера Robots.txt.
Там вы также найдете роботов.txt Tester tool:
Выберите свойство, над которым вы собираетесь работать, например, веб-сайт вашей компании из раскрывающегося списка.
Удалите все, что сейчас находится в коробке, замените его новым файлом robots.txt и нажмите, протестируйте:
. Если «Тест» изменится на «Разрешено», значит, вы получили полностью работающий robots.txt.
Правильное создание файла robots.txt означает, что вы улучшаете SEO и удобство работы посетителей.
Позволяя ботам тратить свои дни на сканирование нужных вещей, они смогут систематизировать и показывать ваш контент так, как вы хотите, чтобы он отображался в поисковой выдаче.
Ресурсы для платформ CMS
Получите бесплатную 7-дневную пробную версию
Начните работать над своей онлайн-видимостью
Robots.txt: руководство по передовой практике + примеры
Файл robots.txt — это часто упускаемая из виду, а иногда и забываемая часть веб-сайта и SEO.
Но, тем не менее, файл robots.txt является важной частью любого набора инструментов SEO, независимо от того, начинаете ли вы работать в отрасли или являетесь опытным ветераном SEO.
Что такое файл robots.txt?
Файл robots.txt можно использовать для различных целей, от предоставления поисковым системам информации о том, где найти карту сайта для ваших сайтов, до сообщения им, какие страницы сканировать, а какие не сканировать, а также в качестве отличного инструмента для управления вашими сайтами. краулинговый бюджет.
Вы можете спросить себя: « подождите минутку, что такое краулинговый бюджет? ”Бюджет сканирования — это то, что Google использует для эффективного сканирования и индексации страниц вашего сайта. Каким бы большим ни был Google, у них все еще есть ограниченное количество ресурсов, доступных для сканирования и индексации содержания ваших сайтов.
Если на вашем сайте всего несколько сотен URL-адресов, Google сможет легко сканировать и индексировать страницы вашего сайта.
Однако, если ваш сайт большой, например, сайт электронной коммерции, и у вас есть тысячи страниц с множеством автоматически сгенерированных URL-адресов, тогда Google может не сканировать все эти страницы, и вам будет не хватать большого потенциального трафика и видимости. .
Именно здесь становится важным расставить приоритеты, что, когда и сколько сканировать.
Google заявил, что « наличие большого количества URL с низкой добавленной стоимостью может негативно повлиять на сканирование и индексирование сайта. ”Здесь наличие файла robots.txt может помочь с факторами, влияющими на бюджет сканирования вашего сайта.
Вы можете использовать этот файл, чтобы управлять бюджетом сканирования вашего сайта, убедившись, что поисковые системы проводят свое время на вашем сайте как можно более эффективно (особенно если у вас большой сайт) и сканируют только важные страницы, не теряя времени. на таких страницах, как страницы входа, регистрации или благодарности.
Зачем нужен robots.txt?Прежде чем робот, такой как Googlebot, Bingbot и т. Д., Просканирует веб-страницу, он сначала проверит, существует ли на самом деле файл robots.txt, и, если он существует, они обычно будут следовать и соблюдать указания, найденные в этом файле. .
Файл robots.txt может стать мощным инструментом в арсенале любого оптимизатора поисковых систем, поскольку это отличный способ контролировать доступ роботов / сканеров поисковых систем к определенным областям вашего сайта.Имейте в виду, что вам нужно быть уверенным, что вы понимаете, как работает файл robots.txt, иначе вы случайно запретите роботу Googlebot или любому другому боту сканировать весь ваш сайт и не увидите его в результатах поиска!
Но если все сделано правильно, вы можете контролировать такие вещи, как:
- Блокировка доступа ко всем разделам вашего сайта (среда разработки, промежуточная среда и т. Д.)
- Предотвратить сканирование, индексирование или отображение страниц результатов внутреннего поиска ваших сайтов.
- Указание местоположения вашей карты сайта или карты сайта
- Оптимизация бюджета сканирования путем блокировки доступа к малоценным страницам (вход, спасибо, корзины покупок и т. Д.)
- Запрет индексирования определенных файлов на вашем веб-сайте (изображения, PDF-файлы и т. Д.)
Ниже приведены несколько примеров использования файла robots.txt на своем сайте.
