
Семантическое ядро сайта – как правильно его составить и не допустить ошибок?
Что такое семантическое ядро?
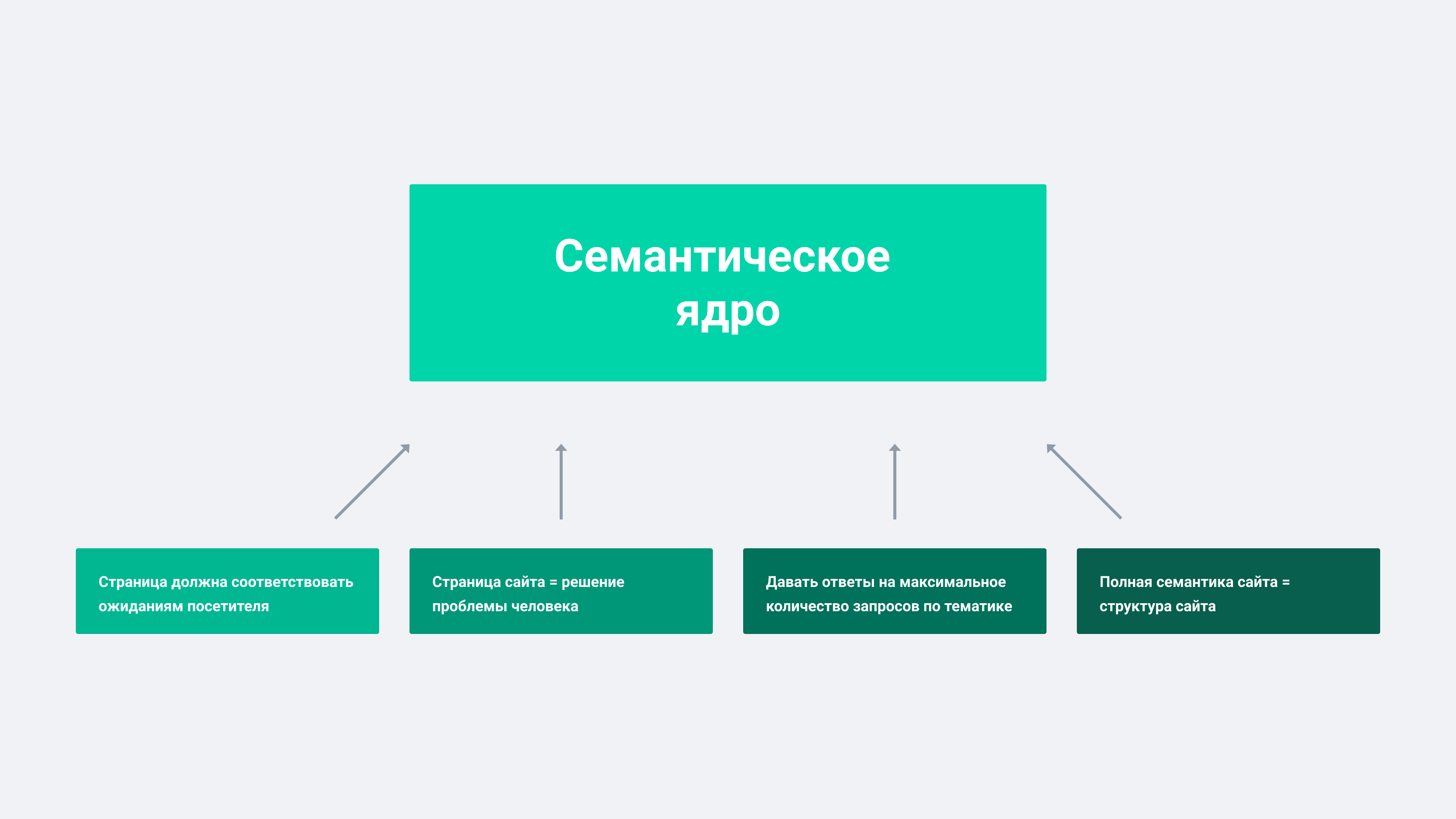
Семантическое ядро – это набор поисковых фраз и слов, по которым осуществляется продвижение сайта. Эти поисковые слова и фразы помогают роботам определить тематику страницы или всего сервиса, то есть узнать, чем занимается компания.
В русском языке семантикой называется раздел науки о языке, занимающийся изучением смыслового наполнения лексических единиц языка. Применительно к поисковой оптимизации это означает, что семантическое ядро – это смысловое наполнение ресурса. Оно помогает определиться, какую информацию доносить до пользователей и в каком ключе. Поэтому семантика – это фундамент, основа всего SEO.
Для чего нужно семантическое ядро сайта и как его использовать?
- Правильное семантическое ядро необходимо, чтобы точно рассчитать стоимость продвижения.

- Семантика – это вектор построения внутренней seo-оптимизации: подбираются наиболее релевантные запросы для каждой услуги или товара, чтобы пользователи и поисковые роботы лучше их находили.
- На его основе создаются структура сайта и тексты для тематических страниц.
- Ключи из семантики используются для написания сниппетов (кратких описаний страницы).
Вот семантическое ядро – пример его составления в компании SEO.RU для сайта строительной компании:
Оптимизатор собирает семантику, разбирает ее по логическим блокам, выясняет число их показов и на основе стоимости запросов в топе Яндекса и Google рассчитывает общую стоимость продвижения.
Разумеется, при подборе семантического ядра учитывается специфика работы компании: например, если бы компания не проектировала и не строила дома из клееного бруса, то соответствующие запросы мы бы удалили и не использовали в дальнейшем. Поэтому обязательный этап работы с семантикой – согласование его с заказчиком: лучше него никто не знает особенности работы компании.
Поэтому обязательный этап работы с семантикой – согласование его с заказчиком: лучше него никто не знает особенности работы компании.
Виды ключевых слов
Есть несколько параметров, по которым классифицируются ключевые запросы.
- По частотности
- высокочастотные – слова и фразы с частотой от 1000 показов в месяц;
- среднечастотные – до 1000 показов в месяц;
- низкочастотные – до 100 показов.
- По типу:
- геозависимые и негеозависимые – привязанные к региону продвижения и непривязанные;
- информационные – по ним пользователь получает какую-то информацию.
- брендовые – содержат в себе название продвигаемого бренда;
- транзакционные – подразумевающие действие от пользователя (купить, скачать, заказать) и так далее.
- Другие виды – те, которые сложно отнести к какому-либо типу: допустим, ключ «профилированный брус». Вбивая такой запрос в поисковик, пользователь может подразумевать что угодно: покупку бруса, свойства, сравнения с другими материалами и прочее.
Сбор частотности по ключевым словам помогает узнать, что чаще всего запрашивают пользователи. Но высокочастотный запрос – необязательно запрос с высокой конкурентностью, и составление семантики с высокой частотностью и низкой конкурентностью – один из главных аспектов в работе со смысловым ядром.

Как собрать семантическое ядро для сайта?
Как собрать семантическое ядро для сайта?
Пример сбора семантики в KeyCollector
- Путем анализа сайтов-конкурентов (в SEMrush, SerpStat можно посмотреть семантическое ядро конкурентов):
Пример сбора семантики в SerpStat
Процесс составления семантического ядра
Собранные запросы – это еще не семантическое ядро, тут надо еще зерна от плевел отделить, чтобы все запросы были релевантны услугам клиента.
Чтобы составить семантическое ядро, запросы нужно кластеризовать (разбить на блоки по логике оказания услуги). Делать это можно с помощью программ (например, KeyAssort или TopSite) – особенно, если семантика объемная. Или вручную оценивать и перебирать весь список, удалять неподходящие запросы.
Затем отправить клиенту и уточнить, есть ли ошибки.
Готовое семантическое ядро – дорожка из желтого кирпича к контент-плану, к статьям в блоге, текстам для карточек товаров, новостям компании и так далее. Это таблица с потребностями аудитории, которые вы можете удовлетворить, используя свой сайт.
- Распределите ключи по страницам.
- Используйте ключевые запросы в метатегах <title>, <description>, <h> (особенно в заголовке первого уровня h2).
- Вставьте ключи в тексты для страниц. Это один из белых методов оптимизации, но тут важно не переборщить: за переспам можно попасть под фильтры поисковых систем.
- Оставшиеся поисковые запросы и те, которые не подходят ни под один раздел, сохраните под названием «О чем еще написать». В дальнейшем можно использовать их для информационных статей.
- И помните: ориентироваться надо на запросы и интересы пользователей, поэтому пытаться впихнуть все ключи в один текст бессмысленно
Сбор семантического ядра для сайта: основные ошибки
- Отказ от высококонкурентных ключей. Да, возможно, в топ по запросу «купить профилированный брус» вы не попадете (и это не помешает вам успешно продавать свои услуги), но включать в тексты его все равно нужно.
- Отказ от низкочастотки. Ошибочно это по той же причине, что и отказ от высококонкурентных запросов.
- Создание страниц под запросы и ради запросов.
- Абсолютное и безусловное доверие к софту. Без seo-программ не обойтись, но ручной анализ и проверка данных необходимы. И никакая программа пока не может оценить отрасль, уровень конкуренции и распределить ключи без ошибок.
- Ключи – наше всё. Нет, наше всё – удобный, понятный сайт и полезный контент. Ключи нужны любому тексту, но если текст плохой, то ключи не спасут.
Правильно собрать семантическое ядро для продвижения сайта — SEO на vc.ru
{«id»:61162,»url»:»https:\/\/vc.ru\/seo\/61162-pravilno-sobrat-semanticheskoe-yadro-dlya-prodvizheniya-sayta»,»title»:»\u041f\u0440\u0430\u0432\u0438\u043b\u044c\u043d\u043e \u0441\u043e\u0431\u0440\u0430\u0442\u044c \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0435 \u044f\u0434\u0440\u043e \u0434\u043b\u044f \u043f\u0440\u043e\u0434\u0432\u0438\u0436\u0435\u043d\u0438\u044f \u0441\u0430\u0439\u0442\u0430″,»services»:{«facebook»:{«url»:»https:\/\/www.
 ru\/seo\/61162-pravilno-sobrat-semanticheskoe-yadro-dlya-prodvizheniya-sayta»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/seo\/61162-pravilno-sobrat-semanticheskoe-yadro-dlya-prodvizheniya-sayta»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}40 851 просмотров
Семантическое ядро — основа поискового продвижения. Если допустить ошибки на этом этапе, дальнейшая работа по SEO пойдёт под откос. Это руководство поможет собрать семантику для проекта любого масштаба и ничего не упустить.
Этапы работы
Сбор семантического ядра состоит из четырёх последовательных этапов:
*Маркером (или маркерным запросом) называют слово или словосочетание наиболее точно отражающее суть конкретной страницы сайта.
 Обычно в качестве основного «маркерного» запроса для страницы берётся содержимое заголовка h2. У одной страницы может быть несколько маркерных запросов.
Обычно в качестве основного «маркерного» запроса для страницы берётся содержимое заголовка h2. У одной страницы может быть несколько маркерных запросов.Получение маркеров и работа с ними
На рисунке изображена последовательность действий по подбору и обработке маркеров:
Последовательность подбора и обработки маркеров
Собираем список заголовков h2
Собирать заголовки вручную долго и муторно, особенно если сайт состоит из тысяч страниц.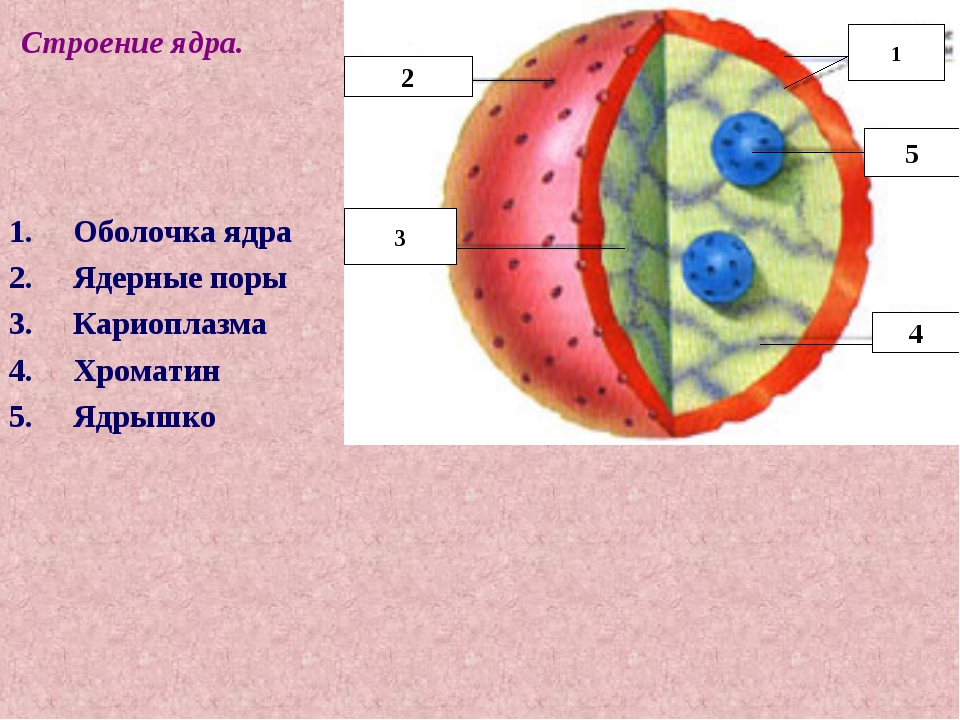 Процесс можно автоматизировать и ускорить с помощью «пауков».
Процесс можно автоматизировать и ускорить с помощью «пауков».
«Пауки» — программы, которые эмулируют роботов поисковых систем: обходят все страницы на сайте, получают список URL-адресов и заголовков h2. Список экспортируется в любой удобный формат, например, в Excel. Вот ссылки на наиболее популярные программы:
Корректируем заголовки
Убедитесь, что собранные маркерные запросы обладают частотностью. Если частотность вызывает сомнения, сверьтесь с «Вордстатом», а потом скорректируйте запрос или найдите более частотный.
Не используйте несколько интентов (потребностей пользователей) для продвижения на одной странице. Например, на сайте магазина мебели есть раздел «Кресла и стулья». Но пользователи так не ищут, поэтому эффективней создать два отдельных раздела «Кресла» и «Стулья».
Не проектируйте структуру сайта так, чтобы в разных разделах дублировались одинаковые страницы, как на скриншоте ниже.
Страница «Смесители» дублируется в разделах «Ванная» и «Душ»
В примере выше для раздела «Душ» можно оставить ссылку на раздел «Смесители для ванны и душа», но она должна вести на страницу: http://www. domain.ru/catalog/vannaya/smesiteli-dlya-vanny-i-dusha/.
domain.ru/catalog/vannaya/smesiteli-dlya-vanny-i-dusha/.
Не создавайте отдельные страницы под синонимичные группы запросов вроде «дешевые матрасы», «недорогие матрасы». Они могут быть восприняты поисковыми системами как нечёткие дубли. Это может привести к проблемам с индексацией сайта: часть страниц будет исключена из поиска.
