
Атрибут rel=canonical
Привет, друзья! Я уже писал про дубли страниц и то какой вред они могут нанести сайту. Сегодняшняя тема напрямую связана с этим явлением. Я расскажу про атрибут rel=canonical.
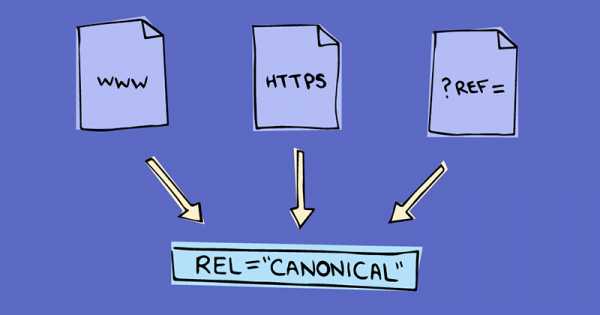
Атрибут rel=canonical был введен Google 12 февраля 2009 года. Он учитывается до сих пор, поисковой системой Яндекс в том числе. Атрибут rel=canonical указывает поисковым роботам какая страница является предпочтительной при индексации, если на сайте имеется несколько страниц с одинаковым содержимым, но с разными URL-адресами.
Допустим существует 2 страницы:
http://nazyrov.ru/chto-takoe-alexa-rank.html
http://nazyrov.ru/chto-takoe-alexa-rank.html?id=4535
В данном случае первая страница является основной, именно для нее и должен быть прописан атрибут rel=canonical. А вторая страница является лишь ее копией, но с другим URL-адресом. Следовательно, если не будет прописан rel=canonical, то поисковая система будет индексировать как основной адрес, так и дубль страницы.
Конечно, поисковые системы не глупы и со временем выкинут дубль из индекса, но на это требуется время. А если сайт ежедневно пополняется несколькими сотнями новых страниц, то отсутствие указания канонического URL-адреса может негативно сказаться на продвижении.
Возьмем интернет магазин с 10 000 товарами. У каждого товара на сайте своя страница и несколько дублей. Представляете как подпортит продвижение сайта могут 20 000 дублированных страниц?
Откуда берутся неканонические страницы на сайте
Неканонические страницы или дубли генерируют движки управления, такие как WordPress, phpBB и прочие. Если у вас сайт написан на чистом HTML, то дублированных страниц в принципе быть не должно, если только вы их специально не добавляли конечно.
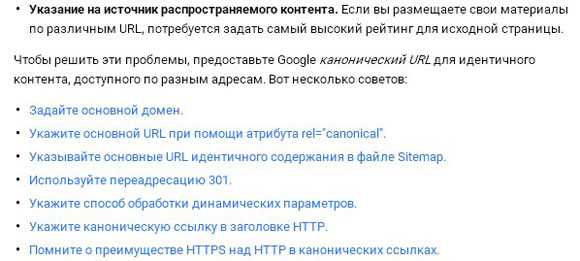
Если мы обратимся к справочнику вебмастера в Google и Яндекс, то увидим следующее:
Сообщение Google
Рекомендации Яндекс
Указание атрибута rel=canonical не является строгой директивой. При отсутствии данного атрибута, поисковые системы попытаются определить каноническую страницу самостоятельно.
Как прописать атрибут rel=canonical
С тех пор, как Google ввел данный атрибут, прошло много времени и практически на всех CMS и конструкторах сайтов есть возможность его прописать. В конструкторах сайтов он обычно прописывается автоматически, а для движков существуют дополнения в виде модулей и плагинов.
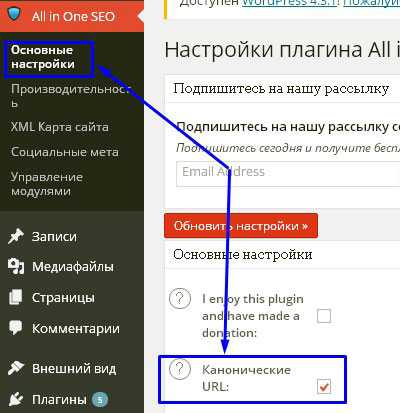
Если взять CMS WordPress, то практически все SEO плагины предоставляют возможность прописать канонический URL автоматически. Я пользуюсь плагином All In One Seo Pack, поэтому покажу на его примере.
В настройках плагина нужно отметить галочкой, чтобы автоматически прописывались канонические URL-адреса.
