Что это за теги Nofollow и Noindex, в чем разница и как правильно прописывать
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.

- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.

Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
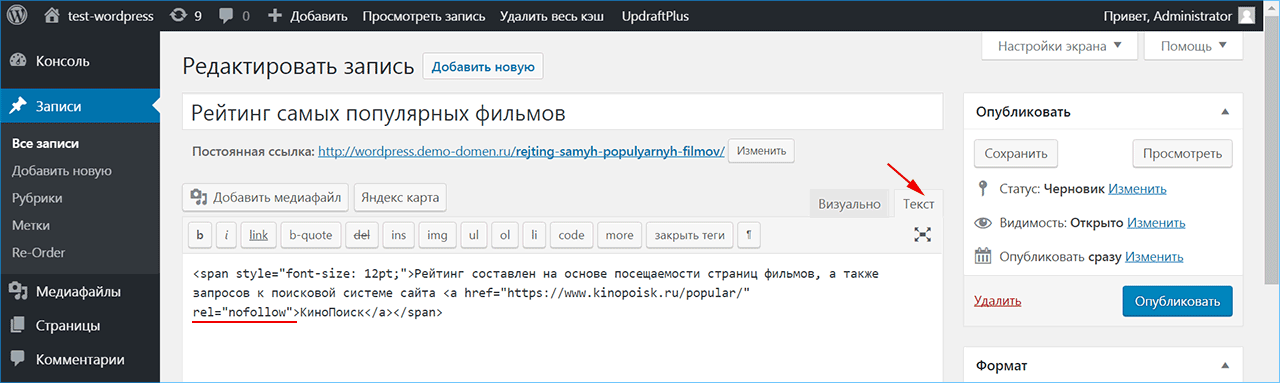
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
 Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
Какая разница между тегами nofollow и noindex? — SEO
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.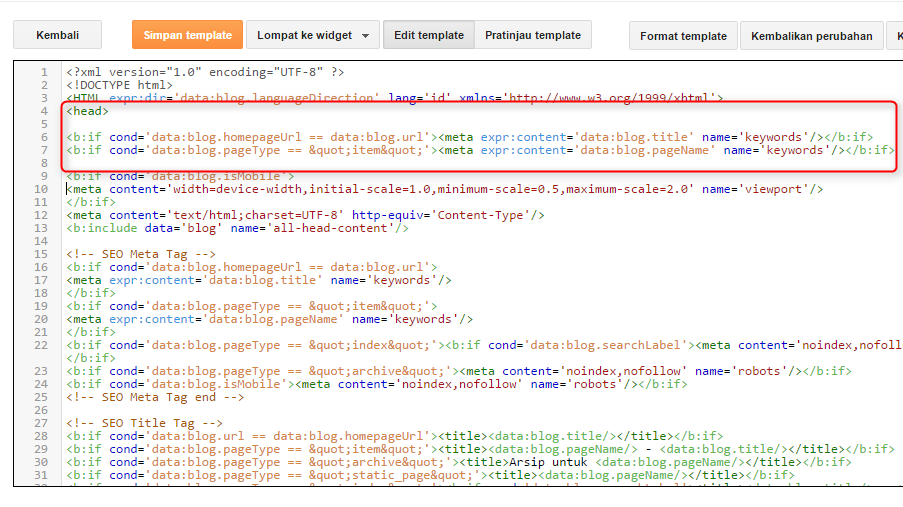 txt заносите новые ссылки, неизвестные для Google и Яндекс.
txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
что это значит, в чем разница и как правильно их использовать
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
 youtube.com/embed/tGU7v4Zhyco» frameborder=»0″ allowfullscreen=»allowfullscreen»/>
youtube.com/embed/tGU7v4Zhyco» frameborder=»0″ allowfullscreen=»allowfullscreen»/>Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
В чем отличие между noindex и nofollow
Первое существенное отличие их в том, что первый был виден ранее для Google, а второй — только для Яндекса и Rambler. В настоящее время Яндекс также научился распознавать Ноуфоллоу, который работает только для ссылок, а Ноуиндекс — для любого кода сайта.
Применение Nofollow не превращает ссылку в невидимую, а всего лишь указывает, что по ней не нужно идти и индексировать документ, на который она ведет. Поисковый робот индексирует эту гиперссылку, но вес с сайта не передается, если она ведет на чужой ресурс. Работает этот атрибут для всех поисковиков.
Что касается тега Noindex, то с ним работает только Яндекс. Гугл же просто проигнорирует его. Использовать его нужно в тех случаях, когда вы хотите закрыть какой-то участок страницы — текст, картинку или ссылку — от индексации.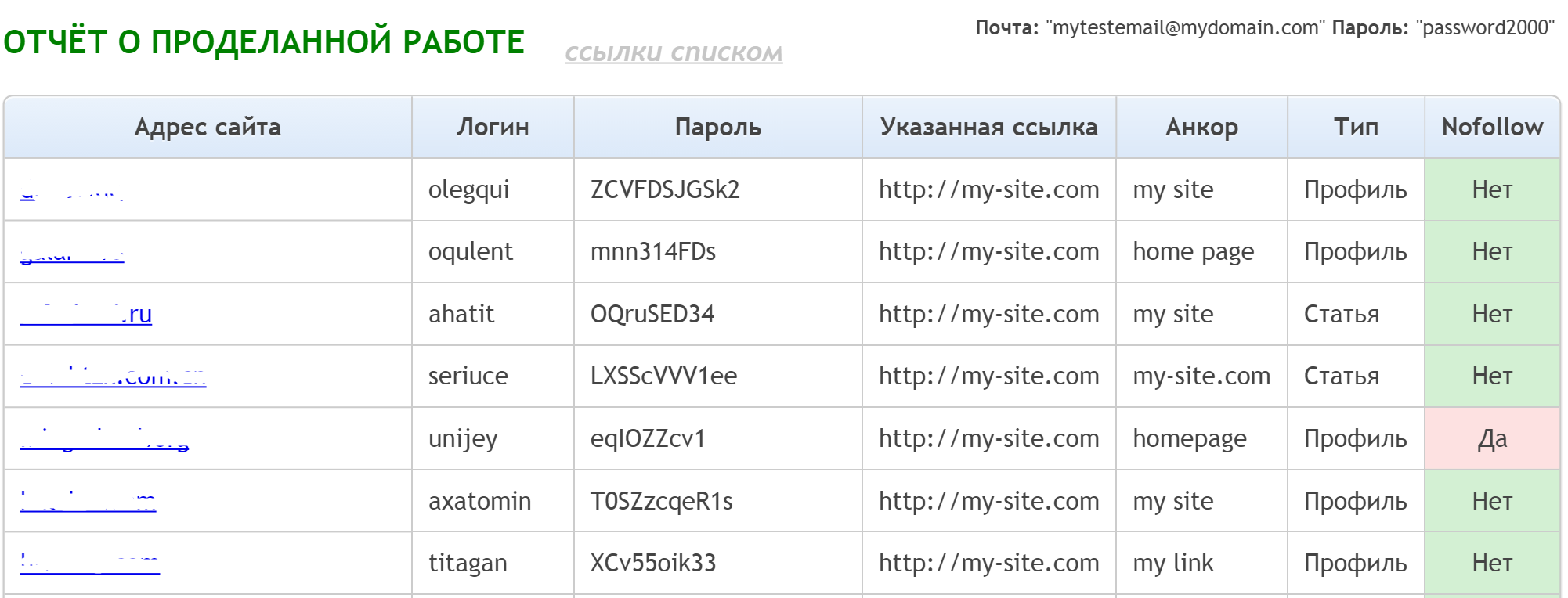 Поисковик контент распознает, но впоследствии выкидывает из индекса. Эта мера установлена для полного анализа страницы и процедуры наложения возможных санкций за нарушения.
Поисковик контент распознает, но впоследствии выкидывает из индекса. Эта мера установлена для полного анализа страницы и процедуры наложения возможных санкций за нарушения.
Для чего нужен Noindex
- Закрывается ненужная/неуникальная информация, что улучшает релевантность страницы, потому что увеличивается плотность ключевых фраз, соответствие тематике, уникальность.
- Прячутся сквозные блоки и гиперссылки, наличие которых может приводить к пессимизации.
- Скрывается личная и служебная информация, если вы не хотите, чтобы она легко находилась через поиск.
Для чего нужен Nofollow
- Закрытие лишних веб-ссылок.
- Сохранение веса страницы неизменным.
- Распределение определенного веса по ссылкам.
Как использовать noindex и nofollow
Тэг Noindex для любого контента применяется так:текст, который надо скрыть <a href=”ссылка куда-то”>, и еще</a> текст</noindex>.
Весь текст и анкор ссылки изначально индексируются, но потом удаляются из базы поисковика. Гиперссылка индексируется, и вес по ней передается.
При работе с Ноиндекс существует вероятность того, что снизится валидность кода, так как данный тэг знает только российский поисковик. Поэтому рекомендуется следующий вариант написания:
<!—Noindex—> Весь текст, который надо скрыть <!—/noindex—>.
Весь текст, который надо скрыть .
При этом другие поисковики просто его пропустят, и валидность кода останется неизменной.
Атрибут Nofollow для ссылок применяется
<a href=”веб-ссылка куда-то” rel=”nofollow”> анкор </a>
При этом анкор попадает в индекс, но поисковик по веб-ссылке не идет, вес на странице остается.
Если на странице слишком много Нофоллоу, то это может негативно сказаться на лояльности поисковиков.
Совместное использование
Для того чтобы закрыть и текстовую часть, и гиперссылку, следует придерживаться такого написания:
<!—Noindex—> Весь текст, который надо скрыть <a href=”веб-ссылка куда-то” rel=”nofollow”> анкор </a>, и еще текст <!—/noindex—>
Варианты правильного использования Noindex и Nofollow для запрета индексации документа в целом
Тег и атрибут, все время ходят “за ручку”, и часто их применяют вместе. Они могут применяться в meta name=robots документа для указания рекомендаций по его индексации и переходу по веб-ссылкам. Указание на запрет индексации необходимо, если обнаружены дубли страниц, Или в сети появилась конфиденциальная или устаревшая информация, а другим способом страницы убрать нельзя.
Они могут применяться в meta name=robots документа для указания рекомендаций по его индексации и переходу по веб-ссылкам. Указание на запрет индексации необходимо, если обнаружены дубли страниц, Или в сети появилась конфиденциальная или устаревшая информация, а другим способом страницы убрать нельзя.
В случае, если вы хотите закрыть всю страницу от индексации и запретить учет располагающихся на ней ссылок, необходимо указать в метаданных страницы — следующее:
Ноуиндекс создает команду Яндексу не индексировать контент на странице, но робот ходит по ее веб-ссылкам. Поэтому дополнительный Ноуфоллоу указывает по ним на не ходить. Данное указание воспринимают как Яндекс, так и Google.
Что касается удаления документа из индекса Google, то поисковиком предусмотрен альтернативный метод: запись X-Robots-Tag: noindex, nofollow. Данное указание закрепляется в http-заголовках, не видимых в коде страницы.
Рассказываем о разнице между Nofollow и Noindex, как их правильно использовать для ссылок и скрытия контента на сайте.
Всегда следите за наличием рассмотренных в статье тегов и атрибутов в нужных местах, чтобы получать именно тот результат, которого вы ожидаете.
Теги noindex и nofollow в чем разница и как они работают
Привет, Друзья! На показатели сайта в первую очередь влияет количество и естественность входящих ссылок. По сути, ссылки (линки) переносят вес с сайтов-доноров на продвигаемый веб-сайта. В том случае, если постоянно ставить ссылки на другие сайты, и не дай бог другого профиля (тематики), то в этом случае общий вес сайта будет значительно снижен. Именно об этом и будет этот текст, как можно управлять индексацией поисковых систем, скрывать целые блоки текстов и ссылки от поисковых роботов. Все это можно сделать, воспользовавшись мета-тегами, которые понимают только поисковые роботы. С целью управления этим процессом и были разработаны поисковыми системами специальные теги nofollow и noindex.
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex. Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя. Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами. Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому.
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому.
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт. Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе.