Чтобы определить, какие запросы можно продвигать на одной странице, а какие — нет, воспользуйтесь сервисом кластеризации*.
*Кластеризация — принцип группировки запросов на основании общего числа URL в поисковой выдаче.

Суть кластеризации в том, чтобы изучить, как распределены запросы у сайтов, уже находящихся в верхней десятке поисковых систем. Для определения совместимости интентов идеально подойдёт такой сервис. А про методы кластеризации подробнее расскажу ниже.
Расширяем заголовки за счёт интентов и дополнительных слов
Когда мы получили маркеры, дальше собираем ключевые слова с помощью «Вордстата». Стоит учесть, что «Вордстат» отображает только 41 страницу со статистикой по запросу.
Если мы имеем дело с частотным маркером (например, «Диван»), то есть вероятность, что весь пул запросов мы не охватим.
Как видно, запросы ещё есть, но на следующей странице результаты не отображаются
Поэтому стоит подготовить список уточняющих запросов, характерных для конкретной тематики: например, «диван купить», «диван цена» и так далее.
Готовые тематические подборки можно найти на этой странице.
Получить маркеры, сцепленные с дополнительными словами, можно при помощи формулы =СЦЕПИТЬ(A1;» «;$E$1).
Маркеры не должны содержать символы .
 ,»?!()- и другие знаки. Замените символы в Excel на пробел, используя сочетание клавиш Ctrl и H, а затем проверьте список маркерных запросов на орфографию.
,»?!()- и другие знаки. Замените символы в Excel на пробел, используя сочетание клавиш Ctrl и H, а затем проверьте список маркерных запросов на орфографию.Собираем заголовки с сайтов конкурентов
Проанализируйте сайты конкурентов, находящиеся в топе выдачи по интересующим вас запросам. В ходе анализа особенно интересно получить заголовки «теговых страниц», которые заточены под конкретный пользовательский интент.
Заголовки сайтов-конкурентов можно просканировать «пауками», о которых говорилось выше (например, Screaming frog SEO spider).
Этот подход поможет расширить структуру сайта и подобрать новые запросы для семантического ядра.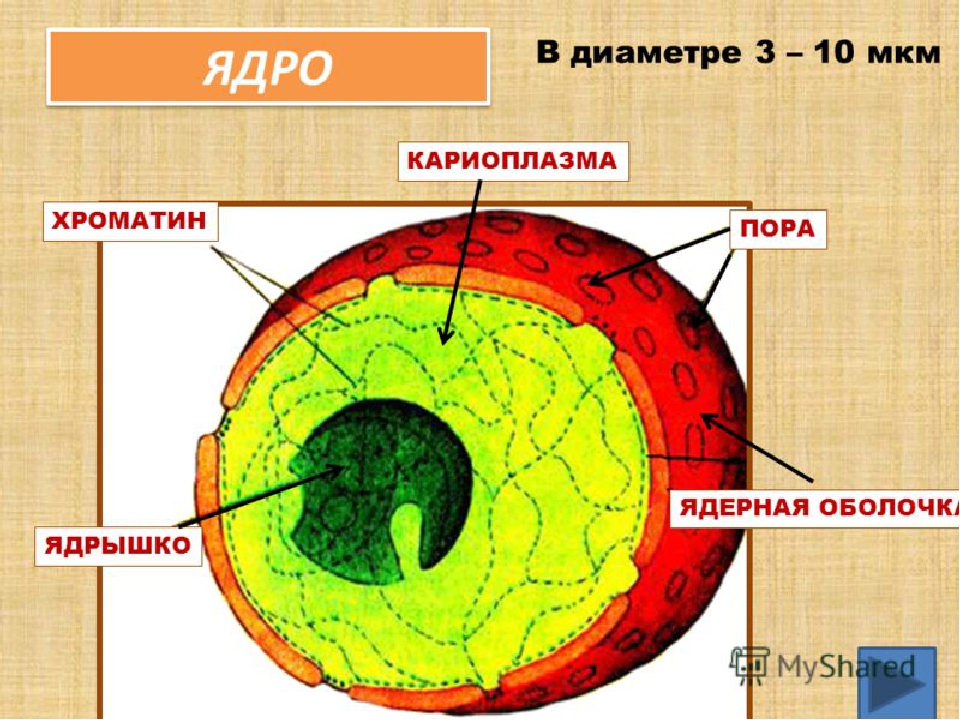
Нормализуем запросы
Под нормализацией понимается определение наиболее частотной формы запроса. Это нужно, чтобы не упустить запросы с высокой частотой, приносящие больше трафика на сайт.
Если запросов немного, они состоят из двух слов, то определить наиболее частотный запрос можно в «Вордстате» при помощи операторов: «[!поисковый !запрос]».
Если запрос состоит из трех и более слов, а запросов больше ста, проверка вручную займёт много времени. Чтобы автоматически выявлять наиболее частотную словоформу, я сделал специальный парсер на базе А-parser.
Чтобы автоматически выявлять наиболее частотную словоформу, я сделал специальный парсер на базе А-parser.
Логика работы парсера в следующем:
- в «Вордстате» запросы выводятся в порядке убывания частоты;
- каждый запрос, подаваемый на вход, заключается в кавычки, тем самым анализируются все словоформы запроса;
- в качестве результата берётся первый запрос из левой колонки, то есть наиболее частотная из словоформ.
Как видно из примера ниже, наиболее частотной словоформой является «купить диван», что подтверждается точной частотой запросов из примеров выше.
Когда мы провели работы, описанные в разделе, у нас получается список маркерных запросов, удовлетворяющий следующим критериям:
- нет опечаток;
- нет символов и знаков препинания;
- все маркерные запросы частотные;
- часть маркеров содержит дополнительные слова и словосочетания, характерные для конкретной тематики;
- в списке присутствуют наиболее частотные словоформы запросов;
Парсинг запросов
Список маркеров, который мы получили, нужно расширить дополнительными словами — «хвостами». Это поможет нам максимально охватить семантику в поисковой нише, в которой продвигается сайт. Дополнительные слова можно взять из источников, указанных на схеме ниже.
Наиболее популярные источники для парсинга поисковых запросов
Коротко разберу особенности некоторых источников.
Поисковые подсказки «Яндекса» и Google
Основное преимущество подсказок в том, что их база намного больше, чем база того же «Вордстата».
В подсказки попадают запросы, обладающие частотой, которые реально запрашивают пользователи. В «Вордстате» же есть доля мусорных и автосгенерированных запросов, не обладающих реальным поисковым спросом.
Подсказки в «Яндексе» можно получать в формате json. В этом случае каждой поисковой подсказке присваивается определенный тип.
Ниже приведены наиболее часто встречающиеся типы подсказок:
- B и T обозначают «обычные» подсказки;
- W — это перестановка слов;
- In — автодополнение;
- Pb — порно-подсказка;
- Nav — навигационный запрос;
- Rich — расширенная подсказка-сниппет, появляется для «Википедии»;
- Tail_word — как правило, означает, что подсказка дополняется не с конца, а с начала;
- Art, Fast_w, Fresh_console, Fast — неизвестные типы.
Например, после сбора можно сразу удалить все подсказки с типом «In», что существенно уменьшит число мусорных запросов. Для сбора подсказок с указанием типов я использую парсер.
«Яндекс.Вебмастер»
В «Вебмастере» есть раздел, в котором можно получить рекомендованные поисковые запросы. Достаточно нажать на кнопку и через некоторое время список будет доступен для скачивания.
Рекомендованные поисковые запросы в «Яндекс.Вебмастере»
«Яндекс.Метрика» и Google Analytics
Часть запросов можно выгрузить из отчёта «Яндекс.Метрики»: «Стандартные отчеты» → «Источники» → «Поисковые запросы».
Выгрузка поисковых запросов из «Яндекс.Метрики»
В Google Analytics также есть данные о запросах, но с 2011 года Google начал шифровать запросы пользователей, поэтому собрать большой объём информации из данного источника не получится.
Выгрузка поисковых запросов из Google Analytics
Готовые базы ключевых слов
На рынке есть готовые базы ключевых слов для различных тематик. Например:
У готовых баз есть два недостатка: они обновляются нерегулярно и содержат много мусорной и автосгенерированной семантики.
Тем не менее предпочтительнее использовать базу «Букварикс». Как показали исследования коллег из Rush Analytics, она содержит минимум мусорных запросов и к тому же бесплатная.
SaaS-решения
SaaS-решения (software as a service) помогают выгружать списки запросов, по которым находится в выдаче ваш сайт или сайты конкурентов. Ниже список наиболее популярных сервисов:
Когда получим «хвосты» для маркерных запросов, нужно объединить данные из всех источников в один список и избавиться от дублей.
Для автоматизации сбора запросов можно воспользоваться программами:
Чистка запросов
Удаляем мусорные фразы
В процессе сбора хвостов в списки неизбежно попадают мусорные запросы. Избавится от них можно с помощью функции «Стоп слова» программы Key collector.
В качестве стоп-слов можно использовать готовые тематические подборки.
С помощью функции «Анализ групп» можно найти и удалить нецелевую семантику.
Удаление низкочастотных запросов
Часть собранных запросов может быть автосгенерированными или низкочастотными (менее трех запросов). Если такие запросы попадут в семантическое ядро, то с высокой вероятностью для них будут созданы отдельные страницы на сайте. Значимого объема трафика они не принесут, но будут отнимать краулинговый бюджет.
Краулинговый бюджет — количество страниц, которые поисковый бот может обойти за период времени.
Нижний порог частоты запроса определяется отдельно для каждой тематики. Брать в работу микро- и низкочастотные запросы стоит лишь в исключительных ситуациях (например, если продукт супермаржинальный). Пример: разработка и внедрение ERP-систем, продажа нефтеперерабатывающего оборудования и так далее.
Для определения точной частоты запросов можно воспользоваться одной из программ — Key collector или A-parser, либо сервисами:
После чистки вы получите список целевых запросов, обладающих достаточной частотой.
Распределение запросов и кластеризация
Основная идея кластеризации — выяснить, как распределены запросы у сайтов, находящихся в первой десятке поисковой выдачи.
Наиболее широкое распространение данная методология получила около четырёх лет назад. Правда, некоторые оптимизаторы до сих пор предпочитают распределять запросы вручную, а зря.
Кластеризация позволяет решить ряд проблем при распределении запросов по страницам сайта. Она особенно полезна на больших объемах — от 1000 запросов и более.
Определяем тип запроса (коммерческий, информационный)
Запросы «пудра» и «пудра купить» на первый взгляд про одно и тоже. Но в первом случае поисковая выдача заполнена преимущественно информационными сайтами.
Исключение составляют два сайта: pudra.ru и «Подружка»: https://www.podrygka.ru/catalog/makiyazh/litso-1/pudra/. Их в расчет не берем, так как первый ранжируется за счет вхождения запроса в домен. А второй — за счёт своей популярности и больших объёмов прямого трафика на сайт.
По запросу «пудра» лидируют в основном информационные сайты
По запросу «пудра купить» десятку результатов поисковой выдачи занимают в основном интернет-магазины.
Можно сделать вывод, что продвинуть оба запроса на одной странице не получится. Для продвижения запроса «пудра» нужна информационная статья с достаточным объемом текста и иллюстрациями. А для продвижения запроса «пудра купить» — небольшой текст и каталог товаров с ценами.
Результаты выдачи поисковых систем — особенно «Яндекса» — достаточно сильно типизированы. Выдача состоит либо преимущественно из коммерческих сайтов, либо из информационных. Кластеризация позволяет с большой точностью отделить коммерческие запросы от информационных.
Определяем типы страниц (главная, внутренняя)
Теперь проанализируем выдачу по запросы «люстры купить» и «люстры интернет-магазин», которые также похожи. Видно, что по запросу «люстры купить» топ занимают внутренние страницы сайтов, а по запросу «люстры интернет-магазин» — главные страницы.
По запросу типа «люстры купить» приоритет отдается внутренним страницам сайтов
Следовательно, по запросу «люстра купить» продвигаем внутренние страницы с каталогом люстр, а по запросу «люстры интернет магазин» — главную страницу сайта.
Определяем совместимость продвижения запросов на одной странице
На скриншоте ниже видно, что запросы «угловые диваны» и «недорогие диваны» не имеют между собой ни одного общего URL. Для достижения лучших результатов эти запросы стоит продвигать на отдельных страницах.
Кластеризация — инструмент аналитики, который не даёт готового решения. Он собирает данные в удобном отображении для дальнейшей постобработки и анализа.
Существует два метода кластеризации:
- Hard — используется для продвижения по позициям, а также для продвижения в конкурентных тематиках. Количество запросов в кластере меньше, но точность выше.
Условие, соблюдаемое при hard-кластеризации, — у всех запросов в кластере должен быть общий набор URL.
- Soft — в основном используется для трафикового продвижения. Количество запросов в кластере больше, но точность ниже.
Условие, соблюдаемое при soft-кластеризации, — запросы сравниваются на предмет общих URL у всех запросов в группе. Например, у запроса А есть общий набор URL с запросом В, у запроса В есть общий набор URL с запросом С.
Схематичное изображение методов hard- и soft-кластеризации
Приведу несколько популярных сервисов кластеризации:
Для постобработки кластеризованной семантики можно воспользоваться бесплатной надстройкой для Excel.
Сбор семантики для больших проектов
Если проект содержит тысячи посадочных страниц, лучше собирать семантику отдельно для каждого раздела, учитывая приоритеты бизнеса и сезонность. А затем последовательно собирать семантическое ядро для двух–трёх разделов за каждую итерацию. Такой подход позволит собрать качественное семантическое ядро и не упустить целевые запросы
Если же собирать семантическое ядро сразу под весь проект, то на выходе получатся тысячи или даже десятки тысяч кластеров запросов, которые будет сложно обработать.
Как сохранить наследственность «Маркерный запрос — URL»
На первом шаге, описанном в статье, мы выгружали табличный список «Маркерный запрос — URL». Если сохранить URL после всех корректировок с маркерными запросами, то с помощью функции ВПР в Excel можно привязать часть URL-адресов к уже раскластеризованной семантике.
То есть — если маркерный запрос находится в кластере с другими запросами и у маркерного запроса уже известен URL, то можно считать, что все запросы кластера принадлежат к этому URL.
Не стоит бояться развивать структуру сайта. Если по результатам сбора запросов и их кластеризации вы понимаете, что под часть запросов не хватает посадочных страниц, лучше создать их или в крайнем случае отказаться от продвижения части запросов. Это будет эффективнее, чем вести несколько групп запросов (часто с несовместимыми интентами) на одну страницу сайта.
Семантическое ядро сайта: что это
СЯ изнутри и снаружи
Семантическим ядром для сайта (от греч. sēmantikos – обозначающий) называется перечень слов и словосочетаний, которыми описывается его тематика и направленность. В лингвистике «семантика» – это значение, смысл слова. СЯ – смысл сайта, поле основных значений, отражающих суть работы компании. На основе семантического ядра формируется стратегия продвижения. В конечном итоге СЯ во многом обеспечивает результативность SEO-продвижения, помогает получить целевых посетителей. СЯ, как правило, выглядит как таблица со списком целевых, профильных для данного сайта, запросов, указанием спроса (частотностью их набора пользователями в строку поисковой системы) и региона.