Разрешить всем веб-сканерам / роботам доступ ко всему содержимому ваших сайтов:
Агент пользователя: * Disallow:
Блокировка всех веб-сканеров / ботов для доступа ко всему содержимому ваших сайтов:
Агент пользователя: * Disallow: /
Вы видите, как легко сделать ошибку при создании вашего сайта robots.txt, так как блокировка всего вашего сайта от просмотра отличается простой косой чертой в директиве disallow (Disallow: /).
Блокировка определенных поисковых роботов / роботов из определенной папки:
Пользовательский агент: Googlebot Disallow: /
Блокировка доступа поисковых роботов / роботов к определенной странице вашего сайта:
Агент пользователя: Disallow: /thankyou.html
Исключить всех роботов из части сервера:
Агент пользователя: * Disallow: / cgi-bin / Запретить: / tmp / Disallow: / junk /
Это пример того, что файл robots.txt на сайте theverge.com выглядит так:
Файл с примером можно посмотреть здесь: www.theverge.com/robots.txt
Вы можете увидеть, как The Verge использует свой файл robots.txt, чтобы специально вызвать новостного бота Google «Googlebot-News», чтобы убедиться, что он не сканирует эти каталоги на сайте.
Важно помнить, что если вы хотите убедиться, что бот не сканирует определенные страницы или каталоги на вашем сайте, вы вызываете эти страницы и / или каталоги в объявлениях Disallow в ваших файлах robots.txt, как в приведенных выше примерах.
Вы можете просмотреть, как Google обрабатывает файл robots.txt, в их руководстве по спецификациям robots.txt. Google имеет текущий максимальный размер файла robots.txt, максимальный размер для Google установлен на уровне 500 КБ, поэтому важно соблюдать помните о размере файла robots.txt на вашем сайте.
Как создать файл robots.txtСоздание файла robots.txt для вашего сайта — довольно простой процесс, но также легко сделать ошибку.Не позволяйте этому отвлекать вас от создания или изменения файла robots для вашего сайта. Эта статья от Google проведет вас через процесс создания файла robots.txt и должна помочь вам освоиться в создании собственного файла robots.txt.
Когда вы освоитесь с созданием или изменением файла robots вашего сайта, у Google есть еще одна отличная статья, в которой объясняется, как проверить файл robots.txt на вашем сайте, чтобы убедиться, что он правильно настроен.
Проверяем, есть ли у вас robots.txt файлЕсли вы плохо знакомы с файлом robots.txt или не уверены, есть ли он на вашем сайте, вы можете быстро проверить его. Все, что вам нужно сделать для проверки, это перейти в корневой домен вашего сайта и добавить /robots.txt в конец URL-адреса. Пример: www.yoursite.com/robots.txt
Если ничего не отображается, значит, у вас нет файла robots.txt для вашего сайта. Сейчас самое подходящее время, чтобы попробовать создать его для вашего сайта.
Передовой опыт:- Убедитесь, что все важные страницы доступны для сканирования, а контент, не представляющий реальной ценности при обнаружении в поиске, заблокирован.
- Не блокируйте свои сайты файлы JavaScript и CSS
- Всегда делайте быструю проверку своего файла, чтобы убедиться, что ничего случайно не изменилось
- Правильное использование заглавных букв в именах каталогов, подкаталогов и файлов
- Поместите файл robots.txt в корневой каталог своего веб-сайта, чтобы его можно было найти.
- Файл Robots.txt чувствителен к регистру, файл должен называться «robots.txt» (без других вариантов).
- Не используйте файл robots.txt для скрытия личной информации пользователя, так как она все равно будет видна
- Добавьте местоположение вашей карты сайта в файл robots.txt файл.
- Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно сканировать.
Если у вас есть поддомен или нескольких поддоменов на вашем сайте, вам понадобится файл robots.txt на каждом поддомене, а также в основном корневом домене. Это будет выглядеть примерно так: store.yoursite.com/robots.txt и yoursite.com/robots.txt.
Как упоминалось выше в разделе « лучших практик », важно помнить, что нельзя использовать роботов.txt, чтобы предотвратить сканирование и отображение конфиденциальных данных, таких как личная информация пользователя, в результатах поиска.