Если взглянем на исходный код страницы, то увидим что rel=canonical прописан. И если поисковый робот зайдет на этот дубль страницы, то увидит, что страница не является основной.
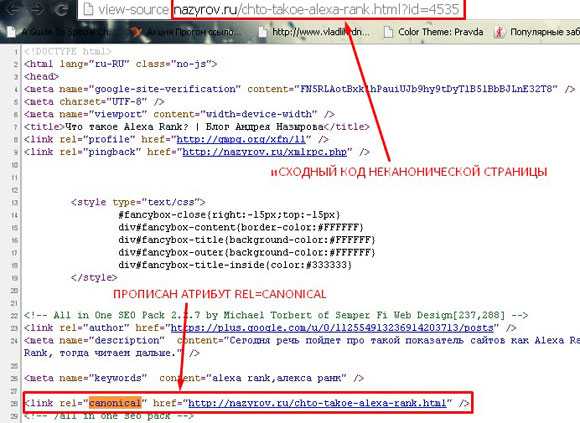
Вот такой вот интересный атрибут. Конечно, ничего нового я вам не открыл. Но почему-то многие не обращают внимания на вот такие мелочи, особенно владельцы небольших интернет-магазинов.
nazyrov.ru
Исключенные страницы: документ является неканоническим
Очень странная произошла вещь с одним сайтом, созданном на OpenCart. Все страницы выпали из индекса Яндекса — осталось только одна — главная. Первая мысль — сайт попал под фильтр. Но это не обычный сайт, а интернет-магазин, который, кстати, приносит доход его владельцу.
Я впервые написал Платону Щукину с просьбой указать причину происшедшего.
Что же это могло произойти? Описание товаров почти все уникальные, сайт еще не продвигался и обратных ссылок пока нет.
 baranq / Shutterstock.com
baranq / Shutterstock.comВ панели Яндекс.Вебастера в разделе «Исключенные страницы» находится информация о страницах, которые не были проиндексированы роботом.
В этом разделе находится информация о страницах, которые не были проиндексированы роботом при посещении сайта. Часто индексирование страниц намеренно запрещается вебмастером – это не является ошибкой и исправления не требует. Иногда могут возникать неполадки на стороне вашего сервера или сайта, что ведет к нежелательному исключению страниц, в этом случае проблему рекомендуется устранить.
В настройках вы самостоятельно можете указать, к какой категории относится та или иная причина исключения.
Я проверил все три категории
Ресурс не найден
Там все ОК, судя по всему кто-то набирал УРЛ в адресной строке и ошибся.
Документ запрещен в файле robots.txt
Я проверил, здесь всё правильно, эти страницы индексировать не нужно.
/index.php?route=account/account |
/index.php?route=account/address |
/index.php?route=account/download |
/index.php?route=account/edit |
/index.php?route=account/forgotten |
/index.php?route=account/login |
/index.php?route=account/newsletter |
/index.php?route=account/order |
/index.php?route=account/password |
/index.php?route=account/register |
/index.php?route=account/return |
/index.php?route=account/return/insert |
З/index.php?route=account/transaction |
/index.php?route=account/wishlist |
/index.php?route=affiliate/account |
/index.php?route=checkout/cart |
/index.php?route=checkout/checkout |
/index.php?route=checkout/quickcheckout |
/index.php?route=checkout/voucher |
/index.php?route=product/search |
/index.php?route=product/search&filter_tag=Product Name |
Документ является неканоническим
А вот тут уже интересно.
В коде документа в тэге содержится параметр rel=»canonical», содержащий канонический адрес страницы, по которому она индексируется роботом. Как правило, тег с атрибутом rel=»canonical» прописывают на дублирующих страницах сайта, в этом случае ничего исправлять не требуется.
Если страницы дублями не являются и должны индексироваться роботом, то вам необходимо убрать атрибут из их исходного кода. Более подробную информацию об использовании rel=»canonical» вы можете прочитать на следующей странице нашей Помощи.
Также в этом разделе могут присутствовать страницы, содержащие в коде документа мета-тег, и поэтому вместо них индексируются html-версии. Подробнее об индексировании AJAX-сайтов вы также можете прочитать в нашей Помощи.
Далее идет список УРЛ карточек продуктов (здесь их приводить не буду).
Теперь давайте размышлять вместе. Значит так. Что мы имеем? >Недоработку в OpenCart или странную реакцию Яндекса?