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста.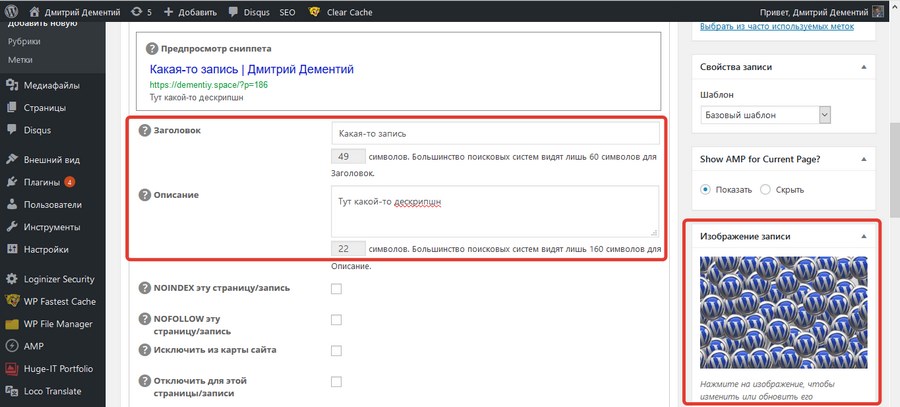 В этом случае и текст и ссылка не будет доступна к индексации. Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс.
В этом случае и текст и ссылка не будет доступна к индексации. Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс.
Обучение продвижению сайтов
Более подробно о том, как выводить сайты в ТОП 10 поисковых систем Яндекс и Google, я рассказываю на своих онлайн-уроках по SEO-оптимизации (смотри видео ниже). Все свои интернет-проекты я вывел на посещаемость более 1000 человек в сутки и могу научить этому Вас. Кому интересно обращайтесь!
На этом сегодня всё, всем удачи и до новых встреч!
Используем rel=nofollow и noindex для Yandex » WPbloging
В апреле, поисковик Yandex, обрадовал рунетовских веб-мастеров, включением поддержки атрибута rel=»nofollow» в ссылках. Какую пользу это нам — блоггерам принесет? Как правильно прописать атрибут rel=»nofollow» в ссылках и что теперь будет с <noindex>?Давайте попробуем разобраться в этих новинках Яндекса .
Небольшая предыстория атрибута rel=nofollow
Что такое rel=nofollow?
Rel=» « — атрибут в ссылке <a>, указывающий отношение ссылки к целевой странице. Также, есть еще атрибут Rev=» «, указывающий отношение целевой страницы к ссылке, например (ссылка с rev=»sponsor» указывает, что это спонсорская ссылка). Но об этом в следующей статье.
Nofollow — статус, говорящий о том,что вы не одобряете данную ссылку.
Исходя из вышесказанного:
Rel=nofollow — определяет отношение вашей ссылки к целевой странице как не одобряемое. Применительно к поисковикам, данный атрибут указывает индексирующим роботам, что по данной ссылке не следует переходить на целевую страницу.
Rel=nofollow был введен и стандартизирован в 2005 году, в ответ на многочисленный ссылочный спам, присутствующий в блогах. Инициатором введения была поисковая система Google, источник.
Google, встречая ссылку с данным атрибутом, не следует по данной ссылке и не передает вес PR целевым страницам. Также, данные ссылки не учитывались в расчетах распределения ссылочного веса по ссылкам страницы. Но, так было до 2010 года. На данный момент, Google, также не передает ссылочный вес и не следует по ссылкам с rel=»nofollow», но вот ссылочный вес, внутри страницы, стал распределятся и на эти ссылки но впустую. То есть, если у вашей страницы PR-10 и 10 ссылок на странице, где 5 из них закрыты, то каждая открытая ссылка передавала по 2PR на целевую страницу. Теперь каждая открытая ссылка будет передавать 1PR по открытым ссылкам и по 1PR в пустоту по закрытым. Но эта статья не о Google, вернемся к Яндексу.
Также, данные ссылки не учитывались в расчетах распределения ссылочного веса по ссылкам страницы. Но, так было до 2010 года. На данный момент, Google, также не передает ссылочный вес и не следует по ссылкам с rel=»nofollow», но вот ссылочный вес, внутри страницы, стал распределятся и на эти ссылки но впустую. То есть, если у вашей страницы PR-10 и 10 ссылок на странице, где 5 из них закрыты, то каждая открытая ссылка передавала по 2PR на целевую страницу. Теперь каждая открытая ссылка будет передавать 1PR по открытым ссылкам и по 1PR в пустоту по закрытым. Но эта статья не о Google, вернемся к Яндексу.
Yandex, до апреля месяца 2010г., не учитывал данный статус. В рекомендациях Яндекса находим нашумевший тег <noindex>, который позволял сделать тоже самое и больше. Теперь там и nofollow.
В чем разница rel=nofollow и <noindex>
Так в чем же проблема?
Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
 Данный тег нигде в мире, кроме самого Яндекс, не поддерживается и не стандартизирован. При проверке ресурса на ошибки в коде и поддержке web-стандартов, веб-мастера всегда получали «не валидный» код. То есть, ваш ресурс содержит ошибки. Но, спешу вас успокоить, это не критическая ошибка и практически ни на что не влияет. Для тех кому важен валидный код, вот структура, рекомендованная самим Yandex для валидности вашего кода:
Данный тег нигде в мире, кроме самого Яндекс, не поддерживается и не стандартизирован. При проверке ресурса на ошибки в коде и поддержке web-стандартов, веб-мастера всегда получали «не валидный» код. То есть, ваш ресурс содержит ошибки. Но, спешу вас успокоить, это не критическая ошибка и практически ни на что не влияет. Для тех кому важен валидный код, вот структура, рекомендованная самим Yandex для валидности вашего кода:<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->
Еще одна проблема тега <noindex> в том, что зарубежные веб-мастера, не ведая о данном теге, не используют его в разработках своих плагинов к WordPress. Приходится данные плагины адаптировать под Яндексовскую реальность.
Если в комментариях блога ссылки были закрыты атрибутом rel=»nofollow», то для Яндекса эти ссылки были открыты. Это означало, что роботу приходилось путешествовать по всем ссылкам указанным в комментариях.
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать.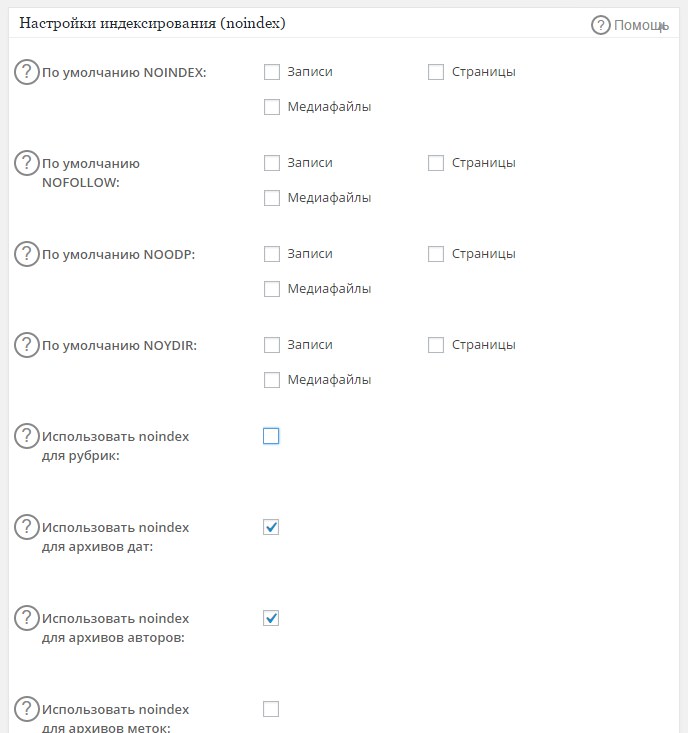
Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow». Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
Зачем нужен <noindex>?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex.
Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует. Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент.
Как правильно прописать rel=nofollow и <noindex>
- Для закрытия ссылок от индексации, с помощью rel=»nofollow», используется простая схема:
<a rel=»nofollow» href=»http://www.site.com» title=»Подсказка»>Ссылка на сайт</a>
перехода по ссылке не будет. - Для закрытия блока текста тегом <noindex>, со всем содержимым, в том числе и с анкорами ссылок, используется схема:
<!--noindex-->Блок вашего закрываемого текста<!--/noindex-->данный текстовый блок не будет проиндексирован в Яндекс, со всеми текстами ссылок. - Для закрытия блока текста тегом и ссылок в блоке, используется схема:
<!--noindex-->Блок вашего закрываемого текста <a rel="nofollow" href="http://www.site.com" title="Подсказка">Текст анкор ссылки</a> Блок вашего закрываемого текста<!--/noindex-->данный блок не будет проиндексирован в Яндекс, со всеми ссылками содержащимся в данном блоке.

Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Источник
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.

P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
Нашел ошибку в тексте? Выдели ее мышкой и нажми
Использование тега noindex и атрибута nofollow. Отличие noindex и nofollow.
Правильное использование тега noindex и атрибута nofollow – самый первый шаг в грамотной оптимизации. Ведь noindex и nofollow играют огромную роль при передаче веса с одной страницы сайта на другую. Тег noindex используется для запрета индексации какой-то части html-кода страницы. Тег noindex не является валидным, поэтому некоторые html-редакторы отказываются его воспринимать. Ноиндекс воспринимается исключительно поисковиком Яндексом, а Гугл на него никак не реагирует.
Тег noindex используется для запрета индексации какой-то части html-кода страницы. Тег noindex не является валидным, поэтому некоторые html-редакторы отказываются его воспринимать. Ноиндекс воспринимается исключительно поисковиком Яндексом, а Гугл на него никак не реагирует.
Не стоит путать обычный тег <noindex> с мета-тегом noindex, прописываемым вначале страницы, их задачи разные. Простой тег запрещает для индексации только ту часть кода страницы, которая находится между открывающимся <noindex> и закрывающимся </noindex> тегами. Что же касается мета-тега, то он запрещает индексировать всю страницу (запрет прописывается в файле robots.txt) – такую страницу Яндекс вообще не индексирует.
Тег работает безотказно: вся текстовая информация внутри него не попадает в индекс яндекса. Однако некоторые оптимизаторы утверждают, что порой текст внутри ноиндекс индексируются – увы, такое действительно бывает. Дело в том, что Яндекс все же изначально индексирует весь html-код, даже тот, что внутри тега, но потом проводит фильтрацию.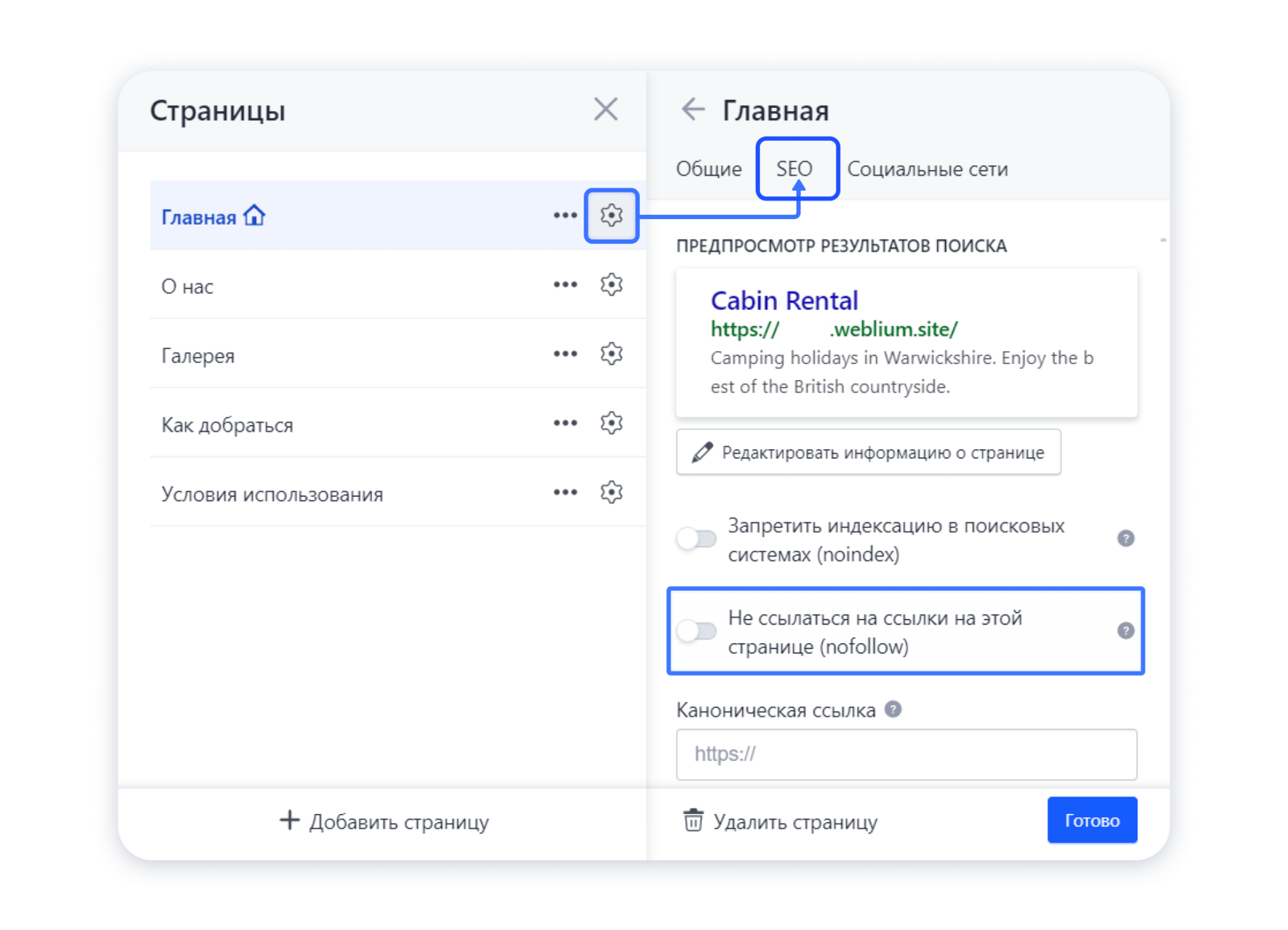 В начале служебного фрагмента поставьте — <noindex>, а в конце — </noindex>, и Яндекс не будет индексировать данный участок текста. Тег noindex не чувствителен к вложенности.