Причина этого в том, что другие страницы могут ссылаться на эту информацию, и если есть прямая обратная ссылка, она будет обходить правила robots.txt, и этот контент все равно может быть проиндексирован. Если вам нужно заблокировать действительно индексацию ваших страниц в результатах поиска, используйте другой метод, например, добавление защиты паролем или добавление метатега noindex к этим страницам.Google не может войти на сайт / страницу, защищенную паролем, поэтому они не смогут сканировать или индексировать эти страницы.
ЗаключениеВы можете немного нервничать, если никогда раньше не работали с файлом robots.txt, но будьте уверены, что его довольно просто использовать и настроить. Освоив все тонкости файла robots, вы сможете улучшить SEO своего сайта, а также помочь посетителям и роботам поисковых систем.
Настроив robots.txt, вы поможете роботам поисковых систем разумно расходовать свои бюджеты сканирования и гарантировать, что они не тратят свое время и ресурсы на сканирование страниц, сканирование которых не требуется. Это поможет им в организации и отображении контента вашего сайта в поисковой выдаче наилучшим образом, что, в свою очередь, означает, что вы будете более заметны.
Имейте в виду, что настройка файла robots.txt не обязательно требует много времени и усилий. По большей части это единовременная настройка, после которой вы можете внести небольшие корректировки и изменения, которые помогут лучше оформить свой сайт.
Я надеюсь, что методы, советы и предложения, описанные в этой статье, придадут вам уверенности при создании / настройке файла robots.txt на вашем сайте и в то же время помогут вам плавно пройти через этот процесс.
Майкл Макманус — руководитель практики Earned Media (SEO) в iProspect.
роботов.txt — Все, что нужно знать оптимизаторам поисковых систем
В этом разделе нашего руководства по директивам для роботов мы более подробно рассмотрим текстовый файл robots.txt и то, как его можно использовать для инструктирования поисковых роботов. Этот файл особенно полезен для , управляющего бюджетом сканирования и проверки того, что поисковые системы проводят время на вашем сайте эффективно и сканируют только важные страницы.
Для чего используется txt-файл robots?
Роботы .txt файл предназначен для того, чтобы сообщить сканерам и роботам, какие URL-адреса им не следует посещать на вашем веб-сайте. Это важно, чтобы помочь им избежать сканирования страниц низкого качества или застревания в ловушках сканирования, где потенциально может быть создано бесконечное количество URL-адресов, например, раздел календаря, который создает новый URL-адрес для каждого дня.
Как объясняет Google в своем руководстве по спецификациям robots.txt , формат файла должен быть простым текстом в кодировке UTF-8. Записи (или строки) файла должны быть разделены CR, CR / LF или LF.
Следует помнить о размере файла robots.txt, поскольку поисковые системы имеют свои собственные ограничения на максимальный размер файла. Максимальный размер для Google — 500 КБ.
Где должен находиться файл robots.txt?
Файл robots.txt всегда должен существовать в корне домена, например:
Этот файл относится к протоколу и полному домену, поэтому robots.txt на https://www.example.com не влияет на сканирование https: // www.example.com или https://subdomain.example.com ; у них должны быть собственные файлы robots.txt.
Когда следует использовать правила robots.txt?
В общем, веб-сайты должны стараться как можно реже использовать robots.txt для контроля сканирования. Лучшее решение — улучшить архитектуру вашего веб-сайта и сделать его чистым и доступным для поисковых роботов. Однако рекомендуется использовать файл robots.txt там, где это необходимо для предотвращения доступа сканеров к некачественным разделам сайта, если эти проблемы не могут быть устранены в краткосрочной перспективе.
Google рекомендует использовать robots.txt только при возникновении проблем с сервером или при проблемах с эффективностью сканирования, например, когда робот Google тратит много времени на сканирование неиндексируемых разделов сайта.
Вот несколько примеров страниц, сканирование которых может быть нежелательно:
- Страницы категорий с нестандартной сортировкой , так как это обычно создает дублирование со страницей основной категории
- Пользовательский контент , который нельзя модерировать
- Страницы с конфиденциальной информацией
- Страницы внутреннего поиска , так как таких страниц результатов может быть бесконечное количество, что создает неудобства для пользователя и расходует бюджет сканирования
Когда нельзя использовать robots.текст?