Смотрим что находится в коде страницы товара. Да там есть тег <link> с параметром rel=»canonical».
<link href="//site.ru/product-name" rel="canonical" />
Дело в том, что УРЛ, указанный в теге <link> совпадает с УРЛ самой страницы. Она что камикадзе? Что за суицит такой? Я понимаю, если бы УРЛ страницы, в коде которой был бы этот тег, указывающий на оригинал, тогда вопросов нет.
Теперь проверяем страницу этого поста моего блога, который работает на Вордпресс.
<link rel="canonical" href="//www.fortress-design.com/isklyuchennye-stranicy-dokument-yavlyaetsya-nekanonicheskim/" />
И что? И чем отличаются теги на этих двух страницах? Только тем, что у OpenCart rel="canonical" после ссылки, у WordPress — вначале. Но при этом мой блог отлично индексируется. Почему так? Где логика?
Значит Яндекс думает, что в Опенкарт эти карточки товара неканонические, а являются дублями оригинальных страниц. Но они как раз и являются оригиналами. Мда, наверное придется убирать из кода этот тег. Зачем мне проблемы? То что не нужно, я и сам закрою от индексации в robots.txt.
Читаем из Помощи Яндекса
Атрибут rel=»canonical» тега <link>
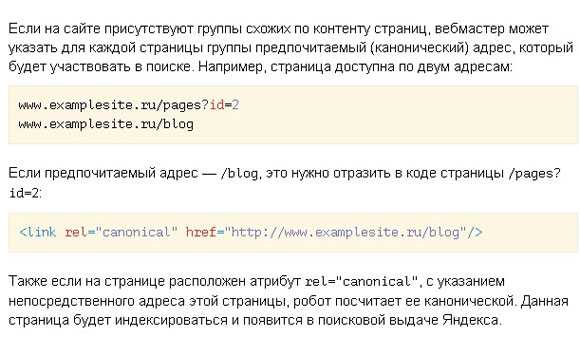
Если на сайте присутствуют группы схожих по контенту страниц, вебмастер может указать для каждой страницы группы предпочитаемый (канонический) адрес, который будет участвовать в поиске. Например, страница доступна по двум адресам:
<code>www.site.ru/pages?id=2 www.site.ru/blog</code>
Если предпочитаемый адрес — /blog, это нужно отразить в коде страницы /pages?id=2:
<code><link rel="canonical" href="//www.examplesite.ru/blog"/></code>
Робот считает ссылку с атрибутом rel=»canonical» не строгой директивой, а предлагаемым вариантом, который учитывается, но может быть проигнорирован.
Например, робот может не использовать указанный вами адрес, если:
- Документ по каноническому адресу недоступен для индексирования.
- В качестве канонического адреса указывается URL в другом домене или поддомене.
- Вы указали несколько канонических адресов.
fortress-design.com
Канонические URL адреса страниц или link rel=»canonical»
Что такое канонические URL адреса?
В широком смысле слова, канонический означает «принятый за образец», «твердо установленный». То есть, канонический URL это, грубо говоря, основной адрес страницы.
Обычно, один материал имеет один URL адрес, к примеру www.example.ru/1.html. Но иногда одна и так же страница может быть доступна по нескольким адресам. К примеру:
Предположим, что www.example.ru/1.html был выбран в качестве основного URL. Тогда на странице с данным адресом (а так же, других страницах с копией контента) необходимо разместить следующий элемент:
<link rel="canonical" href="www.example.ru/1.html" />Размещается он в шапке сайта, между тегов <head></head>.
Внимание! Что бы снизить вероятность ошибки, внутри элемента link rel=»canonical» необходимо использовать абсолютные, а не относительные адреса. То есть, добавлять к ссылке домен.
Убедитесь, что в технической карте сайта sitemap.xml размещены именно канонические ссылки. Иначе это может привести к ошибкам индексирования.
Примеры канонических адресов
Предположим, что мы создали статью о продвижении Интернет-магазина одежды, для которой сделали красивый, понятный для человека URL.
Но статья осталась доступна по техническому адресу, который мы больше видеть не хотим.
В этом случае, на странице со статьей, нам необходимо прописать элемент <link rel=»canonical» href=»https://dh-agency.ru/prodvijenie-magazina-odejdy/» />, в котором указан основной, канонический адрес.