В начале служебного фрагмента поставьте — <noindex>, а в конце — </noindex>, и Яндекс не будет индексировать данный участок текста. Тег noindex не чувствителен к вложенности.
Используя открывающийся тег (<noindex>), не забудьте поставить закрывающийся — (</noindex>), иначе весь текст, следующий после <noindex> не будет проиндексирован.
Поскольку тег noindex не входит в официальную спецификацию языка HTML, то большинство HTML-валидаторов считает его ошибкой. Потому для того, чтобы сделать код с noindex валидным, рекомендуется использовать следующую конструкцию:
<!–noindex–>Текст или код, который нужно исключить из индексации<!–/noindex–>
Немалая часть оптимизаторов очень часто высказывают мнения, насчет того, что Яндекс не обращает внимания на этот тег. Обычно аргументируется это тем, что текст, закрытый в ноиндекс, есть в сохраненной копии страницы в Яндексе, следовательно, поисковик видит его. Другая же часть оптимизаторов считает, что это просто на просто очередной миф, и ноиндекс есть ноиндекс, т. е. Яша не видит текст (ссылку) заключенный в него.
е. Яша не видит текст (ссылку) заключенный в него.
Атрибут NOFOLLOW появился в январе 2005-го года как продукт борьбы со спамом в комментариях по инициативе Google. Его поддержку тогда сразу же объявили Yahoo и MSN/Bing. Спустя пять лет, в начале мая 2010 года, nofollow поддержал и Яндекс.
Атрибут nofollow предназначен для закрытия от индексации ссылок как для Гугла, так и для Яндекса. Он используется для того, чтобы не передавать вес со ссылающегося сайта на ссылаемый. Атрибут “nofollow” запрещает поисковой системе переходить по ссылкам на данной странице или по конкретной ссылке. Изначально атрибут nofollow использовался в метатеге уровня страницы и запрещал поисковым системам сканировать все внешние ссылки на этой странице. Например:
<meta name=”robots” content=”nofollow” />
До того как атрибут nofollow стало возможным использовать для отдельных ссылок, закрывать роботу доступ к определенным ссылкам было непросто (например, такие ссылки перенаправляли на URL, заблокированный в файле robots. txt). Поэтому было создано значение nofollow для атрибута rel. Оно обеспечивает более гибкое управление: вместо того чтобы запрещать поисковым системам и роботам переходить по всем ссылкам на странице, можно закрыть для них определенные ссылки.
txt). Поэтому было создано значение nofollow для атрибута rel. Оно обеспечивает более гибкое управление: вместо того чтобы запрещать поисковым системам и роботам переходить по всем ссылкам на странице, можно закрыть для них определенные ссылки.
Параметр nofollow используется в теге HTML <a href=”…” rel=”nofollow”>Ссылка</a> этот параметр, не входит в стандарты HTML, и используется для предотвращения веб-спама, на страницах сайтов, форумов, блогов и гостевых книг.
Поисковой спам, как правило выражается в автоматической отправке комментариев с ссылками на рекламируемые сайты, в кучу блогов иногда подходящей тематики. Использование параметра nofollow снижает эффективность поискового спама. Так что параметр как видите полезный и призван работать во благо честных блоггеров.
Например, если ссылка из комментария может указывать на не заслуживающий доверия сайт и нет возможности его предварительно модерировать, то чтобы не получить за это штрафные санкции со стороны поисковых систем (а это может быть очень строгое наказание, вплоть до бана – исключения из индекса) – однозначно правильней добавлять к ней атрибут rel=”nofollow”.
Статический вес с ссылки, заключенной в тег nofollow, не передается на внешний ресурс, а остается на сайте, равномерно перераспределяясь между оставшимися незакрытыми ссылками. Так было раньше в Google. Статический вес через ссылку, заключенную в тег nofollow, все равно утекает, но не на внешний ресурс, а в никуда. Именно так теперь Google понимает этот атрибут.
Правильное использование тега noindex и атрибута nofollow – залог успешного продвижения сайта, а неправильное может привести к нехорошим последствиям. Поисковые системы уделяют особое внимание ноиндекс-нофоллоу тегам, поэтому использовать их нужно аккуратно.
В отличие от тега noindex, который закрывает от индексации текст, атрибут тега <a> nofollow служит только для перенаправления статического веса ссылок. Пока принято считать, что есть только два пути – либо на внешний сайт-акцептор, либо мимо сайта-акцептора в бесконечное пространство. Эти два тега отлично сочетаются друг с другом и их можно использовать совместно.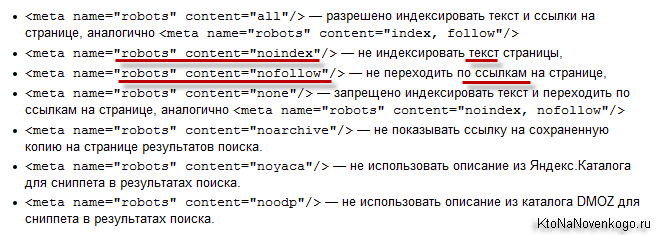
Очень часто вебмастера стараются использовать оба тега вместе:
<noindex><a href=”ссылка” rel=”nofollow”>текст ссылки</a></noindex>
Новоиспеченные вебмастера, прочитав какую-нибудь статью про теги noindex nofollow, начинают массовое закрытие ссылок, в итоге они прячут все без исключения внешние ссылки, опасаясь потери драгоценного веса страниц.
Прочитав выше написанное, у вас может появиться желание вообще не ссылаться ни на кого, раз статический вес страницы, уходящий через ссылки, никак нельзя сохранить. Но и отсутствие ссылок на странице – не лучший вариант. Дело в том, что любая статья должна ссылаться на источники, которые использовались при ее написании. Любая статья должна ссылаться на источники, которые дополняют и обогащают ее. Ссылки помогают посетителям находить информацию, и поисковые системы это прекрасно понимают.
Несколько внешних ссылок со страницы не повредят ей, поэтому не бойтесь ссылаться и не закрывайте ссылки от индексации, если на это нет оснований.
Нужно ли добавлять атрибут nofollow rel к ссылкам, если страница href содержит метатег роботов, содержащий noindex и nofollow?
Если у меня есть страница («dontFollowMe.html») с метатегом:
< meta name = "robots" content = "noindex, nofollow" / >
… и я ссылаюсь на эту страницу …
Нужно ли включать атрибут nofollow rel в элемент a? :
<a href="dontFollowMe.html" rel="nofollow">sign in</a>
Спасибо
html seo meta googlebot nofollowПоделиться Источник user1566224 06 февраля 2015 в 17:36
4 ответа
- Как добавить rel=»nofollow» к ссылкам с preg_replace()
Приведенная ниже функция предназначена для применения атрибутов rel=nofollow ко всем внешним ссылкам и никаких внутренних ссылок, если только путь не совпадает с предопределенным корнем URL, определенным как $my_folder ниже.
Итак, учитывая переменные… $my_folder = ‘http://localhost/mytest/go/’;… - SEO — noindex, nofollow и канонический тег
Мне нужно кое-что объяснить по поводу моего вопроса. Пример в моем заголовке уже добавлен <meta name=robots content=noindex, nofollow /> Должен ли я снова добавить канонический тег в свой заголовок? <link rel=”canonical” href=”http://www.example.com/product.php?item=big-fish” /> Дайте…
5
Нет, вам не обязательно использовать nofollow на странице, которая не индексируется (по техническим причинам, как описано в вашем вопросе).
вес = «не передают ссылочный вес этой страницы. Просто притворись, что его не существует». Конечно, это всего лишь предложение поисковым системам.
noindex = » не индексируйте эту страницу. Мне все равно, будут ли другие страницы, связанные с ним, подписаны или нет, просто не индексируйте его. »
»
По SEO причинам: если этот вопрос предполагает, что вы ссылаетесь на внутреннюю страницу, то ответ на ваш вопрос будет заключаться в том, что обычно вы хотите не следовать ссылке на эту неважную страницу, а также не индексировать ее на неважной странице.
Поделиться rick6 06 февраля 2015 в 17:57
2
rel=»nofollow» будет сигнализировать искателям, чтобы они не следовали по ссылкам. Если вы хотите, чтобы пауки тратили качественное время на другие ссылки на странице, вы обычно добавляете rel=»nofollow» к ссылкам, которые вы не хотите обходить. Другая причина будет заключаться в том, что вы не можете поручиться за то, что есть на связанной странице. Наличие «no follow» на странице сигнализирует об отказе следовать по любым исходящим ссылкам на странице. Страница все равно будет сканироваться искателем google.
Поделиться minion 06 февраля 2015 в 18:41
0
nofollow как значение meta-robots и nofollow как тип ссылки означают разные вещи или точно то же самое, в зависимости от того, какому определению вы следуете ( подробнее ).
HTML5 определяет, что тип ссылки nofollow
[ … ] указывает на то, что ссылка не одобрена первоначальным автором или издателем страницы, или что ссылка на упомянутый документ была включена в основном из-за коммерческих отношений между людьми, связанными с этими двумя страницами.
Это не означает, что ссылка должна / не должна сопровождаться visitors/bots.
Поэтому, если вы не одобряете ссылку на ваш dontFollowMe.html или если вы добавили ее только по коммерческим причинам (например, реклама), вы не должны использовать тип ссылки nofollow .
Поделиться unor 07 февраля 2015 в 12:36
- Перенаправление исходящих ссылок и атрибут rel=»nofollow»-в чем разница?
Насколько я знаю, многие сайты добавляют атрибут rel=nofollow ко всем исходящим ссылкам внутри сообщений своего форума.
Насколько я понимаю, таким образом они говорят поисковым роботам не использовать эти ссылки для ранжирования веб-страниц. Кроме того, я заметил, что некоторые форумы используют… - Noindex, nofollow-достаточно ли поместить их в ответ HTTP?
Я думаю, что название этого вопроса говорит само за себя — при разработке и развертывании бета-версий, должен ли я поставить X-Robots-Tag: noindex, nofollow в ответе HTTP, или <meta name=robots content=noindex, nofollow> в разделе <head></head> каждой страницы?
 Насколько я понимаю, таким образом они говорят поисковым роботам не использовать эти ссылки для ранжирования веб-страниц. Кроме того, я заметил, что некоторые форумы используют…
Насколько я понимаю, таким образом они говорят поисковым роботам не использовать эти ссылки для ранжирования веб-страниц. Кроме того, я заметил, что некоторые форумы используют…
0
(Поскольку вы пометили свой вопрос тегом googlebot, я предполагаю, что ваш интерес связан с Google и атрибутом nofollow tag and link.)
Если у вас есть nofollow в качестве мета-тега, то вам не нужно добавлять отдельные ссылки, потому что :
Метатег nofollow robots применяется ко всем ссылкам на странице. Атрибут rel=»nofollow» link применяется только к определенным ссылкам на странице.
 Для получения дополнительной информации об атрибуте ссылки rel=»nofollow»,
пожалуйста, ознакомьтесь со статьями нашего справочного центра о пользовательском спаме и
rel=»nofollow».
Для получения дополнительной информации об атрибуте ссылки rel=»nofollow»,
пожалуйста, ознакомьтесь со статьями нашего справочного центра о пользовательском спаме и
rel=»nofollow».Как метатег nofollow robots сравнивается с атрибутом ссылки rel=»nofollow»?