Кто создает семантическое ядро
Как и любая другая важная работа, составление семантического ядра – коллективное дело. Обычно оно формируется специалистом по продвижению сайта и заказчиком совместно. И это логично, ведь первый может найти все возможные формулировки целевых запросов в поисковых системах, а второй знает свою область деятельности как никто другой, поэтому сможет исключить неподходящие запросы и предложить свои.
Как создается семантическое ядро
Процесс создания СЯ укладывается в следующие несколько этапов.
Отбор ключевых слов:
- Первичный. Во-первых, нужно тщательно изучить все направления деятельности компании. Именно направления, а не весь контент сайта, ведь там может быть отражено далеко не все. На основании этого составляется список ключевых слов, по которым будет осуществляться продвижение с привлечением сервисов поисковых систем «Яндекс.Вордстат», Google.Adwords, ссылочных агрегаторов и др.
- Вторичный. Необходимо отсеять лишнее, то есть неподходящие запросы, по которым Вы не будете продвигаться (в частности, слова, не соответствующие тематике сайта) и добавить необходимое, что не было найдено при первичном подборе. Последнее также делается с помощью одного из сервисов. Возьмем, к примеру, «Яндекс.Директ». Введя в строке «ключевые слова и словосочетания» запрос «автомобили», можно увидеть запросы пользователей, включающие заданное нами слово и другие запросы, которые делали те же люди. Семантическое ядро сайта расширяется именно за счет них.
Оптимизация количества низкочастотных запросов. Это максимально точные запросы, которые вводятся в поисковик примерно 100-200 людьми в месяц. Продвижение по ним вряд ли даст много трафика, хотя они обеспечивают наибольшую конверсию.
Распределение запросов между страницами. Чаще по наиболее конкурентным запросам продвигают главную страницу и страницы с наибольшим статическим весом. Другие запросы группируются и распределяются между остальными страницами сайта.
Какие бывают запросы
По частотности запросы бывают:
- высокочастотные – вводимые пользователями в строку поисковой системы больше 10 000 раз в месяц.
- среднечастотные –относительно популярные слова и фразы с частотой набора от 1 000 до 10 000.
- низкочастотные –те, которые пользователи набирают реже всего (до 1 000 раз в месяц).
По конкурентности запросы бывают высоко- (стоимость более 20 $), средне- (5 $-20 $ ) и низкоконкурентными (меньше 5 $). Нельзя путать понятия «высокочастотные запросы» и «высококонкурентные запросы»: однозначного соответствия между ними не наблюдается.
Используемые сервисы
Основной сервис для формирования СЯ – это «Яндекс.Вордстат». Он помогает составить список ключевых слов, предоставляя статистику запросов в Яндексе. При необходимости можно воспользоваться и другими разработками, такими как Google.Adwords или различные ссылочные агрегаторы.
Возможные проблемы при составлении СЯ
- Использование нетематичных запросов.
- Привлечение при составлении большого количества высокочастотных фраз, не обеспечивающих конверсии.
- Выбор для продвижения общих запросов.
- Составление СЯ с использованием некорректных с точки зрения русского языка запросов.
- Игнорирование существующего ранжирования сайта по запросам.
- Использование «запросов-пустышек» – фраз, имеющих меньший реальный спрос из-за того, что слова чаще употребляются в другом порядке.
Итак, составление семантического ядра – основа для грамотного поискового продвижения по ключевым словам. Корректно собранное, оно поможет привлекать целевых посетителей, и о ресурсе узнает множество потенциальных потребителей.
Другие термины на букву « С»
Все термины SEO-ВикипедииТеги термина
Голосов 5, рейтинг 5 | |||||||||
Как собрать семантическое ядро? Инструменты для сбора и чистки СЯ
Яндекс обрабатывает более 50 миллионов поисковых запросов в день и показывает в выдаче только те сайты, которые способны удовлетворить любопытство пользователей. Список фраз, по которым пользователи могут найти определенный сайт в поисковой системе, называется семантическим ядром. Семантическое ядро — это словно черты характера вашего сайта, то есть все фразы, которые точно его характеризуют.
Существуют фразы, которые вводят в поисковиках чаще остальных – они называются высокочастотными (ВЧ). Фразы, которые вводят редко — низкочастотными (НЧ). Где-то между ними располагаются среднечастотные фразы (СЧ). Чтобы вам стали понятны масштабы, разделим их по частоте:
- ВЧ — 10 000 поисковых запросов в месяц и более;
- СЧ — 1000-10 000 в месяц;
- НЧ — 100-1000 в месяц.
Узнать частотность запроса можно с помощью Яндекс.Wordstat. Введите запрос в строку Вордстата, чтобы увидеть количество показов в месяц у слова или словосочетания.
Зачем собирать семантическое ядро?
Семантическое ядро служит упорядочиванию всех поисковых запросов на сайте. Собирать ядро начинают в самом начале продвижения, чтобы актуализировать все ключевые запросы и составить технические задания для будущих SEO-текстов. Зная позиции по определенным запросам, вы можете оперативно приступить к работе над сайтом. После публикации текстов нужно завести проект в сервисе для мониторинга позиций, например, в Topvisor или AllPositions. В этот проект вы загружаете семантическое ядро и регулярно мониторите движение сайта в поисковой выдаче.
Если вы заметите, что высокочастотная фраза подобралась к топу, вы сможете подтолкнуть ее выше, например, с помощью внешней ссылки. Если все получилось, то трафик на сайте заметно вырастет.
Инструменты для сбора СЯ
Существует масса инструментов для сбора семантики. В этой статье я расскажу только о тех, которыми пользовался лично. Некоторые инструменты нужны, чтобы собрать ядро, а некоторые — чтобы очистить его от ненужных запросов.
Инструменты, которые я упомяну в этой статье:
- Яндекс Wordstat,
- Wordstat Assistant,
- Key Collector,
- Bukvarix,
- Serpstat,
- Screaming Frog SEO Spider,
- Муравейник Tools,
- KeyAssort,
- Promotools.
Яндекс Wordstat
Старый добрый Вордстат позволяет бесплатно собрать нужные запросы. Не требуется никаких навыков в продвижении, чтобы ввести интересующую вас фразу в Вордстат и получить список запросов.
Если ставить перед каждым словом восклицательный знак (!семантическое !ядро), то Вордстат фиксирует окончание каждого слова. Если же мы введем запрос в кавычках (“семантическое ядро”), то будут доступны разные окончания порядка слов. При совместном использовании (“!семантическое !ядро”) кавычек и восклицательного знака фиксируется запрос и окончание. В таком случае меняться может только порядок слов. Например, ядро семантическое.
Ниже строки запроса можно выбрать региональность и узнать количество запросов в определенном городе или стране.
Копируем полученные запросы, чистим ненужные и получаем примитивную семантику. Можно воспользоваться расширением для браузера Wordstat Assistant, но лично мне оно не нравится. Думаю, что лучшим дополнением к Вордстату может служить сам Яндекс. Вводим интересующий запрос в строку поиска и получаем подсказки:
Если пролистать страницу до конца, можно увидеть похожие запросы:
С помощью Яндекс Вордстат можно бесплатно собирать СЯ, но, как я уже говорил, оно получается примитивным. Если вы собираете скудное семантическое ядро для сайта, вы можете потерять огромную часть трафика. Поэтому для сбора семантического ядра Вордстат я не использую. Он полезен, когда нужно быстро посмотреть запросы для продвижения в рамках одной страницы, но ядро лучше собирать в других сервисах.
Перемножение анкоров в сервисе Promotools
Есть отличный инструмент для перемножения анкоров на сайте Promotools. Сейчас объясню, что это за инструмент и почему он бывает так полезен.
Допустим, я собираю ядро для компании пластиковых окон. В первое окно ввожу продвигаемые фразы, а во второе коммерческие дополнения:
Нажимаю «Сгенерить!» и получаю перемноженные фразы.
Этот инструмент позволяет сэкономить кучу времени, составляя ключи за вас.
Key Collector
Кей Коллектор я считаю лучшим выбором для сбора семантического ядра. Программа платная, но ее функционал очень широкий, так что цена вполне оправдана.
Я работаю в Key Collector вкупе с сервисом по перемножению анкоров. Перехожу в Key Collector и собираю поисковые подсказки с указанных фраз. Под указанными фразами я имею в виду ключевые запросы всех страниц сайта. Их можно скопировать вручную или спарсить заголовки с помощью Screaming Frog SEO Spider (об этом ниже). Больше всего в Key Collector нас интересуют 3 кнопки:
С помощью них я на автомате собираю подсказки. И не только с Яндекса, но и с Гугла. Далее могу одним нажатием кнопки спарсить фразы из левой (точные запросы) и правой колонки (похожие запросы) в Вордстат. После того как парсинг закончится, снимаю частоты и удаляю запросы, частотность которых меньше 2-3 в месяц. В Key Collector можно удалить неявные дубли. Например, «пластиковые окна цена», «пластиковые окна цены».
В программе есть функция, с помощью которой отмечаются и удаляются неявные дубли. Далее из полученного списка ключевых фраз удаляем ненужные запросы… И ядро готово!
Для меня сбор ядра в Кей Коллектор привычен и прост. Кстати, у Кей Коллектора есть бесплатная альтернатива — Словоеб. К сожалению, бесплатная версия собирает запросы только из Вордстата, а вот Кей Коллектор может делать это из Директа, AdWords, AdStat и других агрегаторов.
Bukvarix
Иногда для сбора ключевых фраз я использую Bukvarix. Заходим в «Анализ доменов» и выбираем СЯ конкурентов:
Берем несколько конкурентов и закидываем в Букварикс.
Скачиваем файл с ключами, подчищаем их и радуемся готовому ядру! В бесплатной версии Букварикса можно скачивать до 1000 ключевых фраз.
Serpstat
В Серпстате все по аналогии с Буквариксом. Заходим в «Анализ ключевых фраз», затем в «Суммарный отчет»:
Вставляем домен конкурента в строку и ждем результата.
Serpstat в бесплатной версии, к сожалению, не позволит вам экспортировать запросы в файл.
Screaming Frog SEO Spider
Я уже рассказывал, как с помощью Screaming Frog SEO Spider можно сделать аудит сайта. Но его также можно использовать для сбора семантического ядра.
Вставляем сайт конкурента в строку и запускаем сканирование.
После сканирования необходимо перейти во вкладку h2 и экспортировать все заголовки. Если на сайте в заголовках указаны названия товаров, можно смешать их с коммерческими дополнениями с помощью инструмента для перемножения анкоров, о котором я писал выше.
После перемножения такое ядро, грубо говоря, не придется чистить. Потому что там будут только названия товаров со связками типа «купить» и «цена». Возможно, попадется какой-то мусор, но после снятия частотности он отсеется.
Если вас раздражает чистка ядра, то сбор семантики с помощью Screaming Frog SEO Spider подойдет вам больше всего.
Чистка семантического ядра
Мы спарсили подсказки и ключевые фразы конкурентов. Порой получается несколько десятков, а то и сотен запросов. Что со всем этим делать? Нам нужно оставить только релевантные, то есть соответствующие нашему сайту, запросы. Для этого нужно удалить все нерелевантные запросы, но делать это вручную очень долго. Рассмотрим сервисы, которые помогут почистить наше семантическое ядро.
Муравейник ToolsАналогов этого инструмента я не встречал. Чтобы почистить ядро с помощью Муравейник Tools, нужно зайти в «Анализ семантики», добавить задачу и загрузить ключи (до 10 000 запросов).
Муравейник Tools анализирует выдачу по каждому запросу и ищет сайты, похожие на вас. После анализа нужно будет разметить похожие сайты, то есть указать инструменту, какие сайты являются конкурентами нашему. Часто там можно встретить сайты типа ВКонтакте или Яндекс.Дзен – отмечаем, что они не похожи на наш сайт.
Затем скачиваем файл и сортируем сайты по схожести. Если в Яндексе и Гугле напротив запроса стоит 0, то такой запрос продвигать бесполезно.
Далее СЯ нужно проверить вручную. После чистки нужно будет пробежаться по ядру и вручную удалить неподходящие запросы.
Чистим ядро с помощью Key CollectorВ Key Collector можно не только собирать, но и чистить запросы. Для этого во вкладке «Данные» нажимаем «Анализ групп». После этого программа группирует слова. Выбираем группировку по отдельным словам. Если слово явно не подходит для вашей тематики, ставим напротив него галочку. После простановки галочек возвращаемся к «Сбору данных» и нажимаем «Удалить фразы».
Экспортируем оставшиеся фразы и проверяем полученные данные.
Муравейник Tools и Key Collector можно использовать в паре. Это поможет сэкономить время.
Кластеризация семантического ядра с помощью KeyAssort
Кластеризация — это распределение похожих запросов по группам. В кластерах будут только те запросы, которые релевантны определенной странице. С кластеризацией запросов отлично справляется KeyAssort.
Пример кластеризации
Для того чтобы сделать кластеризацию, загружаем в KeyAssort грязное семантическое ядро и нажимаем «Cобрать данные». Программа анализирует выдачу по каждому запросу и готовится к кластеризации. После того как данные будут собраны, нажимаем «Кластеризовать» и получаем нужные кластеры. Кластеры, которые релевантны нашему сайту, перетаскиваем в левую часть программы, а затем экспортируем их.
С кластеризацией может также помочь Key Collector с помощью функции «Анализ релевантных страниц». Анализ позволяет понять, на какую страницу лучше направить тот или иной запрос по мнению программы.
После кластеризации необходимо выполнить приоритизацию. То есть определить, какие кластеры нужно продвигать в первую очередь. Приоритезация довольно сложный процесс, который основывается на частоте запроса, его места в поисковой выдаче и конкурентности тематики. На основе этих данных можно составить план эффективного SEO.
Краткая инструкция по добавлению семантического ядра в TopvisorЯдро собрано и все тексты написаны? Теперь нужно добавить новые страницы в сервис Topvisor, чтобы следить за динамкой роста сайта. Постоянный мониторинг позиций и обновление ключей поможет вам вовремя реагировать на ухудшение позиций.
- Открываем сайт Topvisor и регистрируемся в сервисе.
- Переходим в «Мои проекты» и нажимаем «Добавить проект».
- Вводим адрес своего сайта и создаем проект.
- Выбираем поисковую систему и нажимаем «Добавить».
- Выбираем регион сайта.
- Переходим во вкладку «Поисковые запросы» и нажимаем на +, чтобы добавить группу запросов. Вставляем скопированные запросы в строку «Добавить запрос» и нажимаем на +.
- Когда все запросы будут добавлены, переходим во вкладку «Проверка позиций». Чтобы проверить позиции, нужно нажать на значок «Обновить».