Вот таким образом:
Теперь адрес https://dh-agency.ru/prodvijenie-magazina-odejdy/ будет считаться основным.
Роль канонических адресов страниц в SEO
С точки зрения поисковой оптимизации, наличие одного основного URL адреса страницы просто необходимо. Во-первых, это позволяет сэкономить время, так как роботу не приходится загружать копии контента. Во-вторых, не остается никаких сомнений, какой адрес должен участвовать в поисковой выдаче. В-третьих, снижается нагрузка на сайт, что так-же важно для посещаемого ресурса.
Нужно понимать, что краулер отводит ограниченное количество времени на индексацию сайта, поэтому многочисленные дубли страниц могут сильно ударить по эффективности его работы.
Правильно устанавливаем канонические URL адреса
Правильно установленный канонический адрес отвечает следующим требованиям:
Каноническая страница, указанная в элементе link rel=»canonical», обязательно должна существовать и быть доступна для пользователей;
Канонический адрес должен быть указан только для одного домена и поддомена. Грубо говоря, не должно быть ссылок на другие ресурсы;
Для страницы может быть указан один единственный канонический адрес;
Убедитесь, что на сайте отсутствуют рекурсии или «цепочки» канонических адресов. То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;
Элемент link rel=»canonical» должен находится между тегами <head></head>.
Уверены, что Ваши канонические адреса соответствуют всем вышеуказанным требованиям? Тогда можете считать их просто превосходными!
Понятие «каноническая ссылка»
Те, кто только начал окунаться в основы поисковой оптимизации, иногда разделяют понятия «канонический адрес» и «каноническая ссылка». На самом деле, речь идет об одном и том же — о главном URL адресе страницы.
Нет никаких канонических <a href=»»> </a> и «главных ссылок ссылок для перелинковки».
301 редирект — замена rel=»canonical»?
Когда речь заходит о выборе между 301 редиректом и элементом link rel=»canonical», мы обычно советуем использовать именно переадресацию. Все дело в том, что тег link rel=»canonical» не является обязательным, то есть, может быть проигнорирован поисковой системой.
Использование link rel=»canonical» актуально только тогда, когда сделать 301 редирект невозможно или проблематично.
Есть и еще один плюс link rel=»canonical» перед 301 редиректом — его простановку возможно сделать автоматической при создании страницы. К примеру, в WordPress эта функция уже реализована. То есть, заранее указав канонический адрес, Вы можете избавить себя от будущих проблем с индексацией.
Яндекс Вебмастер — статус «неканоническая»
В Яндекс Вебмастере есть раздел «Исключенные страницы«, добраться туда можно из меню «Индексирование» -> «Страницы в поиске» -> «Исключенные страницы«.
Перейдя в этот раздел, Вы увидите все материалы, которые были по какой либо причине загружены в базу, но исключены из поиска.
Среди прочих причин исключения Вы можете увидеть статус «Неканоническая». Нажав на троеточие, отроется сообщение следующего вида:
«Страница проиндексирована по каноническому адресу https://dh-agency.ru/category/vnutrennyaya-optimizaciya/design/, который был указан в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут canonical, если он указан некорректно. Робот отследит изменения автоматически.»
Что это значит?
Ничего страшного не произошло. Робот Яндекса проиндексировал страницу по первому (написанному синем шрифтом) URL, при этом на самой странице стоял элемент link rel=»canonical», в котором, в качестве канонического, был указан другой адрес (написанный серым шрифтом).
Пользуясь данной инструкцией, робот исключил неканонический URL.
Переживать, что материал был полностью исключен из поиска не стоит, он находится в выдаче, но по другому URL адресу.
Что с этим делать?
Если Вас не устраивает URL, который был выбран в качестве основного, необходимо поменять адрес в элементе link rel=»canonical» на предпочтительный. После изменения, страницу желательно отправить на переобход индексирующему роботу.
(«Индексирование» -> «Переобход страниц«)
Так изменения будут загружены в базу в самое ближайшее время.
Только не забудьте изменить адрес в файле sitemap.xml.
dh-agency.ru
Яндекс выкинул мои страницы как неканонические, но это не правда. — Яндекс
Здравствуйте.
Пожалуйста не проходите мимо. У меня вот такая проблема:
всего товаров выставлено >800, в поиске всего 320,
http://joxi.ru/PafHU_3JTJDfRxZa8fc
остальные страницы исключены как неканонические. Обратилась техподдержку, где арендован магазин, Что у них там с каноническими урлами.. у них все ок.