Файл robots.txt — полезный инструмент при правильном использовании, однако в некоторых случаях это не лучшее решение. Вот несколько примеров того, когда не следует использовать robots.txt для управления сканированием:
1. Блокировка Javascript / CSS
Поисковые системы должны иметь доступ ко всем ресурсам на вашем сайте, чтобы правильно отображать страницы, что является необходимой частью поддержания хорошего рейтинга. Файлы JavaScript, которые кардинально меняют взаимодействие с пользователем, но запрещены для сканирования поисковыми системами, могут привести к ручным или алгоритмным штрафам.
Например, если вы показываете рекламное межстраничное объявление или перенаправляете пользователей с помощью JavaScript, к которому поисковая система не может получить доступ, это может рассматриваться как маскировка, и рейтинг вашего контента может быть соответствующим образом скорректирован.
2. Блокировка параметров URL
Вы можете использовать robots.txt для блокировки URL-адресов, содержащих определенные параметры, но это не всегда лучший способ действий. Лучше обрабатывать их в консоли поиска Google, так как там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
Вы также можете поместить информацию во фрагмент URL ( / page # sort = price ), так как поисковые системы не сканируют его. Кроме того, если необходимо использовать параметр URL, ссылки на него могут содержать атрибут rel = nofollow, чтобы предотвратить попытки поисковых роботов получить к нему доступ.
3. Блокировка URL с обратными ссылками
Запрет URL-адресов в файле robots.txt предотвращает передачу ссылочного веса на веб-сайт. Это означает, что если поисковые системы не могут переходить по ссылкам с других веб-сайтов, поскольку целевой URL-адрес запрещен, ваш веб-сайт не получит авторитет, который передаются по этим ссылкам, и, как следствие, вы не сможете получить такой же высокий рейтинг в целом.
4. Получение деиндексированных проиндексированных страниц
Использование Disallow не приводит к деиндексированию страниц, и даже если URL-адрес заблокирован и поисковые системы никогда не сканировали страницу, запрещенные страницы все равно могут быть проиндексированы. Это связано с тем, что процессы сканирования и индексирования в значительной степени разделены.
5. Установка правил, игнорирующих поисковые роботы социальных сетей
Даже если вы не хотите, чтобы поисковые системы сканировали и индексировали страницы, вы можете захотеть, чтобы социальные сети имели доступ к этим страницам, чтобы можно было создать фрагмент страницы.Например, Facebook будет пытаться посетить каждую страницу, размещенную в сети, чтобы предоставить соответствующий фрагмент. Помните об этом при настройке правил robots.txt.
6. Блокировка доступа с тестовых сайтов или сайтов разработчиков
Использование robots.txt для блокировки всего промежуточного сайта — не лучшая практика. Google рекомендует не индексировать страницы, но разрешить их сканирование, но в целом лучше сделать сайт недоступным для внешнего мира.
7. Когда нечего блокировать
Некоторым веб-сайтам с очень чистой архитектурой не нужно блокировать поисковые роботы с каких-либо страниц.В этой ситуации совершенно приемлемо не иметь файла robots.txt и возвращать статус 404 по запросу.
Синтаксис и форматирование Robots.txt
Теперь, когда мы узнали, что такое robots.txt и когда его следует и не следует использовать, давайте взглянем на стандартизированный синтаксис и правила форматирования, которых следует придерживаться при написании файла robots.txt.
Комментарии
Комментарии — это строки, которые полностью игнорируются поисковыми системами и начинаются с # .Они существуют, чтобы вы могли писать заметки о том, что делает каждая строка вашего robots.txt, почему она существует и когда была добавлена. Как правило, рекомендуется задокументировать назначение каждой строки файла robots.txt, чтобы ее можно было удалить, когда она больше не нужна, и не изменять, пока она еще необходима.
Указание агента пользователя
Блок правил может быть применен к определенным пользовательским агентам с помощью директивы « User-agent ». Например, если вы хотите, чтобы определенные правила применялись к Google, Bing и Яндексу; но не Facebook и рекламные сети, этого можно достичь, указав токен пользовательского агента, к которому применяется набор правил.
У каждого поискового робота есть собственный токен агента пользователя, который используется для выбора совпадающих блоков.