Поделиться user29671 09 февраля 2015 в 10:17
Похожие вопросы:
Добавьте атрибут nofollow к ссылке, если тег заголовка отсутствует, используя PHP
У меня есть куча текста с html в нем. В основном то, что я хочу сделать, это для всех ссылок, найденных в этом тексте, я хочу добавить rel=noindex к каждой найденной ссылке, только если атрибут…
Добавление атрибута rel=»nofollow», чтобы все ссылки в постах WordPress
Я хочу добавить rel=nofollow ко всем ссылкам в моих постах wordpress, и я хочу иметь список ссылок, которые не получат nofollow. Я много старался, но не могу сделать это правильно, потому что я. ..
..
Добавление rel=nofollow к ссылкам will_paginate в rails
Есть ли какой-нибудь способ добавить rel=nofollow к ссылкам, созданным will_paginate gem в rails?
Как добавить rel=»nofollow» к ссылкам с preg_replace()
Приведенная ниже функция предназначена для применения атрибутов rel=nofollow ко всем внешним ссылкам и никаких внутренних ссылок, если только путь не совпадает с предопределенным корнем URL,…
SEO — noindex, nofollow и канонический тег
Мне нужно кое-что объяснить по поводу моего вопроса. Пример в моем заголовке уже добавлен <meta name=robots content=noindex, nofollow /> Должен ли я снова добавить канонический тег в свой…
Перенаправление исходящих ссылок и атрибут rel=»nofollow»-в чем разница?
Насколько я знаю, многие сайты добавляют атрибут rel=nofollow ко всем исходящим ссылкам внутри сообщений своего форума. Насколько я понимаю, таким образом они говорят поисковым роботам не. ..
..
Noindex, nofollow-достаточно ли поместить их в ответ HTTP?
Я думаю, что название этого вопроса говорит само за себя — при разработке и развертывании бета-версий, должен ли я поставить X-Robots-Tag: noindex, nofollow в ответе HTTP, или <meta name=robots…
PHP регулярное выражение для добавления rel=»nofollow» к внешним ссылкам
Мне нужно добавить rel=nofollow ко всем внешним ссылкам (не ведущим на мой сайт или его поддомены). Я сделал это в два этапа, сначала я добавляю rel=nofollow ко всем ссылкам (даже внутренним…
Установите NOINDEX, NOFOLLOW на конкретные продукты
My magento store имеет следующее, чтобы позволить google / поисковым системам сканировать весь сайт. <meta name=robots content=INDEX,FOLLOW /> Теперь я нуждаюсь в некоторых конкретных…
Как добавить `nofollow, noindex` всех страниц в robots.txt?
Я хочу добавить nofollow и noindex на свой сайт, пока он строится. У клиента есть запрос, чтобы я использовал эти правила. Я знаю о <meta name=robots content=noindex,nofollow> Но у меня есть…
У клиента есть запрос, чтобы я использовал эти правила. Я знаю о <meta name=robots content=noindex,nofollow> Но у меня есть…
Какие страницы на вашем сайте использовать noindex или nofollow? • Yoast
Михил ХеймансМихиэль был одним из наших первых сотрудников и раньше был партнером Yoast. Начните оптимизацию своего сайта с его статей!
Некоторые страницы вашего сайта служат определенной цели, но эта цель не заключается в ранжировании в поисковых системах и даже не в привлечении трафика на ваш сайт. Эти страницы должны быть там, как клей для других страниц или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте.Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Что такое noindex nofollow?
noindex означает, что веб-страница не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поиска.
nofollow означает, что пауки поисковых систем не должны переходить по ссылкам на этой странице.Вы можете добавить эти значения в свой метатег robots. Метатег robots — это фрагмент кода в разделе заголовка веб-страницы. Он сообщает поисковым системам, как сканировать и индексировать ли страницу.
Наше полное руководство по метатегу robots — отличное чтение, если вы хотите немного глубже погрузиться в эту тему.
Вкратце:
- В большинстве случаев метатег robots выглядит следующим образом:
- VALUE1 и VALUE2 имеют индекс
, по умолчанию используется, что означает данная страница может быть проиндексирована поисковыми системами, и по ссылкам на этой странице можно переходить для сканирования страниц, на которые они ссылаются. - VALUE1 и VALUE2 могут быть установлены на
noindex, nofollowили другую комбинацию, например индекс, nofollow.

Но пусть вас не пугает этот код. Yoast SEO поможет вам! Если вы хотите узнать, как noindex пост в WordPress супер-простым способом, вам следует прочитать этот пост: Как noindexировать пост в WordPress: простой способ.
Но когда какое значение использовать?
Страниц для установки noindex
Авторский архив в блоге одного автора
Если вы единственный, кто пишет для своего блога, страницы ваших авторов, вероятно, на 90% совпадают с домашней страницей вашего блога.Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете noindex . К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как не индексировать архив автора.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения, который вы не хотите индексировать.Например, в Yoast мы используем настраиваемые страницы для наших продуктов, поскольку мы не являемся типичным интернет-магазином, продающим физические продукты. Таким образом, нам не нужно изображение продукта, фильтры, такие как размеры и технические характеристики, на вкладке рядом с описанием. Поэтому мы не индексируем обычные страницы продуктов, которые выводит WooCommerce, и используем наши собственные страницы. Действительно, у нас noindex тип сообщения о продукте.
Соответственно, мы видели решения для электронной коммерции, которые также добавляли такие характеристики, как размеры и вес, в качестве настраиваемого типа сообщений.Эти страницы считаются некачественным контентом. Вы поймете, что эти страницы не нужны ни посетителям, ни Google, поэтому их тоже нужно держать подальше от страниц результатов поиска.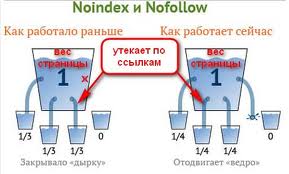
Страницы благодарности
Эта страница не служит никакой другой цели, кроме как поблагодарить вашего клиента / подписчика на информационную рассылку / впервые комментирующего. Эти страницы, как правило, представляют собой страницы с тонким контентом, с возможностью дополнительных продаж и социальных сетей, но они не представляют ценности для тех, кто использует Google для поиска полезной информации. Следовательно, этих страниц не должно быть на страницах результатов поиска.
Страницы администратора и входа в систему
Большинство страниц входа не должны находиться в Google. Но это так. Не допускайте попадания своего в индекс, добавив к нему noindex . Исключением являются страницы входа, которые обслуживают сообщество, например Dropbox или аналогичные службы. Просто спросите себя, стали бы вы гуглить одну из своих страниц входа в систему, если бы вы не работали в своей компании. Если нет, то можно с уверенностью сказать, что Google не нужно индексировать эти страницы входа. К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS автоматически не индексирует страницу входа на ваш сайт.
К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS автоматически не индексирует страницу входа на ваш сайт.
Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, вы ссылаетесь на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Таким образом, необходимо переходить по всем ссылкам, а мета-настройка роботов должна быть:
Yoast SEO следит за тем, чтобы для ваших внутренних поисковых страниц по умолчанию было установлено значение noindex.Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.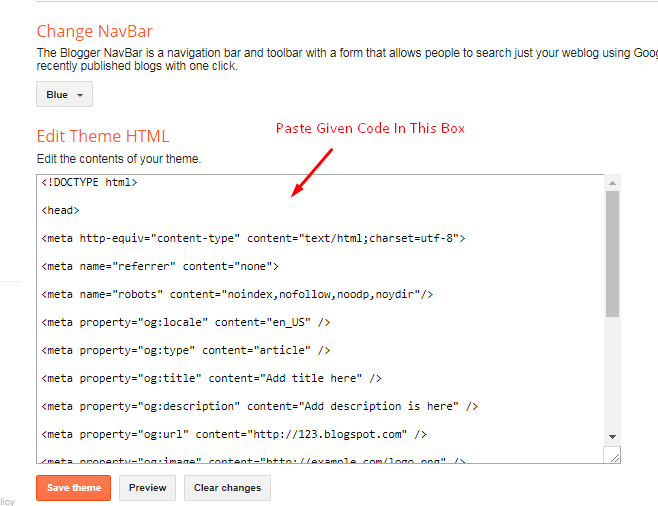
Только для разработчиков: если вы действительно хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Страниц для установки на nofollow
Для всех примеров, упомянутых выше, нет необходимости nofollow для всех ссылок на этих страницах.Вы не хотите отображать их в результатах поиска, но хотите, чтобы Google переходил по ссылкам на странице. Теперь, когда должен , вы добавляете nofollow в метатег роботов?
Если вы установите для страницы значение nofollow с метатегом robots, ни одна из ссылок на этой странице не будет переходить. Google придумал nofollow, чтобы иметь возможность различать ссылки на ненадежный контент (или, позже, оплаченный, например, рекламу). На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по по любой ссылке .
Пример: если у вас есть страница со списком книг по SEO с избытком партнерских ссылок Amazon, они могут быть полезны для вашего сайта для ваших пользователей. Но я бы дал
Но я бы дал nofollow всю страницу, если на странице нет ничего важного. Однако вы могли бы проиндексировать его. Просто убедитесь, что вы правильно скрываете свои ссылки.
Одинарные ссылки Nofollow
Если у вас есть сообщение или страница с несколькими ссылками, вы можете помочь поисковым системам квалифицировать их.В настоящее время вы можете nofollow для одной ссылки или даже установить для нее спонсируемый или пользовательский контент. Добавление правильных атрибутов rel к вашей ссылке позволяет вам это сделать. Например, ссылка на рекламу будет выглядеть так: пример ссылки . С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
Заключение
Как мы видели, независимо от того, будет ли ссылка на noindex на страницу или на nofollow на ссылку, сводится к двум вопросам: хотите ли вы, чтобы эта страница отображалась на страницах результатов поиска и , если поисковые системы будут переходить по ссылкам на эта страница? Например, для страниц с благодарностями или страниц входа в систему ответ на первый вопрос — «нет». Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
PS. Вы noindex пост или страницу, хотя не хотели? Не беспокойтесь, вы легко можете исправить случайную ошибку noindex !
Подробнее: Как не индексировать пост »
noindex vs. nofollow — Справочный центр Siteimprove
Модуль Siteimprove SEO уведомляет пользователей о страницах, исключенных с помощью noindex / nofollow.Эта статья предназначена для объяснения разницы между метатегами noindex и nofollow, когда их использовать и как эти теги влияют на веб-индексирование и страницы результатов поиска (SERP).
И noindex, и nofollow являются частью протокола исключения роботов (REP) , стандарта для управления индексацией веб-страниц на вашем сайте. Давайте рассмотрим несколько примеров noindex и nofollow и то, как они контролируют доступ и индексацию вашего веб-сайта Google и другими поисковыми системами.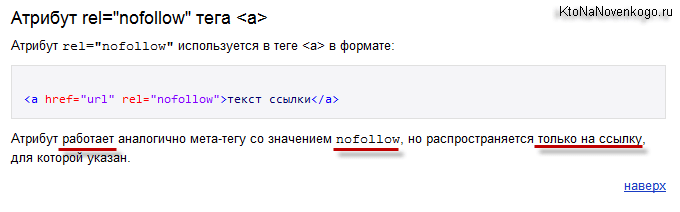
Что такое noindex и когда его использовать?
Обычно, когда робот Googlebot находит страницу, он читает все ссылки на этой странице, а затем выбирает эти страницы и индексирует их. Это основной процесс, с помощью которого робот Google «сканирует» Интернет. Это полезно, поскольку позволяет Google включать все страницы вашего сайта, если они связаны друг с другом. Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что она не может добавить страницу в свой поисковый индекс, даже если поисковая система может сканировать страницу.
Пример Noindex
статей в разделе «Последние новости» CNN могут появиться только на несколько часов, прежде чем они будут обновлены и перенесены в раздел «Статьи». В этом случае CNN захочет проиндексировать полные статьи, а не раздел последних новостей с короткой частью полной статьи.
Таким образом, вы можете добавить тег noindex к статьям, находящимся в настоящее время в разделе «Последние новости», и удалить этот тег, как только статья больше не будет актуальной.
Чтобы превратить обычные ссылки в ссылки noindex, добавьте «noindex» в HTML-код:
Текст ссылки
Что такое nofollow и когда его использовать?
Nofollow — это атрибут HTML, который предписывает большинству поисковых систем воздерживаться от перехода по ссылке и тем самым передавать значение на страницу, на которую ведет ссылка. Некоторые эксперты по SEO интерпретируют это как способ сообщить поисковым системам, что вы не доверяете или не можете поручиться за содержание ссылки, на которую ведет ссылка. Короче говоря, если вы хотите, чтобы поисковая машина проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице; добавьте на свою страницу тег nofollow.