вот пример:
выставлены на сайт 800. товаров, не страниц. это значит что_500 ТОВАРОВ_ отсутствуют в поиске. страниц же за счет дублирования в разных категориях значительно больше.
вот результат по товару, которое находится в 4 категориях- все 4 страницы с одним платьем не участвуют в поиске. т.е.- одна страница должна участвовать в поиске. а не участвует НИ ОДНА. и ни одна из этих страниц не является _новой_.
http://joxi.ru/hZzHU4wyTJDELl7Tz_w
http://joxi.ru/m5zHU4wyTJBSOENc2o0
http://joxi.ru/uJzHU4wyTJBROC1oB70
http://joxi.ru/_pzHU_3JTJDjR_PLvLE
http://joxi.ru/FZ3HU_3JTJDoR_pDzxI
техподдержка платформы дала такой ответ и отправила с вопросом к яндексу:
Каждый товар, помимо того, что доступен по отдельному адресу в каждой из категорий, где он расположен, имеет ещё 2 адреса.
Если говорить о товаре «Свадебное платье Тесс», то эти адреса:
…./product/svadebnoe-platie-tess
…/product_by_id/27108258
,которые каноническими не являются и не должны таковыми быть.
Что касается категорий, то канонический адрес вот этот:
…./collection/kategoriya/product/svadebnoe-platie-tess
Собственно, он попадает в исходный код для всех страниц-дублей, здесь всё верно. Если Яндекс по-прежнему считает каноническим адрес с какой-либо другой категорией, имеет смысл уточнить непосредственно у специалистов поддержки Яндекса, по какой причине так происходит. Их ответ можно будет переслать нам, если что-то будет непонятно.
Ответ яндекса:
Мы проверили, Ваш сайт присутствует в поиске и находится пользователями, но некоторые его страницы, включая ….. /collection/kategoriya/product/svadebnoe-platie-tesshttp:// …/collection/kategoriya/product/svadebnoe-platie-tess, действительно отсутствуют в выдаче, при этом они не являются неканоническими, и никаких санкций на них не наложено. Дело в том, что наши алгоритмы устроены так, чтобы на запросы пользователей давать наиболее полный ответ, и в связи с этим в поисковую базу попадают наиболее релевантные документы ( http://help.yandex.ru/webmaster/yandex-indexing/excluded-pages.xml ).
В то же время наш робот помнит о других страницах сайта, если на них присутствуют ссылки, он периодически посещает их, и со временем они также могут быть включены в поиск. Помимо этого мы всегда работаем над совершенствованием алгоритма, принимающего решение по включению страниц в выдачу. И пример Вашего сайта передан в поисковый отдел нашей компании для анализа и последующего улучшения алгоритма.
Продолжайте работать над развитием Вашего ресурса, ориентируясь на его посетителей, и со временем число его страниц, участвующих в поиске, может увеличиться. С некоторыми нашими рекомендациями Вы можете ознакомиться в Помощи:
http://help.yandex.ru/webmaster/recommendations/targeting.xml ;
http://help.yandex.ru/webmaster/recommendations/presentation.xml .
И я теперь совсем не понимаю, что мне делать. Я пишу/покупаю уникальные тексты, вешаю их постепенно на все страницы, покупаю директ, твиты, посты пр. и прочее и тд. Но что делать, если это бесполезно- у яндекса такие алгоритмы. В приведенном примере- уникальный товар, картинка, описание..
Я буду вам очень признательна за небольшую консультацию.
talk.pr-cy.ru
Нужен ли атрибут rel=’canonical’ в оригинале
Путь к успеху 341
Очень рекомендую просмотреть это замечательное видео. Честно говоря, я впервые смотрел видео-интервью с Радиславом Гандапасом.
Интернет-маркетинг 64
СодержаниеБольшие пользовательские данныеАтрибуция как основа мобильной аналитикиКак оценить эффективность размещения онлайн-видеорекламы с позиций бизнесаЗапуск
Лассо удобный и очень полезный инструмент. Есть еще магнитное лассо, к которым я почти
Темы 2 468
Адаптивная, SEO оптимизированная, с микроразметкой, валидная, со смайликами, слайдером, спойлерами, кастомными виджетами, расширенным форматированием,
fortress-design.com
Яндекс.Вебмастер расскажет больше об исключенных страницах
Пост в архиве.