Поисковые роботыбудут следовать наиболее конкретным правилам пользовательского агента, установленным для них с именами, разделенными дефисами, а затем будут использовать более общие правила, если точное соответствие не найдено. Например, Googlebot News будет искать соответствие « googlebot-news «, затем « googlebot «, затем « * «.
Вот некоторые из наиболее распространенных токенов пользовательских агентов, с которыми вы можете столкнуться:
- * — Правила применяются к каждому боту, если нет более конкретного набора правил
- Googlebot — Все сканеры Google
- Googlebot-News — Поисковый робот для новостей Google
- Googlebot-Image — сканер изображений Google
- Mediapartners-Google — поисковый робот Google AdSense
- Bingbot — сканер Bing
- Яндекс — поисковый робот Яндекса
- Baiduspider — гусеничный робот Baidu
- Facebot — поисковый робот Facebook
- Twitterbot — поисковый робот Twitter
Этот список токенов пользовательских агентов ни в коем случае не является исчерпывающим, поэтому, чтобы узнать больше о некоторых из сканеров, взгляните на документацию, опубликованную Google , Bing , Yandex , Baidu , Facebook и Twitter .
При сопоставлении токена пользовательского агента с блоком robots.txt регистр не учитывается. Например. «Googlebot» будет соответствовать токену пользовательского агента Google «Googlebot».
URL с сопоставлением с шаблоном
У вас может быть определенная строка URL-адреса, которую вы хотите заблокировать от сканирования, поскольку это намного эффективнее, чем включение полного списка полных URL-адресов, которые следует исключить в файле robots.txt.
Чтобы помочь вам уточнить пути URL-адресов, вы можете использовать символы * и $. Вот как они работают:
- * — Это подстановочный знак, представляющий любое количество любого символа.Он может быть в начале или в середине пути URL, но не обязателен в конце. В строке URL-адреса можно использовать несколько подстановочных знаков, например, « Disallow: * / products? * Sort = ». Правила с полными путями не должны начинаться с подстановочного знака.
- $ — Этот символ обозначает конец строки URL-адреса, поэтому « Disallow: * / dress $ » будет соответствовать только URL-адресам, заканчивающимся на « / dress », а не « / dress? Parameter ».
Стоит отметить, что robots.txt чувствительны к регистру, что означает, что если вы запретите URL-адреса с параметром « search » (например, « Disallow: *? search = »), роботы все равно могут сканировать URL-адреса с разными заглавными буквами, например «? Search = ничего ».
Правила директивы сопоставляются только с путями URL и не могут включать протокол или имя хоста. Косая черта в начале директивы совпадает с началом пути URL. Например. « Disallow: / start » будет соответствовать www.example.com/starts .
Если вы не добавите начало директивы, совпадающей с / или * , она ни с чем не будет соответствовать. Например. « Disallow: start » никогда ничего не совпадет.
Чтобы помочь наглядно представить, как работают разные правила для URL, мы собрали для вас несколько примеров:
Robots.txt Ссылка на карту сайта
Директива карты сайта в файле robots.txt сообщает поисковым системам, где найти карту сайта XML, которая помогает им обнаруживать все URL-адреса на веб-сайте.Чтобы узнать больше о файлах Sitemap, ознакомьтесь с нашим руководством по аудиту карт сайта и расширенной настройке .
При включении файлов Sitemap в файл robots.txt следует использовать абсолютные URL-адреса (например, https://www.example.com/sitemap.xml ) вместо относительных URL (например, /sitemap.xml ). Это также Стоит отметить, что карты сайта не обязательно должны располагаться в одном корневом домене, они также могут размещаться во внешнем домене.
Поисковые системы обнаружат и могут сканировать карты сайта, перечисленные в вашем файле robots.txt, однако эти карты сайта не будут отображаться в Google Search Console или Bing Webmaster Tools без отправки вручную.
Robots.txt Блокирует
Правило «запрета» в файле robots.txt может использоваться разными способами для различных пользовательских агентов. В этом разделе мы рассмотрим некоторые из различных способов форматирования комбинаций блоков.
Важно помнить, что директивы в файле robots.txt — это всего лишь инструкции. Вредоносные сканеры проигнорируют ваших роботов.txt и сканировать любую часть вашего сайта, которая является общедоступной, поэтому запрет не следует использовать вместо надежных мер безопасности.