Рекомендую делать срез позиций раз в неделю.
Заключение
Разумеется, инструментов для сборки и чистки семантического ядра гораздо больше. Пробуйте разные сервисы, используйте различные связки инструментов, и тогда вы найдете оптимальный вариант. Главное, чтобы на выходе у вас получилось хорошее семантическое ядро без мусорных запросов.
Семантическое ядро для информационного сайта
Семантическое ядро – залог успешной кампании по продвижению. Неверные слова могут свести на нет все усилия по раскрутке вашего сайта. В сети много данных о составлении семантики, но крайне мало полезной информации о подборе ключей именно для информационных сайтов.
Видео о продвижении информационного сайта:
Содержание
Особенность семантики для СМИ заключается в том, что у таких сайтов нет постоянного семантического ядра. Оно с той или иной скоростью непрерывно изменяется, и предвидеть что-либо заранее практически невозможно, так как статистика поисковиков дается, как правило, за предыдущий месяц. По этой причине поисковые запросы для информационных ресурсов можно разделить на 2 группы:
- Постоянные слова – неизменная часть семантики.
- Новые или меняющиеся слова – динамичная группа поисковых запросов.
Давайте подробнее разберемся во всех тонкостях SEO-продвижения информационного сайта.
Типы запросов и интент пользователя
Типичная ошибка начинающих оптимизаторов – сбор всех возможных поисковых запросов с помощью автоматических систем или специализированных программ. Пользователи идут в поиск с какой-либо целью, и эта цель всегда «скрыта» в запросе. Для того чтобы отобрать правильные запросы, нужно верно определить цель. А для этого нужно знать, какие типы запросов бывают, и какие цели преследуют пользователи, их вводящие.
Поисковые запросы принято делить на 3 основные группы, в зависимости от того, какую потребность с помощью поиска пользователь закрывает:
Пользователь ищет в сети конкретную компанию. Обычно сайты компаний на 1-х местах по таким запросам.
[iqad агентство] – пример навигационного запроса
Можно ли использовать навигационные запросы для продвижения СМИ? В большинстве случаев нет. В том случае, если само издание готово создать специальные страницы – карточки организаций – такой вариант возможен. Но важно понимать, что первое место всегда будет отдано официальной странице.
Например, у вас интернет-СМИ, посвященное теме «Спорт и здоровье». В этом случае вы можете создать каталог медицинских и спортивных организаций и собирать соответствующий трафик.
wordstat.yandex.ru – сервис анализа и подбора ключевых слов
В алгоритме ранжирования «Андромеда», введенному поисковой системой Яндекс в конце 2018 года, сайты по ряду запросов, стали подсвечиваться значком «навигационный ответ». Такие значки появились именно для тех запросов, по которым, по мнению поисковой системы, пользователю важно найти именно официальный сайт:
Значок навигационного ответа в органической выдаче Яндекса. Алгоритм «Андромеда».Транзакционные и коммерческиеСамые простые поисковые запросы этой группы, включающие в себя такие слова как: [купить], [заказать], [скачать] — т. е. призывающие совершить действие. Для сайтов СМИ подходят слабо, только если у вас есть специальные сервисы или коммерческие разделы, так как коммерческие слова наиболее конкурентные, а значит дорогие в плане трудозатрат на их вывод в ТОП-10.
Однако, если исключить на 100% коммерческую группу запросов и оставить навигационные с меньшей конкуренцией или с уклоном в информационную составляющую, можно собирать дополнительный трафик.
Например, ваше СМИ может быть посвящено финансовой сфере. Создание сервиса расчета ипотечного платежа – «Ипотечный калькулятор» – позволит привлекать дополнительные объемы трафика.
Банки.ру – в ТОП-10 поисковой системы Яндекс сервис по расчету ипотекиИнформационные запросы
С их помощью пользователь ищет информацию в сети. Это те запросы, на которые любое СМИ или информационный ресурс \ раздел должны делать упор. Это ключевая группа запросов для всех информационных сайтов!
Пример таких запросов:
- [рецепт ухи],
- [как разобрать телефон],
- [куда вложить пенсию] и т. п.
Структура поисковых запросов не всегда говорит нам о потребности пользователя, о том, что он хочет получить вводя тот или иной поисковый запрос. Например, что хотел получить пользователь, вводивший в поиск запрос [владимир путин]?
- Личный сайт президента РФ?
- Профиль в соцсетях?
- Биографию?
- Новости?
- Фотографии?
- Видео?
- Интервью?
Истинная потребность пользователя называется интентом. И для того чтобы его понять,
мы должны обратиться к результатам поиска.
Если мы видим в выдаче преобладание каких-либо определенных сайтов, посчитав и оценив их контент, можно определить тип запроса.
Например:
- если мы видим магазины – запрос коммерческий,
- если мы видим статьи – информационный,
- если мы видим разные сайты – смешанный.
Пример поисковой выдачи по общему или смешанному запросу
Особенности устройства поисковых сервисов
Пользователи поисковых сервисов — это самые разные люди. Об этих людях поисковые сервисы собирают информацию, строят портрет пользователя, изучают их предпочтения. Зная характер поведения пользователя и его предпочтения, можно отдавать те сайты, которые интересны именно этому пользователю. Выдача подстраивается под конкретного пользователя. Такой процесс называется – персонализация.
Подробнее о персональном поиске в справке Яндекс.
Для более точного определения типа запроса всегда отключайте в настройках поисковой машины персональный поиск. Иначе ваши личные предпочтения могут исказить объективную картину, и вы неверно определите тип поискового запроса.
Персональные ответы в поиске Яндекса
Анализ поисковых запросов для СМИ
После того как мы разобрались в типах запросов, можно приступать к отбору нужных нам слов для раскрутки СМИ или информационного сайта/раздела на сайте.
Основным сервисом информации о поисковых запросах является wordstat.yandex.
Wordstat.yandex – сервис статистики поисковых запросов к поисковой системе Яндекс
Мы видим все ключевые слова и статистику того, сколько раз этот запрос вводили пользователи Яндекса. Запросы сортируются от наиболее популярных к наименее.
Вторым по популярности сервисом анализа поисковых запросов, вводимых в Google, является сервис контекстной рекламы — ads.google.com. Конкретно его раздел:
keywordplanner или планировщик ключевых слов
Планировщик ключевых слов Google показывает статистику поисковых запросов в диапазоне.
На практике такие системы неудобны для сбора больших семантических ядер. А именно такие ядра необходимы для сайтов СМИ. Специалисты по поисковой оптимизации прибегают к инструментам автоматизации. Такие сервисы и программы автоматизируют рутинные процессы и многократно ускоряют работу.
Автоматизация по сбору поисковых запросов для информационного сайта
Программы для профессионалов
Ввиду того, что семантика сайта СМИ может включать в себя сотни, тысячи или десятки тысяч запросов, нам необходима автоматизация сбора данных о поисковых запросах. Разберем самые популярные программы и сервисы.
Key Collector
Особой популярностью у SEO-оптимизаторов пользуется программа Key Collector.
Key Collector – одна из самых популярных программ для подбора и анализа ключевых слов
Функционал программы насчитывает десятки функций. Наиболее популярные среди них:
- Сбор статистики Yandex.Wordstat.
- Сбор статистики Yandex.Metrika.
- Сбор статистики Google.Analytics.
- Сбор поисковых подсказок.
- Сбор статистики из сервисов продвижения.
- Сбор статистики Yandex.Direct.
- Сбор статистики Google.Adwords.
- Сбор статистики ВКонтакте.
- Показатели KEI.
- Определение релевантных страниц и съем позиций.
Хочется отметить, что программа – платная и для большинства пользователей ее функционал избыточен. К счастью, есть и бесплатная альтернатива. Это сокращенная версия KeyCollector – Слово*б.
Подробнее о программе Слово*б.
Ее функционала будет достаточно для большинства штатных задач по подбору и анализу ключевых слов.
Есть и другие популярные программы и сервисы. Среди них можно выделить:
Готовые базы поисковых запросов
В связи с тем, что статистика Yandex.Wordstat не полная, она ограничена минимальной частотностью. А в периоды «не сезона» может быть крайне незначительной. Для подбора максимальной базы можно воспользоваться готовыми базами ключевых слов.
База поисковых запросов Пастухова – одна из самых крупных в русскоязычном сегменте.
База поисковых запросов Пастухова содержит 1,655,810,672 ключевых слов.
Группировка запросов
После сбора списка ключевых слов их принято объединять в группы или кластеры.
В группы слова объединяются по общей потребности. Для каждой потребности мы выделяем свою страницу сайта, и цель страницы – закрыть потребность. Например: цель этой страницы закрыть потребность в информации о поисковых запросах для сайта СМИ.
Пример группировки или разбивки:
Группировка запросов – важный этап при разработке семантического ядра сайта
Для автоматизации группировки запросов мы используем инструменты кластеризации. На основании того, какие страницы сейчас показываются в поиске и по каким запросам, эти сервисы способны автоматизировать всю работу по объединению слов в группы.
Среди платных инструментов это:
- Rush Analytics.
- SEMparser.
- Just Magic.
Среди бесплатных:
Coolakov – один из самых популярных бесплатных инструментов группировки слов. Но лимиты ограничены
Структура ядра для СМИ
Классический способ продвижения: подбор запросов и продвижение сайта по выбранному списку. Такой способ не в полной мере подходит для информационных сайтов. Обычно ядро для СМИ нужно составлять таким образом, чтобы оно состояло из двух частей:
- Статическая или неизменная часть семантики.
- Динамическая или изменяемая часть семантики
Неизменная часть семантики
Как правило, это могут быть страницы разделов – новости китая/новости политики и т. п.
Это ключевые разделы вашего сайта. Они всегда доступны и не теряют своей актуальности. Не забывайте подбирать запросы и для главной страницы сайта.
Главные страницы сайта чаще всего продвигают по наиболее общим и популярным ключевым словам Долгоиграющие сюжеты
Долгоиграющие сюжеты – интервью с Пугачевой, биография Галкина и т. п. Подготовка таких материалов позволит долгое время привлекать на ваш сайт трафик. Нередко такие станицы дают большую долю органического трафика.
ТрендыТренды – набирающие популярность темы, которые могут перерасти в долгоиграющие сюжеты. Для подбора и анализа можно использовать сервис — Google Trends.
Google Trends – отображает динамику популярности
На графике Google Trends мы видим уровень интереса к теме по отношению к наиболее высокому показателю в таблице для определенного региона и периода времени. Таким образом можно отбирать темы, набирающие популярность в данный момент.
Новостные или короткие по жизни сюжеты
Это то, что мы видим в ТОП-10 и те новостные сюжеты, которые имеют короткий срок жизни. Быть в ТОП-ах новостных агрегаторов – это не задача поисковой оптимизации. Семантику под такие событийные запросы не собрать даже с помощью Google Trends.
Зато без специальной оптимизации легко попасть в ТОП-10 выдачи. Для этого необходимо:
А вот быть в ТОП-10 это да, но тут не нужно специальной оптимизации, необходимо:
1. Быть добавленным в агрегаторы поисковиков.
Чтобы узнать о добавлении ресурса в агрегаторы, достаточно:
Отправить запрос на добавление в Google.Новостях – тут: https://support.google.com/news/publisher-center/answer/40787?hl=ru.
Отправить письмо на добавление сайта в Я.Новости – тут: https://yandex.ru/support/news/info-for-mass-media.html.
2. Писать новости сразу и с уникальным текстом.
3. Печатать много новостей для привлечения быстробота (робот поисковой машины, который индексирует новые материалы и выводит их в поиск в течение нескольких минут).
Персоналии
Всегда есть люди, умеющие поддерживать к себе неиссякаемый интерес аудитории. Это знаменитости или публичные люди. Для СМИ вашей тематики это могут быть звезды, политологи, политики, популярные авторы и т. д. Создание таких страниц может поддержать стабильно высокий трафик для вашего сайта.
Обучение журналистов
Часто авторы используют именно творческие названия разделов/колонок/публикаций. Что не поспособствует их ранжированию в ТОП-10 по популярным поисковым запросам.
Например, автор, делая обзор на новую модель BMW, может написать: «Яблочко от яблони». Понятно, что он имеет ввиду факт: новая модель от старой не отличается. Но, добавив к названию и в заголовок ключевые слова, получим шанс подняться в ТОП-10:
«Обзор нового BMW: Яблочко от яблони».
Научите журналистов (копирайтеров) пользоваться статистикой поисковых запросов.
Изучение конкурентов
Изучайте успешные СМИ (контент, разделы, перелинковка, тегирование и т. п.). Это поможет найти вектор развития для вашего сайта, подкинуть свежих идей и перенять успешный опыт.
Как найти конкурента
Для поиска сайта конкурента можно воспользоваться поисковой системой. Вбивайте в поиск наиболее популярные слова и выделяйте сайты, которые ранжируются в ТОП-10. Также можно воспользоваться платными сервисами и программами. Например, сервис SpyWords.
Сервис SpyWords покажет наиболее близкие по семантике сайты
Выбирайте наиболее близкие к вашему сайту по видимости конкурентов или к лидеру, к которому вы стремитесь.
План публикаций
Проблема, с которой вы обязательно столкнетесь после подбора всех запросов: семантика очень большая. И не всегда понятно, как выстраивать приоритеты. Мы предлагаем простой способ составить контент-план на основании оценок групп запросов.
Мне тут не хватает инфы, как часто стоит пересобирать СЯ. Так и хочется спросить – с какой периодичностью к этому нужно возвращаться?
Оцениваем кластеры запросов по 2 параметрам:
- Конкуренция.
- Популярность.
После оценки мы выстраиваем контент-план для сайта, основываясь на принципе: максимум трафика с меньшей конкуренцией. Для старых и трастовых сайтов можно попробовать изменить приоритет и строить контент-план, основываясь только на частотности кластеров.
Обновление семантического ядра
Семантическое ядро необходимо актуализировать.
Составить ядро 1 раз и на всю жизнь проекта не получится. В общем смысле, актуализация семантического ядра сводится к тому, что мы должны пересобрать или обновить нашу семантику. Дополнить ее новыми запросами. Убрать из нее более не актуальные или не интересные.
Технические аспекты продвижения информационного сайта
Технический аудит новостного сайта обязателен и имеет высокий приоритет. Дело в том, что одной из отличительных особенностей информационных сайтов является их размер. Чем больше сайт, тем больше ошибок может возникать.
Выделим основные технические ошибки, влияющие на ранжирование в поиске.
Дублирование
Дублироваться может часть контента страницы. Наиболее часты ошибки — это:
- Наличие дублей тегов, особенно TITLE.
- Дубли текста или его частей.
- Полные или частичные дубли страниц.
Любое дублирование, даже частичное, снижает уникальность документов, а значит их ценность в глазах поисковых машин будет ниже.
Ссылки на сайте и изображения
Битые внешние и внутренние ссылки, недоступные изображения, циклические ссылки – это все ошибки, снижающие скорость индексации ресурса, увеличивающие показатель отказов и время на сайте. Устраняйте их обязательно.