1 ноября 2012, 18:47
На этапе загрузки или обработки страниц поисковый робот может столкнуться с различными препятствиями, которые не позволяют ему проиндексировать документы. На сервисе Яндекс.Вебмастер есть раздел «Исключенные страницы» — там вы найдете подробную информацию о таких страницах и о причинах их исключения.
Наличие исключенных страниц на сайте — это нормальная ситуация, не всегда требующая исправления. Например, какие-то страницы на вашем сайте перестают существовать или вы сами запрещаете их индексирование в robots.txt. Но иногда проблемы возникают на стороне сервера или сайта, и это, как правило, приводит к нежелательному выпадению страниц из результатов поиска.
Не так давно мы обновили раздел «Исключенные страницы» и разделили все причины исключения на три группы:
Ошибки на стороне сервера или сайта
На эту группу стоит обратить внимание в первую очередь – в этом случае вам необходимо устранить причину возникновения этих ошибок.
Страницы запрещены к индексированию вебмастером или не существуют
Здесь, как правило, ничего исправлять не нужно. В этом разделе показывается информация об удаленных и более не существующих на сайте страницах, о страницах, запрещенных в robots.txt, неканонических страницах и т.д.
Не поддерживается роботом
Сюда попадают страницы с неподдерживаемым форматом, языком и т.п.
Такое разделение помогает понять, что необходимо исправить, а что исправлять не требуется. Если какая-то причина исключения конкретно для вашего сайта не является ошибкой, вы всегда можете самостоятельно внести изменения в разделе «Настройки», выбрав «Исключенные страницы». Смотрите также Справочник по ошибкам индексирования.
Кроме того, на графике в разделе «Общая информация о сайте» теперь показываются данные только о страницах из первой группы (которые были исключены по причине ошибок на стороне сервера или сайта), что помогает максимально быстро обнаружить проблему во взаимодействии вашего сайта с поисковой системой.
webmaster.yandex.ru
Что такое canonical, как и зачем его настраивать
Зачем нужны canonical-адреса
Канонический URL (canonical) позволяет указать поисковой системе, какая ссылка является предпочтительной для индексации. Настройкой canonical необходимо заниматься, если у вас на сайте имеются страницы с одинаковым содержанием. Ввиду особенностей CMS сайта могут автоматически создаваться страницы с одним и тем же контентом по разным адресам URL (более подробно читайте ниже). Появление подобных страниц возможно вследствие таких причин:
- Если вы написали одно и то же сообщение в разных темах блога, то есть вероятность автоматического создания еще одной страницы сайта.
- Например, у вас есть несколько доменов: http://article.example.com и http://blogs.example.com. И вы планируете размещать информацию сразу на обоих ресурсах. В таком случае размещаемый контент будет дублированным.
- Если была обновлена структура вашего сайта, после чего URL страниц сайта могли быть изменены.
Чтобы не допустить дублирования страниц сайта в поисковой выдаче, необходимо настроить канонические URL, после чего поисковик сможет определить, какую страницу нужно индексировать. Рассмотрим причины, из-за которых важно заниматься настройкой canonical:
- Если на разных страницах вашего сайта публикуется частично или полностью идентичная информация, то следует указать, какую страницу следует считать основной.
- Одна и та же информация, размещенная на разных страницах, затрудняет получение статистики о данных страницах.
Как настроить канонические адреса
Рассмотрим способы настройки «канонических» URL:
- Следует указать, какой URL считается основным. Сделать это можно при помощи атрибута rel=»canonical» тега link. Например, на сайте присутствует несколько страниц с идентичным содержимым. Для того чтобы задать URL https://example.com/buyingcar в качестве основного, указываем на страницах с дублируемым контентом в блоке head кода страницы тег вида <link rel=»canonical» href=»https://example.com/buyingcar» />. В данной ситуации вы задаете главный URL, который в дальнейшем будет использован для просмотра сообщения о покупке автомобилей. Также эта страница будет показываться в результатах поисковой выдачи. Предпочтительнее задавать адрес сайта в абсолютном виде (https://example.com/buyingcar), избегайте относительных путей (/buyingcar).
- В карту сайта добавляем только канонические URL, в таком случае вы сможете сообщить поисковому роботу, какие страницы сайта вы считаете основными. При индексировании сайта поисковой робот не будет заходить на неканонические страницы, тем самым быстрее индексируя сайт.