Несколько блоков пользовательского агента
Вы можете сопоставить блок правил с несколькими пользовательскими агентами, указав их перед набором правил, например, следующие запрещающие правила будут применяться как к Googlebot, так и к Bing в следующем блоке правил:
Пользовательский агент: googlebot
Пользовательский агент: bing
Запрещено: / a
Расстояние между блоками директив
Google игнорирует пробелы между директивами и блоками.В этом первом примере будет выбрано второе правило, даже если есть пробел, разделяющий две части правила:
[код]
User-agent: *
Disallow: / disallowed /Запретить: / test1 / robots_excluded_blank_line
[/ code]
Во втором примере робот Googlebot-mobile унаследует те же правила, что и Bingbot:
[код]
Пользовательский агент: googlebot-mobileUser-agent: bing
Disallow: / test1 / deepcrawl_excluded
[/ code]
Блоки раздельные, комбинированные
Объединяются несколько блоков с одним и тем же пользовательским агентом.Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « / b » и « / a ».
User-agent: googlebot
Disallow: / bUser-agent: bing
Disallow: / aUser-agent: googlebot
Disallow: / a
Robots.txt Разрешить
«Разрешающее» правило robots.txt явно дает разрешение на сканирование определенных URL. Хотя это значение по умолчанию для всех URL-адресов, это правило можно использовать для перезаписи запрещающего правила.Например, если « / location » не разрешено, вы можете разрешить сканирование « / locations / london » с помощью специального правила « Allow: / locations / london ».
Robots.txt Приоритизация
Когда к URL-адресу применяется несколько разрешающих и запрещающих правил, применяется самое длинное правило сопоставления. Давайте посмотрим, что произойдет с URL « / home / search / shirts » при следующих правилах:
Disallow: / home
Allow: * search / *
Disallow: * рубашки
В этом случае сканирование URL разрешено, потому что правило разрешения содержит 9 символов, а правило запрета — только 7.Если вам нужно разрешить или запретить конкретный URL-путь, вы можете использовать *, чтобы сделать строку длиннее. Например:
Disallow: ******************* / рубашки
Если URL-адрес соответствует и разрешающему правилу, и запрещающему правилу, но правила имеют одинаковую длину, будет выполнено запрещение. Например, URL « / search / shirts » будет запрещен в следующем сценарии:
Disallow: / search
Allow: * рубашки
Роботы.txt Директивы
Директивы уровня страницы (которые мы рассмотрим позже в этом руководстве) — отличные инструменты, но проблема с ними заключается в том, что поисковые системы должны сканировать страницу, прежде чем смогут прочитать эти инструкции, что может потребовать бюджета сканирования.
Директивы Robots.txt могут помочь снизить нагрузку на бюджет сканирования, поскольку вы можете добавлять директивы непосредственно в файл robots.txt, а не ждать, пока поисковые системы просканируют страницы, прежде чем принимать меры. Это решение намного быстрее и проще в использовании.
Следующие директивы robots.txt работают так же, как директивы allow и disallow, в том, что вы можете указать подстановочные знаки ( * ) и использовать символ $ для обозначения конца строки URL.
Robots.txt NoIndex
Robots.txt noindex — полезный инструмент для управления индексированием поисковой системы без использования краулингового бюджета. Запрещение страницы в robots.txt не означает, что она удаляется из индекса, поэтому для этой цели гораздо эффективнее использовать директиву noindex.
Google официально не поддерживает noindex в robots.txt, и вам не следует полагаться на него, потому что, хотя он работает сегодня, он может не работать завтра. Этот инструмент может быть полезен и должен использоваться в качестве краткосрочного исправления в сочетании с другими долгосрочными элементами управления индексами, но не в качестве критически важной директивы. Взгляните на тесты, проведенные ohgm и Stone Temple , которые доказывают, что функция работает эффективно.
Вот пример использования robots.txt noindex:
[код]
User-agent: *
NoIndex: / directory
NoIndex: / *? * Sort =
[/ code]
Помимо noindex, Google в настоящее время неофициально подчиняется нескольким другим директивам индексирования, когда они помещаются в robots.txt. Важно отметить, что не все поисковые системы и сканеры поддерживают эти директивы, а те, которые поддерживают, могут перестать поддерживать их в любой момент — не следует полагаться на их постоянную работу.