Чтобы превратить обычные ссылки в ссылки nofollow, добавьте «nofollow» в HTML-код *:
Текст ссылки
* Вы можете добавить код вручную, но многие CMS автоматически вставляют его при необходимости. Обратитесь за советом к своему веб-мастеру.
Пример Nofollow
Когда пользователи ищут в Google фразы, связанные с новостями, CNN хочет, чтобы разделы их статей (со статьями) находились в первых строчках поисковой выдачи, потому что статьи являются наиболее ценным активом CNN.
Не имеет смысла располагать их раздел входа наверху.
Таким образом, чтобы сообщить Google, что статьи важнее входа в систему, CNN добавит тег nofollow к своей ссылке для входа.
Примечание: Сканер Siteimprove не учитывает «noindex» или «nofollow» при определении содержания для сканирования. Сканируем на основе настроек сканирования.
Разница между мета-тегами Noindex и Nofollow
Узнали об index, noindex, follow, nofollow…. и интересно, о чем, черт возьми, люди говорят? Прочтите это руководство, чтобы узнать больше!
и интересно, о чем, черт возьми, люди говорят? Прочтите это руководство, чтобы узнать больше!
NOINDEX
Директива noindex — это часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не включать эту конкретную страницу в свой список результатов поиска.
По умолчанию веб-страница настроена на «индексирование». Вам следует добавить директиву на веб-страницу в разделе
Какие примеры страниц следует установить на «noindex»?
- Страницы с благодарностями — если вы включаете на свой веб-сайт формы для сбора потенциальных клиентов, такие как «Свяжитесь с нами» или «Назначьте встречу», вы, вероятно, направите пользователей из своих веб-форм на уникальные страницы с благодарностью после того, как пользователь отправит форму. Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму.Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
- Страницы только для членов — Если у вас есть раздел вашего веб-сайта, посвященный вашим сотрудникам или членам организации, но вы не хотите, чтобы эти веб-страницы были доступны для широкой публики или поисковых систем, директива «noindex» поможет уберечь эти страницы от быть найденным в поисковой выдаче.
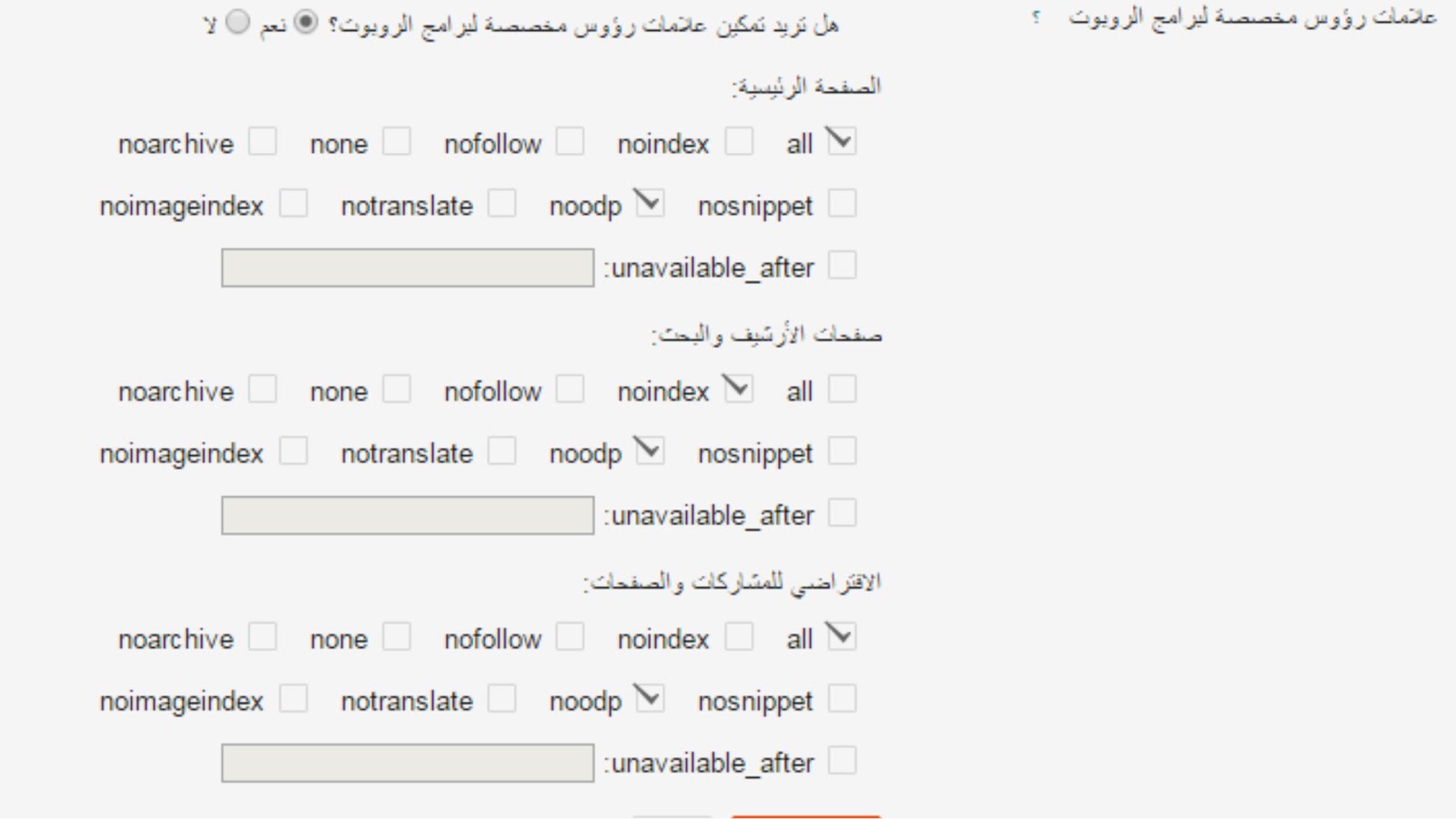 Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму.Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму.Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.NOFOLLOW
Директива nofollow — это часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не передавать равенство ссылок через какие-либо ссылки на данной веб-странице.
Ссылки — важная часть поисковой оптимизации, хотя эксперты все время спорят о том, какую роль ссылки играют в общем рейтинге. Мы знаем, что ссылки с внешних авторитетных веб-сайтов помогут укрепить доверие к нашему собственному веб-сайту и повысить его рейтинг. Внутренние ссылки тоже полезны! Они помогают пользователям и роботу Google перемещаться по вашему сайту и объединять важные идеи.
По умолчанию ссылки настроены на «подписку». Вы можете установить ссылку на «nofollow» следующим образом: Anchor Text , если вы хотите предложить Google, чтобы гиперссылка не передавала значение ссылочного капитала / SEO целевой ссылке.
Какие примеры ссылок следует установить на «nofollow»?
- Ссылки в комментариях блога — Если вы потратили время на написание ценного сообщения в блоге для своего веб-сайта, вы не хотите, чтобы конкурент или спамер по ссылкам мог добавить бесполезный комментарий к вашему сообщению в блоге со ссылкой на свой собственный веб-сайт, на котором написано что-то вроде «Отличный блог. Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
- Платные ссылки — Еще одна тактика SEO, завоевавшая популярность в SEO-сообществе blackhat, — это массовая покупка ссылок в Интернете.Владельцы веб-сайтов со страницей спонсоров на своем сайте могут выбрать включение логотипов и ссылок на свои веб-сайты спонсоров мероприятия, но использовать метатег «nofollow» для каждой ссылки на странице спонсора, чтобы указать Google, что они не могут поручиться за каждую. веб-сайт организации, на который делается ссылка. Имейте в виду, что, хотя ссылки «nofollow» не предназначены для повышения SEO связанного контента, они по-прежнему ценны для взаимодействия с пользователем и привлечения трафика.
 Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
ЗАКЛЮЧЕНИЕ
Надеюсь, это руководство дало вам лучшее понимание noindex vs.nofollow и когда каждый из них может быть полезен. Напоминаем:
- «noindex» предлагает поисковым системам (в первую очередь Google) не индексировать определенную веб-страницу.
- «nofollow» предлагает поисковым системам (в первую очередь Google) не передавать ссылочную массу через ссылки на веб-странице.
При применении директив noindex и nofollow к своему веб-сайту обязательно проконсультируйтесь с квалифицированным агентством цифрового маркетинга. Если все сделано неправильно, эти маленькие теги могут нанести большой ущерб вашему органическому трафику.
Познакомьтесь с Кэти Хельгесен
Кэти Хельгесен, директор по SEO в Launch Digital Marketing, имеет более чем 15-летний опыт работы в области цифрового маркетинга, SEO и аналитики. Ей нравится кататься на американских горках, читать, смеяться, спать и проводить время со своим мужем, 3 детьми и 2 собаками.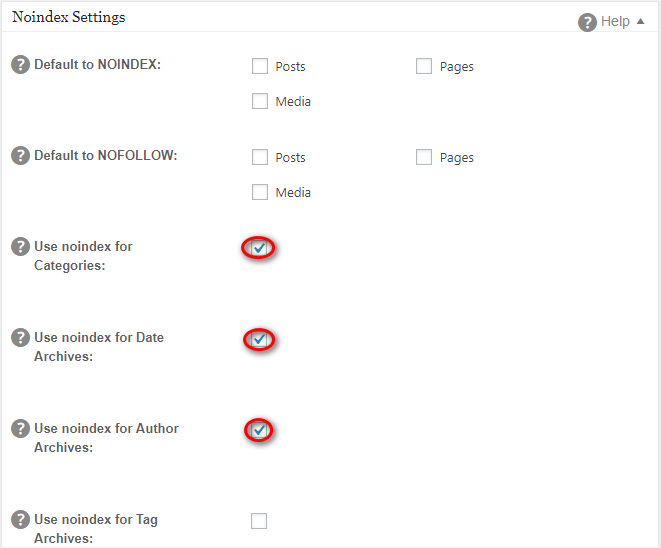 Просмотреть все сообщения Кэти Хельгесен →
Просмотреть все сообщения Кэти Хельгесен →В чем разница между NoIndex и NoFollow?
В чем разница между NoFollow и NoIndex?
Цифровые маркетологи тратят много времени и энергии на совершенствование каждой страницы контента на веб-сайте.У каждой страницы есть цель, с хорошо проработанным и стратегически сформулированным содержанием, ориентированным на целевого пользователя. Контент создается для привлечения потенциальных клиентов и повышения авторитета веб-страниц и их соответствующих доменов. Затем эти страницы отправляются для индексации поисковым системам, чтобы их можно было сканировать и в конечном итоге сохранять для того, чтобы их нашел конечный пользователь.
Однако есть страницы, сканирование которых запрещено. Эти страницы могут помешать вашей тяжелой работе по созданию этого красивого и индивидуального контента.Помня об этом, вам нужно знать, как правильно сообщить сканерам поисковых систем, что вы не хотите, чтобы ваш контент индексировался или сканировался.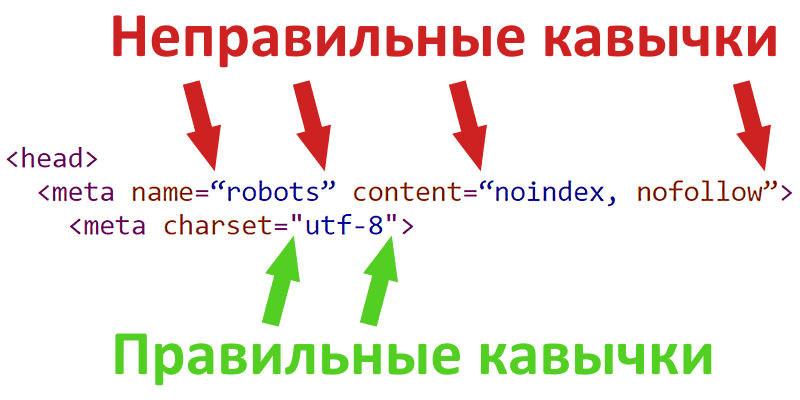
NoIndex — это метатег, который добавляется в код заголовка веб-страницы, чтобы сообщить поисковым системам, что, хотя они могут сканировать страницу, чтобы понять ее содержание, они не могут проиндексировать страницу, чтобы она отображалась в результатах поиска. Это пример того, как NoIndex отображается в исходном коде веб-страницы:
Что такое NoFollow?NoFollow — это метатег, добавляемый в код заголовка веб-страницы, который сообщает поисковым системам не переходить по ссылкам на этой странице.По сути, это дезавуирует ссылки на этой странице и информирует поисковую систему, чтобы она не передавала никаких полномочий или «ссылочного веса» страницам, на которые есть ссылки в вашем контенте. Это пример того, как NoFollow отображается в исходном коде веб-страницы:
Чем они отличаются? NoIndex и NoFollow сильно различаются по полезности. Вы будете использовать NoIndex при указании поисковой системе не сохранять вашу веб-страницу для отображения в результатах поиска, в то время как вы будете использовать NoFollow, когда вы дадите указание сканерам поисковой системы не переходить по ссылкам на вашей странице.Следовательно, NoIndex предназначен для вашей веб-страницы , а NoFollow — для ссылок , которые существуют на вашей веб-странице.