- Для различных CMS существуют различные плагины, которые позволяют настроить канонические URL, например, для WordPress можно воспользоваться Yoast SEO.
Для OpenCart настройка атрибута canonical производится средствами CMS. Необходимо зайти в настройки товара и задать параметр SEO URL.
Для настройки canonical в Joomla нужно включить в настройках CMS функцию SEF. После включения для технических страниц вида /index.php?option будет добавлен атрибут rel=»canonical» (с указанием URL на страницу с настроенным ЧПУ).
Как проверить дублированный контент
Проверить, настроен canonical для страниц вашего сайта или нет, можно с помощью следующих инструментов:
1. Для проверки настройки canonical, открываем html-код страницы и проверяем наличие атрибута canonical у тега link (в блоке <head> кода страницы).
Плагин для браузеров RDS Bar позволит просмотреть эту информацию без совершения лишних действий. Включаем данную опцию в настройках плагина (Параметры – SEO – теги – Canonical), после чего при переходе на страницы, где canonical настроен, будет отображаться следующая информация:
2. Проверить наличие дублируемого контента можно с помощью Расширенного поиска Яндекса. Для этого указываем адрес сайта и часть текста со страницы, контент которой будем проверять на дублирование. В результатах поиска будет указано, нашлись точные совпадения или нет. Если дублирование отсутствует, то будут предложены варианты по запросу.
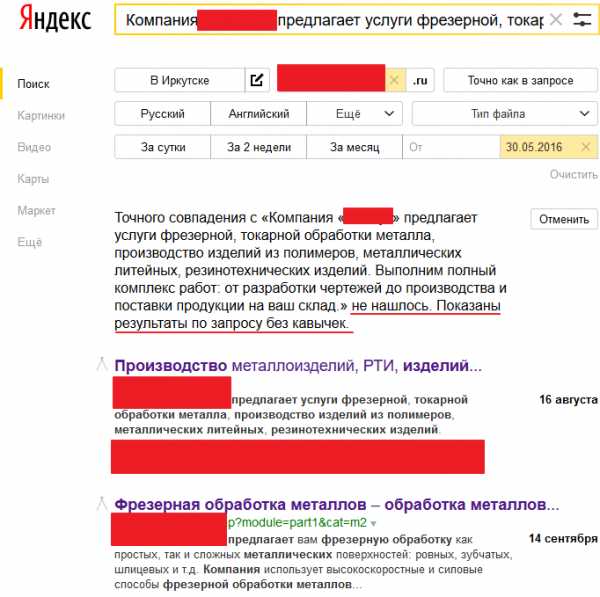
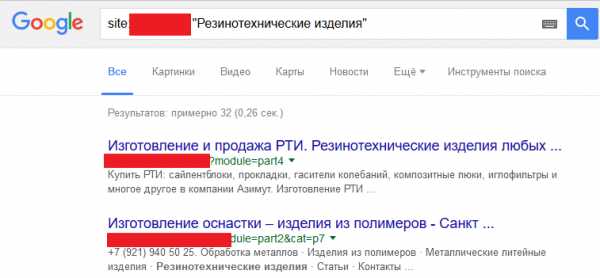
Также проверить контент на наличие дублей можно с помощью операторов поиска, рассмотрим на примере Google. Для этого нужно ввести в поисковую строку site:имя_домена «запрос», в итоге аналогично поиску от Яндекса по результатам поисковой выдачи делаем вывод о наличии дублированного контента.
3. Еще один способ найти дублируемый контент – уникальность. В этом нам помогут специальные программы и сервисы, мы рассмотрим на примере сервиса text.ru. Для анализа необходимо добавить информацию со страницы вашего сайта в сервис и запустить проверку. В результате вы увидите, на каких сайтах в Интернете есть такой же текст, и на сколько процентов ваш текст совпадает с текстами других сайтов.
Итог
Грамотно настроенный canonical повышает эффективность работы и ускоряет индексирование сайта. Если у вас не получится самостоятельно это сделать, то вы можете обратиться к нашим специалистам, и мы сделаем настройку rel=»canonical» для вашего сайта.
© 1PS.RU, при полном или частичном копировании материала ссылка на первоисточник обязательна.
Понравилась статья?
54 6
Сожалеем, что не оправдали ваши ожидания ((
Возможно, вам понравятся другие статьи блога.
1ps.ru