Скорость загрузки
Скорость загрузки сайта – один из факторов ранжирования. Замечено как его прямое воздействие, например, в мобильной выдаче, так и косвенное через поведенческие метрики.
До 40% посетителей сайта готовы закрыть страницу до ее полной загрузки, если скорость загрузки страницы выше 3 сек.
Турбо-страницы и AMP Google
Это специальные технологии поисковых систем, способные многократно увеличить загрузку документов за счет их упрощения. Подробнее о технологиях:
Турбо-страницы Яндекса способны
увеличить загрузку контента сайтов из поиска Яндекса, Новостей и Дзена в 15 раз в 3G-сетях
Расширенные сниппеты
Cниппет – это текстовая часть, которая описывает ваш сайт в результатах поиска. Его привлекательность для пользователя напрямую влияет на вероятность перехода именно на ваш сайт.
Иконка сайта, текст, TITLE, изображение – элементы привлекательного описания документа в поисковой выдачеСуществует несколько способов сделать ваш сниппет привлекательным. Отметим наиболее важные.
МикроформатыНаиболее популярные и поддерживаемые Яндексом:
- hCard — стандарт разметки контактной информации вашего сайта.
- hReview — стандарт разметки отзывов.
- hRecipe — стандарт разметки рецептов. hProduct — стандарт разметки разметка товаров.
Больше о микроформатах в помощи Яндекса: https://yandex.ru/support/webmaster/microformats/what-is-microformat.html.
Семантическая разметка Schema.org
https://schema.org/
Это международный формат разметки данных, поддерживаемый большинством поисковых систем.
Если ваш сайт относится к группе специализированных, например, рецепты, и для него есть свой формат разметки – используйте специализированные форматы от Яндекса. Для всех общих и стандартных элементов, например, контактная информация, лучше прибегать к стандарту Schema.
Социальные сети
Мы не будем рассматривать вопрос раскурки СМИ в социальных сетях. Остановимся лишь на аспекте влияния социальных сетей на ранжирование вашего сайта в поиске. Поисковая система должна видеть ряд сигналов, которые укажут ей на то, что вы ведете активность в соц.сетях.
- Наличие официальных групп и сообществ в социальных сетях.
- Наличие ссылок на ваш сайт из социальных сетей.
- Наличие переходов на ваш сайт из социальных сетей.
Разрабатывая стратегию продвижения в социальных сетях, учитывайте 3 основные вышеуказанные рекомендации.
Заключение
Продвижение информационного сайта – это работа с большими объемами данных. Сбор семантики – кропотливый труд. Но в инструментах SEO сегодня появились помощники, которые сильно упрощают нашу жизнь. Собирайте наиболее полное ядро. Группируйте запросы по потребностям пользователей и раскрывайте потребность на продвигаемых страницах. Научите журналистов и редакторов SEO-магии. Изучайте конкурентов. Актуализируйте ядро. Органический трафик – один из самых стабильных и недорогих, хотя и трудозатратный.
Избавляйте сайт от технических ошибок, исследуйте технологии поисковых сервисов, которые могут быть полезны вашему сайту. Улучшайте сниппет вашего сайта.
Следуйте нашим инструкциям и привлекайте максимум органического трафика.
Семантическое ядро — основа продвижения вашего сайта
Перед SEO-продвижением сайта главное что вам нужно — это семантическое ядро. От того, насколько вы грамотно его соберете зависит эффективность дальнейшего продвижения.
Семантическое ядро (СЯ) — это документ с списком ключевых фраз для вашего сайта, а также их параметров, таких как частотность, конкурентность, геозависимость. Данные ключевые фразы должны наиболее точно передавать суть контента вашего сайта. Для каждой ключевой фразы должна быть определена релевантная страница.
В нашей очередной публикации делимся основами сбора семантического ядра.Но сначала разберем основные источники для фраз для него.
Источники для поисковых запросов
🦄 wordstat.yandex.ru
Сервис по подбору слов от Яндекс. У каждого запроса отображается частотность, можно узнать ее изменение по месяцам на протяжении последних 2-х лет. Все, что нужно для использования, это иметь аккаунт в Яндекс и список маркерных запросов (об этом ниже в статье), знать операторы «» и!.
🦄 webmaster.yandex.ru
Личный кабинет для вебмастера, где фиксируются запросы, по которым не только приходят пользователи, но и по которым сайт просто показывался в поисковой выдаче. Получить эти и другие данные можно после регистрации в сервисе сайта.
🦄 metrika.yandex.ru
Сервис аналитики от Яндекс. При условии, что на вашем сайте уже установлен счетчик, здесь можно узнать поисковые запросы, по которым уже приходят пользователи. Часть из них непременно будут обозначать четкое намерение пользователей, которое необходимо вам. Остается только проанализировать их частотность.
🦄 Google Keyword planner
Планировщик ключевых слов от Google. Если предыдущие источники годны только для Яндекс, то здесь вы найдете запросы для второго популярного поисковика, т. е. для Google. Жаль только, что частотности указываются округленные, не точные.
🦄 Google Search console
Аналог webmaster.yandex.ru в Google. Все похоже: регистрируете сайт, получаете среди прочего данные о ключевых запросах, по которым совершены переходы и имеются показы.
🦄 Любой софт, сервисы которые могут парсить wordstat.yandex.ru и /google/keyword-planner/
Например, seranking.ru или key-collector.ru. В них же есть возможность собрать семантику из дополнительных источников, таких как поисковые подсказки или собственные базы ключевых запросов. Поиск ключевиков с помощью подобного софта автоматизирован, есть удобные настройки для их фильтрации от ненужных фраз, слов.
Составьте список маркерных запросов
Итак, с источниками разобрались. Переходим к процессу сбора СЯ. Для начала вам необходимо составить список так называемых маркерных запросов. Маркерные запросы — это фразы, которые в общем смысле описывают ваши услуги /товары, например, «мопеды Suzuki» или же просто «мопеды» (первый пример подойдет к категории каталога, а второй может для главной страницы, если у вас на сайте продажа исключительно мопедов). Как правило такие фразы — это ВЧ запросы в своей тематике.
Маркерные запросы вы можете определить с помощью мозгового штурма: записать все фразы, по которым пользователи ищут ваше предложение. Вы также можете отыскать такие фразы в Яндекс. Вебмастер (если в нем зарегистрирован сайт), подсмотреть у конкурентов (в заголовках страниц, названиях категорий каталога). Для каждого маркерного запроса необходимо определить релевантную страницу на сайте. Далее с полученным списком обратитесь к wordstat.yandex.ru, Google keyword-planner, или любому софту, который работает с этими сервисами.
Проанализируйте фразы из вашего списка
Каждый такой маркерный запрос, как правило, имеет хвост других запросов, которые содержат дополнительные или уточняющие слова, в случае нашего примера — «мопеды Suzuki цена», «мопеды Suzuki ZZ купить». Такие фразы нам и нужны, потому что именно они являются транзакционными, т. е. они отражают намерение пользователей приобрести мопед.
Список фраз из хвоста можно получить, если вбить в wordstat.yandex.ru маркерный запрос (список будет отображаться в левой колонке) или же применив софт, который упомянут выше.
Если вас интересует только продажа определенного предложения, товара, то нужно отфильтровать полученный список от фраз, которые не отражают четкое намерение покупки пользователя, сконцентрировавшись только на коммерческих запросах. Таким образом, трафик будет целевым. Отфильтрованные фразы типа «обслуживание мопеда Suzuki ZZ» можно оставить для блога на сайте, там они пригодятся, способствуя улучшению поведенческих факторов.
Каждую полученную полезную ключевую фразу из хвоста можно таким же образом снова проанализировать и получить дополнительные фразы. Для интернет-магазинов может быть важным поиск и анализ запросов с вхождением бренда и артикула товара.
Не забудьте для каждой фразы заносить в список их базовую частотность по wordstat.yandex.ru!
Соберите список похожих слов
Обратите внимание при анализе каждой ключевой фразы в wordstat.yandex.ru на правую колонку. В ней список похожих фраз, которые запрашивали пользователи. Здесь вы тоже можете подобрать подходящие ключевики.
Соберите поисковые подсказки
Поисковые подсказки из Яндекса и Google — это источник ультра НЧ запросов, которые имеют низкую конкурентность, а значит по ним легко выйти в топ.
Проанализируйте частотность полученных ключевых запросов
У вас уже получен объемный список фраз, которые, кстати, хорошо хранить в таблице Excel. Теперь нужно проверить хотя бы частотность в фразовом вхождении с помощью оператора «кавычки» в Wordstat. Удобнее это сделать автоматически с помощью софта, например seranking.ru или key-collector.ru, о которых мы уже упоминали.
Финализируйте и сгруппируйте ваши ключевые запросы
Еще раз просмотрите внимательно ваш список слов. Можно удалить запросы, которые вы вряд ли станете продвигать из-за специфики вашей деятельности, вхождения в них названий других городов или конкурентов, или слишком уж «корявой» формы фразы вида «мопед улица фонарь цена».
У вас уже есть маркерные фразы, для которых определены релевантные страницы. Также под каждую маркерную фразу вам необходимо определить группу запросов. Следует знать и то, что для эффективного продвижения сайта необходимо по одной группе запросов продвигать одну страницу. Определение релевантной страницы под определенную группу запросов называется кластеризацией и это отдельная тема для следующей публикации.
В финале вашего труда должна получится примерно такая таблица. Это лайт-версия СЯ без параметров типа геозависимость, сезонность, конкурентность.
Если у вас остались вопросы, пишите нам письма на наш замечательный адрес: [email protected].
Или звоните нам 8 (800) 200 · 69 · 20 и приезжайте в гости (это временно) 😀
Как составить семантическое ядро сайта правильно в 2020 году
О том, как составить семантическое ядро, написаны мегатонны буковок, но то ли тема такая, то ли я такой, что долго не мог понять, как же это делается, в чем суть СЯ и каковы нюансы? Пришлось долго и нудно раскуривать завалы статей, результатом чего стала еще одна.
Итак, по общему мнению семантическое ядро сайта – полный список запросов, по которым продвигается сайт.
Создание семантического ядра для сайта, особенно мощного коммерческого – сложный и длительный процесс. Но с блогом проще. В случае блога СЯ носит более вальяжный характер.
Честно говоря, создавая Оружейную, я не чувствовал необходимости в каком-то там семантическом ядре. В голове я держал примерный курс развития и план написания статей. Этого, казалось, всегда будет достаточно.
Однако позже я начал задумываться… Вот, к примеру, обмен или покупка ссылок: нужно быстро выбрать запрос для продвижения, получить URL продвигаемой по этому запросу статьи и анкор. А быстро получается не всегда.
А вот другой пример: мониторинг позиций блога с программой Site Auditor. По каким запросам? Естественно, лучше по всем тем, по которым блог продвигается. А где их взять? Листать страницы блога и вспоминать, под какой запрос написана какая статья? Нет, это не системно.
Семантическое «недоядро»
В общем, раз за разом я натыкался на мысль, что нужно иметь список или таблицу, вмещающую в себя:
- — ключевые запросы, по которым блог продвигается
- — URL статей, оптимизированных под соответствующий запрос
- — title этих статей
- — ну, и еще желательно приблизительную частотность запроса (хоть она и меняется, но хотя бы пометку: ВЧ, СЧ, НЧ)
- — а еще можно количество внешних ссылок в статье, но это уже роскошь.
Иными словами, жизнь сама подвела меня к необходимости семантического ядра.
Говоря строго, то, что я себе представлял было не совсем СЯ, а каким-то «семантическим недоядром», т. е. списком уже имеющихся статей и запросов, но до нормального СЯ от такого списка пара шагов.
Читая одну за другой статьи в интернет, я сталкивался с противоречиями. Кто-то преподносит создание ядра как легкое занятие, кто-то наоборот нагнетает, что сложность чрезвычайно высока: структура запросов в семантическом ядре должна соответствовать структуре страниц сайта и их перелинковке. Я не представлял, как применить эти рекомендации к своему блогу. Вывод, до которого я шел долго, чрезвычайно прост: создание СЯ – процесс сложный, но в отличие от коммерческих сайтов, для блога процесс может быть значительно упрощен.
СЯ – список запросов, по которым продвигается блог. И точка. Не имеет значения, как он будет представлен и что будет содержать, кроме самих запросов, но для удобства я решил делать его в электронных таблицах (Excel, Calc) и помимо запросов указывать другую информацию, перечисленную в списке выше.
Основное отличие списка статей и запросов, о котором я мечтал поначалу, от полноценного семантического ядра в том, что настоящее ядро – это еще и Ваш roadmap в наполнении блога материалами. Ведь ядро может содержать и те запросы, статьи по которым еще не написаны. То есть, выполнять функцию планирования.
Завел я, к примеру, сайтег про дыхательные методики и сразу составил список запросов (читай статей и разделов сайта), которые предстоит написать.
Или заметил, я скажем, в вордстат. яндексе забавный запрос «основатель математики», ввел его в поиск, а в ответ, – оппаньки! – ни одной более-менее релевантной статьи… «Эге, – думаю, – надо бы заполнить пустоту статейкой на skolkobudet. ru». Кто основал математику, я, разумеется, четкого представления не имею, но это не значит, что не смогу написать небольшое словоблудие исследование, оптимизированное под этот запрос.
В общем, вот. Теперь поговорим конкретнее о том, как составить семантическое ядро блога: сбор запросов
Ядро состоит из запросов. Сколько запросов для своего сайта вы придумаете сходу? У меня получалось не больше 10. К счастью, фантазия не единственный их источник. Запросы для семантического ядра можно взять в следующих местах:
1) ну, перво-наперво из головы, да. Ее никто не отменял. К примеру, я без всяких фокусов знаю, что мой сайт skolkobudet. ru отвечает запросу «деление в столбик», «системы счисления тренажер» и «тренажеры по математике». Также я знаю, что для Оружейной подойдут запросы: «летающая птичка twitter», «загнутый угол page peel» или «блоггинг». А предполагаемый бложек про дыхательные методики будет иметь в ядре запросы «дыхательные методики», «метод Бутейко», «метод Фролова», «тренажер Фролова» и т. п.
То есть, основу для семантического ядра составляет наши собственные представления о том, чему в общем посвящен сайт, или что могут на нем искать посетители. Эти запросы можно использовать как отправную точку в Wordstat. yandex и сервисах подбора ключевых запросов.
2) с сайта/блога. Если сайт уже существует, если уже есть страницы, соответствующие каким-то запросам, эти запросы, конечно, включаем в ядро.
3) из wordstat. yandex. ru и adwords. google. ru. Набираем, к примеру, запрос «математика» (взятый из головы) и видим различные варианты запросов с этим словом, а также связанные запросы (см. выше про запрос «основатель математики»). Не забываем про использование кавычек и восклицательного знака в вордстат. яндексе. Так статистика будет точной для этого словосочетания, а не для всех его словоформ. Иными словами: «! устный! счет» — 126 показов в месяц (и это точно), а устный счет — 3822 показа в месяц (это с кучей других запросов, содержавших «устный счет» в различных словоформах).