Вы будете использовать NoIndex при указании поисковой системе не сохранять вашу веб-страницу для отображения в результатах поиска, в то время как вы будете использовать NoFollow, когда вы дадите указание сканерам поисковой системы не переходить по ссылкам на вашей странице.Следовательно, NoIndex предназначен для вашей веб-страницы , а NoFollow — для ссылок , которые существуют на вашей веб-странице.
Примером метатега NoIndex является страница с благодарностью. Вы бы не хотели, чтобы поисковая система отображала страницу с благодарностью на странице результатов поисковой системы, поскольку это обычно страница, на которую пользователь попадает после того, как он заполнил вашу форму генерации лидов. Чтобы поисковые системы знали, что эту страницу хранить нельзя, вы должны указать метатег NoIndex в коде заголовка вашей веб-страницы.Другие примеры страниц, которые вы не хотели бы индексировать поисковыми системами, включают Политику конфиденциальности, Положения и условия и страницы Страница не найдена.
Примером метатега NoFollow также является целевая страница. Если ваша целевая страница содержит ссылку на ваше предложение, скажем, электронную книгу «10 советов, как максимально использовать ваши усилия в цифровом маркетинге», вы должны убедиться, что сканер поисковой системы не просканирует эту ссылку и не начнет индексировать этот контент.
Изучение ресурсов для защиты и оптимизации вашего контента для поисковых систем является важной частью вашего контент-маркетинга и инициатив по привлечению потенциальных клиентов.Правильное использование метатегов NoFollow и NoIndex поможет вам максимально использовать вашу контент-стратегию и убедиться, что вы не теряете ценных потенциальных клиентов.
Как мне реализовать NoIndex или NoFollow на моем веб-сайте?
Если вы используете WordPress, мы рекомендуем бесплатный инструмент Yoast SEO для управления вашими усилиями по SEO на странице. Чтобы активировать функции NoIndex и NoFollow, вы должны включить «расширенные настройки» на панели настроек Yoast.
Оттуда вы найдете варианты для реализации правил NoIndex и NoFollow на каждой странице вашего веб-сайта.
Легко, как пирог!
Что это такое и как их использовать?
Три слова, приведенные выше, могут звучать как SEO gobbledegook, но это слова, которые стоит знать, поскольку понимание того, как их использовать, означает, что вы можете управлять роботом Googlebot. Это весело.
Итак, начнем с основ: есть три способа контролировать, какие части вашего сайта будут сканироваться поисковыми системами:
- Noindex: указывает поисковым системам не включать ваши страницы в результаты поиска.
- Disallow: запрещает сканирование ваших страниц.
- Nofollow: говорит им не переходить по ссылкам на вашей странице.
Что такое метатег Noindex?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный метод запрета индексирования страницы — это добавить тег в заголовок HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница не должна быть заблокирована (запрещена) в файле robots.txt файл. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы поисковые системы не индексировали вашу страницу, просто добавьте в раздел следующее:
Вторая часть тега содержимого указывает, что необходимо переходить по всем ссылкам на этой странице, что мы обсудим ниже.
В качестве альтернативы тег noindex можно использовать в теге X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Дополнительную информацию см. В сообщении разработчиков Google о спецификациях метатега Robots и HTTP-заголовка X-Robots-Tag.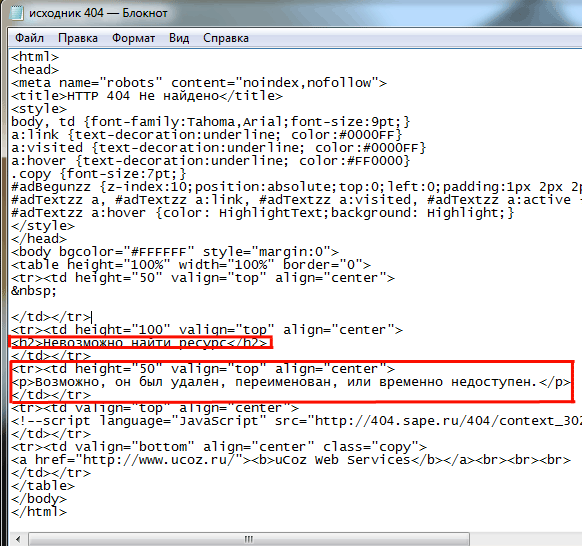
Как использовать Noindex в файле robots.txt?
Тег noindex в файле robots.txt также указывает поисковым системам не включать страницу в результаты поиска, но это более быстрый и простой способ не индексировать сразу много страниц, особенно если у вас есть доступ к вашему robots.txt. файл. Например, вы не можете индексировать любые URL-адреса в определенной папке.
Вот пример директивы noindex, которую можно поместить в файл robots.txt:
Noindex: / robots-txt-noindexed-page /
Однако Google не рекомендует использовать этот метод: Джон Мюллер заявил, что «не следует полагаться на него».
Что такое запретительная директива?
Запрещение страницы означает, что вы даете поисковым системам указание не сканировать ее, что должно быть выполнено в файле robots.txt вашего сайта. Это полезно, если у вас много страниц или файлов, которые бесполезны для читателей или поискового трафика, поскольку это означает, что поисковые системы не будут тратить время на сканирование этих страниц.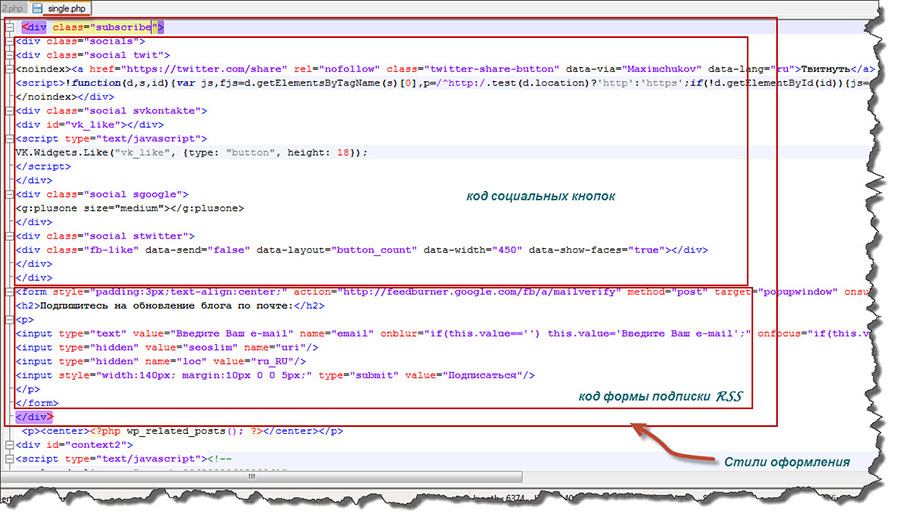
Чтобы добавить запрет, просто добавьте в файл robots.txt следующую строку:
Запретить: / your-page-url /
Если на странице есть внешние ссылки или канонические теги, указывающие на нее, ее все равно можно проиндексировать и ранжировать, поэтому важно сочетать запрет с тегом noindex, как описано ниже.
Предупреждение: запрещая страницу, вы фактически удаляете ее со своего сайта.
Запрещенные страницы не могут передавать PageRank куда-либо еще — поэтому любые ссылки на этих страницах фактически бесполезны с точки зрения SEO — а запрещение страниц, которые должны быть включены, может иметь катастрофические последствия для вашего трафика, поэтому будьте особенно осторожны при написании запрещающих директив.
Как объединить Noindex и Disallow?
Noindex (страница) + Disallow: Disallow не может сочетаться с noindex на странице, потому что страница заблокирована, и, следовательно, поисковые системы не будут сканировать ее, чтобы знать, что они не должны оставлять страницу вне индекс.
Noindex (robots.txt) + Disallow : предотвращает появление страниц в индексе, а также предотвращает сканирование страниц. Однако помните, что через эту страницу не может пройти PageRank.
Чтобы объединить запрет с индексом noindex в файле robots.txt, просто добавьте обе директивы в файл robots.txt:
Запрещено: / example-page-1/
Запрещено: / example-page-2/
Noindex: / example-page-1/
Noindex: / example-page-2/
Что такое тег Nofollow?
Тег nofollow в ссылке указывает поисковым системам не использовать ссылку для определения важности связанных страниц (PageRank) или обнаружения дополнительных URL-адресов на том же сайте.
Обычно nofollows использует ссылки в комментариях и другом контенте, который вы не контролируете, платные ссылки, встраиваемые элементы, такие как виджеты или инфографику, ссылки в гостевых сообщениях или что-то не по теме, на которое вы все еще хотите ссылаться.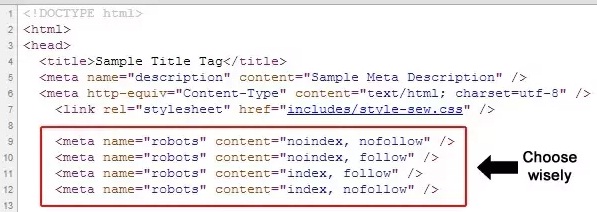
Исторически сложилось так, что оптимизаторы поисковых систем также избирательно исключали переход по ссылкам, чтобы направлять внутренний PageRank на более важные страницы.
Теги Nofollow могут быть добавлены в одном из двух мест:
- страницы (чтобы nofollow все ссылки на этой странице):
- Код ссылки (для nofollow отдельной ссылки): пример страницы
nofollow не предотвратит полное сканирование связанной страницы; он просто предотвращает сканирование по этой конкретной ссылке. Наши и другие тесты показали, что Google не будет сканировать URL-адрес, который он находит в ссылке nofollowed.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница отображается в файле Sitemap, эта страница все равно может отображаться в результатах поиска. Точно так же, если это URL, о котором уже знают поисковые системы, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и представил два новых атрибута ссылки, а именно:
- rel = «sponsored» — Атрибут sponsored следует использовать для идентификации ссылок, предназначенных для рекламных целей, при наличии соглашений о спонсорстве и компенсации.
- rel = «ugc» — В качестве атрибута для пользовательского содержимого это значение рекомендуется для ссылок на сайтах с пользовательским содержимым, например для сообщений на форумах и комментариев в блогах.
Кроме того, все ссылки, помеченные как nofollow, sponsored или ugc, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как раньше использовалось для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние и мнения экспертов.
Что такое Noindex Nofollow?
Как упоминалось выше, добавление тега nofollow к странице не препятствует ее полному сканированию. Поэтому, чтобы предотвратить индексирование, вам также нужно не индексировать страницу. Это позволит Google сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вы также должны запретить это (см. Выше).
Поэтому, чтобы предотвратить индексирование, вам также нужно не индексировать страницу. Это позволит Google сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вы также должны запретить это (см. Выше).
Другие директивы: Canonical Tags, Pagination и Hreflang
Есть и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса:
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать.Канонизированные (т.е. вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
- Pagination группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента предназначены для какого региона, чтобы они могли определить приоритетность правильной версии для каждой аудитории.Все эти версии останутся в индексе.
 Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.Сколько времени вам следует потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны эффективность сканирования и бюджет сканирования для SEO, и, хотя обычной практикой является запрещение и noindex большие группы страниц, которые не имеют преимуществ для поисковых систем или читателей (например, back -end кода, который используется только для работы сайта или некоторых типов дублированного контента), решение о том, скрывать ли много отдельных страниц, вероятно, не лучший вариант использования времени и усилий.
Google любит индексировать как можно больше URL-адресов, поэтому, если нет особой причины скрыть страницу от поисковых систем, обычно можно оставить решение на усмотрение Google. В любом случае, даже если вы скроете страницы от поисковых систем, Google все равно будет проверять, изменились ли эти URL-адреса. Это особенно актуально, если есть ссылки, указывающие на эту страницу; даже если Google забыл об URL-адресе, он может снова обнаружить его в следующий раз, когда на него будет найдена ссылка.