Обычные роботы.txt, проблемы
Есть несколько ключевых проблем и соображений, касающихся файла robots.txt и его влияния на производительность сайта. Мы нашли время, чтобы перечислить некоторые ключевые моменты, которые следует учитывать при работе с robots.txt, а также некоторые из наиболее распространенных проблем, которых вы, надеюсь, можете избежать.
- Иметь запасной блок правил для всех ботов — Использование блоков правил для определенных строк пользовательского агента без резервного блока правил для каждого другого бота означает, что ваш сайт в конечном итоге встретит бота, у которого нет никаких наборов правил для следить.
- I t Важно, чтобы robots.txt поддерживался в актуальном состоянии. — Относительно распространенная проблема возникает, когда robots.txt устанавливается на начальной стадии разработки веб-сайта, но не обновляется по мере роста веб-сайта, а это означает, что потенциально полезные страницы запрещены.
- Помните о перенаправлении поисковых систем через запрещенные URL-адреса — Например, / продукт > / запрещенный > / категория
- Чувствительность к регистру может вызвать множество проблем — Веб-мастера могут ожидать, что какой-то раздел веб-сайта не будет сканироваться, но эти страницы могут сканироваться из-за альтернативного регистра i.е. «Disallow: / admin» существует, но поисковые системы сканируют « / ADMIN ».
- Не запрещать URL-адреса с обратными ссылками — Это предотвращает переход PageRank на ваш сайт от других пользователей, которые ссылаются на вас.
- Задержка сканирования может вызвать проблемы с поиском — Директива « crawl-delay » заставляет сканеры посещать ваш веб-сайт медленнее, чем им хотелось бы, а это означает, что ваши важные страницы могут сканироваться реже, чем это необходимо. Эта директива не соблюдается Google или Baidu, но поддерживается Bing и Яндексом.
- Убедитесь, что robots.txt возвращает код состояния 5xx только в том случае, если весь сайт не работает. — Возвращение кода состояния 5xx для /robots.txt указывает поисковым системам, что веб-сайт закрыт на техническое обслуживание. Обычно это означает, что они попытаются сканировать веб-сайт еще раз позже.
- Disallow Robots.txt переопределяет инструмент удаления параметров. — Помните, что ваши правила robots.txt могут переопределять обработку параметров и любые другие подсказки по индексации, которые вы могли дать поисковым системам.
- Разметка окна поиска дополнительных ссылок будет работать с заблокированными страницами внутреннего поиска. — Страницы внутреннего поиска на сайте не должны сканироваться, чтобы разметка окна поиска дополнительных ссылок работала.
- Запрещение перенесенного домена повлияет на успех миграции — Если вы запретите перенесенный домен, поисковые системы не смогут отслеживать перенаправления со старого сайта на новый, поэтому миграция маловероятна. быть успешным.
Роботы для тестирования и аудита.txt
Учитывая, насколько опасным может быть файл robots.txt, если содержащиеся в нем директивы не обрабатываются должным образом, есть несколько различных способов проверить его, чтобы убедиться, что он настроен правильно. Взгляните на это руководство о том, как проверять URL-адреса, заблокированные файлом robots.txt , а также на эти примеры:
- Используйте DeepCrawl — Запрещенные страницы и Запрещенные URL (не просканированные) Отчеты могут показать вам, какие страницы блокируются поисковыми системами вашими роботами.txt файл.
- Используйте Google Search Console — с помощью инструмента GSC robots.txt тестера вы можете увидеть последнюю кэшированную версию страницы, а также с помощью инструмента Fetch and Render просмотреть рендеры от пользовательского агента Googlebot, а также пользовательский агент браузера. На заметку: GSC работает только с пользовательскими агентами Google, и можно тестировать только отдельные URL-адреса.
- Попробуйте объединить выводы обоих инструментов, выбрав выборочную проверку запрещенных URL-адресов, которые DeepCrawl пометил в роботах GSC.txt tester, чтобы уточнить конкретные правила, которые приводят к запрету.