Я не буду здесь описывать технологию работы с wordstat. yandex и adwords. google. Я писал об этом в статье про подбор ключевых слов для статьи. Да и интерфейс, в общем-то, прозрачен.
4) с сайтов-конкурентов. Если чей-то сайт пробился в ТОП-5, значит, не худо перенять опыт. Заходим на Megaindex (или в какой-то другой ссылочный агрегатор, имеющий аналогичный функционал), выбираем раздел «Анализ сайтов», вводим URL сайта-конкурента и видим запросы, по которым продвигается сайт:
Вот таким вот нехитрым способом Megaindex позволяет узнать, по каким запросам (всего их около 850) продвигается взятый для примера блог А. Борисова. Некоторые запросы грех не позаимствовать в качестве тем для будущих статей.
Кстати, 30 мая MegaIndex проводит бесплатный семинар по аудиту сайтов:
Сервис подбора запросов от Megaindex предлагает мне вот такие запросы для семантического ядра сайта seo-armory. ru. Данные получены на основании автоматического анализа сайтов-конкурентов.
5) пользуясь парсерами ключевых слов. KeyCollector (и бесплатный младший брат его СловоЁб), Магадан (версия LITE бесплатна в отличие от PRO), Анадырь (бесплатен)… Всё это программы, позволяющие значительно упростить и ускорить сбор ключевиков с сервисов wordstat. yandex. ru и adwords. google. ru, а также с массы других сервисов (например, с ссылочных агрегаторов). Как правило, парсеры имеют массу удобных функций, значительно облегчающих жизнь составителю СЯ.
6) из готовых баз ключевых слов. Да, база Пастухова. Да, стоит в районе 500$. Да, облизнулись и читаем дальше. Ну, или купили побыренькому и читаем дальше. Хотя есть и бесплатные базы. Например, база, которую можно взять на keybooster. ru (на момент написания статьи URL не открывается). Кроме того, эта база интегрирована в программу Магадан, которую можно взять на magadanparser. ru (открывается нормально).
А дальше?
Итак, мы надергали изо всех указанных мест несколько сотен (или тысяч) запросов и смотрим на этот список. Что делать дальше?
Фильтрация ключевых запросов
Какие из попавшихся запросов подходят для нашего сайта/блога? Есть 5 критериев фильтрации:
1) Перво-наперво исключаем те запросы, по которым не собираемся писать статьи. Это могут быть замечательные во всех отношениях запросы, но нам с ними не по пути. Мы не будем о них писать. Например, MegaIndex предложил в числе прочих запросы «монетизация форума» и «интернет-магазин на Joomla». Я пока далек от монетизации форумов (есть у меня один форум, но ему еще расти и расти). CMS Joomla тоже пока не входит в круг моих интересов. Зачем мне эти запросы? Выкидываю их.
Часто можно сразу выкинуть запросы, содержащие слова «реферат», «бесплатно» или «скачать» (если, конечно, вы не предлагаете рефераты, халяву или файлы для скачивания).
2) Взглянем на статистику запросов (в том же вордстате). Нужен ли нам в семантическом ядре запрос, которым озадачились всего 5 человек в месяц? Не думаю. Потому, подбирая запросы, отсеиваем всё, что принесет меньше 10 человек в месяц (а хотите меньше 20 или 30, всё зависит от Вашего самомнения). Но будьте внимательны: вордстат в отличие от гугл эдвордс не учитывает сезонность. Вряд ли зимой в Москве запрос «куда выйти на шашлыки» будет так же популярен, как летом. Ориентировочно: низкочастотный (НЧ) запрос – менее 1000 в месяц, среднечастотные (СЧ) – от 1000 до 10000, высокочастотные (ВЧ) – более 10000.
3) Кстати, о Москве. Важно также настроить регион продвижения. Это позволяют сделать все сервисы, даже вордстат. Статистика запросов может сильно отличаться для разных регионов.
4) Мы не одни такие умные, что продвигаемся в инете. Конкуренция всеобъемлюща. По каждому запросу у нас будут конкуренты. Запросы делятся на высоко-, средне- и низкоконкурентные. Эдвордс показывает уровень конкуренции по запросам, правда, не расшифровывая, что такое «низкий», «средний», «высокий» в его понимании. Лезть в высококонкурентные области мне как-то страшновато. Запинают и не заметят. Или даже просто не заметят.
5) Следует также исключить из семантического ядра накрученные запросы, то есть, имеющие высокую базовую частотность, но «! крайне! малую! частотность! по! точной! словоформе» (см. выше). Скорее всего, такие запросы имеют высокую базовую частотность из-за действий оптимизаторов, мутящих воду в яндексе своими бесконечными составлениями семантических ядер. Если разница между двумя частотностями – 10-30 раз, это признак накрученного запроса.
Кроме того, полезно набрать интересующий запрос в поиске и посмотреть выдачу. Если в ТОП-10 суперпуперсайты, то ловить нечего. Плохо (для нас), когда в выдаче главные страницы сайтов («морды»). Вторые по вложенности – получше. Третьи – совсем хорошо (для нас). Если в тайтлах ТОП-10 есть прямые вхождения ключевиков – это для нас тоже плохо. Кое-где встречаются рекомендации не связываться с запросами, по которым в выдаче больше 4 «морд».
Настоятельно советую пооткрывать сайты ТОП-10 по данному запросу и на глаз оценить их конкурентный потенциал. Более подробных рекомендаций тут не даю, т. к. анализ сайтов-конкурентов – это тема для отдельного и долгого разговора.
В общем, фильтруем запросы, исходя из частотности и конкурентности. И не думайте, что второе прямо пропорционально первому.
В итоге
Итак, после мозгового штурма и фильтрации у нас в руках (в Блокноте, в gedit, в Excel, Calc или даже на бумажке) есть список ключевых слов. У меня для Оружейной получилось около трех сотен запросов. Форма их записи – свободная. Главное, чтобы вам было удобно.
Вот этих тем и ждет от Вас Общественность. Вот по этим запросам и надо выбирать тему для ВОСТРЕБОВАННЫХ статей.
Фрагмент семантического ядра Оружейной в процессе работы над ним. Не утверждаю, что это ядро — безусловный образец для подражания, но оно хотя бы дает представление о том, как МОЖЕТ выглядеть семантическое ядро..
Если вы указываете в ядре соответствующие запросам страницы, учтите, что теоретически одна страница может быть оптимизирована под несколько схожих запросов. Например, для этой статьи запросто: «семантическое ядро» и «семантическое ядро сайта».
Учтите так же, что семантическое ядро блога – это не статуя, а вполне себе живое образование, то есть, его можно и нужно менять по мере изменения вашего взгляда на собственный блог и наполнения его контентом. В этом еще одно отличие блога от коммерческого сайта, который зачастую предполагает более-менее постоянное содержимое.
AmeriFlux — Основные сайты AmeriFlux
AmeriFlux Core Sites — это башни потоков, управляющие PI и персонал которых согласились предоставлять своевременные, высококачественные и непрерывные данные в базу данных AmeriFlux. Они получают поддержку операций и инструментов от проекта AmeriFlux Management Project (AMP). Основная цель AMP — обеспечить сбор высококачественных данных с этих сайтов, которые представляют широкий спектр экосистем и мест в континентальной части США.AMP получает финансовую поддержку для основных сайтов AmeriFlux от Министерства энергетики, Управления науки, Программы изучения наземных экосистем.
В настоящее время существует 49 основных сайтов, поддерживающих AMP, в 12 кластерах и 2 отдельных сайтах. Еще два сайта (US-MOz и US-ARM) добровольно согласились на те же стандарты качества данных и доставки, что и основные сайты, поддерживаемые AMP, но не получают финансирования AMP. Исходные участки были выбраны после тщательного анализа в 2012-2013 гг. На основе представления экосистемы, длины предшествующей записи данных, качества существующих данных и установленной способности ИП участков обеспечивать преемственность в управлении участками.
Примечание. Кластер Core Site Cluster — это случай, когда поддержка одного основного основного сайта использовалась для поддержки нескольких сайтов. Например, поддержка менеджера данных гарантирует своевременный просмотр и обработку данных для нескольких сайтов.
Санта-Рита Мескит — US-SRM. Кредит Расс Скотт, USDA-ARS.
Текущие основные сайты с контактами
* Означает, что это «основной» сайт для этого основного кластера сайтов.
Гарвардский лес
- US-Ha1 * • Harvard Forest EMS Tower (HFR1): лиственный широколиственный лес
- US-Ha2 • Участок болиголова в Гарвардском лесу: вечнозеленый игольчатый лес: в основном болиголов
Билл Мангер, Гарвардский университет, [адрес электронной почты]
Государственный лес Морган Монро (MMSF)
- US-MMS * • Государственный лес Морган Монро: лиственный широколиственный лес
- US-BRG • Государственный лес Морган Монро
Ким Новик, Университет Индианы, [адрес электронной почты]
Рич Филлипс, [адрес электронной почты]
ChEAS (Исследование экосистемы атмосферы Chequamegon)
- США-Лос-Анджелес * • Лост-Крик: кустарниковое водно-болотное угодье (самый продолжительный участок притока водно-болотных угодий в США)
- US-Syv • Дикая природа Сильвания: старовозрастные (350 лет) зрелые северные лиственные леса
- US-PFa • Park Falls / WLEF (очень высокая башня): кустарник / заболоченный лес, смешанные хвойные / лиственные породы (50 лет)
- US-WCr • Willow Creek (спелые лиственные породы): спелые северные лиственные леса
- US-ALQ • Ручей Аллекуаш: постоянное водно-болотное угодье
Анкур Десаи, Висконсинский университет, [адрес электронной почты защищен]
Кен Дэвис, Государственный университет Пенсильвании, [адрес электронной почты защищен]
Градиент высоты Нью-Мексико (NMEG)
- US-Mpj * • Участок пинон-можжевельник (Mountainair): сосново-можжевеловый лес 2100 м
- US-Wjs • Участок можжевеловой саванны (Уиллард): открытый кустарник, 1925 м.
- US-Vcp • Национальный заповедник Валлес Кальдера: вечнозеленый хвойный лес (сосна Пондероза), 2542 м.
- US-Vcm • Национальный заповедник Валлес Кальдера: вечнозеленый хвойный лист (смешанный хвойный лес), 3000 м; Пожар 2012 г.
- US-Ses • Севиллета (пустынный кустарник LTER): открытый кустарник, 1593 м.
- US-Seg • Севиллета (пустынные луга LTER): пустынные луга, 1622 м.
- US-Vcs • Субальпийский смешанный хвойный лес: вечнозеленый хвойный лес, 2752 м.
Марси Литвак, Университет Нью-Мексико, [адрес электронной почты защищен]
Санта-Рита / Ореховое ущелье
- US-SRM * • Санта-Рита Мескит: полупустынные луга
- US-Wkg • Ореховое ущелье Кендалл Луга: пустынные луга, пастбища
- US-Whs • Кустарник Грецкого ореха Лаки-Хиллс: Кустарник пустыни Чихуахуа
- US-SRG • Луга Санта-Рита: полупустынные луга
Рассел Скотт, Западный регион USDA-ARS, [адрес электронной почты]
Тонзи / Вайра / Дельта
- США-тонна * • Ранчо Тонзи: Предгорья Сьерра — дубовая саванна, выпас
- US-Var • Ранчо Вайра • Ион: Предгорья Сьерры — дубовая саванна, пастбище
- US-Myb • Водно-болотные угодья Мэйберри: Дельта Сакраменто — водно-болотные угодья восстановлены, 2010 г.
- US-Tw1 • Остров Твитчелл (влажный запад): Дельта Сакраменто — водно-болотные угодья восстановлены в 1997 г. (заменено на US-Twt • Остров Твитчелл: Дельта Сакраменто — рисовые поля)
- US-Bi1 • Остров Боулдин Люцерна: пахотные земли
- US-Bi2 • Кукуруза о-ва Боулдин: пахотные земли
Деннис Балдокки, Калифорнийский университет в Беркли, [адрес электронной почты защищен]
Северная Каролина Сосна Лоблолли
- US-NC2 * • Плантация NC Loblolly: SE Loblolly Pine, управляемая
- US-NC3 • NC Loblolly: SE Loblolly Pine, управляемый
- US-NC4 • Национальный заповедник дикой природы «Река Аллигатор»: прибрежные лесные заболоченные территории с повышением уровня воды
Аско Норметс, Техас, A&M, [адрес электронной почты]
Джон Кинг, Государственный университет Северной Каролины, [адрес электронной почты защищен]
Нивот Ридж
- US-NR1 * • Лес хребта Нивот (LTER NWT1): субальпийский хвойный лес
Питер Бланкен, Университет Колорадо, [адрес электронной почты защищен]
Дэвид Боулинг, Университет штата Юта, [адрес электронной почты защищен]
Расс Монсон, Университет Аризоны, [защита электронной почты]
Биологическая станция Мичиганского университета (UMBS)
- US-UMB * • Биологическая станция Мичиганского университета: лиственный широколиственный лес
- US-UMd * • UMBS Нарушение: лиственный широколиственный лес, опыт сукцессии
- US-OWC • Old Woman Creek
Гил Борер, Государственный университет Огайо, [адрес электронной почты]
Кристофер Гоф, Университет Содружества Вирджинии, [адрес электронной почты защищен]
Rosemount
- US-Ro5 * • Rosemount: севооборот кукурузы / сои.Заменяет Ro1. См. Примечание .
- US-Ro4 • Rosemount: восстановленная прерия. Новый конец 2015 года. Заменяет Ro3. См. Примечание .
- US-Ro6 • Rosemount: севооборот кукуруза / соя / озимый покров с минимальной обработкой почвы. Заменяет Ro2. См. Примечание .
Примечание: севооборот кукурузы / сои, соответствующий стандарту Ro1 (более не активен). Система была переведена на новое месторождение в 2017 году (US-Ro5).
Примечание: сельскохозяйственная площадка Ro2-Alternative (более не действующая).Система перенесена в новое поле (US-Ro6).
Примечание: Ro3 — кукуруза / соя в многолетнем клевере кура. Выведен на пенсию в конце 2015 г. (US-Ro4)
Тим Гриффис, Университет Миннесоты, [адрес электронной почты защищен]
Хауленд Форест
- US-Ho1 * • Howland Forest (главная башня): с 1996 г.
- US-Ho2 • Лес Хауленд (западная башня): с 1999 г.
- US-Ho3 • Лес Хауленд (лесозаготовительная площадка): с 2003 г.