Тестирование с помощью Search Console, DeepCrawl и Robotto
Тестовые роботы.txt с помощью Search Console
Тестер robots.txt в Search Console (в разделе «Сканирование») — популярный и в значительной степени эффективный способ проверить новую версию файла на наличие ошибок до того, как он будет опубликован, или протестировать конкретный URL, чтобы убедиться, что он заблокирован:
Однако этот инструмент не работает точно так же, как Google, с некоторыми небольшими различиями в конфликтующих правилах разрешения / запрета, которые имеют одинаковую длину.
Инструмент тестирования robots.txt сообщает, что это разрешено, однако Google сказал: «Если результат не определен, robots.txt могут разрешить или запретить сканирование. По этой причине не рекомендуется полагаться на то, что какой-либо из результатов будет использоваться повсеместно ».
Подробнее см. В этом обсуждении на справочном форуме в Центре веб-мастеров.
Найти все неиндексируемые страницы с помощью DeepCrawl
Запустите универсальное сканирование без каких-либо ограничений (но с применением условий robots.txt), чтобы DeepCrawl мог вернуть все ваши URL-адреса и показать вам все индексируемые / неиндексируемые страницы.
Если у вас есть параметры URL, которые были заблокированы для робота Googlebot с помощью Search Console, вы можете имитировать эту настройку для сканирования, используя поле «Удалить параметры» в разделе Дополнительные настройки> Перезапись URL .
Затем вы можете использовать следующие отчеты, чтобы убедиться, что сайт настроен так, как вы ожидали при первом сканировании, а затем объединить их со встроенными журналами изменений при последующих сканированиях.
Индексация> Страницы Noindex
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, HTTP-заголовке или файле robots.txt файл.
Индексация> Запрещенные страницы
В этом отчете содержатся все URL-адреса, которые невозможно просканировать из-за запрещающего правила в файле robots.txt. На панели управления вашего отчета есть цифры для обоих этих отчетов:
Используйте наши интуитивно понятные отчеты в каждом из наших отчетов, чтобы проверять определенные папки и выявлять шаблоны в URL-адресах, которые в противном случае вы могли бы пропустить:
Протестируйте новый файл robots.txt с помощью DeepCrawl
Используйте роботов DeepCrawl.txt Функция перезаписи в дополнительных настройках для замены живого файла на пользовательский.
Затем при следующем запуске сканирования вы можете использовать тестовую версию вместо активной.
В отчетах о добавленных и удаленных запрещенных URL-адресах будет показано, какие именно URL-адреса были затронуты измененным файлом robots.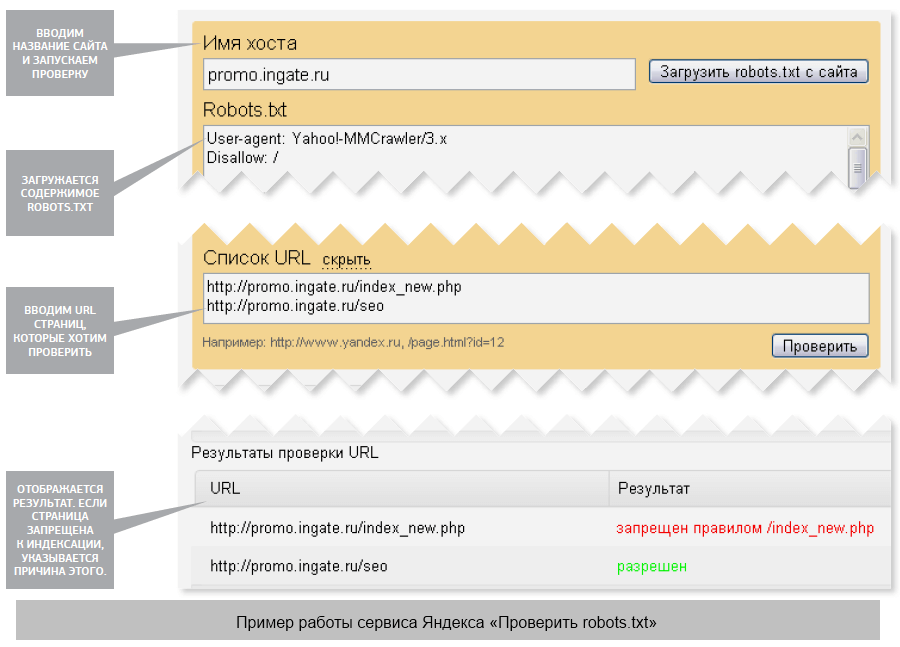 txt, что упростит оценку.
txt, что упростит оценку.
Для получения дополнительной информации прочтите наше руководство по управлению изменениями robots.txt с помощью DeepCrawl.
Хотите больше такого?
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и disallow для управления сканированием вашего сайта.
Вы можете узнать больше об этих темах в нашей Технической библиотеке SEO или, если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство.
Кроме того, если вы заинтересованы в том, чтобы быть в курсе последних обновлений Google и рекомендациями по передовому опыту, почему бы не заглянуть в наши электронные письма?
Зайди меня!
Автор
Сэм Марсден
Сэм Марсден — менеджер по поисковой оптимизации и контенту DeepCrawl.Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых публикаций, таких как Search Engine Journal и State of Digital.
Теги
Управление роботами
Разница между метатегами Noindex и Nofollow
Если вы тратите какое-то время на выполнение задач цифрового маркетинга, вы, вероятно, встречали разные термины. Некоторые из них, такие как скорость страницы и цена за клик (CPC), довольно просты.Однако некоторые маркетинговые термины, особенно относящиеся к метатегам, могут немного сбивать с толку. Сегодня эксперты по цифровому маркетингу из Saba SEO, ведущей SEO-компании в Сан-Диего, обсуждают разницу между метатегами noindex и nofollow.
Что такое тег Noindex?
Тег «noindex» предназначен для того, чтобы делать то, что подразумевает его название — указывать поисковым системам, таким как Google, не индексировать или оценивать конкретную веб-страницу. Это необходимо сделать, поскольку веб-страницы по умолчанию автоматически устанавливаются на «index.Как правило, у вас должны быть поисковые системы, пропускающие страницы, которые мало или совсем не предлагают SEO, а также страницы, на которые вы не хотите, чтобы клиенты попадали в поисках того, что вы предлагаете. Общие страницы noindex включают в себя:
Общие страницы noindex включают в себя:
• Страницы с благодарностью
• Страницы с конфиденциальным содержанием, предназначенные только для внутреннего доступа
• Страницы только для членов
Что такое тег Nofollow?
Тег «nofollow» предназначен только для ссылок. Он говорит поисковым системам не подсчитывать ссылки на определенные страницы для целей качества / равенства ссылок.Хотя как внешние, так и внутренние ссылки могут быть полезны для целей ранжирования, бывают случаи, когда вы не хотите, чтобы ссылки имели большое значение, потому что они не предлагают реальной ценности для SEO или могут быть сомнительными. Теги Nofollow могут использоваться для:
• Комментарии в блогах, где легче разместить нерелевантные ссылки
• Ссылки, которые являются рекламными или спонсорскими
• Платные ссылки
• Ссылки, которые появляются в пресс-релизах
Примечание: ссылки Nofollow не имеют Значение PageRank (фактор Google), но они по-прежнему имеют некоторую ценность, поскольку позволяют посетителям находить ваш контент или сайт.
Вкратце, теги noindex не позволяют поисковым системам подсчитывать определенные страницы для целей ранжирования, а теги nofollow управляют количеством ссылок. То, как вы будете использовать эти теги, будет зависеть от представленного контента и целей ваших веб-страниц, но конечная цель — оптимизировать вашу видимость в Интернете, а также создать удобство для пользователей.
Цифровым маркетологам, которым нужна помощь в использовании таких инструментов, как метатеги, для оптимизации своего присутствия в Интернете и повышения рейтинга в поисковой сети, следует обратиться к надежным профессионалам в Saba SEO, ведущей SEO-компании в Сан-Диего.Мы предлагаем первоклассный опыт в области поисковой оптимизации, маркетинговых кампаний в Интернете, управления социальными сетями, веб-разработки и многого другого. Чтобы узнать больше о наших передовых услугах, позвоните нам сегодня по телефону 858-277-1717.
Noindex vs Nofollow vs Disallow Commands
29 марта 2019 г.
Части следующего адаптированы из моей книги Tech SEO Guide , теперь доступной на Amazon.
Существует распространенная проблема, связанная с различием между командами noindex, nofollow и disallow.Все три являются мощными инструментами для повышения эффективности обычного поиска на веб-сайте, но каждый имеет уникальные ситуации, в которых они могут применяться. К сожалению, во многих случаях они применяются неправильно, что значительно снижает эффективность поиска на сайте.
Две операции поискового робота Чтобы понять, что делают команды noindex, nofollow и disallow, давайте сделаем шаг назад и рассмотрим, что делают роботы поисковых систем. Поисковые системы рассылают роботов, чтобы они сканировали и понимали сайт. Эти роботы сложны, но выполняют две основные операции.
Эти роботы сложны, но выполняют две основные операции.
- Сканирование : как только робот обнаруживает веб-сайт, он просматривает все страницы и файлы на веб-сайте, которые может найти. Можно установить ограничения для файлов и страниц, которые может видеть робот, и внести другие изменения, чтобы робот находил все, что ему нужно.
- Индексирование : после сканирования роботы берут всю информацию, собранную во время этого сканирования, чтобы решить, какая информация, содержащаяся на конкретной странице, может и должна отображаться в результатах поиска.В рамках этого роботы поисковых систем также будут решать, в какие результаты поиска следует включить страницы веб-сайта (если таковые имеются) и где страница должна занимать место в этих результатах.
Disallow против Noindex против Nofollow
Disallow: Controlling Crawling Первый метод управления поисковым роботом — это команда запрета. Это указано в файле robots. txt. Файл robots.txt — это простой текстовый файл, размещенный в корневом каталоге вашего веб-сайта.Он предоставляет роботам директивы, сообщающие им, какие каталоги вы бы предпочли, чтобы они не сканировали.
txt. Файл robots.txt — это простой текстовый файл, размещенный в корневом каталоге вашего веб-сайта.Он предоставляет роботам директивы, сообщающие им, какие каталоги вы бы предпочли, чтобы они не сканировали.
Если указано, поисковый робот, который соблюдает эту команду, не будет сканировать страницу, файл или каталог, которые были запрещены. Например, вы можете указать это в файле robots.txt, чтобы запретить поисковому роботу сканировать все, что находится в / a-secret-directory.
Disallow: / a-secret-directory
Вы также можете указать запрет только для определенного робота.Например, эта запись в файле robots.txt указывает ботам Google избегать каталога my-content-admin-area. Однако боты Bing все еще могли сканировать этот каталог.
user-agent: googlebot
Disallow: / my-content-admin-area /
Запрещенные файлы могут по-прежнему индексироваться и появляться в результатах поиска. Например, Google и Bing могут найти ссылку на запрещенную страницу на вашем веб-сайте или в другом месте в Интернете.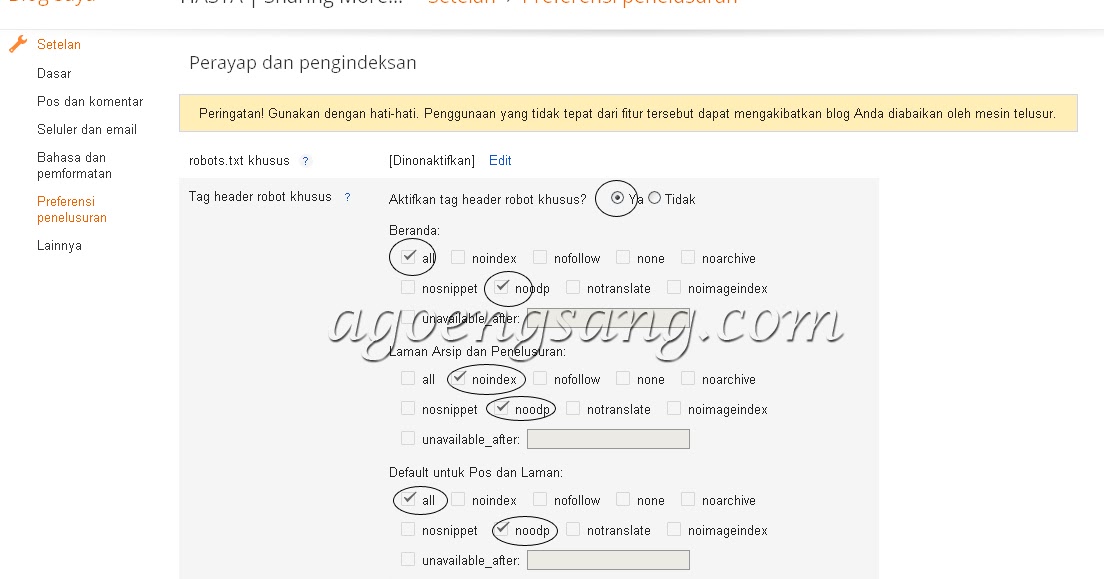 Они не могли сканировать страницу, чтобы увидеть ее содержимое, но они знали бы, что страница существует, и могли бы показать ее в индексе Google.