Monitoring Robots.txt Changes
Когда над сайтом работает много людей и возникают проблемы, которые могут возникнуть, если хотя бы один символ неуместен в файле robots.txt, постоянный мониторинг вашего robots.txt имеет решающее значение. Вот несколько способов проверить наличие проблем:
- Проверьте Google Search Console, чтобы увидеть текущий файл robots.txt, который использует Google. Иногда robots.txt может быть доставлен условно на основе пользовательских агентов, поэтому это единственный способ увидеть, что именно видит Google.
- Проверьте размер файла robots.txt, если вы заметили существенные изменения, чтобы убедиться, что он не превышает установленный Google предел в 500 КБ.
- Перейдите к отчету о статусе индекса в Google Search Console в расширенном режиме, чтобы проверить изменения файла robots.txt с количеством запрещенных и разрешенных URL-адресов на вашем сайте.
- Запланируйте регулярное сканирование с помощью DeepCrawl, чтобы постоянно отслеживать количество запрещенных страниц на вашем сайте, чтобы вы могли отслеживать изменения.
Далее: Директивы по роботам на уровне URL
Автор
Рэйчел Костелло
Рэйчел Костелло — технический менеджер по поисковой оптимизации и контенту DeepCrawl. Чаще всего она пишет и говорит обо всем, что касается SEO.
Файлы Robots.txt
Файл /robots.txt — это текстовый файл, который инструктирует автоматизированных веб-ботов о том, как сканировать и / или индексировать веб-сайт. Веб-группы используют их для предоставления информации о том, какие каталоги сайта следует сканировать, а какие нет, как быстро следует обращаться к контенту и какие боты приветствуются на сайте.
Как должен выглядеть мой файл robots.txt?
Пожалуйста, обратитесь к протоколу robots.txt (Внешняя ссылка) для получения подробной информации о том, как и где создать свой robots.txt. Ключевые моменты, о которых следует помнить:
- Файл должен находиться в корне домена, и каждому поддомену нужен свой собственный файл.
- Протокол robots.txt чувствителен к регистру.
- Легко случайно заблокировать сканирование всего
-
Disallow: /означает запретить все -
Disallow:означает ничего не запрещать, тем самым разрешая все -
Разрешить: /означает разрешить все -
Разрешить:означает ничего не разрешать, таким образом запрещая все
-
- Инструкции в robots.txt — это руководство для ботов, а не обязательные требования.
Как мне оптимизировать свой robots.txt для Search.gov?
Задержка сканирования
Файл robots.txt может указывать директиву «задержки сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта. Например, задержка сканирования 10 указывает, что поисковый робот не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней на однократное индексирование сайта. Мы рекомендуем задержку сканирования в 2 секунды для нашего пользовательского агента usasearch и установку более высокой задержки сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт. В файле robots.txt это будет выглядеть так:
Агент пользователя: usasearch
Задержка сканирования: 2
Пользовательский агент: *
Задержка сканирования: 10
XML-файлы Sitemap
В вашем файле robots.txt также должна быть указана одна или несколько ваших XML-карт сайта.Например:
Карта сайта: https://www.exampleagency.gov/sitemap.xml
Карта сайта: https://www.exampleagency.gov/independent-subsection-sitemap.xml
- Отображает только карты сайта для домена, в котором находится файл robots.txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.
Разрешить только тот контент, который должен быть доступен для поиска
Мы рекомендуем запретить использование любых каталогов или файлов, которые не должны быть доступны для поиска.Например:
Запретить: / archive /
Disallow: / новости-1997 /
Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите использование каталога после того, как он был проиндексирован поисковой системой, это может не привести к удалению этого содержания из индекса. Чтобы запросить удаление, вам нужно будет открыть инструменты для веб-мастеров поисковой системы.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода без сканирования, такого как ссылка с другого сайта или ваша карта сайта.Чтобы гарантировать, что данная страница недоступна для поиска, установите на этой странице метатег robots.
Настройка параметров для разных ботов
Вы можете установить разные разрешения для разных ботов. Например, если вы хотите, чтобы мы проиндексировали ваш заархивированный контент, но не хотите, чтобы Google или Bing индексировали его, вы можете указать это:
Агент пользователя: usasearch
Задержка сканирования: 2
Разрешить: / archive /
Пользовательский агент: *
Задержка сканирования: 10
Запретить: / архив /
Контрольный список Robots.txt
1.В корневом каталоге сайта создан файл robots.txt ( https://exampleagency.gov/robots.txt )
2.