Дэвид Холлингер, Северный регион лесной службы Министерства сельского хозяйства США, [адрес электронной почты]
Сосна Метолиус
- US-Me2 * • Сосна Ponderosa Metolius средней выдержки: вечнозеленый хвойный лес, 64 года
- US-Me6 • Ожог молодой сосны Metolius: вечнозеленый хвойный лес, 20 лет, после пожара
Закон Беверли, Государственный университет Орегона, [адрес электронной почты защищен]
Мед
- US-Ne1 * • Орошаемая кукуруза непрерывного действия
- US-Ne2 • Орошаемая кукуруза / соя, без обработки почвы
- US-Ne3 • Осадки кукурузы / сои, без обработки почвы
Эндрю Сайкер, Университет Небраски-Линкольн, [адрес электронной почты защищен]
core-site.xml · GitHub
core-site.xml · GitHubМгновенно делитесь кодом, заметками и фрагментами.
| <собственность> | |
| | |
| | |
| | |
| <собственность> | |
| <имя> фс.defaultFS | |
| | |
| | |
| <собственность> | |
| | |
| | |
| <описание> | |
| Какие группы пользователей могут подключаться к прокси HDFS. | |
| * для всех. | |
| <собственность> | |
| | |
| | |
| <описание> | |
| Какие пользовательские хосты могут подключаться к прокси HDFS. | |
| * для всех. | |
| <собственность> | |
| | |
| | |
| | |
| <собственность> | |
| <имя> dfs.block.size | |
| | |
| | |
| <собственность> | |
| | |
| <значение> 0.0.0.0 | |
| <описание> | |
| определяет, к какому IP-адресу привязывается NameNode. | |
| 0.0.0.0 означает все доступно. | |
| <собственность> | |
| <имя> dfs.namenode.servicerpc-bind-host | |
| | |
| <описание> | |
| определяет, к какому IP-адресу привязывается NameNode. | |
| 0.0.0.0 означает все доступно. | |
| <собственность> | |
| <имя> dfs.namenode.http-bind-host | |
| | |
| <описание> | |
| определяет, к какому IP-адресу привязывается NameNode. | |
| 0.0.0.0 означает все доступно. | |
| <собственность> | |
| <имя> dfs.namenode.https-bind-host | |
| | |
| <описание> | |
| определяет, к какому IP-адресу привязывается NameNode. | |
| 0.0.0.0 означает все доступно. | |
| <собственность> | |
| <имя> nfs.dump.dir | |
| | |
| | |
| <собственность> | |
| | |
| | |
| <описание> | |
| Включите гистограммы задержки для запросов на чтение, запись и фиксацию. | |
| В этом примере единицей времени является 100 секунд. | |
| <собственность> | |
| | |
| | |
| <описание> Разрешения хоста для подключения к прокси. | |
| <собственность> | |
| | |
| | |
| | |
| <собственность> | |
| <имя> dfs.permissions.supergroup | |
| | |
| | |
| <собственность> | |
| <имя> mapreduce.framework.name | |
| | |
| <собственность> | |
| | |
| | |
| <собственность> | |
| <имя> mapreduce.reduce.memory.mb | |
| | |
| <собственность> | |
| | |
| | |
| <собственность> | |
| <имя> mapreduce.reduce.java.opts | |
| | |
| <собственность> | |
| | |
| | |
| <собственность> | |
| <имя> пряжа.app.mapreduce.am.resource.mb | |
| | |
| <собственность> | |
| | |
| | |
| <собственность> | |
| <имя> пряжа.nodemanager.resource.memory-mb | |
| | |
| <собственность> | |
| | |
| | |
| <собственность> | |
| <имя> пряжа.nodemanager.vmem-check-enabled | |
| | |
| | |
| <собственность> | |
| | |
| | |
| <описание> | |
| Соотношение между виртуальной памятью и физической памятью при установке памяти | |
| лимиты для контейнеров | |
| <собственность> | |
| <имя> пряжа.resourcemanager.resource-tracker.address | |
| | |
| <собственность> | |
| | |
| | |
| <собственность> | |
| <имя> пряжа.resourcemanager.address | |
| | |
CoreSite Realty: что вам нужно знать
В наши дни, когда технологические изменения меняются, единственное, на что вы можете рассчитывать, — это то, что компьютеры никуда не денутся в ближайшее время.Эта стабильность означает, что центры обработки данных и инвестиционные фонды в недвижимость облачных провайдеров (REIT) находятся на захватывающей траектории роста. Одним из основных игроков в секторе центров обработки данных является CoreSite Realty (NYSE: COR), базирующийся на восьми высокопроизводительных рынках США. Вот более подробный взгляд на компанию и ее финансовые показатели.
Профиль компании CoreSite Realty
CoreSite Realty — это центр обработки данных REIT, расположенный в Денвере. По состоянию на ноябрь 2020 года компании принадлежат 24 операционных центра обработки данных на восьми рынках в США, включая район залива Сан-Франциско, Лос-Анджелес, район Северной Вирджинии (включая Вашингтон Д.C.), район Нью-Йорка, Бостон, Чикаго, Денвер и Майами.
С момента своего основания в 2001 году CoreSite Realty получала доход за счет приобретения, разработки и эксплуатации недвижимости на рынке размещения центров обработки данных. Согласно его последнему годовому отчету, компания владеет более чем 4,6 миллиона квадратных футов чистой арендуемой площади (NRSF), из которых 2,6 миллиона NRSF в настоящее время находятся в эксплуатации.
REIT в настоящее время обслуживает более 1350 клиентов, которые в основном являются поставщиками облачных и ИТ-услуг (24%), поставщиками сетевых услуг (33%) или в сфере корпоративного и цифрового контента (41%).Однако всего компания обслуживает более 40 отраслей.
Подавляющая часть доходов компании поступает от доходов центров обработки данных, включая аренду, аренду электроэнергии и сопутствующие услуги. Однако они также получают доход от предложения решений для межсетевого взаимодействия. Небольшая часть их доходов (около 2,5 млн долларов, согласно отчету CoreSite о доходах за третий квартал 2020 г.) поступает от офисных помещений и помещений легкой промышленности.
Новости CoreSite Realty
CoreSite Realty планирует увеличить свои доходы за счет увеличения денежного потока в существующих объектах центра обработки данных, использования возможностей расширения, новых возможностей развития и приобретения, а также использования отношений с потребителями для привлечения новых клиентов доска.
В 2019 году компания продвинулась к своим целям, расширив свой существующий центр обработки данных в Рестоне, штат Вирджиния, на 50 000 квадратных футов, открыв новый центр обработки данных в центре Вашингтона, округ Колумбия, и приступив к строительству нового центра обработки данных недалеко от центра Чикаго на 169 000 квадратных метров. центр обработки данных квадратных футов.
В 2020 году многие REIT столкнулись с финансовыми трудностями из-за повсеместного увеличения числа сотрудников, начинающих работать удаленно во время пандемии COVID-19. Во всяком случае, текущие условия вынудили все больше полагаться на центры обработки данных.Как сообщается в презентации для инвесторов CoreSite за третий квартал 2020 года, возросшая зависимость, возможно, способствовала росту его чистой прибыли на 6,6% по сравнению с аналогичным периодом прошлого года.
Однако это не означает, что инвестирование в этот REIT не связано с определенным риском. Согласно последнему годовому отчету, к самым большим рискам, с которыми сталкивается бизнес и операции CoreSite Realty, относятся:
- Уязвимость к атакам кибербезопасности
- Зависимость от высокого уровня задолженности для продолжения своей коммерческой деятельности
К последнему пункту: поскольку в сегодняшних рыночных условиях технологии меняются так быстро, CoreSite опасается, что его информационная структура центра обработки данных может со временем устареть.
Стоимость акций CoreSite Realty
Примечательно, что CoreSite является одним из пяти основных REIT центров обработки данных, наряду с Equinix (NASDAQ: EQIX), QTS Realty Trust (NYSE: QTS), CyrusOne (NASDAQ: CONE), и Digital Realty Trust (NYSE: DLR.PK).
В то время как многие REIT недавно объявили о сокращении или полной приостановке своих общих дивидендов во время пандемии, REIT центров обработки данных сумели избежать этой участи. Тем не менее, из пяти основных игроков CoreSite дает максимальную доходность в 3 раза.9%. Для сравнения: Digital Realty составляет 3,2%, QTS — 2,9% и CyrusOne — 2,8%. Со своей стороны, Equinix выплачивает доходность всего 1,5%, но сохраняет большую часть своего денежного потока.
Помимо того, что CoreSite Realty лидирует по доходности, компания демонстрирует стабильный рост дивидендов на протяжении 10 лет работы на Нью-Йоркской фондовой бирже. В 2010 году он выплатил инвесторам 0,13 доллара в виде дивидендов, и с тех пор выплаты только выросли. По состоянию на 9 декабря 2020 года общие дивиденды за год составляли 4 доллара.89.
Нет сомнений в том, что CoreSite является крупным плательщиком дивидендов. Его общие дивиденды были на уровне 4 долларов в течение последних нескольких лет, а если быть точным, с 2018 года.
Итоги CoreSite Realty
Хотя CoreSite Realty не может быть центром обработки данных REIT, который генерирует самые фанфары (это был бы Equinix с его рыночной капитализацией в 65 миллиардов долларов), он показал сильную траекторию роста за последнее время. десятилетие. Хотя есть некоторые неотъемлемые риски, особенно высокий уровень обязательств по обслуживанию долга, похоже, что это хороший выбор для инвесторов, готовых принять риск.
Безопасность | Стеклянная дверь
Мы получаем подозрительную активность от вас или кого-то, кто пользуется вашей интернет-сетью. Подождите, пока мы убедимся, что вы настоящий человек. Ваш контент появится в ближайшее время. Если вы продолжаете видеть это сообщение, напишите нам чтобы сообщить нам, что у вас проблемы.
Nous aider à garder Glassdoor sécurisée
Nous avons reçu des activités suspectes venant de quelqu’un utilisant votre réseau internet.Подвеска Veuillez Patient que nous vérifions que vous êtes une vraie personne. Вотре содержание apparaîtra bientôt. Si vous continuez à voir ce message, veuillez envoyer un электронная почта à pour nous informer du désagrément.
Unterstützen Sie uns beim Schutz von Glassdoor
Wir haben einige verdächtige Aktivitäten von Ihnen oder von jemandem, der in ihrem Интернет-Netzwerk angemeldet ist, festgestellt. Bitte warten Sie, während wir überprüfen, ob Sie ein Mensch und kein Bot sind.Ihr Inhalt wird в Kürze angezeigt. Wenn Sie weiterhin diese Meldung erhalten, informieren Sie uns darüber bitte по электронной почте: .
We hebben verdachte activiteiten waargenomen op Glassdoor van iemand of iemand die uw internet netwerk deelt. Een momentje geduld totdat, мы выяснили, что u daadwerkelijk een persoon bent. Uw bijdrage zal spoedig te zien zijn. Als u deze melding blijft zien, электронная почта: om ons te laten weten dat uw проблема zich nog steeds voordoet.
Hemos estado detectando actividad sospechosa tuya o de alguien con quien compare tu red de Internet. Эспера mientras verificamos que eres una persona real. Tu contenido se mostrará en breve. Si Continúas recibiendo este mensaje, envía un correo electrónico a para informarnos de que tienes problemas.
Hemos estado percibiendo actividad sospechosa de ti o de alguien con quien compare tu red de Internet. Эспера mientras verificamos que eres una persona real.Tu contenido se mostrará en breve. Si Continúas recibiendo este mensaje, envía un correo electrónico a para hacernos saber que estás teniendo problemas.
Temos Recebido algumas atividades suspeitas de voiceê ou de alguém que esteja usando a mesma rede. Aguarde enquanto confirmamos que Você é Uma Pessoa de Verdade. Сеу контексто апаресера эм бреве. Caso продолжить Recebendo esta mensagem, envie um email para пункт нет informar sobre o проблема.
Abbiamo notato alcune attività sospette da parte tua o di una persona che condivide la tua rete Internet.Attendi mentre verifichiamo Che sei una persona reale. Il tuo contenuto verrà visualizzato a breve. Secontini visualizzare questo messaggio, invia un’e-mail all’indirizzo per informarci del проблема.
Пожалуйста, включите куки и перезагрузите страницу.
Этот процесс автоматический. Ваш браузер в ближайшее время перенаправит вас на запрошенный контент.
Подождите до 5 секунд…
Перенаправление…
Заводское обозначение: CF-102 / 62df40e4dc124985.
пиматген.Модуль core.sites — документация pymatgen 2022.0.4
пиматгенЭтот модуль определяет классы, представляющие непериодические и периодические сайты.
- класс
PeriodicSite( видов: Union [str, pymatgen.core.periodic_table.Element, pymatgen.core.periodic_table.Species, pymatgen.core.periodic_table.DummySpecies, dict, pymatgen.core.composition.Composition] , , координаты: Union [int, float, complex, str, bytes, numpy.generic, Sequence [Union [int, float, complex, str, bytes, numpy.generic]], Sequence [Sequence [Any]], numpy.typing._array_like._SupportsArray] , решетка: pymatgen.core.lattice.Lattice , to_unit_cell: bool = False , coords_are_cartesian: bool = False , свойства: Необязательно [dict] = Нет , skip_checks: bool = False ) [источник] ¶ Основания:
пиматген.core.sites.Site,monty.json.MSONableРасширение универсального объекта Site на периодические системы. PeriodicSite включает решетчатую систему.
Создайте периодический сайт.
- Параметры
виды —
Виды на участке. Возможно: я. Объект типа «композиция» (предпочтительно) II. Элемент / вид, указанный либо как строка
символа, например «Li», «Fe2 +», «P» или атомные номера, е.g., 3, 56, или фактические объекты Element или Species.
- iii. Диктограмма элементов / видов и заселенностей, например,
{«Fe»: 0,5, «Mn»: 0,5}. Это позволяет настроить неупорядоченные структуры.
координаты — декартовы координаты участка.
решетка — Решетка, связанная с сайтом.
to_unit_cell — переводит дробные координаты в основная элементарная ячейка, т.е.е. все дробные координаты удовлетворяют 0 <= a <1. По умолчанию - False.
coords_are_cartesian — Установите значение True, если вы предоставляете декартовы координаты. По умолчанию False.
properties — Свойства, связанные с сайтом как dict, например {«Магмом»: 5}. По умолчанию Нет.
skip_checks — Игнорировать ли все обычные проверки и просто создать сайт. Используйте это, если PeriodicSite создается в желательны контролируемая манера и скорость.
- недвижимость
a[источник] ¶ Дробная координата а
-
as_dict(подробность : int = 0 ) → dict [источник] ¶ Json-сериализуемое dict-представление PeriodicSite.
- Параметры
verbosity ( int ) — уровень детализации. По умолчанию 0 включает только матричное представление. Установите значение 1 для получения дополнительных сведений, например декартовы координаты и др.
- недвижимость
б[источник] ¶ Дробная координата b
- недвижимость
c[источник] ¶ Дробная координата c
- недвижимость
координаты[источник] ¶ Декартовы координаты
-
расстояние( other: pymatgen.core.sites.PeriodicSite , jimage: Необязательно [Union [int, float, complex, str, bytes, numpy.generic, Sequence [Union [int, float, complex, str, bytes, numpy.generic]], Sequence [Sequence [Any]], numpy.typing._array_like._SupportsArray]] = None ) [источник] ¶ Получите расстояние между двумя участками при периодических граничных условиях.