Они не могли сканировать страницу, чтобы увидеть ее содержимое, но они знали бы, что страница существует, и могли бы показать ее в индексе Google.
Как правило, лучше ничего не запрещать. Один набор файлов, который вы хотите никогда не запрещать, — это файлы JavaScript, CSS или изображения. Эти файлы управляют внешним видом страницы, и Google полагается на эти факторы дизайна при оценке страницы, особенно при определении удобства для мобильных устройств.
Meta Robots Nofollow: Controlling CrawlingДалее у нас есть команда nofollow. На самом деле существует два разных оператора nofollow. Команда nofollow, управляющая сканированием, — это мета-робот nofollow.Этот nofollow применяется на уровне страницы путем указания nofollow в метатеге robots в теге
страницы.
...
...
При размещении в
веб-страницы мета-nofollow дает команду роботу поисковой системы не сканировать никакие ссылки на странице. Это часть большого набора директив, которые вы можете указать в метатеге robots.
Это часть большого набора директив, которые вы можете указать в метатеге robots.Роботы, соблюдающие эту директиву, смогут сканировать эту страницу, но не будут сканировать страницы, на которые есть ссылки с этой страницы. Если вы не хотите, чтобы роботы вообще сканировали страницу, не говоря уже о ссылках, содержащихся на этой странице, то запрет robots.txt — лучший метод управления сканированием.
Rel Nofollow: объяснение природы ссылки Другой вариант nofollow — это команда rel = ”nofollow”. Это может повлиять на сканирование, но более важная цель состоит в том, чтобы объяснить, почему эта ссылка включена.Традиционно rel = ”nofollow” использовался для указания любых ссылок, которые были спонсируемыми или имели денежные отношения. С тех пор Google ввел другие типы квалификаторов: rel = «sponsored» и rel = «ugc». Квалификатор rel = «sponsored» предназначен для любой платной ссылки, rel = «ugc» — для любой ссылки, содержащейся в пользовательском контенте, а rel = «nofollow» — для любой другой ссылки, с которой вы бы предпочли, чтобы роботы Google не связывали Ваш сайт.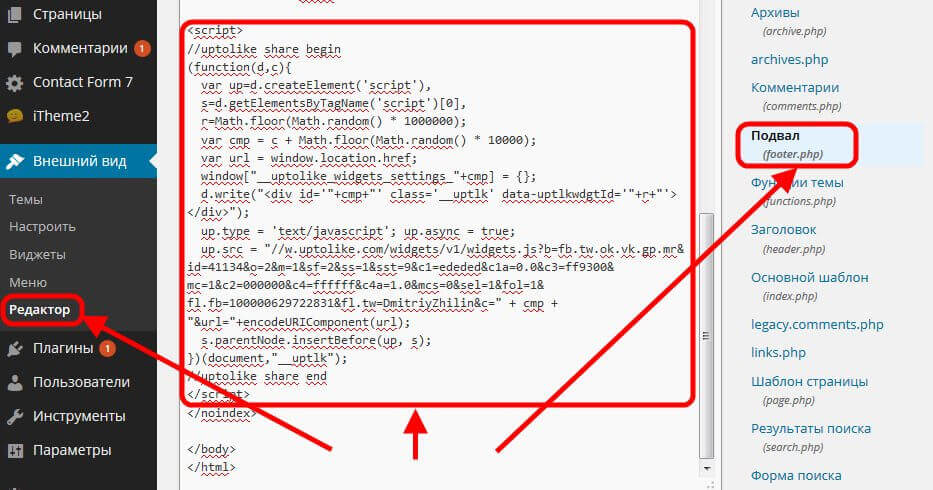
Эти команды rel указываются на уровне ссылки с атрибутом rel, добавленным к определенному тегу .Например, эта ссылка будет nofollowed, и эта ссылка на страницу / no-robots-here не будет связана с вашим веб-сайтом.
Noindex: управление индексированием
Команда «noindex» может быть указана на странице в мета-роботах тег. Если на страницу включен метатег noindex, поисковым роботам разрешено сканировать страницу, но им не рекомендуется индексировать страницу (это означает, что страница не будет включена в результаты поиска, если эта команда будет соблюдена).
Пример:
Несколько примечаний:
- Ранее вы могли указать noindex в файле robots.txt. Однако это больше не поддерживается Google (и, вероятно, никогда не было). При этом официальном отсутствии поддержки единственный способ указать noindex — на уровне страницы.
- Если вы не можете добавить метатег к страницы, вы также можете использовать X-Robots в заголовке HTTP. Это может быть полезно для запрета индексации содержимого, отличного от HTML, например PDF-файлов или некоторых изображений.

Важно четко понимать, как команды Disallow и Noindex работают вместе. Эти команды можно объединить тремя способами, чтобы повлиять на индексацию и сканирование.
| Запрет | Noindex | |
| Сценарий 1 | X | |
| X | X |
В сценарии 1 страница с параметром noindex не будет включена в результат поиска.Однако робот все еще может сканировать страницу, то есть роботы могут получать доступ к содержанию на странице и переходить по ссылкам на странице.
В сценарии 2 страница не будет сканироваться, но может быть проиндексирована и появится в результатах поиска. Поскольку робот не сканировал страницу, робот ничего об этом не знает. Любой контент, включенный в эту страницу в результаты поиска, будет собираться из других источников, например, из ссылок на страницу.
Сценарий 3 будет работать точно так же, как Сценарий 2, если в метатеге robots был указан noindex.Это связано с тем, что при указании Disallow робот не будет сканировать страницу. Если робот не сканирует страницу, он не увидит метатег, указывающий на то, что страницу не индексировать. Если для страницы необходимо установить значение noindex и запретить, сначала установите noindex, а затем, после удаления страницы из поискового индекса, установите запрет.
Рекомендации по использованию Nofollow Когда использовать Nofollow для управления сканированием? Как правило, роботам нужно сказать, что они могут переходить по всем ссылкам на странице. Если слишком агрессивно указывать, по каким ссылкам следовать или nofollow, может начаться впечатление, что веб-сайт пытается манипулировать восприятием веб-сайта роботом. Это практика, известная как формирование страницы, где команды nofollow используются для моделирования того, как сигналы с одной страницы передаются на другую. В лучшем случае эти попытки манипулировать роботом больше не работают. В худшем случае попытки манипулировать роботами с помощью rel nofollow могут привести к штрафу.
Если слишком агрессивно указывать, по каким ссылкам следовать или nofollow, может начаться впечатление, что веб-сайт пытается манипулировать восприятием веб-сайта роботом. Это практика, известная как формирование страницы, где команды nofollow используются для моделирования того, как сигналы с одной страницы передаются на другую. В лучшем случае эти попытки манипулировать роботом больше не работают. В худшем случае попытки манипулировать роботами с помощью rel nofollow могут привести к штрафу.
Когда использовать квалификаторы Rel в ссылках
Rel = «nofollow», rel = «sponsored» или rel = «ugc» следует использовать для конкретных случаев, когда вам необходимо четко указать характер ссылки.Ярким примером являются ссылки на странице, на которой был произведен платеж в обмен на ссылку. Например, если сообщение в блоге содержит ссылки на рекламу, эти ссылки должны иметь атрибут rel nofollow. Однако с помощью дополнительных квалификаторов Google дает понять, что любые пользовательские ссылки должны иметь этот квалификатор.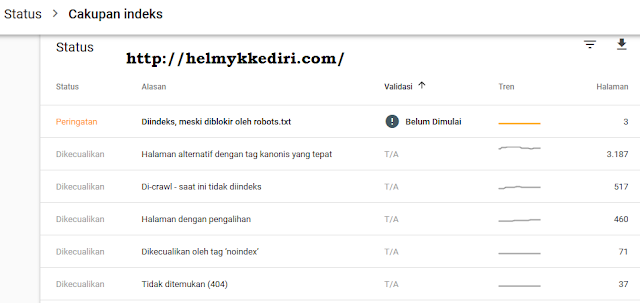
Disallow, Noindex или Nofollow являются необязательными
Disallow, Noindex и Nofollow являются необязательными — роботам не нужно выполнять ни одну из этих команд. На самом деле, слово «команда» — это немного преувеличение.Эти директивы являются рекомендациями. Боты Google могут игнорировать любую из этих рекомендаций. Часто игнорирование этих команд является признаком более серьезной проблемы, связанной с тем, что роботы неправильно понимают, как сканировать ваш сайт. В таких ситуациях вы хотите исследовать, в чем заключается эта более серьезная проблема, и решить ее, вместо того, чтобы просто переоснащать свои команды noindex, disallow или nofollow.
Кроме того, поскольку эти команды являются необязательными, вы не хотите полагаться на них для каких-либо важных аспектов своего веб-сайта.Если часть веб-сайта не должна быть общедоступной или если вы хотите, чтобы часть вашего веб-сайта не попала в результаты поиска Google, вам следует рассмотреть альтернативы. Обычной областью, где это становится проблемой, являются промежуточные веб-сайты, которые вы явно не хотите, чтобы роботы Google сканировали, и определенно не хотите их индексировать. На промежуточном веб-сайте запрета запрета или noindex недостаточно для гарантии того, что боты покинут сайт. Вместо этого вы захотите потребовать логин для доступа к этому промежуточному сайту.Вход в систему не является обязательным и не может быть проигнорирован, что означает, что боты не смогут его сканировать или индексировать.
Обычной областью, где это становится проблемой, являются промежуточные веб-сайты, которые вы явно не хотите, чтобы роботы Google сканировали, и определенно не хотите их индексировать. На промежуточном веб-сайте запрета запрета или noindex недостаточно для гарантии того, что боты покинут сайт. Вместо этого вы захотите потребовать логин для доступа к этому промежуточному сайту.Вход в систему не является обязательным и не может быть проигнорирован, что означает, что боты не смогут его сканировать или индексировать.
Самое важное, что нужно помнить, — это две операции: сканирование и индексирование. Мы можем контролировать или влиять на оба из них, используя разные директивы.
В итоге эти директивы таковы:
- Disallow запрещает роботу сканировать страницу, файл или каталог.
- Noindex запрещает роботу индексировать страницу.
- Meta nofollow говорит роботу не переходить по определенной ссылке или всем ссылкам на странице.
- Rel = «nofollow» (или rel = «sponsored» или rel = «ugc») дополнительно уточняет природу ссылки
Используйте квалификаторы Disallow, Noindex, Meta Nofollow и rel умеренно и только после тщательного рассмотрения всех возможных последствий как их использование повлияет на эффективность SEO вашего сайта. При их использовании убедитесь, что вы не блокируете доступ роботов к важным частям вашего веб-сайта, таким как JavaScript, CSS или файлы изображений.В случае сомнений не добавляйте никаких директив.
Тестирование команд роботаЕсли вы решили использовать команды робота, вы хотите протестировать их, чтобы убедиться, что роботы правильно понимают команды. Хотя вы можете использовать инструменты сканирования, чтобы помочь в этом, более простой метод тестирования — в Google Search Console.
Тестирование Robots.txt
В Google Search Console вы можете проверить текущий файл robots.txt, чтобы увидеть, какие страницы, если таковые имеются, в настоящее время указаны как страницы, к которым Google не должен получать доступ. В настоящее время он недоступен в навигации в Google Search Console, но доступен как устаревший инструмент (доступ прямо здесь).
В настоящее время он недоступен в навигации в Google Search Console, но доступен как устаревший инструмент (доступ прямо здесь).
На этой странице вы увидите текущий файл robots.txt вашего сайта. Под файлом robots.txt вы можете ввести URL-адреса со своего веб-сайта и проверить, не сможет ли Google сканировать эту страницу из-за файла robots.txt. В этом примере каталог wp-admin заблокирован для сканирования, но все остальные URL-адреса должны быть разрешены для сканирования.
Проверка возможности сканирования и индексирования
Другой метод проверки того, могут ли роботы сканировать или индексировать страницу в Google Search Console, заключается в использовании инспектора URL.В новой консоли поиска Google введите URL-адрес, который вы хотите протестировать.
После загрузки результатов в отчете о покрытии вы можете увидеть, разрешены ли сканирование и индексирование. В этом примере разрешены оба варианта — это предполагаемый ответ. Если, однако, я указал noindex или disallow для этой страницы, сканирование или проиндексированные разрешенные ответы должны быть отрицательными.