- Параметры
другие ( PeriodicSite ) — Другой сайт, от которого нужно уточнить расстояние.
jimage ( 3×1 array ) — конкретное периодическое изображение в терминах решетки переводы, эл.g., [1,0,0] означает взять периодический образ это на расстоянии одного вектора a-решетки. Если jimage — None, будет найдено ближайшее к сайту изображение.
- Возвращает
Расстояние между двумя участками
- Тип возврата
расстояние (поплавок)
-
distance_and_image( other: pymatgen.core.sites.PeriodicSite , jimage: Необязательно [Union [int, float, complex, str, bytes, numpy.общий, Последовательность [Объединение [int, float, complex, str, bytes, numpy.generic]], Последовательность [Sequence [Any]], numpy.typing._array_like._SupportsArray]] = None ) → Кортеж [float, numpy. ndarray] [источник] ¶ Получает расстояние и экземпляр между двумя сайтами, предполагая периодическую границу условия. Если индекс jimage двух сайтов атома j не указан, то он выбирает j-образное изображение, ближайшее к i-му атому, и возвращает расстояние и индексы jimage в терминах переносов векторов решетки. Если индекс jimage атома j указан, он возвращает расстояние между i-м атом и указанный атом jimage, также возвращается данное изображение jimage.
- Параметры
другие ( PeriodicSite ) — Другой сайт, от которого нужно уточнить расстояние.
jimage ( 3×1 array ) — конкретное периодическое изображение в терминах решетки переводы, например, [1,0,0] подразумевают получение периодического изображения это на расстоянии одного вектора a-решетки. Если jimage — None, будет найдено ближайшее к сайту изображение.
- Возвращает
дистанционные и периодические переводы решетки другого участка, для которого действует указанное расстояние.
- Тип возврата
(дистанция, jimage)
-
distance_and_image_from_frac_coords( fcoords: Union [int, float, complex, str, bytes, numpy.generic, Sequence [Union [int, float, complex, str, bytes, numpy.generic]], Sequence [Sequence [Any]] , numpy.typing._array_like._SupportsArray] , jimage: Необязательно [Union [int, float, complex, str, bytes, numpy.generic, Sequence [Union [int, float, complex, str, bytes, numpy.generic]], Sequence [Sequence [Any]], numpy.typing._array_like._SupportsArray]] = None ) → Tuple [float, numpy.ndarray] [source] ¶ Получает расстояние между сайтом и дробную координату, предполагая периодические граничные условия. Если индекс jimage двух узлов атома j не указан, он выбирает j-е изображение, ближайшее к i-му атому, и возвращает индексы расстояния и jimage в терминах вектора решетки переводы. Если указан индекс jimage атома j, он возвращает расстояние между атомом i и указанным атомом jimage, данное jimage также возвращается.
- Параметры
fcoords ( 3×1 array ) — координаты, от которых нужно определить расстояние.
jimage ( 3×1 array ) — конкретное периодическое изображение с точки зрения трансляции решетки, например [1,0,0], подразумевают периодические изображение, которое находится на расстоянии одного вектора a-решетки. Если jimage — None, будет найдено ближайшее к сайту изображение.
- Возвращает
дистанционные и периодические переводы решетки другого участка, для которого действует указанное расстояние.
- Тип возврата
(дистанция, jimage)
- недвижимость
frac_coords[источник] ¶ Дробные координаты
- classmethod
from_dict( d , lattice = None ) → pymatgen.core.sites.PeriodicSite [источник] ¶ Создайте PeriodicSite из представления dict.
- Параметры
d ( dict ) — dict представление PeriodicSite
решетка — Дополнительная решетка для отмены решетки, указанной в d.Полезно для обеспечения того, чтобы все сайты в структуре имели одинаковые решетка.
- Возвращает
PeriodicSite
-
is_periodic_image( other: pymatgen.core.sites.PeriodicSite , допуск : float = 1e-08 , check_lattice: bool = True ) → bool [источник] ¶ Возвращает True, если сайты являются периодическими изображениями друг друга.
- Параметры
прочие ( PeriodicSite ) — Другой сайт
Допуск ( float ) — Допуск для сравнения дробных координат
check_lattice ( bool ) — проверять, есть ли на двух сайтах такая же решетка.
- Возвращает
Верно, если сайты являются периодическими изображениями друг друга.
- Тип возврата
булев
- недвижимость
решетка[источник] ¶ Решетка, связанная с PeriodicSite
-
to_unit_cell( in_place = False ) → Необязательно [pymatgen.core.sites.PeriodicSite] [источник] ¶ Переместите координаты гидроразрыва в ячейку элементарной ячейки.
- недвижимость
x[источник] ¶ Декартова координата x
- недвижимость
y[источник] ¶ Декартова координата y
- недвижимость
z[источник] ¶ Декартова координата z
- класс
Участок( видов: Union [str, pymatgen.core.periodic_table.Element, pymatgen.core.periodic_table.Species, pymatgen.core.periodic_table.DummySpecies, dict, pymatgen.core.composition.Composition] , координаты: Union [int, float, complex, str, bytes, numpy .generic, Sequence [Union [int, float, complex, str, bytes, numpy.generic]], Sequence [Sequence [Any]], numpy.typing._array_like._SupportsArray] Свойства , : Необязательно [dict] = None , skip_checks: bool = False ) [источник] ¶ Базы:
сборников.abc.Hashable,monty.json.MSONableОбобщенный непериодический сайт . По сути, это композиция в точке пространства с некоторыми дополнительными свойствами, связанными с ней. А Состав используется для представления атомов и занятости, что позволяет неупорядоченное представление сайта. Координаты даны в стандартном декартовом формате. координаты.
Создает непериодический сайт.
- Параметры
виды —
Виды на участке.Возможно: я. Объект типа «композиция» (предпочтительно) II. Элемент / вид, указанный либо как строка
символа, например «Li», «Fe2 +», «P» или атомные номера, например, 3, 56 или фактические объекты Element или Species.
- iii. Диктограмма элементов / видов и заселенностей, например,
{«Fe»: 0,5, «Mn»: 0,5}. Это позволяет настроить неупорядоченные структуры.
координаты — декартовы координаты участка.
properties — Свойства, связанные с сайтом как dict, e.грамм. {«Магмом»: 5}. По умолчанию Нет.
skip_checks — Игнорировать ли все обычные проверки и просто создать сайт. Используйте это, если Сайт создан в контролируемой манера и скорость желательны.
-
as_dict() → dict [источник] ¶ Json-сериализуемое представление dict для сайта.
-
расстояние( другие ) → поплавок [источник] ¶ Получите расстояние между двумя сайтами.
- Параметры
прочее — Другой сайт.
- Возвращает
Расстояние (плавающее)
-
distance_from_point( pt ) → float [источник] ¶ Возвращает расстояние между сайтом и точкой в пространстве.
- Параметры
pt — декартовы координаты точки.
- Возвращает
Расстояние (плавающее)
- classmethod
from_dict( d: dict ) → pymatgen.core.sites.Site [источник] ¶ Создать сайт из представления dict
- недвижимость
is_ordered[источник] ¶ Верно, если сайт является заказанным сайтом, т. Е. С одним видом с вместимость 1.
-
position_atol= 1e-05 [источник] ¶
- недвижимость
экз[источник] ¶ Вид / Элемент на сайте.Работает только для заказанных сайтов. Иначе возникает AttributeError. Используйте это свойство экономно. Крепкий вместо этого при проектировании следует использовать свойства вида. Обратите внимание, что единичный вид — это тоже вид. Итак, выбор этой переменной name управляется программными проблемами, а не грамматикой.
- Повышает
AttributeError, если сайт не заказан. –
- объект недвижимости
видов[источник] ¶ Вид на участке в составе, эл.г., Fe0.5Mn0.5.
- Тип
возврат
- недвижимость
разновидностей_and_occu[источник] ¶
- недвижимость
разновидностей_строка[источник] ¶ Строковое представление видов на сайте.
- недвижимость
x[источник] ¶ Декартова координата x
- недвижимость
y[источник] ¶ Декартова координата y
- недвижимость
z[источник] ¶ Декартова координата z
© Copyright 2011, Команда разработчиков Pymatgen
Создан с помощью Sphinx с использованием тема предоставлено Read the Docs.Ядров — Ядров
Нажать
ПРИОБРЕСТИ ЛУЧШЕЕ МЕСТА ДЛЯ ЖИЗНИ
Мы ищем не только безопасные идеи, но и те, кто меняет правила игры. Мы наращиваем возможности, делая инновации частью своей работы, независимо от вашей роли. И мы сосредотачиваемся на том, что нужно построить, зная, что волнует наших жителей. Вот как мы произвели революцию в жилищном строительстве для студентов и продолжаем изобретать лучшие места для жизни.
блеск
ПОЛУЧИТЕ СЕБЯ
Мы — уникальный состав персонажей из самых разных сфер деятельности. Чтобы вписаться в него, вы должны быть полноценным, подлинным «я». Эта энергия объединяет нас. Стены растворяются. Поток идей. Заголовки и иерархия значат меньше. Мы больше смеемся и больше выигрываем. Строятся и другие места, где люди могут жить лучше всего.
Рост
ВСЕГДА СТАНОВИТСЯ ЛУЧШЕ
Ошибки — реактивное топливо для роста.Мы живем в соответствии с этим мышлением, давая людям возможность действовать. Мы поощряем эксперименты и препятствуем выходу из себя, когда дела идут плохо. Когда пыль оседает, мы вырезаем то, что не сработало, и удваиваем то, что сработало. Чтобы так работать, нужно смелость. Но это держит нас на вершине нашей игры и дает нам возможность расти дальше.
Шлифовка
ПЕРЕВОЗКА ПРЕПЯТСТВИЙ
Мы стремимся к достижению нашего видения лучшего проживания в отеле.Мы тратим ресурсы, придумывая новые способы использовать то, что у нас есть, для достижения цели. И мы приучаем себя решать стоящую перед нами проблему, пока она не будет решена. Затем мы приступаем к работе над следующим.
Подъемник
ПОМОГИТЕ ДРУГУ ВЫИГРАТЬ
Мы постоянно ищем способы сделать так, чтобы окружающие нас люди хорошо выглядели. В результате такого поведения возникает наша командная работа. Люди поднимаются и делают друг другу добро.Построение более глубоких и сильных отношений, чем просто коллег — внутри и за пределами Core.
Uphold
НИКОГДА НЕ ПЕРЕРЫВАЙТЕ ДОВЕРИЕ
Когда мы заключаем сделку, мы следим за тем, чтобы она была выгодна всем — нашим резидентам, инвесторам и нам самим. Мы информируем заинтересованные стороны с помощью прозрачных коммуникаций. И мы заботимся о жителях, как о самых важных людях в мире. Благодаря этой честности партнеры любят работать с нами, а жители любят жить с нами.
CoreSite Realty Corporation | Nareit
Alexander & Baldwin (NYSEMKT: ALEX) объявили об отставке Джеймса Мида, исполнительного вице-президента и финансового директора, начиная с 15 ноября. Компания также сообщила, что Франсиско Гутьеррес назначен старшим вице-президентом по развитию. Гутьеррес в последнее время занимал должность старшего директора по развитию в GGP.
Cousins Properties Inc. (NYSE: CUZ) назначила Колина Коннолли генеральным директором, начиная с января.1 января 2019 г. Ларри Геллерштедт, нынешний председатель и главный исполнительный директор, станет исполнительным председателем. В июле 2017 года Коннолли был назначен президентом, и этот титул он сохранит в дополнение к своей роли генерального директора.
CyrusOne Inc. (NASDAQ: CONE) назначила Марка Скомала старшим вице-президентом и главным бухгалтером.
Чарльз Мейерс был назначен президентом и главным исполнительным директором Equinix, Inc. (NASDAQ: EQIX). Он сменил Питера Ван Кэмпа, который исполнял обязанности генерального директора с января 2018 года.Ван Кэмп возобновил свою роль исполнительного председателя. Мейерс присоединился к Equinix в 2010 году в качестве президента Северной и Южной Америки. В 2013 году он был назначен операционным директором, а в прошлом году занимал должность президента по стратегии, услугам и инновациям (SSI).
Equity Residential (NYSE: EQR) сообщил, что президент и генеральный директор Дэвид Нитеркат уйдет на пенсию 31 декабря. Марк Паррелл, который в настоящее время является исполнительным вице-президентом и финансовым директором, был назначен президентом и сменит Neithercut на посту генерального директора в конце года. . Ниитеркат не занимал посты президента и генерального директора с 2006 года.Он останется членом совета директоров после выхода на пенсию. В 2015 году Неизеркат занимал должность председателя Нарейт.
Грир Авив присоединился к Iron Mountain Inc. (NYSE: IRM) в качестве старшего вице-президента по связям с инвесторами. Она заменила Мелиссу Марсден, которая ушла на пенсию после шести лет работы в компании и более 35 лет работы в сфере отношений с инвесторами. В последнее время Авив занимал должность вице-президента по связям с инвесторами и корпоративным коммуникациям в CoreSite Realty Corp. (NYSE: COR).
PREIT (NYSE: PEI) сообщил, что Джонатен Белл, старший вице-президент и главный бухгалтер, покинул компанию. Помимо своей постоянной роли финансового директора, Роберт Маккадден взял на себя обязанности главного бухгалтера Белла.
PS Business Parks, Inc. (NYSE: PSB) назначил Джеффри Хеджеса исполнительным вице-президентом, финансовым директором и секретарем и объявил о повышении Трентона Гроувса до старшего вице-президента, главного бухгалтера и помощника секретаря.Hedges присоединяется к бизнес-паркам PS из Invitation Homes (NYSE: INVH).
Urban Edge Properties (NYSE: UE) назначил Криса Вейлминстера главным операционным директором и Дона Бриггса президентом по развитию, вступившие в силу 31 декабря 2018 г. или ранее. Роберт Минутоли, который в настоящее время является операционным директором, планирует уйти на пенсию через год конец. Вайльминстер и Бриггс оба присоединились к Urban Edge из Federal Realty Investment Trust (NYSE: FRT), где они занимали руководящие должности.
Welltower Inc. (NYSE: WELL) повысил Шанха Митру до исполнительного вице-президента и ИТ-директора с его предыдущей должности старшего вице-президента по инвестициям. Тим МакХью был назначен старшим вице-президентом по корпоративным финансам с предыдущей должности вице-президента по финансам и инвестициям. Дойл Саймонс, президент и главный исполнительный директор Weyerhaeuser Co. (NYSE: WY), объявил о своем намерении уйти в отставку. Его сменит Девин Стокфиш 1 января 2019 года. Стокфиш является старшим вице-президентом по лесоматериалам с 1 января 2019 года.1, 2018. Ранее Stockfish занимал должности старшего вице-президента компании, главного юрисконсульта и корпоративного секретаря, а также вице-президента Western Timberlands. Саймонс уйдет из совета директоров 1 января 2019 г. и будет исполнять обязанности старшего советника до выхода на пенсию 1 апреля 2019 г.
.